Організації в різних галузях хочуть класифікувати та витягувати інформацію з великих обсягів документів різних форматів. Ручна обробка цих документів для класифікації та вилучення інформації залишається дорогою, схильною до помилок і важкою для масштабування. Аванси в генеративний штучний інтелект (AI) створили рішення для інтелектуальної обробки документів (IDP), які можуть автоматизувати класифікацію документів і створити економічно ефективний рівень класифікації, здатний обробляти різноманітні неструктуровані корпоративні документи.
Категоризація документів є важливим першим кроком у системах ВПО. Це допоможе вам визначити наступний набір дій залежно від типу документа. Наприклад, під час процесу розгляду претензій група з питань кредиторської заборгованості отримує рахунок-фактуру, тоді як відділ претензій керує контрактом або політичними документами. Традиційні механізми правил або класифікація на основі ML можуть класифікувати документи, але часто досягають обмежень щодо типів форматів документів і підтримки динамічного додавання нових класів документів. Для отримання додаткової інформації див Класифікатор документів Amazon Comprehend додає підтримку макета для більшої точності.
У цій публікації ми обговорюємо класифікацію документів за допомогою Модель Amazon Titan Multimodal Embeddings класифікувати будь-які типи документів без необхідності навчання.
Amazon Titan Multimodal Embeddings
Нещодавно представлений Amazon Titan Multimodal Embeddings in Amazon Bedrock. Ця модель може створювати вбудовування для зображень і тексту, дозволяючи створювати вбудовування документів для використання в нових робочих процесах класифікації документів.
Він створює оптимізоване векторне представлення документів, відсканованих як зображення. Завдяки кодуванню як візуальних, так і текстових компонентів у єдині числові вектори, які інкапсулюють семантичне значення, це забезпечує швидке індексування, потужний контекстний пошук і точну класифікацію документів.
Коли в бізнес-процесах з’являються нові шаблони та типи документів, ви можете просто викликати API Amazon Bedrock динамічно векторизувати їх і додавати до своїх систем IDP для швидкого розширення можливостей класифікації документів.
Огляд рішення
Давайте розглянемо наступне рішення для класифікації документів із моделлю Amazon Titan Multimodal Embeddings. Для досягнення оптимальної продуктивності вам слід налаштувати рішення відповідно до конкретного випадку використання та наявних налаштувань конвеєра IDP.
Це рішення класифікує документи за допомогою семантичного пошуку із вбудованим вектором, зіставляючи вхідний документ із уже проіндексованою галереєю документів. Ми використовуємо наступні ключові компоненти:
- Вкладиші - Вкладиші це числові представлення об’єктів реального світу, які використовують системи машинного навчання (ML) і ШІ для розуміння складних областей знань, як це роблять люди.
- Векторні бази даних - Векторні бази даних використовуються для зберігання вставок. Векторні бази даних ефективно індексують і впорядковують вбудовування, забезпечуючи швидкий пошук схожих векторів на основі таких показників відстані, як евклідова відстань або подібність косинусів.
- Семантичний пошук – Семантичний пошук працює, враховуючи контекст і значення вхідного запиту та його відповідність вмісту, який шукається. Вбудовування векторів — це ефективний спосіб зафіксувати й зберегти контекстне значення тексту та зображень. У нашому рішенні, коли програма хоче виконати семантичний пошук, пошуковий документ спочатку перетворюється на вбудовування. Потім виконується запит до векторної бази даних із відповідним вмістом, щоб знайти найбільш схожі вбудовування.
У процесі маркування зразок набору бізнес-документів, як-от рахунків-фактур, банківських виписок або рецептів, перетворюється на вбудовування за допомогою моделі Amazon Titan Multimodal Embeddings і зберігається у векторній базі даних із попередньо визначеними мітками. Модель Amazon Titan Multimodal Embedding було навчено за допомогою алгоритму Евкліда L2, тому для отримання найкращих результатів використана векторна база даних має підтримувати цей алгоритм.
Наступна діаграма архітектури ілюструє, як можна використовувати модель Amazon Titan Multimodal Embeddings із документами в Служба простого зберігання Amazon (Amazon S3) відро для створення галереї зображень.
Робочий процес складається з наступних кроків:
- Користувач або програма завантажує зразок зображення документа з метаданими класифікації в галерею зображень документа. Для класифікації зображень галереї можна використовувати префікс S3 або метадані об’єкта S3.
- Подія сповіщення об’єкта Amazon S3 викликає вбудовування AWS Lambda функції.
- Функція Lambda зчитує зображення документа та перетворює зображення на вбудовування, викликаючи Amazon Bedrock і використовуючи модель Amazon Titan Multimodal Embeddings.
- Вбудовані зображення разом із класифікацією документів зберігаються у векторній базі даних.
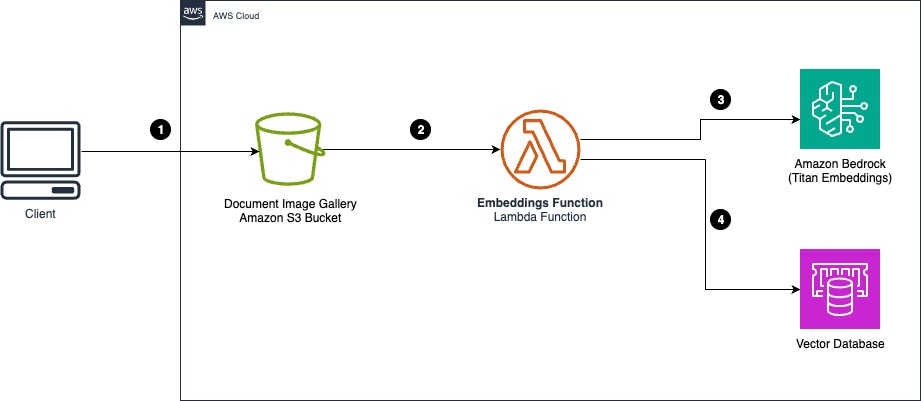
Коли новий документ потребує класифікації, та сама модель вбудовування використовується для перетворення документа запиту на вбудовування. Потім у векторній базі даних виконується семантичний пошук подібності за допомогою вбудовування запиту. Мітка, отримана за найвищим збігом вбудовування, буде міткою класифікації для документа запиту.
Наступна схема архітектури ілюструє, як використовувати модель Amazon Titan Multimodal Embeddings із документами в сегменті S3 для класифікації зображень.
Робочий процес складається з наступних кроків:
- Документи, які потребують класифікації, завантажуються у вхідне відро S3.
- Функція класифікації Lambda отримує повідомлення про об’єкт Amazon S3.
- Функція Lambda перетворює зображення на вбудовування, викликаючи API Amazon Bedrock.
- У векторній базі даних шукається відповідний документ за допомогою семантичного пошуку. Класифікація відповідного документа використовується для класифікації вхідного документа.
- Вхідний документ переміщується до цільового каталогу S3 або префікса за допомогою класифікації, отриманої з пошуку векторної бази даних.

Щоб допомогти вам перевірити рішення за допомогою ваших власних документів, ми створили приклад блокнота Python Jupyter, який доступний на GitHub.
Передумови
Щоб запустити блокнот, вам потрібен Обліковий запис AWS з відповідною Управління ідентифікацією та доступом AWS (IAM) дозволи на виклик Amazon Bedrock. Додатково на в Доступ до моделі на сторінці консолі Amazon Bedrock переконайтеся, що доступ надано для моделі Amazon Titan Multimodal Embeddings.
Реалізація
У наступних кроках замініть кожен заповнювач, введений користувачем, своєю власною інформацією:
- Створіть векторну базу даних. У цьому рішенні ми використовуємо базу даних FAISS у пам’яті, але ви можете використовувати альтернативну векторну базу даних. Розмір розміру Amazon Titan за умовчанням становить 1024.
- Після того, як векторну базу даних створено, пронумеруйте зразки документів, створивши вбудовування кожного з них і збережіть їх у векторній базі даних
- Перевірте зі своїми документами. Замініть папки в наведеному нижче коді своїми власними папками, які містять відомі типи документів:
- Використовуючи бібліотеку Boto3, викличте Amazon Bedrock. Змінна
inputImageB64це масив байтів у кодуванні base64, що представляє ваш документ. Відповідь від Amazon Bedrock містить вбудовування.
- Додайте вбудовування до векторної бази даних з ідентифікатором класу, який представляє відомий тип документа:
- Завдяки векторній базі даних, наповненій зображеннями (які представляють нашу галерею), ви можете виявити схожість із новими документами. Наприклад, наступний синтаксис використовується для пошуку. K=1 повідомляє FAISS повернути найкращий 1 збіг.
Крім того, також повертається евклідова відстань L2 між наявним зображенням і знайденим зображенням. Якщо зображення точно збігається, це значення дорівнюватиме 0. Що більше це значення, то далі зображення схожі.
Додаткові міркування
У цьому розділі ми обговорюємо додаткові міркування щодо ефективного використання рішення. Це включає конфіденційність даних, безпеку, інтеграцію з існуючими системами та оцінку витрат.
Конфіденційність даних та безпека
AWS модель спільної відповідальності стосується захист даних в Amazon Bedrock. Як описано в цій моделі, AWS відповідає за захист глобальної інфраструктури, на якій працює вся хмара AWS. Клієнти несуть відповідальність за контроль над своїм вмістом, розміщеним у цій інфраструктурі. Як клієнт ви несете відповідальність за конфігурацію безпеки та завдання керування службами AWS, якими ви користуєтеся.
Захист даних в Amazon Bedrock
Amazon Bedrock уникає використання підказок клієнтів і продовжень для навчання моделей AWS або надання ними доступу третім особам. Amazon Bedrock не зберігає та не реєструє дані клієнтів у своїх журналах обслуговування. Постачальники моделей не мають доступу до журналів Amazon Bedrock або доступу до підказок і продовжень клієнтів. Як результат, зображення, які використовуються для створення вставок за допомогою моделі Amazon Titan Multimodal Embeddings, не зберігаються та не використовуються в навчальних моделях AWS або зовнішньому розповсюдженні. Крім того, інші дані про використання, такі як мітки часу та зареєстровані ідентифікатори облікових записів, виключаються з навчання моделі.
Інтеграція з існуючими системами
Модель Amazon Titan Multimodal Embeddings пройшла навчання з алгоритмом Euclidean L2, тому векторна база даних, яка використовується, має бути сумісною з цим алгоритмом.
Кошторис
На момент написання цього допису, згідно з Ціни Amazon Bedrock для моделі Amazon Titan Multimodal Embeddings нижче наведено приблизні витрати з використанням ціноутворення за запитом для цього рішення:
- Одноразова вартість індексації – $0.06 за один запуск індексування, припускаючи, що галерея містить 1,000 зображень
- Вартість класифікації – $6 за 100,000 XNUMX вхідних зображень на місяць
Прибирати
Щоб уникнути майбутніх витрат, видаліть створені вами ресурси, наприклад Примірник блокнота Amazon SageMaker, коли не використовується.
Висновок
У цій публікації ми дослідили, як можна використовувати модель Amazon Titan Multimodal Embeddings для створення недорогого рішення для класифікації документів у робочому процесі IDP. Ми продемонстрували, як створити галерею зображень відомих документів і виконати пошук схожості з новими документами, щоб класифікувати їх. Ми також обговорили переваги використання мультимодальних вбудованих зображень для класифікації документів, зокрема їх здатність обробляти різноманітні типи документів, масштабованість і низьку затримку.
Коли в бізнес-процесах з’являються нові шаблони та типи документів, розробники можуть викликати Amazon Bedrock API, щоб динамічно їх векторизувати та додавати до своїх систем IDP для швидкого покращення можливостей класифікації документів. Це створює недорогий шар класифікації з безмежним масштабуванням, який може обробляти навіть найрізноманітніші неструктуровані корпоративні документи.
Загалом, ця публікація містить дорожню карту створення недорогого рішення для класифікації документів у робочому процесі IDP за допомогою Amazon Titan Multimodal Embeddings.
Як наступні кроки перевірте Що таке Amazon Bedrock щоб почати користуватися послугою. І слідуйте Amazon Bedrock у блозі машинного навчання AWS щоб бути в курсі нових можливостей і випадків використання Amazon Bedrock.
Про авторів
 Суміт Бхаті є старшим менеджером з рішень для клієнтів в AWS, спеціалізується на прискоренні хмарної подорожі для корпоративних клієнтів. Sumit прагне допомогти клієнтам на кожному етапі впровадження хмарних технологій, від прискорення міграції до модернізації робочих навантажень і сприяння інтеграції інноваційних практик.
Суміт Бхаті є старшим менеджером з рішень для клієнтів в AWS, спеціалізується на прискоренні хмарної подорожі для корпоративних клієнтів. Sumit прагне допомогти клієнтам на кожному етапі впровадження хмарних технологій, від прискорення міграції до модернізації робочих навантажень і сприяння інтеграції інноваційних практик.
 Девід Гірлінг є старшим архітектором рішень AI/ML із понад 20-річним досвідом проектування, керування та розробки корпоративних систем. Девід є частиною команди спеціалістів, яка зосереджена на тому, щоб допомогти клієнтам вивчати, впроваджувати інновації та використовувати ці високопродуктивні служби з їх даними для своїх випадків використання.
Девід Гірлінг є старшим архітектором рішень AI/ML із понад 20-річним досвідом проектування, керування та розробки корпоративних систем. Девід є частиною команди спеціалістів, яка зосереджена на тому, щоб допомогти клієнтам вивчати, впроваджувати інновації та використовувати ці високопродуктивні служби з їх даними для своїх випадків використання.
 Раві Авула є старшим архітектором рішень в AWS, який зосереджується на корпоративній архітектурі. Раві має 20-річний досвід у розробці програмного забезпечення та обіймав кілька керівних посад у розробці програмного забезпечення та архітектурі програмного забезпечення, працюючи в індустрії платежів.
Раві Авула є старшим архітектором рішень в AWS, який зосереджується на корпоративній архітектурі. Раві має 20-річний досвід у розробці програмного забезпечення та обіймав кілька керівних посад у розробці програмного забезпечення та архітектурі програмного забезпечення, працюючи в індустрії платежів.
 Джордж Белсіан є старшим архітектором хмарних програм в AWS. Він прагне допомогти клієнтам прискорити процес модернізації та впровадження хмарних технологій. У своїй нинішній посаді Джордж працює разом із командами клієнтів над розробкою стратегії, проектуванням і розробкою інноваційних масштабованих рішень.
Джордж Белсіан є старшим архітектором хмарних програм в AWS. Він прагне допомогти клієнтам прискорити процес модернізації та впровадження хмарних технологій. У своїй нинішній посаді Джордж працює разом із командами клієнтів над розробкою стратегії, проектуванням і розробкою інноваційних масштабованих рішень.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/cost-effective-document-classification-using-the-amazon-titan-multimodal-embeddings-model/

