이것은 NXP SEMICONDUCTORS NV와 AWS Machine Learning Solutions Lab(MLSL)의 공동 게시물입니다.
기계 학습(ML)은 프로세스를 간소화하고 수익 창출을 개선하기 위해 데이터에서 실행 가능한 통찰력을 추출하기 위해 광범위한 산업에서 사용되고 있습니다. 이 게시물에서는 반도체 부문의 업계 리더인 NXP가 어떻게 협력했는지 보여줍니다. AWS 기계 학습 솔루션 랩 (MLSL) ML 기술을 사용하여 NXP 연구 개발(R&D) 예산을 투자하여 장기 투자 수익(ROI)을 극대화합니다.
NXP는 상당한 성장 기회가 있는 새로운 반도체 솔루션 개발에 R&D 노력을 집중하고 있습니다. 시장 성장을 앞지르기 위해 NXP는 빠르게 성장하는 상당한 규모의 시장 부문에 중점을 두고 선도적인 시장 위치를 확장하거나 창출하기 위해 연구 개발에 투자합니다. 이 계약을 위해 그들은 다양한 재료 그룹과 비즈니스 라인에 걸쳐 신규 및 기존 제품에 대한 월별 판매 예측을 생성하려고 했습니다. 이 게시물에서는 MLSL 및 NXP가 어떻게 사용되었는지 보여줍니다. 아마존 예측 다양한 NXP 제품의 장기 판매 예측을 위한 기타 맞춤형 모델.
“우리는 [the] Amazon Machine Learning Solutions Lab의 과학자 및 전문가 팀과 협력하여 신제품 판매를 예측하는 솔루션을 구축하고 R&D 지출을 최적화하기 위한 [] 의사 결정 프로세스에 정보를 제공할 수 있는 추가 기능을 이해했습니다. 단 몇 주 만에 팀은 일부 비즈니스 라인, 재료 그룹 및 개별 제품 수준에서 여러 솔루션과 분석을 제공했습니다. MLSL은 현재의 수동 예측 방식을 보완하는 판매 예측 모델을 제공하고 Amazon Forecast 및 Amazon SageMaker를 사용하여 새로운 기계 학습 접근 방식으로 제품 수명 주기를 모델링하는 데 도움을 주었습니다. MLSL은 우리 팀과 지속적으로 협업하는 작업 흐름을 유지하면서 AWS 인프라를 사용한 ML 개발에 대한 과학적 우수성과 모범 사례와 관련하여 우리 전문가의 기술을 향상시키는 데 도움이 되었습니다.”
– Bart Zeeman, NXP Semiconductors CTO 사무실의 전략가 겸 분석가.
목표 및 사용 사례
NXP와 MLSL 팀 간의 계약 목표는 다양한 최종 시장에서 NXP의 전체 판매를 예측하는 것입니다. 일반적으로 NXP 팀은 여러 MAG(재료 그룹)를 포함하는 다양한 비즈니스 라인(BL)의 판매를 포함하는 거시적 수준의 판매에 관심이 있습니다. 또한 NXP 팀은 새로 출시되는 제품의 제품 수명 주기를 예측하는 데에도 관심이 있습니다. 제품의 라이프사이클은 네 가지 단계(도입기, 성장기, 성숙기, 쇠퇴기)로 나뉩니다. 제품 수명 주기 예측을 통해 NXP 팀은 각 제품에서 생성된 수익을 식별하여 R&D 활동에 대한 ROI를 극대화할 수 있는 가장 높은 매출 또는 잠재력이 가장 높은 제품에 R&D 자금을 추가로 할당할 수 있습니다. 또한 미시적 수준에서 장기 판매를 예측할 수 있으므로 시간이 지남에 따라 수익이 어떻게 변하는지 상향식으로 볼 수 있습니다.
다음 섹션에서는 장기 판매 예측을 위한 강력하고 효율적인 모델 개발과 관련된 주요 과제를 제시합니다. 원하는 정확도를 달성하기 위해 사용되는 다양한 모델링 기술의 이면에 있는 직관에 대해 자세히 설명합니다. 그런 다음 최종 모델에 대한 평가를 제시하고 NXP의 시장 전문가와 판매 예측 측면에서 제안된 모델의 성능을 비교합니다. 또한 최첨단 포인트 클라우드 기반 제품 수명 주기 예측 알고리즘의 성능을 시연합니다.
도전
판매 예측을 위해 제품 수준 모델과 같은 세분화된 또는 마이크로 수준 모델링을 사용하는 동안 직면한 문제 중 하나는 판매 데이터가 누락되었다는 것입니다. 누락된 데이터는 매월 매출이 부족한 결과입니다. 마찬가지로 거시적 수준의 판매 예측의 경우 과거 판매 데이터의 길이가 제한되었습니다. 누락된 판매 데이터와 제한된 길이의 과거 판매 데이터는 2026년까지의 장기 판매 예측을 위한 모델 정확도 측면에서 상당한 문제를 제기합니다. 우리는 탐색적 데이터 분석(EDA) 중에 마이크로 수준 판매에서 ( 제품 수준)에서 거시 수준 판매(BL 수준)로 변경하면 결측값의 중요성이 낮아집니다. 그러나 과거 판매 데이터의 최대 길이(최대 길이 140개월)는 모델 정확도 측면에서 여전히 상당한 문제를 제기했습니다.
모델링 기법
EDA 이후에는 BL 및 MAG 수준과 NXP의 가장 큰 최종 시장 중 하나(자동차 최종 시장)에 대한 제품 수준 예측에 집중했습니다. 그러나 우리가 개발한 솔루션은 다른 최종 시장으로 확장될 수 있습니다. BL, MAG 또는 제품 수준의 모델링에는 모델 성능 및 데이터 가용성 측면에서 장단점이 있습니다. 다음 표는 이러한 각 수준의 장단점을 요약한 것입니다. 거시적 수준의 판매 예측을 위해 최종 솔루션으로 Amazon Forecast AutoPredictor를 사용했습니다. 마찬가지로 미시적 수준의 판매 예측을 위해 새로운 포인트 클라우드 기반 접근 방식을 개발했습니다.

매크로 판매 예측(하향식)
거시적 수준에서 장기 판매 가치(2026년)를 예측하기 위해 Amazon Forecast, GluonTS 및 N-BEATS(GluonTS 및 PyTorch에서 구현됨)를 포함한 다양한 방법을 테스트했습니다. 전반적으로 Forecast는 거시적 수준의 판매 예측을 위해 백테스팅 접근 방식(이 게시물 뒷부분의 평가 메트릭 섹션에서 설명)을 기반으로 하는 다른 모든 방법보다 성능이 뛰어났습니다. 또한 AutoPredictor의 정확도를 사람의 예측과 비교했습니다.
또한 N-BEATS의 해석적 특성으로 인해 사용을 제안했습니다. N-BEATS는 예측을 위해 누적된 잔차 블록이 있는 잔차 연결을 사용하는 피드포워드 네트워크의 앙상블을 사용하는 매우 단순하지만 강력한 아키텍처를 기반으로 합니다. 이 아키텍처는 시계열 모델이 추세와 계절성을 추출할 수 있도록 아키텍처의 귀납적 편향을 추가로 인코딩합니다(다음 그림 참조). 이러한 해석은 PyTorch Forecasting을 사용하여 생성되었습니다.

마이크로 판매 예측(상향식)
이 섹션에서는 콜드 스타트 제품을 고려하면서 다음 그림과 같은 제품 수명 주기를 예측하기 위해 개발된 새로운 방법에 대해 설명합니다. 우리는 PyTorch를 사용하여 이 방법을 구현했습니다. 아마존 세이지 메이커 스튜디오. 먼저 포인트 클라우드 기반 방식을 도입했습니다. 이 방법은 먼저 판매 데이터를 포인트 클라우드로 변환합니다. 여기서 각 포인트는 제품의 특정 연령에서의 판매 데이터를 나타냅니다. 포인트 클라우드 기반 신경망 모델은 이 데이터를 사용하여 추가로 제품 수명 주기 곡선의 매개변수를 학습합니다(다음 그림 참조). 이 접근 방식에서는 제품 수명 주기 곡선을 예측하기 위해 콜드 스타트 문제를 해결하기 위한 단어 모음으로 제품 설명을 포함하여 추가 기능을 통합했습니다.

포인트 클라우드 기반 제품 수명 주기 예측으로서의 시계열
우리는 제품 수명 주기 및 미시적 수준의 판매 예측을 예측하기 위해 새로운 포인트 클라우드 기반 접근 방식을 개발했습니다. 또한 콜드 스타트 제품 수명 주기 예측을 위한 모델 정확도를 더욱 향상시키기 위해 추가 기능을 통합했습니다. 이러한 기능에는 제품 제조 기술 및 제품과 관련된 기타 관련 범주 정보가 포함됩니다. 이러한 추가 데이터는 모델이 제품이 시장에 출시되기 전에(콜드 스타트) 신제품의 판매를 예측하는 데 도움이 될 수 있습니다. 다음 그림은 포인트 클라우드 기반 접근 방식을 보여줍니다. 이 모델은 정규화된 제품 판매 및 제품 수명(제품 출시 이후 개월 수)을 입력으로 사용합니다. 이러한 입력을 기반으로 모델은 경사 하강법을 사용하여 훈련 중에 매개변수를 학습합니다. 예측 단계에서는 콜드 스타트 제품의 기능과 함께 매개변수를 사용하여 수명 주기를 예측합니다. 제품 수준에서 데이터의 많은 누락된 값은 거의 모든 기존 시계열 모델에 부정적인 영향을 미칩니다. 이 새로운 솔루션은 누락된 값을 완화하기 위해 수명 주기 모델링 및 시계열 데이터를 포인트 클라우드로 취급하는 아이디어를 기반으로 합니다.
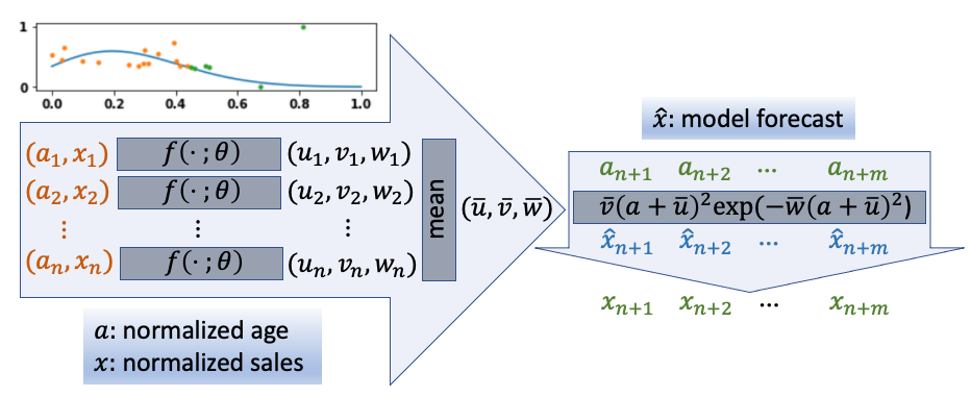
다음 그림은 포인트 클라우드 기반 수명 주기 방법이 누락된 데이터 값을 처리하고 극소수의 교육 샘플로 제품 수명 주기를 예측할 수 있는 방법을 보여줍니다. X축은 시대를 나타내고 Y축은 제품의 판매량을 나타냅니다. 주황색 점은 훈련 샘플을 나타내고, 녹색 점은 테스트 샘플을 나타내며, 파란색 선은 모델에서 예측한 제품 수명 주기를 나타냅니다.

방법론
거시적 수준의 판매를 예측하기 위해 우리는 다른 기술 중에서 Amazon Forecast를 사용했습니다. 마찬가지로 소규모 판매를 위해 최첨단 포인트 클라우드 기반 사용자 지정 모델을 개발했습니다. Forecast는 모델 성능 측면에서 다른 모든 방법보다 성능이 뛰어났습니다. Amazon SageMaker 노트북 인스턴스를 사용하여 Amazon Simple Storage Service(Amazon S3)에서 교육 예제를 추출하는 데이터 처리 파이프라인을 생성했습니다. 훈련 데이터는 모델을 훈련하고 장기 판매를 예측하기 위한 Forecast의 입력으로 추가로 사용되었습니다.
Amazon Forecast를 사용하여 시계열 모델을 교육하는 것은 세 가지 주요 단계로 구성됩니다. 첫 번째 단계에서는 과거 데이터를 Amazon S3로 가져왔습니다. 둘째, 과거 데이터를 사용하여 예측기를 훈련했습니다. 마지막으로 훈련된 예측기를 배포하여 예측을 생성했습니다. 이 섹션에서는 각 단계의 코드 스니펫과 함께 자세한 설명을 제공합니다.
최신 판매 데이터를 추출하는 것부터 시작했습니다. 이 단계에는 데이터 세트를 올바른 형식으로 Amazon S3에 업로드하는 작업이 포함되었습니다. Amazon Forecast는 타임스탬프, item_id 및 target_value(판매 데이터)의 세 열을 입력으로 사용합니다. 타임스탬프 열에는 매시간, 매일 등의 형식이 될 수 있는 판매 시간이 포함됩니다. item_id 열에는 판매된 항목의 이름이 포함되고 target_value 열에는 판매 값이 포함됩니다. 다음으로 Amazon S3에 있는 훈련 데이터의 경로를 사용하고, 시계열 데이터 세트 빈도(H, D, W, M, Y)를 정의하고, 데이터 세트 이름을 정의하고, 데이터 세트의 속성을 식별했습니다(각 열은 데이터 세트 및 해당 데이터 유형). 다음으로 Boto3 API에서 create_dataset 함수를 호출하여 Domain, DatasetType, DatasetName, DatasetFrequency 및 Schema와 같은 속성이 있는 데이터 세트를 생성했습니다. 이 함수는 ARN(Amazon 리소스 이름)이 포함된 JSON 객체를 반환했습니다. 이 ARN은 이후 다음 단계에서 사용되었습니다. 다음 코드를 참조하십시오.
dataset_path = "PATH_OF_DATASET_IN_S3"
DATASET_FREQUENCY = "M" # Frequency of dataset (H, D, W, M, Y) TS_DATASET_NAME = "NAME_OF_THE_DATASET"
TS_SCHEMA = { "Attributes":[ { "AttributeName":"item_id", "AttributeType":"string" }, { "AttributeName":"timestamp", "AttributeType":"timestamp" }, { "AttributeName":"target_value", "AttributeType":"float" } ]
} create_dataset_response = forecast.create_dataset(Domain="CUSTOM", DatasetType='TARGET_TIME_SERIES', DatasetName=TS_DATASET_NAME, DataFrequency=DATASET_FREQUENCY, Schema=TS_SCHEMA) ts_dataset_arn = create_dataset_response['DatasetArn']데이터 세트가 생성된 후 Boto3를 사용하여 Amazon Forecast로 가져왔습니다. create_dataset_import_job 함수. 그만큼 create_dataset_import_job 함수는 작업 이름(문자열 값), 이전 단계에서 데이터 세트의 ARN, 이전 단계에서 Amazon S3의 교육 데이터 위치 및 타임스탬프 형식을 인수로 사용합니다. 가져오기 작업 ARN이 포함된 JSON 객체를 반환합니다. 다음 코드를 참조하십시오.
TIMESTAMP_FORMAT = "yyyy-MM-dd"
TS_IMPORT_JOB_NAME = "SALES_DATA_IMPORT_JOB_NAME" ts_dataset_import_job_response = forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME, DatasetArn=ts_dataset_arn, DataSource= { "S3Config" : { "Path": ts_s3_path, "RoleArn": role_arn } }, TimestampFormat=TIMESTAMP_FORMAT, TimeZone = TIMEZONE) ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']가져온 데이터세트는 create_dataset_group 함수를 사용하여 데이터세트 그룹을 만드는 데 사용되었습니다. 이 함수는 도메인(예측 도메인을 정의하는 문자열 값), 데이터 세트 그룹 이름 및 데이터 세트 ARN을 입력으로 사용합니다.
DATASET_GROUP_NAME = "SALES_DATA_GROUP_NAME"
DATASET_ARNS = [ts_dataset_arn] create_dataset_group_response = forecast.create_dataset_group(Domain="CUSTOM", DatasetGroupName=DATASET_GROUP_NAME, DatasetArns=DATASET_ARNS) dataset_group_arn = create_dataset_group_response['DatasetGroupArn']
다음으로 데이터 세트 그룹을 사용하여 예측 모델을 교육했습니다. Amazon Forecast는 다양한 최신 모델을 제공합니다. 이러한 모델은 학습에 사용할 수 있습니다. AutoPredictor를 기본 모델로 사용했습니다. AutoPredictor 사용의 주요 이점은 입력 데이터 세트를 기반으로 3개의 최신 모델 앙상블에서 최적의 모델을 사용하여 항목 수준 예측을 자동으로 생성한다는 것입니다. BotoXNUMX API는 다음을 제공합니다. create_auto_predictor 자동 예측 모델 훈련을 위한 함수. 이 함수의 입력 매개변수는 다음과 같습니다. 예측자 이름, 예보지평선및 예측빈도. 또한 사용자는 예측 범위와 빈도를 선택해야 합니다. 예측 기간은 미래 예측의 창 크기를 나타내며 시간, 일, 주, 월 등의 형식을 지정할 수 있습니다. 마찬가지로 예측 빈도는 매시간, 매일, 매주, 매월 또는 매년과 같은 예측 값의 세분성을 나타냅니다. 주로 다양한 BL에서 NXP의 월 매출을 예측하는 데 중점을 두었습니다. 다음 코드를 참조하십시오.
PREDICTOR_NAME = "SALES_PREDICTOR"
FORECAST_HORIZON = 24
FORECAST_FREQUENCY = "M" create_auto_predictor_response = forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME, ForecastHorizon = FORECAST_HORIZON, ForecastFrequency = FORECAST_FREQUENCY, DataConfig = { 'DatasetGroupArn': dataset_group_arn }) predictor_arn = create_auto_predictor_response['PredictorArn']그런 다음 훈련된 예측자를 사용하여 예측 값을 생성했습니다. 예측은 다음을 사용하여 생성되었습니다. create_forecast 이전에 훈련된 예측자의 기능. 이 함수는 예측의 이름과 예측 변수의 ARN을 입력으로 사용하고 예측 변수에 정의된 범위 및 빈도에 대한 예측 값을 생성합니다.
FORECAST_NAME = "SALES_FORECAST" create_forecast_response = forecast.create_forecast(ForecastName=FORECAST_NAME, PredictorArn=predictor_arn)Amazon Forecast는 학습 및 테스트 데이터 세트를 자동으로 생성하고 모델 생성 예측의 신뢰성을 평가하기 위한 다양한 정확도 지표를 제공하는 완전 관리형 서비스입니다. 그러나 예측 데이터에 대한 합의를 구축하고 예측 값을 사람의 예측과 비교하기 위해 과거 데이터를 훈련 데이터와 검증 데이터로 수동으로 나누었습니다. 검증 데이터에 모델을 노출하지 않고 훈련 데이터를 사용하여 모델을 훈련하고 검증 데이터의 길이에 대한 예측을 생성했습니다. 검증 데이터를 예측값과 비교하여 모델 성능을 평가했습니다. 유효성 검사 메트릭에는 MAPE(평균 절대 백분율 오류) 및 WAPE(가중 절대 백분율 오류) 등이 포함될 수 있습니다. 다음 섹션에서 설명하는 대로 WAPE를 정확도 메트릭으로 사용했습니다.
평가 지표
먼저 장기 판매 예측(2026년 판매)에 대한 예측 모델의 예측을 검증하기 위해 백테스팅을 사용하여 모델 성능을 검증했습니다. WAPE를 사용하여 모델 성능을 평가했습니다. WAPE 값이 낮을수록 더 나은 모델입니다. MAPE와 같은 다른 오류 메트릭에 비해 WAPE를 사용하는 주요 이점은 WAPE가 각 품목 판매의 개별 영향을 평가한다는 것입니다. 따라서 전체 오차를 계산하면서 각 제품의 총 판매 기여도를 설명합니다. 예를 들어, 2천만 달러를 벌어들이는 제품에서 30%의 오류를 범하고 10달러를 벌어들이는 제품에서 50,000%의 오류를 범하면 MAPE는 전체 이야기를 말하지 않습니다. 2% 오류는 MAPE를 사용하여 알 수 없는 10% 오류보다 실제로 더 많은 비용이 듭니다. 상대적으로 WAPE는 이러한 차이를 설명합니다. 또한 모델 예측의 상한 및 하한을 나타내기 위해 판매에 대한 다양한 백분위수 값을 예측했습니다.
거시적 수준의 판매 예측 모델 검증
다음으로 WAPE 값 측면에서 모델 성능을 검증했습니다. 데이터를 테스트 및 검증 세트로 분할하여 모델의 WAPE 값을 계산했습니다. 예를 들어 2019년 WAPE 값에서 2011~2018년 사이의 판매 데이터와 향후 12개월(2019년 판매)의 예상 판매 값을 사용하여 모델을 교육했습니다. 다음으로 다음 공식을 사용하여 WAPE 값을 계산했습니다.

2020년과 2021년의 WAPE 값을 계산하기 위해 동일한 절차를 반복했습니다. 2019년, 2020년, 2021년 자동 최종 시장의 모든 BL에 대한 WAPE를 평가했습니다. 전반적으로 Amazon Forecast는 0.33년(COVID-2020 팬데믹 기간). 19년과 2019년에 우리 모델은 2020 미만의 WAPE 값을 달성하여 높은 정확도를 입증했습니다.
거시적 수준의 판매 예측 기준선 비교
2019년, 2020년 및 2021년 WAPE 값 측면에서 Amazon Forecast를 사용하여 개발한 거시적 판매 예측 모델의 성과를 세 가지 기본 모델과 비교했습니다(다음 그림 참조). Amazon Forecast는 다른 기준 모델보다 훨씬 뛰어난 성능을 보였거나 3년 내내 동일한 성능을 보였습니다. 이러한 결과는 최종 모델 예측의 효율성을 더욱 검증합니다.

거시적 수준의 판매 예측 모델과 사람의 예측
매크로 수준 모델의 신뢰도를 더욱 검증하기 위해 다음으로 모델의 성능을 사람이 예측한 판매 가치와 비교했습니다. 매년 2019분기 초 NXP의 시장 전문가들은 글로벌 시장 동향과 NXP 제품 판매에 잠재적으로 영향을 미칠 수 있는 기타 글로벌 지표를 고려하여 각 BL의 판매 가치를 예측합니다. 2020년, 2021년, 2011년의 실제 판매 가치와 모델 예측 대 인간 예측의 백분율 오류를 비교합니다. 2018~2021년의 데이터를 사용하여 2018개의 모델을 교육하고 1년까지의 판매 가치를 예측했습니다. 다음에 대한 MAPE를 계산했습니다. 실제 판매 가치. 그런 다음 3년 말까지 사람이 예측한 값을 사용했습니다(2019Y 앞 예측에서 1Y 앞 예측 예측 모델 테스트). 우리는 이 과정을 반복하여 2년(2020Y 전방 예측에서 1Y 전방 예측으로) 및 XNUMX년(XNUMXY 전방 예측으로) 값을 예측했습니다. 전반적으로 모델은 인간 예측자와 동등하거나 경우에 따라 더 나은 성능을 보였습니다. 이 결과는 우리 모델의 효율성과 신뢰성을 보여줍니다.
마이크로 수준의 판매 예측 및 제품 수명 주기
다음 그림은 모델이 각 제품에 대한 극히 적은 관찰(즉, 제품 수명 주기 예측을 위한 입력에서 하나 또는 두 개의 관찰)에 액세스하면서 제품 데이터를 사용하여 어떻게 작동하는지 보여줍니다. 주황색 점은 교육 데이터를 나타내고 녹색 점은 테스트 데이터를 나타내며 파란색 선은 모델 예측 제품 수명 주기를 나타냅니다.



새 판매 데이터를 사용할 수 있게 되면 재교육할 필요 없이 모델에 컨텍스트에 대한 더 많은 관찰을 제공할 수 있습니다. 다음 그림은 더 많은 컨텍스트가 제공된 경우 모델이 어떻게 작동하는지 보여줍니다. 궁극적으로 컨텍스트가 많을수록 WAPE 값이 낮아집니다.
또한 제조 기술 및 기타 범주 정보를 포함하여 각 제품에 대한 추가 기능을 통합했습니다. 이와 관련하여 외부 기능은 저맥락 체제에서 WAPE 값을 줄이는 데 도움이 되었습니다(다음 그림 참조). 이 동작에 대한 두 가지 설명이 있습니다. 첫째, 우리는 데이터가 상위 맥락에서 스스로 말하도록 해야 합니다. 추가 기능이 이 프로세스를 방해할 수 있습니다. 둘째, 더 나은 기능이 필요합니다. 우리는 1,000차원의 XNUMX-핫 인코딩 기능(단어 모음)을 사용했습니다. 추측은 더 나은 기능 엔지니어링 기술이 WAPE를 더욱 줄이는 데 도움이 될 수 있다는 것입니다.
이러한 추가 데이터는 모델이 제품이 시장에 출시되기 전에도 신제품 판매를 예측하는 데 도움이 될 수 있습니다. 예를 들어 다음 그림에서는 외부 기능에서만 얻을 수 있는 마일리지를 표시합니다.

결론
이 게시물에서는 MLSL과 NXP 팀이 협력하여 NXP의 거시적 및 미시적 수준의 장기 판매를 예측하는 방법을 시연했습니다. NXP 팀은 이제 프로세스에서 이러한 판매 예측을 사용하는 방법(예: R&D 자금 조달 결정을 위한 입력으로 사용하고 ROI를 향상시키는 방법)을 배우게 됩니다. 우리는 Amazon Forecast를 사용하여 비즈니스 라인(매크로 판매)의 판매를 예측했으며 이를 하향식 접근 방식이라고 합니다. 또한 시계열을 포인트 클라우드로 사용하여 제품 수준(마이크로 수준)에서 누락된 값 및 콜드 스타트 문제를 해결하는 새로운 접근 방식을 제안했습니다. 우리는 이 접근 방식을 상향식(Bottom-up)이라고 부르며 각 제품의 월별 매출을 예측했습니다. 콜드 스타트 모델의 성능을 향상시키기 위해 각 제품의 외부 기능을 추가로 통합했습니다.
전반적으로 이 작업 중에 개발된 모델은 사람의 예측과 동등한 성능을 보였습니다. 어떤 경우에는 모델이 장기적으로 사람의 예측보다 더 잘 수행되었습니다. 이 결과는 우리 모델의 효율성과 신뢰성을 보여줍니다.
이 솔루션은 모든 예측 문제에 사용할 수 있습니다. ML 솔루션 설계 및 개발 측면에서 추가 지원을 받으려면 언제든지 문의하십시오. MLSL 팀.
저자 소개
 수아드 부탄 NXP-CTO의 데이터 과학자로서 고급 도구와 기술을 사용하여 비즈니스 의사 결정을 지원하기 위해 다양한 데이터를 의미 있는 통찰력으로 변환하고 있습니다.
수아드 부탄 NXP-CTO의 데이터 과학자로서 고급 도구와 기술을 사용하여 비즈니스 의사 결정을 지원하기 위해 다양한 데이터를 의미 있는 통찰력으로 변환하고 있습니다.
 벤 프리돌린 NXP-CTO의 데이터 과학자로서 AI 및 클라우드 채택 가속화를 조정합니다. 그는 기계 학습, 딥 러닝 및 종단 간 ML 솔루션에 중점을 둡니다.
벤 프리돌린 NXP-CTO의 데이터 과학자로서 AI 및 클라우드 채택 가속화를 조정합니다. 그는 기계 학습, 딥 러닝 및 종단 간 ML 솔루션에 중점을 둡니다.
 코니 기넨 NXP 데이터 포트폴리오의 프로젝트 리더로서 데이터 중심화를 향한 조직의 디지털 혁신을 지원합니다.
코니 기넨 NXP 데이터 포트폴리오의 프로젝트 리더로서 데이터 중심화를 향한 조직의 디지털 혁신을 지원합니다.
 바트 제만 NXP-CTO에서 데이터 및 분석에 대한 열정을 가진 전략가로서 더 많은 성장과 혁신을 위해 더 나은 데이터 기반 의사결정을 추진하고 있습니다.
바트 제만 NXP-CTO에서 데이터 및 분석에 대한 열정을 가진 전략가로서 더 많은 성장과 혁신을 위해 더 나은 데이터 기반 의사결정을 추진하고 있습니다.
 아산 알리 Amazon Machine Learning Solutions Lab의 응용 과학자로서 다양한 도메인의 고객과 협력하여 최첨단 AI/ML 기술을 사용하여 긴급하고 비용이 많이 드는 문제를 해결합니다.
아산 알리 Amazon Machine Learning Solutions Lab의 응용 과학자로서 다양한 도메인의 고객과 협력하여 최첨단 AI/ML 기술을 사용하여 긴급하고 비용이 많이 드는 문제를 해결합니다.
 이푸 후 Amazon Machine Learning Solutions 연구실의 응용 과학자로 다양한 산업 분야에서 고객의 비즈니스 문제를 해결하기 위한 창의적인 ML 솔루션 설계를 돕습니다.
이푸 후 Amazon Machine Learning Solutions 연구실의 응용 과학자로 다양한 산업 분야에서 고객의 비즈니스 문제를 해결하기 위한 창의적인 ML 솔루션 설계를 돕습니다.
 메디 누리 Amazon ML Solutions Lab의 응용 과학 관리자로서 다양한 산업 분야의 대규모 조직을 위한 ML 솔루션 개발을 돕고 에너지 분야를 이끌고 있습니다. 그는 AI/ML을 사용하여 고객이 지속 가능성 목표를 달성하도록 돕는 데 열정적입니다.
메디 누리 Amazon ML Solutions Lab의 응용 과학 관리자로서 다양한 산업 분야의 대규모 조직을 위한 ML 솔루션 개발을 돕고 에너지 분야를 이끌고 있습니다. 그는 AI/ML을 사용하여 고객이 지속 가능성 목표를 달성하도록 돕는 데 열정적입니다.
 후제파 랑왈라 AWS AIRE의 수석 응용 과학 관리자입니다. 그는 데이터 자산의 기계 학습 기반 검색을 가능하게 하는 과학자 및 엔지니어 팀을 이끌고 있습니다. 그의 연구 관심 분야는 책임 있는 AI, 연합 학습 및 의료 및 생명 과학 분야의 ML 응용 분야입니다.
후제파 랑왈라 AWS AIRE의 수석 응용 과학 관리자입니다. 그는 데이터 자산의 기계 학습 기반 검색을 가능하게 하는 과학자 및 엔지니어 팀을 이끌고 있습니다. 그의 연구 관심 분야는 책임 있는 AI, 연합 학습 및 의료 및 생명 과학 분야의 ML 응용 분야입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/predicting-new-and-existing-product-sales-in-semiconductors-using-amazon-forecast/

