Це гостьовий пост, написаний у співавторстві з керівництвом Iambic Therapeutics.
Ямбічна терапія – це стартап із розробки ліків, місія якого полягає у створенні інноваційних технологій на основі штучного інтелекту, щоб швидше надавати кращі ліки хворим на рак.
Наші передові інструменти генеративного та прогнозного штучного інтелекту (ШІ) дозволяють нам швидше та ефективніше шукати величезний простір можливих молекул ліків. Наші технології є універсальними та застосовними в різних терапевтичних областях, класах білків і механізмах дії. Окрім створення диференційованих інструментів ШІ, ми створили інтегровану платформу, яка об’єднує програмне забезпечення ШІ, хмарні дані, масштабовану обчислювальну інфраструктуру та високопродуктивні можливості хімії та біології. Платформа забезпечує наш штучний інтелект, надаючи дані для вдосконалення наших моделей, і підтримується ним, використовуючи можливості для автоматизованого прийняття рішень і обробки даних.
Ми вимірюємо успіх нашою здатністю створювати чудові клінічні кандидати для вирішення нагальних потреб пацієнтів із безпрецедентною швидкістю: ми просунулися від запуску програми до клінічних кандидатів лише за 24 місяці, значно швидше, ніж наші конкуренти.
У цій публікації ми зосередимося на тому, як ми використовували Карпентер on Послуга Amazon Elastic Kubernetes (Amazon EKS) для масштабування навчання штучного інтелекту та висновків, які є основними елементами платформи відкриття Iambic.
Потреба в масштабованому навчанні ШІ та висновках
Щотижня Iambic виконує штучний інтелект для десятків моделей і мільйонів молекул, обслуговуючи два основних випадки використання:
- Хіміки-медики та інші вчені використовують нашу веб-програму Insight, щоб досліджувати хімічний простір, отримувати доступ до експериментальних даних і інтерпретувати їх, а також прогнозувати властивості новостворених молекул. Уся ця робота виконується в інтерактивному режимі в реальному часі, створюючи потребу в висновках із низькою затримкою та середньою пропускною здатністю.
- Водночас наші генеративні моделі штучного інтелекту автоматично проектують молекули, націлені на покращення багатьох властивостей, шукають мільйони кандидатів і вимагають величезної пропускної здатності та середньої затримки.
Керуючись технологіями штучного інтелекту та експертами-мисливцями за наркотиками, наша експериментальна платформа щотижня генерує тисячі унікальних молекул, кожна з яких піддається численним біологічним аналізам. Згенеровані точки даних автоматично обробляються та використовуються для точного налаштування наших моделей ШІ щотижня. Спочатку тонке налаштування нашої моделі займало години процесорного часу, тому структура для масштабування точного налаштування моделі на графічних процесорах була обов’язковою.
Наші моделі глибокого навчання мають нетривіальні вимоги: вони мають розмір у гігабайтах, є численними та різнорідними та потребують графічних процесорів для швидкого висновку та тонкого налаштування. Розглядаючи хмарну інфраструктуру, нам потрібна була система, яка б дозволяла нам отримувати доступ до графічних процесорів, швидко збільшувати та зменшувати масштаб, щоб справлятися з різкими неоднорідними робочими навантаженнями та запускати великі образи Docker.
Ми хотіли створити масштабовану систему для підтримки навчання ШІ та висновків. Ми використовуємо Amazon EKS і шукали найкраще рішення для автоматичного масштабування наших робочих вузлів. Ми вибрали Karpenter для автоматичного масштабування вузла Kubernetes з кількох причин:
- Простота інтеграції з Kubernetes, використання семантики Kubernetes для визначення вимог до вузлів і специфікацій модулів для масштабування
- Масштабування вузлів із низькою затримкою
- Простота інтеграції з нашою інфраструктурою як інструментарій кодування (Terraform)
Провайдери вузлів підтримують легку інтеграцію з Amazon EKS та іншими ресурсами AWS, як-от Обчислювальна хмара Amazon Elastic (Amazon EC2) примірники та Магазин еластичних блоків Amazon обсяги. Семантика Kubernetes, яку використовують провайдери, підтримує спрямоване планування за допомогою конструкцій Kubernetes, таких як плями або допуски, а також специфікації спорідненості або антиспорідненості; вони також полегшують контроль над кількістю та типами екземплярів GPU, які можуть бути заплановані Карпентером.
Огляд рішення
У цьому розділі ми представляємо загальну архітектуру, подібну до тієї, яку ми використовуємо для наших власних робочих навантажень, яка дозволяє еластичне розгортання моделей за допомогою ефективного автоматичного масштабування на основі користувацьких показників.
Наступна діаграма ілюструє архітектуру рішення.

Архітектура розгортає a простий сервіс у модулі Kubernetes у межах an Кластер EKS. Це може бути висновок моделі, симуляція даних або будь-який інший контейнерний сервіс, доступний через запит HTTP. Служба розкрита за допомогою зворотного проксі Traefik. Зворотний проксі-сервер збирає метрики про виклики служби та надає їх через стандартний API метрик Прометей. Керований подіями автомасштабувальник Kubernetes (KEDA) налаштовано на автоматичне масштабування кількості пакетів послуг на основі спеціальних показників, доступних у Prometheus. Тут ми використовуємо кількість запитів за секунду як спеціальний показник. Той самий архітектурний підхід застосовується, якщо ви виберете інший показник для свого робочого навантаження.
Karpenter стежить за будь-якими модулями, що очікують на розгляд, які не можуть працювати через відсутність достатніх ресурсів у кластері. Якщо такі модулі виявлені, Карпентер додає додаткові вузли до кластера, щоб забезпечити необхідні ресурси. І навпаки, якщо в кластері більше вузлів, ніж потрібно для запланованих модулів, Карпентер видаляє деякі робочі вузли, і модулі переплановуються, консолідуючи їх у меншій кількості екземплярів. Кількість HTTP-запитів за секунду та кількість вузлів можна візуалізувати за допомогою a Grafana панель приладів. Щоб продемонструвати автоматичне масштабування, ми запускаємо один або декілька прості вантажоутворювальні контейнери, які надсилають HTTP-запити до служби за допомогою витися.
Розгортання рішення
У покрокова інструкція, ми використовуємо AWS Cloud9 як середовище для розгортання архітектури. Це дає змогу виконувати всі кроки з веб-браузера. Ви також можете розгорнути рішення з локального комп’ютера або інсталяції EC2.
Щоб спростити розгортання та покращити відтворюваність, ми дотримуємося принципів do-framework та структура шаблон depend-on-docker. Ми клонуємо aws-do-eks проект і, використовуючи Docker, ми створюємо образ контейнера, оснащений необхідними інструментами та сценаріями. Усередині контейнера ми проходимо всі кроки наскрізного керівництва, від створення кластера EKS за допомогою Karpenter до масштабування екземпляри EC2.
Для прикладу в цій публікації ми використовуємо наступне Маніфест кластера EKS:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueЦей маніфест визначає кластер під назвою do-eks-yaml-karpenter з драйвером EBS CSI, встановленим як доповнення. Керована група вузлів із двома c5.xlarge вузлів включено для запуску системних модулів, необхідних кластеру. Робочі вузли розміщені в приватних підмережах, а кінцева точка API кластера загальнодоступна за замовчуванням.
Ви також можете використовувати наявний кластер EKS замість того, щоб його створювати. Ми розгортаємо Karpenter, дотримуючись інструкції у документації Karpenter або виконавши наступне сценарій, що автоматизує інструкції з розгортання.
Наступний код показує конфігурацію Karpenter, яку ми використовуємо в цьому прикладі:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueМи визначаємо типовий пул вузлів Karpenter із такими вимогами:
- Karpenter може запускати екземпляри з обох
spotтаon-demandмісткість пулів - Екземпляри мають бути з "
c” (оптимізовано для обчислень), “m" (Головна мета), "r” (оптимізовано пам’ять) або „g"І"p” (прискорений GPU) обчислювальних сімейств - Генерація екземплярів має бути більше 2; наприклад,
g3прийнятно, алеg2НЕ
Пул вузлів за замовчуванням також визначає політики зриву. Вузли, які не використовуються, буде видалено, щоб модулі можна було консолідувати для роботи на меншій кількості вузлів. Крім того, ми можемо налаштувати видалення порожніх вузлів після зазначеного періоду часу. The expireAfter Параметр визначає максимальний термін служби будь-якого вузла, перш ніж його буде зупинено та замінено, якщо необхідно. Це допомагає зменшити вразливість системи безпеки, а також уникнути проблем, типових для вузлів із тривалим часом безвідмовної роботи, таких як фрагментація файлів або витік пам’яті.
За замовчуванням Karpenter надає вузли з невеликим кореневим об’ємом, якого може бути недостатньо для виконання робочих навантажень AI або машинного навчання (ML). Розмір деяких зображень контейнерів глибокого навчання може становити десятки ГБ, і нам потрібно переконатися, що на вузлах достатньо місця для зберігання, щоб запускати модулі за допомогою цих зображень. Для цього ми визначаємо EC2NodeClass з blockDeviceMappings, як показано в попередньому коді.
Карпентер відповідає за автоматичне масштабування на рівні кластера. Щоб налаштувати автоматичне масштабування на рівні модуля, ми використовуємо KEDA для визначення спеціального ресурсу під назвою ScaledObject, як показано в наступному коді:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])Попередній маніфест визначає a ScaledObject названий keda-prometheus-hpa, який відповідає за масштабування розгортання php-apache і завжди підтримує роботу принаймні однієї репліки. Він масштабує пакети цього розгортання на основі метрики http_requests_total доступний у Prometheus, отриманий за вказаним запитом, і націлений на збільшення модулів таким чином, щоб кожен пакет обслуговував не більше одного запиту на секунду. Він зменшує репліки після того, як навантаження запиту було нижче порогового значення протягом довше 30 секунд.
Команда розгортання спец для нашого прикладу служба містить наступне запити на ресурси та обмеження:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1За такої конфігурації кожен із пакетів послуг використовуватиме лише один графічний процесор NVIDIA. Коли створюються нові пакети, вони перебувають у стані очікування, доки не стане доступним графічний процесор. Karpenter додає вузли графічного процесора до кластера за потреби для розміщення модулів, що очікують на розгляд.
A навантажувальний под надсилає HTTP-запити до служби із заданою частотою. Ми збільшуємо кількість запитів за рахунок збільшення кількості реплік у розгортання генератора навантаження.
Повний цикл масштабування з консолідацією вузлів на основі використання відображається на інформаційній панелі Grafana. На наступній інформаційній панелі показано кількість вузлів у кластері за типом екземпляра (угорі), кількість запитів на секунду (унизу ліворуч) і кількість пакетів (внизу праворуч).
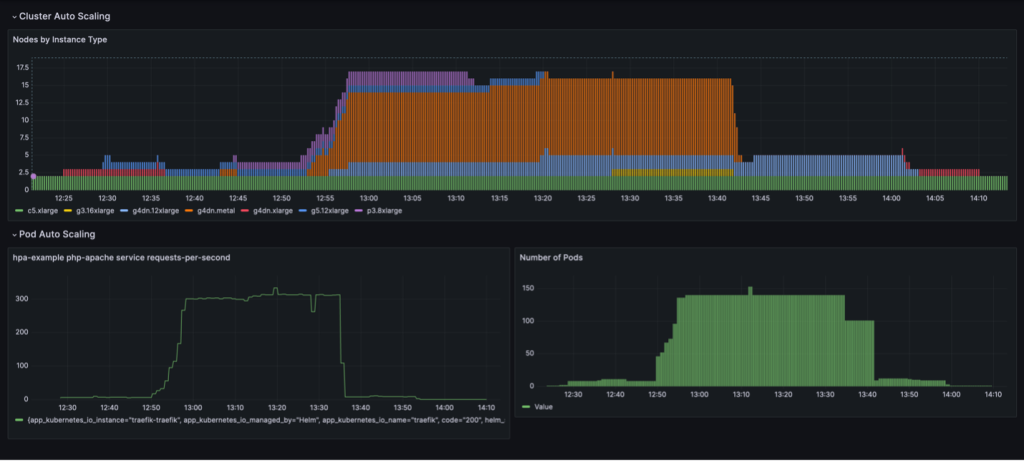
Ми починаємо лише з двох екземплярів ЦП c5.xlarge, з якими було створено кластер. Потім ми розгортаємо один екземпляр служби, для якого потрібен один графічний процесор. Karpenter додає екземпляр g4dn.xlarge, щоб задовольнити цю потребу. Потім ми розгортаємо генератор навантаження, що змушує KEDA додавати більше пакетів служб, а Karpenter додає більше екземплярів GPU. Після оптимізації стан установлюється на один екземпляр p3.8xlarge з 8 графічним процесором і один екземпляр g5.12xlarge з 4 графічним процесором.
Коли ми масштабуємо розгортання, що генерує навантаження, до 40 реплік, KEDA створює додаткові пакети служб, щоб підтримувати необхідне навантаження запитів на пакет. Карпентер додає вузли g4dn.metal і g4dn.12xlarge до кластера, щоб забезпечити необхідні графічні процесори для додаткових модулів. У масштабованому стані кластер містить 16 вузлів GPU і обслуговує близько 300 запитів на секунду. Коли ми зменшуємо генератор навантаження до 1 репліки, відбувається зворотний процес. Після періоду відновлення KEDA зменшує кількість службових контейнерів. Потім, коли запущено менше модулів, Карпентер видаляє вузли, що недостатньо використовуються, з кластера, а пакети служб консолідуються для роботи на меншій кількості вузлів. Коли модуль генератора навантаження видаляється, один модуль служби в одному екземплярі g4dn.xlarge з 1 графічним процесором продовжує працювати. Коли ми також видаляємо пакет обслуговування, кластер залишається у початковому стані лише з двома вузлами ЦП.
Ми можемо спостерігати таку поведінку, коли NodePool має налаштування consolidationPolicy: WhenUnderutilized.
За допомогою цього параметра Karpenter динамічно налаштовує кластер із якомога меншою кількістю вузлів, забезпечуючи достатні ресурси для роботи всіх модулів і мінімізуючи витрати.
Поведінка масштабування, показана на наступній інформаційній панелі, спостерігається, коли NodePool встановлено політику консолідації WhenEmpty, разом з consolidateAfter: 30s.
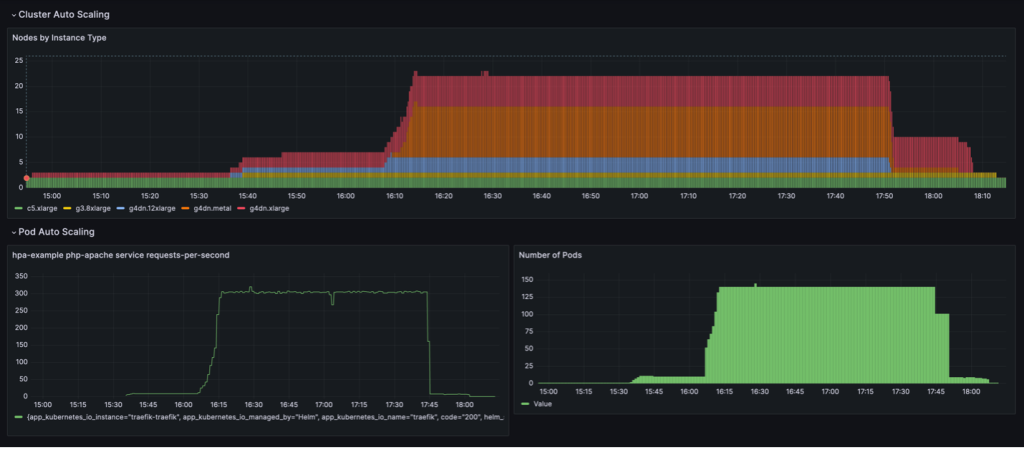
У цьому сценарії вузли зупиняються лише тоді, коли на них не працюють модулі після періоду охолодження. Крива масштабування виглядає гладкою порівняно з політикою консолідації на основі використання; однак можна побачити, що в масштабованому стані використовується більше вузлів (22 проти 16).
Загалом поєднання автоматичного масштабування модуля й кластера гарантує, що кластер динамічно масштабується відповідно до робочого навантаження, розподіляючи ресурси за потреби та видаляючи їх, коли вони не використовуються, тим самим максимізуючи використання та мінімізуючи витрати.
Результати
Iambic використовував цю архітектуру, щоб забезпечити ефективне використання GPU на AWS і перенести навантаження з CPU на GPU. Використовуючи екземпляри з графічним процесором EC2, Amazon EKS і Karpenter, ми змогли забезпечити швидший висновок для наших моделей на основі фізики та короткий час ітерації експерименту для вчених-прикладників, які покладаються на навчання як на послугу.
У наведеній нижче таблиці підсумовано деякі часові показники цієї міграції.
| Завдання | Процесори | Графічні процесори |
| Висновок із використанням моделей дифузії для моделей ML на основі фізики | 3,600 секунд: |
100 секунд: (через невід'ємне пакетування GPU) |
| Навчання моделі ML як послуга | 180 хвилин | 4 хвилин |
У таблиці нижче наведено деякі з наших показників часу та вартості.
| Завдання | Продуктивність/Вартість | |
| Процесори | Графічні процесори | |
| Навчання моделі ML |
240 хвилин в середньому 0.70 доларів США за навчальне завдання |
20 хвилин в середньому 0.38 доларів США за навчальне завдання |
Підсумки
У цьому дописі ми продемонстрували, як Iambic використовував Karpenter і KEDA для масштабування нашої інфраструктури Amazon EKS, щоб відповідати вимогам щодо затримки наших висновків ШІ та навчальних навантажень. Karpenter і KEDA — це потужні інструменти з відкритим кодом, які допомагають автоматично масштабувати кластери EKS і робочі навантаження, які на них виконуються. Це допомагає оптимізувати витрати на обчислення, одночасно задовольняючи вимоги до продуктивності. Ви можете перевірити код і розгорнути ту саму архітектуру у своєму власному середовищі, виконавши повну інструкцію в цьому GitHub репо.
Про авторів
 Меттью Велборн є директором машинного навчання в Iambic Therapeutics. Він і його команда використовують штучний інтелект, щоб прискорити ідентифікацію та розробку нових терапевтичних засобів, швидше доставляючи життєво важливі ліки пацієнтам.
Меттью Велборн є директором машинного навчання в Iambic Therapeutics. Він і його команда використовують штучний інтелект, щоб прискорити ідентифікацію та розробку нових терапевтичних засобів, швидше доставляючи життєво важливі ліки пацієнтам.
 Пол Віттемор є головним інженером компанії Iambic Therapeutics. Він підтримує створення інфраструктури для платформи виявлення ліків на основі ШІ Iambic.
Пол Віттемор є головним інженером компанії Iambic Therapeutics. Він підтримує створення інфраструктури для платформи виявлення ліків на основі ШІ Iambic.
 Алекс Янкульський є головним архітектором рішень, ML/AI Frameworks, який зосереджується на допомозі клієнтам організовувати робочі навантаження ШІ за допомогою контейнерів та прискореної обчислювальної інфраструктури на AWS.
Алекс Янкульський є головним архітектором рішень, ML/AI Frameworks, який зосереджується на допомозі клієнтам організовувати робочі навантаження ШІ за допомогою контейнерів та прискореної обчислювальної інфраструктури на AWS.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

