
출처: rawpixel.com
대화형 AI는 다양한 산업 및 사용 사례에 걸친 확장성으로 인해 많은 화제와 관심을 불러일으킨 LLM의 응용 프로그램입니다. 대화형 시스템은 수십 년 동안 존재해 왔지만 LLM은 대규모 채택에 필요한 품질 향상을 가져왔습니다. 이 기사에서는 그림 1에 표시된 멘탈 모델을 사용하여 대화형 AI 애플리케이션을 분석합니다(참조: 전체적인 정신 모델로 AI 제품 구축 정신 모델에 대한 소개). 대화형 AI 시스템의 시장 기회와 비즈니스 가치를 고려한 후, 대화를 가능하게 할 뿐만 아니라 유용하게 만들기 위해 설정해야 하는 데이터, LLM 미세 조정 및 대화 설계 측면에서 추가 "기계"에 대해 설명합니다. 그리고 즐겁다.
1. 기회, 가치, 한계
전통적인 UX 디자인은 수많은 인공 UX 요소, 스와이프, 탭, 클릭을 중심으로 구축되므로 새로운 앱마다 학습 곡선이 필요합니다. 대화형 AI를 사용하면 이러한 분주함을 없애고 서로 다른 앱, 창 및 장치 간의 전환을 잊을 수 있는 자연스럽게 흐르는 대화의 우아한 경험으로 대체할 수 있습니다. 우리는 보편적이고 친숙한 의사소통 프로토콜인 언어를 사용하여 다양한 가상 비서(VA)와 상호 작용하고 작업을 수행합니다.
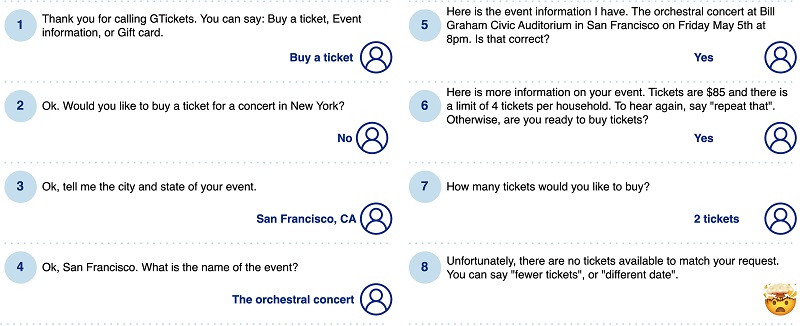
대화형 UI는 정확히 새로운 인기 항목은 아닙니다. 대화형 음성 응답 시스템(IVR)과 챗봇은 1990년대부터 존재해 왔으며 NLP의 주요 발전은 음성 및 채팅 인터페이스에 대한 희망의 물결과 개발로 이어졌습니다. 그러나 LLM 이전에는 대부분의 시스템이 규칙, 키워드 및 대화 패턴에 의존하는 기호 패러다임으로 구현되었습니다. 또한 이는 미리 정의된 특정 "역량" 영역으로 제한되었으며, 사용자가 이 영역을 벗어나 모험을 시도하면 곧 막다른 골목에 부딪히게 됩니다. 전체적으로 이러한 시스템은 잠재적인 실패 지점을 가지고 채굴되었으며 몇 번의 실망스러운 시도 후에 많은 사용자가 다시는 돌아오지 않았습니다. 다음 그림은 대화의 예를 보여줍니다. 특정 콘서트의 티켓을 주문하려는 사용자는 끈기 있게 상세한 문의 과정을 거치다가 결국 해당 콘서트가 매진되었음을 알게 됩니다.
LLM은 구현 기술로서 대화형 인터페이스를 새로운 수준의 품질과 사용자 만족도로 끌어올릴 수 있습니다. 이제 대화 시스템은 훨씬 더 폭넓은 세계 지식, 언어 능력, 대화 능력을 보여줄 수 있습니다. 사전 훈련된 모델을 활용하면 규칙, 키워드 및 대화 흐름을 컴파일하는 지루한 작업이 이제 LLM의 통계 지식으로 대체되므로 훨씬 짧은 시간 내에 개발할 수도 있습니다. 대화형 AI가 대규모로 가치를 제공할 수 있는 두 가지 주요 애플리케이션을 살펴보겠습니다.
- 고객 지원 더 일반적으로는 비슷한 요청을 자주 하는 다수의 사용자가 사용하는 애플리케이션입니다. 여기서 고객 지원을 제공하는 회사는 사용자보다 확실한 정보 우위를 갖고 있으며 이를 활용하여 보다 직관적이고 즐거운 사용자 경험을 만들 수 있습니다. 항공편을 재예약하는 경우를 생각해 보세요. 비행기를 자주 이용하는 나로서는 이런 일이 1년에 2~XNUMX번씩 일어난다. 그 사이에 특정 항공사의 사용자 인터페이스는 말할 것도 없고 프로세스의 세부 사항을 잊어버리는 경향이 있습니다. 대조적으로, 항공사의 고객 지원팀은 운영의 최전선과 중앙에서 재예약 요청을 하고 있습니다. 복잡한 그래픽 인터페이스를 통해 재예약 프로세스를 노출하는 대신, 지원팀에 문의하는 고객에게 논리를 "숨길" 수 있으며 언어를 자연스러운 채널로 사용하여 재예약할 수 있습니다. 물론 덜 친숙한 요청의 '롱테일'이 여전히 남아 있을 것입니다. 예를 들어, 비즈니스 고객이 사랑하는 개를 예약된 항공편에 초과 수하물로 추가하도록 유도하는 자발적인 기분 변화를 상상해 보십시오. 이러한 개별적인 요청은 상담원에게 전달되거나 가상 비서에 연결된 내부 지식 관리 시스템을 통해 처리될 수 있습니다.
- 지식 관리 엄청난 양의 데이터를 바탕으로 한 것입니다. 많은 현대 기업의 경우, 수년간의 운영, 반복 및 학습을 통해 축적한 내부 지식이 효율적인 방식으로 저장, 관리 및 액세스된다면 핵심 자산이자 차별화 요소가 됩니다. 협업 도구, 내부 위키, 지식 기반 등에 숨겨진 풍부한 데이터에 의존하여 이를 실행 가능한 지식으로 변환하지 못하는 경우가 많습니다. 직원이 떠나고 새 직원이 합류하며 XNUMX개월 전에 시작한 문서 페이지를 마무리하지 못하면 귀중한 지식이 엔트로피의 희생양이 됩니다. 내부 데이터 미로에서 길을 찾고 특정 비즈니스 상황에 필요한 정보를 얻는 것이 점점 더 어려워지고 있습니다. 이는 지식 근로자에게 막대한 효율성 손실을 초래합니다. 이 문제를 해결하기 위해 내부 데이터 소스에 대한 의미 검색을 통해 LLM을 강화할 수 있습니다. LLM을 사용하면 복잡한 공식 쿼리 대신 자연어 질문을 사용하여 이 데이터베이스에 대해 질문할 수 있습니다. 따라서 사용자는 지식 기반의 구조나 SQL과 같은 쿼리 언어의 구문보다는 자신의 정보 요구 사항에 집중할 수 있습니다. 텍스트 기반인 이러한 시스템은 풍부한 의미 공간에서 데이터와 함께 작동하여 "내부적으로" 의미 있는 연결을 만듭니다.
이러한 주요 애플리케이션 영역 외에도 원격 의료, 정신 건강 보조원, 교육용 챗봇 등 UX를 간소화하고 더 빠르고 효율적인 방식으로 사용자에게 가치를 제공할 수 있는 수많은 다른 애플리케이션이 있습니다.
이 심층 교육 콘텐츠가 유용하다면 AI 연구 메일 링리스트 구독 새로운 자료를 공개 할 때 경고를받습니다.
2. 데이터
LLM은 원래 유창한 잡담이나 보다 실질적인 대화에 참여하도록 훈련받지 않았습니다. 오히려 각 추론 단계에서 다음 토큰을 생성하는 방법을 학습하여 결국 일관된 텍스트를 생성합니다. 이 낮은 수준의 목표는 인간 대화의 도전과 다릅니다. 대화는 인간에게 믿을 수 없을 정도로 직관적이지만, 기계에게 대화를 가르치려고 할 때 대화는 믿을 수 없을 정도로 복잡하고 미묘해집니다. 예를 들어 인텐트의 기본 개념을 살펴보겠습니다. 우리가 언어를 사용할 때는 특정 목적, 즉 의사소통 의도를 위해 사용합니다. 즉, 정보를 전달하거나, 친목을 도모하거나, 누군가에게 무언가를 요청하는 것일 수 있습니다. 처음 두 가지는 LLM의 경우(데이터에서 필요한 정보를 확인한 경우) 다소 간단하지만 후자는 이미 더 어렵습니다. LLM은 관련 정보를 일관되게 결합하고 구조화해야 할 뿐만 아니라 형식성, 창의성, 유머 등 연성 기준 측면에서 올바른 감정 톤을 설정해야 합니다. 이는 대화 디자인의 과제입니다. (섹션 5 참조) 이는 미세 조정 데이터를 생성하는 작업과 밀접하게 얽혀 있습니다.
고전적인 언어 생성에서 특정 의사소통 의도를 인식하고 응답하는 것으로 전환하는 것은 대화 시스템의 더 나은 유용성과 수용을 향한 중요한 단계입니다. 모든 미세 조정 노력은 적절한 데이터 세트를 컴파일하는 것부터 시작됩니다.
미세 조정 데이터는 (미래) 실제 데이터 분포에 최대한 가까워야 합니다. 첫째, 대화형(Dialogue) 데이터이어야 한다. 둘째, 가상 비서가 특정 도메인에 특화되어 있다면 필요한 도메인 지식을 반영하는 미세 조정 데이터를 모으도록 노력해야 합니다. 셋째, 고객 지원의 경우처럼 애플리케이션에서 자주 반복되는 일반적인 흐름과 요청이 있는 경우 이러한 다양한 예를 교육 데이터에 통합해 보세요. 다음 표는 대화형 미세 조정 데이터의 샘플을 보여줍니다. ChatBot용 3K 대화 데이터세트, Kaggle에서 무료로 사용할 수 있습니다.
대화형 데이터를 수동으로 생성하는 것은 비용이 많이 드는 작업이 될 수 있습니다. 데이터를 생성하는 데 도움이 되는 크라우드소싱과 LLM을 사용하는 것은 규모를 확장하는 두 가지 방법입니다. 대화 데이터가 수집되면 대화를 평가하고 주석을 달아야 합니다. 이를 통해 모델에 긍정적인 예와 부정적인 예를 모두 표시하고 "올바른" 대화의 특성을 포착하도록 유도할 수 있습니다. 평가는 절대 점수 또는 서로 다른 옵션의 순위로 이루어질 수 있습니다. 후자의 접근 방식은 더 정확한 미세 조정 데이터로 이어집니다. 왜냐하면 인간은 일반적으로 여러 옵션을 개별적으로 평가하는 것보다 순위를 매기는 데 더 능숙하기 때문입니다.
데이터가 준비되면 모델을 미세 조정하고 추가 기능으로 모델을 강화할 수 있습니다. 다음 섹션에서는 미세 조정, 메모리 및 의미 검색의 추가 정보 통합, 에이전트를 대화 시스템에 연결하여 특정 작업을 실행할 수 있는 기능을 살펴보겠습니다.
3. 대화 시스템 조립
일반적인 대화형 시스템은 LLM, 메모리, 외부 데이터 소스 등 시스템의 구성 요소와 기능을 조정하고 조정하는 대화형 에이전트로 구축됩니다. 대화형 AI 시스템의 개발은 매우 실험적이고 실증적인 작업이며, 개발자는 데이터 최적화, 미세 조정 전략 개선, 추가 구성 요소 및 개선 사항 사용, 결과 테스트 사이를 끊임없이 오가게 됩니다. . 제품 관리자, UX 디자이너 등 기술팀이 아닌 팀원들도 지속적으로 제품을 테스트할 예정입니다. 고객 발견 활동을 기반으로 미래 사용자의 대화 스타일과 내용을 예측할 수 있는 좋은 위치에 있으며 이러한 지식을 적극적으로 제공해야 합니다.
3.1 LLM에게 대화 기술 가르치기
미세 조정을 위해서는 미세 조정 데이터(섹션 2 참조)와 사전 훈련된 LLM이 필요합니다. LLM은 이미 언어와 세계에 대해 많은 것을 알고 있으므로 우리의 과제는 그들에게 대화의 원리를 가르치는 것입니다. 미세 조정에서 대상 출력은 텍스트이며 모델은 대상과 최대한 유사한 텍스트를 생성하도록 최적화됩니다. 지도형 미세 조정을 위해서는 먼저 모델이 수행할 대화형 AI 작업을 명확하게 정의하고, 데이터를 수집하고, 미세 조정 프로세스를 실행 및 반복해야 합니다.
LLM에 대한 과대광고로 인해 다양한 미세 조정 방법이 등장했습니다. 대화를 미세 조정하는 전통적인 예를 보려면 LaMDA 모델에 대한 설명을 참조하세요.[1] LaMDA는 두 단계로 미세 조정되었습니다. 첫째, 대화 데이터는 모델 대화 기술("생성적" 미세 조정)을 가르치는 데 사용됩니다. 그런 다음 데이터 평가 중에 주석자가 생성한 레이블은 민감성, 특이성, 흥미로움 및 안전성("차별적" 미세 조정)을 포함하는 원하는 속성에 따라 모델의 출력을 평가할 수 있는 분류기를 훈련하는 데 사용됩니다. 그런 다음 이러한 분류자는 이러한 속성에 대한 모델의 동작을 조정하는 데 사용됩니다.

또한, 결과를 신뢰할 수 있는 외부 정보에 근거하는 능력인 사실 기반은 LLM의 중요한 특성입니다. 사실적 근거를 보장하고 환각을 최소화하기 위해 LaMDA는 외부 지식이 필요할 때마다 외부 정보 검색 시스템에 대한 호출이 포함된 데이터 세트로 미세 조정되었습니다. 따라서 모델은 사용자가 새로운 지식이 필요한 쿼리를 할 때마다 사실 정보를 먼저 검색하도록 학습했습니다.
또 다른 인기 있는 미세 조정 기술은 RLHF(인간 피드백을 통한 강화 학습)[2]입니다. RLHF는 간단하지만 인위적인 다음 토큰 예측 작업에서 주어진 의사소통 상황에서 인간 선호도를 학습하는 방향으로 LLM의 학습 프로세스를 "리디렉션"합니다. 이러한 인간 선호도는 훈련 데이터에 직접 인코딩됩니다. 주석 처리 과정에서 인간에게는 프롬프트가 표시되고 원하는 응답을 작성하거나 일련의 기존 응답에 순위를 매깁니다. 그런 다음 LLM의 동작은 인간의 선호도를 반영하도록 최적화됩니다.
3.2 외부 데이터 추가 및 의미 검색
모델을 미세 조정하기 위해 대화를 컴파일하는 것 외에도 대화 중에 활용할 수 있는 특수 데이터로 시스템을 향상시키고 싶을 수도 있습니다. 예를 들어, 시스템은 특허나 과학 논문과 같은 외부 데이터나 고객 프로필이나 기술 문서와 같은 내부 데이터에 액세스해야 할 수 있습니다. 이는 일반적으로 의미론적 검색(검색 증강 생성 또는 RAG라고도 함)을 통해 수행됩니다[3]. 추가 데이터는 의미론적 임베딩 형태로 데이터베이스에 저장됩니다(참조: 이 문서 임베딩 및 추가 참조에 대한 설명) 사용자 요청이 들어오면 전처리를 거쳐 의미론적 임베딩으로 변환됩니다. 그런 다음 의미 체계 검색을 통해 요청과 가장 관련성이 높은 문서를 식별하고 이를 프롬프트의 컨텍스트로 사용합니다. 추가 데이터를 의미 검색과 통합하면 환각을 줄이고 더욱 유용하고 사실에 근거한 응답을 제공할 수 있습니다. 임베딩 데이터베이스를 지속적으로 업데이트하면 미세 조정 프로세스를 지속적으로 다시 실행하지 않고도 시스템의 지식과 응답을 최신 상태로 유지할 수 있습니다.
3.3 기억과 맥락 인식
파티에 가서 변호사인 피터를 만났다고 상상해 보세요. 당신은 흥분하여 현재 구축하려는 법적 챗봇을 홍보하기 시작합니다. 피터는 흥미로워보이고 당신 쪽으로 몸을 기울이고, 음, 고개를 끄덕입니다. 어느 시점에서 당신은 그가 당신의 앱을 사용하고 싶은지에 대한 그의 의견을 원합니다. 당신의 웅변을 보상하는 유익한 설명 대신에 "음... 이 앱이 또 뭘 하고 있던 거지?"라는 말을 듣게 됩니다.
인간 사이의 암묵적인 의사소통 계약은 우리가 대화 상대의 말을 듣고 상호작용 중에 공동 창조하는 맥락에 따라 우리 자신의 언어 행위를 구축한다는 것을 전제로 합니다. 사회적 환경에서 이러한 공동 이해의 출현은 유익하고 풍요로운 대화의 특징입니다. 레스토랑 테이블을 예약하거나 기차표를 구매하는 등 보다 일상적인 환경에서는 작업을 수행하고 사용자에게 기대되는 가치를 제공하기 위해 절대적으로 필요합니다. 이를 위해서는 어시스턴트가 현재 대화의 기록뿐만 아니라 과거 대화의 기록도 알아야 합니다. 예를 들어 사용자가 대화를 시작할 때마다 사용자의 이름 및 기타 개인 세부 정보를 반복해서 요청해서는 안 됩니다.
상황 인식을 유지하는 데 따른 과제 중 하나는 상호 참조 해결, 즉 대명사가 어떤 개체를 참조하는지 이해하는 것입니다. 인간은 언어를 해석할 때 직관적으로 많은 상황적 단서를 사용합니다. 예를 들어, 어린 아이에게 "빨간색 상자에서 녹색 공을 꺼내서 나에게 가져오세요"라고 말하면 아이는 당신이 공을 의미한다는 것을 알게 될 것입니다. , 상자가 아닙니다. 가상 비서의 경우 이 작업은 다음 대화에서 설명하는 것처럼 다소 어려울 수 있습니다.
조수: 감사합니다. 이제 항공편을 예약하겠습니다. 비행기 기내식도 주문하시겠습니까?
사용자 : 음… 원하는지 나중에 결정할 수 있나요?
조수: 죄송합니다. 이 항공편은 나중에 변경하거나 취소할 수 없습니다.
여기서 어시스턴트는 대명사가 무엇인지 인식하지 못합니다. it 사용자가 비행편이 아닌 식사를 언급하므로 이러한 오해를 바로잡기 위해 또 다른 반복이 필요합니다.
3.4 추가 가드레일
때로는 최고의 LLM조차도 잘못된 행동과 환각을 느낄 수 있습니다. 많은 경우 환각은 단순한 정확성 문제입니다. 그리고 어떤 AI도 100% 정확할 수는 없다는 사실을 받아들여야 합니다. 다른 AI 시스템에 비해 사용자와 AI 사이의 '거리'는 다소 작습니다. 단순한 정확성 문제는 독성이 있거나 차별적이거나 일반적으로 해로운 것으로 인식되는 문제로 빠르게 변할 수 있습니다. 또한 LLM은 개인 정보 보호에 대한 본질적인 이해가 없기 때문에 개인 식별 정보(PII)와 같은 민감한 데이터를 공개할 수도 있습니다. 추가 가드레일을 사용하면 이러한 동작에 대처할 수 있습니다. Guardrails AI, Rebuff, NeMo Guardrails 및 Microsoft Guidance와 같은 도구를 사용하면 LLM 출력에 대한 추가 요구 사항을 공식화하고 원치 않는 출력을 차단하여 시스템의 위험을 제거할 수 있습니다.
대화형 AI에서는 여러 아키텍처가 가능합니다. 다음 스키마는 프롬프트 구성과 가드레일도 담당하는 대화형 에이전트에 의해 미세 조정된 LLM, 외부 데이터 및 메모리가 어떻게 통합될 수 있는지에 대한 간단한 예를 보여줍니다.

4. 사용자 경험과 대화형 디자인
대화형 인터페이스의 매력은 다양한 애플리케이션에서의 단순성과 일관성에 있습니다. 사용자 인터페이스의 미래가 모든 앱이 거의 동일하게 보이는 것이라면 UX 디자이너의 직업은 불운한 것일까요? 확실히 그렇지 않습니다. 대화는 LLM에게 가르쳐야 하는 기술이므로 사용자에게 도움이 되고 자연스럽고 편안한 대화를 수행할 수 있습니다. 좋은 대화형 디자인은 인간 심리학, 언어학, UX 디자인에 대한 지식을 결합할 때 탄생합니다. 다음에서는 대화 시스템을 구축할 때 먼저 두 가지 기본 선택, 즉 음성 및/또는 채팅을 사용할지 여부와 시스템의 더 큰 컨텍스트를 고려할 것입니다. 그런 다음 대화 자체를 살펴보고 도움이 되고 협력적인 대화에 참여하도록 가르치면서 어시스턴트의 성격을 어떻게 디자인할 수 있는지 살펴보겠습니다.
4.1 음성 대 채팅
대화형 인터페이스는 채팅이나 음성을 사용하여 구현할 수 있습니다. 간단히 말해서 음성은 더 빠르며 채팅을 통해 사용자는 비공개를 유지하고 풍부한 UI 기능의 이점을 누릴 수 있습니다. 두 가지 옵션에 대해 좀 더 자세히 살펴보겠습니다. 이는 대화형 앱을 구축할 때 직면하게 될 첫 번째이자 가장 중요한 결정 중 하나이기 때문입니다.
두 가지 대안 중 하나를 선택하려면 먼저 앱이 사용될 물리적 설정을 고려하세요. 예를 들어, Nuance Communications에서 제공하는 것과 같은 자동차의 거의 모든 대화 시스템이 음성을 기반으로 하는 이유는 무엇입니까? 운전자의 손은 이미 바빠서 스티어링 휠과 키보드 사이를 지속적으로 전환할 수 없기 때문입니다. 이는 사용자가 앱을 사용하는 동안 활동 흐름을 유지하려는 요리와 같은 다른 활동에도 적용됩니다. 자동차와 주방은 대부분 개인 공간이므로 사용자는 개인 정보 보호나 다른 사람을 귀찮게 하는 것에 대해 걱정하지 않고 음성 상호 작용의 즐거움을 경험할 수 있습니다. 이와 대조적으로 사무실, 도서관, 기차역 등 공공 장소에서 앱을 사용하는 경우에는 음성을 먼저 선택하지 않을 수도 있습니다.
물리적 환경을 이해한 후 감정적인 측면을 고려하십시오. 음성은 어조, 분위기, 성격을 전달하기 위해 의도적으로 사용될 수 있습니다. 이것이 귀하의 상황에 가치를 더합니까? 여가용 앱을 구축하는 경우 음성은 재미있는 요소를 증가시킬 수 있는 반면, 정신 건강 보조자는 더 많은 공감을 수용하고 잠재적으로 문제가 있는 사용자에게 더 큰 표현의 범위를 허용할 수 있습니다. 대조적으로, 앱이 거래나 고객 서비스와 같은 전문적인 환경에서 사용자를 지원할 경우 익명의 텍스트 기반 상호 작용이 보다 객관적인 결정에 기여하고 지나치게 감정적인 경험을 디자인하는 번거로움을 덜어줄 수 있습니다.
다음 단계로 기능에 대해 생각해 보세요. 텍스트 기반 인터페이스를 사용하면 이미지와 같은 다른 미디어와 버튼과 같은 그래픽 UI 요소를 사용하여 대화를 풍부하게 할 수 있습니다. 예를 들어, 전자상거래 도우미에서 사진과 구조화된 설명을 게시하여 제품을 제안하는 앱은 음성을 통해 제품을 설명하고 잠재적으로 식별자를 제공하는 앱보다 사용자에게 훨씬 더 친숙할 것입니다.
마지막으로 음성 UI 구축에 따른 추가적인 디자인 및 개발 과제에 대해 이야기해 보겠습니다.
- 사용자 입력이 LLM 및 NLP(자연어 처리)로 처리되기 전에 발생하는 추가 음성 인식 단계가 있습니다.
- 음성은 보다 개인적이고 감정적인 의사소통 매체입니다. 따라서 가상 비서 뒤에 일관되고 적절하며 즐거운 페르소나를 디자인하기 위한 요구 사항이 더 높으며 음색과 같은 "음성 디자인"의 추가 요소를 고려해야 합니다. , 스트레스, 어조, 말하기 속도.
- 사용자는 음성 대화가 인간 대화와 동일한 속도로 진행되기를 기대합니다. 음성을 통해 자연스러운 상호작용을 제공하려면 채팅보다 훨씬 짧은 대기 시간이 필요합니다. 인간 대화에서 턴 사이의 일반적인 간격은 200밀리초입니다. — 파트너의 연설을 들으면서 턴 구성을 시작하기 때문에 이러한 신속한 응답이 가능합니다. 음성 어시스턴트는 상호작용에서 이 정도의 유창함을 갖춰야 합니다. 대조적으로, 챗봇의 경우 몇 초의 시간 범위와 경쟁해야 하며 일부 개발자는 대화가 인간 사이의 입력된 채팅처럼 느껴지도록 추가 지연을 도입하기도 합니다.
- 음성을 통한 통신은 선형적이고 일회성 기업입니다. 사용자가 말한 내용을 이해하지 못한 경우 지루하고 오류가 발생하기 쉬운 설명 루프에 빠지게 됩니다. 따라서 차례는 최대한 간결하고 명확하며 유익해야 합니다.
음성 솔루션을 선택하는 경우 채팅에 비해 장점을 명확하게 이해할 뿐만 아니라 이러한 추가 문제를 해결할 수 있는 기술과 리소스도 갖추고 있는지 확인하세요.
4.2 대화형 AI는 어디에 살까요?
이제 대화형 AI를 통합할 수 있는 더 큰 맥락을 고려해 보겠습니다. 우리 모두는 회사 웹사이트의 챗봇, 즉 회사 웹사이트를 열 때 팝업으로 나타나는 화면 오른쪽의 위젯에 익숙합니다. 개인적으로 저는 닫기 버튼을 찾는 것이 직관적인 반응인 경우가 많습니다. 왜 그런 겁니까? 이 봇과 "대화"하려는 초기 시도를 통해 나는 그들이 더 구체적인 정보 요구 사항을 충족할 수 없다는 것을 알게 되었고 결국에는 여전히 웹 사이트를 샅샅이 뒤져야 합니다. 이 이야기의 교훈? 멋지고 트렌디하기 때문에 챗봇을 구축하지 마십시오. 오히려 사용자를 위한 추가적인 가치를 창출할 수 있다고 확신하기 때문에 구축하세요.
회사 웹사이트의 논란의 여지가 있는 위젯 외에도 LLM을 통해 가능해진 보다 일반적인 챗봇을 통합할 수 있는 몇 가지 흥미로운 상황이 있습니다.
- 부조종사: 이러한 도우미는 프로그래밍을 위한 GitHub CoPilot과 같은 특정 프로세스 및 작업을 안내하고 조언합니다. 일반적으로 부조종사는 특정 응용 프로그램(또는 관련 응용 프로그램의 소규모 제품군)에 "연결"됩니다.
- 합성 인간 (또한 디지털 인간): 이 생물체는 디지털 세계에서 실제 인간을 "모방"합니다. 그들은 인간처럼 보이고, 행동하고, 말하기 때문에 풍부한 대화 능력도 필요합니다. 합성 인간은 게임, 증강 현실 및 가상 현실과 같은 몰입형 애플리케이션에 자주 사용됩니다.
- 디지털 쌍둥이: 디지털 트윈은 공장, 자동차, 엔진 등 실제 프로세스와 사물의 디지털 "복사본"입니다. 이는 실제 객체의 설계와 동작을 시뮬레이션, 분석 및 최적화하는 데 사용됩니다. 디지털 트윈과의 자연어 상호 작용을 통해 데이터와 모델에 더욱 원활하고 다양하게 액세스할 수 있습니다.
- 데이터베이스: 요즘에는 투자 추천, 코드 조각, 교육 자료 등 모든 주제에 대한 데이터를 사용할 수 있습니다. 종종 어려운 점은 특정 상황에서 사용자에게 필요한 매우 구체적인 데이터를 찾는 것입니다. 데이터베이스에 대한 그래픽 인터페이스는 너무 거칠거나 끝없는 검색 및 필터 위젯으로 덮여 있습니다. SQL 및 GraphQL과 같은 다목적 쿼리 언어는 해당 기술을 갖춘 사용자만 액세스할 수 있습니다. 대화형 솔루션을 통해 사용자는 자연어로 데이터를 쿼리할 수 있으며, 요청을 처리하는 LLM은 자동으로 해당 쿼리 언어로 변환합니다(참조: 이 문서 Text2SQL에 대한 설명)을 참조하세요.
4.3 어시스턴트에게 개성 각인하기
인간으로서 우리는 의인화하도록 되어 있습니다. 즉 인간과 막연하게 닮은 것을 볼 때 추가적인 인간 특성을 부여하도록 되어 있습니다. 언어는 인류의 가장 독특하고 매혹적인 능력 중 하나이며 대화의 산물은 자동으로 인간과 연관됩니다. 사람들은 화면이나 장치 뒤에 있는 사람을 상상할 것입니다. 그리고 이 특정 사람을 사용자의 상상에 맡기지 않고 오히려 제품 및 브랜드와 일치하는 일관된 개성을 부여하는 것이 좋습니다. 이러한 과정을 '페르소나 디자인'이라고 합니다.
페르소나 디자인의 첫 번째 단계는 페르소나가 보여주고 싶은 캐릭터 특성을 이해하는 것입니다. 이상적으로 이는 훈련 데이터 수준에서 이미 수행되었습니다. 예를 들어 RLHF를 사용할 때 모델을 편향시키기 위해 유용성, 공손함, 재미 등과 같은 특성에 따라 데이터 순위를 매기도록 주석자에게 요청할 수 있습니다. 원하는 특성. 이러한 특성은 브랜드 속성과 일치하여 제품 경험을 통해 지속적으로 브랜드를 홍보하는 일관된 이미지를 만들 수 있습니다.
일반적인 특성 외에도 가상 비서가 "행복한 경로"를 넘어서는 특정 상황을 어떻게 처리할지에 대해서도 생각해야 합니다. 예를 들어, 범위를 벗어나는 사용자 요청에 어떻게 응답하고, 자신에 대한 질문에 응답하고, 욕설이나 저속한 언어를 처리합니까?
데이터 주석 작성자와 대화 디자이너가 사용할 수 있는 페르소나에 대한 명시적인 내부 지침을 개발하는 것이 중요합니다. 이를 통해 목적에 맞는 방식으로 페르소나를 디자인하고 애플리케이션이 여러 번 반복되고 개선될 때 팀 전체와 시간이 지남에 따라 일관성을 유지할 수 있습니다.
4.4 '협력의 원칙'을 바탕으로 도움이 되는 대화 만들기
실제로 사람과 대화를 나누다가 벽돌담에 대고 대화하는 듯한 느낌을 받은 적이 있나요? 때때로 우리는 대화 파트너가 대화를 성공으로 이끄는 데 관심이 없다는 것을 알게 됩니다. 다행스럽게도 대부분의 경우 상황이 더 순조롭게 진행되어 인간은 언어 철학자 폴 그라이스가 제시한 '협력의 원리'를 직관적으로 따를 것입니다. 이 원칙에 따르면, 서로 성공적으로 의사소통하는 인간은 양, 질, 관련성, 방식이라는 네 가지 격언을 따릅니다.
수량의 최대치
수량의 최대치는 화자에게 정보를 제공하고 필요에 따라 정보를 제공하도록 요구합니다. 가상 비서 측면에서 이는 대화를 적극적으로 진행하는 것을 의미하기도 합니다. 예를 들어 전자상거래 패션 앱의 다음 코드를 살펴보세요.
조수: 어떤 종류의 의류 품목을 찾고 계시나요?
사용자 : 나는 오렌지색 드레스를 찾고 있어요.
어시스턴트: 하지 마세요: 죄송합니다. 지금은 주황색 드레스가 없습니다.
해야 할 일: 죄송합니다. 주황색 드레스는 없지만 노란색 드레스는 훌륭하고 매우 편안합니다. …
사용자는 적절한 항목을 사용하여 앱을 떠나기를 원합니다. 정확한 설명에 맞는 항목이 없다고 대화를 중단하면 성공 가능성이 사라집니다. 그러나 앱이 대체 항목에 대한 제안을 제공하면 더 유용해 보이고 성공적인 상호 작용 옵션을 열어 둘 것입니다.
특히 음성 상호 작용에서는 사용자에게 성공을 위해 필요할 수 있는 모든 정보를 제공하는 동시에 상호 작용을 흐리게 할 수 있는 불필요한 정보로 사용자를 압도하지 않는 것 사이에서 올바른 균형을 찾는 것이 중요합니다.
품질의 맥심
품질의 격률은 화자에게 진실을 요구하고, 거짓이라고 생각하거나 적절한 증거가 부족한 것을 말하지 말 것을 요구합니다. 여기에는 많은 주관성과 개인적 신념이 관련되어 있으므로 이 격언을 LLM에 직접 투영할 수는 없습니다. 앞서 살펴보았듯이 LLM은 환각을 느끼는 경향이 있으며 대화가 덜 친숙한 영역으로 흘러갈 때 이러한 위험은 특히 높습니다. 오해의 소지가 있는 진술을 방지하고 대화를 다시 정상화하기 위해 추가 가드레일을 사용할 수 있습니다.
관련성 최대치
관련성의 격언은 우리에게 - 음, 관련성이 있을 것을 요구합니다. 전제 조건으로 가상 비서는 사용자의 진정한 의도를 이해해야 합니다. 다음은 이 규칙을 위반하는 항공사 보조원의 예입니다.
사용자 : 내일 아침 베를린에서 취리히로 가는 비행기가 필요해요.
조수: 알겠습니다. 내일 아침 베를린발 취리히행 항공편을 다음과 같이 찾았습니다. BZ36294편은 오전 6.30시 8분에 베를린을 출발해 오전 96294시에 취리히에 도착합니다. BZ8편은 오전 9.30시에 베를린을 출발해 오전 96294시 8분에 도착합니다. BZ9.30편은 오전 95614시에 베를린을 출발해 오전 11시 12.30분에 취리히에 도착합니다. BZ11.45편은 오전 3시에 베를린을 출발해 오후 XNUMX시 XNUMX분에 취리히에 도착합니다. 연결 항공편의 가능성도 있습니다. 이 경우 오전 XNUMX시 XNUMX분에 베를린을 떠나 오후 XNUMX시에 취리히에 도착합니다.
사용자 : 죄송합니다... 다시 한 번 말씀해 주시겠어요?
어시스턴트는 관련성이 없을 수도 있는 자세한 정보로 사용자를 압도합니다. 이를 분할하고 사용자가 검색 공간을 제한하도록 안내하면 대화를 소화하기가 훨씬 쉬워집니다.
사용자 : 내일 아침 베를린에서 취리히로 가는 비행기가 필요해요.
조수: 알겠습니다. 오전 6.30시 8분, 11시, XNUMX시에 출발하는 항공편을 찾았습니다. 몇 시에 떠나시겠어요?
사용자 : 오전 9시 이전에 취리히에 도착해야 해요.
조수: 알겠습니다. BZ36294 항공편을 타시면 됩니다. 6.30시 8분에 출발해서 오전 XNUMX시에 도착합니다. 제가 당신을 위해 표를 사야 할까요?
사용자 : 네, 고마워요.
매너의 격언
마지막으로, 매너의 격률은 우리의 언어 행위가 명확하고 간결하며 질서정연해야 하며 표현의 모호함과 모호함을 피해야 한다고 말합니다. 가상 비서는 기술적이거나 내부적인 전문 용어를 피하고 간단하고 보편적으로 이해할 수 있는 공식을 선호해야 합니다.
Grice의 원칙은 특정 도메인과 관계없이 모든 대화에 유효하지만, 대화에 대해 특별히 교육받지 않은 LLM은 원칙을 충족하지 못하는 경우가 많습니다. 따라서 훈련 데이터를 컴파일할 때 모델이 이러한 원칙을 학습할 수 있도록 충분한 대화 샘플을 보유하는 것이 중요합니다.
대화형 디자인 영역은 상당히 빠르게 발전하고 있습니다. 이미 AI 제품을 구축하고 있거나 AI 분야의 진로에 대해 생각하고 있다면 이 주제를 더 깊이 파고들기를 권장합니다([5] 및 [6]의 훌륭한 소개 참조). AI가 상품으로 변하면서 방어 가능한 데이터 전략과 함께 좋은 디자인은 AI 제품의 두 가지 중요한 차별화 요소가 될 것입니다.
요약
기사의 주요 내용을 요약해 보겠습니다. 또한 그림 5에서는 참조용으로 다운로드할 수 있는 주요 사항이 포함된 "치트 시트"를 제공합니다.
- LLM은 대화형 AI를 향상시킵니다. LLM(대형 언어 모델)은 다양한 산업 및 사용 사례에 걸쳐 대화형 AI 애플리케이션의 품질과 확장성을 크게 향상시켰습니다.
- 대화형 AI는 유사한 사용자 요청(예: 고객 서비스)이 많거나 대량의 구조화되지 않은 데이터(예: 지식 관리)에 액세스해야 하는 애플리케이션에 많은 가치를 추가할 수 있습니다.
- 데이터: 대화 작업을 위해 LLM을 미세 조정하려면 실제 상호 작용을 밀접하게 반영하는 고품질 대화 데이터가 필요합니다. 크라우드소싱 및 LLM 생성 데이터는 데이터 수집 규모를 확장하는 데 유용한 리소스가 될 수 있습니다.
- 시스템 통합: 대화형 AI 시스템을 개발하는 것은 지속적인 데이터 최적화, 미세 조정 전략 및 구성 요소 통합을 포함하는 반복적이고 실험적인 프로세스입니다.
- LLM에게 대화 기술 가르치기: LLM을 미세 조정하려면 특정 의사소통 의도와 상황을 인식하고 대응하도록 훈련하는 것이 포함됩니다.
- 의미론적 검색으로 외부 데이터 추가: 의미론적 검색을 사용하여 외부 및 내부 데이터 소스를 통합하면 보다 상황에 맞는 관련 정보를 제공하여 AI의 응답이 향상됩니다.
- 기억 및 상황 인식: 효과적인 대화 시스템은 의미 있고 일관된 응답을 제공하기 위해 현재 대화 및 과거 상호 작용의 기록을 추적하는 등 상황 인식을 유지해야 합니다.
- 가드레일 설정: 책임 있는 행동을 보장하기 위해 대화형 AI 시스템은 부정확성, 환각 및 개인정보 침해를 방지하는 가드레일을 사용해야 합니다.
- 페르소나 디자인: 응집력 있고 브랜드화된 사용자 경험을 만들기 위해서는 대화 도우미를 위한 일관된 페르소나를 디자인하는 것이 필수적입니다. 페르소나 특성은 제품 및 브랜드 속성과 일치해야 합니다.
- 음성 대 채팅: 음성과 채팅 인터페이스 중 하나를 선택하는 것은 물리적 환경, 감정적 맥락, 기능, 디자인 과제와 같은 요소에 따라 달라집니다. 대화형 AI의 인터페이스를 결정할 때 이러한 요소를 고려하십시오.
- 다양한 맥락에서의 통합: 대화형 AI는 부조종사, 합성 인간, 디지털 트윈, 데이터베이스 등 각각 특정 사용 사례와 요구 사항이 있는 다양한 맥락에서 통합될 수 있습니다.
- 협력 원칙 준수: 대화의 양, 질, 관련성 및 방식의 원칙을 따르면 대화형 AI와의 상호 작용이 더욱 유용하고 사용자 친화적이 될 수 있습니다.

참고자료
[1] Heng-Tze Chen 외. 2022. LaMDA: 모든 것을 위한 안전하고 근거 있는 고품질 대화 모델을 향하여.
[2] 오픈AI. 2022. ChatGPT: 대화를 위한 언어 모델 최적화. 13년 2022월 XNUMX일에 확인함.
[3] 패트릭 루이스 외. 2020. 지식 집약적 NLP 작업을위한 검색 증강 생성.
[4] 폴 그라이스. 1989. 말의 방식에 관한 연구.
[5] 캐시 펄. 2016. 음성 사용자 인터페이스 디자인.
[6] 마이클 코헨 외. 2004. 음성 사용자 인터페이스 디자인.
참고: 별도의 언급이 없는 한 모든 이미지는 작성자의 것입니다.
이 기사는 원래에 게시되었습니다. 데이터 과학을 향해 저자의 허락을 받아 TOPBOTS에 다시 게시했습니다.
이 기사를 즐기십니까? 더 많은 AI 연구 업데이트에 가입하십시오.
이와 같은 더 많은 요약 기사를 발표하면 알려 드리겠습니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.topbots.com/redefining-conversational-ai-with-large-language-models/

