개요
이 가이드는 SVM(Support Vector Machines)에 대한 세 가지 가이드 중 세 번째이자 마지막 부분입니다. 이 가이드에서는 위조 지폐 사용 사례로 계속 작업하고, SVM의 일반적인 아이디어에 대해 간단히 요약하고, 커널 트릭이 무엇인지 이해하고, Scikit-Learn으로 다양한 유형의 비선형 커널을 구현할 것입니다.
전체 SVM 가이드 시리즈에서는 다른 유형의 SVM에 대해 배우는 것 외에도 간단한 SVM, SVM 사전 정의 매개변수, C 및 Gamma 하이퍼 매개변수와 그리드 검색 및 교차 유효성 검사로 조정하는 방법에 대해 알아봅니다.
이전 가이드를 읽으려면 처음 두 가이드를 살펴보거나 가장 관심 있는 주제를 확인할 수 있습니다. 다음은 각 가이드에서 다루는 항목의 표입니다.
- 사용 사례: 지폐를 잊어버림
- SVM의 배경
- 단순(선형) SVM 모델
- 데이터세트 정보
- 데이터세트 가져오기
- 데이터 세트 탐색
- Scikit-Learn으로 SVM 구현
- 데이터를 훈련/테스트 세트로 나누기
- 모델 훈련
- 예측하기
- 모델 평가
- 결과 해석
- C 하이퍼파라미터
- 감마 하이퍼파라미터
3. Python의 Scikit-Learn으로 다른 SVM 기능 구현
- SVM의 일반적인 아이디어(요약)
- 커널(트릭) SVM
- Scikit-Learn으로 비선형 커널 SVM 구현
- 라이브러리 가져 오기
- 데이터세트 가져오기
- 데이터를 기능(X)과 대상(y)으로 나누기
- 데이터를 훈련/테스트 세트로 나누기
- 알고리즘 훈련
- 다항식 커널
- 예측하기
- 알고리즘 평가
- 가우스 커널
- 예측 및 평가
- 시그모이드 커널
- 예측 및 평가
- 비선형 커널 성능 비교
흥미로운 SVM 커널 변형을 보기 전에 SVM이 무엇인지 기억해 봅시다.
SVM의 일반적인 아이디어
1차원에서 선형적으로 분리 가능한 데이터의 경우(그림 1 참조) 일반적인 기계 학습 알고리즘 접근 방식은 오분류 오류가 최소화되는 방식으로 데이터를 나누는 경계를 찾는 것입니다. 그림 XNUMX을 자세히 보면 데이터 포인트를 올바르게 나누는 여러 경계(무한)가 있을 수 있음을 알 수 있습니다. 두 개의 점선과 실선은 모두 유효한 데이터 분류입니다.
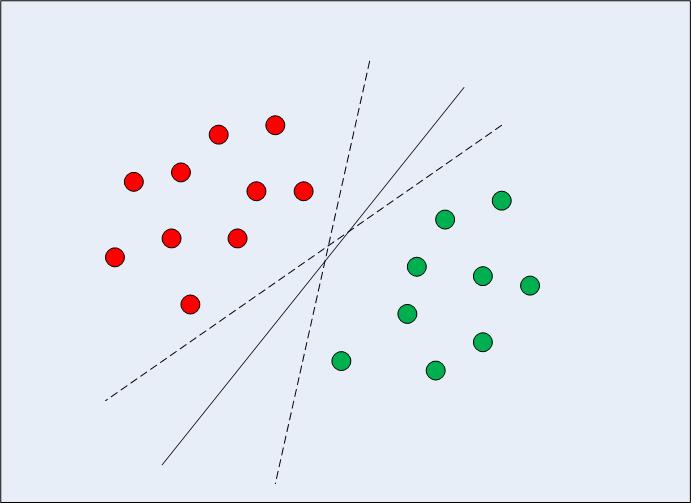
그림 1: 다중 결정 경계
SVM이 결정 경계, 자신과 클래스의 가장 가까운 데이터 포인트 사이의 거리를 최대화하는 경계를 선택합니다. 우리는 이미 가장 가까운 데이터 포인트가 지원 벡터이고 거리가 다음과 같이 매개변수화될 수 있다는 것을 알고 있습니다. C 및 gamma 초매개변수.
결정 경계를 계산할 때 알고리즘은 고려해야 할 포인트 수와 마진이 얼마나 멀리 갈 수 있는지 선택합니다. 이는 마진 최대화 문제를 구성합니다. 마진 최대화 문제를 해결하기 위해 SVM은 지원 벡터(그림 2 참조)를 사용하고 마진 거리를 더 크게 유지하는 최적의 값이 무엇인지 파악하는 동시에 사용 중인 함수에 따라 더 많은 포인트를 올바르게 분류합니다. 데이터를 분리합니다.
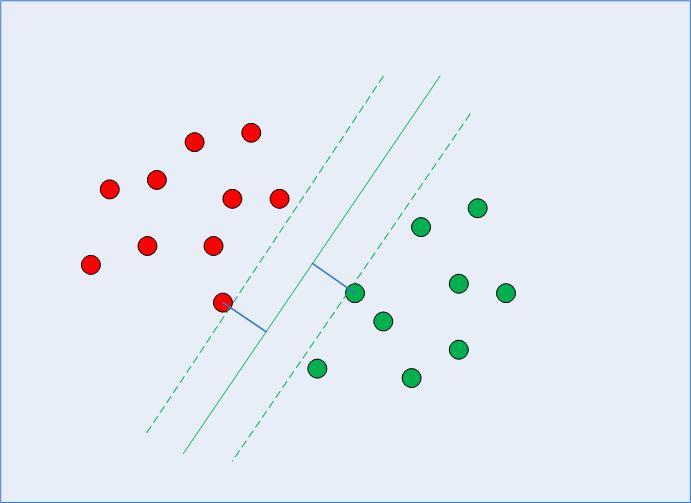
그림 2: 지원 벡터가 있는 결정 경계
이것이 SVM이 단순히 결정 경계를 찾는 것이 아니라 최적의 결정 경계를 찾는다는 점에서 다른 분류 알고리즘과 다른 이유입니다.
서포트 벡터 찾기, 결정 경계와 서포트 벡터 사이의 마진 계산, 마진 최대화와 관련된 통계 및 계산 방법에서 파생된 복잡한 수학이 있습니다. 이번에는 수학이 어떻게 진행되는지 자세히 다루지 않겠습니다.
더 깊이 파고들어 기계 학습 알고리즘이 일종의 신비한 주문이 아닌지 확인하는 것이 항상 중요합니다. 비록 현재 모든 수학적 세부 사항을 알지 못한다고 해서 알고리즘을 실행하고 결과를 얻을 수 있는 것을 막지는 못할 것입니다.
조언: 이제 우리는 알고리즘 프로세스를 요약했으므로 데이터 포인트 사이의 거리가 SVM이 선택하는 결정 경계에 영향을 미칠 것이 분명합니다. 데이터 스케일링 일반적으로 SVM 분류기를 사용할 때 필요합니다. 사용해보기 Scikit-learn의 표준 스케일러 방법 데이터를 준비한 다음 코드를 다시 실행하여 결과에 차이가 있는지 확인합니다.
커널(트릭) SVM
이전 섹션에서 우리는 SVM의 일반적인 개념을 기억하고 정리했습니다. 선형적으로 분리 가능한 데이터에 대한 최적의 결정 경계를 찾는 데 SVM이 어떻게 사용될 수 있는지 살펴봤습니다. 그러나 그림 3과 같이 비선형적으로 분리 가능한 데이터의 경우 직선을 결정 경계로 사용할 수 없다는 것을 이미 알고 있습니다.
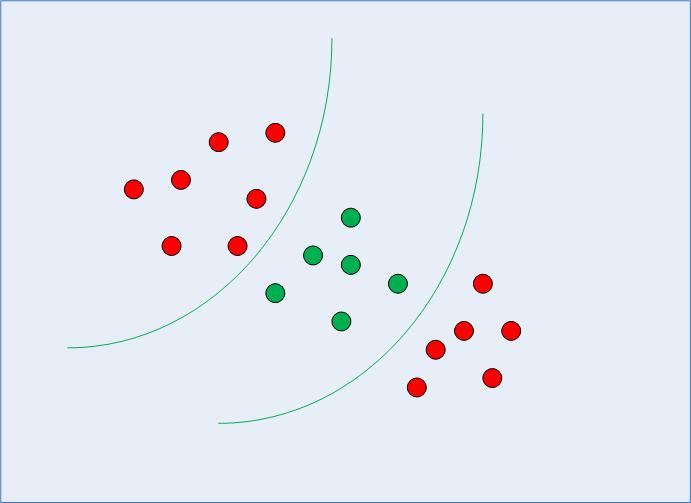
그림 3: 비선형적으로 분리 가능한 데이터
대신 커널 SVM이라고 하는 처음에 논의한 SVM의 수정된 버전을 사용할 수 있습니다.
기본적으로 커널 SVM이 하는 일은 저차원의 비선형 분리 가능한 데이터를 고차원의 해당 형식으로 투영하는 것입니다. 비선형적으로 분리 가능한 데이터를 더 높은 차원으로 투영할 때 데이터 모양이 분리 가능한 방식으로 변경되기 때문에 이것은 트릭입니다. 예를 들어 3차원에 대해 생각할 때 각 클래스의 데이터 포인트는 결국 다른 차원에 할당되어 분리할 수 있습니다. 데이터 차원을 늘리는 한 가지 방법은 지수화하는 것입니다. 다시 말하지만 여기에는 복잡한 수학이 관련되어 있지만 SVM을 사용하기 위해 걱정할 필요는 없습니다. 오히려 Python의 Scikit-Learn 라이브러리를 사용하여 선형 커널을 사용한 것과 같은 방식으로 비선형 커널을 구현하고 사용할 수 있습니다.
Scikit-Learn으로 비선형 커널 SVM 구현
이 섹션에서는 동일한 데이터 세트를 사용하여 우리가 이미 알고 있는 네 가지 기능에 따라 지폐가 진짜인지 위조되었는지 예측합니다.
나머지 단계는 일반적인 기계 학습 단계이며 비선형 커널 SVM을 교육하는 부분에 도달할 때까지 거의 설명이 필요하지 않습니다.
라이브러리 가져 오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
데이터세트 가져오기
data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()mes)
데이터를 기능(X)과 대상(y)으로 나누기
X = bankdata.drop('class', axis=1)
y = bankdata['class']
데이터를 훈련/테스트 세트로 나누기
SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
알고리즘 훈련
커널 SVM을 교육하기 위해 동일한 것을 사용합니다. SVC Scikit-Learn의 클래스 svm 도서관. 차이점은 커널 매개변수의 값에 있습니다. SVC 클래스입니다.
단순 SVM의 경우 커널 매개변수 값으로 "선형"을 사용했습니다. 그러나 앞에서 언급했듯이 커널 SVM의 경우 가우시안, 다항식, 시그모이드 또는 계산 가능한 커널을 사용할 수 있습니다. 우리는 다항식, 가우시안 및 시그모이드 커널을 구현하고 최종 메트릭을 살펴보고 어떤 것이 더 높은 메트릭으로 우리 클래스에 맞는지 확인합니다.
1. 다항식 커널
대수학에서 다항식은 다음 형식의 표현입니다.
$$
2a*b^3 + 4a – 9
$$
여기에는 다음과 같은 변수가 있습니다. a 및 b, 상수는 이 예에서 9 및 계수(변수가 수반되는 상수), 예: 2 및 4. 그만큼 3 다항식의 차수로 간주됩니다.
다항식 함수를 사용할 때 가장 잘 설명할 수 있는 데이터 유형이 있습니다. 여기서 커널이 수행하는 작업은 차수를 선택할 다항식에 데이터를 매핑하는 것입니다. 차수가 높을수록 함수는 데이터에 더 가까워지려고 하므로 결정 경계가 더 유연해집니다(과적합되기 쉽습니다). 차수가 낮을수록 유연성이 떨어집니다.
모범 사례, 업계에서 인정하는 표준 및 포함된 치트 시트가 포함된 Git 학습에 대한 실습 가이드를 확인하십시오. 인터넷 검색 Git 명령을 중지하고 실제로 배움 이것!
따라서 구현을 위해 다항식 커널를 선택하는 것 외에도 poly 커널에 대한 값도 전달합니다. degree 의 매개 변수 SVC 수업. 아래는 코드입니다.
from sklearn.svm import SVC
svc_poly = SVC(kernel='poly', degree=8)
svc_poly.fit(X_train, y_train)
예측하기
이제 알고리즘을 훈련했으면 다음 단계는 테스트 데이터에 대한 예측을 만드는 것입니다.
이전에 했던 것처럼 다음 스크립트를 실행하여 이를 수행할 수 있습니다.
y_pred_poly = svclassifier.predict(X_test)
알고리즘 평가
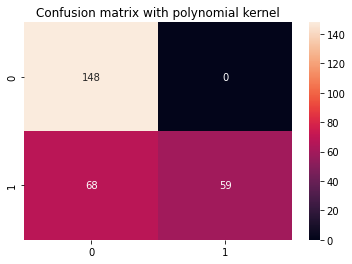
여느 때처럼 마지막 단계는 다항식 커널에서 평가하는 것입니다. 분류 보고서와 혼동 행렬에 대한 코드를 몇 번 반복했으므로 이를 함수로 변환해 보겠습니다. display_results 각각을 받은 후 y_test, y_pred 및 Seaborn의 혼란 행렬에 대한 제목 cm_title:
def display_results(y_test, y_pred, cm_title): cm = confusion_matrix(y_test,y_pred) sns.heatmap(cm, annot=True, fmt='d').set_title(cm_title) print(classification_report(y_test,y_pred))
이제 함수를 호출하고 다항식 커널로 얻은 결과를 볼 수 있습니다.
cm_title_poly = "Confusion matrix with polynomial kernel"
display_results(y_test, y_pred_poly, cm_title_poly)
출력은 다음과 같습니다.
precision recall f1-score support 0 0.69 1.00 0.81 148 1 1.00 0.46 0.63 127 accuracy 0.75 275 macro avg 0.84 0.73 0.72 275
weighted avg 0.83 0.75 0.73 275
이제 가우시안 및 시그모이드 커널에 대해 동일한 단계를 반복할 수 있습니다.
2. 가우시안 커널
가우스 커널을 사용하려면 'rbf'를 값으로 지정하기만 하면 됩니다. kernel SVC 클래스의 매개변수:
svc_gaussian = SVC(kernel='rbf', degree=8)
svc_gaussian.fit(X_train, y_train)
이 커널을 더 자세히 탐색할 때 그리드 검색을 사용하여 다른 커널과 결합할 수도 있습니다. C 및 gamma values.
예측 및 평가
y_pred_gaussian = svc_gaussian.predict(X_test)
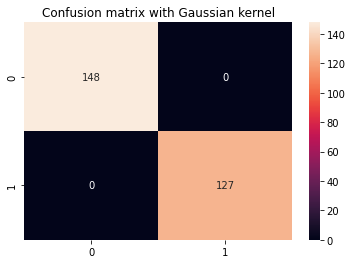
cm_title_gaussian = "Confusion matrix with Gaussian kernel"
display_results(y_test, y_pred_gaussian, cm_title_gaussian)
가우스 커널 SVM의 출력은 다음과 같습니다.
precision recall f1-score support 0 1.00 1.00 1.00 148 1 1.00 1.00 1.00 127 accuracy 1.00 275 macro avg 1.00 1.00 1.00 275
weighted avg 1.00 1.00 1.00 275
3. 시그모이드 커널
마지막으로 커널 SVM을 구현하기 위해 시그모이드 커널을 사용해 봅시다. 다음 스크립트를 살펴보십시오.
svc_sigmoid = SVC(kernel='sigmoid')
svc_sigmoid.fit(X_train, y_train)
시그모이드 커널을 사용하려면 '시그모이드'를 다음의 값으로 지정해야 합니다. kernel 의 매개 변수 SVC 클래스입니다.
예측 및 평가
y_pred_sigmoid = svc_sigmoid.predict(X_test)
cm_title_sigmoid = "Confusion matrix with Sigmoid kernel"
display_results(y_test, y_pred_sigmoid, cm_title_sigmoid)
Sigmoid 커널이 있는 커널 SVM의 출력은 다음과 같습니다.
precision recall f1-score support 0 0.67 0.71 0.69 148 1 0.64 0.59 0.61 127 accuracy 0.65 275 macro avg 0.65 0.65 0.65 275
weighted avg 0.65 0.65 0.65 275

비선형 커널 성능 비교
다양한 유형의 비선형 커널의 성능을 간단히 비교하면 시그모이드 커널의 메트릭이 가장 낮아 성능이 가장 낮은 것처럼 보일 수 있습니다.
가우시안 및 다항식 커널 중에서 가우시안 커널이 완벽한 100% 예측률을 달성했음을 볼 수 있습니다. 이는 일반적으로 의심스럽고 과적합을 나타낼 수 있는 반면 다항식 커널은 클래스 68의 인스턴스 1개를 잘못 분류했습니다.
따라서 하이퍼파라미터를 추가로 검색하고, 각 함수 형태에 대해 이해하고, 데이터를 탐색하고, 알고리즘이 올바른지 확인하기 위해 훈련 및 테스트 결과를 비교하지 않고 모든 시나리오 또는 현재 시나리오에서 어떤 커널이 가장 잘 수행되는지에 대한 엄격하고 빠른 규칙은 없습니다. 일반화하고 있다.
모든 커널을 테스트하고 프로젝트의 컨텍스트에 따라 예상되는 결과를 제공하는 매개변수와 데이터 준비의 조합으로 커널을 선택하는 것이 전부입니다.
더 나아가기 – 핸드헬드 엔드투엔드 프로젝트
당신의 호기심 많은 성격이 당신을 더 멀리 가고 싶게 만드나요? 다음을 확인하는 것이 좋습니다. 가이드 프로젝트: “실습 주택 가격 예측 – Python의 기계 학습”.

이 가이드 프로젝트에서는 강력한 기존 머신 러닝 모델과 딥 러닝 모델을 구축하는 방법, Ensemble Learning을 활용하는 방법, 메타 학습자를 교육하여 Scikit-Learn 및 Keras 모델 가방에서 주택 가격을 예측하는 방법을 배웁니다.
Tensorflow를 기반으로 구축된 딥 러닝 API인 Keras를 사용하여 아키텍처를 실험하고 스택 모델의 앙상블을 구축하고 메타 학습자 신경망(레벨 1 모델)을 사용하여 주택 가격을 파악합니다.
딥 러닝은 놀랍습니다. 그러나 딥 러닝에 의존하기 전에 얕은 학습 알고리즘. 기본 성능은 다음을 기반으로 합니다. 랜덤 포레스트 회귀 연산. 또한 – 다음과 같은 기술을 통해 Scikit-Learn을 통해 모델의 앙상블을 만드는 방법을 살펴보겠습니다. 포장 및 투표.
이것은 종단 간 프로젝트이며 모든 기계 학습 프로젝트와 마찬가지로 다음으로 시작합니다. 탐색 적 데이터 분석, 다음 데이터 전처리 그리고 마지막으로 건물 얕은 및 딥 러닝 모델 이전에 탐색하고 정리한 데이터에 맞도록 합니다.
결론
이 기사에서 우리는 SVM에 대해 간단히 요약하고 커널 트릭에 대해 연구했으며 다양한 비선형 SVM을 구현했습니다.
각 커널을 구현하고 계속 진행하는 것이 좋습니다. 각기 다른 커널을 생성하는 데 사용된 수학, 커널이 생성된 이유 및 하이퍼파라미터와 관련된 차이점을 탐색할 수 있습니다. 그런 식으로 상황과 사용 가능한 데이터에 따라 적용하는 것이 가장 좋은 기술과 커널 유형에 대해 배우게 됩니다.
각 커널의 작동 방식과 사용 시기를 명확하게 이해하면 여정에 확실히 도움이 될 것입니다. 진행 상황을 알려주시고 행복한 코딩하세요!
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- 출처: https://stackabuse.com/implementing-other-svm-flavors-with-pythons-scikit-learn/

