Dieser Blog wurde gemeinsam mit Josh Reini, Shayak Sen und Anupam Datta von TruEra geschrieben
Amazon SageMaker-JumpStart bietet eine Vielzahl vorab trainierter Basismodelle wie Llama-2 und Mistal 7B, die schnell an einem Endpunkt bereitgestellt werden können. Diese Basismodelle eignen sich gut für generative Aufgaben, von der Erstellung von Texten und Zusammenfassungen über die Beantwortung von Fragen bis hin zur Produktion von Bildern und Videos. Trotz der großen Generalisierungsfähigkeit dieser Modelle gibt es häufig Anwendungsfälle, in denen diese Modelle an neue Aufgaben oder Domänen angepasst werden müssen. Eine Möglichkeit, diesen Bedarf zu decken, besteht darin, das Modell anhand eines kuratierten Ground-Truth-Datensatzes zu bewerten. Nachdem klar ist, dass das Grundmodell angepasst werden muss, können Sie eine Reihe von Techniken verwenden, um dies durchzuführen. Ein beliebter Ansatz ist die Feinabstimmung des Modells mithilfe eines Datensatzes, der auf den Anwendungsfall zugeschnitten ist. Eine Feinabstimmung kann das Basismodell verbessern und seine Wirksamkeit kann erneut anhand des Ground-Truth-Datensatzes gemessen werden. Das Notizbuch zeigt, wie man Modelle mit SageMaker JumpStart verfeinert.
Eine Herausforderung bei diesem Ansatz besteht darin, dass die Erstellung kuratierter Ground-Truth-Datensätze teuer ist. In diesem Beitrag gehen wir diese Herausforderung an, indem wir diesen Workflow um ein Framework für erweiterbare, automatisierte Auswertungen erweitern. Wir beginnen mit einem Basismodell von SageMaker JumpStart und evaluieren es mit TruLens, eine Open-Source-Bibliothek zur Evaluierung und Verfolgung von LLM-Apps (Large Language Model). Nachdem wir den Anpassungsbedarf erkannt haben, können wir die Feinabstimmung in SageMaker JumpStart durchführen und die Verbesserung mit TruLens bestätigen.

TruLens-Auswertungen verwenden eine Abstraktion von Feedback-Funktionen. Diese Funktionen können auf verschiedene Weise implementiert werden, einschließlich Modellen im BERT-Stil, LLMs mit entsprechender Eingabeaufforderung und mehr. TruLens-Integration mit Amazonas Grundgestein ermöglicht Ihnen die Durchführung von Auswertungen mithilfe von LLMs, die bei Amazon Bedrock verfügbar sind. Die Zuverlässigkeit der Amazon Bedrock-Infrastruktur ist besonders wertvoll für die Durchführung von Evaluierungen in der Entwicklung und Produktion.
Dieser Beitrag dient sowohl als Einführung in den Platz von TruEra im modernen LLM-App-Stack als auch als praktischer Leitfaden zur Verwendung Amazon Sage Maker und TruEra zum Bereitstellen, Feinabstimmen und Iterieren von LLM-Apps. Hier ist das Komplette Notizbuch mit Codebeispielen zur Darstellung der Leistungsbewertung mit TruLens
TruEra im LLM-App-Stack
TruEra lebt auf der Observability-Ebene von LLM-Apps. Obwohl neue Komponenten Eingang in die Rechenschicht (Feinabstimmung, Prompt Engineering, Modell-APIs) und die Speicherschicht (Vektordatenbanken) gefunden haben, bleibt der Bedarf an Beobachtbarkeit bestehen. Dieser Bedarf erstreckt sich von der Entwicklung bis zur Produktion und erfordert miteinander verbundene Funktionen zum Testen, Debuggen und zur Produktionsüberwachung, wie in der folgenden Abbildung dargestellt.
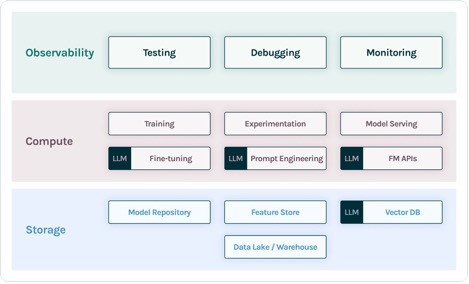
In der Entwicklung können Sie verwenden Open-Source-TruLens um Ihre LLM-Apps in Ihrer Umgebung schnell zu evaluieren, zu debuggen und zu iterieren. Eine umfassende Suite von Bewertungsmetriken, einschließlich LLM-basierter und traditioneller Metriken, die in TruLens verfügbar sind, ermöglicht es Ihnen, Ihre App anhand der Kriterien zu messen, die für die Überführung Ihrer Anwendung in die Produktion erforderlich sind.
In der Produktion können diese Protokolle und Bewertungsmetriken mit der TruEra-Produktionsüberwachung im großen Maßstab verarbeitet werden. Durch die Verbindung der Produktionsüberwachung mit Tests und Debugging können Leistungseinbußen wie Halluzinationen, Sicherheit usw. erkannt und korrigiert werden.
Stellen Sie Fundamentmodelle in SageMaker bereit
Sie können Foundation-Modelle wie Llama-2 in SageMaker mit nur zwei Zeilen Python-Code bereitstellen:
Rufen Sie den Modellendpunkt auf
Nach der Bereitstellung können Sie den bereitgestellten Modellendpunkt aufrufen, indem Sie zunächst eine Nutzlast erstellen, die Ihre Eingaben und Modellparameter enthält:
Dann können Sie diese Nutzlast einfach an die Vorhersagemethode des Endpunkts übergeben. Beachten Sie, dass Sie das Attribut jedes Mal übergeben müssen, um die Endbenutzer-Lizenzvereinbarung zu akzeptieren, wenn Sie das Modell aufrufen:
Bewerten Sie die Leistung mit TruLens
Jetzt können Sie mit TruLens Ihre Auswertung einrichten. TruLens ist ein Observability-Tool, das einen erweiterbaren Satz an Feedback-Funktionen zur Verfolgung und Bewertung von LLM-basierten Apps bietet. Hier sind Feedback-Funktionen unerlässlich, um die Abwesenheit von Halluzinationen in der App zu überprüfen. Diese Feedback-Funktionen werden durch den Einsatz von Standardmodellen von Anbietern wie Amazon Bedrock umgesetzt. Hier sind die Modelle von Amazon Bedrock aufgrund ihrer geprüften Qualität und Zuverlässigkeit im Vorteil. Sie können den Anbieter mit TruLens über den folgenden Code einrichten:
In diesem Beispiel verwenden wir drei Feedback-Funktionen: Antwortrelevanz, Kontextrelevanz und Bodenständigkeit. Diese Auswertungen haben sich schnell zum Standard für die Halluzinationserkennung in kontextbasierten Fragebeantwortungsanwendungen entwickelt und sind besonders nützlich für unbeaufsichtigte Anwendungen, die die überwiegende Mehrheit der heutigen LLM-Anwendungen abdecken.

Lassen Sie uns jede dieser Feedbackfunktionen durchgehen, um zu verstehen, welchen Nutzen sie für uns haben können.
Kontextrelevanz
Der Kontext ist eine entscheidende Eingabe für die Qualität der Antworten unserer Anwendung, und es kann nützlich sein, programmgesteuert sicherzustellen, dass der bereitgestellte Kontext für die Eingabeabfrage relevant ist. Dies ist von entscheidender Bedeutung, da dieser Kontext vom LLM verwendet wird, um eine Antwort zu formulieren, sodass alle irrelevanten Informationen im Kontext zu einer Halluzination verwoben werden könnten. Mit TruLens können Sie die Kontextrelevanz anhand der Struktur des serialisierten Datensatzes bewerten:
Da der für LLMs bereitgestellte Kontext der folgenreichste Schritt einer Retrieval Augmented Generation (RAG)-Pipeline ist, ist die Kontextrelevanz entscheidend für das Verständnis der Qualität von Abrufen. Bei der Zusammenarbeit mit Kunden aus verschiedenen Branchen haben wir mithilfe dieser Auswertung eine Vielzahl von Fehlermodi festgestellt, wie z. B. unvollständiger Kontext, irrelevanter irrelevanter Kontext oder sogar das Fehlen ausreichend verfügbarer Kontexte. Durch die Identifizierung der Art dieser Fehlermodi sind unsere Benutzer in der Lage, ihre Indizierungs- (z. B. Einbettungsmodell und Chunking) und Abrufstrategien (z. B. Satzfensterung und automatische Zusammenführung) anzupassen, um diese Probleme zu entschärfen.
Bodenständigkeit
Nachdem der Kontext abgerufen wurde, wird er von einem LLM in eine Antwort umgewandelt. LLMs neigen oft dazu, von den bereitgestellten Fakten abzuweichen, zu übertreiben oder zu einer korrekt klingenden Antwort zu gelangen. Um die Begründetheit des Antrags zu überprüfen, sollten Sie die Antwort in separate Aussagen unterteilen und unabhängig voneinander nach Beweisen suchen, die die einzelnen Aussagen im abgerufenen Kontext stützen.
Probleme mit der Bodenständigkeit können oft ein nachgelagerter Effekt der Kontextrelevanz sein. Wenn es dem LLM an ausreichendem Kontext mangelt, um eine evidenzbasierte Antwort zu formulieren, ist es wahrscheinlicher, dass es bei dem Versuch, eine plausible Antwort zu generieren, halluziniert. Selbst in Fällen, in denen ein vollständiger und relevanter Kontext bereitgestellt wird, kann es beim LLM zu Problemen mit der Bodenständigkeit kommen. Dies trat insbesondere bei Anwendungen auf, bei denen das LLM in einem bestimmten Stil reagiert oder zur Erledigung einer Aufgabe verwendet wird, für die es nicht gut geeignet ist. Mithilfe von Groundedness-Bewertungen können TruLens-Benutzer LLM-Antworten Anspruch für Anspruch aufschlüsseln, um zu verstehen, wo der LLM am häufigsten halluziniert. Dies hat sich als besonders nützlich erwiesen, um den Weg zur Eliminierung von Halluzinationen durch modellseitige Änderungen (z. B. Aufforderung, Modellauswahl und Modellparameter) aufzuzeigen.
Antwortrelevanz
Schließlich muss die Antwort noch eine hilfreiche Antwort auf die ursprüngliche Frage geben. Sie können dies überprüfen, indem Sie die Relevanz der endgültigen Antwort auf die Benutzereingabe bewerten:
Durch die zufriedenstellende Bewertung dieses Dreiklangs können Sie eine differenzierte Aussage über die Richtigkeit Ihrer Bewerbung treffen; Diese Anwendung ist im Rahmen ihrer Wissensbasis nachweislich frei von Halluzinationen. Mit anderen Worten: Wenn die Vektordatenbank nur genaue Informationen enthält, sind auch die Antworten der kontextbasierten Frage-Antwort-App korrekt.
Ground-Truth-Bewertung
Zusätzlich zu diesen Feedbackfunktionen zur Erkennung von Halluzinationen verfügen wir über einen Testdatensatz, DataBricks-Dolly-15k, was es uns ermöglicht, Ground-Truth-Ähnlichkeit als vierte Bewertungsmetrik hinzuzufügen. Siehe den folgenden Code:
Erstellen Sie die Anwendung
Nachdem Sie Ihre Evaluatoren eingerichtet haben, können Sie Ihre Anwendung erstellen. In diesem Beispiel verwenden wir eine kontextfähige QA-Anwendung. Stellen Sie in dieser Anwendung die Anweisung und den Kontext für die Vervollständigungs-Engine bereit:
Nachdem Sie die App- und Feedback-Funktionen erstellt haben, können Sie mit TruLens ganz einfach eine umschlossene Anwendung erstellen. Diese verpackte Anwendung, die wir base_recorder nennen, protokolliert und bewertet die Anwendung bei jedem Aufruf:
Ergebnisse mit Basis Llama-2
Nachdem Sie die Anwendung für jeden Datensatz im Testdatensatz ausgeführt haben, können Sie die Ergebnisse in Ihrem SageMaker-Notizbuch mit anzeigen tru.get_leaderboard(). Der folgende Screenshot zeigt die Ergebnisse der Auswertung. Die Antwortrelevanz ist alarmierend niedrig, was darauf hindeutet, dass das Modell Schwierigkeiten hat, die bereitgestellten Anweisungen konsequent zu befolgen.

Optimieren Sie Llama-2 mit SageMaker Jumpstart
Hier finden Sie auch Schritte zur Feinabstimmung des Llama-2-Modells mit SageMaker Jumpstart Notizbuch.
Um die Feinabstimmung einzurichten, müssen Sie zunächst das Trainingsset herunterladen und eine Vorlage für Anweisungen einrichten
Laden Sie dann sowohl den Datensatz als auch die Anweisungen in eine hoch Amazon Simple Storage-Service (Amazon S3) Eimer fürs Training:
Zur Feinabstimmung von SageMaker können Sie den SageMaker JumpStart Estimator verwenden. Wir verwenden hier hauptsächlich Standard-Hyperparameter, außer dass wir die Befehlsoptimierung auf „true“ setzen:
Nachdem Sie das Modell trainiert haben, können Sie es wie zuvor bereitstellen und Ihre Anwendung erstellen:
Bewerten Sie das fein abgestimmte Modell
Sie können das Modell erneut auf Ihrem Testsatz ausführen und die Ergebnisse anzeigen, dieses Mal im Vergleich zum Basismodell Llama-2:

Das neue, fein abgestimmte Llama-2-Modell hat die Antwortrelevanz und die Bodenständigkeit sowie die Ähnlichkeit zum Ground-Truth-Testset erheblich verbessert. Diese große Qualitätsverbesserung geht mit einer leichten Erhöhung der Latenz einher. Dieser Anstieg der Latenz ist eine direkte Folge der Feinabstimmung, die die Größe des Modells erhöht.
Sie können diese Ergebnisse nicht nur im Notizbuch anzeigen, sondern auch die Ergebnisse in der TruLens-Benutzeroberfläche erkunden, indem Sie tru.run_dashboard() ausführen. Dadurch können dieselben aggregierten Ergebnisse auf der Bestenlistenseite bereitgestellt werden, Sie haben aber auch die Möglichkeit, tiefer in problematische Datensätze einzutauchen und Fehlermodi der Anwendung zu identifizieren.

Um die Verbesserung der App auf Datensatzebene zu verstehen, können Sie zur Bewertungsseite wechseln und die Feedback-Ergebnisse auf einer detaillierteren Ebene untersuchen.
Wenn Sie dem Basis-LLM beispielsweise die Frage stellen: „Welcher ist der stärkste Porsche-Boxermotor?“ halluziniert das Modell Folgendes.

Darüber hinaus können Sie die programmgesteuerte Auswertung dieses Datensatzes untersuchen, um die Leistung der Anwendung im Vergleich zu jeder der von Ihnen definierten Feedbackfunktionen zu verstehen. Wenn Sie die Ergebnisse des Groundedness-Feedbacks in TruLens untersuchen, können Sie eine detaillierte Aufschlüsselung der verfügbaren Beweise zur Stützung jeder Behauptung des LLM sehen.

Wenn Sie denselben Datensatz für Ihr fein abgestimmtes LLM in TruLens exportieren, können Sie sehen, dass die Feinabstimmung mit SageMaker JumpStart die Bodenständigkeit der Antwort erheblich verbessert hat.

Durch die Verwendung eines automatisierten Bewertungsworkflows mit TruLens können Sie Ihre Anwendung anhand eines breiteren Satzes von Metriken messen, um deren Leistung besser zu verstehen. Wichtig ist, dass Sie diese Leistung jetzt für jeden Anwendungsfall dynamisch nachvollziehen können – auch für solche, bei denen Sie keine fundierte Datenerfassung durchgeführt haben.
So funktioniert TruLens
Nachdem Sie den Prototyp Ihrer LLM-Anwendung erstellt haben, können Sie TruLens (siehe oben) integrieren, um den Aufrufstapel zu instrumentieren. Nachdem der Aufrufstapel instrumentiert wurde, kann er bei jeder Ausführung in einer Protokollierungsdatenbank in Ihrer Umgebung protokolliert werden.
Neben den Instrumentierungs- und Protokollierungsfunktionen ist die Auswertung eine zentrale Wertkomponente für TruLens-Benutzer. Diese Auswertungen werden in TruLens durch Feedback-Funktionen implementiert, die auf Ihrem instrumentierten Aufrufstapel ausgeführt werden und wiederum externe Modellanbieter dazu auffordern, das Feedback selbst zu erzeugen.
Nach der Feedback-Inferenz werden die Feedback-Ergebnisse in die Protokollierungsdatenbank geschrieben, von der aus Sie das TruLens-Dashboard ausführen können. Mit dem TruLens-Dashboard, das in Ihrer Umgebung ausgeführt wird, können Sie Ihre LLM-App erkunden, iterieren und debuggen.
In großem Umfang können diese Protokolle und Auswertungen an TruEra übertragen werden Beobachtbarkeit der Produktion das Millionen von Beobachtungen pro Minute verarbeiten kann. Mit der TruEra Observability Platform können Sie Halluzinationen und andere Leistungsprobleme schnell erkennen und mit der integrierten Diagnose in Sekundenschnelle auf einen einzelnen Datensatz zoomen. Wenn Sie zu einem diagnostischen Gesichtspunkt wechseln, können Sie Fehlermodi für Ihre LLM-App wie Halluzinationen, schlechte Abrufqualität, Sicherheitsprobleme und mehr leicht identifizieren und abmildern.

Bewerten Sie ehrliche, harmlose und hilfreiche Antworten
Durch zufriedenstellende Bewertungen dieser Triade können Sie ein höheres Maß an Vertrauen in die Wahrhaftigkeit der Antworten erreichen. Über die Wahrhaftigkeit hinaus bietet TruLens umfassende Unterstützung für die Bewertungen, die erforderlich sind, um die Leistung Ihres LLM auf der Achse „Ehrlich, harmlos und hilfreich“ zu verstehen. Unsere Benutzer haben enorm von der Möglichkeit profitiert, nicht nur Halluzinationen zu erkennen, wie wir zuvor besprochen haben, sondern auch Probleme mit Sicherheit, Sprachübereinstimmung, Kohärenz und mehr. Dies sind alles chaotische, reale Probleme, mit denen LLM-App-Entwickler konfrontiert sind und die mit TruLens sofort identifiziert werden können.

Zusammenfassung
In diesem Beitrag wurde erläutert, wie Sie die Produktion von KI-Anwendungen beschleunigen und Basismodelle in Ihrem Unternehmen verwenden können. Mit SageMaker JumpStart, Amazon Bedrock und TruEra können Sie grundlegende Modelle für Ihre LLM-Anwendung bereitstellen, optimieren und iterieren. Schau dir das an Link um mehr über TruEra zu erfahren und es auszuprobieren Notizbuch dich selber.
Über die Autoren
 Josh Reini ist einer der Hauptautoren des Open-Source-Programms TruLens und Gründungsmitglied des Developer Relations Data Scientist bei TruEra, wo er für Bildungsinitiativen und die Förderung einer florierenden Gemeinschaft von KI-Qualitätsexperten verantwortlich ist.
Josh Reini ist einer der Hauptautoren des Open-Source-Programms TruLens und Gründungsmitglied des Developer Relations Data Scientist bei TruEra, wo er für Bildungsinitiativen und die Förderung einer florierenden Gemeinschaft von KI-Qualitätsexperten verantwortlich ist.
 Shayak Sen ist CTO und Mitbegründer von TruEra. Shayak konzentriert sich auf den Aufbau von Systemen und leitet die Forschung, um maschinelle Lernsysteme erklärbarer, datenschutzkonformer und fairer zu machen.
Shayak Sen ist CTO und Mitbegründer von TruEra. Shayak konzentriert sich auf den Aufbau von Systemen und leitet die Forschung, um maschinelle Lernsysteme erklärbarer, datenschutzkonformer und fairer zu machen.
 Anupam Datta ist Mitbegründer, Präsident und Chefwissenschaftler von TruEra. Vor TruEra war er 15 Jahre lang an der Fakultät der Carnegie Mellon University tätig (2007–22), zuletzt als ordentlicher Professor für Elektrotechnik, Informationstechnik und Informatik.
Anupam Datta ist Mitbegründer, Präsident und Chefwissenschaftler von TruEra. Vor TruEra war er 15 Jahre lang an der Fakultät der Carnegie Mellon University tätig (2007–22), zuletzt als ordentlicher Professor für Elektrotechnik, Informationstechnik und Informatik.
 Vivek Gangasani ist ein KI/ML-Startup-Solutions-Architekt für generative KI-Startups bei AWS. Er unterstützt aufstrebende GenAI-Startups beim Aufbau innovativer Lösungen mithilfe von AWS-Diensten und beschleunigter Datenverarbeitung. Derzeit konzentriert er sich auf die Entwicklung von Strategien zur Feinabstimmung und Optimierung der Inferenzleistung großer Sprachmodelle. In seiner Freizeit wandert Vivek gerne, schaut Filme und probiert verschiedene Küchen.
Vivek Gangasani ist ein KI/ML-Startup-Solutions-Architekt für generative KI-Startups bei AWS. Er unterstützt aufstrebende GenAI-Startups beim Aufbau innovativer Lösungen mithilfe von AWS-Diensten und beschleunigter Datenverarbeitung. Derzeit konzentriert er sich auf die Entwicklung von Strategien zur Feinabstimmung und Optimierung der Inferenzleistung großer Sprachmodelle. In seiner Freizeit wandert Vivek gerne, schaut Filme und probiert verschiedene Küchen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/deploy-foundation-models-with-amazon-sagemaker-iterate-and-monitor-with-truera/

