
In the rapidly evolving field of artificial intelligence, natural language processing has become a focal point for researchers and developers alike. Building on the foundations of Transformer architecture and BERT’s bidirectional upgrade, several groundbreaking language models have emerged in recent years, pushing the boundaries of what machines can understand and generate.
In this article, we will delve into the latest advancements in the world of large-scale language models, exploring enhancements introduced by each model, their capabilities, and potential applications. We’ll also look into the Visual Langauge Models (VLMs) that are trained to process not only textual but also visual data.
If you’d like to skip around, here are the language models we featured:
- GPT-3 by OpenAI
- LaMDA by Google
- PaLM by Google
- Flamingo by DeepMind
- BLIP-2 by Salesforce
- LLaMA by Meta AI
- GPT-4 by OpenAI
If this in-depth educational content is useful for you, you can subscribe to our AI research mailing list to be alerted when we release new material.
The Most Important Large Language Models (LLMs) and Visual Language Models (VLMs) in 2023
1. GPT-3 by OpenAI
Summary
The OpenAI team introduced GPT-3 as an alternative to having a labeled dataset for every new language task. They suggested that scaling up language models can improve task-agnostic few-shot performance. To test this suggestion, they trained a 175B-parameter autoregressive language model, called GPT-3, and evaluated its performance on over two dozen NLP tasks. The evaluation under few-shot learning, one-shot learning, and zero-shot learning demonstrated that GPT-3 achieved promising results and even occasionally outperformed the state-of-the-art results achieved by fine-tuned models.
What is the goal?
- To suggest an alternative solution to the existing problem, when a labeled dataset is needed for every new language task.
How is the problem approached?
- The researchers suggested scaling up language models to improve task-agnostic few-shot performance.
- The GPT-3 model uses the same model and architecture as GPT-2, including modified initialization, pre-normalization, and reversible tokenization.
- However, in contrast to GPT-2, it uses alternating dense and locally banded sparse attention patterns in the layers of the transformer, as in the Sparse Transformer.
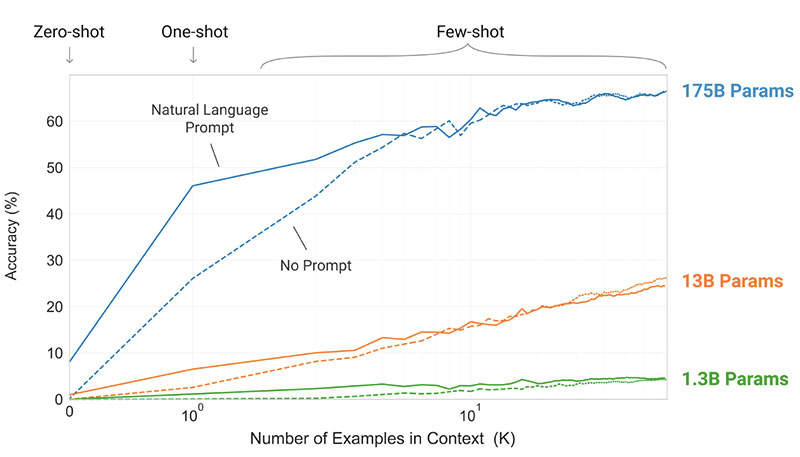
What are the results?
- The GPT-3 model without fine-tuning achieves promising results on a number of NLP tasks, and even occasionally surpasses state-of-the-art models that were fine-tuned for that specific task:
- On the CoQA benchmark, 81.5 F1 in the zero-shot setting, 84.0 F1 in the one-shot setting, and 85.0 F1 in the few-shot setting, compared to the 90.7 F1 score achieved by fine-tuned SOTA.
- On the TriviaQA benchmark, 64.3% accuracy in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting, surpassing the state of the art (68%) by 3.2%.
- On the LAMBADA dataset, 76.2 % accuracy in the zero-shot setting, 72.5% in the one-shot setting, and 86.4% in the few-shot setting, surpassing the state of the art (68%) by 18%.
- The news articles generated by the 175B-parameter GPT-3 model are hard to distinguish from real ones, according to human evaluations (with accuracy barely above the chance level at ~52%).
- Despite the remarkable performance of GPT-3, it got mixed reviews from the AI community:
- “The GPT-3 hype is way too much. It’s impressive (thanks for the nice compliments!) but it still has serious weaknesses and sometimes makes very silly mistakes. AI is going to change the world, but GPT-3 is just a very early glimpse. We have a lot still to figure out.” – Sam Altman, CEO and co-founder of OpenAI.
- “I’m shocked how hard it is to generate text about Muslims from GPT-3 that has nothing to do with violence… or being killed…” – Abubakar Abid, CEO and founder of Gradio.
- “No. GPT-3 fundamentally does not understand the world that it talks about. Increasing corpus further will allow it to generate a more credible pastiche but not fix its fundamental lack of comprehension of the world. Demos of GPT-4 will still require human cherry picking.” – Gary Marcus, CEO and founder of Robust.ai.
- “Extrapolating the spectacular performance of GPT3 into the future suggests that the answer to life, the universe and everything is just 4.398 trillion parameters.” – Geoffrey Hinton, Turing Award winner.
Where to learn more about this research?
Where can you get implementation code?
- The code itself is not available, but some dataset statistics together with unconditional, unfiltered 2048-token samples from GPT-3 are released on GitHub.
2. LaMDA by Google
Summary
Language Models for Dialogue Applications (LaMDA) were created through the process of fine-tuning a group of Transformer-based neural language models that are specifically designed for dialogues. These models have a maximum of 137B parameters and were trained to use external sources of knowledge. LaMDA developers had three key objectives in mind – quality, safety, and groundedness. The results demonstrated that fine-tuning allows narrowing of the quality gap to human levels, but the model’s performance remained below human levels with respect to safety and groundedness.
Google’s Bard, released recently as an alternative to ChatGPT, is powered by LaMDA. Despite Bard being often labeled as boring, it could be seen as evidence of Google’s commitment to prioritizing safety, even amidst the intense rivalry between Google and Microsoft to establish dominance in the field of generative AI.
What is the goal?
- To build a model for open-domain dialog applications, where a dialog agent is able to converse about any topic with responses being sensible, specific to the context, grounded on reliable sources, and ethical.
How is the problem approached?
- LaMDA is built on Transformer, a neural network architecture that Google Research invented and open-sourced in 2017.
- Like other large language models, including BERT and GPT-3, LaMDA is trained on terabytes of text data to learn how words relate to one another and then predict what words are likely to come next.
- However, unlike most language models, LaMDA was trained on dialogue to pick up on nuances that distinguish open-ended conversation from other forms of language.
- The model is also fine-tuned to improve the sensibleness, safety, and specificity of its responses. While phrases like “that’s nice” and “I don’t know” can be meaningful in many dialog scenarios, they are not likely to lead to interesting and engaging conversations.
- The LaMDA generator first generates several candidate responses, which are all scored based on how safe, sensible, specific, and interesting they are. Responses with low safety scores are filtered out, and then the top-ranked result is selected as a response.
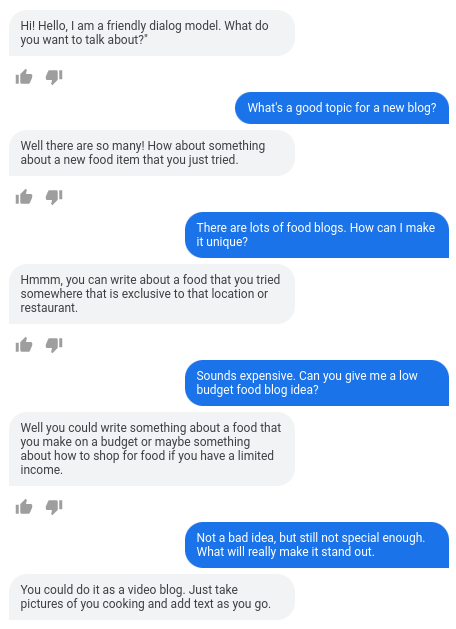
What are the results?
- Numerous experiments show that LaMDA can participate in engaging open-ended conversations on a variety of topics.
- A series of qualitative evaluations confirmed that the model’s responses tend to be sensible, specific, interesting, and grounded on reliable external sources but there is still room for improvement.
- Despite all the progress made so far, the authors recognize that the model still has many limitations that may result in generating inappropriate or even harmful responses.
Where to learn more about this research?
Where can you get implementation code?
- An open-source PyTorch implementation for the pre-training architecture of LaMDA is available on GitHub.
3. PaLM by Google
Summary
Pathways Language Model (PaLM) is a 540-billion parameter, Transformer-based language model. PaLM was trained on 6144 TPU v4 chips using Pathways, a new ML system for efficient training across multiple TPU Pods. The model demonstrates the benefits of scaling in few-shot learning, achieving state-of-the-art results on hundreds of language understanding and generation benchmarks. PaLM outperforms finetuned state-of-the-art models on multi-step reasoning tasks and exceeds average human performance on the BIG-bench benchmark.
What is the goal?
- To improve understanding of how scaling of large language models affects few-shot learning.
How is the problem approached?
- The key idea is to scale the training of a 540-billion parameter language model with the Pathways system:
- The team was using data parallelism at the Pod level across two Cloud TPU v4 Pods while using standard data and model parallelism within each Pod.
- They were able to scale training to 6144 TPU v4 chips, the largest TPU-based system configuration used for training to date.
- The model achieved a training efficiency of 57.8% hardware FLOPs utilization, which, as the authors claim, is the highest yet achieved training efficiency for large language models at this scale.
- The training data for the PaLM model included a combination of English and multilingual datasets containing high-quality web documents, books, Wikipedia, conversations, and GitHub code.
What are the results?
- Numerous experiments demonstrate that model performance steeply increased as the team scaled to their largest model.
- PaLM 540B achieved breakthrough performance on multiple very difficult tasks:
- Language understanding and generation. The introduced model surpassed the few-shot performance of prior large models on 28 out of 29 tasks that include question-answering tasks, cloze and sentence-completion tasks, in-context reading comprehension tasks, common-sense reasoning tasks, SuperGLUE tasks, and more. PaLM’s performance on BIG-bench tasks showed that it could distinguish cause and effect, as well as understand conceptual combinations in appropriate contexts.
- Reasoning. With 8-shot prompting, PaLM solves 58% of the problems in GSM8K, a benchmark of thousands of challenging grade school level math questions, outperforming the prior top score of 55% achieved by fine-tuning the GPT-3 175B model. PaLM also demonstrates the ability to generate explicit explanations in situations that require a complex combination of multi-step logical inference, world knowledge, and deep language understanding.
- Code generation. PaLM performs on par with the fine-tuned Codex 12B while using 50 times less Python code for training, confirming that large language models transfer learning from both other programming languages and natural language data more effectively.
Where to learn more about this research?
Where can you get implementation code?
- An unofficial PyTorch implementation of the specific Transformer architecture from the PaLM research paper is available on GitHub. It will not scale and is published for educational purposes only.
4. Flamingo by DeepMind
Summary
Flamingo is a cutting-edge family of Visual Language Models (VLMs), trained on large-scale multimodal web corpora with mixed text and images. With this training, the models can adapt to new tasks using minimal annotated examples, provided as a prompt. Flamingo incorporates key architectural advancements designed to merge the strengths of pretrained vision-only and language-only models, process sequences of variably interleaved visual and textual data, and accommodate images or videos as inputs seamlessly. The models demonstrate impressive adaptability to a range of image and video tasks such as visual question-answering, captioning tasks, and multiple-choice visual question-answering, setting new performance standards using task-specific prompts in few-shot learning.
What is the goal?
- To make progress towards enabling multimodal models to quickly learn and perform new tasks based on short instructions:
- The widely-used paradigm of pretraining a model on a large amount of supervised data, then fine-tuning it for the specific task, is resource-intensive and requires thousands of annotated data points along with careful per-task hyperparameter tuning.
- Current models that use a contrastive objective allow for zero-shot adaptation to new tasks but fall short on more open-ended tasks like captioning or visual question-answering because they lack language generation capabilities.
- This research aims to introduce a new model that effectively addresses these issues and demonstrates superior performance in low-data regimes.
How is the problem approached?
- The DeepMind introduced Flamingo, VLMs designed for few-shot learning on various open-ended vision and language tasks, using only a few input/output examples.
- Flamingo models are visually-conditioned autoregressive text generation models that can process text tokens mixed with images and/or videos and generate text as output.
- The architecture of Flamingo incorporates two complementary pre-trained and frozen models:
- A vision model capable of “perceiving” visual scenes.
- A large language model tasked with performing basic reasoning.
- Novel architecture components integrate these models in a way that retains the knowledge gained during their computationally intensive pre-training.
- In addition, Flamingo models feature a Perceiver-based architecture, allowing them to ingest high-resolution images or videos. This architecture can generate a fixed number of visual tokens per image/video from a broad and variable array of visual input features.
What are the results?
- The research shows that similarly to LLMs, which are good few-shot learners, VLMs can learn from a few input/output examples for image and video understanding tasks such as classification, captioning, or question-answering.
- Flamingo establishes a new benchmark in few-shot learning, demonstrating superior performance on a broad range of 16 multimodal language and image/video understanding tasks.
- For 6 out of these 16 tasks, Flamingo surpasses the performance of the fine-tuned state of the art, even though it utilizes only 32 task-specific examples – approximately 1000 times less task-specific training data than the current top-performing models.
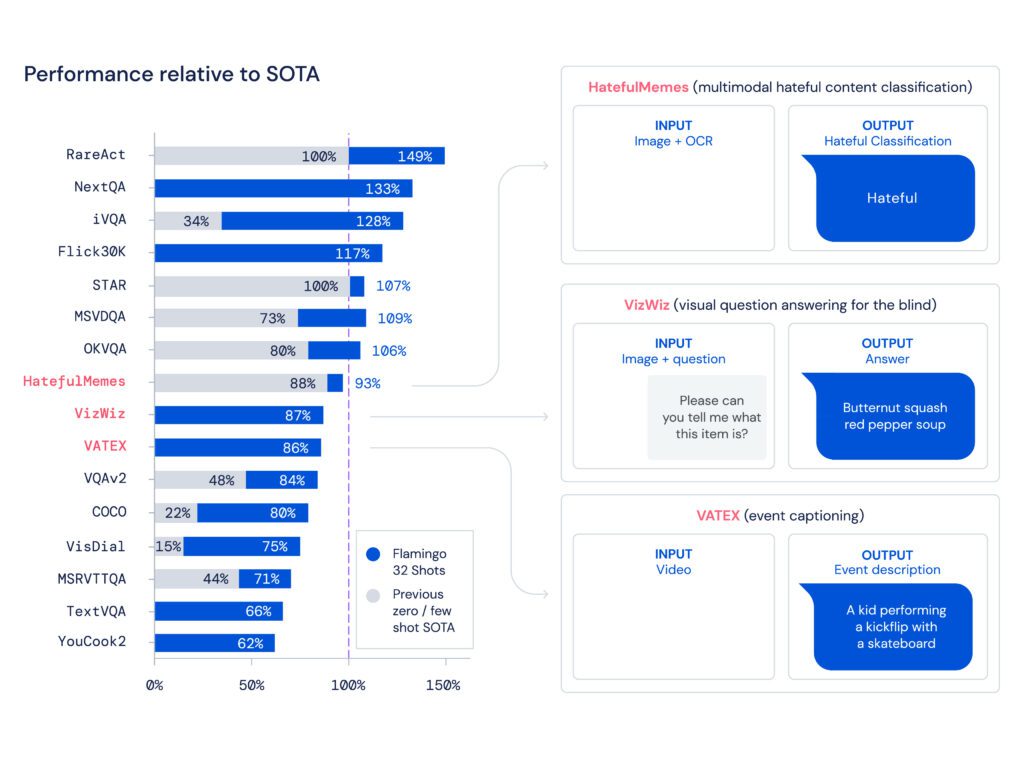
Where to learn more about this research?
Where can you get implementation code?
- DeepMind didn’t release the official implementation of Flamingo.
- You may find open source implementation of the introduced approach in the OpenFlamingo Github Repo.
- The alternative PyTorch implementation is available here.
5. BLIP-2 by Salesforce
Summary
BLIP-2 is an efficient and generic pre-training framework for vision-and-language models, designed to circumvent the increasingly prohibitive cost of pre-training large-scale models. BLIP-2 leverages off-the-shelf frozen pre-trained image encoders and frozen large language models to bootstrap vision-language pre-training, incorporating a lightweight Querying Transformer pre-trained in two stages. The first stage initiates vision-language representation learning from a frozen image encoder, and the second stage propels vision-to-language generative learning from a frozen language model. Despite having significantly fewer trainable parameters, BLIP-2 outperforms state-of-the-art methods, surpassing DeepMind’s Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. The model also exhibits promising zero-shot image-to-text generation capabilities following natural language instructions.
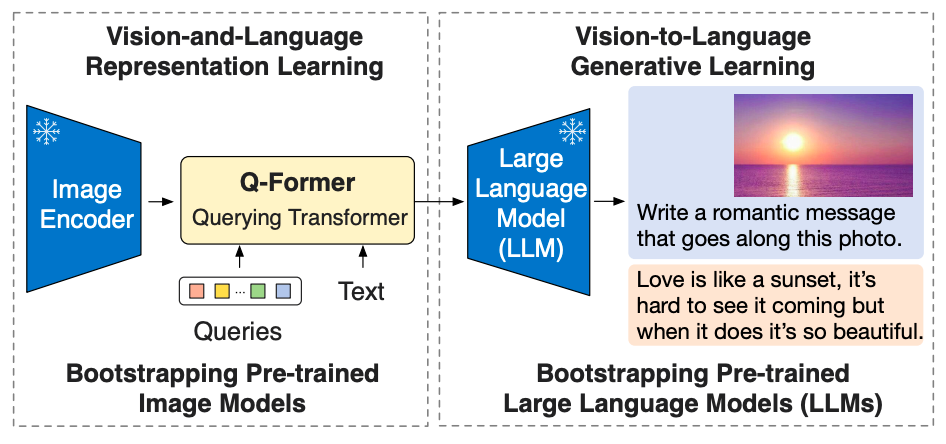
What is the goal?
- To get state-of-the-art performance on vision language tasks, while reducing the computation costs.
How is the problem approached?
- The Salesforce team introduced a new vision-language pre-training framework dubbed BLIP-2, Bootstrapping Language-Image Pre-training with frozen unimodal models:
- The pre-trained unimodal models remain frozen during pre-training to reduce computation cost and avoid the issue of catastrophic forgetting.
- To facilitate cross-modal alignment and bridge the modality gap between pre-trained vision models and pre-trained language models, the team proposes a lightweight Querying Transformer (Q-Former) that acts as an information bottleneck between the frozen image encoder and the frozen LLM.
- Q-former is pre-trained with a new two-stage strategy:
- The first pre-training stage performs vision-language representation learning. This enforces the Q-Former to learn visual representation most relevant to the text.
- The second pre-training stage performs vision-to-language generative learning by connecting the output of the Q-Former to a frozen LLM. The Q-Former is trained such that its output visual representation can be interpreted by the LLM.
What are the results?
- BLIP-2 delivers exceptional, state-of-the-art results across a variety of vision-language tasks, encompassing visual question answering, image captioning, and image-text retrieval.
- For example, it outperforms Flamingo by 8.7% on zero-shot VQAv2.
- Moreover, this outstanding performance is achieved with significantly higher computer efficiency:
- BLIP-2 outperforms Flamingo-80B while using 54× fewer trainable parameters.
- BLIP-2 has the capacity to undertake zero-shot image-to-text generation in response to natural language instructions, thereby paving the way for developing skills like visual knowledge reasoning and visual conversation among others.
- Finally, it’s important to note that BLIP-2 is a versatile approach that can leverage more sophisticated unimodal models to further enhance the performance of vision-language pre-training.
Where to learn more about this research?
Where can you get implementation code?
The official BLIP-2 implementation is available on GitHub.
6. LLaMA by Meta AI
Summary
The Meta AI team asserts that smaller models trained on more tokens are easier to retrain and fine-tune for specific product applications. Therefore, they introduce LLaMA (Large Language Model Meta AI), a collection of foundational language models with 7B to 65B parameters. LLaMA 33B and 65B were trained on 1.4 trillion tokens, while the smallest model, LLaMA 7B, was trained on one trillion tokens. They exclusively used publicly available datasets, without depending on proprietary or restricted data. The team also implemented key architectural enhancements and training speed optimization techniques. Consequently, LLaMA-13B outperformed GPT-3, being over 10 times smaller, and LLaMA-65B exhibited competitive performance with PaLM-540B.
What is the goal?
- To demonstrate the feasibility of training top-performing models solely on publicly accessible datasets, without relying on proprietary or restricted data sources.
- To provide the research community with smaller and more performant models and thus, enable those who don’t have access to large amounts of infrastructure, to study large language models.
How is the problem approached?
- To train the LLaMA model, researchers only used data that is publicly available, and compatible with open sourcing.
- They have also introduced a few improvements to the standard Transformer architecture:
- Adopting the GPT-3 methodology, the stability of training was enhanced by normalizing the input for each transformer sub-layer, rather than normalizing the output.
- Inspired by the PaLM models, the researchers replaced the ReLU non-linearity with the SwiGLU activation function, to improve the performance.
- Inspired by Su et al (2021), they eliminated the absolute positional embeddings and instead, incorporated rotary positional embeddings (RoPE) at every layer of the network.
- Finally, the Meta AI team improved the training speed of their model by:
- Using efficient causal multi-head attention implementation by not storing attention weights or computing masked key/query scores.
- Using checkpointing to minimize recomputed activations during the backward pass.
- Overlapping the computation of activations and the communication between GPUs over the network (due to all_reduce operations).
What are the results?
- LLaMA-13B surpasses GPT-3 despite being over 10 times smaller, while LLaMA-65B holds its own against PaLM-540B.
Where to learn more about this research?
Where can you get implementation code?
- Meta AI provides access to LLaMA to academic researchers, individuals associated with government, civil society, academic institutions, and global industry research labs on an individual case evaluation basis. To apply, go to the following GitHub repository.
7. GPT-4 by OpenAI
Summary
GPT-4 is a large-scale, multimodal model that accepts image and text inputs and generates text outputs. Due to competitive and safety concerns, specific details about the model’s architecture and training are withheld. In terms of performance, GPT-4 surpasses previous language models on traditional benchmarks and shows significant improvements in user intent understanding and safety properties. The model also achieves human-level performance on various exams, including a top 10% score on a simulated Uniform Bar Examination.
What is the goal?
- To develop a large-scale, multimodal model which can accept image and text inputs and produce text outputs.
- To develop infrastructure and optimization methods that behave predictably across a wide range of scales.
How is the problem approached?
- Due to competitive landscape and safety implications, OpenAI decided to withhold details on architecture, model size, hardware, training compute, dataset construction, and training methods.
- They disclose that:
- GPT-4 is a Transformer-based model, pre-trained to predict the next token in a document.
- It utilizes publicly available data and third-party licensed data.
- The model was fine-tuned using Reinforcement Learning from Human Feedback (RLHF).
- Unconfirmed information suggests that GPT-4 isn’t a singular dense model like its predecessors, but a powerhouse coalition of eight separate models, each packing a staggering 220 billion parameters.
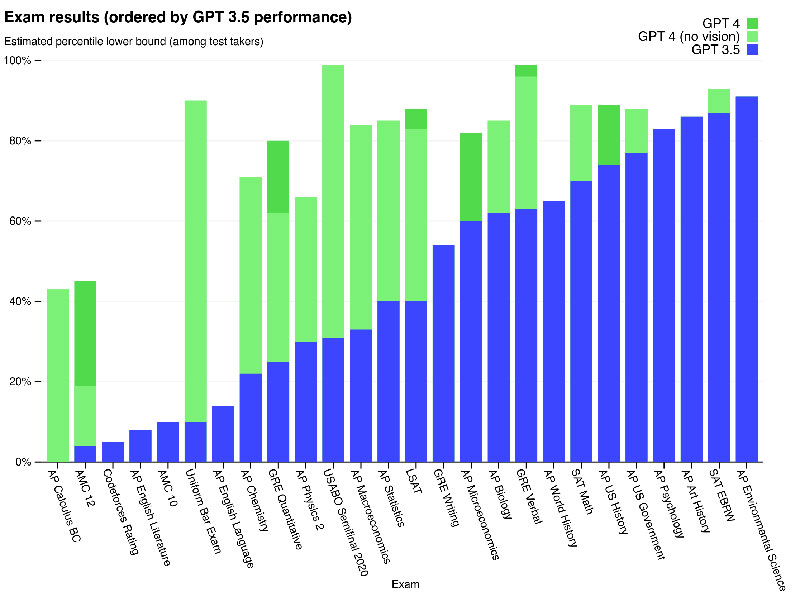
What are the results?
- GPT-4 achieves human-level performance on most professional and academic exams, notably scoring in the top 10% on a simulated Uniform Bar Examination.
- The pre-trained base GPT-4 model outperforms existing language models and prior state-of-the-art systems on traditional NLP benchmarks, without benchmark-specific crafting or additional training protocols.
- GPT-4 demonstrates a substantial improvement in following user intent, with its responses preferred over GPT-3.5’s responses in 70.2% of 5,214 prompts from ChatGPT and the OpenAI API.
- GPT-4’s safety properties have significantly improved compared to GPT-3.5, with an 82% decrease in responding to disallowed content requests and a 29% increase in compliance with policies for sensitive requests (e.g., medical advice and self-harm).
Where to learn more about this research?
Where can you get implementation code?
- Code implementation of GPT-4 is not available.
Real-world Applications of Large (Vision) Language Models
The most significant AI research breakthroughs of recent years come from large AI models trained on huge datasets. These models demonstrate impressive performance, and it’s fascinating to think how AI can revolutionize whole industries, like customer service, marketing, e-commerce, healthcare, software development, journalism, and many others.
Large language models have numerous real-world applications. GPT-4 lists the following:
- Natural language understanding and generation for chatbots and virtual assistants.
- Machine translation between languages.
- Summarization of articles, reports, or other text documents.
- Sentiment analysis for market research or social media monitoring.
- Content generation for marketing, social media, or creative writing.
- Question-answering systems for customer support or knowledge bases.
- Text classification for spam filtering, topic categorization, or document organization.
- Personalized language learning and tutoring tools.
- Code generation and software development assistance.
- Medical, legal, and technical document analysis and assistance.
- Accessibility tools for individuals with disabilities, such as text-to-speech and speech-to-text conversion.
- Speech recognition and transcription services.
If we add a visual part, the areas of possible applications expand further:
It’s very exciting to follow the recent AI breakthroughs and think about their potential real-world applications. However, before deploying these models in real life we need to address the corresponding risks and limitations, which unfortunately are quite significant.
Risks and Limitations
If you ask GPT-4 about its risks and limitations, it will likely provide you with a long list of relevant concerns. After filtering through this list and adding some additional considerations, I’ve ended up with the following set of key risks and limitations possessed by modern large language models:
- Bias and discrimination: These models learn from vast amounts of text data, which often contain biases and discriminatory content. As a result, the generated outputs can inadvertently perpetuate stereotypes, offensive language, and discrimination based on factors like gender, race, or religion.
- Misinformation: Large language models may generate content that is factually incorrect, misleading, or outdated. While the models are trained on a diverse range of sources, they may not always provide the most accurate or up-to-date information. Often this happens because the model prioritizes generating outputs that are grammatically correct or seem coherent, even if they are misleading.
- Lack of understanding: Although these models appear to understand human language, they operate primarily by identifying patterns and statistical associations in the training data. They do not have a deep understanding of the content they generate, which can sometimes result in nonsensical or irrelevant outputs.
- Inappropriate content: Language models can sometimes generate content that is offensive, harmful, or inappropriate. While efforts are made to minimize such content, it can still occur due to the nature of the training data and the models’ inability to discern context or user intent.
Conclusion
Large language models have undoubtedly revolutionized the field of natural language processing and demonstrated immense potential in enhancing productivity across various roles and industries. Their ability to generate human-like text, automate mundane tasks, and provide assistance in creative and analytical processes has made them indispensable tools in today’s fast-paced, technology-driven world.
However, it is crucial to acknowledge and understand the limitations and risks associated with these powerful models. Issues such as bias, misinformation, and the potential for malicious use cannot be ignored. As we continue to integrate these AI-driven technologies into our daily lives, it is essential to strike a balance between leveraging their capabilities and ensuring human supervision, particularly in sensitive and high-risk situations.
If we succeed in adopting generative AI technologies responsibly, we’ll pave the way for a future where artificial intelligence and human expertise work together to drive innovation and create a better world for all.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/

