오늘날의 비즈니스 환경에서 조직은 재무 프로세스를 최적화하고 효율성을 향상하며 비용을 절감할 수 있는 방법을 끊임없이 모색하고 있습니다. 개선의 여지가 큰 영역 중 하나는 지급 계정입니다. 높은 수준에서 보면 지급 계정 프로세스에는 송장 수신 및 스캔, 스캔한 송장에서 관련 데이터 추출, 검증, 승인 및 보관이 포함됩니다. 두 번째 단계(추출)는 복잡할 수 있습니다. 청구서와 영수증은 각각 다르게 보입니다. 라벨이 불완전하고 일관성이 없습니다. 가격, 공급업체 이름, 공급업체 주소, 지불 조건 등 가장 중요한 정보는 명시적으로 표시되지 않은 경우가 많으며 상황에 따라 해석해야 합니다. 인간 검토자를 사용하여 데이터를 추출하는 기존 접근 방식은 시간이 많이 걸리고 오류가 발생하기 쉬우며 확장성이 없습니다.
이 게시물에서는 다음을 사용하여 지급 계정 프로세스를 자동화하는 방법을 보여줍니다. 아마존 텍사스 데이터 추출을 위해. 또한 추출, 확인, 보관 및 지능형 검색을 지원하는 송장 자동화 파이프라인을 구축하기 위한 참조 아키텍처도 제공합니다.
솔루션 개요
다음 아키텍처 다이어그램은 영수증 및 송장 처리 워크플로의 단계를 보여줍니다. 스캔한 청구서와 영수증을 안전하게 수집하고 보관하기 위한 문서 캡처 단계부터 시작됩니다. 다음 단계는 수집된 송장과 영수증을 Amazon Textract로 전달하는 추출 단계입니다. AnalyzeExpense 공급업체 이름, 송장 수령 날짜, 주문 날짜, 미결제 금액, 결제 금액 등과 같은 텍스트 간의 재무 관련 관계를 추출하는 API입니다. 다음 단계에서는 미리 정의된 비용 규칙을 사용하여 영수증을 자동으로 승인할지 거부할지 결정합니다. 승인된 문서와 거부된 문서는 다음의 해당 폴더로 이동됩니다. 아마존 단순 스토리지 서비스 (Amazon S3) 버킷. 승인된 문서의 경우 다음을 사용하여 추출된 모든 필드와 값을 검색할 수 있습니다. 아마존 오픈서치 서비스. OpenSearch 대시보드를 사용하여 인덱싱된 메타데이터를 시각화할 수 있습니다. 승인된 문서도 다음으로 이동되도록 설정되어 있습니다. Amazon S3 지능형 계층화 S3 수명 주기 정책을 사용하여 장기 보존 및 보관이 가능합니다.
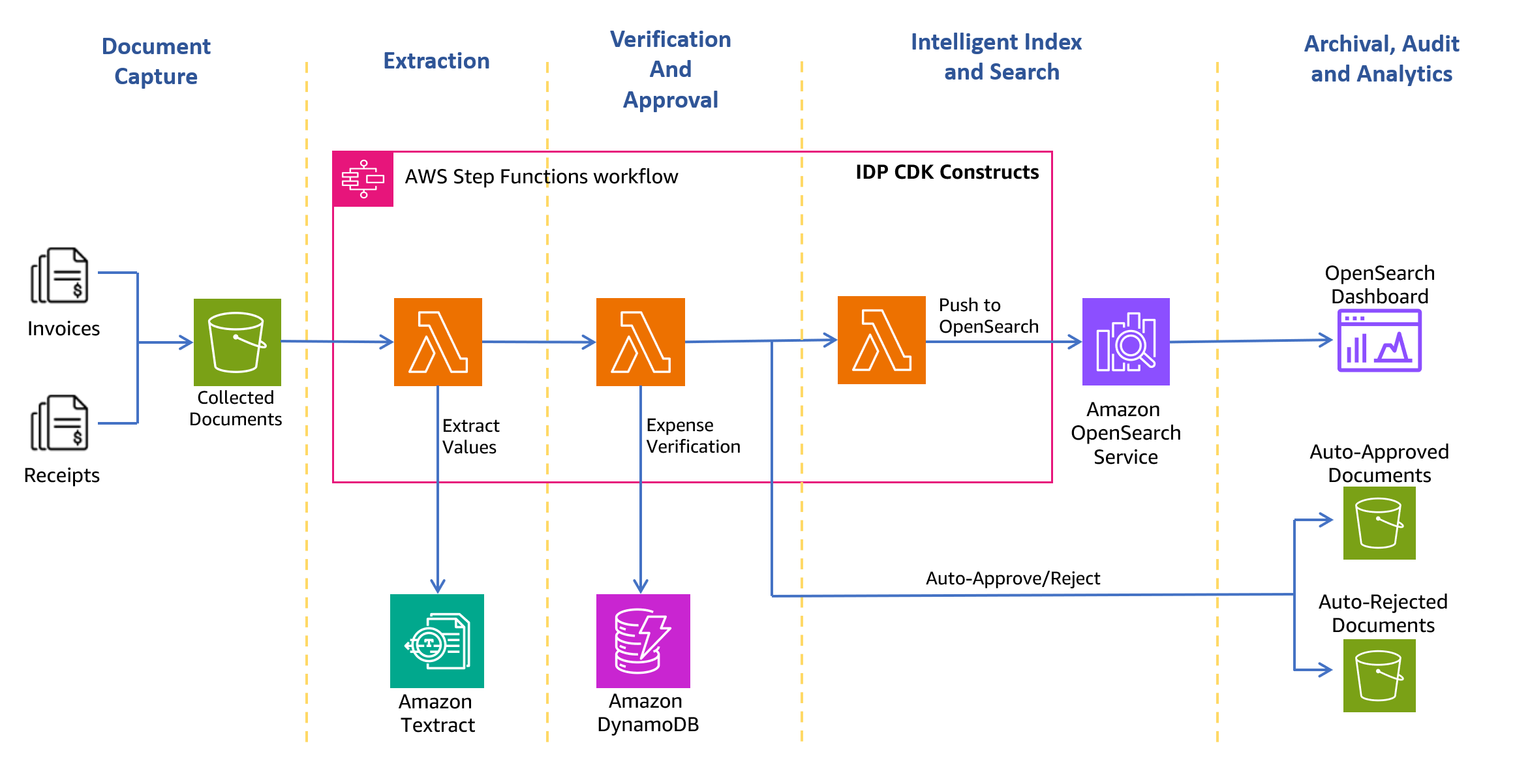
다음 섹션에서는 솔루션을 만드는 과정을 안내합니다.
사전 조건
이 솔루션을 배포하려면 다음이 필요합니다.
- AWS 계정.
- An AWS 클라우드9 환경. AWS Cloud9은 브라우저만으로 코드를 작성, 실행 및 디버깅할 수 있는 클라우드 기반 통합 개발 환경(IDE)입니다. 여기에는 코드 편집기, 디버거 및 터미널이 포함됩니다.
AWS Cloud9 환경을 생성하려면 이름과 설명을 제공하십시오. 다른 모든 항목은 기본값으로 유지하세요. AWS Cloud9 콘솔에서 IDE 링크를 선택하여 IDE로 이동합니다. 이제 AWS Cloud9 환경을 사용할 준비가 되었습니다.
솔루션 배포
솔루션을 설정하려면 AWS 클라우드 개발 키트 (AWS CDK)를 배포하기 위해 AWS 클라우드 포메이션 스택.
- AWS Cloud9 IDE 터미널에서 GitHub 저장소 종속성을 설치합니다. 다음 명령을 실행하여 배포합니다.
InvoiceProcessor스택:
GitHub 리포지토리의 기본 구성 설정을 사용하면 배포에 약 25분이 소요됩니다. 추가 출력 정보는 AWS CloudFormation 콘솔에서도 확인할 수 있습니다.
- AWS CDK 배포가 완료된 후 비용 확인 규칙을 생성합니다. 아마존 DynamoDB 테이블. 동일한 AWS Cloud9 터미널을 사용하여 다음 명령을 실행할 수 있습니다.
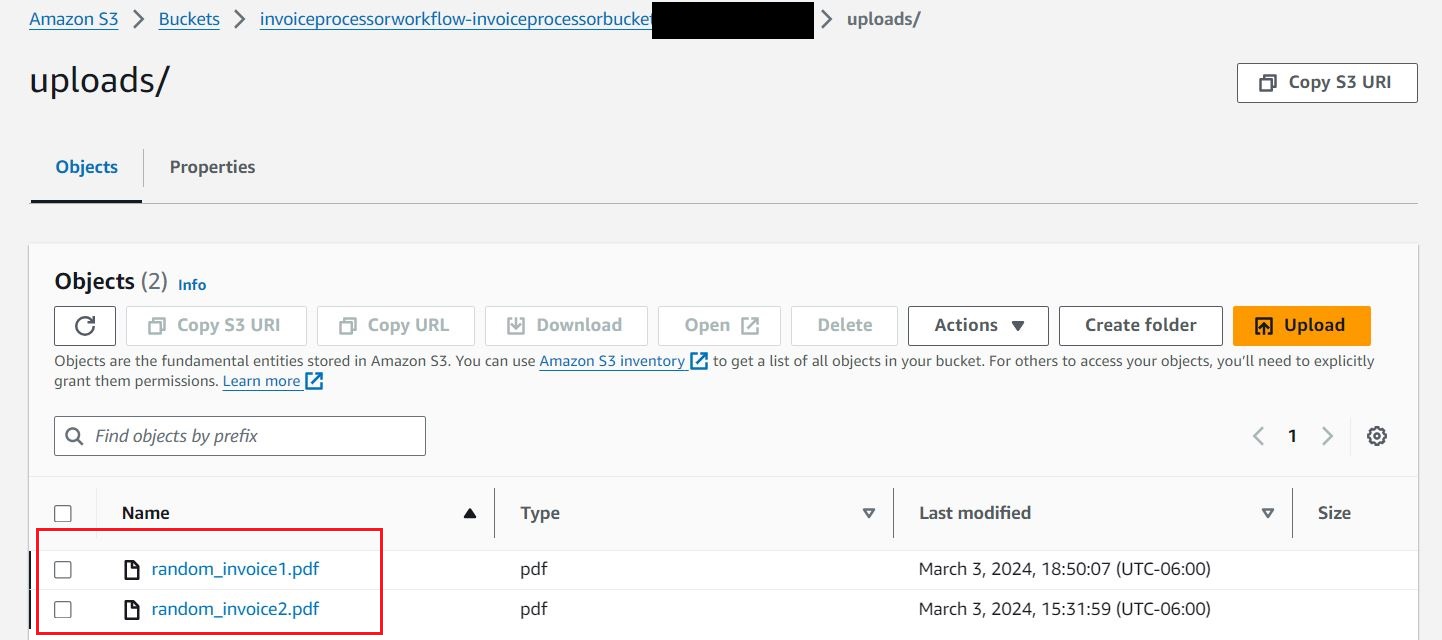
- 다음으로 시작하는 S3 버킷에서
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, 업로드 폴더를 만듭니다.
In 아마존 코 그니 토, 다음과 같은 기존 사용자 풀이 이미 있어야 합니다. OpenSearchResourcesCognitoUserPool*. 우리는 이 사용자 풀을 사용하여 새 사용자를 생성합니다.
- Amazon Cognito 콘솔에서 사용자 풀로 이동합니다.
OpenSearchResourcesCognitoUserPool*. - 새로운 Amazon Cognito 사용자를 생성합니다.
- 선택한 사용자 이름과 비밀번호를 제공하고 나중에 사용할 수 있도록 기록해 두십시오.
- 문서 업로드 무작위_인보이스1 및 무작위_인보이스2 S3로
uploads워크플로를 시작하는 폴더입니다.
이제 각 문서 처리 단계를 살펴보겠습니다.
문서 캡처
고객은 다양한 공급업체의 다양한 형식으로 송장과 영수증을 처리합니다. 이러한 문서는 인쇄본, 파일 저장소에 업로드된 스캔본, 공유 저장 장치 등의 채널을 통해 수신됩니다. 문서 캡처 단계에서는 스캔한 모든 영수증 및 송장 사본을 S3 버킷과 같이 확장성이 뛰어난 스토리지에 저장합니다.
추출
다음 단계는 수집된 송장과 영수증을 Amazon Textract로 전달하는 추출 단계입니다. AnalyzeExpense 공급업체 이름, 송장 수령 날짜, 주문 날짜, 결제 금액 등 텍스트 간의 재무 관련 관계를 추출하는 API입니다.
비용 분석 송장 및 영수증 문서 처리 전용 API입니다. 동기식 또는 비동기식 API로 모두 사용할 수 있습니다. 동기 API를 사용하면 이미지를 바이트 형식으로 보낼 수 있으며, 비동기 API를 사용하면 JPG, PNG, TIFF 및 PDF 형식의 파일을 보낼 수 있습니다. 그만큼 AnalyzeExpense API 응답은 세 가지 개별 섹션으로 구성됩니다.
- 요약 필드 – 이 섹션에는 정규화된 키와 명시적으로 언급된 키가 해당 값과 함께 포함되어 있습니다.
AnalyzeExpense공급업체 이름 및 공급업체 주소와 같은 연락처 관련 정보, 납세자 ID와 같은 세금 ID 관련 키, 미결제 금액 및 할인과 같은 결제 관련 키, 송장 ID, 배송 날짜 및 배송 날짜와 같은 일반 키를 정규화합니다. 계좌 번호. 정규화되지 않은 키는 여전히 요약 필드에 키-값 쌍으로 나타납니다. 지원되는 비용 필드의 전체 목록은 다음을 참조하세요. 송장 및 영수증 분석. - 광고 항목 – 이 섹션에는 품목 설명, 단가, 수량, 제품 코드 등 정규화된 품목 키가 포함됩니다.
- OCR 블록 – 블록에는 송장 페이지에서 추출된 원시 텍스트가 포함되어 있습니다. 원시 텍스트 추출은 요약 및 품목 필드의 일부로 다루지 않는 정보를 후처리하고 식별하는 데 사용할 수 있습니다.
이 게시물은 Amazon Textract IDP CDK 구성 (지능형 문서 처리(IDP) 워크플로를 위한 인프라를 정의하는 AWS CDK 구성 요소)를 사용하면 사용 사례별 사용자 지정 가능한 IDP 워크플로를 구축할 수 있습니다. 구성 및 샘플은 AWS에서 IDP 프로세스를 정의할 수 있도록 하고 다음에 게시되는 구성 요소 모음입니다. GitHub의. 사용된 주요 개념은 AWS CDK 구성, 실제 AWS CDK 스택및 AWS 단계 함수.
다음 그림은 Step Functions 워크플로를 보여줍니다.
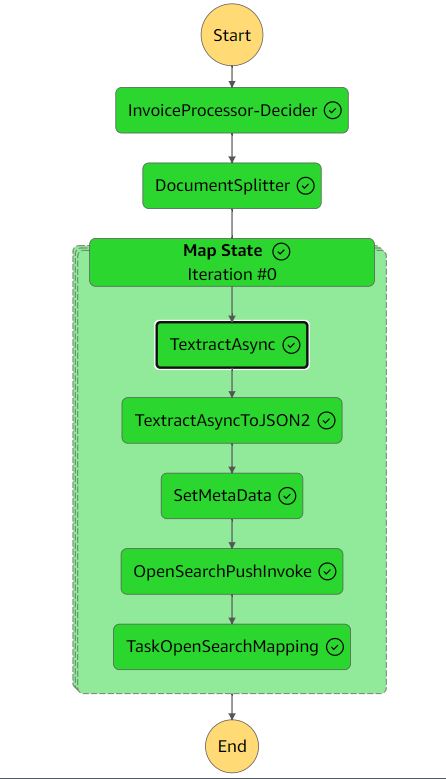
추출 작업 흐름에는 다음 단계가 포함됩니다.
- 송장처리자-결정자 - AWS 람다 입력 문서 형식이 Amazon Textract에서 지원되는지 확인하는 함수입니다. 지원되는 형식에 대한 자세한 내용은 다음을 참조하세요. 입력서류.
- 문서 분할기 – 문서에서 2,500페이지(최대) 청크를 생성하고 여러 페이지로 구성된 대규모 문서를 처리할 수 있는 Lambda 함수입니다.
- 지도 상태 – 각 청크를 병렬로 처리하는 Lambda 함수입니다.
- TextractAsync – 이 작업은 다음과 같은 비동기 API를 사용하여 Amazon Textract를 호출합니다. 모범 사례 과 아마존 단순 알림 서비스 (Amazon SNS) 알림 및 사용
OutputConfig이전에 생성한 S3 버킷에 Amazon Textract JSON 출력을 저장합니다. 이는 두 개의 Lambda 함수로 구성됩니다. 하나는 처리를 위해 문서를 제출하는 함수이고 다른 하나는 SNS 알림에서 트리거되는 함수입니다. - TextractAsyncToJSON2 – 때문에
TextractAsync작업은 페이지가 매겨진 여러 출력 파일을 생성할 수 있습니다.TextractAsyncToJSON2프로세스는 이를 하나의 JSON 파일로 결합합니다.
다음 섹션에서는 다음 세 단계에 대해 자세히 설명합니다.
확인 및 승인
검증단계에서는 SetMetaData Lambda 함수는 업로드된 파일이 이전에 DynamoDB 테이블에 구성된 규칙에 따라 유효한 비용인지 확인합니다. 이 게시물에서는 다음 샘플 규칙을 사용합니다.
- 다음과 같은 경우 확인이 성공한 것입니다.
INVOICE_RECEIPT_ID존재하며 정규식과 일치합니다.(?i)[0-9]{3}[a-z]{3}[0-9]{3}$및 ifPO_NUMBER존재하며 정규식과 일치합니다.(?i)[a-z0-9]+$ - 다음 중 하나에 해당하면 확인이 실패합니다.
PO_NUMBERorINVOICE_RECEIPT_ID문서에 내용이 잘못되었거나 누락되었습니다.
파일이 처리된 후 비용 확인 기능은 입력 파일을 다음 중 하나로 이동합니다. approved or declined 동일한 S3 버킷의 폴더.
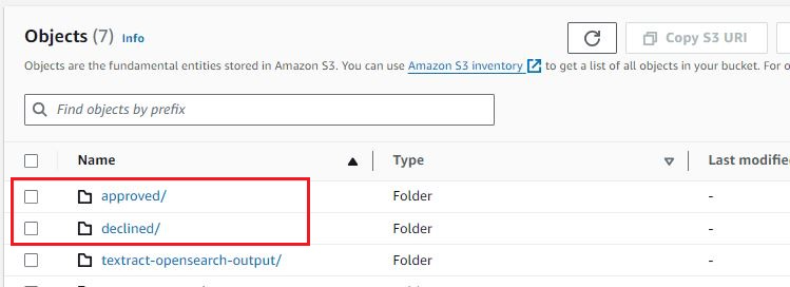
이 솔루션의 목적을 위해 우리는 DynamoDB를 사용하여 비용 확인 규칙을 저장합니다. 그러나 이 솔루션을 수정하여 자체 또는 상업적 비용 검증 또는 관리 솔루션과 통합할 수 있습니다.
지능형 색인 및 검색
와 더불어 OpenSearchPushInvoke 추출된 비용 메타데이터인 Lambda 함수가 OpenSearch 서비스 인덱스로 푸시되어 검색에 사용할 수 있습니다.
마지막 TaskOpenSearchMapping 단계에서는 컨텍스트를 지웁니다. 그렇지 않으면 컨텍스트를 초과할 수 있습니다. Step Functions 할당량 작업, 상태 또는 워크플로 실행에 대한 최대 입력 또는 출력 크기입니다.
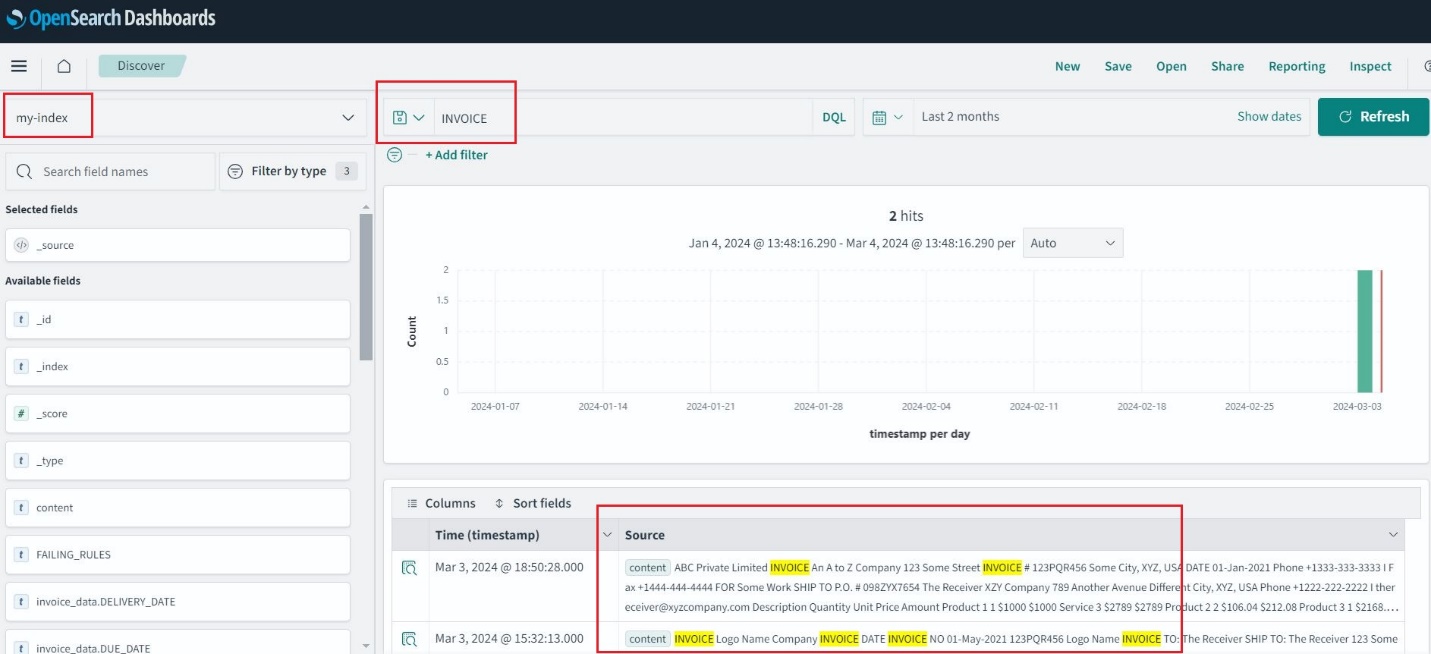
OpenSearch 서비스 인덱스가 생성되면 OpenSearch 대시보드를 통해 추출된 텍스트에서 키워드를 검색할 수 있습니다.
보관, 감사 및 분석
송장 및 영수증의 수명 주기와 보관을 관리하려면 S3 객체를 표준에서 지능형 계층형 스토리지 클래스로 전환하도록 S3 수명 주기 규칙을 구성할 수 있습니다. S3 Intelligent-Tiering은 액세스 패턴을 모니터링하고 30일 연속으로 객체에 액세스하지 않으면 자동으로 Infrequent Access 계층으로 객체를 이동합니다. 90일 동안 액세스할 수 없으면 개체는 성능에 미치는 영향이나 운영 오버헤드 없이 Archive Instant Access 계층으로 이동됩니다.
감사 및 분석을 위해 이 솔루션은 송장 요청에 대한 분석을 실행하기 위해 OpenSearch Service를 사용합니다. OpenSearch 서비스를 사용하면 로그 분석, 애플리케이션 검색, 엔터프라이즈 검색 등과 같은 다양한 사용 사례에 대한 데이터를 손쉽게 수집, 보호, 검색, 집계, 확인 및 분석할 수 있습니다.
OpenSearch 대시보드에 로그인하고 다음으로 이동합니다. 스택 관리, 저장된 개체다음을 선택 수입. 선택 송장.ndjson 복제된 저장소에서 파일을 선택하고 수입. 이렇게 하면 인덱스가 미리 채워지고 시각화가 구축됩니다.
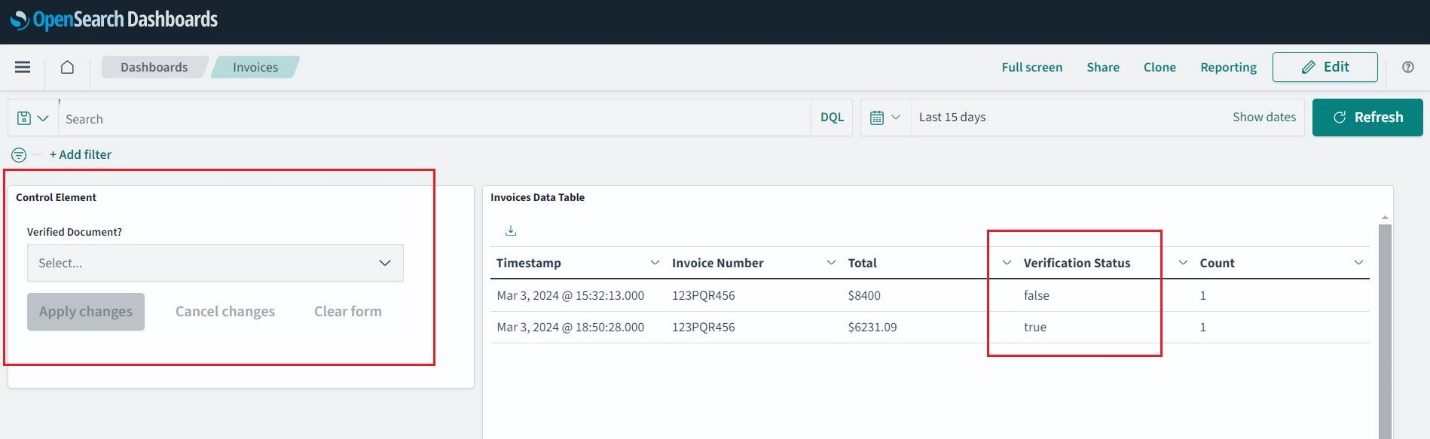
페이지를 새로 고치고 다음으로 이동하세요. 홈, 대시보드오픈 송장. 이제 필터를 선택 및 적용하고 기간을 확장하여 과거 송장을 탐색할 수 있습니다.
정리
영수증 및 송장 처리를 위해 Amazon Textract 평가를 마쳤으면 생성했을 수 있는 모든 리소스를 정리하는 것이 좋습니다. 다음 단계를 완료하세요.
- S3 버킷에서 모든 콘텐츠 삭제
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - AWS Cloud9에서 다음 명령을 실행하여 Amazon Cognito 리소스 및 CloudFormation 스택을 삭제합니다.
- AWS Cloud9 콘솔에서 생성한 AWS Cloud9 환경을 삭제합니다.
결론
이 게시물에서는 데이터 추출을 위해 Amazon Textract를 사용하여 송장 자동화 파이프라인을 구축하고 검증, 보관 및 검색을 위한 워크플로를 생성하는 방법에 대한 개요를 제공했습니다. 우리는 사용 방법에 대한 코드 샘플을 제공했습니다. AnalyzeExpense 송장에서 중요한 필드를 추출하기 위한 API입니다.
시작하려면 Amazon Textract 콘솔에 로그인하여 이 기능을 사용해 보십시오. Amazon Textract 기능에 대해 자세히 알아보려면 다음을 참조하십시오. Amazon Textract 개발자 안내서 or Textract 리소스. IDP에 대해 자세히 알아보려면 AWS AI 서비스가 포함된 IDP를 참조하세요. 파트 1 및 파트 2 게시물.
저자에 관하여
 수샨트 프라단 Amazon Web Services의 수석 솔루션 설계자로 기업 고객을 돕고 있습니다. 그의 관심과 경험에는 컨테이너, 서버리스 기술, DevOps가 포함됩니다. 여가 시간에 Sushant는 가족과 함께 야외에서 시간을 보내는 것을 즐깁니다.
수샨트 프라단 Amazon Web Services의 수석 솔루션 설계자로 기업 고객을 돕고 있습니다. 그의 관심과 경험에는 컨테이너, 서버리스 기술, DevOps가 포함됩니다. 여가 시간에 Sushant는 가족과 함께 야외에서 시간을 보내는 것을 즐깁니다.
 시빈 미카엘라즈 AWS Textract 팀의 선임 제품 관리자입니다. AWS 고객을 위한 AI/ML 기반 제품 구축에 주력하고 있습니다.
시빈 미카엘라즈 AWS Textract 팀의 선임 제품 관리자입니다. AWS 고객을 위한 AI/ML 기반 제품 구축에 주력하고 있습니다.
 수프라카시 두타 Amazon Web Services의 선임 솔루션 아키텍트입니다. 그는 디지털 혁신 전략, 애플리케이션 현대화 및 마이그레이션, 데이터 분석 및 기계 학습에 중점을 둡니다. 그는 AWS의 AI/ML 커뮤니티의 일원이며 지능형 문서 처리 솔루션을 설계합니다.
수프라카시 두타 Amazon Web Services의 선임 솔루션 아키텍트입니다. 그는 디지털 혁신 전략, 애플리케이션 현대화 및 마이그레이션, 데이터 분석 및 기계 학습에 중점을 둡니다. 그는 AWS의 AI/ML 커뮤니티의 일원이며 지능형 문서 처리 솔루션을 설계합니다.
 마란 찬드라세카란 엔터프라이즈 고객과 함께 일하는 Amazon Web Services의 선임 솔루션 아키텍트입니다. 직장 밖에서 그는 텍사스 힐 컨트리에서 오토바이를 타고 여행하는 것을 좋아합니다.
마란 찬드라세카란 엔터프라이즈 고객과 함께 일하는 Amazon Web Services의 선임 솔루션 아키텍트입니다. 직장 밖에서 그는 텍사스 힐 컨트리에서 오토바이를 타고 여행하는 것을 좋아합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

