Im ersten Teil In dieser dreiteiligen Serie haben wir eine Lösung vorgestellt, die zeigt, wie Sie die Erkennung von Dokumentenmanipulationen und Betrug mithilfe von AWS-KI und maschinellen Lerndiensten (ML) für einen Anwendungsfall bei der Hypothekenübernahme automatisieren können.
In diesem Beitrag stellen wir einen Ansatz zur Entwicklung eines Deep-Learning-basierten Computer-Vision-Modells vor, um gefälschte Bilder bei der Hypothekenabsicherung zu erkennen und hervorzuheben. Wir bieten Anleitungen zum Aufbau, zur Schulung und zum Einsatz von Deep-Learning-Netzwerken Amazon Sage Maker.
In Teil 3 zeigen wir, wie die Lösung implementiert wird Amazon Fraud Detector.
Lösungsüberblick
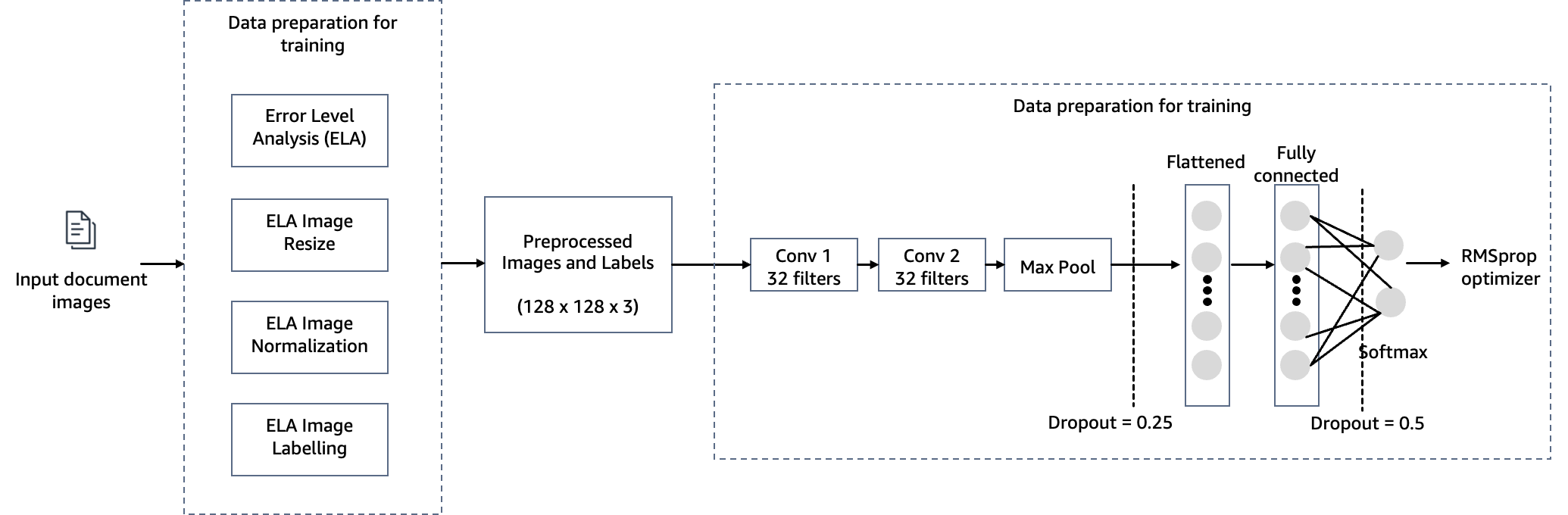
Um das Ziel der Erkennung von Dokumentenmanipulationen bei der Hypothekenvergabe zu erreichen, verwenden wir für unsere Bildfälschungserkennungslösung ein auf SageMaker gehostetes Computer-Vision-Modell. Dieses Modell empfängt ein Testbild als Eingabe und generiert als Ausgabe eine Wahrscheinlichkeitsvorhersage für eine Fälschung. Die Netzwerkarchitektur ist im folgenden Diagramm dargestellt.
Bei der Bildfälschung handelt es sich hauptsächlich um vier Techniken: Spleißen, Kopieren, Entfernen und Verbessern. Abhängig von den Merkmalen der Fälschung können unterschiedliche Hinweise als Grundlage für die Erkennung und Lokalisierung herangezogen werden. Zu diesen Hinweisen gehören JPEG-Komprimierungsartefakte, Kanteninkonsistenzen, Rauschmuster, Farbkonsistenz, visuelle Ähnlichkeit, EXIF-Konsistenz und Kameramodell.
Angesichts des umfangreichen Bereichs der Bildfälschungserkennung verwenden wir den Error Level Analysis (ELA)-Algorithmus als anschauliche Methode zur Erkennung von Fälschungen. Wir haben die ELA-Technik für diesen Beitrag aus folgenden Gründen ausgewählt:
- Es ist schneller zu implementieren und kann Manipulationen an Bildern leicht erkennen.
- Es funktioniert durch die Analyse der Komprimierungsgrade verschiedener Teile eines Bildes. Auf diese Weise können Inkonsistenzen erkannt werden, die auf Manipulationen hinweisen können – beispielsweise wenn ein Bereich aus einem anderen Bild kopiert und eingefügt wurde, das mit einer anderen Komprimierungsstufe gespeichert wurde.
- Es ist gut geeignet, subtilere oder nahtlose Manipulationen zu erkennen, die mit bloßem Auge möglicherweise schwer zu erkennen sind. Selbst kleine Änderungen an einem Bild können zu erkennbaren Komprimierungsanomalien führen.
- Es ist nicht darauf angewiesen, dass zum Vergleich das unveränderte Originalbild zur Verfügung steht. ELA kann Manipulationszeichen nur im befragten Bild selbst identifizieren. Bei anderen Techniken ist oft das unveränderte Original zum Vergleich erforderlich.
- Es handelt sich um eine leichtgewichtige Technik, die lediglich auf der Analyse von Komprimierungsartefakten in den digitalen Bilddaten beruht. Es ist nicht auf spezielle Hardware oder forensische Fachkenntnisse angewiesen. Dadurch wird ELA als First-Pass-Analysetool zugänglich.
- Das ausgegebene ELA-Bild kann Unterschiede in den Komprimierungsstufen deutlich hervorheben und so manipulierte Bereiche sichtbar machen. Dadurch können auch Laien Anzeichen einer möglichen Manipulation erkennen.
- Es funktioniert mit vielen Bildtypen (z. B. JPEG, PNG und GIF) und erfordert zur Analyse nur das Bild selbst. Andere forensische Techniken unterliegen möglicherweise stärkeren Einschränkungen in Bezug auf Formate oder Originalbildanforderungen.
In realen Szenarien, in denen Sie möglicherweise über eine Kombination von Eingabedokumenten (JPEG, PNG, GIF, TIFF, PDF) verfügen, empfehlen wir jedoch die Verwendung von ELA in Verbindung mit verschiedenen anderen Methoden, z Erkennen von Inkonsistenzen in Kanten, Geräuschmuster, Farbgleichmäßigkeit, EXIF-Datenkonsistenz, Identifizierung des Kameramodells und Einheitlichkeit der Schriftarten. Unser Ziel ist es, den Code für diesen Beitrag mit zusätzlichen Techniken zur Fälschungserkennung zu aktualisieren.
Die zugrunde liegende Prämisse von ELA geht davon aus, dass die Eingabebilder im JPEG-Format vorliegen, das für seine verlustbehaftete Komprimierung bekannt ist. Dennoch kann die Methode auch dann noch effektiv sein, wenn die Eingabebilder ursprünglich in einem verlustfreien Format (z. B. PNG, GIF oder BMP) vorlagen und später während des Manipulationsprozesses in JPEG konvertiert wurden. Wenn ELA auf ursprüngliche verlustfreie Formate angewendet wird, zeigt es in der Regel eine gleichbleibende Bildqualität ohne jegliche Verschlechterung an, was es schwierig macht, veränderte Bereiche zu lokalisieren. Bei JPEG-Bildern ist die erwartete Norm, dass das gesamte Bild ähnliche Komprimierungsgrade aufweist. Wenn jedoch ein bestimmter Abschnitt im Bild einen deutlich anderen Fehlergrad aufweist, deutet dies häufig darauf hin, dass eine digitale Änderung vorgenommen wurde.
ELA hebt Unterschiede in der JPEG-Komprimierungsrate hervor. Bereiche mit gleichmäßiger Färbung weisen wahrscheinlich ein niedrigeres ELA-Ergebnis auf (z. B. eine dunklere Farbe im Vergleich zu kontrastreichen Kanten). Zu den Dingen, nach denen Sie suchen müssen, um Manipulationen oder Modifikationen zu erkennen, gehören:
- Ähnliche Kanten sollten im ELA-Ergebnis eine ähnliche Helligkeit haben. Alle Kanten mit hohem Kontrast sollten einander ähnlich aussehen, und alle Kanten mit niedrigem Kontrast sollten ähnlich aussehen. Bei einem Originalfoto sollten kontrastarme Kanten fast so hell sein wie kontrastreiche Kanten.
- Ähnliche Texturen sollten unter ELA eine ähnliche Farbgebung haben. Bereiche mit mehr Oberflächendetails, beispielsweise eine Nahaufnahme eines Basketballs, werden wahrscheinlich ein höheres ELA-Ergebnis aufweisen als eine glatte Oberfläche.
- Unabhängig von der tatsächlichen Farbe der Oberfläche sollten alle ebenen Flächen unter ELA etwa die gleiche Farbe haben.
JPEG-Bilder verwenden ein verlustbehaftetes Komprimierungssystem. Jede Neukodierung (Neuspeicherung) des Bildes führt zu einem weiteren Qualitätsverlust des Bildes. Konkret arbeitet der JPEG-Algorithmus mit einem 8×8-Pixel-Raster. Jedes 8×8-Quadrat wird unabhängig komprimiert. Wenn das Bild völlig unverändert ist, sollten alle 8×8-Quadrate ähnliche Fehlerpotentiale aufweisen. Wenn das Bild unverändert bleibt und erneut gespeichert wird, sollte sich jedes Quadrat ungefähr mit der gleichen Geschwindigkeit verschlechtern.
ELA speichert das Bild in einer angegebenen JPEG-Qualitätsstufe. Dieses erneute Speichern führt zu einer bekannten Anzahl von Fehlern im gesamten Bild. Das erneut gespeicherte Bild wird dann mit dem Originalbild verglichen. Wenn ein Bild geändert wird, sollte jedes 8×8-Quadrat, das von der Änderung berührt wurde, ein höheres Fehlerpotenzial aufweisen als der Rest des Bildes.
Die Ergebnisse von ELA hängen direkt von der Bildqualität ab. Möglicherweise möchten Sie wissen, ob etwas hinzugefügt wurde. Wenn das Bild jedoch mehrmals kopiert wird, lässt ELA möglicherweise nur die Erkennung der Neuspeicherungen zu. Versuchen Sie, die qualitativ beste Version des Bildes zu finden.
Mit Schulung und Übung kann ELA auch lernen, Bildskalierung, Bildqualität, Zuschnitt und Neuspeicherungstransformationen zu erkennen. Wenn beispielsweise ein Nicht-JPEG-Bild sichtbare Gitterlinien enthält (1 Pixel breit in 8×8 Quadraten), bedeutet dies, dass das Bild als JPEG begann und in ein Nicht-JPEG-Format (z. B. PNG) konvertiert wurde. Wenn in einigen Bildbereichen Gitterlinien fehlen oder sich die Gitterlinien verschieben, handelt es sich um eine Verbindungsstelle oder einen gezeichneten Teil im Nicht-JPEG-Bild.
In den folgenden Abschnitten demonstrieren wir die Schritte zum Konfigurieren, Trainieren und Bereitstellen des Computer-Vision-Modells.
Voraussetzungen:
Um diesem Beitrag folgen zu können, müssen die folgenden Voraussetzungen erfüllt sein:
- Haben Sie ein AWS-Konto.
- Einrichten Amazon SageMaker-Studio. Sie können SageMaker Studio mithilfe von Standardvoreinstellungen schnell starten und so einen schnellen Start ermöglichen. Weitere Informationen finden Sie unter Amazon SageMaker vereinfacht die Einrichtung von Amazon SageMaker Studio für einzelne Benutzer.
- Öffnen Sie SageMaker Studio und starten Sie ein Systemterminal.
- Führen Sie den folgenden Befehl im Terminal aus:
git clone https://github.com/aws-samples/document-tampering-detection.git - Die Gesamtkosten für die Ausführung von SageMaker Studio für einen Benutzer und die Konfigurationen der Notebook-Umgebung betragen 7.314 USD pro Stunde.
Richten Sie das Modellschulungsnotizbuch ein
Führen Sie die folgenden Schritte aus, um Ihr Schulungsnotizbuch einzurichten:
- Öffnen Sie den Microsoft Store auf Ihrem Windows-PC.
tampering_detection_training.ipynbDatei aus dem Verzeichnis „document-tampering-Detection“. - Richten Sie die Notebook-Umgebung mit dem Image TensorFlow 2.6 Python 3.8 CPU oder GPU Optimized ein.
Bei der Auswahl GPU-optimierter Instanzen kann es sein, dass Sie Probleme mit unzureichender Verfügbarkeit haben oder das Kontingentlimit für GPU-Instanzen in Ihrem AWS-Konto erreichen. Um das Kontingent zu erhöhen, besuchen Sie die Service Quotas-Konsole und erhöhen Sie das Servicelimit für den spezifischen Instanztyp, den Sie benötigen. In solchen Fällen können Sie auch eine CPU-optimierte Notebook-Umgebung nutzen. - Aussichten für Kernel, wählen Python3.
- Aussichten für Instanztyp, wählen ml.m5d.24xlarge oder jede andere große Instanz.
Wir haben einen größeren Instanztyp ausgewählt, um die Trainingszeit des Modells zu verkürzen. Bei einer ml.m5d.24xlarge-Notebookumgebung betragen die Kosten pro Stunde 7.258 USD pro Stunde.
Führen Sie das Trainingsnotizbuch aus
Führen Sie jede Zelle im Notizbuch aus tampering_detection_training.ipynb in Ordnung. In den folgenden Abschnitten besprechen wir einige Zellen ausführlicher.
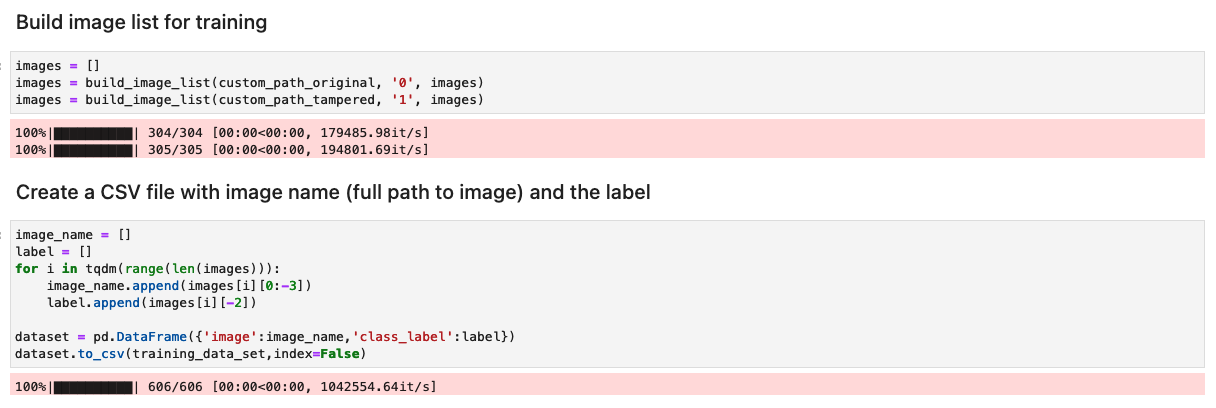
Bereiten Sie den Datensatz mit einer Liste der ursprünglichen und manipulierten Bilder vor
Bevor Sie die folgende Zelle im Notizbuch ausführen, bereiten Sie einen Datensatz mit Originaldokumenten und manipulierten Dokumenten basierend auf Ihren spezifischen Geschäftsanforderungen vor. Für diesen Beitrag verwenden wir einen Beispieldatensatz manipulierter Gehaltsabrechnungen und Kontoauszüge. Der Datensatz ist im Bilderverzeichnis des verfügbar GitHub-Repository.

Das Notebook liest die Original- und manipulierten Bilder aus dem images/training Verzeichnis.
Der Datensatz für das Training wird mithilfe einer CSV-Datei mit zwei Spalten erstellt: dem Pfad zur Bilddatei und der Bezeichnung für das Bild (0 für Originalbild und 1 für manipuliertes Bild).
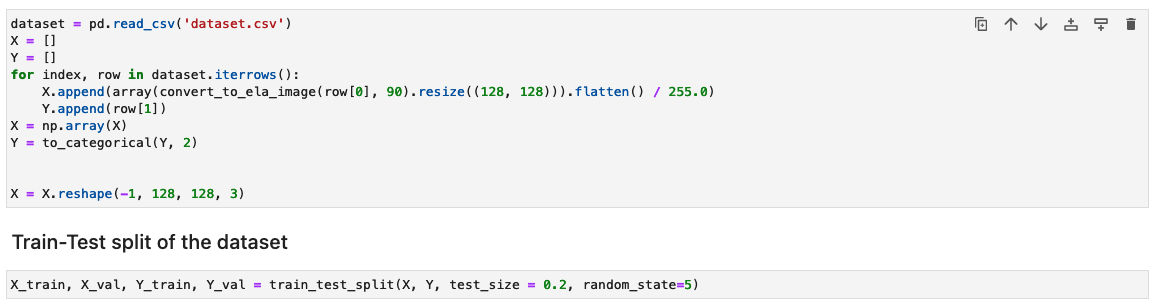
Verarbeiten Sie den Datensatz, indem Sie die ELA-Ergebnisse für jedes Trainingsbild generieren
In diesem Schritt generieren wir das ELA-Ergebnis (mit 90 % Qualität) des eingegebenen Trainingsbilds. Die Funktion convert_to_ela_image benötigt zwei Parameter: path, der der Pfad zu einer Bilddatei ist, und quality, der den Qualitätsparameter für die JPEG-Komprimierung darstellt. Die Funktion führt die folgenden Schritte aus:
- Konvertieren Sie das Bild in das RGB-Format und speichern Sie das Bild erneut als JPEG-Datei mit der angegebenen Qualität unter dem Namen tempresaved.jpg.
- Berechnen Sie die Differenz zwischen dem Originalbild und dem erneut gespeicherten JPEG-Bild (ELA), um den maximalen Unterschied in den Pixelwerten zwischen dem Originalbild und dem erneut gespeicherten Bild zu ermitteln.
- Berechnen Sie einen Skalierungsfaktor basierend auf der maximalen Differenz, um die Helligkeit des ELA-Bildes anzupassen.
- Verbessern Sie die Helligkeit des ELA-Bildes mithilfe des berechneten Skalierungsfaktors.
- Ändern Sie die Größe des ELA-Ergebnisses auf 128 x 128 x 3, wobei 3 die Anzahl der Kanäle darstellt, um die Eingabegröße für das Training zu reduzieren.
- Geben Sie das ELA-Bild zurück.
Bei verlustbehafteten Bildformaten wie JPEG führt der anfängliche Speichervorgang zu erheblichen Farbverlusten. Wenn das Bild jedoch geladen und anschließend im gleichen verlustbehafteten Format neu codiert wird, kommt es im Allgemeinen zu einer geringeren zusätzlichen Farbverschlechterung. Die ELA-Ergebnisse heben die Bildbereiche hervor, die beim erneuten Speichern am anfälligsten für Farbverschlechterungen sind. Im Allgemeinen treten Veränderungen deutlich in Bereichen auf, die im Vergleich zum Rest des Bildes ein höheres Potenzial für eine Verschlechterung aufweisen.
Als nächstes werden die Bilder zum Training in ein NumPy-Array verarbeitet. Anschließend teilen wir den Eingabedatensatz zufällig in Trainings- und Test- oder Validierungsdaten auf (80/20). Sie können alle Warnungen ignorieren, wenn Sie diese Zellen ausführen.
Abhängig von der Größe des Datensatzes kann die Ausführung dieser Zellen einige Zeit in Anspruch nehmen. Für den Beispieldatensatz, den wir in diesem Repository bereitgestellt haben, kann es 5–10 Minuten dauern.
Konfigurieren Sie das CNN-Modell
In diesem Schritt erstellen wir eine Minimalversion des VGG-Netzwerks mit kleinen Faltungsfiltern. Der VGG-16 besteht aus 13 Faltungsschichten und drei vollständig verbundenen Schichten. Der folgende Screenshot veranschaulicht die Architektur unseres Convolutional Neural Network (CNN)-Modells.

Beachten Sie die folgenden Konfigurationen:
- zufuhr – Das Modell nimmt eine Bildeingabegröße von 128 x 128 x 3 auf.
- Faltungsschichten – Die Faltungsschichten verwenden ein minimales Empfangsfeld (3×3), die kleinstmögliche Größe, die noch oben/unten und links/rechts erfasst. Darauf folgt eine Aktivierungsfunktion für gleichgerichtete lineare Einheiten (ReLU), die die Trainingszeit verkürzt. Dies ist eine lineare Funktion, die die Eingabe ausgibt, wenn sie positiv ist; andernfalls ist die Ausgabe Null. Der Faltungsschritt ist auf den Standardwert (1 Pixel) festgelegt, um die räumliche Auflösung nach der Faltung beizubehalten (der Schritt ist die Anzahl der Pixelverschiebungen über die Eingabematrix).
- Vollständig verbundene Schichten – Das Netzwerk verfügt über zwei vollständig verbundene Schichten. Die erste dichte Ebene verwendet die ReLU-Aktivierung und die zweite verwendet Softmax, um das Bild als Original oder manipuliert zu klassifizieren.
Sie können alle Warnungen ignorieren, wenn Sie diese Zellen ausführen.
Speichern Sie die Modellartefakte
Speichern Sie das trainierte Modell unter einem eindeutigen Dateinamen – beispielsweise basierend auf dem aktuellen Datum und der aktuellen Uhrzeit – in einem Verzeichnis mit dem Namen „model“.

Das Modell wird im Keras-Format mit der Erweiterung gespeichert .keras. Wir speichern die Modellartefakte auch als Verzeichnis mit dem Namen 1, das serialisierte Signaturen und den für ihre Ausführung erforderlichen Status enthält, einschließlich Variablenwerten und Vokabularien zur Bereitstellung in einer SageMaker-Laufzeitumgebung (auf die wir später in diesem Beitrag eingehen).
Messen Sie die Modellleistung
Die folgende Verlustkurve zeigt den Verlauf des Modellverlusts über Trainingsepochen (Iterationen).
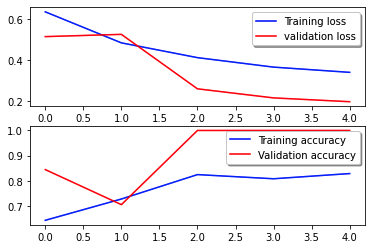
Die Verlustfunktion misst, wie gut die Vorhersagen des Modells mit den tatsächlichen Zielen übereinstimmen. Niedrigere Werte weisen auf eine bessere Übereinstimmung zwischen Vorhersagen und wahren Werten hin. Sinkende Verluste über Epochen hinweg bedeuten, dass sich das Modell verbessert. Die Genauigkeitskurve veranschaulicht die Genauigkeit des Modells über Trainingsepochen. Genauigkeit ist das Verhältnis der richtigen Vorhersagen zur Gesamtzahl der Vorhersagen. Eine höhere Genauigkeit weist auf ein leistungsstärkeres Modell hin. Normalerweise erhöht sich die Genauigkeit während des Trainings, da das Modell Muster lernt und seine Vorhersagefähigkeit verbessert. Anhand dieser Informationen können Sie feststellen, ob das Modell überangepasst ist (gute Leistung bei Trainingsdaten, aber schlechte Leistung bei unsichtbaren Daten) oder unterangepasst ist (nicht ausreichend aus den Trainingsdaten lernt).
Die folgende Verwirrungsmatrix stellt visuell dar, wie gut das Modell genau zwischen den Klassen positiv (gefälschtes Bild, dargestellt als Wert 1) und negativ (unverfälschtes Bild, dargestellt als Wert 0) unterscheidet.
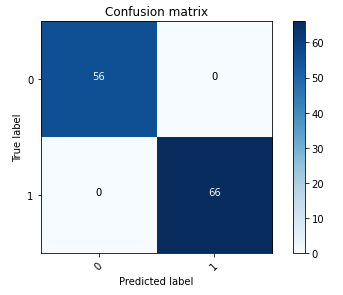
Nach dem Modelltraining besteht unser nächster Schritt darin, das Computer-Vision-Modell als API bereitzustellen. Diese API wird als Bestandteil des Underwriting-Workflows in Geschäftsanwendungen integriert. Um dies zu erreichen, nutzen wir Amazon SageMaker Inference, einen vollständig verwalteten Dienst. Dieser Service lässt sich nahtlos in MLOps-Tools integrieren und ermöglicht eine skalierbare Modellbereitstellung, kosteneffiziente Inferenz, verbessertes Modellmanagement in der Produktion und eine geringere betriebliche Komplexität. In diesem Beitrag stellen wir das Modell als Echtzeit-Inferenzendpunkt bereit. Beachten Sie jedoch, dass die Modellbereitstellung je nach Arbeitsablauf Ihrer Geschäftsanwendungen auch als Stapelverarbeitung, asynchrone Verarbeitung oder über eine serverlose Bereitstellungsarchitektur angepasst werden kann.
Richten Sie das Modellbereitstellungsnotizbuch ein
Führen Sie die folgenden Schritte aus, um Ihr Modellbereitstellungsnotizbuch einzurichten:
- Öffnen Sie den Microsoft Store auf Ihrem Windows-PC.
tampering_detection_model_deploy.ipynbDatei aus dem Verzeichnis „document-tampering-Detection“. - Richten Sie die Notebook-Umgebung mit dem Image Data Science 3.0 ein.
- Aussichten für Kernel, wählen Python3.
- Aussichten für Instanztyp, wählen ml.t3.mittel.
Bei einer ml.t3.medium-Notebookumgebung betragen die Kosten pro Stunde 0.056 USD.
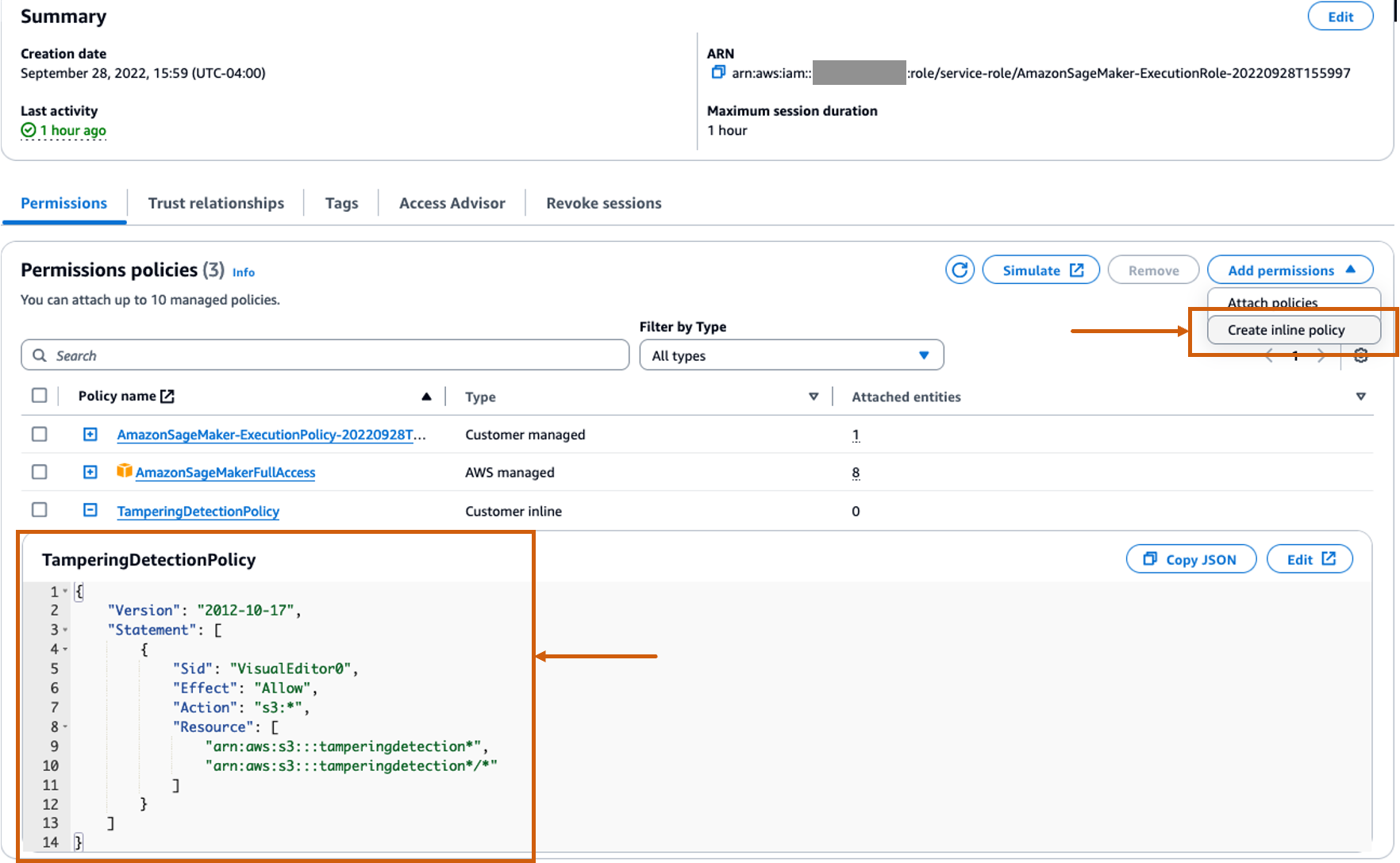
Erstellen Sie eine benutzerdefinierte Inline-Richtlinie für die SageMaker-Rolle, um alle Amazon S3-Aktionen zuzulassen
Das AWS Identity and Access Management and (IAM)-Rolle für SageMaker wird im Format vorliegen AmazonSageMaker- ExecutionRole-<random numbers>. Stellen Sie sicher, dass Sie die richtige Rolle verwenden. Den Rollennamen finden Sie unter den Benutzerdetails in den SageMaker-Domänenkonfigurationen.

Aktualisieren Sie die IAM-Rolle so, dass sie eine Inline-Richtlinie enthält, die alle zulässt Amazon Simple Storage-Service (Amazon S3) Aktionen. Dies ist erforderlich, um das Erstellen und Löschen von S3-Buckets zu automatisieren, in denen die Modellartefakte gespeichert werden. Sie können den Zugriff auf bestimmte S3-Buckets beschränken. Beachten Sie, dass wir in der IAM-Richtlinie einen Platzhalter für den S3-Bucket-Namen verwendet haben (tamperingdetection*).
Führen Sie das Bereitstellungsnotizbuch aus
Führen Sie jede Zelle im Notizbuch aus tampering_detection_model_deploy.ipynb in Ordnung. In den folgenden Abschnitten besprechen wir einige Zellen ausführlicher.
Erstellen Sie einen S3-Bucket
Führen Sie die Zelle aus, um einen S3-Bucket zu erstellen. Der Eimer wird benannt tamperingdetection<current date time> und in derselben AWS-Region wie Ihre SageMaker Studio-Umgebung.

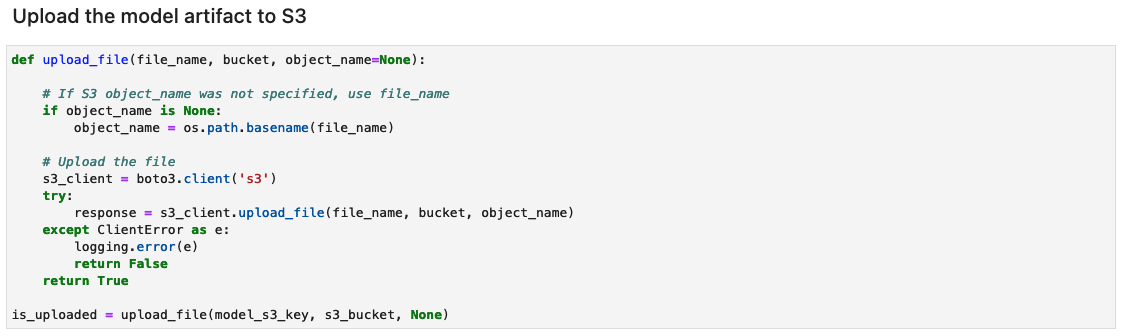
Erstellen Sie das Modellartefaktarchiv und laden Sie es auf Amazon S3 hoch
Erstellen Sie eine tar.gz-Datei aus den Modellartefakten. Wir haben die Modellartefakte als Verzeichnis mit dem Namen 1 gespeichert, das serialisierte Signaturen und den für ihre Ausführung erforderlichen Status enthält, einschließlich Variablenwerten und Vokabularien zur Bereitstellung in der SageMaker-Laufzeit. Sie können auch eine benutzerdefinierte Inferenzdatei mit dem Namen einschließen inference.py im Codeordner im Modellartefakt. Die benutzerdefinierte Inferenz kann zur Vor- und Nachbearbeitung des Eingabebildes verwendet werden.
![]()
Erstellen Sie einen SageMaker-Inferenzendpunkt
Die Fertigstellung der Zelle zum Erstellen eines SageMaker-Inferenzendpunkts kann einige Minuten dauern.
Testen Sie den Inferenzendpunkt
Die Funktion check_image Verarbeitet ein Bild als ELA-Bild vor, sendet es zur Inferenz an einen SageMaker-Endpunkt, ruft die Vorhersagen des Modells ab, verarbeitet sie und druckt die Ergebnisse. Das Modell verwendet ein NumPy-Array des Eingabebildes als ELA-Bild, um Vorhersagen zu liefern. Die Vorhersagen werden als 0 ausgegeben, was ein unverfälschtes Bild darstellt, und als 1, was ein gefälschtes Bild darstellt.

Rufen wir das Modell mit einem unveränderten Bild einer Gehaltsabrechnung auf und überprüfen das Ergebnis.

Das Modell gibt die Klassifizierung als 0 aus, was ein unverfälschtes Bild darstellt.
Rufen wir nun das Modell mit einem manipulierten Bild einer Gehaltsabrechnung auf und überprüfen das Ergebnis.

Das Modell gibt die Klassifizierung als 1 aus, was ein gefälschtes Bild darstellt.
Einschränkungen
Obwohl ELA ein hervorragendes Tool zur Erkennung von Änderungen ist, gibt es eine Reihe von Einschränkungen, wie zum Beispiel die folgenden:
- Eine Änderung eines einzelnen Pixels oder eine geringfügige Farbanpassung führt möglicherweise nicht zu einer spürbaren Änderung des ELA, da JPEG auf einem Raster arbeitet.
- ELA identifiziert nur, welche Regionen unterschiedliche Komprimierungsstufen haben. Wenn ein Bild mit geringerer Qualität in ein Bild mit höherer Qualität eingefügt wird, erscheint das Bild mit der geringeren Qualität möglicherweise als dunklerer Bereich.
- Durch Skalieren, Umfärben oder Hinzufügen von Rauschen zu einem Bild wird das gesamte Bild verändert, wodurch ein höheres Fehlerpotenzial entsteht.
- Wenn ein Bild mehrmals erneut gespeichert wird, weist es möglicherweise eine völlig minimale Fehlerstufe auf, sodass weitere erneute Speicherungen das Bild nicht verändern. In diesem Fall gibt die ELA ein schwarzes Bild zurück und es können mit diesem Algorithmus keine Änderungen identifiziert werden.
- In Photoshop können durch einfaches Speichern des Bildes Texturen und Kanten automatisch geschärft werden, wodurch ein höheres Fehlerpotenzial entsteht. Dieses Artefakt identifiziert keine absichtliche Änderung; Es weist darauf hin, dass ein Adobe-Produkt verwendet wurde. Technisch gesehen erscheint ELA als Modifikation, da Adobe automatisch eine Modifikation durchführte, die Modifikation jedoch nicht unbedingt vom Benutzer beabsichtigt war.
Wir empfehlen die Verwendung von ELA zusammen mit anderen zuvor im Blog besprochenen Techniken, um eine größere Bandbreite an Bildmanipulationsfällen zu erkennen. ELA kann auch als unabhängiges Werkzeug zur visuellen Untersuchung von Bildunterschieden dienen, insbesondere wenn das Training eines CNN-basierten Modells eine Herausforderung darstellt.
Aufräumen
Um die Ressourcen zu entfernen, die Sie im Rahmen dieser Lösung erstellt haben, führen Sie die folgenden Schritte aus:
- Führen Sie die Notebook-Zellen unter dem aus Aufräumen Abschnitt. Dadurch wird Folgendes gelöscht:
- SageMaker-Inferenzendpunkt – Der Name des Inferenzendpunkts lautet
tamperingdetection-<datetime>. - Objekte innerhalb des S3-Buckets und des S3-Buckets selbst – Der Bucket-Name lautet
tamperingdetection<datetime>.
- SageMaker-Inferenzendpunkt – Der Name des Inferenzendpunkts lautet
- schließen die Notebook-Ressourcen von SageMaker Studio.
Zusammenfassung
In diesem Beitrag haben wir eine End-to-End-Lösung zur Erkennung von Dokumentenmanipulationen und Betrug mithilfe von Deep Learning und SageMaker vorgestellt. Wir haben ELA verwendet, um Bilder vorzuverarbeiten und Diskrepanzen in den Komprimierungsstufen zu identifizieren, die auf eine Manipulation hinweisen könnten. Anschließend haben wir ein CNN-Modell auf diesem verarbeiteten Datensatz trainiert, um Bilder als original oder manipuliert zu klassifizieren.
Das Modell kann mit einem für Ihre Geschäftsanforderungen geeigneten Datensatz (gefälscht und original) eine starke Leistung mit einer Genauigkeit von über 95 % erzielen. Dies weist darauf hin, dass gefälschte Dokumente wie Gehaltsabrechnungen und Kontoauszüge zuverlässig erkannt werden können. Das trainierte Modell wird auf einem SageMaker-Endpunkt bereitgestellt, um skalierbare Inferenzen mit geringer Latenz zu ermöglichen. Durch die Integration dieser Lösung in Hypotheken-Workflows können Institutionen verdächtige Dokumente automatisch für weitere Betrugsuntersuchungen kennzeichnen.
Obwohl ELA leistungsstark ist, weist es einige Einschränkungen bei der Identifizierung bestimmter Arten subtilerer Manipulationen auf. Als nächste Schritte könnte das Modell durch die Einbeziehung zusätzlicher forensischer Techniken in das Training und die Verwendung größerer, vielfältigerer Datensätze verbessert werden. Insgesamt zeigt diese Lösung, wie Sie Deep Learning und AWS-Services nutzen können, um wirkungsvolle Lösungen zu entwickeln, die die Effizienz steigern, Risiken reduzieren und Betrug verhindern.
In Teil 3 zeigen wir, wie die Lösung auf Amazon Fraud Detector implementiert wird.
Über die Autoren
 Anup Ravindranath ist Senior Solutions Architect bei Amazon Web Services (AWS) mit Sitz in Toronto, Kanada und arbeitet mit Finanzdienstleistungsorganisationen zusammen. Er hilft Kunden dabei, ihre Unternehmen zu transformieren und Innovationen in der Cloud voranzutreiben.
Anup Ravindranath ist Senior Solutions Architect bei Amazon Web Services (AWS) mit Sitz in Toronto, Kanada und arbeitet mit Finanzdienstleistungsorganisationen zusammen. Er hilft Kunden dabei, ihre Unternehmen zu transformieren und Innovationen in der Cloud voranzutreiben.
 Vinnie Saini ist Senior Solutions Architect bei Amazon Web Services (AWS) mit Sitz in Toronto, Kanada. Sie hat Finanzdienstleistungskunden bei der Umstellung auf die Cloud unterstützt, mit KI- und ML-gesteuerten Lösungen, die auf starken Grundpfeilern architektonischer Exzellenz basieren.
Vinnie Saini ist Senior Solutions Architect bei Amazon Web Services (AWS) mit Sitz in Toronto, Kanada. Sie hat Finanzdienstleistungskunden bei der Umstellung auf die Cloud unterstützt, mit KI- und ML-gesteuerten Lösungen, die auf starken Grundpfeilern architektonischer Exzellenz basieren.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/

