이 블로그 게시물에서는 언어 학습 모델(LLM)과 PDF 파일로 채팅할 수 있는 놀라운 기능을 살펴봅니다. 먼저 다음을 통해 PDF 파일로 채팅하는 방법을 보여드리겠습니다. ChatGPT 웹사이트. 다음으로 모든 종류의 PDF 파일과 채팅하는 방법에 대한 자세한 코드 자습서를 살펴봅니다. 그 후 ChatGPT API를 사용하여 PDF와 관련된 반복 작업을 자동화하는 첫 번째 자동화를 구축합니다. 그런 다음 사용자 인터페이스(UI)가 있는 고유한 챗봇을 구축하고 배포하여 PDF와 채팅합니다. 여정이 끝나면 일상 생활에서 PDF와 관련된 개인 및 전문 작업을 자동화할 수 있는 기술을 갖추게 될 것입니다.
다음과 같이 진행합니다 –
시작하겠습니다!
개요
복잡하고 광대한 디지털 세계에서 PDF는 모든 문서화의 초석이 되었습니다. 그들은 기업 환경에서 개인 환경에 이르기까지 현대 생활의 구석구석에 스며들었습니다. 이러한 디지털화된 문서는 복잡성과 크기가 다양합니다. 상세한 청구서, 편리한 은행 명세서, 구직 이력서 및 복잡한 건축 계획에 이르기까지 이러한 유비쿼터스 파일 형식은 상호 연결된 세상의 필수 요소입니다.
이제 인류는 PDF로 생각할 수 있는 모든 형태의 정보를 디지털화하는 데 성공했습니다. 앞으로 다가올 새로운 과제는 "Data-On-Demand"입니다. 우리 손끝.
언어 학습 모델(LLM)을 입력합니다. 강력한 알고리즘과 인간 언어를 이해하는 타고난 능력을 갖춘 LLM은 주문형 데이터를 달성하는 길을 밝힐 수 있는 횃불 운반자입니다. PDF와의 실시간 커뮤니케이션을 촉진하고 디지털 잉크를 대화식의 의미 있는 대화로 변환하고 매우 빠른 문서 처리 워크플로우를 가능하게 할 수 있습니다.
PDF와의 채팅 기록
역사적으로 PDF와의 "채팅"은 PDF 파일에서 정보를 추출, 처리 및 검색하는 도구와 기술의 조합을 사용하여 매우 제한된 용량으로 가능했습니다.
- Python의 PyPDF2 또는 JavaScript의 PDF.js와 같은 라이브러리는 PDF 파일에서 텍스트를 추출하는 데 사용되었습니다.
- 스캔한 PDF 또는 텍스트 이미지가 포함된 PDF의 경우 OCR 기술을 사용하여 Tesseract와 같은 도구를 사용하여 텍스트를 인식하고 추출했습니다.
- 텍스트가 추출되면 전통적인 검색 알고리즘을 사용하여 키워드나 문구를 기반으로 정보를 찾았습니다.
- 많은 경우에 특정 정보를 검색하기 위해 정규식을 사용하여 추출된 텍스트의 패턴을 일치시켰습니다.
- NLTK, Spacy 또는 Stanford NLP와 같은 라이브러리를 사용하여 콘텐츠를 이해하기 위해 추출된 텍스트에서 토큰화, 품사 태깅 및 명명된 엔터티 인식과 같은 작업을 수행했습니다.
- Dialogflow, IBM Watson 또는 Microsoft의 LUIS와 같은 플랫폼을 사용하여 대화형 에이전트를 만들었습니다. 그러나 이를 위해서는 봇을 교육하고 유지 관리하는 데 상당한 수작업이 필요했으며 PDF 콘텐츠를 이해하고 처리하는 능력이 제한되었습니다.
본질적으로 PDF로 대화에 참여하는 것은 LLM이 등장하기 전에 번거로운 작업이었습니다. 텍스트 추출, 검색 알고리즘, 패턴 인식 및 언어 처리를 위한 다양한 도구의 혼합이 필요했습니다. 노력에도 불구하고 결과가 제한적인 경우가 많아 LLM과 같은 고급 솔루션이 필요했습니다.
LLM을 사용하여 PDF와 채팅
LLM(Language Learning Models)을 사용하여 PDF와 채팅하면 문서와 상호 작용하는 방식이 혁신적으로 바뀌었습니다. LLM의 새로운 물결은 방대한 양의 텍스트에 대해 교육을 받았으며 자연어 쿼리에 대해 인간과 유사한 응답을 생성할 수 있습니다. 사용자는 단순히 자연어로 쿼리를 입력할 수 있으며 LLM은 PDF에서 관련 정보를 추출하여 자연어로 응답합니다.
연구 논문과 대화하고 필요에 따라 특정 정보를 추출하는 아래 예를 살펴보십시오.

LLM의 기술에 대해 자세히 알아보려면 다음으로 이동하십시오. 부록 I.
일상 생활에서 PDF와 관련된 작업을 자동화하고 싶습니까? 더 이상 보지 마세요! 노력하다 Nanonets의 자동화된 문서 워크플로 현재 LLM 및 Generative AI로 구동됩니다.
ChatGPT 웹사이트에서 PDF로 채팅하기
ChatGPT Plus 사용자는 PDF로 채팅하기 쉽습니다. ChatGPT Plus 구독이 없는 다른 사용자에게는 제한이 있는 까다로운 프로세스입니다. 두 가지 경우를 모두 논의해 봅시다.
ChatGPT 플러스 사용자의 경우
이를 수행할 수 있는 두 가지 방법이 있습니다. 둘 다 논의합시다.
방법 I
첫 번째 방법에서는 ChatGPT 플러그인을 사용하여 PDF와 채팅합니다. 이 방법은 모든 종류의 스캔 및 디지털 PDF 파일에 적용됩니다. 시작하자.
방법 II
OpenAI는 ChatGPT Plus 사용자를 위한 "코드 해석기" 기능도 출시했습니다. 위에서 설명한 첫 번째 방법은 대부분의 PDF와 채팅하는 데 권장되지만 Code Interpreter는 PDF에 표 형식 데이터가 많이 포함되어 있을 때 유용할 수 있습니다. 그 이유는 "Code Interpreter"는 ChatGPT 웹사이트의 UI에서 Python 코드를 직접 작성하고 실행할 수 있어 탐색적 데이터 분석(EDA) 및 데이터 시각화를 수행하는 데 사용하기에 적합합니다.
이 기능을 사용하는 방법을 알아봅시다.
따라서 이 방법은 테이블 형식 데이터와 상호 작용하고, EDA를 수행하고, 시각화를 만들고, 일반적으로 통계 작업에 적합합니다.
그러나 첫 번째 방법은 PDF 파일의 텍스트 데이터와 상호 작용하는 데 확실히 더 잘 작동합니다.
필요에 따라 두 가지 방법 중 하나를 사용할 수 있습니다.
다른 사용자를 위해
ChatGPT Plus 구독이 없는 사용자는 PDF에 있는 데이터를 ChatGPT에 제공하기 전에 텍스트로 변환해야 합니다. 이 프로세스는 때때로 다음과 같은 이유로 문제가 될 수 있습니다.
- 작은 PDF 파일만 처리할 수 있습니다.
- 수동적이고 번거롭습니다.
시작하겠습니다 –
따라서 이 방법은 ChatGPT Plus에 가입하지 않았지만 여전히 ChatGPT 웹사이트를 사용하여 PDF로 채팅하려는 사람들을 위한 것입니다.
위 섹션을 요약하면 –
- PDF로 채팅하는 일회성 작업의 경우 ChatGPT Plus 구독을 구매하고 위의 방법을 사용하는 것이 가장 좋습니다.
- 사람들이 ChatGPT Plus 구독 없이 PDF 파일로 채팅을 찾고 있는 일회성 작업의 경우,
- 위에 표시된 방법은 작동하지만 제한이 있습니다. 작은 PDF 파일만 처리할 수 있습니다. 게다가 수동적이고 번거롭다.
- 파이썬 코드로 채팅을 구현하는 것이 더 나을 것입니다. (코드 자습서 섹션으로 이동)
- 자동화하려는 반복 작업의 경우 ChatGPT API를 사용하여 Python 코드에서 채팅/PDF와 상호 작용하는 것이 가장 잘 작동합니다. (코드 자습서 섹션으로 이동)
PDF 채팅을 위한 최고의 LLM
우리는 사용 가능한 가장 진보된 LLM을 시도하고 서로 비교하는 방법을 평가했습니다. 이 섹션에서는 결과를 요약합니다.
우리가 시도한 각 LLM의 장단점과 함께 자세한 분석을 보려면 다음으로 이동하십시오. 부록 II.
요약
현재 API 액세스를 통해 사용할 수 있는 최고의 LLM XNUMX개에 대한 학습 내용을 요약해 보겠습니다.

다음과 같은 표준 벤치마킹 테스트를 위해 각 LLM 모델의 양적 벤치마크 점수도 추가했음을 알 수 있습니다.
- MT-bench(점수): MT-bench 점수는 정확하고 고품질의 번역을 생성하는 모델의 능력을 반영하는 성능 측정입니다.
- Arena Elo 등급: Arena Elo 등급은 다른 엔티티에 대한 게임 결과를 사용하여 플레이어의 상대적 기술을 계산합니다.
- MMLU: MMLU는 합성된 신호와 원본 신호 사이의 왜곡을 평가하여 합성 시스템의 성능과 품질을 정량화합니다.
팁: 실제로 다음으로 이동할 수 있습니다. https://poe.com/ 위에서 논의한 LLM 중 일부를 테스트하십시오. Poe는 ChatGPT 웹사이트와 유사한 인터페이스를 제공하며 이러한 LLM과 채팅할 수 있습니다.

PDF와의 채팅에 권장되는 LLM
- GPT-4: 이 모델은 고급 작업이나 창의적 글쓰기가 필요한 작업에 사용할 수 있습니다. 대부분의 다른 작업에서도 다른 LLM을 쉽게 능가할 수 있지만 비용이 많이 들고 액세스가 제한되므로 모든 작업에 권장되지는 않습니다.
- GPT-3.5: 이 모델은 매우 다재다능하며 대부분의 작업에 사용할 수 있습니다. 가격이 적당하고 미세 조정이 가능합니다. 개인 및 전문 작업에서의 사용은 이미 시작되었으며 엄청난 속도로 성장하고 있습니다.
- 클로드 LLM : 이 모델은 사용자가 보내는 프롬프트의 크기가 크고 사용자가 해결 방법을 사용하지 않고 이러한 큰 채팅 메시지/프롬프트를 직접 보내려는 경우에 사용할 수 있습니다. 제공되는 프롬프트 크기는 100개의 토큰이며 단일 프롬프트에 약 75개의 단어를 수용할 수 있습니다.
이제 PDF로 채팅하기 위한 최상의 모델을 찾았으므로 이제 아래의 Python 코드 자습서를 따라 PDF로 채팅을 시작하는 방법을 알아보겠습니다.
OpenAI API를 사용하여 PDF와 채팅
참고 : 이 자습서에서 사용된 모든 코드 및 예제 파일은 여기에서 액세스할 수 있습니다. Github 저장소.
이제 OpenAI의 GPT 모델을 사용하여 첫 번째 PDF와 채팅해 보겠습니다. 이것을 보여주기 위해 이력서 PDF와 대화할 것입니다.
텍스트가 많은 매우 큰 PDF 파일에는 이 방법이 실패합니다. 이 병목 현상을 제거하는 방법은 섹션에 있어야 합니다. 금후.

1단계: OpenAI API 키 받기
- 방문 https://platform.openai.com/playground. 새 계정을 만들거나 기존 계정을 사용하여 로그인하십시오.
- 오른쪽 상단에 표시된 프로필 사진과 텍스트를 클릭합니다. 드롭다운 메뉴에서 "API 키 보기"를 클릭합니다.

- "새 비밀 키 만들기"를 클릭합니다.

- 기억할 키 이름을 지정하고 "비밀 키 만들기"를 클릭합니다.
- 이제 OpenAI API 키가 표시되며 한 번만 볼 수 있습니다. 이 키를 클립보드에 복사하여 저장하는 것을 잊지 마십시오.

2단계: PDF 읽기
PDF가 스캔되었는지 또는 디지털인지에 따라 다양한 접근 방식을 따릅니다.
둘 다 논의합시다.
사례 1 – PDF가 디지털인 경우
- 우리는 디지털 텍스트로 PDF를 읽기 위해 PyPDF2 라이브러리를 사용할 것입니다. pip를 사용하여 라이브러리를 설치합니다.
pip install PyPDF2
- 아래 코드를 실행하여 PDF 이력서의 내용을 읽습니다.
import PyPDF2 pdf_file_obj = open('resume-sample.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = '' for page_num in range(num_pages): page_obj = pdf_reader.getPage(page_num) detected_text += page_obj.extractText() + 'nn' pdf_file_obj.close() print(detected_text)

사례 2 – PDF가 디지털이 아닌 경우
- 먼저 광학 문자 인식(OCR)을 사용하여 PDF에서 데이터를 추출해야 합니다.
- 이를 위해 Google의 인기 있는 OCR 엔진인 Tesseract를 사용합니다. Tesseract OCR 엔진을 설치하는 것이 첫 번째 단계입니다.
Windows – 미리 컴파일된 바이너리를 찾아 쉽게 설치할 수 있습니다. 여기에서 지금 확인해 보세요.. "경로" 환경 변수를 편집하고 tesseract 경로를 추가하는 것을 잊지 마십시오.
Linux – 함께 설치 가능 몇 가지 명령.
Mac – Mac에 설치하는 가장 쉬운 방법은 homebrew를 사용하는 것입니다. 여기에서 단계를 따르세요.
- 설치 후 터미널 또는 cmd에 다음 명령을 입력하여 모든 것이 작동하는지 확인합니다.
$ tesseract --version
다음과 유사한 출력이 표시됩니다.
tesseract 5.1.0 leptonica-1.82.0 libgif 5.2.1 : libjpeg 9e : libpng 1.6.37 : libtiff 4.4.0 : zlib 1.2.11 : libwebp 1.2.2 : libopenjp2 2.5.0 Found NEON Found libarchive 3.6.1 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3 libzstd/1.5.2 Found libcurl/7.77.0 SecureTransport (LibreSSL/2.8.3) zlib/1.2.11 nghttp2/1.42.0- 이제 tesseract용 파이썬 래퍼를 설치합니다. pip를 사용하여 설치할 수 있습니다.
$ pip install pytesseract
- Tesseract는 이미지 형식을 입력으로 사용하므로 OCR을 사용하여 처리하기 전에 PDF 파일을 이미지로 변환해야 합니다. pdf2image 라이브러리는 이를 달성하는 데 도움이 될 것입니다. pip를 사용하여 설치할 수 있습니다.
$ pip install pdf2image
- 이제 시작하겠습니다. 이제 몇 줄의 파이썬 코드로 PDF에서 텍스트를 읽을 수 있습니다.
import pdf2image
from PIL import Image
import pytesseract image = pdf2image.convert_from_path('FILE_PATH')
for pagenumber, page in enumerate(image): detected_text = pytesseract.image_to_string(page) print(detected_text)
- 이력서에서 위의 Python 코드 스니펫을 실행하면 OCR 엔진에서 아래 출력을 얻습니다.

3단계: PDF와 첫 채팅
pip install --upgrade openai
- os 및 openai 라이브러리를 가져오고 OpenAI API 키를 정의합니다. 이것은 위의 단계에서 얻은 키입니다.
import os
import openai
openai.api_key = '{Your OpenAI API Key}'
- Python 라이브러리를 사용하는 OpenAI 모델에 대한 기본 요청은 다음과 같습니다.
response = openai.ChatCompletion.create( model=model_name, messages=[{"role": "system", "content": system_msg}, {"role": "user", "content": user_msg}, {"role": "assistant", "content": assistant_msg} ])
여기서 변수를 이해합시다 –
system_msg 메시지는 AI 비서의 동작을 설명합니다. 이는 GPT 모델에서 생성된 응답의 어조와 풍미에 영향을 주기 위해 요청의 일부로 보내는 백그라운드 메시지입니다.
user_msg 메시지는 AI 어시스턴트가 말하길 원하는 내용을 설명합니다. 이것은 본질적으로 우리가 모델에 보내는 프롬프트입니다.
assistant_msg 메시지는 대화의 이전 응답을 설명합니다. 이를 통해 대화 기록을 유지하면서 PDF로 확장된 채팅을 할 수 있습니다. 이 작업을 수행하는 방법은 아래에서 설명합니다.
model_name 사용할 GPT 모델을 지정합니다.
We Buy Orders 신청서를 클릭하세요. 부록 III 여기에서 GPT 모델을 선택하는 방법을 이해합니다.
- 이제 GPT 모델에 메시지를 보내는 방법을 이해했으므로 LLM에 그의 이력서를 기반으로 이 사람이 적합할 작업을 제안하도록 요청하겠습니다.
- 추출된 PDF 텍스트에 "위 이력서에 적합한 작업 목록 제공"이라는 쿼리를 추가하고 이를 user_msg로 보냅니다. detected_text 변수에는 이미 PDF에서 추출된 데이터가 포함되어 있습니다. 여기에 쿼리를 추가하기만 하면 됩니다.
query = 'give a list of jobs suitable for the above resume.' user_msg = detected_text + 'nn' + query - 또한 관련 system_msg를 추가하여 AI 도우미의 동작을 구체화합니다. 우리의 경우 유용한 시스템 메시지는 "당신은 유용한 진로 상담사입니다."일 수 있습니다.
system_msg = 'You are a helpful career advisor.'
- 첫 번째 응답을 받기 위해 요청을 보냅니다. 위의 모든 사항을 기반으로 최종적으로 아래에 표시된 코드를 실행합니다.
import pdf2image
from PIL import Image
import pytesseract
import os
import openai
openai.api_key = '{Your OpenAI API Key}' image = pdf2image.convert_from_path('FILE_PATH')
for pagenumber, page in enumerate(image): detected_text = pytesseract.image_to_string(page) print(detected_text) query = 'give a list of jobs suitable for the above resume.'
user_msg = detected_text + 'nn' + query
system_msg = 'You are a helpful career advisor.' response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "system", "content": system_msg}, {"role": "user", "content": user_msg}]) - 요청이 완료되면 응답 개체에 LLM의 응답이 포함됩니다. 다음과 같이 응답 객체의 'choices' 속성에 액세스하여 볼 수 있습니다.
print(response.choices[0].message.content)

짜잔, 방금 GPT를 사용하여 PDF와 첫 대화를 나눴습니다. 모델은 이력서를 기반으로 적합한 10가지 직무를 제안했습니다.
4단계: 대화 계속하기
- 종종 우리는 LLM과 한 쌍의 단일 프롬프트와 단일 응답 이상의 대화를 원할 것입니다. 이제 과거 대화 기록을 사용하여 대화를 계속하는 방법을 알아보겠습니다.
- 여기서 위에서 소개한 assistant_msg 변수가 작동합니다. 이전 응답의 값을 사용하여 어시스턴트 메시지를 작성합니다. assistant_msg 메시지는 기본적으로 모델에 컨텍스트를 제공하기 위해 과거 대화 기록을 제공하여 응답하는 모델을 지원합니다.
구현을 단순화하기 위해 지금부터 OpenAI GPT API를 호출하기 위한 다음 함수를 정의합니다.
def continue_chat(system_message, user_assistant_messages): system_msg = [{"role": "system", "content": system_message}] user_assistant_msgs = [{"role": "assistant", "content": user_assistant_messages[i]} if i % 2 else {"role": "user", "content": user_assistant_messages[i]} for i in range(len(user_assistant_messages))] allmsgs = system_msg + user_assistant_msgs response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=allmsgs) return response["choices"][0]["message"]["content"]
이 기능은 –
- system_message (문자열) : 이것은 system_msg 역할을 합니다.
- user_assistant_messages(목록) : 이 목록에는 교대로 사용자 프롬프트와 모델 응답이 포함되어 있습니다. 대화에서 발생하는 순서이기도 합니다.
함수는 내부적으로 API 호출을 만들어 대화 기록을 기반으로 새 응답을 생성하고 반환합니다.
이제 이 기능을 사용하여 이전 대화를 계속하고 첫 번째 응답에서 추천된 작업 중에서 가장 높은 급여를 받는 작업을 찾아보겠습니다.
- 이전 호출에서 사용한 것과 동일한 시스템 메시지(system_msg)를 사용합니다.
system_msg = 'You are a helpful career advisor.'
- user_assistant_messages 목록을 만듭니다.
user_msg1 = user_msg
model_response1 = response["choices"][0]["message"]["content"]
user_msg2 = 'based on the suggestions, choose the 3 jobs with highest average salary'
user_assistant_msgs = [user_msg1, model_response1, user_msg2]
원래 프롬프트를 첫 번째 사용자 메시지(user_msg1)로, 해당 프롬프트에 대한 응답을 첫 번째 모델 응답 메시지(model_response1)로, 새 프롬프트를 두 번째 사용자 메시지(user_msg2)로 사용했습니다.
마지막으로 대화에서 발생한 순서대로 user_assistant_messages 목록에 추가합니다.
- 마지막으로 우리는 continue_chat() 함수를 호출하여 대화에서 다음 응답을 얻습니다.
response = continue_chat(system_msg, user_assistant_msgs)

모델은 대화 내역을 알고 얻은 컨텍스트를 기반으로 답변하고 쿼리에 완벽하게 답변하는 훌륭한 응답을 생성할 수 있었습니다!
continue_chat() 함수를 사용하여 메시지와 응답이 대화에 나타난 순서대로 대화 기록을 user_assistant_messages 목록에 반복적으로 추가하여 모델과 추가로 대화할 수 있으므로 PDF 파일과 긴 대화가 가능합니다.
ChatGPT API 및 LangChain을 사용하여 대용량 PDF로 채팅
위에 표시된 코드 자습서는 매우 큰 PDF에 대해 실패합니다. 예를 들어 설명하겠습니다. 우리는 채팅을 시도합니다 BCG의 "2022 연례 지속 가능성 보고서", Boston Consulting Group(BCG)에서 업계에 미치는 일반적인 영향에 대해 게시한 대용량 PDF입니다. 우리는 아래에 표시된 코드를 실행합니다 –
import PyPDF2 pdf_file_obj = open('bcg-2022-annual-sustainability-report-apr-2023.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = '' for page_num in range(num_pages): page_obj = pdf_reader.getPage(page_num) detected_text += page_obj.extractText() + 'nn' pdf_file_obj.close()
print(len(detected_text))

PDF가 매우 크고 detected_text 문자열 변수의 길이가 대략 250k임을 알 수 있습니다.
이제 PDF로 채팅을 해보자 –
system_msg = '' query = '''
summarize this PDF in 500 words. ''' user_msg = detected_text + 'nn' + query response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "system", "content": system_msg}, {"role": "user", "content": user_msg}])
프롬프트 길이 임계값에 도달했다는 다음과 같은 오류 메시지가 나타납니다.
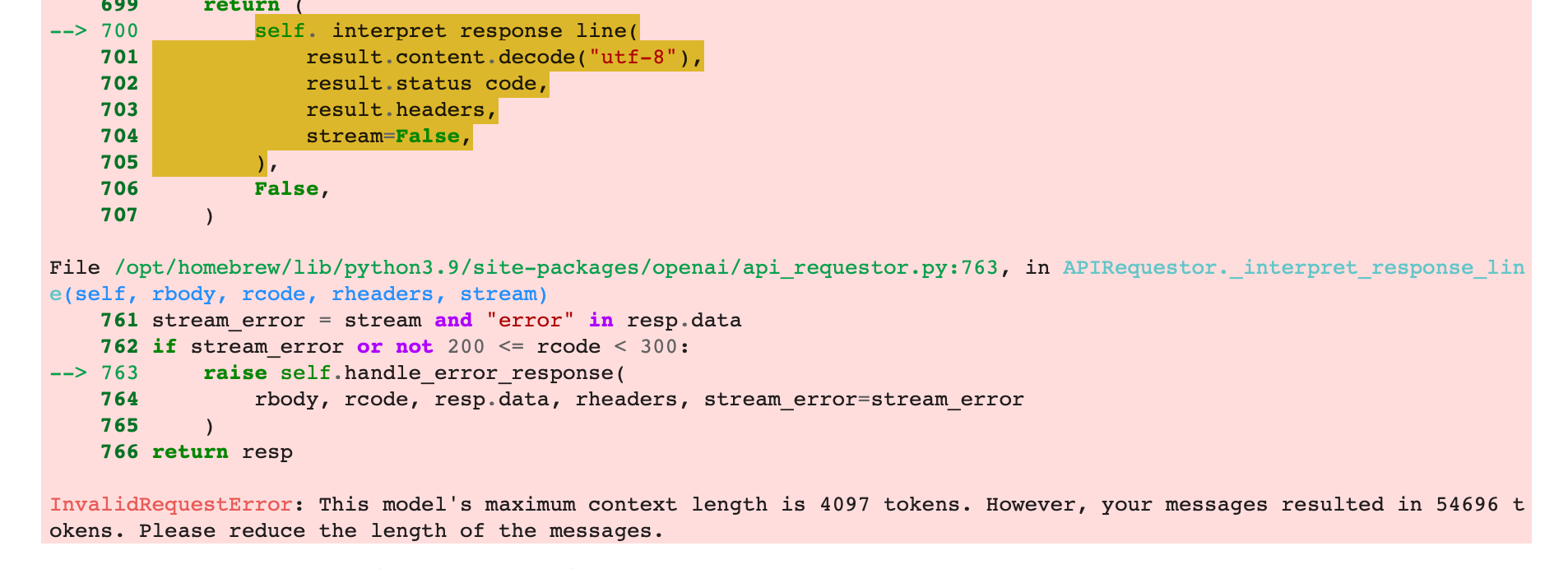
이는 텍스트가 많은 큰 PDF의 경우 OpenAI로 보내는 요청 페이로드가 너무 커지고 OpenAI가 프롬프트 길이 임계값에 도달했다는 오류를 반환하기 때문에 발생합니다.
이제 이 병목 현상을 제거하는 방법을 알아보겠습니다.
- 랭체인을 입력하세요. LangChain은 대규모 언어 모델(LLM)을 Python 프로그래밍, PDF, CSV 파일 또는 데이터베이스와 같은 실용적인 응용 프로그램과 연결하는 다리 역할을 하는 혁신적인 기술입니다.
- pip를 사용하여 필요한 모듈을 설치합니다.
pip install langchain openai pypdf faiss-cpu
- 필요한 종속성을 가져옵니다.
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os
- LangChain용 PyPDF 로더를 사용하여 PDF를 로드합니다.
loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
- 청킹을 수행하고 LangChain 텍스트 분할기를 사용하여 텍스트를 분할합니다.
사용 사례에 따라 다음에서 올바른 텍스트 분할기를 선택할 수 있습니다. 이 문서.
가능한 한 불필요한 분할을 피하기 위해 청크 길이를 조정하여 단락의 무결성을 유지하도록 설계되었기 때문에 RecursiveCharacterTextSplitter를 선택했습니다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text])
위의 코드는 텍스트를 "청크"로 분할합니다. 'texts' 변수의 길이는 텍스트가 분할된 페이지/청크의 수를 제공합니다.
- 청크를 사용하여 벡터 데이터베이스를 만듭니다. 나중에 사용할 수 있도록 데이터베이스에 저장합니다.
사용 사례에 따라 사용할 올바른 벡터 데이터베이스를 선택할 수 있습니다. 이 문서.
우리는 FAISS 벡터 저장소를 선택합니다. 효율적이고 사용자 친화적입니다. 또한 벡터를 파일 시스템/하드 드라이브에 직접 저장합니다.
directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory)
데이터베이스 색인은 'index_store'라는 파일 이름으로 저장됩니다.
- 이제 데이터베이스를 로드합니다. 데이터베이스를 사용하여 검색기를 구성한 다음 채팅 개체를 만듭니다. 이 채팅 개체(qa_interface)는 PDF와 채팅하는 데 사용됩니다.
vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
qa_interface = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True)
- 이제 PDF로 채팅을 시작할 수 있습니다. PDF에 개발도상국에서 발생하는 질병을 해결하기 위해 취한 조치를 나열하도록 요청합시다..
response = qa_interface("List measures taken to address diseases occuring in developing industries")
위의 예를 기반으로 실행한 전체 코드는 다음과 같습니다.
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os os.environ["OPENAI_API_KEY"] = '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'
directory = 'index_store' loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text]) directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory) vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
qa_interface = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True) response = qa_interface("List measures taken to address diseases occuring in developing industries") print(response['result'])
- 결과는 우리의 질문을 해결하고 탁월한 응답을 제공합니다!

- 지금까지 우리는 벡터 저장소에서 문서 조각을 가져와 이에 대해 한 가지 질문을 하기 위한 LangChain 유형인 RetrievalQA 체인을 사용했습니다. 그러나 때때로 우리는 이미 이야기한 주제를 참조하는 것을 포함하여 문서에 대해 완전한 대화를 해야 합니다.
- 고맙게도 LangChain은 우리를 다루었습니다. 이를 가능하게 하려면 시스템에 메모리 또는 대화 기록이 필요합니다. RetrievalQA 체인 대신 ConversationalRetrievalChain을 사용합니다.
conv_interface = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0), retriever=retriever)
- 보고서에서 모로코가 언급된 맥락을 밝히도록 PDF에 요청합시다.
chat_history = []
query = "in what context is Morocco mentioned in the report?"
result = conv_interface({"question": query, "chat_history": chat_history})
print(result["answer"])
'chat_history' 매개변수는 과거 대화 내역이 포함된 목록입니다. 첫 번째 메시지의 경우 이 목록은 비어 있습니다.
'question' 매개변수는 메시지를 보내는 데 사용됩니다.
대용량 PDF와의 대화형 채팅을 위한 전체 코드는 다음과 같습니다.
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os os.environ["OPENAI_API_KEY"] = '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'
directory = 'index_store' loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text]) directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory) vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
conv_interface = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0), retriever=retriever) chat_history = []
query = "in what context is Morocco mentioned in the report?"
result = conv_interface({"question": query, "chat_history": chat_history})
print(result["answer"])
- 결과는 보고서에서 모로코의 언급을 요약합니다.

- 이제 chat_history 변수를 업데이트하여 대화를 계속하고 PDF에 이에 대한 통계를 제공하도록 요청합니다.
대화에 나타나는 순서대로 메시지를 추가합니다. 먼저 초기 메시지를 추가한 다음 첫 번째 응답을 추가합니다.
chat_history.append((query, result["answer"]))
이제 업데이트된 chat_history와 함께 새 질문을 추가하여 대화를 계속합니다.
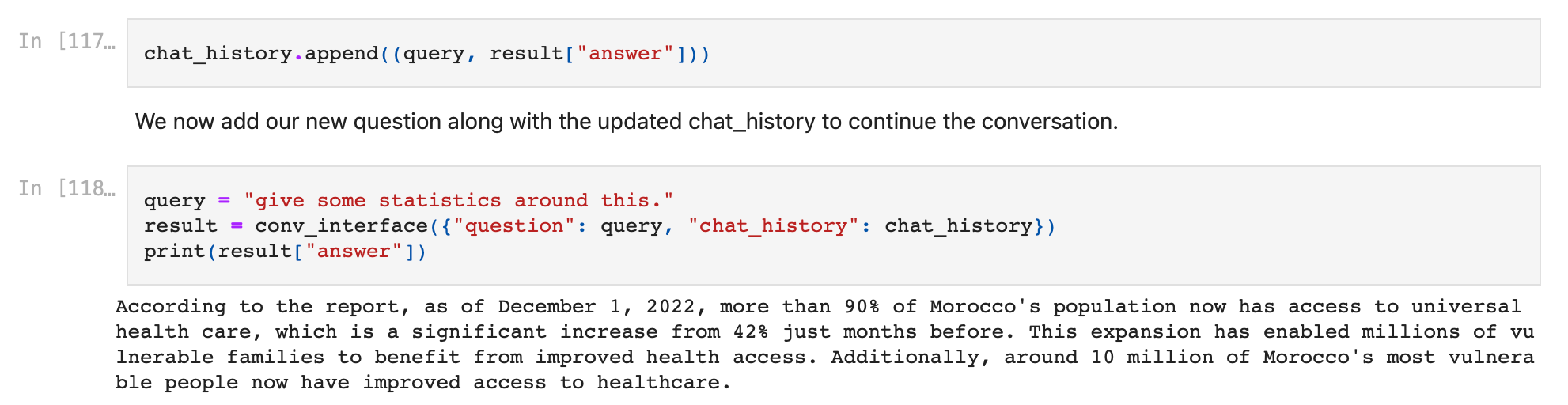
query = "give some statistics around this."
result = conv_interface({"question": query, "chat_history": chat_history})
print(result["answer"])
- 결과는 대화 기록을 알고 얻은 컨텍스트를 사용하고 또 다른 훌륭한 응답을 제공합니다!
chat_history 변수를 계속 업데이트하고 이 방법을 사용하여 대화를 계속할 수 있습니다.
일상 생활에서 PDF와 관련된 작업을 자동화하고 싶습니까? 더 이상 보지 마세요! 노력하다 Nanonets의 자동화된 문서 워크플로 현재 LLM 및 Generative AI로 구동됩니다.
ChatGPT를 사용하여 PDF 자동화 구축
PDF와 관련된 일상적인 개인 및 전문 작업을 자동화하기 위해 ChatGPT API를 사용하는 사람들의 수가 매일 엄청난 속도로 증가하고 있습니다.
이러한 자동화는 우리가 일상적으로 수행하는 반복적인 PDF 작업을 대체하고 심지어 자동화된 문서 워크플로를 생성하여 모든 사람이 시간을 절약하고 정말 중요한 일에 집중할 수 있도록 합니다.
이러한 자동화의 예를 살펴보고 자동화를 만들고 배포하는 방법을 알아보십시오.
GPT-3.5는 문서에서 데이터를 추출하는 데 탁월합니다. 이를 이용하여 아래 인보이스에서 데이터를 추출해 보도록 하겠습니다.
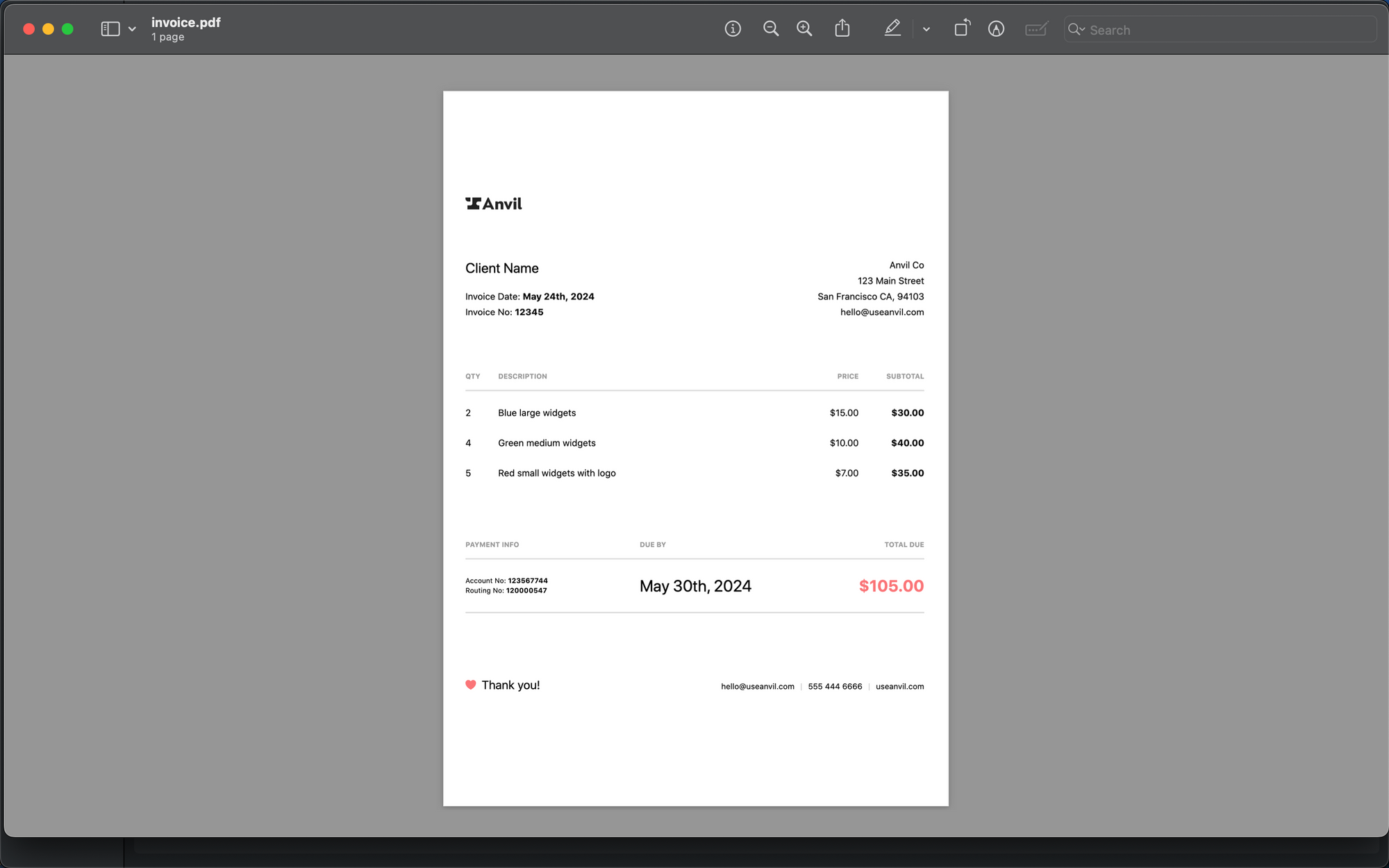
invoice_date, invoice_number, seller_name, seller_address, total_amount 및 송장에 있는 각 라인 항목과 같은 JSON 형식의 필드를 추출할 것입니다.
인보이스 PDF와 함께 추가되고 OpenAI의 API로 전송될 때 Python에서 추가로 읽고 처리할 수 있는 구조화된 json을 반환하는 쿼리를 생성해 보겠습니다.
쿼리 –
extract data from above invoice and return only the json containing the following - invoice_date, invoice_number, seller_name, seller_address, total_amount, and each line item present in the invoice. json=
전체 코드는 다음과 같습니다.
import os
import openai
openai.api_key = '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' import pdf2image
from PIL import Image
import pytesseract image = pdf2image.convert_from_path('invoice.pdf')
for pagenumber, page in enumerate(image): detected_text = pytesseract.image_to_string(page) system_msg = 'You are an invoice processing solution.' query = '''
extract data from above invoice and return only the json containing the following -
invoice_date, invoice_number, seller_name, seller_address, total_amount, and each line item present in the invoice.
json= ''' user_msg = detected_text + 'nn' + query response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "system", "content": system_msg}, {"role": "user", "content": user_msg}]) print(response.choices[0].message.content)
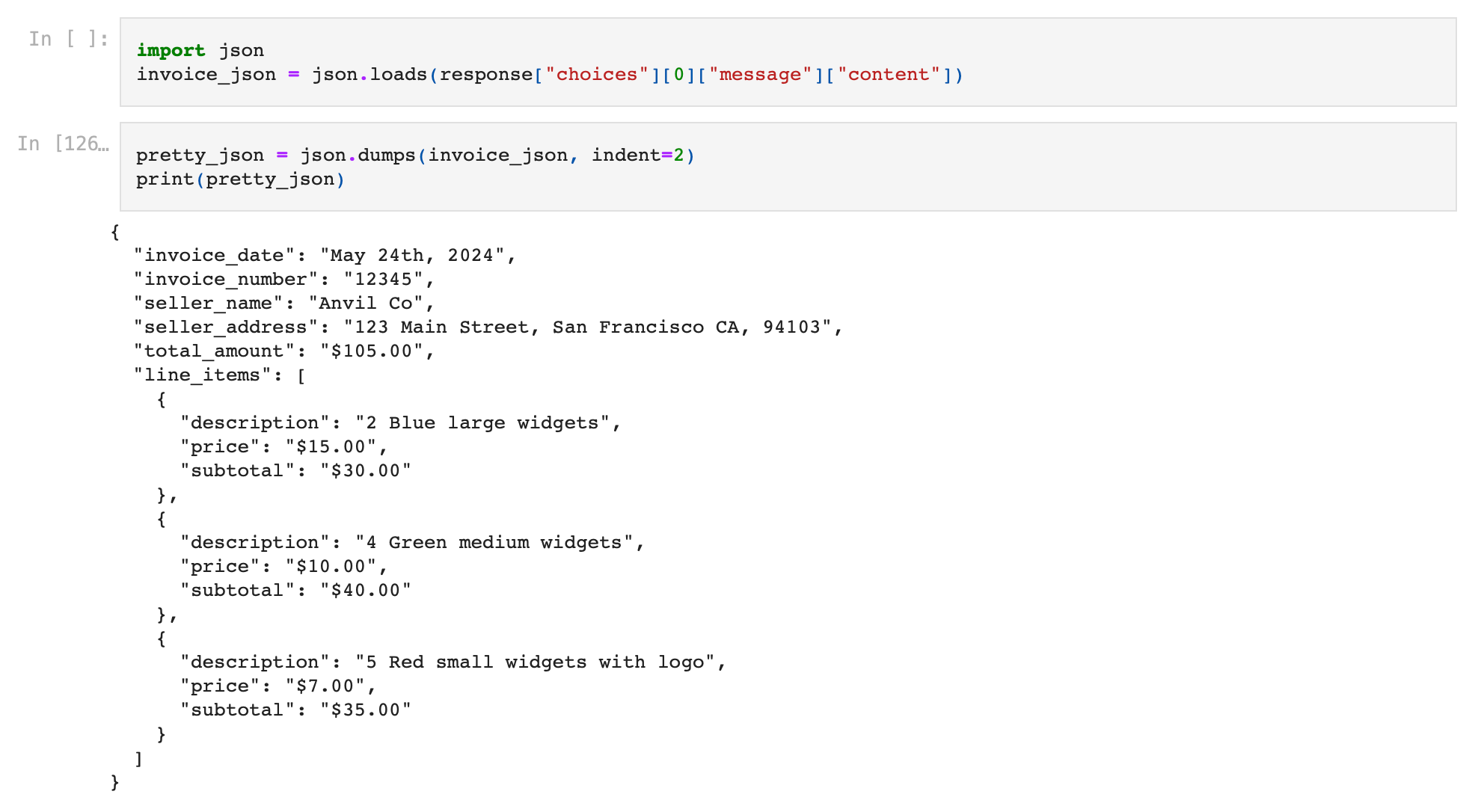
실행 시 제공된 응답은 문서에서 필요한 텍스트를 추출한 완벽하게 구조화된 json입니다!

여기서 json은 기본적으로 json 덤프입니다. 올바른 json 형식의 텍스트 문자열이지만 아직 json 변수는 아닙니다.
이 응답을 json 변수로 변환해 보겠습니다. 코드 한 줄만 추가하면 됩니다.
invoice_json = json.loads(response["choices"][0]["message"]["content"])
송장에서 데이터를 추출했으므로 이제 실제로 송장 처리 워크플로우를 완전히 자동화할 수 있습니다. 수신 송장을 자동으로 수집하고, ChatGPT를 사용하여 송장에서 데이터를 추출하고, 추출된 데이터를 선택한 소프트웨어/데이터베이스/ERP로 내보낼 수 있습니다. 이러한 자동화를 배포하는 방법에 대해서는 섹션에 있어야 합니다. 금후.
자동화 2 – 문서 분류
많은 경우에, 우리는 다양한 목적을 위한 PDF 문서의 폭격을 받고 있으며 그들이 제공하는 목적을 알기 위해 각각의 모든 문서를 열어야 합니다.
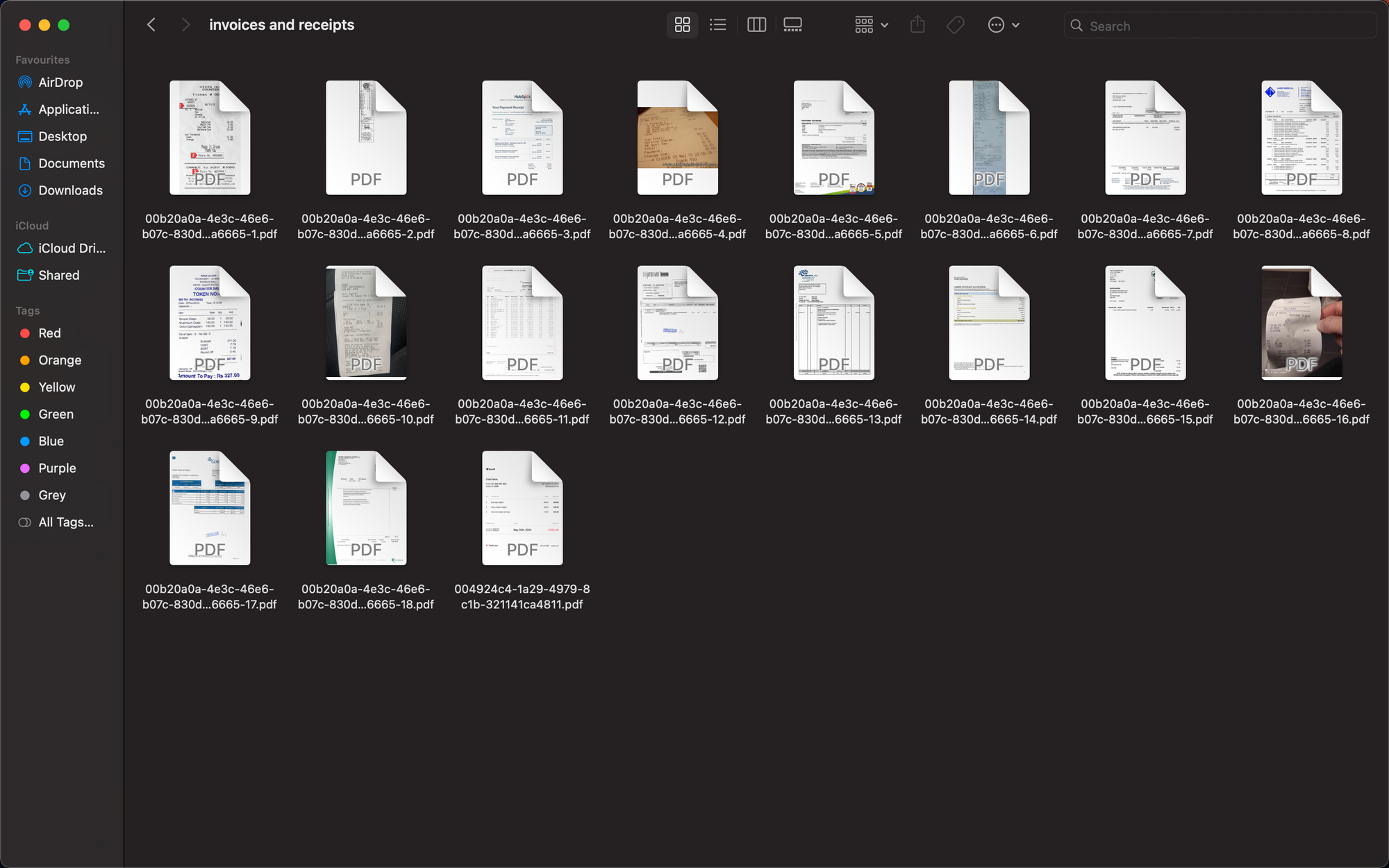
예를 들어 보겠습니다. 송장이나 영수증 파일이 많이 있다고 가정해 보겠습니다. 이러한 문서를 유형에 따라 분류하고 정렬하려고 합니다.
GPT API를 사용하면 쉽게 할 수 있습니다.
이를 위해 간단한 파이썬 함수를 만듭니다.
import shutil
import os
import openai
openai.api_key = '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' def list_files_only(directory_path): if os.path.isdir(directory_path): file_list = [f for f in os.listdir(directory_path) if os.path.isfile(os.path.join(directory_path, f))] file_list = [file for file in file_list if ".pdf" in file] return file_list else: return f"{directory_path} is not a directory" def classify(file_name): image = pdf2image.convert_from_path(file_name) for pagenumber, page in enumerate(image): detected_text = pytesseract.image_to_string(page) system_msg = 'You are an accounts payable expert.' query = ''' Classify this document and return one of these two document types as response - [Invoices, Receipts] Return only the document type in the response. Document Type = ''' user_msg = detected_text + 'nn' + query response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "system", "content": system_msg}, {"role": "user", "content": user_msg}]) return response["choices"][0]["message"]["content"] def move_file(current_path, new_folder): if os.path.isfile(current_path) and os.path.isdir(new_folder): file_name = os.path.basename(current_path) new_path = os.path.join(new_folder, file_name) shutil.move(current_path, new_path) print(f'File moved to {new_path}')
- list_files_only() : 이 함수는 인보이스 및 영수증이 포함된 폴더에서 모든 파일을 가져옵니다. 모든 PDF 파일 목록을 반환합니다.
- classify() : 이 함수는 PDF 파일에서 텍스트를 추출하고 GPT API 쿼리를 적용하여 송장과 영수증 간에 문서를 분류하고 문서 유형을 반환합니다.
- move_file() : 이 함수는 파일을 새 폴더로 이동합니다.
이제 'Invoices' 및 'Receipts'라는 두 개의 폴더를 만듭니다.

이제 코드를 실행하여 이러한 파일을 분류하고 문서 유형에 따라 별도의 폴더로 정렬하겠습니다.
list_of_files = list_files_only('invoices and receipts/')
for doc in list_of_files: current_path = 'invoices and receipts/' + doc doc_type = classify(current_path) new_path = 'invoices and receipts/' + doc_type move_file(current_path, new_path)
실행 시 코드는 이러한 파일을 완벽하게 정렬합니다!

자동화 3 - 레시피 추천기
좋아하는 요리책을 GPT API에 제공하고 입력을 기반으로 레시피 추천을 제공하도록 요청할 수도 있습니다. 예를 살펴보겠습니다. 우리는 브레이크의 식사 n 더 조리법 요리책, 그리고 LangChain을 사용하여 대화하십시오. 집에 있는 재료를 기준으로 추천해 달라고 요청해 보겠습니다.
코드는 다음과 같습니다.
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os os.environ["OPENAI_API_KEY"] = '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'
directory = 'index_store' loader = PyPDFLoader("meals-more-recipes.pdf")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text]) directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory) vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
qa_interface = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True) response = qa_interface("""
I have a lot of broccoli and tomatoes at home. Recommend recipe for some meal I can make at home using these. """) print(response['result'])
실행 시 PDF는 언급된 재료를 사용하여 준비할 수 있는 식사 레시피를 권장합니다!

자동화 4 – 자동화된 질문지 작성기
GPT API를 사용하여 교과서를 제공하고 완전한 질문지 및 시험 작성을 자동화할 수 있습니다. LLM은 마킹 체계도 생성할 수 있습니다!
우리는 교과서를 사용합니다 David B. Surowski의 고급 고등학교 수학 LLM에게 교과서의 특정 장에 대한 채점 체계가 있는 질문지를 작성하도록 요청하십시오.
우리는 아래 코드를 실행합니다 –
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os os.environ["OPENAI_API_KEY"] = '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'
directory = 'index_store' loader = PyPDFLoader("further.pdf")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text]) directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory) vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
qa_interface = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True) response = qa_interface("""
list 5 questions of 20 marks total of varying difficuly and weightage based on the topic "Euclidian Geometry" """) print(response['result'])
LLM은 PDF 교과서를 읽고 우리를 위해 질문지를 만듭니다!

일상 생활에서 PDF와 관련된 작업을 자동화하고 싶습니까? 더 이상 보지 마세요! 노력하다 Nanonets의 자동화된 문서 워크플로 현재 LLM 및 Generative AI로 구동됩니다.
이러한 자동화를 배포하는 방법은 무엇입니까?
이를 구축하는 방법과 위치를 선택하는 것은 자동화 규모, 시간 및 예산 제약, 필요한 가져오기 및 내보내기 통합 등에 따라 달라집니다.
시나리오 I – 저규모/단순 작업
Zapier 및 Make와 같은 코드 없는 워크플로 자동화 소프트웨어를 사용할 수 있습니다.
이러한 플랫폼을 사용하면 코드를 전혀 작성할 필요 없이 코드 없는 플랫폼에서 직접 트리거 및 작업을 기반으로 자동화된 워크플로를 생성하고 애플리케이션 간에 데이터를 교환할 수 있습니다.
자동화된 문서 워크플로를 생성하기 위해 Zapier/Make 및 OpenAI GPT 통합을 사용하려면 시청을 강력히 권장합니다. 이러한 노코드 플랫폼에서 이러한 자동화를 설정하는 방법에 대한 이 Youtube 자습서.
예를 들어 다음과 같이 실행할 워크플로를 만들 수 있습니다.
- Zapier의 Gmail 통합을 사용하여 PDF 인보이스가 첨부된 새 이메일이 Gmail에 도착할 때마다 워크플로를 실행하세요.
- Zapier의 Nanonets OCR 통합을 사용하여 PDF 송장에서 텍스트를 추출하십시오.
- Zapier의 OpenAI GPT 통합을 사용하여 추출된 데이터와 함께 요청을 보내고 인보이스에서 구조화된 데이터를 반환하도록 구성합니다.
- Zapier의 Google 스프레드시트 통합을 사용하여 Google 시트에서 GPT 모델의 응답으로 얻은 응답 데이터를 채웁니다.
- Zapier의 Quickbooks 회계 소프트웨어 통합을 사용하여 Quickbooks에서 동일한 GPT 응답 데이터를 채웁니다.
여기에서 Gmail, Google 스프레드시트 및 Quickbooks 통합은 이미 Zapier에 의해 사전 생성되었습니다. OpenAI GPT API 호출도 사전 구축되어 바로 사용할 수 있습니다.
장점 –
- 외부 앱 통합을 만드는 데 필요한 시간과 리소스를 절약합니다.
- Zapier/Make와 같은 워크플로 자동화 소프트웨어는 요즘 워크플로에서 고급 유연성과 작업을 점점 더 많이 제공하고 있습니다.
단점 -
- 이러한 자동화 구현은 적절하게 확장할 수 없습니다.
- 더 복잡한 작업을 수행하는 데 필요한 수준의 사용자 정의를 제공하지 않습니다.
시나리오 II – 규모가 작고 복잡한 작업
PDF와 상호 작용하는 GPT 작업을 처리하기 위해 API 서비스를 생성하여 시작할 수 있습니다. API는 PDF 페이로드가 포함된 요청을 수락하고, GPT 작업을 실행하고, API 서비스의 응답으로 GPT 응답을 반환(직접 또는 사후 처리 후)할 수 있어야 합니다. 기본적으로 사용 사례에 따라 API 서비스에서 GPT 기능 및 기타 매개변수(모델, 프롬프트, system_msg 등)를 정의합니다. 여기에서 나만의 API 서비스를 만드는 방법을 알아보세요.
팁: 더 높은 수준의 사용자 지정을 원하지만 볼륨 측면에서 자동화를 확장하지 않는 경우 자체 API 서비스를 구축하는 대신 AWS Lambda, Google Cloud Functions 등과 같은 클라우드 서버리스 기능을 사용할 수 있습니다.
다른 애플리케이션으로 데이터 가져오기 및 내보내기를 위해 Zapier 및 Make와 같은 코드 없는 워크플로 자동화 소프트웨어를 계속 사용할 수 있습니다. 이것은 Zapier 또는 Make에서 사용자 지정 API 호출을 사용하여 가능합니다. 여기에서 Zapier에서 사용자 지정 API 호출을 사용하는 방법을 알아보세요. 이러한 플랫폼은 응용 프로그램 간 데이터 흐름 기능을 사용자 지정 API 호출을 API 서비스로 보내는 기능과 결합합니다.
동일한 예제 워크플로를 구현하려면 –
- Zapier의 Gmail 통합을 사용하여 PDF 인보이스가 첨부된 새 이메일이 Gmail에 도착할 때마다 워크플로를 실행하세요.
- Zapier의 Nanonets OCR 통합을 사용하여 PDF 송장에서 텍스트를 추출하십시오.
- Zapier의 Custom Webhooks 또는 Zapier의 Custom Post Requests 통합을 사용하여 청구서에서 추출된 데이터와 함께 API 서비스에 요청을 보냅니다.
- 귀하의 API 서비스가 요청을 수신하고 인보이스의 구조화된 데이터를 반환합니다. 여기에서 나만의 API 서비스를 만드는 방법을 알아보세요.
- Zapier의 Google 스프레드시트 통합을 사용하여 Google 시트에서 GPT 모델의 응답으로 얻은 응답 데이터를 채웁니다.
- Zapier의 Quickbooks 회계 소프트웨어 통합을 사용하여 Quickbooks에서 동일한 GPT 응답 데이터를 채웁니다.
여기서 우리의 임무는 PDF와 상호 작용하는 GPT 작업을 처리하는 API 서비스를 만드는 것뿐입니다. 문서와 데이터를 가져오고 내보내기 위해 다른 앱과 번거로운 통합을 만드는 데 소요되는 시간을 절약할 수 있습니다.
장점 –
- 바로 사용할 수 있는 외부 통합을 제공하여 시간을 절약합니다.
- 자체 API 서비스이므로 복잡한 작업을 유연하게 수행할 수 있습니다.
단점 -
- 이러한 자동화 구현은 적절하게 확장할 수 없습니다.
- 외부 앱과의 고급 상호 작용이 필요한 작업에는 실패합니다.
시나리오 III – 대규모의 복잡한 작업
이러한 종류의 자동화를 구현하는 가장 좋은 방법은 자동화를 종단 간 처리하는 자체 API 서비스를 만드는 것입니다.
동일한 예제 워크플로를 구현하려면 –
- Gmail API를 사용하여 매시간 인보이스 PDF가 포함된 새 이메일을 가져오는 서비스를 만드세요.
- Nanonets API를 사용하여 PDF 송장에서 텍스트를 추출합니다.
- OpenAI GPT API를 사용하여 추출된 텍스트를 입력하면 인보이스에서 구조화된 데이터를 출력합니다.
- Google Sheets API를 사용하여 Google Sheet에서 GPT 모델의 응답으로 얻은 구조화된 데이터를 채웁니다.
- Quickbooks 회계 소프트웨어 API를 사용하여 Quickbooks에서 동일한 GPT 응답 데이터를 채웁니다.
기본적으로 자신의 API 서비스에서 위의 기능을 만들고 배포합니다. 여기에서 나만의 API 서비스를 만드는 방법을 알아보세요.
장점 –
- 높은 수준의 커스터마이징이 가능합니다.
- 복잡한 워크플로의 실행이 가능해집니다.
- 상업용 앱을 만들어 판매할 수 있습니다.
단점 -
- 이러한 구현을 구축하려면 시간과 리소스가 필요합니다.
일상 생활에서 PDF와 관련된 작업을 자동화하고 싶습니까? 더 이상 보지 마세요! 노력하다 Nanonets의 자동화된 문서 워크플로 현재 LLM 및 Generative AI로 구동됩니다.
나만의 PDF 챗봇 구축
이제 지금까지 얻은 지식을 사용하여 고유한 PDF Chatbot을 구축하고 사용자 인터페이스(UI)와 함께 배포해 보겠습니다. 이를 달성하기 위해 Databutton을 사용할 것입니다.
시작하겠습니다 –
- We Buy Orders 신청서를 클릭하세요. https://databutton.com/. 귀하의 계정을 사용하여 가입하거나 로그인하십시오.
- 로그인한 후 "PDF와 채팅" 앱 템플릿을 클릭합니다.
- 앱 이름을 지정하고 "앱 만들기"를 클릭합니다.
- Databutton이 앱 설정을 시작합니다. 앱 구성을 위한 온라인 IDE 환경을 제공합니다.

Databutton "Chat with your PDFs" 템플릿은 GPT-3.5를 사용하여 PDF 파일과 채팅할 수 있는 사용자 인터페이스(UI)가 있는 샘플 앱을 만듭니다. 이전 섹션에서 Langchain을 사용하여 구현한 프레임워크와 유사하게 Databutton은 벡터 데이터베이스를 생성하고 사용자 메시지에 대한 응답을 제공하기 위해 쿼리하는 데 자체 프레임워크를 사용합니다. 긴 대화의 맥락을 유지하는 데 사용되며 ChatGPT 웹사이트와 유사한 채팅 메시지로 앱에 표시되는 채팅 기록을 유지합니다.
- 요구 사항에 따라 앱과 사용자 인터페이스(UI)를 구성합니다.
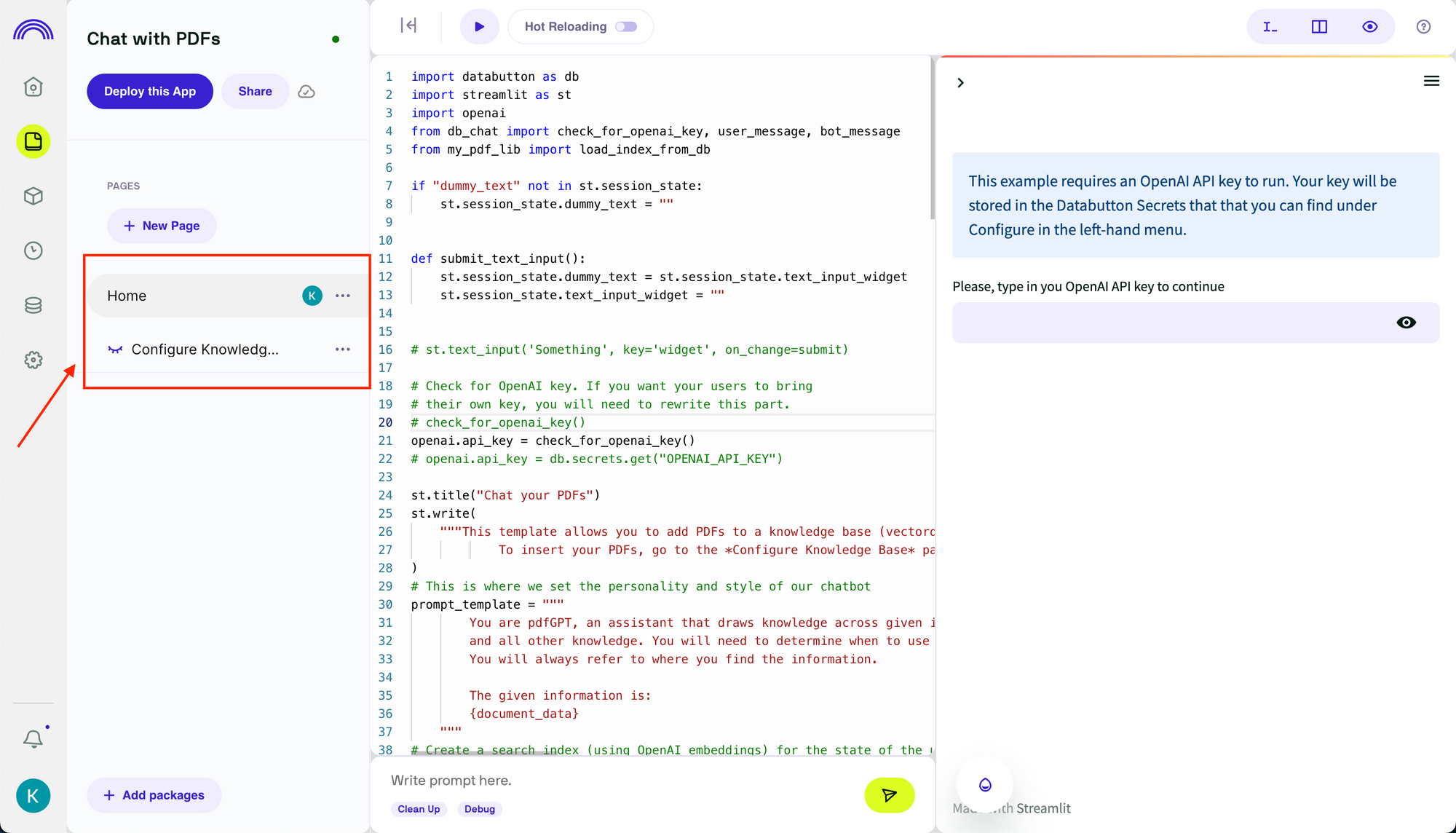
템플릿에는 "홈"과 "지식 기반 구성"이라는 두 개의 화면이 있습니다.
"홈"은 채팅 인터페이스를 구현하고 GPT API 호출을 구성합니다. 여기에서 코드를 수정하여 요구 사항에 따라 작동하는 앱을 만들 수 있습니다. 예를 들어 여기에서 GPT API 호출을 수정하여 항상 관련 통계로 응답하도록 프롬프트 템플릿을 변경할 수 있습니다.
"지식 기반 구성"은 GPT 호출이 사용자 메시지에 의해 트리거될 때 PDF 파일을 챗봇에 추가하고 검색을 위해 벡터 데이터베이스를 저장하는 기능을 구현합니다. 예를 들어 위 섹션에서 langchain 코드를 복사하여 "지식 기반 구성" 코드 파일을 변경하여 langchain 프레임워크로 전환할 수 있습니다.
Databutton을 사용하여 사용자 지정 PDF 챗봇을 구축하고 배포하는 방법에 대한 자세한 자습서는 여기에서 자세한 블로그를 참조할 수 있습니다. 대화 메모리로 개인화된 PDF 채팅 봇을 구축하는 방법.
- 완료되면 화면 왼쪽 상단에 있는 "앱 배포" 버튼을 클릭합니다.
- 이제 제공된 링크에서 앱이 활성화됩니다.



이 방법은 PDF 챗봇을 빠르게 구축하고 배포하는 데 적합합니다. 이러한 챗봇을 작업 공간 내에서 개인용 및 내부 팀용으로 직접 사용할 수 있습니다. 클라이언트 대면 PDF 챗봇을 구축하려면 한 단계 더 나아가 React, next.js 등과 같은 프런트엔드 프레임워크를 사용하여 자체 앱을 구축하는 것도 고려할 수 있습니다.
PDF로 채팅하기: 개인과 기업을 위한 게임 체인저
디지털 시대에 더 깊이 빠져들면서 데이터와 상호 작용하는 보다 직관적이고 효율적인 방법을 탐색하는 것이 필수적이 되었습니다. LLM(Language Learning Models)을 사용하여 PDF와 채팅할 수 있는 기능은 정보에 액세스하고 활용하는 방법에 있어 혁신적인 단계입니다. 이 섹션에서는 이 기술의 혁신적인 영향과 그것이 어떻게 운영을 간소화하고 생산성을 향상시키며 우리의 삶을 더 쉽게 만드는지 한 번에 하나의 PDF로 살펴봅니다.
기업용
빠르게 변화하는 비즈니스 세계에서는 매초가 중요합니다. 종종 전문가와 비즈니스 프로세스는 수많은 문서에서 특정 데이터에 즉시 액세스해야 합니다. 수동 읽기는 시간과 자원의 제약으로 인해 점점 더 불편해지고 있으며 LLM을 통해 우리가 할 수 있는 것(PDF로 채팅)이 혁신적으로 되는 곳입니다.
바쁜 회계 부서의 시나리오를 상상해 보십시오. 이 회사는 매일 다양한 공급업체로부터 수백 개의 송장을 PDF 형식으로 받습니다. 이러한 각 송장은 처리되고 해당 구매 주문서 및 영수증과 대조되어야 합니다. PDF와 채팅하면 이 프로세스를 간소화할 수 있습니다. LLM에게 송장, 영수증 및 구매 주문서에서 공급업체 세부 정보, 날짜, 가격, 금액, 수량 등 관련 세부 정보를 추출하도록 요청하기만 하면 됩니다. LLM은 PDF를 검토하고 필요한 정보를 찾은 다음 송장을 영수증과 일치시키고 즉각적이고 정확한 불일치 감지를 통해 몇 초 만에 구매 주문을 처리합니다.
다른 비즈니스 워크플로도 이점을 얻을 수 있습니다.
- 고객 성공 사례: 광범위한 사용 설명서 및 사용자 설명서에서 특정 제품 또는 서비스 세부 정보를 신속하게 가져와 신속한 고객 지원을 제공합니다.
- 계약 검토: 법무 부서는 PDF 형식으로 저장된 계약서와 대화할 수 있는 기능을 활용할 수 있습니다. 특정 조항 또는 용어에 대한 쿼리는 즉각적인 응답을 반환할 수 있으므로 긴 계약 검토 프로세스를 더 빠르고 관리하기 쉽게 만듭니다.
- 규제 준수: LLM은 규제 서류를 쉽게 검토하고 중요한 사항을 강조하며 비즈니스가 항상 규정을 준수하는지 확인할 수 있습니다.
이러한 기존의 비즈니스 워크플로를 넘어서도 PDF와의 채팅은 비즈니스 운영의 다른 측면을 혁신할 수 있는 잠재력을 가지고 있습니다.
- 영업 기술 자료: 영업 사원은 회사의 PDF 리소스를 실시간으로 "읽는" LLM을 통해 필요한 제품 세부 정보, 비교 또는 과거 판매 데이터를 신속하게 가져와 효과적으로 영업 통화를 수행할 수 있습니다.
- 시장 조사: 분석가는 PDF 보고서와 채팅하여 특정 시장 동향을 빠르게 추출하여 전체 섹션을 탐색하는 시간을 절약할 수 있습니다.
개인을 위해
개인 및 개인의 직업 생활 영역에서 PDF로 채팅하는 기능은 그다지 혁신적이지 않습니다. 우리는 디지털 라이프를 탐색하면서 모든 모양과 크기의 PDF를 지속적으로 접하게 됩니다. 은행 명세서, 전자책, 연구 논문 또는 사용자 설명서가 될 수 있습니다. LLM은 우리가 이 디지털 혼란을 없애고 우리가 찾는 정보를 바로 얻을 수 있도록 도와줄 수 있습니다.
LLM이 개인에게 권한을 부여하는 방법을 살펴보겠습니다.
- 개인 재정: 지출 패턴을 이해하거나 예산을 준비하기 위해 몇 달 간의 은행 명세서와 신용 카드 청구서를 샅샅이 뒤져야 한다고 상상해 보십시오. LLM을 사용하면 "XNUMX월의 총 비용은 얼마였습니까?", "지난 분기에 식료품에 얼마를 썼습니까?" 또는 "지난 달 가장 큰 거래는 무엇이었습니까?"와 같은 질문을 할 수 있습니다. LLM은 PDF 문을 빠르게 구문 분석하고 필요한 답변을 제공하여 시간과 노력을 절약할 수 있습니다.
- 교육 리소스: 학생과 자가 학습자는 이 기술을 통해 막대한 이점을 얻을 수 있습니다. 학생이 수많은 PDF 교과서와 보충 읽기 자료를 가지고 있는 것은 드문 일이 아닙니다. LLM은 특정 정보를 추출하고 장을 요약하거나 수정을 위한 질문을 생성하여 학습을 보다 효율적이고 흥미롭게 만들 수 있습니다.
- 연구 논문: 연구자와 학자에게 관련 정보를 찾기 위해 쏟아지는 연구 논문을 샅샅이 뒤지는 것은 힘든 작업이 될 수 있습니다. LLM은 여기에서 강력한 도구가 될 수 있습니다. PDF로 저장된 연구 논문 모음에서 특정 방법론, 결과 또는 토론을 찾도록 LLM에 요청할 수 있습니다.
- 전문성 개발: 개인은 직업 생활에서 LLM을 활용할 수도 있습니다. 예를 들어 소프트웨어 개발자는 PDF로 저장된 긴 API 문서에서 특정 기능을 이해해야 할 수 있습니다. 문서를 수동으로 검색하는 대신 LLM에 직접 요청할 수 있으므로 소중한 시간과 노력을 절약할 수 있습니다.
- 사용자 설명서: 새로운 소프트웨어든 주방 기기든 복잡한 사용자 설명서를 이해하는 것은 지루한 과정이 될 수 있습니다. LLM을 사용하면 직접 질문하고 설명서에서 관련 단계 또는 예방 조치를 얻을 수 있으므로 새로운 도구 및 어플라이언스를 배우는 과정이 훨씬 원활해집니다.
- 의료 문서: 의료 문서를 탐색하는 것은 특히 건강 위기 상황에서 스트레스가 많은 과정이 될 수 있습니다. LLM을 사용하면 의료 문서와 쉽게 채팅하여 보험 적용 범위, 청구 프로세스 또는 투약 지침을 이해할 수 있습니다.
결론적으로 개인 및 개인의 직업 생활에서 LLM의 잠재적인 적용은 방대하고 혁신적입니다. LLM은 PDF와의 상호 작용을 보다 대화적이고 반응적으로 만들어 디지털 생활을 보다 효율적이고 효과적으로 관리하는 데 도움이 될 수 있습니다. 개인 재정 관리, 학습 향상, 복잡한 문서 탐색 등 PDF로 채팅할 수 있는 기능은 현대인에게 강력한 도구입니다.
일상 생활에서 PDF와 관련된 작업을 자동화하고 싶습니까? 더 이상 보지 마세요! 노력하다 Nanonets의 자동화된 문서 워크플로 현재 LLM 및 Generative AI로 구동됩니다.
Nanonets를 사용하여 PDF와 채팅
Nanonets는 문서와의 상호 작용을 위해 특별히 맞춤화된 자체 LLM을 만들었으며 고객을 위한 모든 종류의 자동화된 문서 워크플로 생성을 용이하게 합니다.
우리는 최근 훈련 데이터를 사용하지 않고 모든 문서에서 데이터를 추출하고 상호 작용할 수 있는 '제로 샷' 추출 모델을 출시했습니다. 모델을 교육하는 대신 필드의 설명/정의와 함께 문서에서 추출하거나 상호 작용하려는 필드의 이름을 표시할 수 있으며 LLM에서 제공하는 모델이 나머지를 처리합니다.
다음은 Generative AI 및 사내 LLM의 기능을 사용하여 몇 초 안에 문서와 관련된 작업 실행을 시작할 수 있는 방법을 살짝 보여줍니다.
또한 문서 워크플로는 다음과 같은 기능 및 통합을 바로 사용할 수 있도록 제공합니다.
- 선택한 소프트웨어/데이터베이스/ERP에서 문서 가져오기.
- 자동화된 유효성 검사를 생성합니다.

- 자동 또는 수동 승인 프로세스 설정.

- 워크플로우 실행 후 문서 및 데이터를 선택한 소프트웨어/데이터베이스/ERP로 내보냅니다.

이 모든 것이 일상 생활에서 PDF와 관련된 개인 또는 전문 작업을 몇 분 안에 자동화할 수 있는 무한한 가능성을 열어줍니다.
요약하면 LLM을 사용하여 PDF로 채팅하면 문서 기반 작업을 변환하고 자동화할 수 있는 엄청난 잠재력이 있습니다. Nanonets는 매우 사용자 친화적인 인터페이스와 함께 도구를 제공하여 몇 초 안에 자동화된 문서 워크플로를 생성하고 방대한 통합을 통해 이미 사용 중인 시스템과 원활하게 통합함으로써 이러한 잠재력을 실현합니다. 당사의 제로 샷 기능을 사용하면 교육 데이터 없이 문서에서 채팅, 상호 작용 및 데이터 추출을 수행할 수 있으므로 비전문가가 PDF에 잠긴 값을 잠금 해제할 수 있습니다.
문서와 대화하고 필요한 통찰력을 즉시 추출하는 기능은 정보 작업 방식을 재정의합니다. LLM은 PDF 데이터 액세스에 내재된 마찰을 제거하여 생산성 향상, 비용 절감 및 조직 효율성 향상으로 이어집니다. PDF 및 구조화되지 않은 데이터의 양이 계속 폭발적으로 증가함에 따라 이러한 기술을 활용하는 것이 중요합니다.
우리는 'Data-On-Demand' 시대를 향해 가고 있습니다. 필요한 모든 정보를 필요할 때 즉시 사용할 수 있어 개인, 기업 및 사회 전체에 막대한 가능성을 열어줍니다. 지금 바로 문서 작업 흐름 자동화를 시작하십시오. Nanonets는 한 번에 하나의 PDF로 'Data-On-Demand'를 향한 여정을 가능하게 합니다!
일상 생활에서 PDF와 관련된 작업을 자동화하고 싶습니까? 더 이상 보지 마세요! 노력하다 Nanonets의 자동화된 문서 워크플로 현재 LLM 및 Generative AI로 구동됩니다.
추가 읽기
충수
부록 1 – LLM 이면의 기술
OpenAI의 GPT-4와 같은 언어 학습 모델(LLM)은 트랜스포머 기반 딥 러닝으로 알려진 고급 형태의 인공 지능을 활용합니다. 이 방법은 변환기로 알려진 특정 신경망 아키텍처를 사용하며 언어 내 컨텍스트를 이해하는 데 탁월합니다. 이러한 이해는 다양한 단어가 서로에게 미치는 영향을 평가하고 조정하는 "주의"라는 메커니즘에 의해 구동됩니다.
LLM 구축의 핵심 사항을 살펴보겠습니다.
- 변압기 : 논문에 소개 “주의가 필요한 전부입니다”, 변환기는 "주의" 메커니즘을 사용하여 문장에서 단어의 문맥과 상호 관계를 이해합니다.
- 비지도 학습: 이 모델은 비지도 학습으로 훈련됩니다. 즉, 방대한 양의 텍스트 데이터(예: 책, 기사, 웹 사이트)를 입력하고 문장의 다음 단어를 예측하여 학습합니다. 그런 다음 모델은 예측과 실제 단어 사이의 오류를 기반으로 자체 조정합니다. 수십억 건의 예측 후 모델은 학습 데이터에 포함된 언어 컨텍스트, 의미 체계 및 사실적 지식에 대한 이해를 크게 향상시킵니다.
학습 과정의 예:
예를 들어, 모델은 종종 다음과 같은 문장을 접하게 됩니다.
"2와 3의 합은 5입니다."
"7과 3을 더하면 10이 됩니다."
이러한 문장은 패턴을 설정합니다. 특정 숫자 값 뒤에 "sum of" 또는 "add"와 같은 문구가 올 때 다음 단어는 종종 언급된 값의 합계를 나타내는 숫자입니다.
이제 "6과 4의 합"이라는 새로운 입력이 주어지면 모델은 다음 단어를 "10"으로 예측합니다.
- 이해와 패턴 인식: 모델이 인간과 같은 방식으로 덧셈의 개념을 진정으로 이해하지 못할 수도 있다는 점에 유의하는 것이 중요합니다. 훈련에서 패턴을 인식하는 데 아주 능숙합니다.
- 미세 조정: 사전 훈련 단계 다음에는 미세 조정 프로세스가 이어집니다. 이 감독 학습 단계에는 질문 응답 또는 텍스트 완성과 같은 특정 작업에 대한 모델의 추가 교육이 포함됩니다. 이 단계에서 모델은 일반 언어 이해 능력을 개선하여 보다 전문적인 작업을 수행합니다.
- 최적화 : 이 모델은 역전파 및 경사하강법을 사용하여 수백만 개의 매개변수를 최적화하고 반복적으로 예측을 개선합니다.
이러한 프로세스의 정점은 대화 또는 텍스트 조각의 맥락에 대한 인상적인 이해를 통해 사람과 유사한 텍스트를 생성할 수 있는 AI 시스템으로 이어집니다.
부록 2 – LLM 모델 비교
우리는 사용 가능한 가장 진보된 LLM을 시도하고 서로 비교하는 방법을 평가했습니다. 한번 살펴봅시다 –
GPT-4
GPT-4는 OpenAI의 LLM 목록에서 사용할 수 있는 최신 모델입니다. 공개적으로 사용 가능한 데이터와 사람의 피드백을 통한 강화 학습을 사용하여 훈련되었습니다. 이 교육 접근 방식을 통해 GPT-4는 창의적이고 기술적인 작문 작업을 모두 생성, 편집 및 반복할 수 있으므로 작곡, 코드 작성, 학습 지원과 같은 작업에서 다재다능하게 사용할 수 있습니다.
장점 :
- 이 모델에는 많은 수의 매개변수(1조 개 이상으로 알려져 있음)가 있어 매우 강력하고 복잡한 작업을 수행할 수 있습니다.
- 자연어 쿼리에 대해 사람과 같은 응답을 생성할 수 있으므로 대화형 애플리케이션에 이상적입니다.
- 언어 번역, 요약, 질의 응답 등 다양한 작업을 쉽게 수행합니다.
- 고급 추론 기능이 있습니다.
- 창의적인 작업을 잘 수행할 수 있습니다.
- 상업적 사용이 허용됩니다.
단점 :
- API 가용성은 제한되어 있으며 대기자 명단을 통해서만 얻을 수 있습니다.
- 이 모델은 API 호출당 비용이 높아 사용 비용이 많이 듭니다.
- 특히 더 긴 입력의 경우 응답 생성이 느릴 수 있습니다.
GPT-3.5
GPT-3.5 모델의 진화인 OpenAI의 GPT-3는 뛰어난 파싱 능력을 갖춘 고급 언어 모델입니다. 그것은 인간의 지시에 따라 밀접하게 에뮬레이션하고 또한 쿼리에 응답하기 위해 대규모 지식 기반을 사용합니다.
장점 :
- GPT-3.5는 3억 개가 넘는 기계 학습 매개 변수를 보유하고 인터넷 데이터로 훈련된 거대한 언어 모델인 GPT-175보다 크게 개선되었습니다.
- GPT-3는 콘텐츠 자동화 및 고객 경험 향상 분야에서 이미 상업적 용도로 사용되고 있습니다.
- 다목적 API를 통해 GPT-3.5를 개발자의 애플리케이션에 완벽하게 통합할 수 있습니다.
- 방대한 매개변수 수는 사람이 쓴 것과 거의 구별할 수 없는 고품질 텍스트 생성을 용이하게 합니다.
- 이 모델은 다양한 데이터 세트에서 훈련되었으며 성능을 미세 조정하기 위해 감독 테스트 및 강화 단계를 거쳤습니다.
- 사용자 지정 미세 조정은 구현하기 쉬우므로 개발자가 특정 목적을 위해 모델의 사용자 지정 변형을 만들 수 있습니다.
단점 :
- 출력 생성의 편향은 잠재적인 문제를 제시하며 개발자는 GPT-3.5를 사용할 때 이를 인식해야 합니다.
- 이 모델은 API 호출당 비용이 높기 때문에 사용 비용이 적당합니다.
구글 팜
PaLM(파싱, 렉싱 및 모델링)은 Google에서 개발한 정교한 AI 언어 모델로, 강력한 텍스트 생성 기능을 제공하는 OpenAI 및 Meta의 모델과 유사합니다. 여러 텍스트 생성 작업에서의 광범위한 유용성으로 인해 PaLM은 자연어 처리 영역에서 다재다능한 도구입니다.
장점 :
- 개발자는 PaLM API의 기능을 활용하여 PaLM을 응용 프로그램 및 서비스에 내장하기 위한 사용하기 쉬운 인터페이스를 제공할 수 있습니다.
- 이 API는 잠재적으로 유해한 스크립트를 조사하고 이해하고, 악의적인 활동을 효율적으로 감지하고, 단어 완성 및 코드 생성과 같은 작업을 실행하는 데 매우 적합합니다.
- PaLM의 상업적 활용이 가능합니다.
- PaLM의 핵심 강점은 다양한 작업을 관리하는 능력에 있습니다. 다재다능함은 개발자와 개인 사용자 모두에게 매력적입니다.
- 방대한 텍스트 및 코드 데이터 세트에 대해 교육을 받은 PaLM은 정확하고 상황에 맞는 결과를 제공합니다.
단점 :
- 잠재적인 단점 중 하나는 편향되거나 부적절한 출력의 위험입니다. 교육 데이터에 편견이나 부적절한 콘텐츠가 포함된 경우 생성된 출력에 반영될 수 있습니다. PaLM을 사용하는 개발자는 이러한 잠재적 편향을 경계하고 적절한 완화 조치를 취해야 합니다.
- PaLM의 훈련 과정에 대한 정확한 세부 사항은 아직 공개되지 않았습니다.
- 고급 OpenAI GPT 모델에 비해 성능이 떨어집니다.
클로드 LLM v1
Anthropic의 Claude LLM은 사용자가 다양한 용도로 고품질 콘텐츠를 생성할 수 있도록 미세 조정된 혁신적인 언어 모델입니다. 고급 기능과 사용자 친화적인 인터페이스로 인해 비즈니스, 콘텐츠 제작자 및 전문가가 선호하는 도구가 되었습니다.
Anthropic은 또한 가장 큰 컨텍스트 창으로 100k 토큰 Claude-instant-100k 모델에서. 기본적으로 단일 채팅 메시지에 75,000개에 가까운 단어를 로드할 수 있으며 이는 논의된 다른 LLM을 통해 직접 가능하지 않습니다.
장점 :
- 가장 큰 컨텍스트 창 크기입니다. 기본적으로 나열된 모든 LLM 중에서 가장 큰 프롬프트 길이(하나의 채팅 메시지 길이) 지원을 제공합니다.
- 이 모델은 일관되고 상황에 맞는 콘텐츠를 생성하여 고품질 결과를 보장합니다.
- Claude LLM은 광범위한 콘텐츠 유형에 사용할 수 있어 다양한 비즈니스 요구에 적응할 수 있습니다.
단점 :
- 인상적인 콘텐츠를 생산하는 능력에도 불구하고 다른 LLM이 모방하는 창의적인 불꽃과 개인적인 감각이 부족할 수 있습니다.
- 출력 품질은 사용자가 제공하는 프롬프트에 크게 좌우됩니다. 잘 만들어진 프롬프트는 더 나은 콘텐츠를 제공합니다.
마이크로소프트 T5
Microsoft T5는 Microsoft에서 도입한 고급 자연어 처리 모델로, 인코더-디코더 아키텍처를 중심으로 구축되었으며 광범위한 NLP 작업을 처리하기 위해 텍스트-텍스트 형식을 활용합니다. 감독 및 비지도 학습 방법의 조합을 통해 훈련된 이 모델은 벤치마크에서 다운스트림 작업 훈련을 통한 감독 학습과 손상된 토큰 사용을 통한 자기 감독 학습을 제공합니다.
장점 :
- 이 모델은 T5v1.1, mT5, byT5, UL2, Flan-T5, Flan-UL2 및 UMT5를 포함한 여러 버전으로 제공되어 사용자에게 다양한 기능을 제공합니다.
- 그것은 교사 강제를 활용하는 감독 및 감독되지 않은 방식 모두에서 미세 조정을 허용합니다.
- 이 모델은 매우 다재다능하며 번역, 요약 및 텍스트 분류와 같은 다양한 작업에 사용할 수 있습니다.
- 개발자를 위한 API를 제공하여 기업이 모델을 애플리케이션 및 서비스에 통합하여 기능을 활용할 수 있도록 합니다.
- Microsoft의 명성과 지원은 안정적이고 지속적인 개발 및 업데이트를 보장합니다.
단점 :
- 모델을 상업적으로 사용하려면 적절한 라이선스가 필요하고 Microsoft의 사용 약관을 준수해야 할 수 있습니다.
- T5에서 생성된 응답의 성능 및 품질은 특정 사용 사례 및 데이터 세트에 따라 달라질 수 있습니다.
- 미세 조정 T5에는 상당한 전문성과 도메인별 지식이 필요합니다.
- T5를 사용하는 관련 비용과 필요한 컴퓨팅 리소스는 특정 비즈니스에 문제가 될 수 있습니다.
야마
Meta AI의 FAIR 팀은 자연어 처리 및 인공 지능과 같은 분야에서 연구용 언어 모델인 LLaMA를 개발했습니다. XNUMX개월 동안 교육을 받았으며 다양한 크기로 제공됩니다.
모델 사용 허가를 신청해야 합니다. 여기에서 지금 확인해 보세요..
장점 :
- 여러 모델 크기는 다양한 연구 요구 사항을 충족합니다.
- 다양한 교육 소스(CCNet[67%], C4[15%], GitHub[4.5%], Wikipedia[4.5%], Books[4.5%], ArXiv[2.5%], Stack Exchange [2%]).
- 다양한 효과로 언어별 작업을 수행할 수 있습니다.
단점 :
- 유해하거나 공격적인 콘텐츠 생성으로 이어질 수 있는 사람의 피드백을 통한 강화 학습이 부족합니다.
- 비상업적 라이선스는 연구 외부에서의 적용 가능성을 제한합니다.
- 액세스하려면 권한이 필요하므로 가용성이 제한될 수 있습니다.
안정LM
Stability AI의 StableLM은 3억 및 7억 매개변수 버전이 있는 오픈 소스 언어 모델 제품군이며 더 큰 모델(최대 65억 매개변수)이 개발 중입니다. 교육은 The Pile에 구축된 새로운 실험 데이터 세트를 기반으로 합니다.
장점 :
- 텍스트와 코드를 모두 생성하여 다양한 애플리케이션에 적용할 수 있습니다.
- 오픈 소스 특성으로 인한 높은 투명성과 확장성.
- 광범위한 기능 범위에 기여하는 다양한 데이터 세트인 The Pile에 대한 교육을 받았습니다.
단점 :
- 아직 알파 버전이므로 안정성 및 성능 문제가 있을 수 있습니다.
- 모델의 크기는 상당한 RAM을 필요로 하므로 일부 플랫폼에서의 유용성이 제한됩니다.
- 비상업적 라이선스로 출시되어 연구용으로만 사용이 제한됩니다.
인형
Databricks에서 만든 언어 모델인 Dolly는 머신 러닝 플랫폼에서 교육을 받았습니다. EleutherAI의 Pythia-12b에서 파생되었으며 Databricks 직원이 생성한 지침/응답 레코드 데이터 세트에서 미세 조정되었습니다.
장점 :
- 상업적 사용이 허가되어 잠재적인 응용 프로그램이 확장됩니다.
- Hugging Face에서 사용할 수 있어 쉽게 사용할 수 있습니다.
단점 :
- 최첨단 모델이 아니며 복잡한 프롬프트와 문제로 어려움을 겪을 수 있습니다.
- 모델 크기가 크면 상당한 RAM이 필요하므로 일부 플랫폼에서 로드하기 어렵습니다.
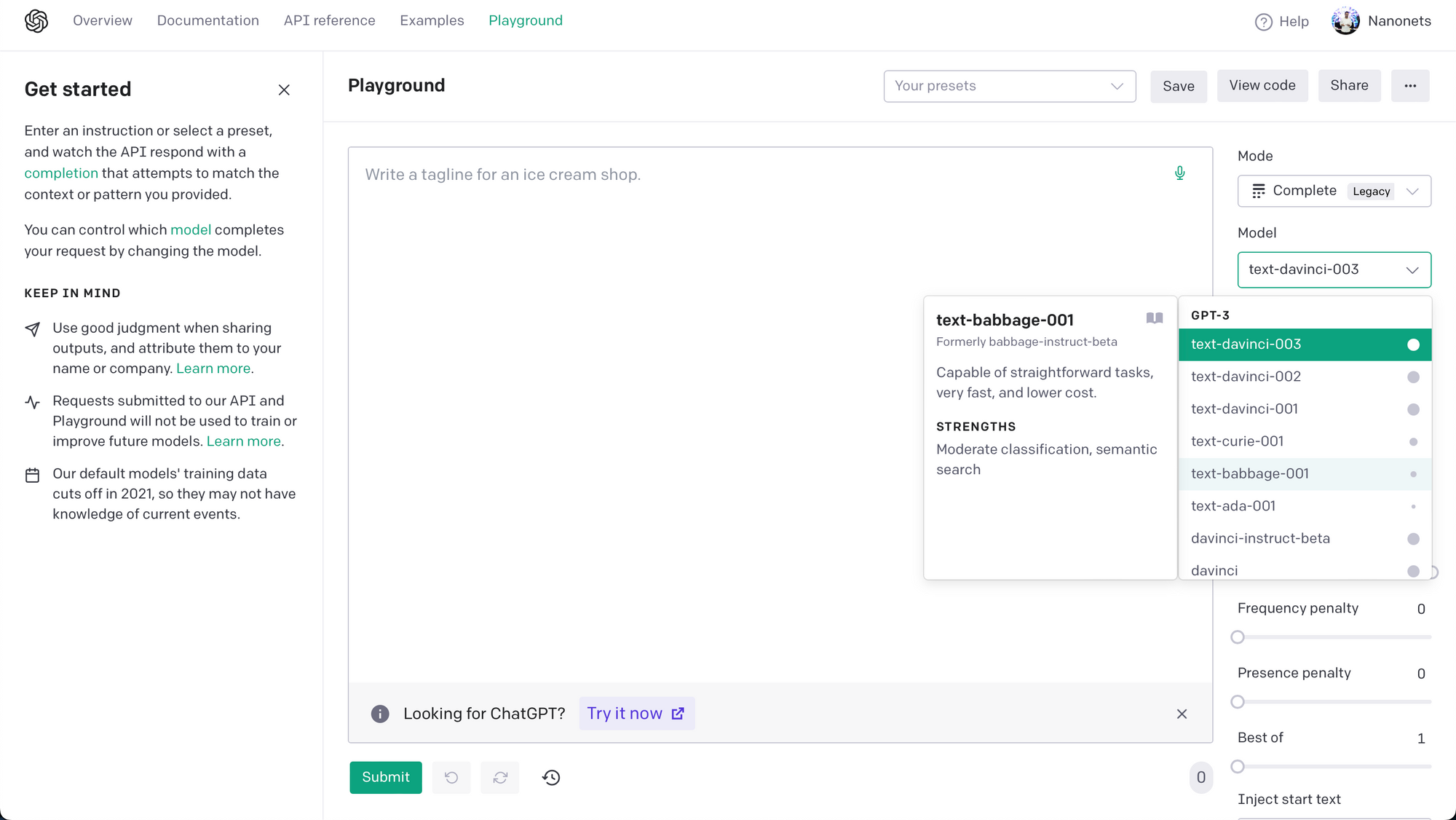
부록 3 – GPT 모델을 선택하는 방법은 무엇입니까?
OpenAI의 Python 라이브러리를 사용하는 동안 이상적인 모델을 선택하는 것은 사용 사례와 특정 요구 사항에 따라 다릅니다. 사용 가능한 모델 목록을 살펴보고 사용 가능한 각 모델의 장단점을 알아보는 것이 좋습니다. 다음과 같이 사용 가능한 모델 목록에 액세스할 수 있습니다.
import pandas as pd
models = openai.Model.list()
modelsdf = pd.DataFrame(models["data"])
print(modelsdf)

OpenAI의 모델 제품군(GPT-4, GPT-3, Codex, 콘텐츠 필터링)에 대한 빠른 요약 –
-> GPT-4는 거의 모든 작업에 대해 다른 모델을 대체할 수 있는 최신 모델입니다. 현재 액세스 권한을 얻기가 어려우며 대기자 명단에 등록하면 가능합니다. 이 모델을 사용하는 비용도 높습니다.
-> GPT-3, Codex 및 Content Filtering 모델은 저렴하고 특정 목적을 수행하는 바로 사용할 수 있는 모델이며 그에 따라 GPT-4 모델 대신 사용할 수 있습니다.
-> GPT-3는 텍스트 완성, 삽입 및 편집에 탁월합니다. 그것은 DaVinci, Curie, Babbage 및 Ada 시리즈를 포함합니다 –
- GPT-3.5는 여기에서 가장 유능하고 비싼 모델입니다. 미세 조정에 권장되며 거의 모든 종류의 작업에서 탁월합니다.
- DaVinci는 복잡한 의도를 이해하고 특정 청중을 위한 정보를 요약하는 데 적합합니다. 미세 조정에 꽤 잘 작동합니다.
- Curie는 감정 분석 및 텍스트 분류에 탁월합니다.
- Babbage 및 Ada 모델은 간단한 작업에 이상적입니다.
-> Codex 모델은 코드 완성, 편집 및 삽입에 능숙합니다. 현재 Davinci와 Cushman의 두 가지 모델이 제공됩니다.
- 다빈치가 더 유능합니다.
- 쿠시맨이 더 빠릅니다.
-> 콘텐츠 필터링 모델은 민감하거나 잠재적으로 유해한 콘텐츠를 감지하고 필터링하는 데 사용됩니다.
OpenAI 놀이터 다양한 모델을 테스트하고 비교하기 위한 효과적인 플랫폼입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://nanonets.com/blog/chat-with-pdfs-using-chatgpt-and-openai-gpt-api/

