Dies ist ein gemeinsamer Beitrag, der von mitgeschrieben wurde Leidos und AWS. Leidos ist ein führendes Unternehmen für Wissenschafts- und Technologielösungen im FORTUNE 500-Ranking, das daran arbeitet, einige der größten Herausforderungen der Welt in den Bereichen Verteidigung, Geheimdienste, innere Sicherheit, Zivil- und Gesundheitsmärkte anzugehen.
Leidos hat sich mit AWS zusammengetan, um einen Ansatz für die Wahrung der Privatsphäre, vertrauliches maschinelles Lernen (ML) zu entwickeln, bei dem Sie Cloud-fähige, verschlüsselte Pipelines erstellen.
Homomorphe Verschlüsselung ist ein neuer Verschlüsselungsansatz, der es ermöglicht, Berechnungen und Analysefunktionen auf verschlüsselten Daten auszuführen, ohne sie zuerst entschlüsseln zu müssen, um die Privatsphäre in Fällen zu wahren, in denen Sie eine Richtlinie haben, die besagt, dass Daten niemals entschlüsselt werden sollten. Vollständig homomorphe Verschlüsselung (FHE) ist die stärkste Idee dieser Art von Ansatz und ermöglicht es Ihnen, den Wert Ihrer Daten freizusetzen, wo Zero-Trust der Schlüssel ist. Die Kernanforderung besteht darin, dass die Daten durch Zahlen durch eine Codierungstechnik dargestellt werden können, die auf numerische, textuelle und bildbasierte Datensätze angewendet werden kann. Daten, die FHE verwenden, sind größer, daher müssen Tests für Anwendungen durchgeführt werden, bei denen die Inferenz nahezu in Echtzeit oder mit Größenbeschränkungen durchgeführt werden muss. Es ist auch wichtig, alle Berechnungen als lineare Gleichungen zu formulieren.
In diesem Beitrag zeigen wir, wie man datenschutzfreundliche ML-Vorhersagen für die am stärksten regulierten Umgebungen aktiviert. Die Vorhersagen (Inferenz) verwenden verschlüsselte Daten und die Ergebnisse werden nur vom Endverbraucher (Client-Seite) entschlüsselt.
Um dies zu demonstrieren, zeigen wir ein Beispiel für die Anpassung von an Amazon Sage Maker Scikit-learn, Open-Source-Deep-Learning-Container um es einem bereitgestellten Endpunkt zu ermöglichen, clientseitig verschlüsselte Inferenzanforderungen zu akzeptieren. Obwohl dieses Beispiel zeigt, wie dies für Inferenzoperationen durchgeführt wird, können Sie die Lösung auf das Training und andere ML-Schritte erweitern.
Endpunkte werden mit ein paar Klicks oder Codezeilen mit SageMaker bereitgestellt, was den Prozess für Entwickler und ML-Experten zum Erstellen und Trainieren von ML- und Deep-Learning-Modellen in der Cloud vereinfacht. Modelle, die mit SageMaker erstellt wurden, können dann als bereitgestellt werden Echtzeit-Endpunkte, was für Inferenz-Workloads entscheidend ist, bei denen Sie Anforderungen in Echtzeit, im stabilen Zustand und mit geringer Latenz haben. Anwendungen und Dienste können den bereitgestellten Endpunkt direkt oder über einen bereitgestellten Serverless aufrufen Amazon API-Gateway die Architektur. Weitere Informationen zu Best Practices für die Echtzeit-Endpunktarchitektur finden Sie unter Erstellen einer maschinell lernbasierten REST-API mit Amazon API Gateway-Zuordnungsvorlagen und Amazon SageMaker. Die folgende Abbildung zeigt beide Versionen dieser Muster.
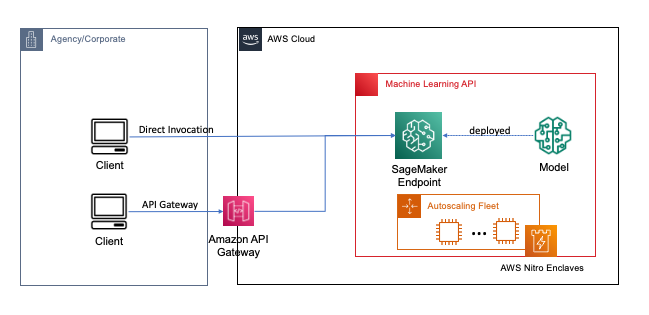
Bei beiden Mustern sorgt die Verschlüsselung während der Übertragung für Vertraulichkeit, während die Daten durch die Dienste fließen, um die Inferenzoperation durchzuführen. Beim Empfang durch den SageMaker-Endpunkt werden die Daten im Allgemeinen entschlüsselt, um die Inferenzoperation zur Laufzeit auszuführen, und sind für keinen externen Code und Prozesse zugänglich. Um zusätzliche Schutzebenen zu erreichen, ermöglicht FHE der Inferenzoperation, verschlüsselte Ergebnisse zu generieren, deren Ergebnisse von einer vertrauenswürdigen Anwendung oder einem vertrauenswürdigen Client entschlüsselt werden können.
Mehr zur vollständig homomorphen Verschlüsselung
FHE ermöglicht es Systemen, Berechnungen mit verschlüsselten Daten durchzuführen. Die resultierenden Berechnungen sind, wenn sie entschlüsselt sind, kontrollierbar nahe an jenen, die ohne den Verschlüsselungsprozess erzeugt werden. FHE kann zu einer kleinen mathematischen Ungenauigkeit führen, ähnlich einem Fließkommafehler, aufgrund von Rauschen, das in die Berechnung eingespeist wird. Sie wird durch die Auswahl geeigneter FHE-Verschlüsselungsparameter gesteuert, bei denen es sich um einen problemspezifischen, abgestimmten Parameter handelt. Weitere Informationen finden Sie im Video Wie würden Sie die homomorphe Verschlüsselung erklären?
Das folgende Diagramm zeigt eine beispielhafte Implementierung eines FHE-Systems.
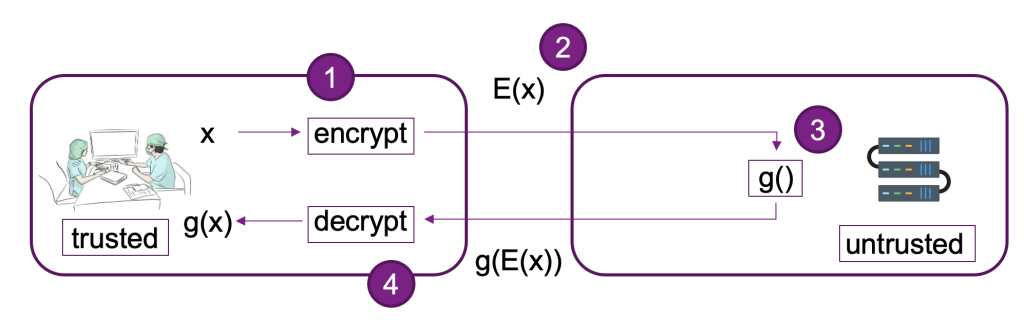
In diesem System können Sie oder Ihr vertrauenswürdiger Kunde Folgendes tun:
- Verschlüsseln Sie die Daten mit einem FHE-Schema mit öffentlichem Schlüssel. Es gibt ein paar verschiedene akzeptable Schemata; In diesem Beispiel verwenden wir das CKKS-Schema. Um mehr über das von uns gewählte FHE-Public-Key-Verschlüsselungsverfahren zu erfahren, beziehen Sie sich auf CKKS erklärt.
- Senden Sie clientseitig verschlüsselte Daten zur Verarbeitung an einen Anbieter oder Server.
- Modellrückschluss auf verschlüsselten Daten durchführen; mit FHE ist keine Entschlüsselung erforderlich.
- Verschlüsselte Ergebnisse werden an den Aufrufer zurückgegeben und dann entschlüsselt, um Ihr Ergebnis mit einem privaten Schlüssel anzuzeigen, der nur Ihnen oder Ihren vertrauenswürdigen Benutzern innerhalb des Clients zur Verfügung steht.
Wir haben die vorhergehende Architektur verwendet, um ein Beispiel mit SageMaker-Endpunkten einzurichten, Pyfhel als FHE-API-Wrapper, der die Integration mit ML-Anwendungen vereinfacht, und SEAL als unser zugrundeliegendes FHE-Verschlüsselungs-Toolkit.
Lösungsüberblick
Wir haben ein Beispiel für eine skalierbare FHE-Pipeline in AWS mit einer erstellt SKLearn logistische Regression Deep-Learning-Container mit der Iris-Datensatz. Wir führen Datenexploration und Feature-Engineering mit einem SageMaker-Notebook durch und führen dann Modelltraining mit a durch SageMaker-Ausbildungsjob. Das resultierende Modell ist Einsatz an einen SageMaker-Echtzeit-Endpunkt zur Verwendung durch Client-Services, wie im folgenden Diagramm dargestellt.

In dieser Architektur sieht nur die Clientanwendung unverschlüsselte Daten. Die durch das Modell für die Inferenz verarbeiteten Daten bleiben während ihres gesamten Lebenszyklus verschlüsselt, selbst zur Laufzeit innerhalb des isolierten Prozessors AWS Nitro-Enklave. In den folgenden Abschnitten gehen wir den Code zum Erstellen dieser Pipeline durch.
Voraussetzungen:
Um mitzumachen, gehen wir davon aus, dass Sie a gestartet haben SageMaker-Notizbuch sowie einem AWS Identity and Access Management and (IAM) Rolle mit der AmazonSageMakerFullAccess verwaltete Richtlinie.
Trainiere das Modell
Das folgende Diagramm veranschaulicht den Modelltrainingsworkflow.
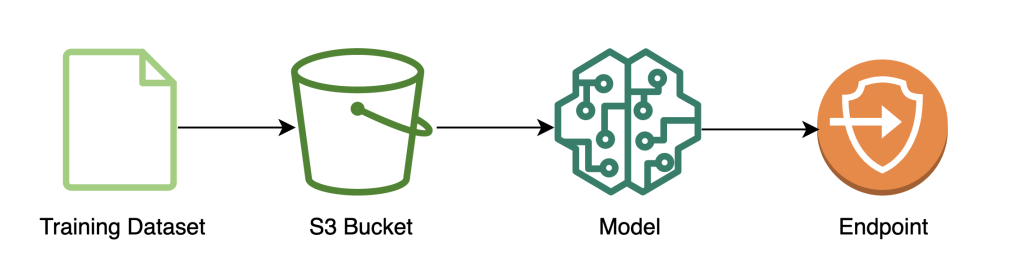
Der folgende Code zeigt, wie wir zunächst die Daten für das Training mit SageMaker-Notebooks vorbereiten, indem wir unser Trainingsdataset abrufen, die erforderlichen Bereinigungsvorgänge durchführen und die Daten dann in eine Amazon Simple Storage-Service (Amazon S3) Eimer. In dieser Phase müssen Sie möglicherweise auch zusätzliches Feature-Engineering Ihres Datasets durchführen oder es in verschiedene Offline-Feature-Stores integrieren.
In diesem Beispiel verwenden wir Skript-Modus auf einem nativ unterstützten Framework in SageMaker (scikit-lernen), wo wir unseren standardmäßigen SageMaker-SKLearn-Estimator mit einem benutzerdefinierten Trainingsskript instanziieren, um die verschlüsselten Daten während der Inferenz zu verarbeiten. Weitere Informationen zu nativ unterstützten Frameworks und dem Skriptmodus finden Sie unter Verwenden Sie Machine Learning Frameworks, Python und R mit Amazon SageMaker.
Schließlich trainieren wir unser Modell mit dem Dataset und stellen unser trainiertes Modell für den Instance-Typ unserer Wahl bereit.
An diesem Punkt haben wir ein benutzerdefiniertes SKLearn-FHE-Modell trainiert und es auf einem SageMaker-Echtzeit-Inferenzendpunkt bereitgestellt, der bereit ist, verschlüsselte Daten zu akzeptieren.
Kundendaten verschlüsseln und versenden
Das folgende Diagramm veranschaulicht den Workflow zum Verschlüsseln und Senden von Clientdaten an das Modell.
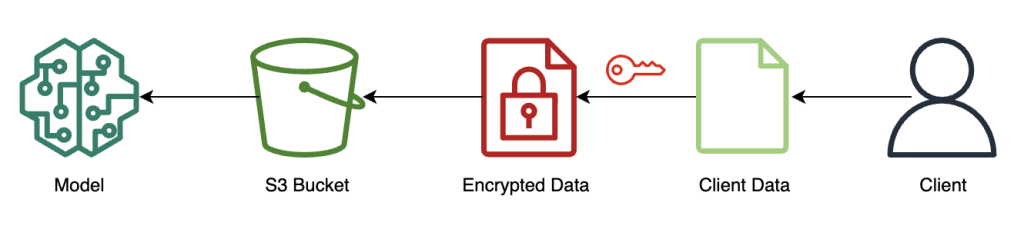
In den meisten Fällen enthält die Nutzlast des Aufrufs an den Inferenzendpunkt die verschlüsselten Daten, anstatt sie zuerst in Amazon S3 zu speichern. Wir tun dies in diesem Beispiel, weil wir eine große Anzahl von Datensätzen für den Inferenzaufruf zusammengefasst haben. In der Praxis ist diese Stapelgröße kleiner oder es wird stattdessen eine Stapeltransformation verwendet. Die Verwendung von Amazon S3 als Vermittler ist für FHE nicht erforderlich.
Nachdem der Inferenzendpunkt eingerichtet wurde, können wir mit dem Senden von Daten beginnen. Normalerweise verwenden wir unterschiedliche Test- und Trainingsdatensätze, aber für dieses Beispiel verwenden wir denselben Trainingsdatensatz.
Zuerst laden wir den Iris-Datensatz auf der Client-Seite. Als Nächstes richten wir den FHE-Kontext mit Pyfhel ein. Wir haben Pyfhel für diesen Prozess ausgewählt, weil es einfach zu installieren und damit zu arbeiten ist, beliebte FHE-Schemata enthält und auf einer vertrauenswürdigen zugrunde liegenden Open-Source-Verschlüsselungsimplementierung beruht SEAL. In diesem Beispiel senden wir die verschlüsselten Daten zusammen mit Informationen zu öffentlichen Schlüsseln für dieses FHE-Schema an den Server, der es dem Endpunkt ermöglicht, das Ergebnis zu verschlüsseln, um es seinerseits mit den erforderlichen FHE-Parametern zu senden, gibt ihm dies jedoch nicht Fähigkeit, die eingehenden Daten zu entschlüsseln. Der private Schlüssel verbleibt nur beim Client, der die Möglichkeit hat, die Ergebnisse zu entschlüsseln.
Nachdem wir unsere Daten verschlüsselt haben, stellen wir ein vollständiges Datenwörterbuch zusammen – einschließlich der relevanten Schlüssel und verschlüsselten Daten – das auf Amazon S3 gespeichert wird. Anschließend macht das Modell seine Vorhersagen über die verschlüsselten Daten des Clients, wie im folgenden Code gezeigt. Beachten Sie, dass wir den privaten Schlüssel nicht übertragen, sodass der Modellhost die Daten nicht entschlüsseln kann. In diesem Beispiel übergeben wir die Daten als S3-Objekt; alternativ können diese Daten direkt an den Sagemaker-Endpunkt gesendet werden. Als Echtzeit-Endpunkt enthält die Nutzlast den Datenparameter im Body der Anfrage, der in der erwähnt wird SageMaker-Dokumentation.
Der folgende Screenshot zeigt die zentrale Vorhersage darin fhe_train.py (Der Anhang zeigt das gesamte Trainingsskript).
Wir berechnen die Ergebnisse unserer verschlüsselten logistischen Regression. Dieser Code berechnet ein verschlüsseltes Skalarprodukt für jede mögliche Klasse und gibt die Ergebnisse an den Client zurück. Die Ergebnisse sind die vorhergesagten Logits für jede Klasse über alle Beispiele hinweg.
Der Client gibt entschlüsselte Ergebnisse zurück
Das folgende Diagramm veranschaulicht den Workflow des Clients, der sein verschlüsseltes Ergebnis abruft und es entschlüsselt (mit dem privaten Schlüssel, auf den nur er Zugriff hat), um das Inferenzergebnis anzuzeigen.

In diesem Beispiel werden Ergebnisse auf Amazon S3 gespeichert, aber im Allgemeinen würden diese über die Nutzlast des Echtzeit-Endpunkts zurückgegeben. Die Verwendung von Amazon S3 als Vermittler ist für FHE nicht erforderlich.
Das Inferenzergebnis wird kontrollierbar nahe an den Ergebnissen liegen, als ob sie es selbst berechnet hätten, ohne FHE zu verwenden.
Aufräumen
Wir beenden diesen Vorgang, indem wir den von uns erstellten Endpunkt löschen, um sicherzustellen, dass nach diesem Vorgang keine ungenutzten Rechenvorgänge vorhanden sind.
Ergebnisse und Überlegungen
Einer der häufigsten Nachteile bei der Verwendung von FHE auf Modellen besteht darin, dass es Rechenaufwand hinzufügt, wodurch das resultierende Modell – in der Praxis – für interaktive Anwendungsfälle zu langsam wird. Aber in Fällen, in denen die Daten hochsensibel sind, kann es sich lohnen, diesen Latenz-Kompromiss in Kauf zu nehmen. Für unsere einfache logistische Regression sind wir jedoch in der Lage, 140 Eingabedatenproben innerhalb von 60 Sekunden zu verarbeiten und eine lineare Leistung zu sehen. Das folgende Diagramm enthält die gesamte End-to-End-Zeit, einschließlich der Zeit, die der Client benötigt, um die Eingabe zu verschlüsseln und die Ergebnisse zu entschlüsseln. Es verwendet auch Amazon S3, das Latenz hinzufügt und für diese Fälle nicht erforderlich ist.

Wir sehen eine lineare Skalierung, wenn wir die Anzahl der Beispiele von 1 auf 150 erhöhen. Dies ist zu erwarten, da jedes Beispiel unabhängig voneinander verschlüsselt wird, sodass wir eine lineare Erhöhung der Berechnung mit festen Einrichtungskosten erwarten.
Das bedeutet auch, dass Sie Ihre Inferenzflotte horizontal skalieren können, um einen höheren Anforderungsdurchsatz hinter Ihrem SageMaker-Endpunkt zu erzielen. Sie können verwenden Amazon SageMaker Inference Recommender zur Kostenoptimierung Ihrer Flotte entsprechend Ihren geschäftlichen Anforderungen.
Zusammenfassung
Und da haben Sie es: vollständig homomorphe ML-Verschlüsselung für ein logistisches SKLearn-Regressionsmodell, das Sie mit wenigen Codezeilen einrichten können. Mit einigen Anpassungen können Sie denselben Verschlüsselungsprozess unabhängig von den Trainingsdaten für verschiedene Modelltypen und Frameworks implementieren.
Wenn Sie mehr über den Aufbau einer ML-Lösung mit homomorpher Verschlüsselung erfahren möchten, wenden Sie sich an Ihr AWS-Kontoteam oder Ihren Partner Leidos, um mehr zu erfahren. Weitere Beispiele finden Sie auch in den folgenden Ressourcen:
Der Inhalt und die Meinungen in diesem Beitrag enthalten die von Drittautoren, und AWS ist nicht verantwortlich für den Inhalt oder die Genauigkeit dieses Beitrags.
Anhang
Das vollständige Trainingsskript lautet wie folgt:
Über die Autoren
Liv d'Aliberti ist Forscher im Leidos AI/ML Accelerator im Office of Technology. Ihre Forschung konzentriert sich auf maschinelles Lernen unter Wahrung der Privatsphäre.
Manbir Gulati ist Forscher im Leidos AI/ML Accelerator im Office of Technology. Seine Forschung konzentriert sich auf die Schnittstelle zwischen Cybersicherheit und neuen KI-Bedrohungen.
Joe Kovba ist Cloud Center of Excellence Practice Lead innerhalb des Leidos Digital Modernization Accelerator unter dem Office of Technology. In seiner Freizeit leitet er gerne Fußballspiele und spielt Softball.
Ben Snively ist ein Spezialist für Lösungen im öffentlichen Sektor. Er arbeitet mit Behörden, gemeinnützigen Organisationen und Bildungseinrichtungen an Big-Data- und Analyseprojekten und hilft ihnen, Lösungen mit AWS zu entwickeln. In seiner Freizeit fügt er IoT-Sensoren im ganzen Haus hinzu und führt Analysen mit ihnen durch.
Sami Hoda ist Senior Solutions Architect im Bereich Partners Consulting, der den weltweiten öffentlichen Sektor abdeckt. Sami ist leidenschaftlich an Projekten interessiert, bei denen Design Thinking, Innovation und emotionale Intelligenz zu gleichen Teilen eingesetzt werden können, um Probleme für Menschen in Not zu lösen und sie zu beeinflussen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/enable-fully-homomorphic-encryption-with-amazon-sagemaker-endpoints-for-secure-real-time-inferencing/

