在不断发展的制造业格局中,人工智能和机器学习 (ML) 的变革力量显而易见,推动了数字革命,简化了运营并提高了生产力。然而,这一进展给企业使用数据驱动解决方案带来了独特的挑战。工业设施需要处理大量非结构化数据,这些数据来自传感器、遥测系统和分散在生产线上的设备。实时数据对于预测维护和异常检测等应用至关重要,但使用此类时间序列数据为每个工业用例开发自定义机器学习模型需要数据科学家投入大量时间和资源,从而阻碍了广泛采用。
生成式人工智能 使用大型预训练基础模型(FM),例如 克劳德 可以根据简单的文本提示快速生成从会话文本到计算机代码的各种内容,称为 零样本提示。这消除了数据科学家为每个用例手动开发特定机器学习模型的需要,从而实现了人工智能访问的民主化,甚至使小型制造商受益。工人可以通过人工智能生成的见解提高生产力,工程师可以主动检测异常情况,供应链经理可以优化库存,工厂领导层可以做出明智的、数据驱动的决策。
然而,独立的 FM 在处理具有上下文大小限制的复杂工业数据时面临着局限性(通常是 少于 200,000 个代币),这带来了挑战。为了解决这个问题,您可以使用 FM 生成代码来响应自然语言查询 (NLQ) 的功能。代理商喜欢 熊猫人工智能 发挥作用,在高分辨率时间序列数据上运行此代码并使用 FM 处理错误。 PandasAI 是一个 Python 库,为流行的数据分析和操作工具 pandas 添加了生成式 AI 功能。
然而,复杂的 NLQ,例如时间序列数据处理、多级聚合以及数据透视表或联合表操作,可能会产生不一致的 Python 脚本精度和零样本提示。
为了提高代码生成的准确性,我们建议动态构建 连拍提示 对于 NLQ。多次提示通过向 FM 显示类似提示所需输出的几个示例,为 FM 提供额外的上下文,从而提高准确性和一致性。在这篇文章中,多镜头提示是从包含在类似数据类型(例如,来自物联网设备的高分辨率时间序列数据)上运行的成功Python代码的嵌入中检索的。动态构建的多镜头提示为 FM 提供了最相关的上下文,并增强了 FM 在高级数学计算、时间序列数据处理和数据首字母缩略词理解方面的能力。这种改进的响应有助于企业工作人员和运营团队处理数据,无需广泛的数据科学技能即可获得见解。
除了时间序列数据分析之外,FM 在各种工业应用中也被证明很有价值。维护团队评估资产健康状况,捕获图像 亚马逊重新认识基于功能摘要,以及使用智能搜索进行异常根本原因分析 检索增强生成 (抹布)。为了简化这些工作流程,AWS 引入了 亚马逊基岩,使您能够使用最先进的预训练 FM 来构建和扩展生成式 AI 应用程序,例如 克劳德 v2。 同 Amazon Bedrock 知识库,您可以简化 RAG 开发流程,为工厂工作人员提供更准确的异常根本原因分析。我们的帖子展示了由 Amazon Bedrock 提供支持的工业用例智能助手,可解决 NLQ 挑战、从图像生成零件摘要,以及通过 RAG 方法增强设备诊断的 FM 响应。
解决方案概述
下图说明了解决方案体系结构。

该工作流程包括三个不同的用例:
用例 1:具有时间序列数据的 NLQ
使用时间序列数据进行 NLQ 的工作流程包含以下步骤:
- 我们使用具有机器学习功能的状态监测系统来进行异常检测,例如 亚马逊Monitron,监控工业设备健康状况。 Amazon Monitron 能够通过设备的振动和温度测量来检测潜在的设备故障。
- 我们通过处理收集时间序列数据 亚马逊Monitron 数据通过 Amazon Kinesis数据流 和 亚马逊数据消防管,将其转换为表格 CSV 格式并将其保存在 亚马逊简单存储服务 (Amazon S3)存储桶。
- 最终用户可以通过向 Streamlit 应用程序发送自然语言查询来开始与 Amazon S3 中的时间序列数据聊天。
- Streamlit 应用程序将用户查询转发到 Amazon Bedrock Titan 文本嵌入模型 嵌入此查询,并在 亚马逊开放搜索服务 索引,其中包含先前的 NLQ 和示例代码。
- 相似性搜索后,最相似的示例(包括 NLQ 问题、数据模式和 Python 代码)将插入到自定义提示中。
- PandasAI 将此自定义提示发送到 Amazon Bedrock Claude v2 模型。
- 该应用程序使用 PandasAI 代理与 Amazon Bedrock Claude v2 模型交互,生成用于 Amazon Monitron 数据分析和 NLQ 响应的 Python 代码。
- Amazon Bedrock Claude v2 模型返回 Python 代码后,PandasAI 会对从应用程序上传的 Amazon Monitron 数据运行 Python 查询,收集代码输出并解决失败运行所需的任何重试问题。
- Streamlit 应用程序通过 PandasAI 收集响应,并将输出提供给用户。如果输出令人满意,用户可以将其标记为有帮助,并将 NLQ 和 Claude 生成的 Python 代码保存在 OpenSearch Service 中。
用例 2:故障部件的摘要生成
我们的摘要生成用例包含以下步骤:
- 用户知道哪个工业资产出现异常行为后,可以上传故障部件的图像,根据其技术规格和运行状况来识别该部件是否存在物理问题。
- 用户可以使用 亚马逊识别 DetectText API 从这些图像中提取文本数据。
- 提取的文本数据包含在 Amazon Bedrock Claude v2 模型的提示中,使模型能够生成故障部分的 200 字摘要。用户可以使用此信息对零件进行进一步检查。
用例 3:根本原因诊断
我们的根本原因诊断用例包括以下步骤:
- 用户获取与故障资产相关的各种文档格式(PDF、TXT 等)的企业数据,并将其上传到 S3 存储桶。
- 这些文件的知识库是在 Amazon Bedrock 中使用 Titan 文本嵌入模型和默认 OpenSearch Service 矢量存储生成的。
- 用户提出与故障设备的根本原因诊断相关的问题。答案是通过 Amazon Bedrock 知识库采用 RAG 方法生成的。
先决条件
要遵循这篇文章,您应该满足以下先决条件:
部署解决方案基础设施
要设置解决方案资源,请完成以下步骤:
- 部署 AWS CloudFormation 模板 opensearchsagemaker.yml,它创建 OpenSearch Service 集合和索引, 亚马逊SageMaker 笔记本实例和 S3 存储桶。您可以将此 AWS CloudFormation 堆栈命名为:
genai-sagemaker. - 在 JupyterLab 中打开 SageMaker 笔记本实例。你会发现以下内容 GitHub回购 已在此实例上下载: 释放工业运营中生成型人工智能的潜力.
- 从此存储库中的以下目录运行笔记本: 解锁工业运营中生成式人工智能的潜力/SagemakerNotebook/nlq-vector-rag-embedding.ipynb。此笔记本将使用 SageMaker 笔记本加载 OpenSearch 服务索引,以存储来自 现有 23 个 NLQ 示例.
- 从数据文件夹上传文档 资产部分文档 将 GitHub 存储库中的内容添加到 CloudFormation 堆栈输出中列出的 S3 存储桶。

接下来,您为 Amazon S3 中的文档创建知识库。
- 在 Amazon Bedrock 控制台上,选择 知识库 在导航窗格中。
- 创建知识库.
- 针对 知识库名称,输入名称。
- 针对 运行时角色, 选择 创建并使用新的服务角色.

- 针对 资料来源名称,输入您的数据源的名称。
- 针对 S3 URI,输入您上传根本原因文档的存储桶的 S3 路径。
- 下一页.
 Titan 嵌入模型是自动选择的。
Titan 嵌入模型是自动选择的。 - 选择 快速创建新的矢量存储.

- 检查您的设置并通过选择创建知识库 创建知识库.
- 知识库创建成功后,选择 Sync 将 S3 存储桶与知识库同步。

- 设置知识库后,您可以通过询问诸如“我的执行器运行缓慢,可能是什么问题?”之类的问题来测试 RAG 方法的根本原因诊断。

下一步是在您的 PC 或 EC2 实例 (Ubuntu Server 22.04 LTS) 上部署具有所需库包的应用程序。
- 设置您的 AWS 凭证 使用本地 PC 上的 AWS CLI。为简单起见,您可以使用用于部署 CloudFormation 堆栈的相同管理员角色。如果您使用的是 Amazon EC2, 将合适的 IAM 角色附加到实例.
- 克隆 GitHub回购:
- 将目录更改为
unlocking-the-potential-of-generative-ai-in-industrial-operations/src并运行setup.sh该文件夹中的脚本用于安装所需的软件包,包括 LangChain 和 PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - 使用以下命令运行 Streamlit 应用程序:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
提供您在上一步中在 Amazon Bedrock 中创建的 OpenSearch Service 集合 ARN。
与您的资产健康助理聊天
完成端到端部署后,您可以通过端口 8501 上的 localhost 访问该应用程序,这将打开一个带有 Web 界面的浏览器窗口。如果您将应用程序部署在 EC2 实例上, 通过安全组入站规则允许8501端口访问。您可以导航到不同用例的不同选项卡。
探索用例 1
要探索第一个用例,请选择 数据洞察和图表。首先上传您的时间序列数据。如果您没有现有的时间序列数据文件可供使用,您可以上传以下内容 示例 CSV 文件 具有匿名 Amazon Monitron 项目数据。如果您已有 Amazon Monitron 项目,请参阅 使用 Amazon Monitron 和 Amazon Kinesis 为预测性维护管理生成可操作的见解 将您的 Amazon Monitron 数据流式传输到 Amazon S3 并在此应用程序中使用您的数据。
上传完成后,输入查询以启动与您的数据的对话。左侧边栏提供了一系列示例问题,以方便您使用。以下屏幕截图说明了 FM 在输入问题(例如“告诉我分别显示为警告或警报的每个站点的传感器的唯一数量?”)时生成的响应和 Python 代码。 (一个困难级别的问题)或“对于显示温度信号不健康的传感器,您能否计算出每个传感器显示异常振动信号的持续时间(以天为单位)?” (挑战级问题)。该应用程序将回答您的问题,还将显示为生成此类结果而执行的数据分析的 Python 脚本。


如果您对答案满意,可以将其标记为 有帮助,将 NLQ 和 Claude 生成的 Python 代码保存到 OpenSearch Service 索引中。

探索用例 2
要探索第二个用例,请选择 捕获的图像摘要 Streamlit 应用程序中的选项卡。您可以上传工业资产的图片,应用程序将根据图片信息生成200字的技术规格和运行状况摘要。以下屏幕截图显示了从皮带电机驱动图像生成的摘要。要测试此功能,如果缺少合适的图像,可以使用以下 示例图片.
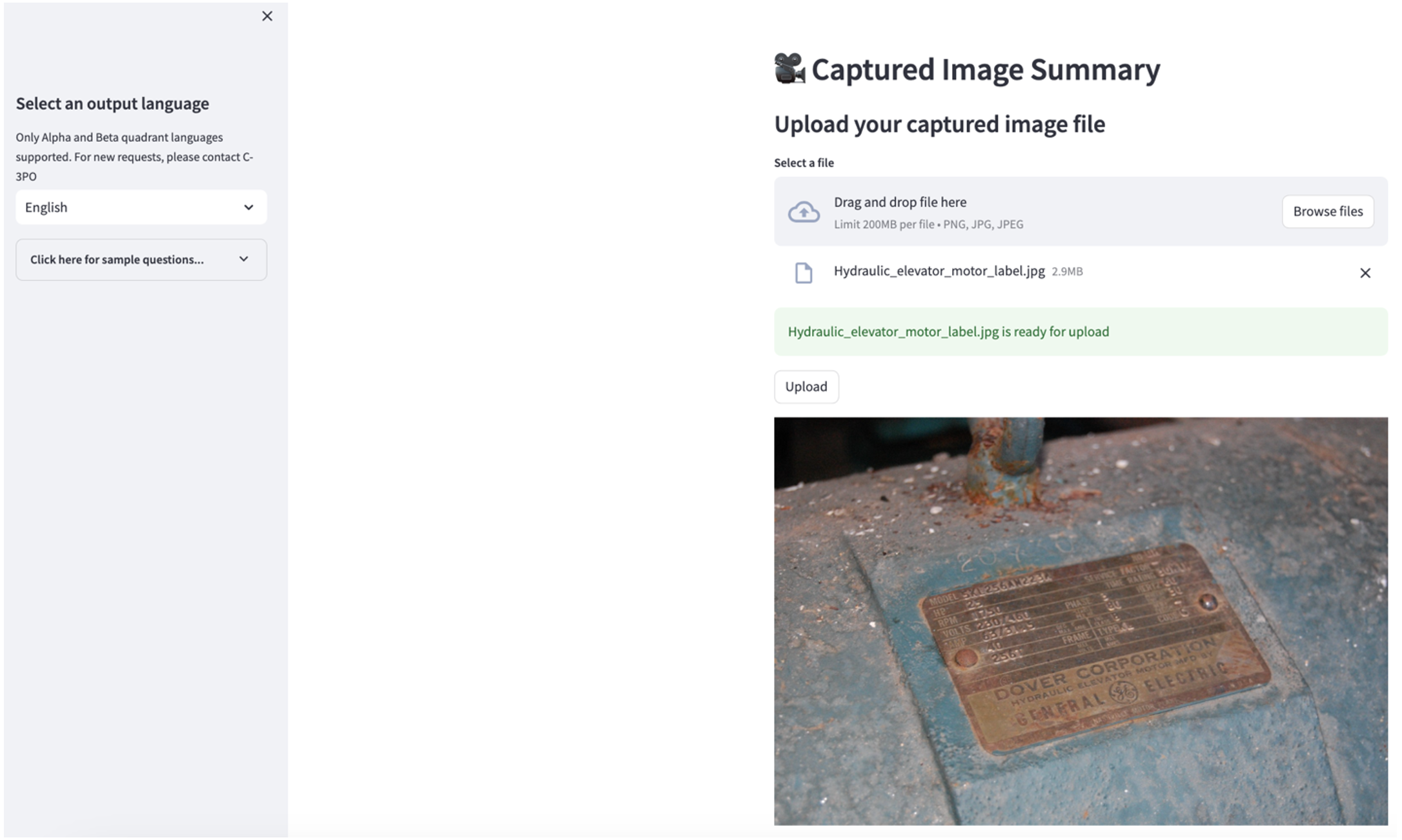
液压电梯电机标签” 作者:Clarence Risher 获得许可 CC BY-SA 2.0.

探索用例 3
要探索第三个用例,请选择 根本原因诊断 标签。输入与损坏的工业资产相关的查询,例如“我的执行器运行缓慢,可能是什么问题?”如以下屏幕截图所示,应用程序会提供响应以及用于生成答案的源文档摘录。

用例 1:设计细节
在本节中,我们将讨论第一个用例的应用程序工作流程的设计细节。
自定义提示构建
用户的自然语言查询有不同的难度级别:简单、困难和挑战。
简单的问题可能包括以下请求:
- 选择唯一值
- 统计总数
- 对值进行排序
对于这些问题,PandasAI可以直接与FM交互生成Python脚本进行处理。
困难问题需要基本的聚合操作或时间序列分析,例如:
- 首先选择值并对结果进行分层分组
- 初始记录选择后执行统计
- 时间戳计数(例如,最小值和最大值)
对于难题,带有详细分步说明的提示模板可帮助 FM 提供准确的答复。
挑战级别的问题需要高级数学计算和时间序列处理,例如:
- 计算每个传感器的异常持续时间
- 每月计算站点的异常传感器
- 比较正常操作和异常情况下的传感器读数
对于这些问题,您可以在自定义提示中使用多次射击来提高回答准确性。此类多重镜头展示了高级时间序列处理和数学计算的示例,并将为 FM 对类似分析执行相关推理提供背景。将 NLQ 题库中最相关的示例动态插入到提示中可能是一个挑战。一种解决方案是从现有的 NLQ 问题样本构建嵌入,并将这些嵌入保存在 OpenSearch Service 等向量存储中。当问题发送到 Streamlit 应用程序时,该问题将被矢量化为 基岩嵌入。使用以下命令检索与该问题最相关的前 N 个嵌入 opensearch_vector_search.similarity_search 并作为多镜头提示插入到提示模板中。
下图说明了此工作流程。

嵌入层是使用三个关键工具构建的:
- 嵌入模型 – 我们使用通过 Amazon Bedrock 提供的 Amazon Titan Embeddings (amazon.titan-embed-text-v1)生成文本文档的数字表示。
- 矢量商店 – 对于我们的向量存储,我们通过 LangChain 框架使用 OpenSearch 服务,简化了从本笔记本中的 NLQ 示例生成的嵌入的存储。
- Index – OpenSearch 服务索引在比较输入嵌入与文档嵌入以及促进相关文档的检索方面发挥着关键作用。由于 Python 示例代码保存为 JSON 文件,因此它们通过 OpenSearch Service 作为向量进行索引 OpenSearchVevtorSearch.fromtexts API调用。
通过 Streamlit 持续收集人工审核的示例
在应用程序开发之初,我们仅在 OpenSearch Service 索引中保存了 23 个示例作为嵌入。随着应用程序在现场上线,用户开始通过应用程序输入他们的 NLQ。但是,由于模板中可用的示例有限,某些 NLQ 可能找不到类似的提示。为了不断丰富这些嵌入并提供更相关的用户提示,您可以使用 Streamlit 应用程序来收集人工审核的示例。
在应用程序中,以下功能可用于此目的。当最终用户发现输出有帮助并选择 有帮助,应用程序遵循以下步骤:
- 使用 PandasAI 的回调方法来收集 Python 脚本。
- 将 Python 脚本、输入问题和 CSV 元数据重新格式化为字符串。
- 使用以下命令检查当前 OpenSearch 服务索引中是否已存在此 NLQ 示例 opensearch_vector_search.similarity_search_with_score.
- 如果没有类似的示例,则会使用以下命令将此 NLQ 添加到 OpenSearch Service 索引中 opensearch_vector_search.add_texts.
如果用户选择 没有帮助,不采取任何行动。这个迭代过程确保系统通过合并用户贡献的示例来不断改进。
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
通过纳入人工审核,OpenSearch Service 中可用于提示嵌入的示例数量随着应用程序使用量的增加而增加。随着时间的推移,这种扩展的嵌入数据集会提高搜索准确性。具体来说,对于具有挑战性的 NLQ,当动态插入类似示例为每个 NLQ 问题构建自定义提示时,FM 的响应准确率达到大约 90%。与没有多次提示的场景相比,这意味着显着增加了 28%。
用例 2:设计细节
在 Streamlit 应用程序上 捕获的图像摘要 选项卡中,您可以直接上传图像文件。这将启动 Amazon Rekognition API (检测文本 API),从图像标签中提取详细说明机器规格的文本。随后,提取的文本数据被发送到 Amazon Bedrock Claude 模型作为提示上下文,从而生成 200 字的摘要。
从用户体验的角度来看,为文本摘要任务启用流功能至关重要,允许用户以较小的块读取 FM 生成的摘要,而不是等待整个输出。 Amazon Bedrock 通过其 API 促进流式传输(bedrock_runtime.invoke_model_with_response_stream).
用例 3:设计细节
在这种情况下,我们采用 RAG 方法开发了一个专注于根本原因分析的聊天机器人应用程序。该聊天机器人借鉴了与轴承设备相关的多个文档,以促进根本原因分析。这个基于 RAG 的根本原因分析聊天机器人使用知识库来生成矢量文本表示或嵌入。 Amazon Bedrock 知识库是一项完全托管的功能,可帮助您实施整个 RAG 工作流程(从摄取到检索和提示增强),而无需构建与数据源的自定义集成或管理数据流和 RAG 实施细节。
当您对 Amazon Bedrock 的知识库响应感到满意时,您可以将知识库中的根本原因响应集成到 Streamlit 应用程序。
清理
为了节省成本,请删除您在本文中创建的资源:
- 从 Amazon Bedrock 中删除知识库。
- 删除 OpenSearch 服务索引。
- 删除 genai-sagemaker CloudFormation 堆栈。
- 如果您使用 EC2 实例运行 Streamlit 应用程序,请停止 EC2 实例。
结论
生成式人工智能应用程序已经改变了各种业务流程,提高了工人的生产力和技能。然而,FM 在处理时间序列数据分析方面的局限性阻碍了工业客户的充分利用。这一限制阻碍了生成式人工智能在日常处理的主要数据类型中的应用。
在这篇文章中,我们介绍了一种生成式人工智能应用解决方案,旨在缓解工业用户的这一挑战。该应用程序使用开源代理PandasAI来增强FM的时间序列分析能力。该应用程序不是将时间序列数据直接发送到 FM,而是使用 PandasAI 生成 Python 代码来分析非结构化时间序列数据。为了提高 Python 代码生成的准确性,实施了带有人工审核的自定义提示生成工作流程。
凭借对资产健康状况的洞察,产业工人可以在各种用例中充分利用生成式人工智能的潜力,包括根本原因诊断和零件更换计划。借助 Amazon Bedrock 知识库,开发人员可以轻松构建和管理 RAG 解决方案。
企业数据管理和运营的轨迹无疑正朝着与生成式人工智能更深入的集成方向发展,以全面洞察运营健康状况。这种由 Amazon Bedrock 引领的转变,因法学硕士(例如 亚马逊基岩克劳德 3 进一步提升解决方案。要了解更多信息,请访问咨询 亚马逊基岩文档,并亲自动手 亚马逊基岩工作室.
关于作者
 朱莉娅胡 是 Amazon Web Services 的高级 AI/ML 解决方案架构师。她专注于生成人工智能、应用数据科学和物联网架构。目前,她是 Amazon Q 团队的一员,也是机器学习技术领域社区的活跃成员/导师。她与从初创企业到大型企业的客户合作开发 AWSSome 生成式人工智能解决方案。她特别热衷于利用大型语言模型进行高级数据分析,并探索解决现实世界挑战的实际应用程序。
朱莉娅胡 是 Amazon Web Services 的高级 AI/ML 解决方案架构师。她专注于生成人工智能、应用数据科学和物联网架构。目前,她是 Amazon Q 团队的一员,也是机器学习技术领域社区的活跃成员/导师。她与从初创企业到大型企业的客户合作开发 AWSSome 生成式人工智能解决方案。她特别热衷于利用大型语言模型进行高级数据分析,并探索解决现实世界挑战的实际应用程序。
 苏迪什·萨西达兰 是 AWS 能源团队的高级解决方案架构师。 Sudeesh 喜欢尝试新技术并构建创新解决方案来解决复杂的业务挑战。当他不设计解决方案或修补最新技术时,您可以发现他在网球场上练习反手。
苏迪什·萨西达兰 是 AWS 能源团队的高级解决方案架构师。 Sudeesh 喜欢尝试新技术并构建创新解决方案来解决复杂的业务挑战。当他不设计解决方案或修补最新技术时,您可以发现他在网球场上练习反手。
 尼尔·德赛 是一位技术高管,在人工智能 (AI)、数据科学、软件工程和企业架构方面拥有 20 多年的经验。在 AWS,他领导着一支由全球人工智能服务专家解决方案架构师组成的团队,帮助客户构建创新的生成式人工智能驱动的解决方案、与客户分享最佳实践并推动产品路线图。 Neil 之前在维斯塔斯、霍尼韦尔和 Quest Diagnostics 任职期间,在开发和推出创新产品和服务方面担任领导职务,这些产品和服务帮助公司改善运营、降低成本和增加收入。他热衷于利用技术解决现实世界的问题,并且是一位拥有良好成功记录的战略思想家。
尼尔·德赛 是一位技术高管,在人工智能 (AI)、数据科学、软件工程和企业架构方面拥有 20 多年的经验。在 AWS,他领导着一支由全球人工智能服务专家解决方案架构师组成的团队,帮助客户构建创新的生成式人工智能驱动的解决方案、与客户分享最佳实践并推动产品路线图。 Neil 之前在维斯塔斯、霍尼韦尔和 Quest Diagnostics 任职期间,在开发和推出创新产品和服务方面担任领导职务,这些产品和服务帮助公司改善运营、降低成本和增加收入。他热衷于利用技术解决现实世界的问题,并且是一位拥有良好成功记录的战略思想家。

