Amazon Titan limage Generator G1 це передова модель перетворення тексту в зображення, доступна через Amazon Bedrock, здатний розуміти підказки, що описують кілька об’єктів у різних контекстах, і фіксувати ці релевантні деталі на створюваних зображеннях. Він доступний у Східному (Північна Вірджинія) і Західному (Орегон) регіонах США AWS і може виконувати розширені завдання редагування зображень, такі як інтелектуальне кадрування, малювання та зміна фону. Однак користувачі хотіли б адаптувати модель до унікальних характеристик у спеціальних наборах даних, на яких модель ще не навчена. Користувацькі набори даних можуть включати в себе конфіденційні дані, які відповідають правилам вашого бренду або певним стилям, наприклад попередній кампанії. Щоб вирішити ці випадки використання та створити повністю персоналізовані зображення, ви можете точно налаштувати Amazon Titan Image Generator за допомогою власних даних за допомогою спеціальні моделі для Amazon Bedrock.
Від створення зображень до їх редагування, моделі перетворення тексту в зображення мають широке застосування в різних галузях. Вони можуть підвищити креативність співробітників і надати можливість уявити нові можливості просто за допомогою текстових описів. Наприклад, він може допомогти архітекторам у проектуванні та плануванні поверхів і дозволить швидше впроваджувати інновації, надаючи можливість візуалізувати різні дизайни без ручного процесу їх створення. Так само він може допомогти в дизайні в різних галузях, таких як виробництво, дизайн одягу в роздрібній торгівлі та дизайн ігор, оптимізувавши створення графіки та ілюстрацій. Моделі перетворення тексту в зображення також покращують взаємодію з клієнтами, дозволяючи персоналізовану рекламу, а також інтерактивні та захоплюючі візуальні чат-боти в медіа та розважальних випадках.
У цій публікації ми проведемо вас через процес тонкого налаштування моделі Amazon Titan Image Generator, щоб вивчити дві нові категорії: собака Рон і кішка Сміла, наші улюблені домашні тварини. Ми обговорюємо, як підготувати ваші дані для завдання тонкого налаштування моделі та як створити завдання налаштування моделі в Amazon Bedrock. Нарешті, ми покажемо вам, як протестувати та розгорнути свою налаштовану модель Забезпечена пропускна здатність.
 |
 |
| собака Рон | Котик Сміла |
Оцінка можливостей моделі перед тонким налаштуванням завдання
Основні моделі навчаються на великих обсягах даних, тому цілком можливо, що ваша модель працюватиме достатньо добре з коробки. Ось чому доцільно перевірити, чи дійсно вам потрібно точно налаштувати свою модель для вашого випадку використання, чи достатньо оперативного проектування. Давайте спробуємо створити декілька зображень собаки Рона та кота Сміла за допомогою базової моделі Amazon Titan Image Generator, як показано на наступних знімках екрана.


Як і очікувалося, готова модель ще не знає Рона та Смілу, а згенеровані результати показують різних собак і котів. Завдяки швидкому розробці ми можемо надати більше деталей, щоб наблизити вигляд наших улюблених домашніх тварин.


Хоча створені зображення більше схожі на Рона та Смілу, ми бачимо, що модель не в змозі відтворити їх повну схожість. Тепер давайте почнемо тонке налаштування фотографій Рона та Сміли, щоб отримати узгоджені персоналізовані результати.
Точне налаштування Amazon Titan Image Generator
Amazon Bedrock надає вам безсерверний досвід для точного налаштування моделі Amazon Titan Image Generator. Вам потрібно лише підготувати дані та вибрати гіперпараметри, і AWS впорається з важким завданням за вас.
Коли ви використовуєте модель Amazon Titan Image Generator для точного налаштування, копія цієї моделі створюється в обліковому записі розробки моделі AWS, яким володіє та керує AWS, і створюється завдання налаштування моделі. Потім це завдання отримує доступ до даних точного налаштування з VPC, і модель Amazon Titan оновлює свої ваги. Потім нова модель зберігається в Служба простого зберігання Amazon (Amazon S3), що знаходиться в тому самому обліковому записі розробки моделі, що й попередньо навчена модель. Тепер він може використовуватися для висновків лише вашим обліковим записом і не надається іншим обліковим записам AWS. Під час запуску виведення ви отримуєте доступ до цієї моделі через a обчислення наданої ємності або безпосередньо, використовуючи пакетний висновок для Amazon Bedrock. Незалежно від вибраного способу висновку, ваші дані залишаються у вашому обліковому записі й не копіюються в облікові записи, що належать AWS, і не використовуються для вдосконалення моделі Amazon Titan Image Generator.
Наступна діаграма ілюструє цей робочий процес.

Конфіденційність даних і мережева безпека
Ваші дані, які використовуються для точного налаштування, включаючи підказки, а також спеціальні моделі, залишаються приватними у вашому обліковому записі AWS. Вони не надаються й не використовуються для навчання моделі чи покращення послуг, а також не надаються стороннім постачальникам моделей. Усі дані, які використовуються для точного налаштування, шифруються під час передавання та зберігання. Дані залишаються в тому ж регіоні, де обробляється виклик API. Ви також можете використовувати AWS PrivateLink щоб створити приватне з’єднання між обліковим записом AWS, де зберігаються ваші дані, та VPC.
Підготовка даних
Перш ніж ви зможете створити завдання налаштування моделі, вам потрібно це зробити підготуйте набір навчальних даних. Формат набору навчальних даних залежить від типу завдання налаштування, яке ви створюєте (точне налаштування або продовження попереднього навчання), і модальності ваших даних (перетворення тексту в текст, перетворення тексту в зображення або перетворення зображення в зображення). вбудовування). Для моделі Amazon Titan Image Generator вам потрібно надати зображення, які ви хочете використовувати для точного налаштування, і підпис для кожного зображення. Amazon Bedrock очікує, що ваші зображення зберігатимуться на Amazon S3, а пари зображень і підписів надаватимуться у форматі JSONL із кількома рядками JSON.
Кожен рядок JSON — це зразок, що містить посилання на зображення, URI S3 для зображення та підпис, що містить текстову підказку для зображення. Ваші зображення мають бути у форматі JPEG або PNG. У наступному коді показано приклад формату:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Оскільки «Рон» і «Сміла» — це імена, які також можна використовувати в інших контекстах, як-от ім’я людини, ми додаємо ідентифікатори «собака Рон» і «кіт Сміла» під час створення підказки для точного налаштування нашої моделі . Хоча це не є обов’язковою умовою для тонкого налаштування робочого процесу, ця додаткова інформація забезпечує більшу контекстуальну ясність для моделі під час її налаштування для нових класів і дозволить уникнути плутанини «собака Рона» з людиною на ім’я Рон і « Котик Сміла» з містом Сміла в Україні. Використовуючи цю логіку, наступні зображення показують зразок нашого навчального набору даних.
 |
 |
 |
| Собака Рон лежить на білому собачому ліжку | Собака Рон сидить на кахельній підлозі | Собака Рон лежить на сидінні автомобіля |
 |
 |
 |
| Кішка Smila лежить на дивані | Кіт Сміла дивиться на камеру, лежачи на дивані | Кіт Сміла лежить у переносці для домашніх тварин |
Під час перетворення наших даних у формат, очікуваний завданням налаштування, ми отримуємо наступну структуру зразка:
{"image-ref": "/ron_01.jpg", "caption": "Собака Рон лежить на білому собачому ліжку"} {"image-ref": "/ron_02.jpg", "caption": "Собака Рон сидить на кахельній підлозі"} {"image-ref": "/ron_03.jpg", "caption": "Собака Рон лежить на сидінні автомобіля"} {"image-ref": "/smila_01.jpg", "caption": "Кішка Сміла лежить на дивані"} {"image-ref": "/smila_02.jpg", "caption": "Кішка Сміла сидить біля вікна біля статуї кота"} {"image-ref": "/smila_03.jpg", "caption": "Кішка Сміла лежить на переносці для домашніх тварин"}
Після того, як ми створили наш файл JSONL, нам потрібно зберегти його у сегменті S3, щоб розпочати роботу з налаштування. Завдання тонкого налаштування Amazon Titan Image Generator G1 працюватимуть із 5–10,000 60 зображень. Для прикладу, який обговорюється в цій публікації, ми використовуємо 30 зображень: 30 зображень собаки Рона та XNUMX зображень кота Сміли. Загалом, надання більшої кількості різновидів стилю чи класу, які ви намагаєтеся вивчити, підвищить точність вашої точно налаштованої моделі. Однак чим більше зображень ви використовуєте для точного налаштування, тим більше часу знадобиться для завершення завдання точного налаштування. Кількість використаних зображень також впливає на ціну вашої точно налаштованої роботи. Відноситься до Ціни Amazon Bedrock для отримання додаткової інформації.
Точне налаштування Amazon Titan Image Generator
Тепер, коли у нас готові навчальні дані, ми можемо розпочати нову роботу з налаштування. Цей процес можна виконати як через консоль Amazon Bedrock, так і через API. Щоб використовувати консоль Amazon Bedrock, виконайте такі дії:
- Виберіть на консолі Amazon Bedrock Індивідуальні моделі у навігаційній панелі.
- на Налаштувати модель меню, виберіть Створіть завдання тонкого налаштування.
- для Точна назва моделі, введіть назву вашої нової моделі.
- для Конфігурація роботи, введіть назву навчальної роботи.
- для Вхідні дані, введіть шлях S3 вхідних даних.

- У Гіперпараметри укажіть значення для наступного:
- Кількість кроків – Кількість разів, коли модель піддається впливу кожної партії.
- Розмір партії – Кількість зразків, оброблених перед оновленням параметрів моделі.
- Швидкість навчання – Швидкість оновлення параметрів моделі після кожної партії. Вибір цих параметрів залежить від заданого набору даних. Як загальну вказівку ми рекомендуємо вам почати з фіксації розміру пакета на 8, швидкості навчання на 1e-5 і встановити кількість кроків відповідно до кількості використаних зображень, як описано в наступній таблиці.
| Кількість наданих зображень | 8 | 32 | 64 | 1,000 | 10,000 |
| Рекомендована кількість кроків | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Якщо результати вашої роботи з тонкого налаштування незадовільні, подумайте про збільшення кількості кроків, якщо ви не помічаєте жодних ознак стилю на згенерованих зображеннях, і зменшення кількості кроків, якщо ви спостерігаєте стиль у згенерованих зображеннях, але з артефактами або розмитістю. Якщо детально налаштована модель не може засвоїти унікальний стиль у вашому наборі даних навіть після 40,000 XNUMX кроків, подумайте про збільшення розміру пакету або швидкості навчання.
- У Вихідні дані у розділі введіть вихідний шлях S3, де зберігаються результати перевірки, включаючи періодично зареєстровані показники втрати перевірки та точності.
- У Доступ до сервісу розділ, створіть новий Управління ідентифікацією та доступом AWS (IAM) або виберіть наявну роль IAM з необхідними дозволами для доступу до сегментів S3.
Ця авторизація дає змогу Amazon Bedrock отримувати вхідні дані та набори даних перевірки з призначеного вами сегмента та безперешкодно зберігати результати перевірки у вашому сегменті S3.
- Вибирати Тонка настройка моделі.

Після встановлення правильних конфігурацій Amazon Bedrock навчить вашу спеціальну модель.
Розгорніть налаштований Amazon Titan Image Generator із забезпеченою пропускною здатністю
Після того, як ви створите настроювану модель, Provisioned Throughput дає змогу призначити наперед визначену фіксовану швидкість обробки для настроюваної моделі. Цей розподіл забезпечує постійний рівень продуктивності та потужності для обробки робочих навантажень, що призводить до кращої продуктивності робочих навантажень виробництва. Другою перевагою Provisioned Throughput є контроль витрат, оскільки стандартне ціноутворення на основі токенів із режимом висновку за вимогою може бути важко передбачити у великих масштабах.
Після завершення точного налаштування вашої моделі ця модель з’явиться на сторінці індивідуальні моделі на консолі Amazon Bedrock.
Щоб придбати Provisioned Throughput, виберіть спеціальну модель, яку ви щойно налаштували, і виберіть Забезпечена пропускна здатність покупки.
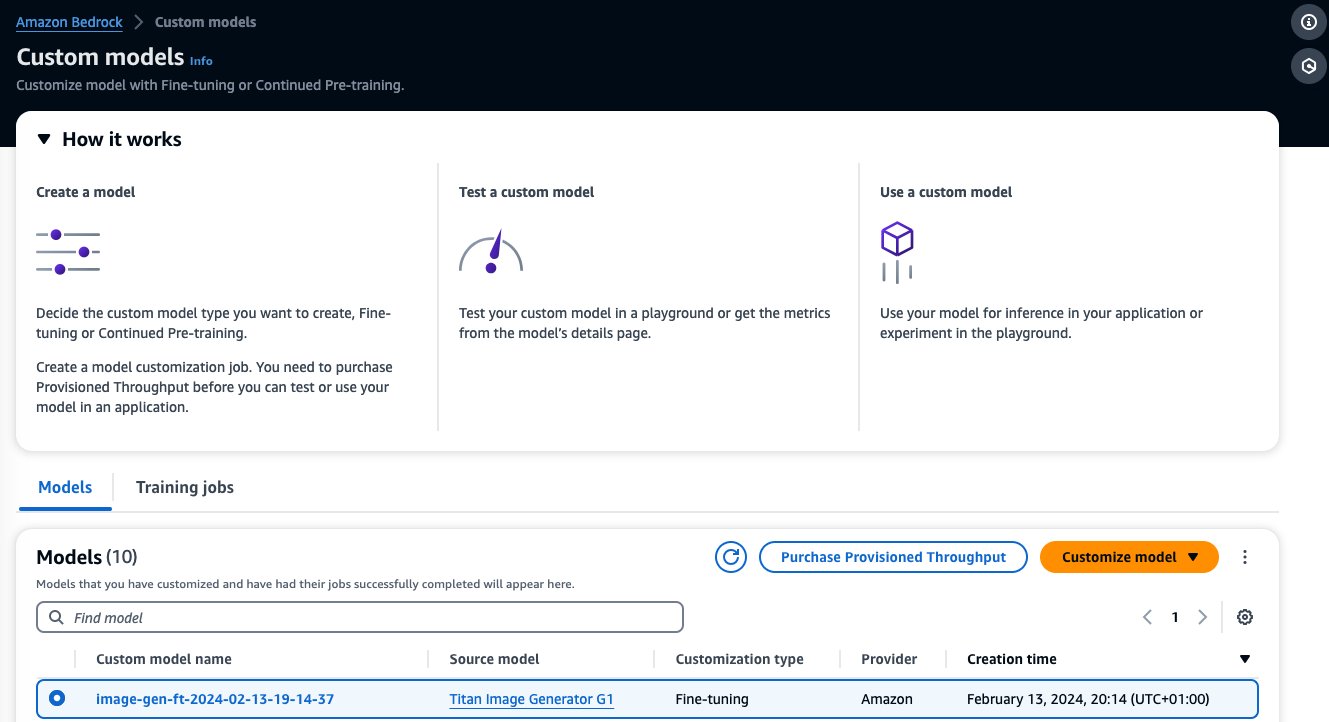
Це попередньо заповнює вибрану модель, для якої ви хочете придбати Provisioned Throughput. Щоб перевірити налаштовану модель перед розгортанням, установіть для одиниць моделі значення 1 і встановіть термін зобов’язання на Ніяких зобов'язань. Це дає змогу швидко розпочати тестування моделей за допомогою спеціальних підказок і перевірити, чи відповідне навчання. Крім того, коли доступні нові вдосконалені моделі та нові версії, ви можете оновити передбачену пропускну здатність, якщо ви оновлюєте її за допомогою інших версій тієї ж моделі.

Результати тонкого налаштування
Експерименти показали, що для нашого завдання з налаштування моделі собаки Рона та кота Сміли найкращими гіперпараметрами були 5,000 кроків із розміром пакету 8 і швидкістю навчання 1e-5.
Нижче наведено кілька прикладів зображень, створених налаштованою моделлю.
 |
 |
 |
| Пес Рон у накидці супергероя | Собака Рон на Місяці | Собака Рон у басейні в темних окулярах |
 |
 |
 |
| Сміла кішка на снігу | Чорно-білий кіт Сміла дивиться на камеру | Кіт Сміла в різдвяному капелюшку |
Висновок
У цій публікації ми обговорили, коли використовувати точне налаштування замість інженерних підказок для генерації зображення кращої якості. Ми показали, як точно налаштувати модель Amazon Titan Image Generator і розгорнути спеціальну модель на Amazon Bedrock. Ми також надали загальні вказівки щодо того, як підготувати ваші дані для тонкого налаштування та встановити оптимальні гіперпараметри для більш точного налаштування моделі.
Як наступний крок ви можете адаптувати наступне приклад для вашого сценарію використання для створення гіперперсоналізованих зображень за допомогою Amazon Titan Image Generator.
Про авторів
 Майра Ладейра Танке є старшим науковим спеціалістом із створення даних AI в AWS. Маючи досвід машинного навчання, вона має понад 10 років досвіду розробки та створення додатків штучного інтелекту з клієнтами в різних галузях. Як технічний керівник, вона допомагає клієнтам прискорити досягнення бізнес-цінності за допомогою генеративних рішень ШІ на Amazon Bedrock. У вільний час Майра любить подорожувати, грати зі своєю кішкою Смілою та проводити час із сім’єю в теплому місці.
Майра Ладейра Танке є старшим науковим спеціалістом із створення даних AI в AWS. Маючи досвід машинного навчання, вона має понад 10 років досвіду розробки та створення додатків штучного інтелекту з клієнтами в різних галузях. Як технічний керівник, вона допомагає клієнтам прискорити досягнення бізнес-цінності за допомогою генеративних рішень ШІ на Amazon Bedrock. У вільний час Майра любить подорожувати, грати зі своєю кішкою Смілою та проводити час із сім’єю в теплому місці.
 Дені Мітчелл є архітектором спеціалістів із штучного інтелекту та ML в Amazon Web Services. Він зосереджується на прикладах використання комп’ютерного зору та допомагає клієнтам у регіоні EMEA пришвидшити їх шлях до машинного навчання.
Дені Мітчелл є архітектором спеціалістів із штучного інтелекту та ML в Amazon Web Services. Він зосереджується на прикладах використання комп’ютерного зору та допомагає клієнтам у регіоні EMEA пришвидшити їх шлях до машинного навчання.
 Бхаратхі Шрінівасан працює спеціалістом із обробки даних у AWS Professional Services, де їй подобається створювати круті речі на Amazon Bedrock. Вона захоплена підвищенням цінності для бізнесу завдяки додаткам машинного навчання, зосереджуючись на відповідальному ШІ. Окрім створення нових можливостей штучного інтелекту для клієнтів, Бхараті любить писати наукову фантастику та займатися спортом на витривалість.
Бхаратхі Шрінівасан працює спеціалістом із обробки даних у AWS Professional Services, де їй подобається створювати круті речі на Amazon Bedrock. Вона захоплена підвищенням цінності для бізнесу завдяки додаткам машинного навчання, зосереджуючись на відповідальному ШІ. Окрім створення нових можливостей штучного інтелекту для клієнтів, Бхараті любить писати наукову фантастику та займатися спортом на витривалість.
 Ачин Джайн є прикладним науковцем у команді Amazon Artificial General Intelligence (AGI). Він має досвід роботи з моделями перетворення тексту в зображення та зосереджений на створенні Amazon Titan Image Generator.
Ачин Джайн є прикладним науковцем у команді Amazon Artificial General Intelligence (AGI). Він має досвід роботи з моделями перетворення тексту в зображення та зосереджений на створенні Amazon Titan Image Generator.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

