会話型人工知能 (AI) アシスタントは、クエリを最適な AI 機能にインテリジェントにルーティングすることで、正確なリアルタイム応答を提供するように設計されています。 AWS の生成 AI サービスを使用すると、 アマゾンの岩盤、開発者は、ユーザーのリクエストを専門的に管理し、応答するシステムを作成できます。 Amazon Bedrock は、単一の API を使用して、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon などの主要 AI 企業の高性能基盤モデル (FM) の選択肢を提供するフルマネージド サービスです。セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築するために必要な機能。
この投稿では、AI アシスタントを開発するための 2 つの主なアプローチを評価します。1 つは、次のようなマネージド サービスの使用です。 Amazon Bedrock のエージェント、および次のようなオープンソース テクノロジーを採用しています。 ラングチェーン。それぞれの利点と課題を検討し、ニーズに合わせて最適な方法を選択できるようにします。
AIアシスタントとは何ですか?
AI アシスタントは、自然言語クエリを理解し、さまざまなツール、データ ソース、API と対話して、ユーザーに代わってタスクを実行したり情報を取得したりするインテリジェント システムです。効果的な AI アシスタントは、次の主要な機能を備えています。
- 自然言語処理 (NLP) と会話フロー
- ナレッジベースの統合とセマンティック検索により、会話のコンテキストのニュアンスに基づいて関連情報を理解して取得します。
- データベースクエリやカスタムなどのタスクの実行 AWSラムダ 機能
- 特殊な会話やユーザーリクエストの処理
モノのインターネット (IoT) デバイス管理を例として、AI アシスタントの利点を示します。このユースケースでは、AI は技術者がデータを取得したりタスクを自動化したりするコマンドを使用して機械を効率的に管理し、製造現場の業務を合理化するのに役立ちます。
Agent for Amazon Bedrock アプローチ
Amazon Bedrock のエージェント を使用すると、企業のシステムとデータ ソース全体で複数ステップのタスクを実行できる生成 AI アプリケーションを構築できます。次の主要な機能を提供します。
- 指示、API 詳細、データ ソース情報からプロンプトを自動作成し、数週間にわたるプロンプト エンジニアリング作業を節約します。
- エージェントを企業のデータ ソースに安全に接続し、関連する応答を提供する取得拡張生成 (RAG)
- リクエストを論理シーケンスに分割し、必要な API を呼び出すことによる、複数ステップのタスクのオーケストレーションと実行
- 思考連鎖 (CoT) トレースを通じてエージェントの推論を可視化し、トラブルシューティングとモデルの動作の制御を可能にします。
- エージェントに対する制御を強化するために、自動生成されたプロンプト テンプレートを変更するプロンプト エンジニアリング機能
Agent for Amazon Bedrock を使用できます。 Amazon Bedrock のナレッジベース 複雑なルーティングのユースケースに対応する AI アシスタントを構築してデプロイします。これらは、インフラストラクチャ管理の簡素化、スケーラビリティの強化、セキュリティの向上、未差別の重労働の削減により、開発者と組織に戦略的な利点をもたらします。また、ルーティング ロジック、ベクトル化、メモリが完全に管理されるため、アプリケーション層のコードがより単純になります。
ソリューションの概要
このソリューションでは、Amazon Bedrock で Anthropic の Claude v2.1 を使用する場合の IoT デバイスの管理と操作に合わせて調整された会話型 AI アシスタントが導入されています。 AI アシスタントの中核機能は、「」として知られる包括的な命令セットによって管理されます。 システムプロンプト、その機能と専門分野を概説します。このガイダンスにより、AI アシスタントがデバイス情報の管理から運用コマンドの実行まで、幅広いタスクを確実に処理できるようになります。
システム プロンプトで詳しく説明されているように、これらの機能を備えた AI アシスタントは、構造化されたワークフローに従ってユーザーの質問に対応します。次の図は、このワークフローを視覚的に表現したもので、最初のユーザー操作から最終応答までの各ステップを示しています。

ワークフローは次のステップで構成されます。
- このプロセスは、ユーザーがアシスタントにタスクの実行を要求すると始まります。たとえば、特定の IoT デバイスの最大データ ポイントを要求する
device_xxx。このテキスト入力はキャプチャされ、AI アシスタントに送信されます。 - AI アシスタントはユーザーのテキスト入力を解釈します。提供された会話履歴、アクション グループ、ナレッジ ベースを使用してコンテキストを理解し、必要なタスクを決定します。
- ユーザーの意図が解析されて理解されると、AI アシスタントがタスクを定義します。これは、システム プロンプトおよびユーザーの入力に従ってアシスタントによって解釈される指示に基づいています。
- その後、タスクは一連の API 呼び出しを通じて実行されます。これは次を使用して行われます 反応します プロンプトは、タスクを一連のステップに分割し、順次処理します。
- デバイスメトリクスのチェックには、
check-device-metricsアクション グループ。これには、クエリを実行する Lambda 関数への API 呼び出しが含まれます。 アマゾンアテナ 要求されたデータの場合。 - 開始、停止、再起動などの直接的なデバイスアクションには、
action-on-deviceアクショングループ。Lambda 関数を呼び出します。この関数は、IoT デバイスにコマンドを送信するプロセスを開始します。この投稿では、Lambda 関数は次を使用して通知を送信します。 AmazonシンプルEメールサービス (Amazon SES)。 - Amazon Bedrock のナレッジベースを使用して、埋め込みとして保存されている履歴データから取得します。 AmazonOpenSearchサービス ベクトルデータベース。
- デバイスメトリクスのチェックには、
- タスクが完了すると、Amazon Bedrock FM によって最終応答が生成され、ユーザーに返されます。
- Agent for Amazon Bedrock は、ステートフル セッションを使用して情報を自動的に保存し、同じ会話を維持します。状態は、設定可能なアイドル タイムアウトが経過すると削除されます。
技術概要
次の図は、Agents for Amazon Bedrock を使用して AI アシスタントをデプロイするためのアーキテクチャを示しています。
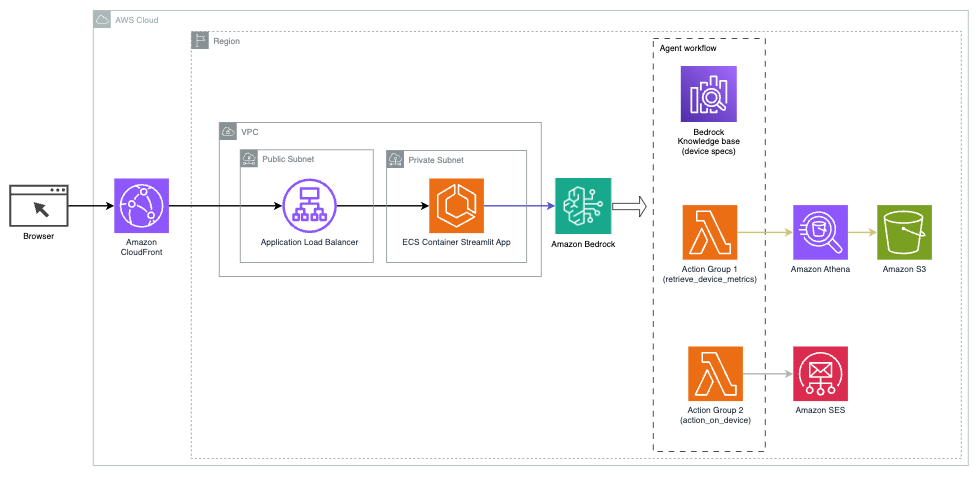
これは次の主要なコンポーネントで構成されます。
- 会話型インターフェース – 会話型インターフェイスでは、機械学習 (ML) およびデータ サイエンス用の視覚的に魅力的なカスタム Web アプリの作成を簡素化するオープンソース Python ライブラリである Streamlit を使用します。でホストされています Amazon エラスティック コンテナ サービス (Amazon ECS) AWSファーゲート、Application Load Balancer を使用してアクセスされます。 Fargate を Amazon ECS で使用して実行できます。 コンテナ サーバー、クラスター、または仮想マシンを管理する必要はありません。
- Amazon Bedrock のエージェント – Agents for Amazon Bedrock は、一連の推論ステップとそれに基づくアクションを通じてユーザーのクエリを完了します。 ReAct プロンプトの表示:
- Amazon Bedrock のナレッジベース – Amazon Bedrock のナレッジベースは、フルマネージドのサービスを提供します RAG AI アシスタントにデータへのアクセスを提供します。私たちのユースケースでは、デバイスの仕様を Amazon シンプル ストレージ サービス (Amazon S3) バケット。これはナレッジ ベースへのデータ ソースとして機能します。
- アクショングループ – これらは、IoT デバイスや他の AWS サービスと対話するために特定の Lambda 関数を呼び出す定義された API スキーマです。
- Amazon Bedrock の Anthropic Claude v2.1 – このモデルはユーザーのクエリを解釈し、タスクのフローを調整します。
- Amazon Titan の埋め込み – このモデルはテキスト埋め込みモデルとして機能し、単一の単語から複雑な文書までの自然言語テキストを数値ベクトルに変換します。これにより、ベクトル検索機能が有効になり、システムはユーザーのクエリと最も関連性の高い知識ベースのエントリを意味的に照合して効果的な検索を行うことができます。
このソリューションは、API 呼び出しに応答してコードを実行する Lambda、データセットをクエリする Athena、ナレッジベースを検索する OpenSearch Service、ストレージ用の Amazon S3 などの AWS サービスと統合されています。これらのサービスは連携して、自然言語コマンドによる IoT デバイスの運用管理のシームレスなエクスペリエンスを提供します。
福利厚生
このソリューションには、次の利点があります。
- 実装の複雑さ:
- Agent for Amazon Bedrock は根底にある複雑さの多くを抽象化し、開発労力を軽減するため、必要なコード行が少なくなります。
- Amazon Bedrock のナレッジベースがベクトル化とストレージを処理するため、OpenSearch Service などのベクトルデータベースの管理が簡素化されます。
- 事前定義されたアクショングループにより、さまざまな AWS サービスとの統合がより合理化されます。
- 開発者の経験:
- Amazon Bedrock コンソールは、迅速な開発、テスト、根本原因分析 (RCA) のためのユーザーフレンドリーなインターフェイスを提供し、全体的な開発者のエクスペリエンスを向上させます。
- 機敏性と柔軟性:
- Agents for Amazon Bedrock を使用すると、新しい FM (Claude 3.0 など) が利用可能になったときにシームレスにアップグレードできるため、ソリューションを常に最新の状態に保つことができます。
- サービスのクォータと制限は AWS によって管理され、インフラストラクチャの監視と拡張のオーバーヘッドが削減されます。
- セキュリティ:
- Amazon Bedrock は、AWS の厳格なセキュリティおよびコンプライアンス基準に準拠したフルマネージド サービスであり、組織のセキュリティ レビューを簡素化できる可能性があります。
Agents for Amazon Bedrock は、会話型 AI アプリケーションを構築するための合理化されたマネージド ソリューションを提供しますが、組織によってはオープンソース アプローチを好む場合があります。このような場合は、次のセクションで説明する LangChain などのフレームワークを使用できます。
LangChain 動的ルーティングのアプローチ
LangChain は、大規模言語モデル (LLM) と動的ルーティング機能の統合を可能にすることで、会話型 AI の構築を簡素化するオープンソース フレームワークです。 LangChain Expression Language (LCEL) を使用すると、開発者は ルーティングこれにより、前のステップの出力が次のステップを定義する非決定的なチェーンを作成できます。ルーティングは、LLM との対話における構造と一貫性を提供するのに役立ちます。
この投稿では、IoT デバイス管理用の AI アシスタントと同じ例を使用します。ただし、主な違いは、システム プロンプトを個別に処理し、各チェーンを別個のエンティティとして扱う必要があることです。ルーティング チェーンは、ユーザーの入力に基づいて宛先チェーンを決定します。決定は、システム プロンプト、チャット履歴、ユーザーの質問を渡すことによって、LLM のサポートを受けて行われます。
ソリューションの概要
次の図は、動的ルーティング ソリューションのワークフローを示しています。

ワークフローは次の手順で構成されます。
- ユーザーは AI アシスタントに質問をします。たとえば、「デバイス 1009 の最大メトリクスは何ですか?」
- LLM は、各質問を同じセッションのチャット履歴とともに評価して、その性質と、どのサブジェクト領域 (SQL、アクション、検索、SME など) に該当するかを判断します。 LLM は入力を分類し、LCEL ルーティング チェーンがその入力を受け取ります。
- ルーター チェーンは入力に基づいて宛先チェーンを選択し、LLM には次のシステム プロンプトが提供されます。
LLM はユーザーの質問とチャット履歴を評価して、クエリの性質とそれがどの主題領域に該当するかを判断します。次に、LLM は入力を分類し、次の形式で JSON 応答を出力します。
ルーター チェーンは、この JSON 応答を使用して、対応する宛先チェーンを呼び出します。主題固有の宛先チェーンが 4 つあり、それぞれに独自のシステム プロンプトがあります。
- SQL 関連のクエリは、データベースと対話するために SQL 宛先チェーンに送信されます。 LCEL を使用して、 SQL チェーン。
- アクション指向の質問は、オペレーションを実行するためにカスタム Lambda 宛先チェーンを呼び出します。 LCEL を使用すると、独自の定義が可能です カスタム関数;この例では、事前定義された Lambda 関数を実行して、解析されたデバイス ID を含むメールを送信する関数です。ユーザー入力の例は、「デバイス 1009 をシャットダウンする」などです。
- 検索を中心としたお問い合わせは、 RAG 情報検索の宛先チェーン。
- 中小企業関連の質問は、専門的な洞察を得るために中小企業/専門家の宛先チェーンに送られます。
- 各宛先チェーンは入力を受け取り、必要なモデルまたは関数を実行します。
- SQL チェーンはクエリの実行に Athena を使用します。
- RAG チェーンは、セマンティック検索に OpenSearch サービスを使用します。
- カスタム Lambda チェーンは、アクションの Lambda 関数を実行します。
- SME/専門家チェーンは、Amazon Bedrock モデルを使用して洞察を提供します。
- 各宛先チェーンからの応答は、LLM によって一貫した洞察に定式化されます。これらの洞察はユーザーに配信され、クエリ サイクルが完了します。
- ユーザー入力と応答は次の場所に保存されます。 Amazon DynamoDB 現在のセッションおよび過去の対話から LLM にコンテキストを提供します。 DynamoDB に保持される情報の期間はアプリケーションによって制御されます。
技術概要
次の図は、LangChain 動的ルーティング ソリューションのアーキテクチャを示しています。
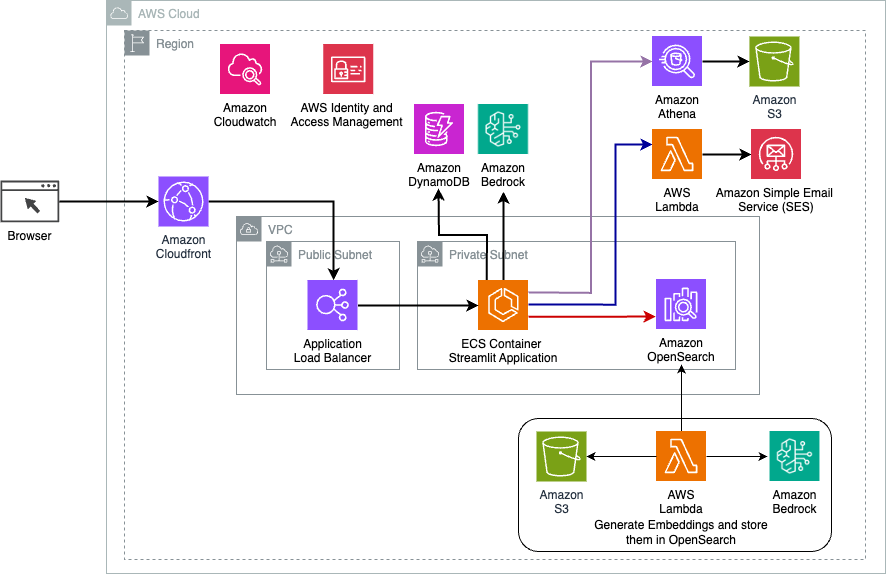
この Web アプリケーションは、Fargate を使用して Amazon ECS でホストされる Streamlit 上に構築されており、Application Load Balancer を使用してアクセスされます。 Amazon Bedrock 上の Anthropic の Claude v2.1 を LLM として使用します。 Web アプリケーションは、LangChain ライブラリを使用してモデルと対話します。また、OpenSearch Service、Athena、DynamoDB などの他のさまざまな AWS サービスと対話して、エンドユーザーのニーズを満たすことができます。
福利厚生
このソリューションには、次の利点があります。
- 実装の複雑さ:
- より多くのコードとカスタム開発が必要ですが、LangChain では、ルーティング ロジックとさまざまなコンポーネントとの統合に対する柔軟性と制御が向上します。
- OpenSearch Service のようなベクター データベースを管理するには、追加のセットアップと構成の作業が必要です。ベクトル化プロセスはコードで実装されます。
- AWS のサービスとの統合には、より多くのカスタム コードと構成が必要になる場合があります。
- 開発者の経験:
- LangChain の Python ベースのアプローチと広範なドキュメントは、Python やオープンソース ツールにすでに慣れている開発者にとって魅力的です。
- 迅速な開発とデバッグには、Amazon Bedrock コンソールを使用する場合と比較して、より多くの手動作業が必要になる場合があります。
- 機敏性と柔軟性:
- LangChain は幅広い LLM をサポートしているため、さまざまなモデルやプロバイダーを切り替えることができ、柔軟性が高まります。
- LangChain のオープンソースの性質により、コミュニティ主導の改善とカスタマイズが可能になります。
- セキュリティ:
- オープンソース フレームワークである LangChain は、組織内でより厳格なセキュリティ レビューと精査を必要とする可能性があり、オーバーヘッドが増加する可能性があります。
まとめ
会話型 AI アシスタントは、業務を合理化し、ユーザー エクスペリエンスを向上させる革新的なツールです。この投稿では、AWS サービスを使用した 2 つの強力なアプローチ、つまりマネージド Agents for Amazon Bedrock と柔軟なオープンソースの LangChain 動的ルーティングについて説明しました。これらのアプローチのどちらを選択するかは、組織の要件、開発設定、および希望するカスタマイズ レベルによって異なります。どのような道をたどっても、AWS を使用すると、ビジネスと顧客のやり取りに革命をもたらすインテリジェントな AI アシスタントを作成できます。
ソリューション コードと導入アセットについては、 GitHubリポジトリでは、各会話型 AI アプローチの詳細な手順に従うことができます。
著者について
 アメール・ハクメ は、ペンシルベニア州に拠点を置く AWS ソリューション アーキテクトです。彼は北東部地域の独立系ソフトウェアベンダー (ISV) と協力して、AWS クラウド上でのスケーラブルで最新のプラットフォームの設計と構築を支援しています。 AI/ML と生成 AI の専門家である Ameer は、お客様がこれらの最先端テクノロジーの可能性を解き放つのを支援します。余暇には、オートバイに乗って家族と充実した時間を過ごすことを楽しんでいます。
アメール・ハクメ は、ペンシルベニア州に拠点を置く AWS ソリューション アーキテクトです。彼は北東部地域の独立系ソフトウェアベンダー (ISV) と協力して、AWS クラウド上でのスケーラブルで最新のプラットフォームの設計と構築を支援しています。 AI/ML と生成 AI の専門家である Ameer は、お客様がこれらの最先端テクノロジーの可能性を解き放つのを支援します。余暇には、オートバイに乗って家族と充実した時間を過ごすことを楽しんでいます。
 シャロン・リー ボストンに拠点を置くアマゾン ウェブ サービスの AI/ML ソリューション アーキテクトであり、AWS でのジェネレーティブ AI アプリケーションの設計と構築に情熱を持っています。彼女は顧客と協力して、AWS AI/ML サービスを活用して革新的なソリューションを実現しています。
シャロン・リー ボストンに拠点を置くアマゾン ウェブ サービスの AI/ML ソリューション アーキテクトであり、AWS でのジェネレーティブ AI アプリケーションの設計と構築に情熱を持っています。彼女は顧客と協力して、AWS AI/ML サービスを活用して革新的なソリューションを実現しています。
 カウサール・カマル アマゾン ウェブ サービスのシニア ソリューション アーキテクトであり、インフラストラクチャの自動化とセキュリティの分野で 15 年以上の経験があります。彼は、クライアントがクラウドでスケーラブルな DevSecOps および AI/ML ソリューションを設計および構築できるよう支援します。
カウサール・カマル アマゾン ウェブ サービスのシニア ソリューション アーキテクトであり、インフラストラクチャの自動化とセキュリティの分野で 15 年以上の経験があります。彼は、クライアントがクラウドでスケーラブルな DevSecOps および AI/ML ソリューションを設計および構築できるよう支援します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

