Generative AI (GenAI) と大規模言語モデル (LLM)。 アマゾンの岩盤 および アマゾンタイタン 開発者や企業が、自然言語の処理と理解に関連する従来の複雑な課題を解決できる方法を変革しています。 LLM が提供する利点には、カスタマー サービス アプリケーション向けのより有能で魅力的な会話型 AI エクスペリエンスを作成する機能や、より直感的で正確な応答によって従業員の生産性を向上させる機能が含まれます。
ただし、これらのユースケースでは、会話型エクスペリエンスを実装する GenAI アプリケーションが XNUMX つの重要な基準を満たすことが重要です。それは、企業データへの応答を制限し、それによってモデルの幻覚 (誤ったステートメント) を軽減し、エンドユーザーのコンテンツ アクセスに応じて応答をフィルター処理することです。パーミッション。
GenAI アプリケーションの応答を企業データのみに制限するには、Retrieval Augmented Generation (RAG) と呼ばれる手法を使用する必要があります。 RAG アプローチを使用するアプリケーションは、エンタープライズ ナレッジ ベースまたはコンテンツからユーザーの要求に最も関連する情報を取得し、それをプロンプトとしてのユーザーの要求と共にコンテキストとしてバンドルし、LLM に送信して GenAI 応答を取得します。 LLM には、入力プロンプトの最大単語数に関する制限があるため、企業内の数千または数百万のドキュメントから適切なパッセージを選択することは、LLM の精度に直接影響します。
効果的な RAG の設計において、コンテンツ検索は、LLM がエンタープライズ コンテンツから最も関連性が高く簡潔なコンテキストを確実に受け取り、正確な応答を生成するための重要なステップです。 これは、非常に正確な機械学習 (ML) を活用した インテリジェント検索 in アマゾンケンドラ 重要な役割を果たします。 Amazon Kendra は、ドキュメントとパッセージの最先端のランキングのために、すぐに使えるセマンティック検索機能を提供する完全マネージド型のサービスです。 Amazon Kendra の高精度検索を使用して、最も関連性の高いコンテンツとドキュメントを調達し、RAG ペイロードの品質を最大化し、従来の検索ソリューションやキーワードベースの検索ソリューションを使用するよりも優れた LLM 応答を得ることができます。 Amazon Kendra は、14 のドメインで事前にトレーニングされ、ML の専門知識を必要としない使いやすい深層学習検索モデルを提供するため、単語の埋め込み、ドキュメントのチャンキング、および通常必要とされるその他の低レベルの複雑さに対処する必要はありません。 RAG 実装用。 Amazon Kendra には、次のような一般的なデータ ソースへの事前構築済みコネクタも付属しています。 Amazon シンプル ストレージ サービス (Amazon S3)、SharePoint、Confluence、および Web サイトに対応し、HTML、Word、PowerPoint、PDF、Excel、純粋なテキスト ファイルなどの一般的なドキュメント形式をサポートします。 エンドユーザーのアクセス許可で許可されているドキュメントのみに基づいて応答をフィルタリングするために、Amazon Kendra はアクセス コントロール リスト (ACL) をサポートするコネクタを提供します。 Amazon Kendra も提供しています AWS IDおよびアクセス管理 (IAM)および AWS IAM アイデンティティ センター Okta や Azure AD などの顧客 ID プロバイダーと同期するユーザー グループ情報のための (AWS Single Sign-On の後継) 統合。
この投稿では、Amazon Kendra の機能を LLM と組み合わせて RAG ワークフローを実装し、エンタープライズ コンテンツに対する会話体験を提供する最先端の GenAI アプリケーションを作成する方法を示します。 後 アマゾンの岩盤 Amazon Bedrock を使用して同様の GenAI アプリケーションを実装する方法を示すフォローアップの投稿を公開する予定です。
ソリューションの概要
次の図は、RAG アプローチを使用した GenAI アプリケーションのアーキテクチャを示しています。
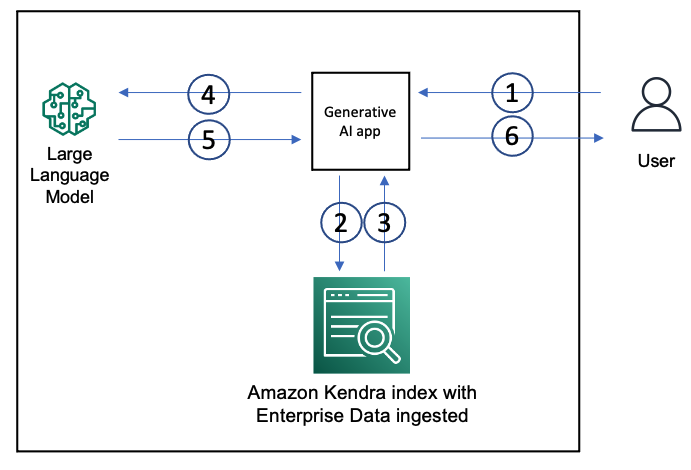
Amazon Kendra インデックスを使用して、wiki ページ、MS SharePoint サイト、Atlassian Confluence、Amazon S3 などのドキュメント リポジトリなどのデータ ソースから企業の非構造化データを取り込みます。 ユーザーが GenAI アプリを操作するときの流れは次のとおりです。
- ユーザーが GenAI アプリにリクエストを送信します。
- アプリは、ユーザーのリクエストに基づいて Amazon Kendra インデックスに検索クエリを発行します。
- インデックスは、取り込まれたエンタープライズ データからの関連ドキュメントの抜粋を含む検索結果を返します。
- アプリは、LLM プロンプトのコンテキストとしてインデックスから取得したデータと共に、ユーザー リクエストを送信します。
- LLM は、取得したデータに基づいて、ユーザーの要求に対して簡潔な応答を返します。
- LLM からの応答がユーザーに返されます。
このアーキテクチャを使用すると、ユース ケースに最適な LLM を選択できます。 LLM オプションには、パートナーである Hugging Face、AI21 Labs、Cohere など、 アマゾンセージメーカー エンドポイント、および次のような企業によるモデル 人間原理 および OpenAI アマゾンの岩盤、選択できるようになります アマゾンタイタン、Amazon 独自の LLM、または AI21 Labs や Anthropic などのパートナー LLM と API を安全に使用でき、データが AWS エコシステムを離れる必要はありません。 Amazon Bedrock が提供するその他の利点には、サーバーレス アーキテクチャ、サポートされている LLM を呼び出す単一の API、および開発者のワークフローを合理化するマネージド サービスが含まれます。
最良の結果を得るには、GenAI アプリは、ユーザーの要求と使用されている特定の LLM に基づいてプロンプトを設計する必要があります。 会話型 AI アプリでは、チャットの履歴とコンテキストも管理する必要があります。 GenAI アプリの開発者は、次のようなオープンソース フレームワークを使用できます。 ラングチェーン 選択した LLM と統合するためのモジュール、およびチャット履歴管理やプロンプト エンジニアリングなどのアクティビティ用のオーケストレーション ツールを提供します。 私たちは提供しました KendraIndexRetriever を実装するクラス LangChain レトリーバー アプリケーションは、次のような他の LangChain インターフェースと組み合わせて使用できます。 チェーン Amazon Kendra インデックスからデータを取得します。 また、いくつかのサンプル アプリケーションも提供しています。 GitHubレポ. この投稿のステップバイステップ ガイドを使用して、このソリューションを AWS アカウントにデプロイできます。
前提条件
このチュートリアルでは、Linux、Mac、または Linux 用 Windows サブシステムに Python 3.9 以降がインストールされた bash ターミナルと、AWS アカウントが必要です。 また、 AWS クラウド9 インスタンスまたは アマゾン エラスティック コンピューティング クラウド (Amazon EC2)インスタンス。
RAG ワークフローを実装する
RAG ワークフローを構成するには、次の手順を実行します。
- 提供されているものを使用してください AWS CloudFormation template 新しい Amazon Kendra インデックスを作成します。
このテンプレートには、Amazon Kendra の AWS オンライン ドキュメントを含むサンプル データが含まれています。 Amazon Lex, アマゾンセージメーカー. または、Amazon Kendra インデックスがあり、独自のデータセットにインデックスを作成している場合は、それを使用できます。 スタックの起動には約 30 分かかり、同期とインデックス内のデータの取り込みには約 15 分かかります。 そのため、スタックを起動してから約 45 分待ちます。 スタックのインデックス ID と AWS リージョンに注意してください 出力 タブには何も表示されないことに注意してください。
- GenAI エクスペリエンスを向上させるために、 Amazon Kendra サービスのクォータの増加 最大の
DocumentExcerptこれにより、Amazon Kendra はより大きなドキュメントの抜粋を提供して、LLM のセマンティック コンテキストを改善します。 - インストール Python 用 AWS SDK 選択したコマンド ライン インターフェイスで。
- を使用して構築されたサンプル Web アプリを使用する場合 ストリームライト、最初に ストリームリットをインストール. サンプル アプリケーションのコマンド ライン バージョンのみを実行する場合、この手順はオプションです。
- LangChain をインストールする.
- このチュートリアルで使用されるサンプル アプリケーションでは、Flan-T5-XL、Flan-T5-XXL、Anthropic Claud-V1、および OpenAI-text-davinci-003 から XNUMX つ以上の LLM にアクセスできる必要があります。
- Flan-T5-XL または Flan-T5-XXL を使用する場合は、以下を使用して推論のためにそれらをエンドポイントにデプロイします。 Amazon SageMaker Studio ジャンプスタート.

- Anthropic Claud-V1 または OpenAI-da-vinci-003 を使用する場合は、対象の LLM の API キーを次から取得します。 https://www.anthropic.com/ および https://openai.com/それぞれ。
- Flan-T5-XL または Flan-T5-XXL を使用する場合は、以下を使用して推論のためにそれらをエンドポイントにデプロイします。 Amazon SageMaker Studio ジャンプスタート.
- の指示に従ってください GitHubレポ インストールする
KendraIndexRetrieverインターフェイスとサンプル アプリケーション。 - サンプルアプリケーションを実行する前に、Flan-T5-XL または Flan-T5-XXL のデプロイメントの優先 LLM または SageMaker エンドポイントの Amazon Kendra インデックスの詳細と API キーを使用して環境変数を設定する必要があります。 以下は、環境変数を設定するサンプル スクリプトです。
- コマンド ライン ウィンドウで、
samplesGitHub リポジトリをクローンした場所のサブディレクトリ。 次のように、コマンド ラインからコマンド ライン アプリを実行できます。python <sample-file-name.py>. ディレクトリを次のように変更することで、streamlit Web アプリを実行できます。samplesそして実行中streamlit run app.py <anthropic|flanxl|flanxxl|openai>. - サンプルファイルを開く
kendra_retriever_flan_xxl.pyお好みのエディターで。
ステートメントを観察する result = run_chain(chain, "What's SageMaker?"). これは、LLM として Flan-T-XXL を使用し、レトリーバーとして Amazon Kendra を使用するチェーンを介して実行されるユーザー クエリ (「What's SageMaker?」) です。 このファイルを実行すると、次のような出力を確認できます。 チェーンはユーザー クエリを Amazon Kendra インデックスに送信し、上位 XNUMX つの結果の抜粋を取得して、クエリと共にプロンプトのコンテキストとして送信し、LLM は簡潔な回答で応答しました。 また、ソース (回答の生成に使用されたドキュメントへの URL) も提供しています。
- それでは、Web アプリを実行してみましょう
app.pyasstreamlit run app.py flanxxl. この特定の実行では、LLM として Flan-T-XXL モデルを使用しています。
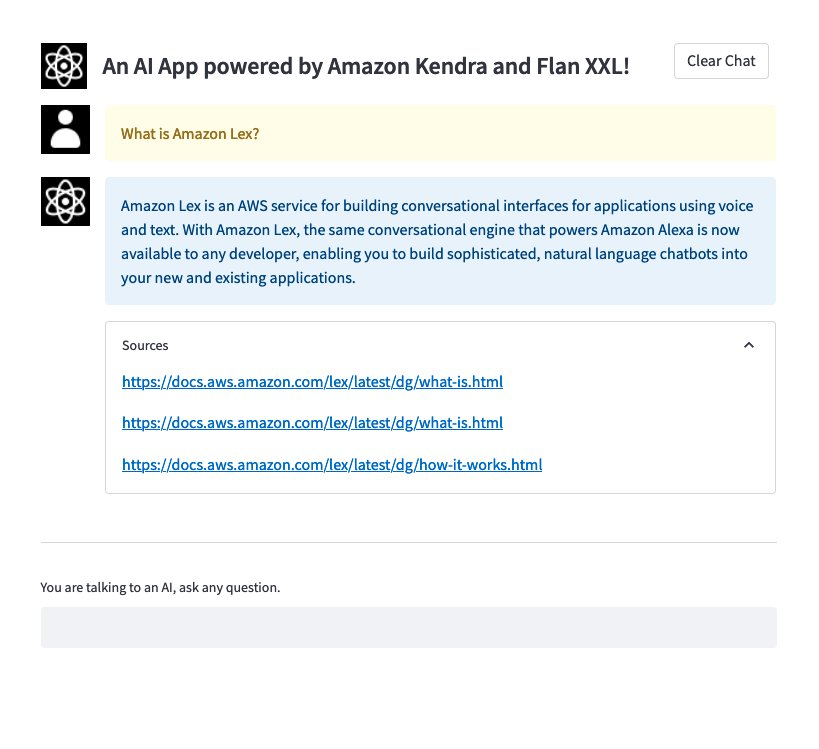
Web インターフェイスを備えたブラウザ ウィンドウが開きます。 この場合は「What is Amazon Lex?」というクエリを入力できます。 次のスクリーンショットに示すように、アプリケーションは応答で応答し、 ソース セクションでは、抜粋が Amazon Kendra インデックスから取得され、クエリとともにコンテキストとしてプロンプトで LLM に送信されたドキュメントへの URL を提供します。
- さあ、走りましょう
app.pyを使用して会話体験を感じてください。streamlit run app.py anthropic. ここで使用される基礎となる LLM は Anthropic Claud-V1 です。
次のビデオでわかるように、LLM は、Amazon Kendra インデックスから取得したドキュメントに基づいてユーザーのクエリに対する詳細な回答を提供し、回答の生成に使用されたソース ドキュメントへの URL で回答をサポートします。 後続のクエリでは、Amazon Kendra について明示的に言及していないことに注意してください。 しかし ConversationalRetrievalChain (LangChain フレームワークの一部であり、この LangChain アプリケーションで使用される、レトリーバー インスタンスから取得された会話型アプリケーション ベースの情報を開発するための簡単なメカニズムを提供するチェーンの一種) は、チャット履歴とコンテキストを管理して、適切な応答を取得します。
また、次のスクリーンショットでは、Amazon Kendra がクエリに対する抽出的な回答を見つけ、上位のドキュメントを抜粋で絞り込みます。 次に、LLM は、取得した抜粋に基づいて、より簡潔な回答を生成できます。

以下のセクションでは、Amazon Kendra で Generative AI を使用する XNUMX つのユースケースについて説明します。
ユースケース 1: 金融サービス企業向けのジェネレーティブ AI
金融機関は、財務報告書、法律文書、ホワイトペーパーなど、さまざまなデータ リポジトリにわたってデータを作成および保存します。 厳格な政府の規制と監視を順守する必要があります。つまり、従業員は関連性があり、正確で信頼できる情報を迅速に見つける必要があります。 さらに、さまざまなデータ ソースにわたって洞察を検索して集約するのは面倒で、エラーが発生しやすくなります。 Generative AI on AWS を使用すると、ユーザーはさまざまなデータ ソースやタイプから回答をすばやく生成し、エンタープライズ規模で正確な回答を合成できます。
Amazon Kendra と AI21 Lab の Jurassic-2 Jumbo Instruct LLM を使用するソリューションを選択しました。 Amazon Kendra を使用すると、Amazon S3、ウェブサイト、ServiceNow などの複数のデータ ソースから簡単にデータを取り込むことができます。 次に、Amazon Kendra は AI21 Lab の Jurassic-2 Jumbo Instruct LLM を使用して、データの要約、レポート生成などの企業データに関する推論アクティビティを実行します。 Amazon Kendra は、LLM を強化して正確で検証可能な情報をエンドユーザーに提供し、LLM の幻覚の問題を減らします。 提案されたソリューションを使用すると、金融アナリストは正確なデータを使用してより迅速に意思決定を行い、詳細で包括的なポートフォリオを迅速に構築できます。 近い将来、このソリューションをオープンソース プロジェクトとして利用できるようにする予定です。
例
Kendra Chatbot ソリューションを使用すると、財務アナリストと監査人は企業データ (財務レポートと契約書) を操作して、監査関連の質問に対する信頼できる回答を見つけることができます。 Kendra ChatBot は、ソース リンクとともに回答を提供し、より長い回答を要約する機能を備えています。 次のスクリーンショットは、Kendra ChatBot との会話の例を示しています。

アーキテクチャの概要
次の図は、ソリューションのアーキテクチャを示しています。
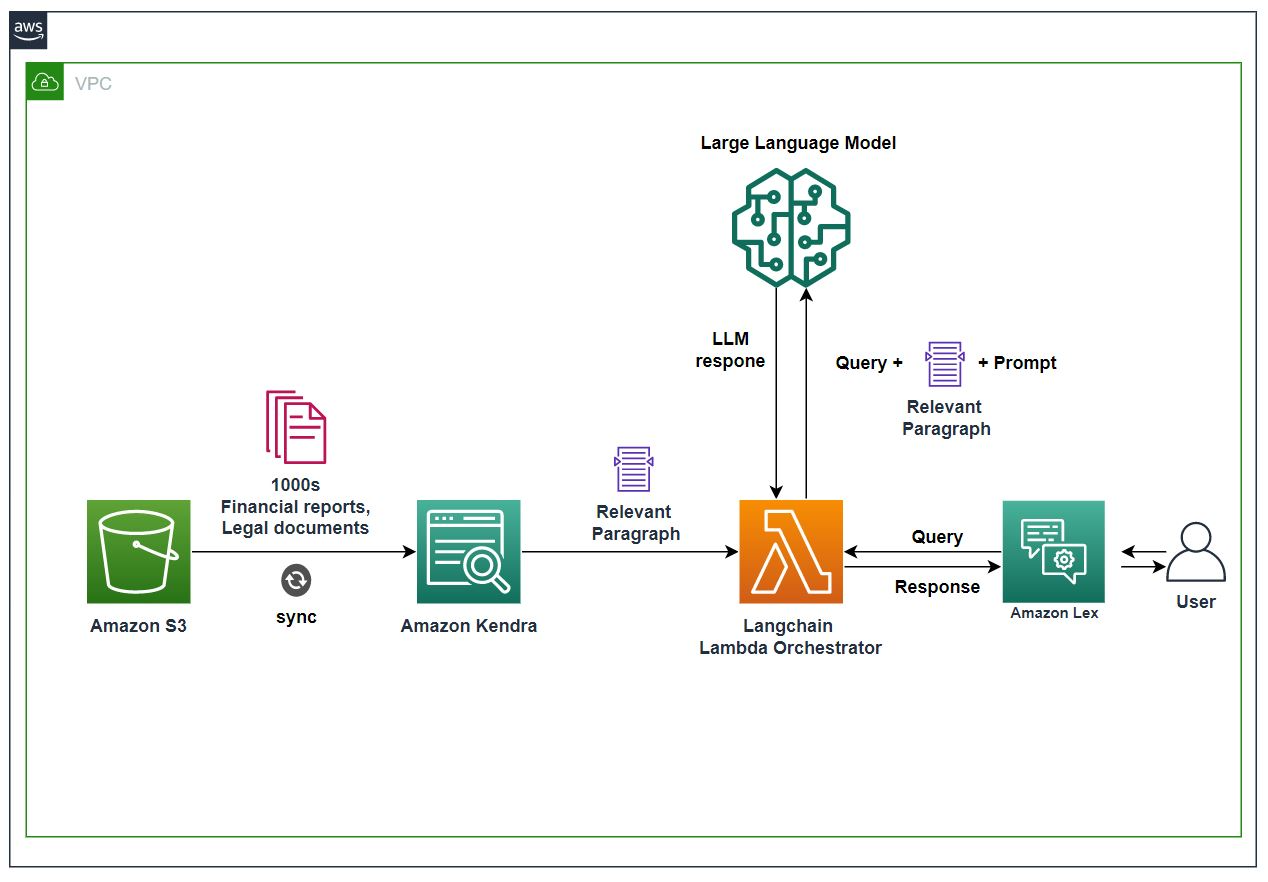
ワークフローには次の手順が含まれます。
- 財務文書と契約書は Amazon S3 に保存され、S3 データ ソース コネクタを使用して Amazon Kendra インデックスに取り込まれます。
- LLM は SageMaker エンドポイントでホストされます。
- Amazon Lex チャットボットを使用して、 Amazon Lex ウェブ UI.
- このソリューションでは、 AWSラムダ LangChain で機能して、Amazon Kendra、Amazon Lex、および LLM の間でオーケストレーションを行います。
- ユーザーが Amazon Lex チャットボットに財務文書からの回答を求めると、Amazon Lex は LangChain オーケストレーターを呼び出して要求を実行します。
- クエリに基づいて、LangChain オーケストレーターは関連する財務記録と段落を Amazon Kendra から引き出します。
- LangChain オーケストレーターは、必要なアクティビティを実行するために、これらの関連レコードをクエリおよび関連するプロンプトと共に LLM に提供します。
- LLM は、LangChain オーケストレーターからの要求を処理し、結果を返します。
- LangChain オーケストレーターは LLM から結果を取得し、Amazon Lex チャットボットを介してエンドユーザーに送信します。
ユースケース 2: ヘルスケア研究者と臨床医向けのジェネレーティブ AI
臨床医や研究者は、研究の一環として、医学雑誌や政府の健康に関する Web サイトから何千もの記事を分析することがよくあります。 さらに重要なことは、調査結果を検証して実証するために使用できる信頼できるデータ ソースを求めていることです。 このプロセスには、何時間もの集中的な調査、分析、およびデータ合成が必要であり、価値と革新までの時間が長くなります。 Generative AI on AWS を使用すると、信頼できるデータ ソースに接続し、自然言語クエリを実行して、これらの信頼できるデータ ソース全体から数秒で洞察を生成できます。 また、応答の生成に使用されたソースを確認し、その正確性を検証することもできます。
Amazon Kendra と Hugging Face の Flan-T5-XXL を使用したソリューションを選択しました。 まず、Amazon Kendra を使用して、コーパス全体で意味的に関連するドキュメントからテキスト スニペットを識別します。 次に、Flan-T5-XXL などの LLM の機能を使用して、Amazon Kendra からのテキスト スニペットをコンテキストとして使用し、簡潔な自然言語の回答を取得します。 このアプローチでは、Amazon Kendra インデックスは、RAG メカニズムのパッセージ リトリーバー コンポーネントとして機能します。 最後に、Amazon Lex を使用してフロントエンドを強化し、エンドユーザーにシームレスでレスポンシブなエクスペリエンスを提供します。 近い将来、このソリューションをオープンソース プロジェクトとして利用できるようにする予定です。
例
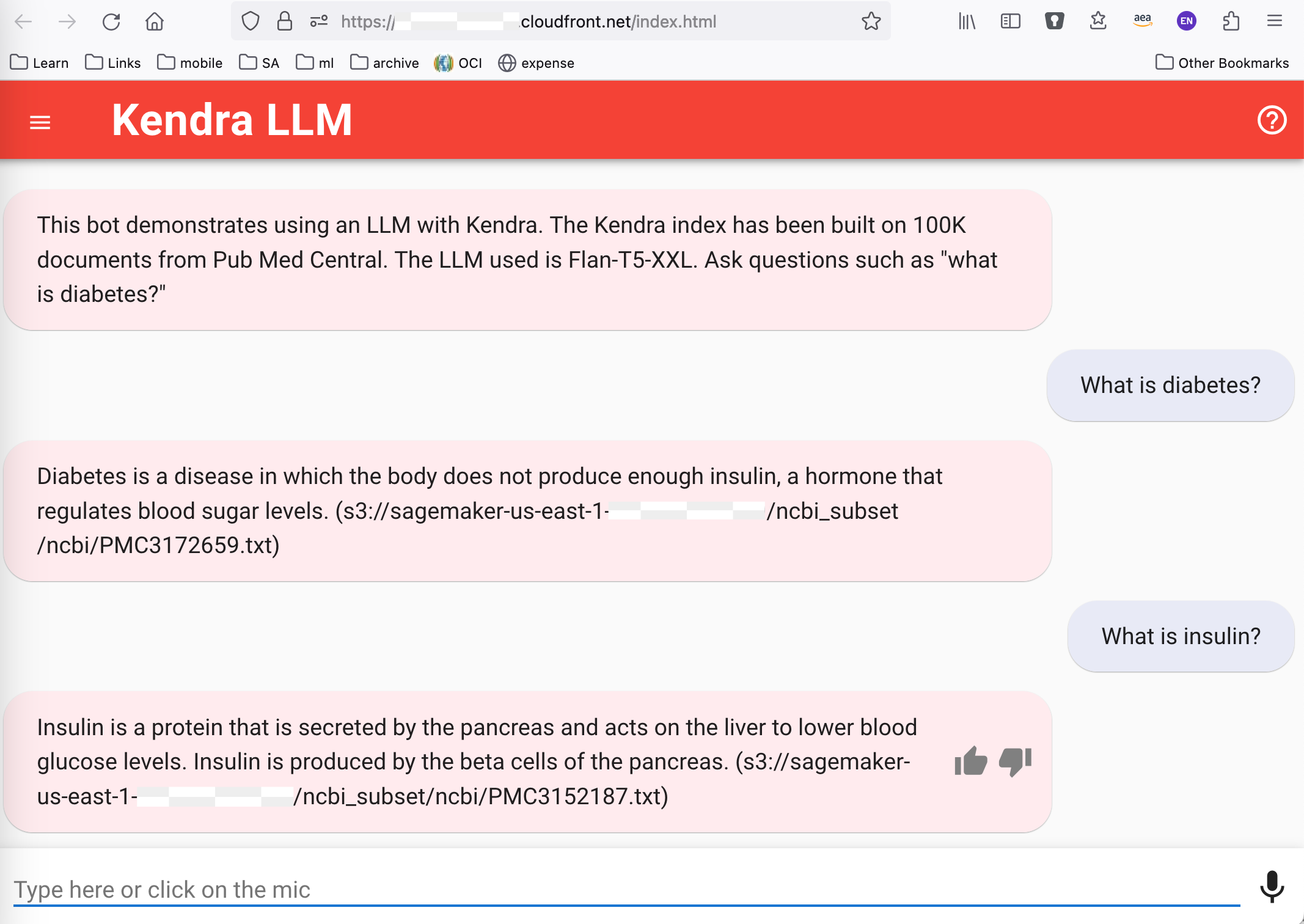
次のスクリーンショットは、次の Web サイトで利用可能なテンプレートを使用してソリューション用に構築された Web UI からのものです。 GitHubの. ピンクのテキストは Amazon Kendra LLM システムからの応答で、青のテキストはユーザーの質問です。
アーキテクチャの概要
このソリューションのアーキテクチャとソリューション ワークフローは、ユース ケース 1 と似ています。
クリーンアップ
コストを節約するには、チュートリアルの一部としてデプロイしたすべてのリソースを削除します。 CloudFormation スタックを起動した場合は、AWS CloudFormation コンソールから削除できます。 同様に、SageMaker コンソールを介して作成した SageMaker エンドポイントを削除できます。
まとめ
大規模な言語モデルを利用したジェネレーティブ AI は、人々が情報から洞察を取得して適用する方法を変えています。 ただし、エンタープライズ ユース ケースでは、検索拡張生成アプローチを使用して、答えをドメイン内に保持し、幻覚を軽減するために、エンタープライズ コンテンツに基づいて洞察を生成する必要があります。 RAG アプローチでは、LLM によって生成される洞察の質は、取得された情報の基になるセマンティック関連性に依存するため、Amazon Kendra などのソリューションを使用して高精度のセマンティック検索結果を提供する必要性がますます高まっています。ボックス。 データ ソース コネクタの包括的なエコシステム、一般的なファイル形式のサポート、およびセキュリティにより、Amazon Kendra を検索メカニズムとして使用するエンタープライズ ユースケース向けのジェネレーティブ AI ソリューションの使用をすぐに開始できます。
AWS で Generative AI を使用する方法の詳細については、次を参照してください。 AWS でジェネレーティブ AI を使用して構築するための新しいツールを発表. このブログで説明されている方法を使用して、エンタープライズ GenAI アプリの RAG の概念実証 (POC) の実験と構築を開始できます。 前述したように、一度 アマゾンの岩盤 が利用可能になったら、Amazon Bedrock を使用して RAG を構築する方法を示すフォローアップ ブログを公開します。
著者について
 アビナブ・ジャワデカール は、AWSのAI/ML言語サービスチームでAmazonKendraに焦点を当てたプリンシパルソリューションアーキテクトです。 Abhinavは、AWSのお客様やパートナーと協力して、AWSでインテリジェントな検索ソリューションを構築できるよう支援します。
アビナブ・ジャワデカール は、AWSのAI/ML言語サービスチームでAmazonKendraに焦点を当てたプリンシパルソリューションアーキテクトです。 Abhinavは、AWSのお客様やパートナーと協力して、AWSでインテリジェントな検索ソリューションを構築できるよう支援します。
 ジャンピエールドーデル Amazon Kendra のプリンシパル プロダクト マネージャーであり、主要な戦略的製品機能とロードマップの優先順位付けを主導しています。 彼は、7 年前に Amazon に入社する前は Autonomy、HP、および検索スタートアップで主導的な役割を果たし、Enterprise Search と ML/AI の豊富な経験をチームにもたらしました。
ジャンピエールドーデル Amazon Kendra のプリンシパル プロダクト マネージャーであり、主要な戦略的製品機能とロードマップの優先順位付けを主導しています。 彼は、7 年前に Amazon に入社する前は Autonomy、HP、および検索スタートアップで主導的な役割を果たし、Enterprise Search と ML/AI の豊富な経験をチームにもたらしました。
 ミシル・シャー AWS の ML/AI スペシャリストです。 現在、AWS で機械学習ソリューションを構築することにより、公共部門の顧客が市民の生活を改善するのを支援しています。
ミシル・シャー AWS の ML/AI スペシャリストです。 現在、AWS で機械学習ソリューションを構築することにより、公共部門の顧客が市民の生活を改善するのを支援しています。
 フィラズ・アクマル AWS の Amazon Kendra のシニアプロダクトマネージャーです。 彼はカスタマー アドボケイトであり、Kendra on AWS を使用した検索および生成 AI のユースケースをお客様が理解できるように支援しています。 仕事以外では、フィラズは PNW の山で過ごすことや、娘の視点を通して世界を体験することを楽しんでいます。
フィラズ・アクマル AWS の Amazon Kendra のシニアプロダクトマネージャーです。 彼はカスタマー アドボケイトであり、Kendra on AWS を使用した検索および生成 AI のユースケースをお客様が理解できるように支援しています。 仕事以外では、フィラズは PNW の山で過ごすことや、娘の視点を通して世界を体験することを楽しんでいます。
 アビシェーク・マリゲハリ・シヴァリンガイア AWS のシニア AI サービス ソリューション アーキテクトであり、Amazon Kendra に重点を置いています。 Amazon Kendra、Generative AI、NLP を使用したアプリケーションの構築に情熱を注いでいます。 彼は、顧客と企業に価値を生み出すためのデータと AI ソリューションの構築に約 10 年の経験があります。 彼は、彼のキャリアとプロの旅についての質問に答えるために、楽しみのために (個人的な) チャットボットを作成しました。 仕事以外では、家族や友人の肖像画を作ることを楽しんでおり、作品を作ることも大好きです。
アビシェーク・マリゲハリ・シヴァリンガイア AWS のシニア AI サービス ソリューション アーキテクトであり、Amazon Kendra に重点を置いています。 Amazon Kendra、Generative AI、NLP を使用したアプリケーションの構築に情熱を注いでいます。 彼は、顧客と企業に価値を生み出すためのデータと AI ソリューションの構築に約 10 年の経験があります。 彼は、彼のキャリアとプロの旅についての質問に答えるために、楽しみのために (個人的な) チャットボットを作成しました。 仕事以外では、家族や友人の肖像画を作ることを楽しんでおり、作品を作ることも大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/quickly-build-high-accuracy-generative-ai-applications-on-enterprise-data-using-amazon-kendra-langchain-and-large-language-models/

