1月の2024では、 アマゾンセージメーカー 新しいバージョンを立ち上げました (0.26.0) 大規模モデル推論 (LMI) 深層学習コンテナ (DLC) の。このバージョンでは、新しいモデル (専門家の混合を含む) のサポート、推論バックエンド全体のパフォーマンスと使いやすさの向上、および制御と予測の説明可能性を高めるための新世代の詳細 (生成完了の理由やトークン レベルのログ確率など) が提供されます。
LMI DLC は、最先端の推論最適化技術とハードウェアの使用を簡素化するローコード インターフェイスを提供します。 LMI を使用すると、テンソル並列処理を適用できます。最新の効率的なアテンション、バッチ処理、量子化、メモリ管理技術。トークンストリーミング。モデル ID とオプションのモデル パラメーターを要求するだけで、さらに多くのことが可能になります。 SageMaker の LMI DLC を使用すると、価値実現までの時間を短縮できます。 生成人工知能 (AI) アプリケーション、インフラストラクチャ関連の重労働をオフロードし、選択したハードウェアに合わせて大規模言語モデル (LLM) を最適化して、クラス最高の価格パフォーマンスを実現します。
この投稿では、このリリースで導入された最新機能を調査し、パフォーマンス ベンチマークを調査し、LMI DLC を備えた新しい LLM を高いパフォーマンスで導入するための詳細なガイドを提供します。
LMI DLC による新機能
このセクションでは、LMI バックエンド全体の新機能について説明し、バックエンド固有のその他の機能について詳しく説明します。 LMI は現在、次のバックエンドをサポートしています。
- LMI 分散ライブラリ – これは、OSS からインスピレーションを得て、LLM で推論を実行し、可能な限り最高のレイテンシーと結果の精度を実現する AWS フレームワークです。
- LMI vLLM – これは、メモリ効率の高い AWS バックエンドの実装です。 vLLM 推論ライブラリ
- LMI TensorRT-LLM ツールキット – これは AWS バックエンドの実装です NVIDIA TensorRT-LLM、GPU 固有のエンジンを作成して、さまざまな GPU のパフォーマンスを最適化します。
- LMIディープスピード – これは AWS への適応です ディープスピードこれにより、真の連続バッチ処理、SmoothQuant 量子化、推論中にメモリを動的に調整する機能が追加されます。
- LMIニューロンX – これをデプロイメントに使用できます。 AWS インフェレンシア 2 および AWS トレーニング-ベースのインスタンス。真の連続バッチ処理と高速化を特徴とし、 AWS ニューロン SDK
次の表は、新しく追加された共通機能とバックエンド固有の機能をまとめたものです。
|
バックエンド間で共通 |
|||
|
|||
|
バックエンド固有 |
|||
|
LMI 分散型 |
vLLM | TensorRT-LLM |
ニューロンX |
|
|
|
|
新しいモデルをサポート
Mistral-7B (すべてのバックエンド)、MoE ベースの Mixtral (Transformers-NeuronX を除くすべてのバックエンド)、Llama2-70B (Transformers-NeuronX) など、新しい人気モデルがバックエンド全体でサポートされています。
コンテキストウィンドウ拡張技術
Rotary Positional Embedding (RoPE) ベースのコンテキスト スケーリングが、LMI-Dist、vLLM、および TensorRT-LLM バックエンドで利用できるようになりました。 RoPE スケーリングを使用すると、微調整を必要とせずに、推論中にモデルのシーケンス長を事実上あらゆるサイズに拡張できます。
RoPE を使用する際の重要な考慮事項は次の 2 つです。
- モデルの複雑さ – シーケンスの長さが増加するにつれて、 そうすることができます モデルの 困惑。この影響は、元のトレーニングで使用されたものよりも大きな入力シーケンスに対して最小限の微調整を行うことで部分的に相殺できます。 RoPE がモデルの品質にどのような影響を与えるかを詳しく理解するには、以下を参照してください。 RoPEの拡張.
- 推論パフォーマンス – シーケンスの長さが長くなると、上位アクセラレータの高帯域幅メモリ (HBM) が消費されます。このメモリ使用量の増加は、アクセラレータが処理できる同時リクエストの数に悪影響を与える可能性があります。
世代の詳細を追加
生成結果に関する 2 つの詳細な詳細を取得できるようになりました。
- 終了理由 – これにより、生成が完了する理由がわかります。これには、最大世代長に達したこと、文の終わり(EOS)トークンが生成されたこと、またはユーザー定義の停止トークンが生成されたことが考えられます。これは、最後にストリーミングされたシーケンス チャンクとともに返されます。
- ログプロブス – これは、ストリーミングされたシーケンス チャンク内の各トークンに対してモデルによって割り当てられた対数確率を返します。シーケンスの結合確率を次の値の合計として計算することで、これらをモデルの信頼性のおおよその推定値として使用できます。
log_probs個々のトークンの情報。これは、モデル出力のスコアリングとランク付けに役立ちます。一般に、LLM トークンの確率は調整なしでは過信されることに注意してください。
他のすべてのパラメーターを変更せずに、入力ペイロードにdetails=TrueをLMIに追加することで、生成結果の出力を有効にできます。
payload = {“inputs”:“your prompt”,
“parameters”:{max_new_tokens”:256,...,“details”:True}
}統合された構成パラメータ
最後に、LMI 構成パラメータも統合されました。すべての共通およびバックエンド固有の展開構成パラメーターの詳細については、次を参照してください。 大規模なモデル推論構成.
LMI 分散バックエンド
AWS re:Invent 2023 では、LMI-Dist に新しい最適化された集合オペレーションが追加され、GPU 間の通信が高速化され、その結果、単一の GPU には大きすぎるモデルのレイテンシーが短縮され、スループットが向上しました。これらのコレクティブは、p4d インスタンスの SageMaker のみで利用できます。
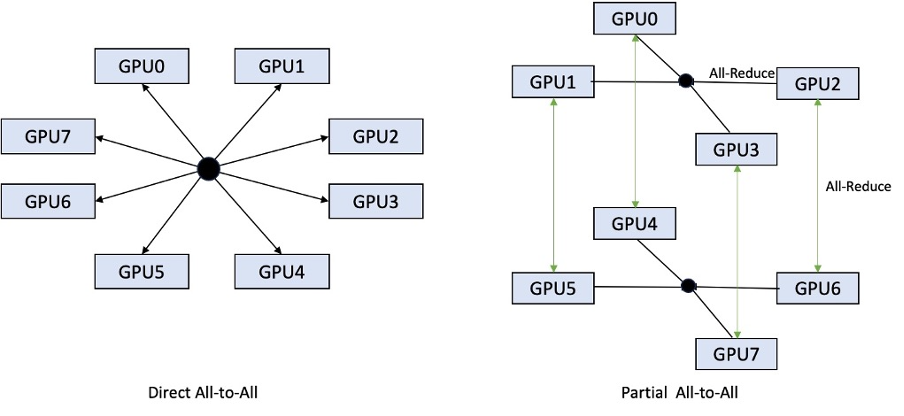
以前のイテレーションでは 8 GPU すべてにわたるシャーディングのみがサポートされていましたが、LMI 0.26.0 では、部分的な全対全パターンで、テンソル並列次数 4 のサポートが導入されました。これと組み合わせることができます SageMaker 推論コンポーネントを使用すると、エンドポイントの背後にデプロイされた各モデルに割り当てるアクセラレータの数を詳細に構成できます。これらの機能を組み合わせることで、基盤となるインスタンスのリソース使用率をより適切に制御できるようになり、1 つのエンドポイントの背後でさまざまなモデルをホストすることでモデルのマルチテナント性を高めたり、モデルとトラフィックの特性に合わせてデプロイメントの総スループットを微調整したりすることができます。
次の図は、直接全対全と部分全対全を比較しています。
TensorRT-LLM バックエンド
NVIDIA の TensorRT-LLM は、以前の LMI DLC リリース (0.25.0) の一部として導入され、最先端の GPU パフォーマンスと、NVIDIA GPU 使用時の SmoothQuant、FP8、LLM の連続バッチ処理などの最適化を可能にします。
TensorRT-LLM では、デプロイメント前にモデルを効率的なエンジンにコンパイルする必要があります。 LMI TensorRT-LLM DLC は、サーバーを起動してリアルタイム推論用のモデルをロードする前に、サポートされているモデルのリストをジャストインタイム (JIT) でコンパイルする処理を自動的に処理できます。 DLC のバージョン 0.26.0 では、JIT コンパイルでサポートされるモデルのリストが増え、Baichuan、ChatGLM、GPT2、GPT-J、InternLM、Mistral、Mixtral、Qwen、SantaCoder、StarCoder モデルが導入されました。
JIT コンパイルでは、エンドポイントのプロビジョニングとスケーリング時間に数分のオーバーヘッドが追加されるため、事前にモデルをコンパイルすることを常にお勧めします。これを行う方法のガイドとサポートされているモデルのリストについては、を参照してください。 TensorRT-LLM モデルの事前コンパイル チュートリアル。選択したモデルがまだサポートされていない場合は、を参照してください。 TensorRT-LLM モデルの手動コンパイル チュートリアル TensorRT-LLM でサポートされている他のモデルをコンパイルします。
さらに、LMI は、トークンまたはチャネルごとにアルファとスケーリング係数を制御するパラメーターを備えたネイティブ TensorRT-LLM SmootQuant 量子化を公開するようになりました。関連する構成の詳細については、を参照してください。 TensorRT-LLM.
vLLM バックエンド
LMI DLC に含まれる vLLM の更新リリースでは、Eager モードではなく CUDA グラフ モードによってパフォーマンスが最大 50% 向上しました。 CUDA グラフは、複数の GPU 操作を個別に起動するのではなく、一度に起動することで GPU ワークロードを高速化し、オーバーヘッドを削減します。これは、テンソル並列処理を使用する場合、小さなモデルで特に効果的です。
パフォーマンスの向上は、GPU メモリ消費量の増加と引き換えに行われます。 CUDA グラフ モードは vLLM バックエンドのデフォルトになっているため、利用可能な GPU メモリの量に制限がある場合は、次のように設定できます。 option.enforce_eager=True PyTorch 熱心モードを強制します。
Transformers-NeuronX バックエンド
の更新リリース ニューロンX LMI NeuronX DLC に含まれる は、Mistral-7B や LLama2-70B など、グループ化されたクエリ アテンション メカニズムを備えたモデルをサポートするようになりました。グループ化されたクエリ アテンションは、デフォルトのトランスフォーマー アテンション メカニズムの重要な最適化であり、クエリ ヘッドよりも少ないキー ヘッドとバリュー ヘッドでモデルがトレーニングされます。これにより、GPU メモリ上の KV キャッシュのサイズが削減され、同時実行性が向上し、価格パフォーマンスが向上します。
次の図は、マルチヘッド、グループ化クエリ、およびマルチクエリ アテンション メソッドを示しています (source).
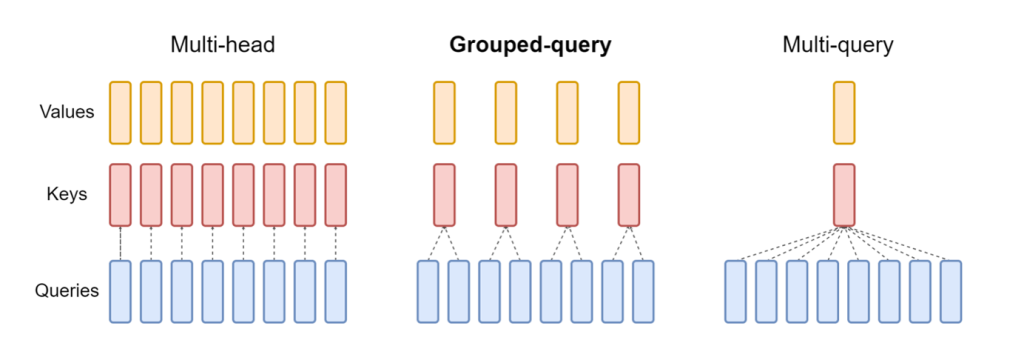
さまざまな種類のワークロードに合わせて、さまざまな KV キャッシュ シャーディング戦略を利用できます。シャーディング戦略の詳細については、次を参照してください。 グループ化されたクエリ アテンション (GQA) のサポート。希望の戦略を有効にすることができます (shard-over-heads、たとえば)次のコードを使用します。
さらに、NeuronX DLC の新しい実装では、KV キャッシュへのアクセスを可能にする TransformerNeuronX 用のキャッシュ API が導入されています。これにより、バッチ推論を処理しながら、新しいリクエストから KV キャッシュ行を挿入および削除できます。この API を導入する前に、新しく追加されたリクエストに対して KV キャッシュが再計算されました。 LMI V7 (0.25.0) と比較して、同時リクエストのレイテンシーが 33% 以上改善され、はるかに高いスループットをサポートします。
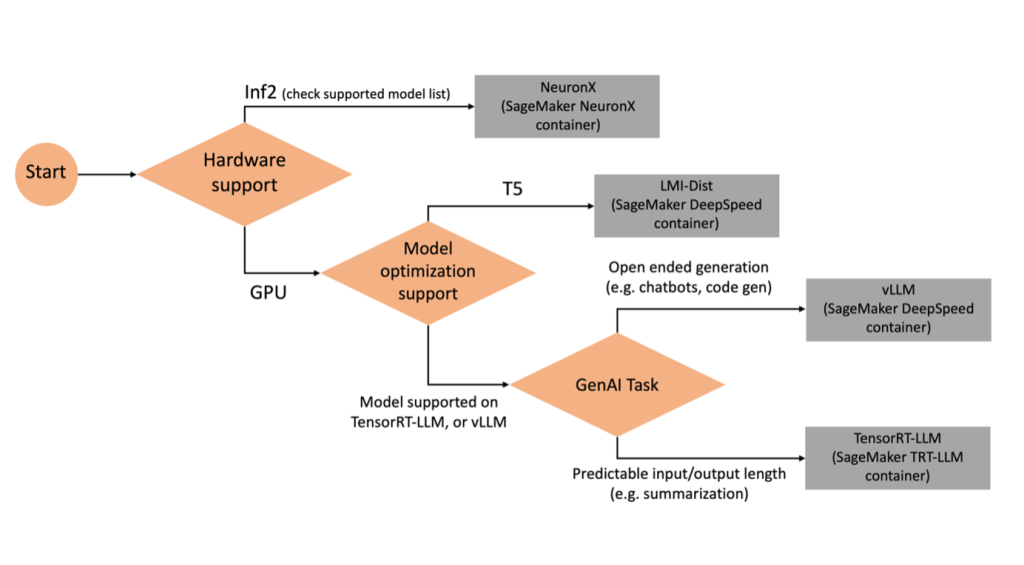
適切なバックエンドの選択
選択したモデルとタスクに基づいてどのバックエンドを使用するかを決定するには、次のフローチャートを使用します。サポートされているモデルとともに個々のバックエンド ユーザー ガイドについては、を参照してください。 LMI バックエンド ユーザー ガイド.
追加の属性を備えた LMI DLC を使用して Mixtral を導入する
LMI 8 コンテナーを使用して Mixtral-7x0.26.0B モデルをデプロイし、次のような追加の詳細を生成する方法を見てみましょう。 log_prob および finish_reason 出力の一部として。また、コンテンツ生成のユースケースを通じて、これらの追加属性からどのようにメリットを得ることができるかについても説明します。
詳細な手順が記載された完全なノートブックは、次の場所で入手できます。 GitHubレポ.
まず、ライブラリをインポートし、セッション環境を構成します。
SageMaker LMI コンテナを使用すると、追加の推論コードなしでモデルをホストできます。モデル サーバーは、環境変数または serving.properties ファイル。オプションで、 model.py 前処理または後処理用のファイルと requirements.txt インストールする必要がある追加パッケージのファイル。
この場合、使用するのは、 serving.properties ファイルを使用してパラメータを構成し、LMI コンテナの動作をカスタマイズします。詳細については、を参照してください。 GitHubレポ。このリポジトリでは、設定できるさまざまな構成パラメーターの詳細が説明されています。次の主要なパラメータが必要です。
- エンジン – DJL が使用するランタイム エンジンを指定します。これにより、モデルのアクセラレータでシャーディングとモデル読み込み戦略が推進されます。
- オプション.モデルID – を指定します Amazon シンプル ストレージ サービス (Amazon S3) 事前トレーニングされたモデルの URI、またはモデル リポジトリ内でホストされている事前トレーニングされたモデルのモデル ID ハグ顔。この場合、Mixtral-8x7B モデルのモデル ID を提供します。
- オプション.tensor_Parallel_degree – Accelerate がモデルを分割する必要がある GPU デバイスの数を設定します。このパラメーターは、DJL サービングの実行時に起動されるモデルごとのワーカーの数も制御します。この値を次のように設定します。
max(現在のマシンの最大 GPU)。 - オプション.ローリングバッチ – 連続バッチ処理を有効にして、アクセラレータの使用率と全体的なスループットを最適化します。 TensorRT-LLM コンテナの場合、次を使用します。
auto. - option.model_loading_timeout – 推論を提供するモデルのダウンロードとロードのタイムアウト値を設定します。
- option.max_rolling_batch – 連続バッチの最大サイズを設定し、同時に並行して処理できるシーケンスの数を定義します。
梱包いたします serving.properties 設定ファイルは tar.gz 形式で保存され、SageMaker ホスティング要件を満たすようになります。 DJL LMI コンテナを次のように構成します。 tensorrtllm バックエンドエンジンとして。さらに、コンテナの最新バージョン (0.26.0) を指定します。
次に、ローカルの tarball ( serving.properties 設定ファイル) を S3 プレフィックスに追加します。 DJL コンテナのイメージ URI と、アーティファクトを提供するモデルの tarball がアップロードされた Amazon S3 の場所を使用して、SageMaker モデル オブジェクトを作成します。
LMI 0.26.0 の一部として、生成された出力に関する XNUMX つの追加の詳細を使用できるようになりました。
- ログプロブス – これは、ストリーミングされたシーケンス チャンク内の各トークンに対してモデルによって割り当てられた対数確率です。シーケンスの同時確率を個々のトークンの対数確率の合計として計算することで、これらをモデルの信頼性の概算として使用でき、モデル出力のスコアリングとランク付けに役立ちます。一般に、LLM トークンの確率は調整なしでは過信されることに注意してください。
- 終了理由 – これが生成完了の理由です。最大生成長に達した場合、EOS トークンが生成された場合、またはユーザー定義の停止トークンが生成された場合が考えられます。これは、最後にストリーミングされたシーケンス チャンクとともに返されます。
これらを有効にするには、次のように渡します。 "details"=True モデルへの入力の一部として。
これらの詳細を生成する方法を見てみましょう。アプリケーションを理解するために、コンテンツ生成の例を使用します。
を定義します。 LineIterator ヘルパー クラスには、応答ストリームからバイトを遅延フェッチし、バッファリングし、バッファーを行に分割する関数があります。このアイデアは、ストリームから非同期でさらに多くのバイトをフェッチしながら、バッファからバイトを提供することです。
追加の詳細としてトークンの確率を生成して使用します
コンテンツを生成するユースケースを考えてみましょう。具体的には、ライフスタイルに焦点を当てた Web サイト向けに、定期的に運動することの利点についての短い文章を書くという使命があります。コンテンツを生成し、生成されたコンテンツにおいてモデルが持つ信頼性を示す何らかの指標スコアを出力したいと考えています。
プロンプトでモデルのエンドポイントを呼び出し、生成された応答をキャプチャします。設定しました "details": True モデルへの入力内のランタイム パラメーターとして。ログ確率は出力トークンごとに生成されるため、個々のログ確率をリストに追加します。また、応答から生成された完全なテキストもキャプチャします。
全体的な信頼スコアを計算するには、すべての個々のトークンの確率の平均を計算し、その後 0 と 1 の間の指数値を取得します。これは、生成されたテキストの推定された全体的な信頼スコアであり、この場合はメリットに関する段落です。定期的な運動のこと。

これは、生成および使用方法の一例でした。 log_prob、コンテンツ生成のユースケースのコンテキストで。同様に、次のように使用できます log_prob 分類ユースケースの信頼スコアの尺度として。
あるいは、出力シーケンス全体または文レベルのスコアリングに使用して、生成された出力に対する温度などのパラメーターの影響を評価することもできます。
追加の詳細として終了理由を生成して使用します
同じユースケースに基づいて構築してみましょう。ただし、今回はより長い記事を書くという使命があります。さらに、生成長の問題 (最大トークン長) や停止トークンの発生によって出力が切り捨てられないようにしたいと考えています。
これを実現するには、 finish_reason 出力で生成された属性を確認し、その値を監視し、出力全体が生成されるまで生成を続けます。
ペイロード入力を受け取り、SageMaker エンドポイントを呼び出し、応答をストリームバックし、生成されたテキストを抽出するために応答を処理する推論関数を定義します。ペイロードには、入力としてプロンプト テキストと、最大トークンや詳細などのパラメーターが含まれます。応答はストリームで読み取られ、1 行ずつ処理されて、生成されたテキスト トークンがリストに抽出されます。次のような詳細を抽出します finish_reason。毎回コンテキストを追加しながらループ (連鎖リクエスト) で推論関数を呼び出し、モデルが終了するまで生成されたトークンの数と送信されたリクエストの数を追跡します。
ご覧のとおり、たとえ max_new_token パラメーターが 256 に設定されている場合、出力の一部としてfinish_reason 詳細属性を使用して、出力全体が生成されるまで複数のリクエストをエンドポイントにチェーンします。

同様に、ユースケースに基づいて、次のように使用できます。 stop_reason 特定のタスクに指定された出力シーケンスの長さが不十分であること、または人間による停止シーケンスによる意図しない完了を検出するため。
まとめ
この投稿では、AWS LMI コンテナの v0.26.0 リリースについて説明しました。重要なパフォーマンスの向上、新しいモデルのサポート、新しい使いやすさの機能を強調しました。これらの機能を使用すると、エンドユーザーにより良いエクスペリエンスを提供しながら、コストとパフォーマンス特性のバランスをより適切に取ることができます。
LMI DLC 機能の詳細については、次を参照してください。 モデルの並列処理と大規模なモデルの推論。 SageMaker のこれらの新機能をどのように使用するか楽しみにしています。
著者について
 ジョアンモウラ AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。 João は、小規模なスタートアップ企業から大企業まで、AWS の顧客が大規模なモデルを効率的にトレーニングしてデプロイし、より広範に AWS 上で ML プラットフォームを構築できるよう支援しています。
ジョアンモウラ AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。 João は、小規模なスタートアップ企業から大企業まで、AWS の顧客が大規模なモデルを効率的にトレーニングしてデプロイし、より広範に AWS 上で ML プラットフォームを構築できるよう支援しています。
 ラーフル・シャルマ AWS のシニア ソリューション アーキテクトとして、AWS の顧客による AI/ML ソリューションの設計と構築を支援しています。 AWS に入社する前は、ラーフルは金融および保険部門で数年間勤務し、顧客のデータおよび分析プラットフォームの構築を支援してきました。
ラーフル・シャルマ AWS のシニア ソリューション アーキテクトとして、AWS の顧客による AI/ML ソリューションの設計と構築を支援しています。 AWS に入社する前は、ラーフルは金融および保険部門で数年間勤務し、顧客のデータおよび分析プラットフォームの構築を支援してきました。
 青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
 ジャン・シェン はアマゾン ウェブ サービスのソフトウェア開発エンジニアであり、機械学習システムのいくつかの重要な側面に取り組んできました。 彼は SageMaker Neo サービスの主要な貢献者であり、深層学習のコンパイルとフレームワークのランタイム最適化に重点を置いています。 最近では、大規模モデル推論のための機械学習システムの最適化に尽力し、貢献しています。
ジャン・シェン はアマゾン ウェブ サービスのソフトウェア開発エンジニアであり、機械学習システムのいくつかの重要な側面に取り組んできました。 彼は SageMaker Neo サービスの主要な貢献者であり、深層学習のコンパイルとフレームワークのランタイム最適化に重点を置いています。 最近では、大規模モデル推論のための機械学習システムの最適化に尽力し、貢献しています。
 タイラー・オスターバーグ AWS のソフトウェア開発エンジニアです。彼は、SageMaker 内で高性能の機械学習推論エクスペリエンスを作成することを専門としています。最近は、SageMaker プラットフォーム上の Inferentia Deep Learning Containers のパフォーマンスの最適化に重点を置いています。タイラーは、大規模な言語モデル向けのパフォーマンスの高いホスティング ソリューションの実装と、最先端のテクノロジーを使用したユーザー エクスペリエンスの向上に優れています。
タイラー・オスターバーグ AWS のソフトウェア開発エンジニアです。彼は、SageMaker 内で高性能の機械学習推論エクスペリエンスを作成することを専門としています。最近は、SageMaker プラットフォーム上の Inferentia Deep Learning Containers のパフォーマンスの最適化に重点を置いています。タイラーは、大規模な言語モデル向けのパフォーマンスの高いホスティング ソリューションの実装と、最先端のテクノロジーを使用したユーザー エクスペリエンスの向上に優れています。
 ルピンダー・グレワル AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。彼は現在、Amazon SageMaker でのモデルと MLOps の提供に重点を置いています。この役職に就く前は、モデルの構築とホスティングを行う機械学習エンジニアとして働いていました。仕事以外では、テニスや山道でのサイクリングを楽しんでいます。
ルピンダー・グレワル AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。彼は現在、Amazon SageMaker でのモデルと MLOps の提供に重点を置いています。この役職に就く前は、モデルの構築とホスティングを行う機械学習エンジニアとして働いていました。仕事以外では、テニスや山道でのサイクリングを楽しんでいます。
 ダワル・パテル AWSのプリンシパル機械学習アーキテクトです。 彼は、分散コンピューティングや人工知能に関連する問題について、大企業から中規模の新興企業に至るまでの組織と協力してきました。 彼は、NLPおよびコンピュータービジョンドメインを含むディープラーニングに焦点を当てています。 彼は、顧客がSageMakerで高性能モデルの推論を実現するのを支援します。
ダワル・パテル AWSのプリンシパル機械学習アーキテクトです。 彼は、分散コンピューティングや人工知能に関連する問題について、大企業から中規模の新興企業に至るまでの組織と協力してきました。 彼は、NLPおよびコンピュータービジョンドメインを含むディープラーニングに焦点を当てています。 彼は、顧客がSageMakerで高性能モデルの推論を実現するのを支援します。
 ラグーラメシャ Amazon SageMaker サービスチームのシニア ML ソリューションアーキテクトです。 彼は、顧客が ML 本番ワークロードを大規模に構築、デプロイ、SageMaker に移行できるよう支援することに重点を置いています。 彼は機械学習、AI、コンピューター ビジョンの分野を専門とし、テキサス大学ダラス校でコンピューター サイエンスの修士号を取得しています。 自由時間には、旅行や写真撮影を楽しんでいます。
ラグーラメシャ Amazon SageMaker サービスチームのシニア ML ソリューションアーキテクトです。 彼は、顧客が ML 本番ワークロードを大規模に構築、デプロイ、SageMaker に移行できるよう支援することに重点を置いています。 彼は機械学習、AI、コンピューター ビジョンの分野を専門とし、テキサス大学ダラス校でコンピューター サイエンスの修士号を取得しています。 自由時間には、旅行や写真撮影を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-mixtral-and-llama-2-models-with-new-amazon-sagemaker-containers/

