Generative KI-Agenten sind in der Lage, menschenähnliche Antworten zu erzeugen und Gespräche in natürlicher Sprache zu führen, indem sie eine Kette von Aufrufen an Foundation Models (FMs) und andere Augmenting-Tools auf der Grundlage von Benutzereingaben orchestrieren. Anstatt nur vordefinierte Absichten über einen statischen Entscheidungsbaum zu erfüllen, sind Agenten im Kontext ihrer Suite verfügbarer Tools autonom. Amazonas Grundgestein ist ein vollständig verwalteter Dienst, der führende FMs von KI-Unternehmen über eine API zusammen mit Entwicklertools zur Verfügung stellt, um die Erstellung und Skalierung generativer KI-Anwendungen zu unterstützen.
In diesem Beitrag zeigen wir, wie man einen generativen KI-Finanzdienstleistungsagenten auf Basis von Amazon Bedrock aufbaut. Der Agent kann Benutzern dabei helfen, ihre Kontoinformationen zu finden, einen Kreditantrag auszufüllen oder Fragen in natürlicher Sprache zu beantworten und gleichzeitig Quellen für die bereitgestellten Antworten anzugeben. Diese Lösung soll als Startrampe für Entwickler dienen, um ihre eigenen personalisierten Konversationsagenten für verschiedene Anwendungen zu erstellen, beispielsweise virtuelle Mitarbeiter und Kundensupportsysteme. Lösungscode und Bereitstellungsressourcen finden Sie im GitHub-Repository.
Amazon Lex stellt die Schnittstelle zum Verstehen natürlicher Sprache (NLU) und zur Verarbeitung natürlicher Sprache (NLP) für Open Source bereit LangChain-Konversationsagent eingebettet in eine AWS verstärken Webseite. Der Agent ist mit Tools ausgestattet, zu denen ein auf Amazon Bedrock gehostetes Anthropic Claude 2.1 FM und die Speicherung synthetischer Kundendaten gehören Amazon DynamoDB und Amazon Kendra um die folgenden Funktionen bereitzustellen:
- Geben Sie personalisierte Antworten – Fragen Sie DynamoDB nach Kundenkontoinformationen ab, z. B. Einzelheiten zur Hypothekenübersicht, zum fälligen Restbetrag und zum nächsten Zahlungsdatum
- Greifen Sie auf Allgemeinwissen zu – Nutzen Sie die Argumentationslogik des Agenten in Verbindung mit den riesigen Datenmengen, die verwendet werden, um die verschiedenen FMs, die über Amazon Bedrock bereitgestellt werden, vorab zu trainieren, um Antworten auf jede Kundenanfrage zu erstellen
- Kuratieren Sie eigensinnige Antworten – Informieren Sie Agenten über Antworten mithilfe eines Amazon Kendra-Index, der mit maßgeblichen Datenquellen konfiguriert ist: Kundendokumente, die in gespeichert sind Amazon Simple Storage-Service (Amazon S3) und Amazon Kendra Web Crawler für die Website des Kunden konfiguriert
Lösungsüberblick
Demo-Aufnahme
Die folgende Demoaufzeichnung beleuchtet die Agentenfunktionalität und technische Implementierungsdetails.
Lösungsarchitektur
Das folgende Diagramm zeigt die Lösungsarchitektur.
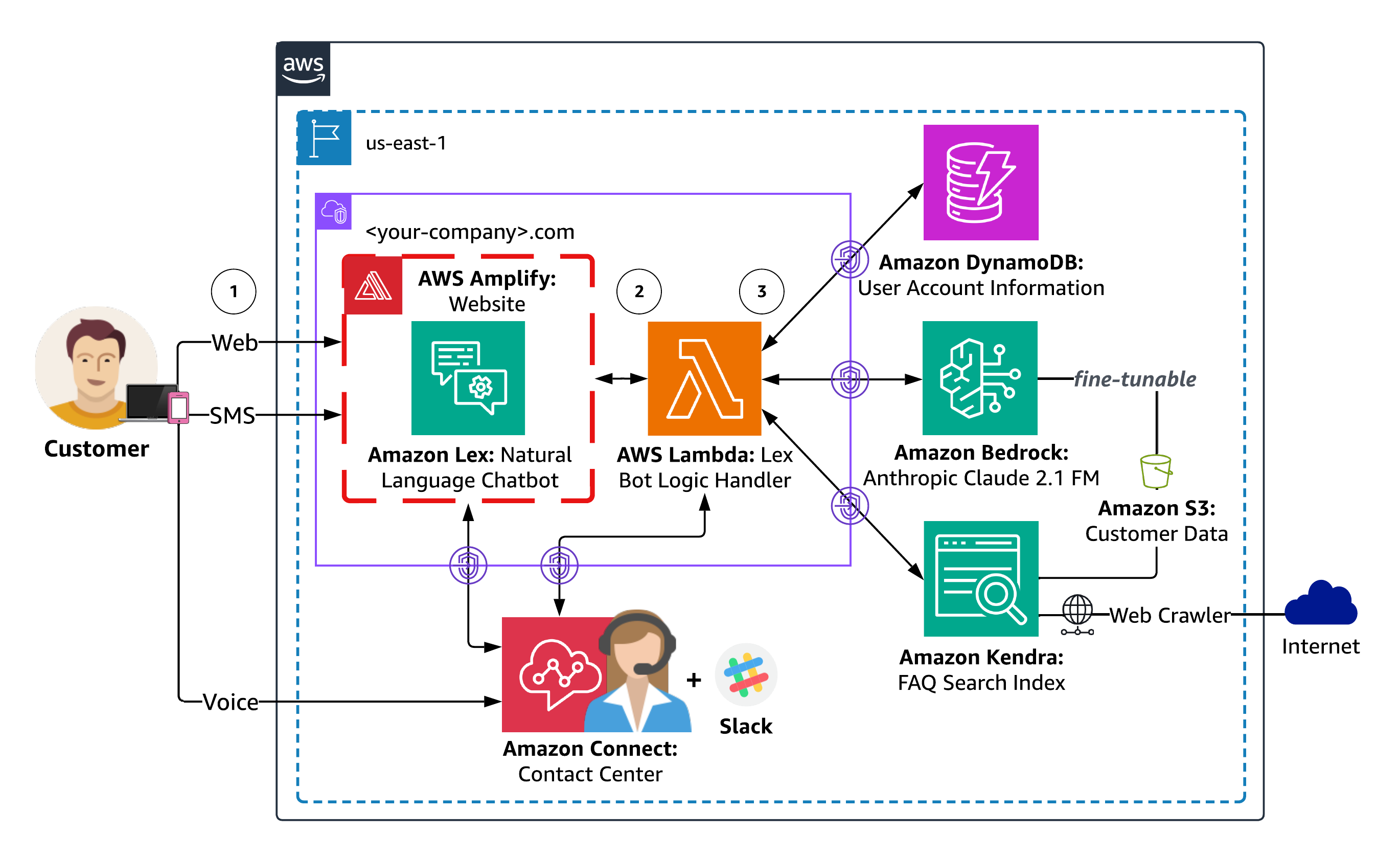
Diagramm 1: Überblick über die Lösungsarchitektur
Der Antwort-Workflow des Agenten umfasst die folgenden Schritte:
- Benutzer führen einen Dialog in natürlicher Sprache mit dem Agenten über Web-, SMS- oder Sprachkanäle ihrer Wahl. Der Webkanal umfasst eine von Amplify gehostete Website mit einem in Amazon Lex eingebetteten Chatbot für einen fiktiven Kunden. SMS- und Sprachkanäle können optional über konfiguriert werden Amazon Connect und Messaging-Integrationen für Amazon Lex. Jede Benutzeranfrage wird von Amazon Lex verarbeitet, um die Benutzerabsicht durch einen Prozess namens Absichtserkennung zu ermitteln, der die Analyse und Interpretation der Benutzereingaben (Text oder Sprache) umfasst, um die beabsichtigte Aktion oder den beabsichtigten Zweck des Benutzers zu verstehen.
- Amazon Lex ruft dann eine auf AWS Lambda Handler für die Erfüllung von Benutzerabsichten. Die mit dem Amazon Lex-Chatbot verknüpfte Lambda-Funktion enthält die Logik und Geschäftsregeln, die zum Verarbeiten der Absicht des Benutzers erforderlich sind. Lambda führt bestimmte Aktionen aus oder ruft Informationen basierend auf den Eingaben des Benutzers ab, trifft Entscheidungen und generiert entsprechende Antworten.
- Lambda instrumentiert die Logik des Finanzdienstleistungsagenten als LangChain-Konversationsagenten, der auf kundenspezifische Daten zugreifen kann, die in DynamoDB gespeichert sind, Meinungsantworten anhand Ihrer von Amazon Kendra indizierten Dokumente und Webseiten kuratieren und über das FM auf Amazon Bedrock allgemeine Wissensantworten bereitstellen kann. Die von Amazon Kendra generierten Antworten umfassen die Quellenangabe und zeigen, wie Sie dem Agenten zusätzliche Kontextinformationen bereitstellen können Augmented Generation abrufen (LAPPEN). Mit RAG können Sie die Fähigkeit Ihres Agenten verbessern, anhand Ihrer eigenen Daten genauere und kontextrelevantere Antworten zu generieren.
Agentenarchitektur
Das folgende Diagramm veranschaulicht die Agentenarchitektur.
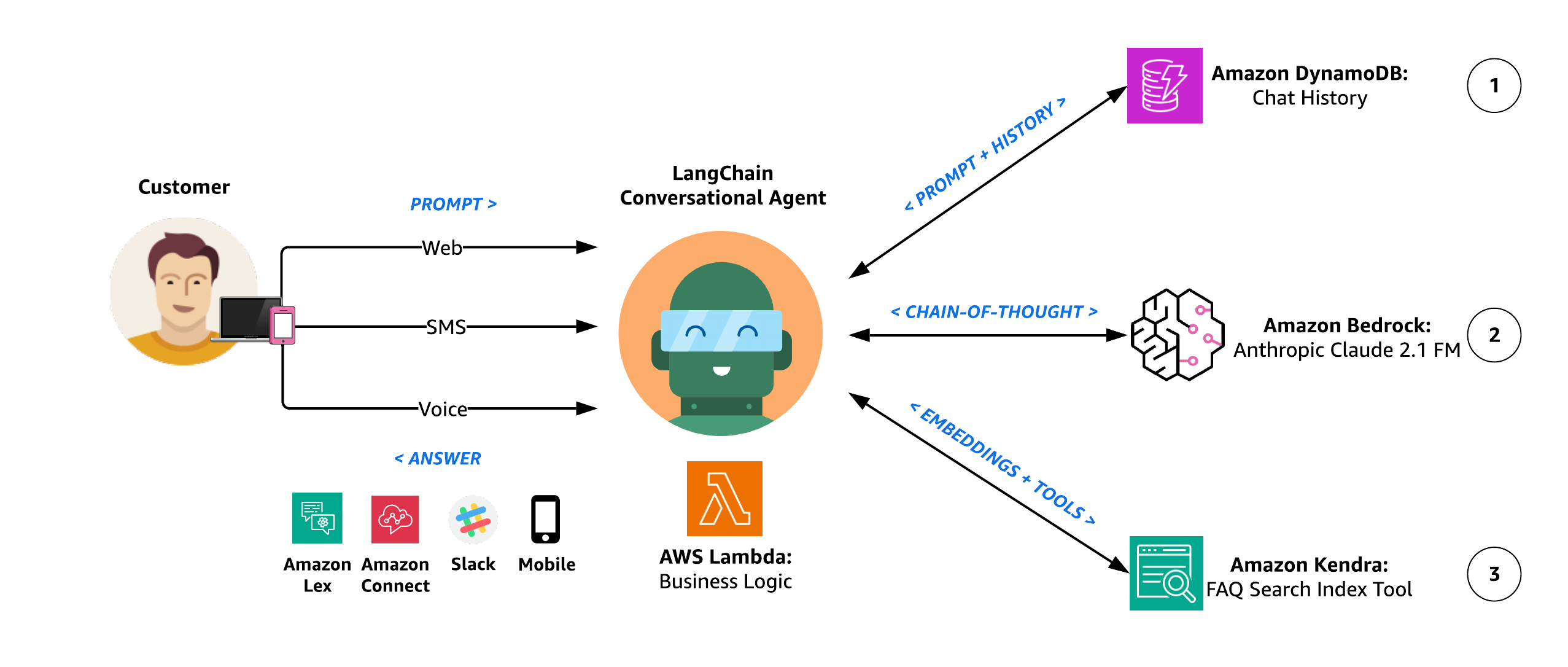
Diagramm 2: LangChain Conversational Agent-Architektur
Der Argumentationsworkflow des Agenten umfasst die folgenden Schritte:
- Der LangChain-Konversationsagent verfügt über einen Konversationsspeicher, sodass er mit kontextbezogener Generierung auf mehrere Abfragen antworten kann. Dieser Speicher ermöglicht es dem Agenten, Antworten zu geben, die den Kontext des laufenden Gesprächs berücksichtigen. Dies wird durch kontextbezogene Generierung erreicht, bei der der Agent basierend auf den Informationen, die er sich aus dem Gespräch gemerkt hat, Antworten generiert, die relevant und kontextuell angemessen sind. Einfacher ausgedrückt: Der Agent erinnert sich an das zuvor Gesagte und nutzt diese Informationen, um auf mehrere Fragen auf eine Weise zu antworten, die im laufenden Gespräch sinnvoll ist. Unser Agent verwendet Die DynamoDB-Chat-Nachrichtenverlaufsklasse von LangChain als Konversationsspeicherpuffer, damit vergangene Interaktionen abgerufen und das Benutzererlebnis durch aussagekräftigere, kontextbezogene Antworten verbessert werden können.
- Der Agent verwendet Anthropic Claude 2.1 auf Amazon Bedrock, um die gewünschte Aufgabe durch eine Reihe sorgfältig selbst generierter Texteingaben, sogenannte „ Eingabeaufforderungen. Das Hauptziel des Prompt Engineering besteht darin, dem FM spezifische und genaue Antworten zu entlocken. Zu den verschiedenen Prompt-Engineering-Techniken gehören:
- Nullschuss – Dem Modell wird eine einzelne Frage ohne zusätzliche Hinweise vorgelegt. Von dem Modell wird erwartet, dass es eine Antwort ausschließlich auf der Grundlage der gegebenen Frage generiert.
- Wenige Schüsse – Vor der eigentlichen Frage sind eine Reihe von Beispielfragen und die entsprechenden Antworten enthalten. Indem das Modell diesen Beispielen ausgesetzt wird, lernt es, auf ähnliche Weise zu reagieren.
- Gedankenkette – Ein spezifischer Stil der Eingabeaufforderung mit wenigen Schüssen, bei der die Eingabeaufforderung eine Reihe von Zwischenschritten zum Denken enthält, die das Modell durch einen logischen Denkprozess führen und letztendlich zur gewünschten Antwort führen.
Unser Agent nutzt die Gedankenkette, indem er beim Eingang einer Anfrage eine Reihe von Aktionen durchführt. Nach jeder Aktion tritt der Agent in den Beobachtungsschritt ein, in dem er einen Gedanken zum Ausdruck bringt. Wenn noch keine endgültige Antwort vorliegt, iteriert der Agent und wählt verschiedene Aktionen aus, um zur endgültigen Antwort zu gelangen. Sehen Sie sich den folgenden Beispielcode an:
Gedanke: Muss ich ein Werkzeug verwenden? Ja
Aktion: Die auszuführende Aktion
Aktionseingabe: Die Eingabe für die Aktion
Beobachtung: Das Ergebnis der Aktion
Gedanke: Muss ich ein Werkzeug verwenden? NEIN
FSI-Agent: [Antwort und Quelldokumente]
- Im Rahmen der unterschiedlichen Argumentationswege und selbstbewertenden Entscheidungen des Agenten zur Entscheidung über die nächste Vorgehensweise verfügt er über die Möglichkeit, über eine auf synthetische Kundendatenquellen zuzugreifen Amazon Kendra Index Retriever-Tool. Mit Amazon Kendra führt der Agent eine kontextbezogene Suche in einer Vielzahl von Inhaltstypen durch, darunter Dokumente, FAQs, Wissensdatenbanken, Handbücher und Websites. Weitere Einzelheiten zu unterstützten Datenquellen finden Sie unter Datenquellen. Der Agent hat die Macht, dieses Tool zu verwenden, um eigenwillige Antworten auf Benutzeraufforderungen bereitzustellen, die mithilfe einer maßgeblichen, vom Kunden bereitgestellten Wissensbibliothek beantwortet werden sollten, anstelle des allgemeineren Wissenskorpus, der zum Vortraining des Amazon Bedrock FM verwendet wird.
Bereitstellungsanleitung
In den folgenden Abschnitten besprechen wir die wichtigsten Schritte zur Bereitstellung der Lösung, einschließlich vor und nach der Bereitstellung.
Vorbereitstellung
Bevor Sie die Lösung bereitstellen, müssen Sie Ihre eigene gespaltene Version des Lösungs-Repositorys mit einem tokengesicherten Webhook erstellen, um die kontinuierliche Bereitstellung Ihrer Amplify-Website zu automatisieren. Die Amplify-Konfiguration verweist auf ein GitHub-Quell-Repository, aus dem das Frontend unserer Website erstellt wird.
Gabeln und klonen generative-ai-amazon-bedrock-langchain-agent-example Quelle
- Befolgen Sie die Anweisungen unter, um den Quellcode zu steuern, der Ihre Amplify-Website erstellt Forken Sie ein Repository um das generative-ai-amazon-bedrock-langchain-agent-example-Repository zu forken. Dadurch wird eine Kopie des Repositorys erstellt, die von der ursprünglichen Codebasis getrennt ist, sodass Sie die entsprechenden Änderungen vornehmen können.
- Bitte notieren Sie sich Ihre gespaltene Repository-URL, die Sie zum Klonen des Repositorys im nächsten Schritt und zum Konfigurieren der Umgebungsvariablen GITHUB_PAT verwenden, die im Automatisierungsskript für die Lösungsbereitstellung verwendet wird.
- Klonen Sie Ihr geforktes Repository mit dem Befehl git clone:
Erstellen Sie ein persönliches GitHub-Zugriffstoken
Die von Amplify gehostete Website verwendet a Persönliches GitHub-Zugriffstoken (PAT) als OAuth-Token für die Quellcodeverwaltung von Drittanbietern. Das OAuth-Token wird zum Erstellen eines Webhooks und eines schreibgeschützten Bereitstellungsschlüssels mithilfe von SSH-Klonen verwendet.
- Befolgen Sie zum Erstellen Ihres PAT die Anweisungen unter Erstellen eines persönlichen Zugriffstokens (klassisch). Möglicherweise bevorzugen Sie die Verwendung von a GitHub-App um im Namen einer Organisation oder für langlebige Integrationen auf Ressourcen zuzugreifen.
- Notieren Sie sich Ihre PAT, bevor Sie Ihren Browser schließen. Sie verwenden sie, um die Umgebungsvariable GITHUB_PAT zu konfigurieren, die im Automatisierungsskript für die Lösungsbereitstellung verwendet wird. Das Skript veröffentlicht Ihr PAT unter AWS Secrets Manager Verwendung von AWS-Befehlszeilenschnittstelle (AWS CLI)-Befehle und der Secret-Name werden als GitHubTokenSecretName verwendet AWS CloudFormation Parameters.
Einsatz
Das Automatisierungsskript für die Lösungsbereitstellung verwendet die parametrisierte CloudFormation-Vorlage. GenAI-FSI-Agent.yml, um die Bereitstellung der folgenden Lösungsressourcen zu automatisieren:
- Eine Amplify-Website zur Simulation Ihrer Front-End-Umgebung.
- Ein Amazon Lex-Bot, der über ein Bot-Import-Bereitstellungspaket konfiguriert wurde.
- Vier DynamoDB-Tabellen:
- UserPendingAccountsTable – Zeichnet ausstehende Transaktionen auf (z. B. Kreditanträge).
- UserExistingAccountsTable – Enthält Informationen zum Benutzerkonto (z. B. eine Zusammenfassung des Hypothekenkontos).
- ConversationIndexTable – Verfolgt den Gesprächsstatus.
- Konversationstabelle – Speichert den Gesprächsverlauf.
- Ein S3-Bucket, der den Lambda-Agent-Handler, den Lambda-Datenlader und die Amazon-Lex-Bereitstellungspakete sowie Kunden-FAQs und Beispieldokumente für Hypothekenanträge enthält.
- Zwei Lambda-Funktionen:
- Agenten-Handler – Enthält die LangChain-Konversationsagentenlogik, die eine Vielzahl von Tools basierend auf Benutzereingaben intelligent einsetzen kann.
- Datenlader – Lädt Beispielkundenkontodaten in UserExistingAccountsTable und wird während der Stack-Erstellung als benutzerdefinierte CloudFormation-Ressource aufgerufen.
- Eine Lambda-Ebene für Amazon Bedrock Boto3-, LangChain- und pdfrw-Bibliotheken. Der Layer versorgt die FM-Bibliothek von LangChain mit einem Amazon Bedrock-Modell als zugrundeliegendem FM und stellt pdfrw als Open-Source-PDF-Bibliothek zum Erstellen und Ändern von PDF-Dateien bereit.
- Ein Amazon Kendra-Index, der einen durchsuchbaren Index kundenrelevanter Informationen bereitstellt, darunter Dokumente, FAQs, Wissensdatenbanken, Handbücher, Websites und mehr.
- Zwei Amazon Kendra-Datenquellen:
- Amazon S3 – Gastgeber und Beispiel eines Kunden-FAQ-Dokuments.
- Amazon Kendra Web Crawler – Konfiguriert mit einer Stammdomäne, die die kundenspezifische Website emuliert (z. B. .com).
- AWS Identity and Access Management and (IAM)-Berechtigungen für die vorhergehenden Ressourcen.
AWS CloudFormation füllt Stack-Parameter vorab mit den in der Vorlage bereitgestellten Standardwerten aus. Um alternative Eingabewerte bereitzustellen, können Sie Parameter als Umgebungsvariablen angeben, auf die in den Paaren „ParameterKey=,ParameterValue=“ im Befehl „aws cloudformation create-stack“ des folgenden Shell-Skripts verwiesen wird.
- Bevor Sie das Shell-Skript ausführen, navigieren Sie zu Ihrer abgezweigten Version des generative-ai-amazon-bedrock-langchain-agent-example-Repositorys als Arbeitsverzeichnis und ändern Sie die Berechtigungen des Shell-Skripts auf ausführbar:
- Legen Sie Ihr Amplify-Repository und die GitHub-PAT-Umgebungsvariablen fest, die während der Schritte vor der Bereitstellung erstellt wurden:
- Führen Sie abschließend das Automatisierungsskript für die Lösungsbereitstellung aus, um die Ressourcen der Lösung bereitzustellen, einschließlich der GenAI-FSI-Agent.yml CloudFormation-Stack:
source ./create-stack.sh
Skript zur Lösungsbereitstellungsautomatisierung
Das Vorhergehende source ./create-stack.sh shell Der Befehl führt die folgenden AWS CLI-Befehle aus, um den Lösungsstapel bereitzustellen:
Nach der Bereitstellung
In diesem Abschnitt besprechen wir die Schritte nach der Bereitstellung zum Starten einer Frontend-Anwendung, die die Produktionsanwendung des Kunden emulieren soll. Der Finanzdienstleister fungiert als eingebetteter Assistent in der Beispiel-Web-Benutzeroberfläche.
Starten Sie eine Web-Benutzeroberfläche für Ihren Chatbot
Das Amazon Lex-Web-Benutzeroberfläche, auch als Chatbot-Benutzeroberfläche bekannt, ermöglicht Ihnen die schnelle Bereitstellung eines umfassenden Web-Clients für Amazon Lex-Chatbots. Die Benutzeroberfläche lässt sich in Amazon Lex integrieren, um ein JavaScript-Plugin zu erstellen, das ein von Amazon Lex unterstütztes Chat-Widget in Ihre bestehende Webanwendung integriert. In diesem Fall verwenden wir die Web-Benutzeroberfläche, um eine vorhandene Kunden-Webanwendung mit einem eingebetteten Amazon Lex-Chatbot zu emulieren. Führen Sie die folgenden Schritte aus:
- Folgen Sie den Anweisungen zu Stellen Sie den Amazon Lex-Web-UI-CloudFormation-Stack bereit.
- Navigieren Sie in der AWS CloudFormation-Konsole zu den Stapeln Ausgänge Klicken Sie auf die Registerkarte und suchen Sie den Wert für
SnippetUrl.

Abbildung 1: Amazon CloudFormation gibt die Lex-Web-UI-Snippet-URL aus
- Kopieren Sie das Iframe-Snippet der Web-Benutzeroberfläche, das dem folgenden Format ähnelt Hinzufügen der ChatBot-Benutzeroberfläche als Iframe zu Ihrer Website.

Abbildung 2: Iframe-Snippet der Lex Web-Benutzeroberfläche
- Bearbeiten Sie Ihre gespaltene Version des Amplify GitHub-Quell-Repositorys, indem Sie Ihr Web-UI-JavaScript-Plugin zum Abschnitt mit der Bezeichnung hinzufügen
<-- Paste your Lex Web UI JavaScript plugin here -->für jede der HTML-Dateien unter Frontend-Verzeichnis:index.html,contact.htmlundabout.html.

Abbildung 3: Lex Web UI Snippet Frontend
Amplify bietet eine automatisierte Build- und Release-Pipeline, die basierend auf neuen Commits an Ihr geforktes Repository ausgelöst wird und die neue Version Ihrer Website auf Ihrer Amplify-Domain veröffentlicht. Sie können den Bereitstellungsstatus auf der Amplify-Konsole anzeigen.

Abbildung 4: AWS Amplify-Pipeline-Status
Rufen Sie die Amplify-Website auf
Nachdem Sie Ihr Amazon Lex-Web-UI-JavaScript-Plugin eingerichtet haben, können Sie jetzt Ihre Amplify-Demo-Website starten.
- Um auf die Domain Ihrer Website zuzugreifen, navigieren Sie zum CloudFormation-Stack Ausgänge Klicken Sie auf die Registerkarte und suchen Sie die Amplify-Domänen-URL. Alternativ können Sie den folgenden Befehl verwenden:
- Nachdem Sie auf die URL Ihrer Amplify-Domäne zugegriffen haben, können Sie mit dem Testen und der Validierung fortfahren.

Abbildung 5: AWS Amplify Frontend
Testen und Validieren
Mit dem folgenden Testverfahren soll überprüft werden, ob der Agent Benutzerabsichten für den Zugriff auf Kundendaten (z. B. Kontoinformationen), die Erfüllung von Geschäftsabläufen durch vordefinierte Absichten (z. B. das Ausfüllen eines Kreditantrags) und die Beantwortung allgemeiner Fragen, z. B. die, korrekt identifiziert und versteht folgende Beispielaufforderungen:
- Warum sollte ich verwenden?
- Wie wettbewerbsfähig sind ihre Tarife?
- Welche Art von Hypothek soll ich nutzen?
- Was sind die aktuellen Hypothekentrends?
- Wie viel muss ich für eine Anzahlung sparen?
- Welche weiteren Kosten fallen bei Abschluss an?
Die Antwortgenauigkeit wird durch die Bewertung der Relevanz, Kohärenz und menschlichen Ähnlichkeit der Antworten bestimmt, die vom von Amazon Bedrock bereitgestellten Anthropic Claude 2.1 FM generiert werden. Die mit jeder Antwort bereitgestellten Quelllinks (z. B. .com basierend auf der Amazon Kendra Web Crawler-Konfiguration) sollten ebenfalls als glaubwürdig bestätigt werden.
Geben Sie personalisierte Antworten
Überprüfen Sie, ob der Agent erfolgreich auf relevante Kundeninformationen in DynamoDB zugreift und diese nutzt, um benutzerspezifische Antworten anzupassen.

Abbildung 6: Personalisierte Antwort
Beachten Sie, dass die Verwendung der PIN-Authentifizierung innerhalb des Agenten nur zu Demonstrationszwecken dient und nicht in Produktionsimplementierungen verwendet werden sollte.
Kuratieren Sie eigensinnige Antworten
Stellen Sie sicher, dass der Agent auf eigensinnige Fragen glaubwürdige Antworten erhält und die Antworten auf der Grundlage maßgeblicher Kundendokumente und von Amazon Kendra indizierter Webseiten korrekt eingibt.
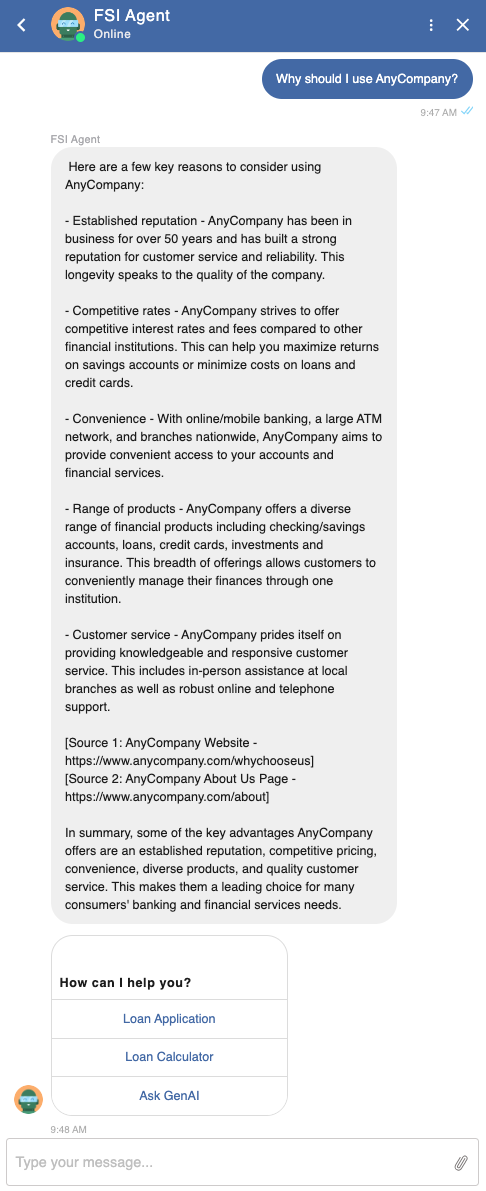
Abbildung 7: Stellungnahme der RAG
Liefern Sie kontextbezogene Generierung
Bestimmen Sie die Fähigkeit des Agenten, kontextrelevante Antworten basierend auf dem vorherigen Chat-Verlauf zu geben.

Abbildung 8: Antwort der kontextbezogenen Generierung
Greifen Sie auf Allgemeinwissen zu
Bestätigen Sie den Zugriff des Agenten auf allgemeine Wissensinformationen für nicht kundenspezifische, nicht meinungsbezogene Anfragen, die genaue und kohärente Antworten basierend auf Amazon Bedrock FM-Trainingsdaten und RAG erfordern.

Abbildung 9: Allgemeine Wissensantwort
Führen Sie vordefinierte Absichten aus
Stellen Sie sicher, dass der Agent Benutzeraufforderungen, die an vordefinierte Absichten weitergeleitet werden sollen, wie etwa das Ausfüllen eines Kreditantrags als Teil eines Geschäftsablaufs, richtig interpretiert und im Dialog ausführt.

Abbildung 10: Vordefinierte Intent-Reaktion
Das Folgende ist das resultierende Kreditantragsdokument, das durch den Gesprächsablauf vervollständigt wurde.

Abbildung 11: Daraus resultierender Kreditantrag
Die Multi-Channel-Support-Funktionalität kann in Verbindung mit den vorangegangenen Bewertungsmaßnahmen über Web-, SMS- und Sprachkanäle hinweg getestet werden. Weitere Informationen zur Integration des Chatbots mit anderen Diensten finden Sie unter Integration eines Amazon Lex V2-Bots mit Twilio SMS und Fügen Sie einen Amazon Lex-Bot zu Amazon Connect hinzu.
Aufräumen
Um Gebühren in Ihrem AWS-Konto zu vermeiden, bereinigen Sie die bereitgestellten Ressourcen der Lösung.
- Widerrufen Sie das persönliche GitHub-Zugriffstoken. GitHub-PATs werden mit einem Ablaufwert konfiguriert. Wenn Sie sicherstellen möchten, dass Ihr PAT nicht für den programmgesteuerten Zugriff auf Ihr geforktes Amplify GitHub-Repository verwendet werden kann, bevor es abläuft, können Sie das PAT widerrufen, indem Sie die folgenden Schritte ausführen Anweisungen für das GitHub-Repo.
- Löschen Sie den GenAI-FSI-Agent.yml CloudFormation-Stack und andere Lösungsressourcen mithilfe des Automatisierungsskripts zum Löschen der Lösung. Die folgenden Befehle verwenden den Standard-Stack-Namen. Wenn Sie den Stack-Namen angepasst haben, passen Sie die Befehle entsprechend an.
# export STACK_NAME=<YOUR-STACK-NAME>./delete-stack.sh
Skript zur Lösungslöschautomatisierung
Das
delete-stack.sh shellDas Skript löscht die Ressourcen, die ursprünglich mithilfe des Automatisierungsskripts für die Lösungsbereitstellung bereitgestellt wurden, einschließlich des CloudFormation-Stacks GenAI-FSI-Agent.yml.
Überlegungen
Obwohl die Lösung in diesem Beitrag die Fähigkeiten eines generativen KI-Finanzdienstleistungsagenten auf Basis von Amazon Bedrock demonstriert, muss man sich darüber im Klaren sein, dass diese Lösung noch nicht produktionsbereit ist. Vielmehr dient es als anschauliches Beispiel für Entwickler, die personalisierte Konversationsagenten für verschiedene Anwendungen wie virtuelle Mitarbeiter und Kundensupportsysteme erstellen möchten. Der Weg eines Entwicklers zur Produktion würde diese Beispiellösung unter Berücksichtigung der folgenden Überlegungen iterieren.
Sicherheit und Privatsphäre
Sorgen Sie während des gesamten Implementierungsprozesses für Datensicherheit und Benutzerschutz. Implementieren Sie geeignete Zugriffskontrollen und Verschlüsselungsmechanismen, um vertrauliche Informationen zu schützen. Lösungen wie der generative KI-Finanzdienstleistungsagent profitieren von Daten, die dem zugrunde liegenden FM noch nicht zur Verfügung stehen, was oft bedeutet, dass Sie Ihre eigenen privaten Daten verwenden möchten, um den größten Leistungssprung zu erzielen. Berücksichtigen Sie die folgenden Best Practices:
- Halten Sie es geheim, bewahren Sie es sicher auf – Sie möchten, dass diese Daten während des Generierungsprozesses vollständig geschützt, sicher und privat bleiben, und möchten die Kontrolle darüber haben, wie diese Daten geteilt und verwendet werden.
- Richten Sie Nutzungsleitlinien ein – Verstehen Sie, wie Daten von einem Dienst verwendet werden, bevor Sie sie Ihren Teams zur Verfügung stellen. Erstellen und verteilen Sie die Regeln dafür, welche Daten mit welchem Dienst verwendet werden können. Machen Sie diese Ihren Teams klar, damit sie schnell handeln und sicher Prototypen erstellen können.
- Beziehen Sie die Rechtsabteilung lieber früher als später ein – Lassen Sie Ihre Rechtsabteilung die Allgemeinen Geschäftsbedingungen und Servicekarten der Dienste überprüfen, die Sie nutzen möchten, bevor Sie damit beginnen, sensible Daten über sie weiterzugeben. Ihre Rechtspartner waren noch nie so wichtig wie heute.
Als Beispiel dafür, wie wir bei AWS mit Amazon Bedrock darüber nachdenken: Alle Daten werden verschlüsselt und verlassen Ihre VPC nicht, und Amazon Bedrock erstellt eine separate Kopie des Basis-FM, die nur für den Kunden zugänglich ist, und führt Feinabstimmungen durch trainiert diese private Kopie des Modells.
User Acceptance Testing
Führen Sie Benutzerakzeptanztests (UAT) mit echten Benutzern durch, um die Leistung, Benutzerfreundlichkeit und Zufriedenheit des generativen KI-Finanzdienstleistungsagenten zu bewerten. Sammeln Sie Feedback und nehmen Sie basierend auf Benutzereingaben notwendige Verbesserungen vor.
Bereitstellung und Überwachung
Stellen Sie den vollständig getesteten Agenten auf AWS bereit und implementieren Sie Überwachung und Protokollierung, um seine Leistung zu verfolgen, Probleme zu identifizieren und das System nach Bedarf zu optimieren. Lambda-Überwachungs- und Fehlerbehebungsfunktionen sind standardmäßig für den Lambda-Handler des Agenten aktiviert.
Wartung und Updates
Aktualisieren Sie den Agent regelmäßig mit den neuesten FM-Versionen und Daten, um seine Genauigkeit und Effektivität zu verbessern. Überwachen Sie kundenspezifische Daten in DynamoDB und synchronisieren Sie die Indizierung Ihrer Amazon Kendra-Datenquelle nach Bedarf.
Zusammenfassung
In diesem Beitrag haben wir uns mit der spannenden Welt generativer KI-Agenten und ihrer Fähigkeit befasst, menschenähnliche Interaktionen durch die Orchestrierung von Anrufen an FMs und andere ergänzende Tools zu ermöglichen. Wenn Sie diesem Leitfaden folgen, können Sie Bedrock, LangChain und vorhandene Kundenressourcen nutzen, um erfolgreich einen zuverlässigen Agenten zu implementieren, zu testen und zu validieren, der Benutzern durch Gespräche in natürlicher Sprache genaue und personalisierte finanzielle Unterstützung bietet.
In einem kommenden Beitrag werden wir zeigen, wie die gleiche Funktionalität mit einem alternativen Ansatz bereitgestellt werden kann Agenten für Amazon Bedrock und Wissensdatenbank für Amazon Bedrock. In dieser vollständig von AWS verwalteten Implementierung wird weiter untersucht, wie intelligente Automatisierungs- und Datensuchfunktionen durch personalisierte Agenten bereitgestellt werden können, die die Art und Weise, wie Benutzer mit Ihren Anwendungen interagieren, verändern und Interaktionen natürlicher, effizienter und effektiver gestalten.
Über den Autor
 Kyle T. Blocksom ist Senior Solutions Architect bei AWS mit Sitz in Südkalifornien. Kyles Leidenschaft ist es, Menschen zusammenzubringen und Technologie zu nutzen, um Lösungen zu liefern, die Kunden lieben. Außerhalb der Arbeit geht er gerne surfen, essen, mit seinem Hund ringen und seine Nichte und seinen Neffen verwöhnen.
Kyle T. Blocksom ist Senior Solutions Architect bei AWS mit Sitz in Südkalifornien. Kyles Leidenschaft ist es, Menschen zusammenzubringen und Technologie zu nutzen, um Lösungen zu liefern, die Kunden lieben. Außerhalb der Arbeit geht er gerne surfen, essen, mit seinem Hund ringen und seine Nichte und seinen Neffen verwöhnen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-generative-ai-agents-with-amazon-bedrock-amazon-dynamodb-amazon-kendra-amazon-lex-and-langchain/

