ML 모델의 개발, 배포, 관리를 간소화하려면 확장 가능하고 효율적인 기계 학습(ML) 파이프라인을 만드는 것이 중요합니다. 이 게시물에서는 방향성 비순환 그래프(DAG) 생성을 자동화하는 프레임워크를 제시합니다. Amazon SageMaker 파이프 라인 간단한 구성 파일을 기반으로 합니다. 그만큼 프레임워크 코드 및 예제 여기에 제시된 내용은 모델 훈련 파이프라인만 다루지만 일괄 추론 파이프라인으로도 쉽게 확장할 수 있습니다.
이 동적 프레임워크는 구성 파일을 사용하여 사용자 정의 Python 스크립트, 인프라 요구 사항(포함)을 기반으로 단일 모델 및 다중 모델 사용 사례 모두에 대한 전처리, 훈련, 평가 및 등록 단계를 조정합니다. 아마존 가상 프라이빗 클라우드 (Amazon VPC) 서브넷 및 보안 그룹, AWS 자격 증명 및 액세스 관리 (IAM) 역할, AWS 키 관리 서비스 (AWS KMS) 키, 컨테이너 레지스트리 및 인스턴스 유형), 입력 및 출력 아마존 단순 스토리지 서비스 (Amazon S3) 경로 및 리소스 태그. 구성 파일(YAML 및 JSON)을 통해 ML 실무자는 선언적 구문을 사용하여 학습 파이프라인을 조정하기 위한 차별화되지 않은 코드를 지정할 수 있습니다. 이를 통해 데이터 과학자는 ML 모델을 신속하게 구축하고 반복할 수 있으며, ML 엔지니어는 지속적 통합 및 지속적 전달(CI/CD) ML 파이프라인을 더 빠르게 실행하여 모델 생산 시간을 단축할 수 있습니다.
솔루션 개요
제안된 프레임워크 코드는 구성 파일을 읽는 것으로 시작됩니다. 그런 다음 구성 파일에 선언된 단계와 단계 간의 상호 작용 및 종속성을 기반으로 SageMaker 파이프라인 DAG를 동적으로 생성합니다. 이 오케스트레이션 프레임워크는 단일 모델 및 다중 모델 사용 사례를 모두 충족하고 데이터 및 프로세스의 원활한 흐름을 제공합니다. 이 솔루션의 주요 이점은 다음과 같습니다.
- 자동화 – 데이터 전처리부터 모델 레지스트리까지 전체 ML 워크플로가 수동 개입 없이 조정됩니다. 이를 통해 모델 실험 및 운영화에 필요한 시간과 노력이 줄어듭니다.
- 재현성 – 사전 정의된 구성 파일을 통해 데이터 과학자와 ML 엔지니어는 전체 워크플로를 재현하여 여러 실행 및 환경에서 일관된 결과를 얻을 수 있습니다.
- 확장성 - 아마존 세이지 메이커 파이프라인 전체에서 사용되므로 ML 실무자는 인프라 문제 없이 대규모 데이터 세트를 처리하고 복잡한 모델을 교육할 수 있습니다.
- 유연성 – 프레임워크는 유연하며 광범위한 ML 사용 사례, ML 프레임워크(예: XGBoost 및 TensorFlow), 다중 모델 교육 및 다단계 교육을 수용할 수 있습니다. 학습 DAG의 모든 단계는 구성 파일을 통해 맞춤설정할 수 있습니다.
- 모델 거버넌스 - Amazon SageMaker 모델 레지스트리 통합을 통해 모델 버전을 추적할 수 있으므로 자신 있게 이를 프로덕션으로 승격할 수 있습니다.
다음 아키텍처 다이어그램은 ML 모델의 실험 및 운영 중에 제안된 프레임워크를 사용할 수 있는 방법을 보여줍니다. 실험하는 동안 이 게시물에 제공된 프레임워크 코드 저장소와 프로젝트별 소스 코드 저장소를 복제할 수 있습니다. 아마존 세이지 메이커 스튜디오, 가상 환경을 설정합니다(이 게시물의 뒷부분에서 자세히 설명). 그런 다음 구성 선택은 물론 전처리, 교육, 평가 스크립트를 반복할 수 있습니다. SageMaker 파이프라인 교육 DAG를 생성하고 실행하려면 프레임워크의 진입점을 호출하면 모든 구성 파일을 읽고, 필요한 단계를 생성하고, 지정된 단계 순서 및 종속성을 기반으로 조정합니다.
운영화 중에 CI 파이프라인은 프레임워크 코드 저장소와 프로젝트별 교육 저장소를 복제합니다. AWS 코드빌드 SageMaker 파이프라인 교육 DAG를 생성 또는 업데이트하기 위해 프레임워크의 진입점 스크립트가 호출되는 작업입니다.

저장소 구조
XNUMXD덴탈의 GitHub 저장소 다음 디렉터리와 파일이 포함되어 있습니다.
- /프레임워크/conf/ – 이 디렉터리에는 런타임 시 서브넷, 보안 그룹, IAM 역할 등 모든 모델링 단위에 공통 변수를 설정하는 데 사용되는 구성 파일이 포함되어 있습니다. 모델링 단위는 ML 모델 학습을 위한 최대 6단계의 시퀀스입니다.
- /프레임워크/모델 생성/ – 이 디렉터리에는 다음을 생성하는 Python 스크립트가 포함되어 있습니다. 세이지메이커 모델 모델 아티팩트를 기반으로 하는 객체 SageMaker 파이프라인 훈련 단계. 모델 객체는 나중에 SageMaker 일괄 변환 테스트 세트에서 모델 성능을 평가하는 작업입니다.
- /프레임워크/모델메트릭스/ – 이 디렉터리에는 다음을 생성하는 Python 스크립트가 포함되어 있습니다. Amazon SageMaker 처리 테스트 데이터에 대해 수행된 SageMaker 배치 변환 작업의 결과를 기반으로 훈련된 모델에 대한 모델 지표 JSON 보고서를 생성하는 작업입니다.
- /프레임워크/파이프라인/ – 이 디렉터리에는 다른 프레임워크 디렉터리에 정의된 Python 클래스를 사용하여 지정된 구성을 기반으로 SageMaker 파이프라인 DAG를 생성하거나 업데이트하는 Python 스크립트가 포함되어 있습니다. model_unit.py 스크립트는 파이프라인_service.py에서 하나 이상의 모델링 단위를 생성하는 데 사용됩니다. 각 모델링 단위는 ML 모델 학습을 위한 최대 6단계(프로세싱, 학습, 모델 생성, 변환, 측정항목, 모델 등록)로 구성된 시퀀스입니다. 각 모델링 단위에 대한 구성은 모델의 해당 저장소에 지정되어야 합니다. 파이프라인_service.py는 또한 모델 리포지토리 중 하나(앵커 모델)의 구성 파일에 정의되어야 하는 sagemakerPipeline 섹션을 기반으로 SageMaker 파이프라인 단계(모델링 단위 내 및 모델링 단위 간 단계가 순서화되거나 연결되는 방식) 간의 종속성을 설정합니다. 이를 통해 SageMaker 파이프라인에서 유추된 기본 종속성을 재정의할 수 있습니다. 이 게시물의 뒷부분에서 구성 파일 구조에 대해 논의합니다.
- /프레임워크/처리/ – 이 디렉터리에는 지정된 Docker 이미지 및 진입점 스크립트를 기반으로 SageMaker 처리 작업을 생성하는 Python 스크립트가 포함되어 있습니다.
- /프레임워크/레지스터 모델/ – 이 디렉터리에는 SageMaker 모델 레지스트리에 계산된 지표와 함께 훈련된 모델을 등록하기 위한 Python 스크립트가 포함되어 있습니다.
- /프레임워크/훈련/ – 이 디렉터리에는 SageMaker 훈련 작업을 생성하는 Python 스크립트가 포함되어 있습니다.
- /프레임워크/변환/ – 이 디렉터리에는 SageMaker 배치 변환 작업을 생성하는 Python 스크립트가 포함되어 있습니다. 모델 훈련의 맥락에서 이는 테스트 데이터에 대해 훈련된 모델의 성능 지표를 계산하는 데 사용됩니다.
- /프레임워크/유틸리티/ – 이 디렉토리에는 구성 파일을 읽고 결합하고 로깅하기 위한 유틸리티 스크립트가 포함되어 있습니다.
- /framework_entrypoint.py – 이 파일은 프레임워크 코드의 진입점입니다. /framework/pipeline/ 디렉터리에 정의된 함수를 호출하여 SageMaker Pipelines DAG를 생성 또는 업데이트하고 실행합니다.
- /예제/ – 이 디렉터리에는 이 자동화 프레임워크를 사용하여 간단하고 복잡한 교육 DAG를 생성하는 방법에 대한 몇 가지 예가 포함되어 있습니다.
- /env.env – 이 파일을 사용하면 서브넷, 보안 그룹, IAM 역할 등 공통 변수를 환경 변수로 설정할 수 있습니다.
- /요구사항.txt – 이 파일은 프레임워크 코드에 필요한 Python 라이브러리를 지정합니다.
사전 조건
이 솔루션을 배포하기 전에 다음과 같은 필수 구성 요소가 있어야 합니다.
- AWS 계정
- SageMaker 스튜디오
- Amazon S3 읽기/쓰기 및 AWS KMS 암호화/해독 권한이 있는 SageMaker 역할
- 데이터, 스크립트, 모델 아티팩트를 저장하기 위한 S3 버킷
- 선택적으로 AWS 명령 줄 인터페이스 (AWS CLI)
- Python3(Python 3.7 이상) 및 다음 Python 패키지:
- 보토3
- 현자
- PyYAML
- 사용자 정의 스크립트에 사용되는 추가 Python 패키지
솔루션 배포
솔루션을 배포하려면 다음 단계를 완료하세요.
- 다음 구조에 따라 모델 학습 리포지토리를 구성합니다.
- Git 리포지토리에서 프레임워크 코드와 모델 소스 코드를 복제합니다.
-
- 복제
dynamic-sagemaker-pipelines-framework훈련 디렉토리에 repo. 다음 코드에서는 교육 디렉터리가 다음과 같이 호출된다고 가정합니다.aws-train: - 동일한 디렉터리에 모델 소스 코드를 복제합니다. 다중 모델 학습의 경우 학습해야 하는 만큼의 모델에 대해 이 단계를 반복하세요.
- 복제
단일 모델 학습의 경우 디렉터리는 다음과 같아야 합니다.
다중 모델 학습의 경우 디렉터리는 다음과 같아야 합니다.
- 다음 환경 변수를 설정합니다. 별표는 필요한 환경 변수를 나타냅니다. 나머지는 선택 사항입니다.
| 환경 변수 | 상품 설명 |
SMP_ACCOUNTID* |
SageMaker 파이프라인이 실행되는 AWS 계정 |
SMP_REGION* |
SageMaker 파이프라인이 실행되는 AWS 리전 |
SMP_S3BUCKETNAME* |
S3 버킷 이름 |
SMP_ROLE* |
SageMaker 역할 |
SMP_MODEL_CONFIGPATH* |
단일 모델 또는 다중 모델 구성 파일의 상대 경로 |
SMP_SUBNETS |
SageMaker 네트워킹 구성을 위한 서브넷 ID |
SMP_SECURITYGROUPS |
SageMaker 네트워킹 구성을 위한 보안 그룹 ID |
단일 모델 사용 사례의 경우 SMP_MODEL_CONFIGPATH 될거야 <MODEL-DIR>/conf/conf.yaml. 다중 모델 사용 사례의 경우 SMP_MODEL_CONFIGPATH 될거야 */conf/conf.yaml, 이를 통해 모든 항목을 찾을 수 있습니다. conf.yaml Python의 glob 모듈을 사용하여 파일을 만들고 결합하여 전역 구성 파일을 형성합니다. 실험(로컬 테스트) 중에 env.env 파일 내에 환경 변수를 지정한 후 터미널에서 다음 명령을 실행하여 내보낼 수 있습니다.
환경 변수의 값은 다음과 같습니다. env.env 따옴표 안에 넣어야 합니다(예: SMP_REGION="us-east-1"). 운영화 중에 이러한 환경 변수는 CI 파이프라인에 의해 설정되어야 합니다.
- 다음 명령을 실행하여 가상 환경을 만들고 활성화합니다.
- 다음 명령을 실행하여 필수 Python 패키지를 설치합니다.
- 모델 학습 편집
conf.yaml파일. 다음 섹션에서 구성 파일 구조에 대해 논의합니다. - 터미널에서 프레임워크의 진입점을 호출하여 SageMaker 파이프라인 교육 DAG를 생성 또는 업데이트하고 실행합니다.
- SageMaker 파이프라인 실행을 보고 디버깅합니다. 파이프 라인 SageMaker Studio UI의 탭입니다.
구성 파일 구조
제안된 솔루션에는 프레임워크 구성과 모델 구성이라는 두 가지 유형의 구성 파일이 있습니다. 이 섹션에서는 각각에 대해 자세히 설명합니다.
프레임워크 구성
XNUMXD덴탈의 /framework/conf/conf.yaml 파일은 모든 모델링 단위에 공통되는 변수를 설정합니다. 여기에는 다음이 포함됩니다 SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPS및 SMP_MODELNAME. 이러한 변수에 대한 설명과 환경 변수를 통해 설정하는 방법은 배포 지침의 3단계를 참조하세요.
모델 구성
프로젝트의 각 모델에 대해 다음을 지정해야 합니다. <MODEL-DIR>/conf/conf.yaml 파일(별표는 필수 섹션을 나타내며 나머지는 선택 사항입니다):
- /conf/모델* – 이 섹션에서는 하나 이상의 모델링 단위를 구성할 수 있습니다. 프레임워크 코드가 실행되면 런타임 중에 모든 구성 파일을 자동으로 읽고 구성 트리에 추가합니다. 이론적으로는 모든 모델링 단위를 동일하게 지정할 수 있습니다.
conf.yaml파일이지만 오류를 최소화하려면 해당 디렉터리나 Git 리포지토리에 각 모델링 단위 구성을 지정하는 것이 좋습니다. 단위는 다음과 같습니다.- {모델명}* – 모델 이름.
- 소스_디렉토리* - 공통
source_dir모델링 단위 내의 모든 단계에 사용할 경로입니다. - 전처리 – 이 섹션에서는 전처리 매개변수를 지정합니다.
- 기차* – 이 섹션에서는 훈련 작업 매개변수를 지정합니다.
- 변환* – 이 섹션에서는 테스트 데이터에 대한 예측을 위한 SageMaker Transform 작업 매개변수를 지정합니다.
- 평가 – 이 섹션에서는 훈련된 모델에 대한 모델 지표 JSON 보고서를 생성하기 위한 SageMaker 처리 작업 매개 변수를 지정합니다.
- 기재* – 이 섹션에서는 SageMaker 모델 레지스트리에 훈련된 모델을 등록하기 위한 매개변수를 지정합니다.
- /conf/sagemaker파이프라인* – 이 섹션에서는 단계 간 종속성을 포함하여 SageMaker 파이프라인 흐름을 정의합니다. 단일 모델 사용 사례의 경우 이 섹션은 구성 파일 끝에 정의됩니다. 다중 모델 사용 사례의 경우
sagemakerPipeline섹션은 모델 중 하나(모든 모델)의 구성 파일에서만 정의하면 됩니다. 우리는 이 모델을 다음과 같이 지칭합니다. 앵커 모델. 매개변수는 다음과 같습니다:- 파이프라인이름* – SageMaker 파이프라인의 이름입니다.
- 모델* – 모델링 단위의 중첩 목록:
- {모델명}* – /conf/models 섹션의 {model-name} 식별자와 일치해야 하는 모델 식별자입니다.
- 단계* -
- 단계_이름* – SageMaker 파이프라인 DAG에 표시될 단계 이름입니다.
- 단계_클래스* – (합집합[처리, 훈련, CreateModel, 변환, 지표, RegisterModel])
- 단계 유형* – 이 매개변수는 전처리 단계에만 필요하며 전처리로 설정되어야 합니다. 이는 전처리 단계와 평가 단계를 구별하는 데 필요하며 두 단계 모두
step_class처리. - 활성화_캐시 – ([합집합[참, 거짓]]). 활성화할지 여부를 나타냅니다. SageMaker 파이프라인 캐싱 이 단계를 위해.
- chain_input_source_step – ([목록[단계_이름]]). 이를 사용하여 다른 단계의 채널 출력을 이 단계의 입력으로 설정할 수 있습니다.
- chain_input_additional_prefix – 이는 변환 단계에만 허용됩니다.
step_class, 와 함께 사용할 수 있습니다.chain_input_source_step매개변수를 사용하여 변환 단계의 입력으로 사용해야 하는 파일을 정확히 찾아낼 수 있습니다.
- 단계* -
- {모델명}* – /conf/models 섹션의 {model-name} 식별자와 일치해야 하는 모델 식별자입니다.
- 의존성 – 이 섹션에서는 SageMaker 파이프라인 단계를 실행해야 하는 순서를 지정합니다. 이 섹션에서는 Apache Airflow 표기법을 적용했습니다(예:
{step_name} >> {step_name}). 이 섹션을 공백으로 두면chain_input_source_step매개변수 또는 암시적 종속성은 SageMaker 파이프라인 DAG 흐름을 정의합니다.
모델링 단위당 하나의 학습 단계를 갖는 것이 좋습니다. 모델링 단위에 대해 여러 훈련 단계가 정의된 경우 후속 단계는 암시적으로 마지막 훈련 단계를 수행하여 모델 객체를 생성하고, 지표를 계산하고, 모델을 등록합니다. 여러 모델을 학습해야 하는 경우 여러 모델링 단위를 만드는 것이 좋습니다.
예
이 섹션에서는 제시된 프레임워크를 사용하여 생성된 ML 모델 학습 DAG의 세 가지 예를 보여줍니다.
단일 모델 훈련: LightGBM
이는 우리가 사용하는 분류 사용 사례에 대한 단일 모델 예입니다. SageMaker의 스크립트 모드에서 LightGBM. 그만큼 데이터 세트 이진 레이블 수익(주체가 구매하는지 여부를 예측하기 위해)을 예측하기 위한 범주형 및 숫자형 변수로 구성됩니다. 그만큼 전처리 스크립트 학습 및 테스트를 위한 데이터를 모델링하는 데 사용되며, S3 버킷에 스테이징. 그런 다음 S3 경로가 훈련 단계 구성 파일에서.
훈련 단계가 실행되면 SageMaker는 컨테이너에 파일을 로드합니다. /opt/ml/input/data/{channelName}/, 환경 변수를 통해 접근 가능 SM_CHANNEL_{channelName} 컨테이너에 (채널 이름= '훈련' 또는 '테스트').그만큼 교육 스크립트 다음을 수행합니다.
- 다음을 사용하여 로컬 컨테이너 경로에서 로컬로 파일을 로드합니다. NumPy 로드 기준 치수.
- 훈련 알고리즘에 대한 하이퍼파라미터를 설정합니다.
- 훈련된 모델을 로컬 컨테이너 경로에 저장
/opt/ml/model/.
SageMaker는 /opt/ml/model/ 아래의 콘텐츠를 가져와 호스팅용 SageMaker에 모델을 배포하는 데 사용되는 tarball을 생성합니다.
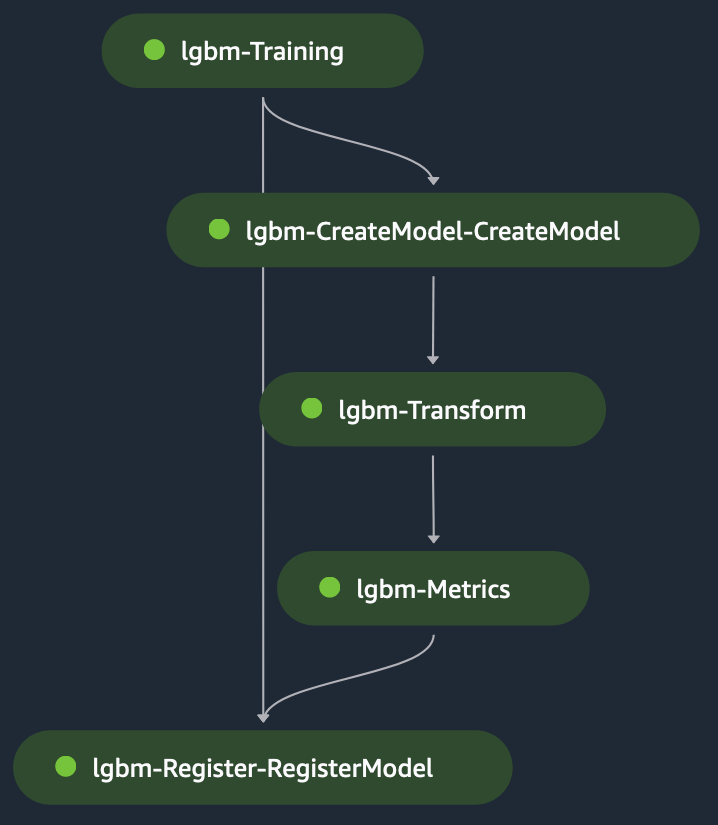
변환 단계에서는 단계적 입력을 사용합니다. 테스트 파일을 입력으로 사용 그리고 훈련된 모델에 대해 예측을 수행하는 훈련된 모델입니다. 변환 단계의 출력은 다음과 같습니다. 묶인 측정항목 단계로 이동하여 모델을 평가합니다. 지상 진실, 이는 메트릭 단계에 명시적으로 제공됩니다. 마지막으로, 메트릭 단계의 출력은 등록 단계에 암시적으로 연결되어 메트릭 단계에서 생성된 모델 성능에 대한 정보를 사용하여 SageMaker 모델 레지스트리에 모델을 등록합니다. 다음 그림은 훈련 DAG의 시각적 표현을 보여줍니다. 이 예에 대한 스크립트 및 구성 파일은 다음에서 참조할 수 있습니다. GitHub 레포.
단일 모델 학습: LLM 미세 조정
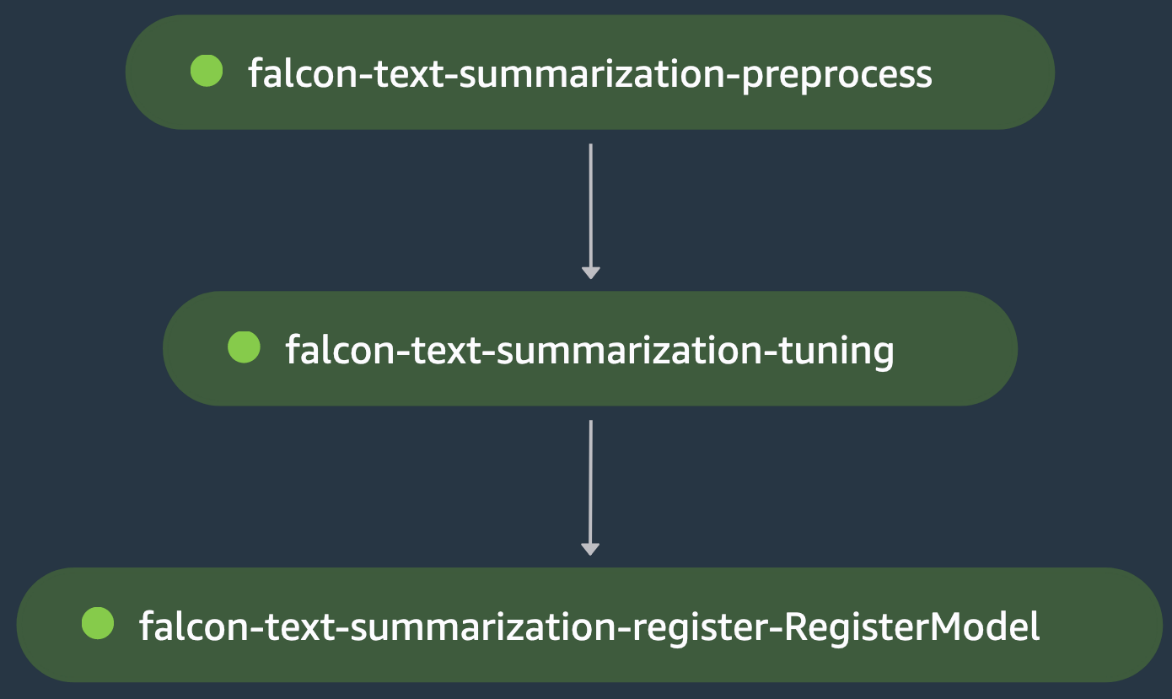
이는 텍스트 요약 사용 사례를 위해 Hugging Face Hub에서 Falcon-40B LLM(대형 언어 모델)의 미세 조정을 조율하는 또 다른 단일 모델 교육 예제입니다. 그만큼 전처리 스크립트 로드 삼섬 Hugging Face의 데이터 세트를 가져와 모델에 대한 토크나이저를 로드하고 falcon-text-summarization-preprocess 단계에서 이 도메인 데이터에 대한 모델을 미세 조정하기 위해 학습/테스트 데이터 분할을 처리합니다.
출력은 묶인 falcon-text-summarization-tuning 단계로 넘어갑니다. 교육 스크립트 Hugging Face Hub에서 Falcon-40B LLM을 로드하고 다음을 사용하여 가속 미세 조정을 시작합니다. 로라 기차 분할에. 모델은 미세 조정 후 동일한 단계로 평가됩니다. 문지기 평가 손실로 인해 falcon-text-summarization-tuning 단계가 실패하여 SageMaker 파이프라인이 미세 조정된 모델을 등록하기 전에 중지됩니다. 그렇지 않으면 falcon-text-summarization-tuning 단계가 성공적으로 실행되고 모델이 SageMaker 모델 레지스트리에 등록됩니다. 다음 그림은 LLM 미세 조정 DAG를 시각적으로 보여줍니다. 이 예제의 스크립트와 구성 파일은 다음에서 사용할 수 있습니다. GitHub 레포.
다중 모델 훈련
이는 차원 축소를 위해 PCA(주성분 분석) 모델을 학습하고, 차원 축소를 위해 TensorFlow Multilayer Perceptron 모델을 학습하는 다중 모델 학습 예시입니다. 캘리포니아 주택 가격 예측. TensorFlow 모델의 전처리 단계에서는 훈련된 PCA 모델을 사용하여 훈련 데이터의 차원성을 줄입니다. PCA 모델 등록 후 TensorFlow 모델이 등록되었는지 확인하기 위해 구성에 종속성을 추가합니다. 다음 그림은 다중 모델 학습 DAG 예를 시각적으로 보여줍니다. 이 예제의 스크립트와 구성 파일은 다음에서 사용할 수 있습니다. GitHub 레포.

정리
리소스를 정리하려면 다음 단계를 완료하세요.
- AWS CLI를 사용하여 명부 및 제거 Python 스크립트에 의해 생성된 나머지 파이프라인.
- 선택적으로 SageMaker 파이프라인 외부에서 생성된 S3 버킷 또는 IAM 역할과 같은 다른 AWS 리소스를 삭제합니다.
결론
이 게시물에서는 구성 파일을 기반으로 SageMaker Pipelines DAG 생성을 자동화하기 위한 프레임워크를 제시했습니다. 제안된 프레임워크는 복잡한 ML 워크로드를 조정하는 과제에 대한 미래 지향적인 솔루션을 제공합니다. SageMaker 파이프라인은 구성 파일을 사용하여 최소한의 코드로 오케스트레이션을 구축할 수 있는 유연성을 제공하므로 단일 모델 및 다중 모델 파이프라인을 모두 생성하고 관리하는 프로세스를 간소화할 수 있습니다. 이 접근 방식은 시간과 리소스를 절약할 뿐만 아니라 MLOps 모범 사례를 장려하여 ML 이니셔티브의 전반적인 성공에 기여합니다. 구현 세부정보에 대한 자세한 내용은 다음을 검토하세요. GitHub 레포.
저자에 관하여
 루이스 펠리페 예페스 바리오스는 기계 학습(ML) 분야의 과학적 혁신을 촉진하기 위해 확장 가능한 분산 시스템 및 자동화 도구에 중점을 두고 있는 AWS 전문 서비스의 기계 학습 엔지니어입니다. 또한 그는 기업 고객이 AWS 서비스를 통해 기계 학습 솔루션을 최적화하도록 지원합니다.
루이스 펠리페 예페스 바리오스는 기계 학습(ML) 분야의 과학적 혁신을 촉진하기 위해 확장 가능한 분산 시스템 및 자동화 도구에 중점을 두고 있는 AWS 전문 서비스의 기계 학습 엔지니어입니다. 또한 그는 기업 고객이 AWS 서비스를 통해 기계 학습 솔루션을 최적화하도록 지원합니다.
 진자오 펑는 AWS Professional Services의 기계 학습 엔지니어입니다. 그는 대규모 Generative AI 및 기존 ML 파이프라인 솔루션을 설계하고 구현하는 데 중점을 두고 있습니다. 그는 FMOps, LLMOps 및 분산 교육을 전문으로 합니다.
진자오 펑는 AWS Professional Services의 기계 학습 엔지니어입니다. 그는 대규모 Generative AI 및 기존 ML 파이프라인 솔루션을 설계하고 구현하는 데 중점을 두고 있습니다. 그는 FMOps, LLMOps 및 분산 교육을 전문으로 합니다.
 가혹한 아스나니는 AWS의 기계 학습 엔지니어입니다. 그의 배경은 응용 데이터 과학이며 클라우드에서 기계 학습 워크로드를 대규모로 운영하는 데 중점을 두고 있습니다.
가혹한 아스나니는 AWS의 기계 학습 엔지니어입니다. 그의 배경은 응용 데이터 과학이며 클라우드에서 기계 학습 워크로드를 대규모로 운영하는 데 중점을 두고 있습니다.
 하산 쇼재에이는 AWS Professional Services의 수석 데이터 과학자로서 다양한 산업 분야의 고객이 빅 데이터, 기계 학습 및 클라우드 기술을 사용하여 비즈니스 과제를 해결하도록 돕습니다. 이 직책을 맡기 전에 Hasan은 최고의 에너지 기업을 위한 새로운 물리학 기반 및 데이터 기반 모델링 기술을 개발하기 위한 여러 이니셔티브를 주도했습니다. 직장 밖에서 Hasan은 책, 하이킹, 사진, 역사에 열정을 쏟고 있습니다.
하산 쇼재에이는 AWS Professional Services의 수석 데이터 과학자로서 다양한 산업 분야의 고객이 빅 데이터, 기계 학습 및 클라우드 기술을 사용하여 비즈니스 과제를 해결하도록 돕습니다. 이 직책을 맡기 전에 Hasan은 최고의 에너지 기업을 위한 새로운 물리학 기반 및 데이터 기반 모델링 기술을 개발하기 위한 여러 이니셔티브를 주도했습니다. 직장 밖에서 Hasan은 책, 하이킹, 사진, 역사에 열정을 쏟고 있습니다.
 알렉 제납는 기업 고객을 위한 규모에 맞는 기계 학습 솔루션을 개발하고 운영하는 것을 전문으로 하는 기계 학습 엔지니어입니다. Alec은 특히 기계 학습이 최종 사용자 경험을 의미있게 향상시킬 수 있는 영역에서 혁신적인 솔루션을 시장에 출시하는 데 열정을 갖고 있습니다. 업무 외에 그는 농구, 스노보드를 즐기고 샌프란시스코의 숨겨진 보석을 찾는 것을 즐깁니다.
알렉 제납는 기업 고객을 위한 규모에 맞는 기계 학습 솔루션을 개발하고 운영하는 것을 전문으로 하는 기계 학습 엔지니어입니다. Alec은 특히 기계 학습이 최종 사용자 경험을 의미있게 향상시킬 수 있는 영역에서 혁신적인 솔루션을 시장에 출시하는 데 열정을 갖고 있습니다. 업무 외에 그는 농구, 스노보드를 즐기고 샌프란시스코의 숨겨진 보석을 찾는 것을 즐깁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

