जेनरेटिव एआई के आगमन के साथ, आज के फाउंडेशन मॉडल (एफएम), जैसे कि बड़े भाषा मॉडल (एलएलएम) क्लाउड 2 और लामा 2, टेक्स्ट डेटा पर प्रश्न उत्तर, सारांश और सामग्री निर्माण जैसे कई जेनरेटर कार्य कर सकते हैं। हालाँकि, वास्तविक दुनिया का डेटा कई तौर-तरीकों में मौजूद है, जैसे पाठ, चित्र, वीडियो और ऑडियो। उदाहरण के लिए, पावरपॉइंट स्लाइड डेक लें। इसमें पाठ के रूप में जानकारी हो सकती है, या ग्राफ़, तालिकाओं और चित्रों में एम्बेडेड हो सकती है।
इस पोस्ट में, हम एक समाधान प्रस्तुत करते हैं जो मल्टीमॉडल एफएम का उपयोग करता है जैसे कि अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल और एलएलएवीए 1.5 और AWS सेवाएँ शामिल हैं अमेज़ॅन बेडरॉक और अमेज़न SageMaker मल्टीमॉडल डेटा पर समान जेनरेटर कार्य करने के लिए।
समाधान अवलोकन
समाधान स्लाइड डेक के पाठ और दृश्य तत्वों में निहित जानकारी का उपयोग करके प्रश्नों के उत्तर देने के लिए एक कार्यान्वयन प्रदान करता है। डिज़ाइन रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) की अवधारणा पर निर्भर करता है। परंपरागत रूप से, आरएजी पाठ्य डेटा से जुड़ा हुआ है जिसे एलएलएम द्वारा संसाधित किया जा सकता है। इस पोस्ट में, हम छवियों को भी शामिल करने के लिए RAG का विस्तार करते हैं। यह पाठ के साथ-साथ तालिकाओं और ग्राफ़ जैसे दृश्य तत्वों से प्रासंगिक रूप से प्रासंगिक सामग्री निकालने के लिए एक शक्तिशाली खोज क्षमता प्रदान करता है।
RAG समाधान को डिज़ाइन करने के विभिन्न तरीके हैं जिनमें छवियां शामिल हैं। हमने यहां एक दृष्टिकोण प्रस्तुत किया है और इस तीन-भाग श्रृंखला के दूसरे पोस्ट में एक वैकल्पिक दृष्टिकोण का पालन करेंगे।
इस समाधान में निम्नलिखित घटक शामिल हैं:
- अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल - इस एफएम का उपयोग इस पोस्ट में प्रयुक्त स्लाइड डेक में सामग्री के लिए एम्बेडिंग उत्पन्न करने के लिए किया जाता है। मल्टीमॉडल मॉडल के रूप में, यह टाइटन मॉडल टेक्स्ट, छवियों या संयोजन को इनपुट के रूप में संसाधित कर सकता है और एम्बेडिंग उत्पन्न कर सकता है। टाइटन मल्टीमॉडल एंबेडिंग मॉडल 1,024 आयामों के वैक्टर (एंबेडिंग) उत्पन्न करता है और अमेज़ॅन बेडरॉक के माध्यम से एक्सेस किया जाता है।
- बड़े भाषा और दृष्टि सहायक (एलएलएवीए) - एलएलएवीए दृश्य और भाषा समझ के लिए एक खुला स्रोत मल्टीमॉडल मॉडल है और इसका उपयोग स्लाइड में डेटा की व्याख्या करने के लिए किया जाता है, जिसमें ग्राफ़ और टेबल जैसे दृश्य तत्व शामिल हैं। हम 7-बिलियन पैरामीटर संस्करण का उपयोग करते हैं एलएलएवीए 1.5-7बी इस समाधान में.
- अमेज़न SageMaker - LLaVA मॉडल को SageMaker होस्टिंग सेवाओं का उपयोग करके SageMaker एंडपॉइंट पर तैनात किया गया है, और हम LLaVA मॉडल के विरुद्ध अनुमान चलाने के लिए परिणामी एंडपॉइंट का उपयोग करते हैं। हम इस समाधान को शुरू से अंत तक व्यवस्थित करने और प्रदर्शित करने के लिए सेजमेकर नोटबुक का भी उपयोग करते हैं।
- Amazon OpenSearch सर्वर रहित - ओपनसर्च सर्वरलेस एक ऑन-डिमांड सर्वरलेस कॉन्फ़िगरेशन है अमेज़न ओपन सर्च सर्विस. हम टाइटन मल्टीमॉडल एंबेडिंग मॉडल द्वारा उत्पन्न एंबेडिंग को संग्रहीत करने के लिए एक वेक्टर डेटाबेस के रूप में ओपनसर्च सर्वरलेस का उपयोग करते हैं। ओपनसर्च सर्वरलेस संग्रह में बनाया गया एक इंडेक्स हमारे आरएजी समाधान के लिए वेक्टर स्टोर के रूप में कार्य करता है।
- अमेज़ॅन ओपनसर्च अंतर्ग्रहण (ओएसआई) - OSI एक पूरी तरह से प्रबंधित, सर्वर रहित डेटा संग्राहक है जो OpenSearch सेवा डोमेन और OpenSearch सर्वर रहित संग्रहों को डेटा वितरित करता है। इस पोस्ट में, हम OpenSearch सर्वरलेस वेक्टर स्टोर पर डेटा पहुंचाने के लिए OSI पाइपलाइन का उपयोग करते हैं।
समाधान वास्तुकला
समाधान डिज़ाइन में दो भाग होते हैं: अंतर्ग्रहण और उपयोगकर्ता सहभागिता। अंतर्ग्रहण के दौरान, हम प्रत्येक स्लाइड को एक छवि में परिवर्तित करके इनपुट स्लाइड डेक को संसाधित करते हैं, इन छवियों के लिए एम्बेडिंग उत्पन्न करते हैं, और फिर वेक्टर डेटा स्टोर को पॉप्युलेट करते हैं। ये चरण उपयोगकर्ता इंटरैक्शन चरणों से पहले पूरे किए जाते हैं।
उपयोगकर्ता इंटरेक्शन चरण में, उपयोगकर्ता के एक प्रश्न को एम्बेडिंग में बदल दिया जाता है और एक स्लाइड खोजने के लिए वेक्टर डेटाबेस पर एक समानता खोज चलाई जाती है जिसमें संभावित रूप से उपयोगकर्ता के प्रश्न के उत्तर हो सकते हैं। फिर हम यह स्लाइड (एक छवि फ़ाइल के रूप में) एलएलएवीए मॉडल और उपयोगकर्ता प्रश्न को क्वेरी का उत्तर उत्पन्न करने के संकेत के रूप में प्रदान करते हैं। इस पोस्ट के लिए सभी कोड उपलब्ध हैं GitHub रेपो।
निम्नलिखित चित्र अंतर्ग्रहण वास्तुकला को दर्शाता है।

वर्कफ़्लो चरण इस प्रकार हैं:
- स्लाइड्स को JPG प्रारूप में छवि फ़ाइलों (प्रति स्लाइड एक) में परिवर्तित किया जाता है और एम्बेडिंग उत्पन्न करने के लिए टाइटन मल्टीमॉडल एंबेडिंग मॉडल में पास किया जाता है। इस पोस्ट में, हम शीर्षक वाले स्लाइड डेक का उपयोग करते हैं एडब्ल्यूएस ट्रेनियम और एडब्ल्यूएस इनफेरेंटिया का उपयोग करके स्थिर प्रसार को प्रशिक्षित और तैनात करें समाधान प्रदर्शित करने के लिए जून 2023 में टोरंटो में AWS शिखर सम्मेलन से। नमूना डेक में 31 स्लाइड हैं, इसलिए हम वेक्टर एम्बेडिंग के 31 सेट तैयार करते हैं, प्रत्येक 1,024 आयामों के साथ। हम इन जेनरेट किए गए वेक्टर एम्बेडिंग में अतिरिक्त मेटाडेटा फ़ील्ड जोड़ते हैं और एक JSON फ़ाइल बनाते हैं। इन अतिरिक्त मेटाडेटा फ़ील्ड का उपयोग ओपनसर्च की शक्तिशाली खोज क्षमताओं का उपयोग करके समृद्ध खोज क्वेरी करने के लिए किया जा सकता है।
- जेनरेट की गई एम्बेडिंग को एक JSON फ़ाइल में एक साथ रखा जाता है जिसे अपलोड किया जाता है अमेज़न सरल भंडारण सेवा (अमेज़न S3)।
- के माध्यम से अमेज़न एस 3 इवेंट नोटिफिकेशन, एक ईवेंट डाला गया है अमेज़ॅन सरल कतार सेवा (अमेज़न SQS) कतार।
- एसक्यूएस कतार में यह घटना ओएसआई पाइपलाइन को चलाने के लिए एक ट्रिगर के रूप में कार्य करती है, जो बदले में डेटा (जेएसओएन फ़ाइल) को ओपनसर्च सर्वरलेस इंडेक्स में दस्तावेजों के रूप में समाहित करती है। ध्यान दें कि ओपनसर्च सर्वरलेस इंडेक्स को इस पाइपलाइन के लिए सिंक के रूप में कॉन्फ़िगर किया गया है और ओपनसर्च सर्वरलेस संग्रह के हिस्से के रूप में बनाया गया है।
निम्नलिखित चित्र उपयोगकर्ता इंटरैक्शन आर्किटेक्चर को दर्शाता है।
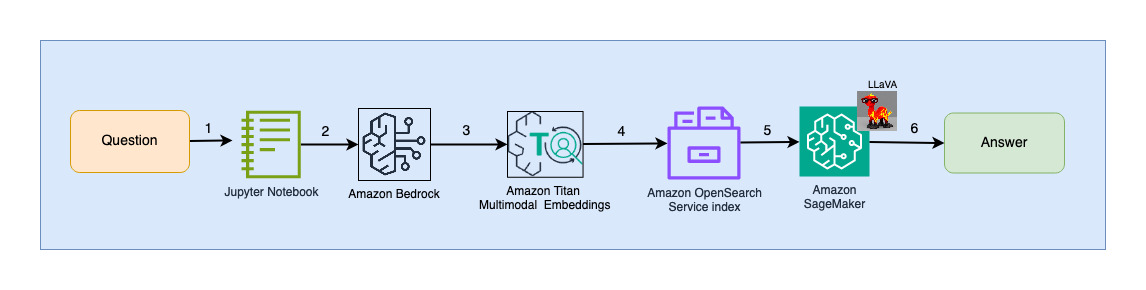
वर्कफ़्लो चरण इस प्रकार हैं:
- एक उपयोगकर्ता अंतर्ग्रहण किए गए स्लाइड डेक से संबंधित एक प्रश्न सबमिट करता है।
- अमेज़ॅन बेडरॉक के माध्यम से एक्सेस किए गए टाइटन मल्टीमॉडल एंबेडिंग मॉडल का उपयोग करके उपयोगकर्ता इनपुट को एम्बेडिंग में परिवर्तित किया जाता है। इन एम्बेडिंग का उपयोग करके एक ओपनसर्च वेक्टर खोज की जाती है। हम उपयोगकर्ता क्वेरी से मेल खाने वाले सबसे प्रासंगिक एम्बेडिंग को पुनः प्राप्त करने के लिए k-निकटतम पड़ोसी (k=1) खोज करते हैं। k=1 सेट करने से उपयोगकर्ता के प्रश्न के लिए सबसे प्रासंगिक स्लाइड पुनः प्राप्त हो जाती है।
- ओपनसर्च सर्वरलेस से प्रतिक्रिया के मेटाडेटा में सबसे प्रासंगिक स्लाइड के अनुरूप छवि का पथ शामिल है।
- उपयोगकर्ता के प्रश्न और छवि पथ को मिलाकर एक प्रॉम्प्ट बनाया जाता है और सेजमेकर पर होस्ट किए गए LLaVA को प्रदान किया जाता है। LLaVA मॉडल उपयोगकर्ता के प्रश्न को समझने और छवि में डेटा की जांच करके उसका उत्तर देने में सक्षम है।
- इस अनुमान का परिणाम उपयोगकर्ता को लौटा दिया जाता है।
इन चरणों पर निम्नलिखित अनुभागों में विस्तार से चर्चा की गई है। देखें परिणाम स्क्रीनशॉट और आउटपुट पर विवरण के लिए अनुभाग।
.. पूर्वापेक्षाएँ
इस पोस्ट में दिए गए समाधान को लागू करने के लिए, आपके पास एक होना चाहिए AWS खाता और एफएम, अमेज़ॅन बेडरॉक, सेजमेकर और ओपनसर्च सेवा से परिचित होना।
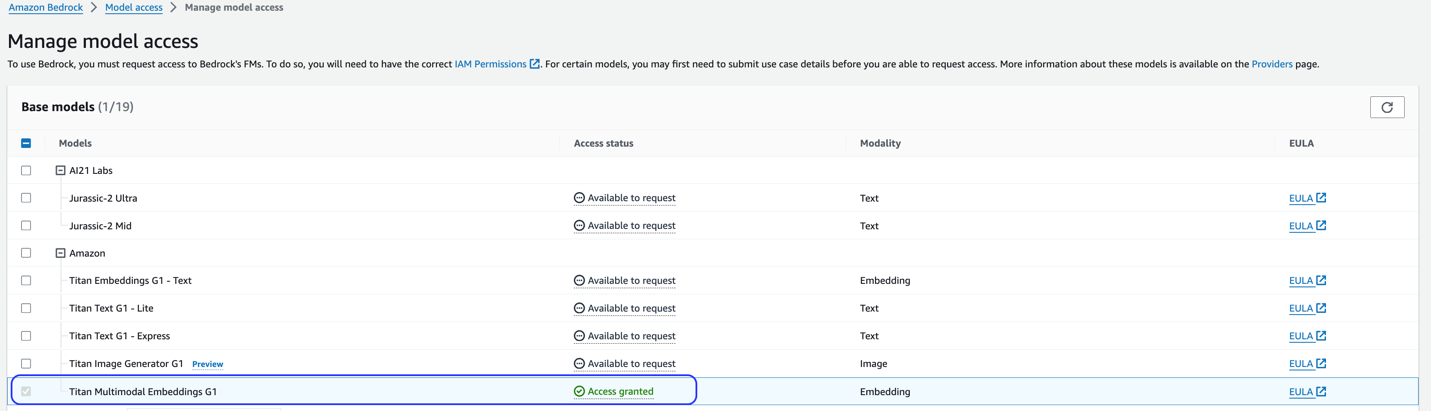
यह समाधान टाइटन मल्टीमॉडल एंबेडिंग मॉडल का उपयोग करता है। सुनिश्चित करें कि यह मॉडल अमेज़ॅन बेडरॉक में उपयोग के लिए सक्षम है। अमेज़ॅन बेडरॉक कंसोल पर, चुनें मॉडल पहुंच नेविगेशन फलक में. यदि टाइटन मल्टीमॉडल एंबेडिंग सक्षम है, तो एक्सेस स्थिति बताई जाएगी प्रवेश करने की अनुमति है.
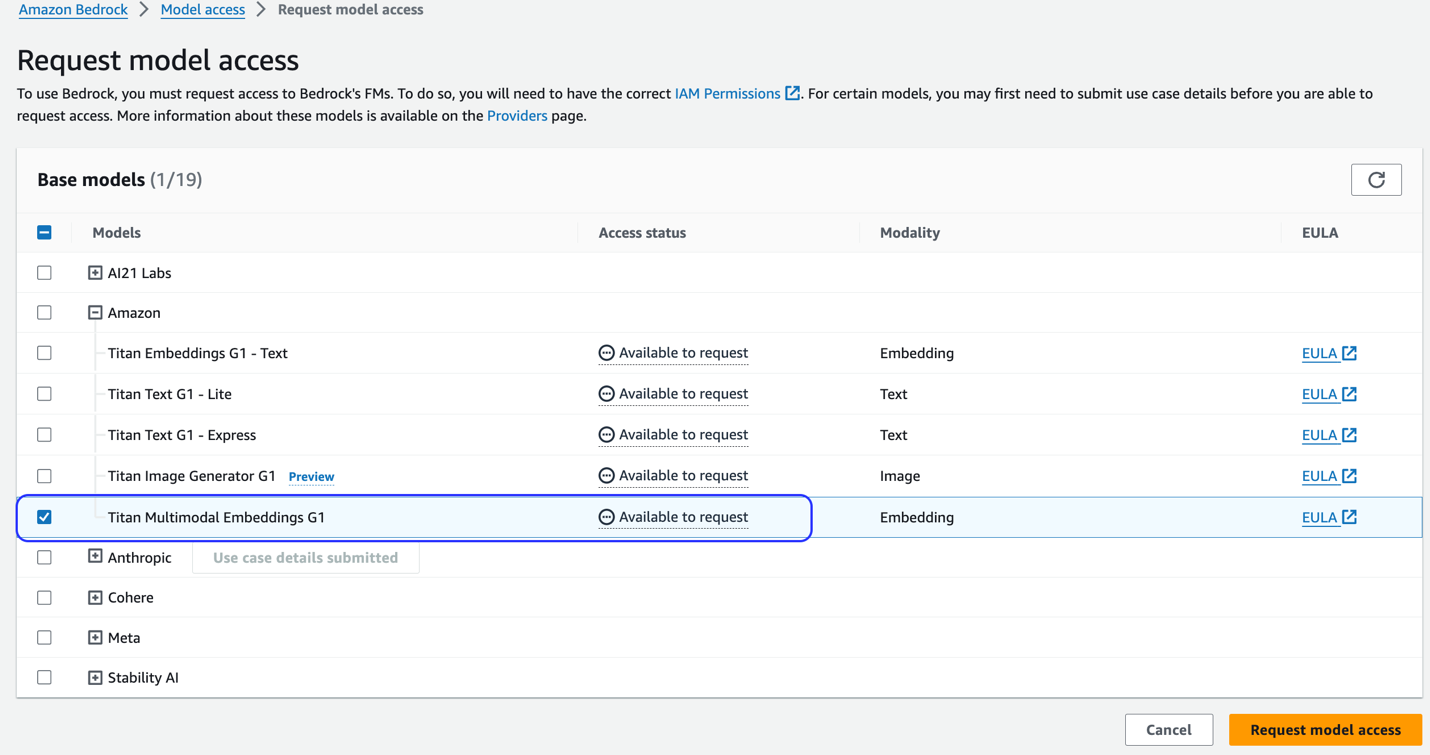
यदि मॉडल उपलब्ध नहीं है, तो चुनकर मॉडल तक पहुंच सक्षम करें मॉडल एक्सेस प्रबंधित करें, चयन करना टाइटन मल्टीमॉडल एंबेडिंग G1, और चुनने मॉडल पहुंच का अनुरोध करें. मॉडल तुरंत उपयोग के लिए सक्षम है.
समाधान स्टैक बनाने के लिए AWS क्लाउडफ़ॉर्मेशन टेम्पलेट का उपयोग करें
निम्नलिखित में से किसी एक का प्रयोग करें एडब्ल्यूएस CloudFormation समाधान संसाधनों को लॉन्च करने के लिए टेम्पलेट (आपके क्षेत्र के आधार पर)।
| AWS क्षेत्र | संपर्क |
|---|---|
us-east-1 |
|
us-west-2 |
स्टैक सफलतापूर्वक बन जाने के बाद, स्टैक पर जाएँ आउटपुट AWS CloudFormation कंसोल पर टैब करें और इसके लिए मान नोट करें MultimodalCollectionEndpoint, जिसका उपयोग हम अगले चरणों में करेंगे।

CloudFormation टेम्पलेट निम्नलिखित संसाधन बनाता है:
- IAM भूमिकाएं - निम्नलिखित AWS पहचान और अभिगम प्रबंधन (IAM) भूमिकाएँ बनाई जाती हैं। लागू करने के लिए इन भूमिकाओं को अपडेट करें न्यूनतम-विशेषाधिकार अनुमतियाँ.
SMExecutionRoleअमेज़ॅन एस3, सेजमेकर, ओपनसर्च सर्विस और बेडरॉक पूर्ण पहुंच के साथ।OSPipelineExecutionRoleविशिष्ट Amazon SQS और OSI क्रियाओं तक पहुंच के साथ।
- सेजमेकर नोटबुक - इस पोस्ट के सभी कोड इस नोटबुक के माध्यम से चलाए जाते हैं।
- OpenSearch सर्वर रहित संग्रह - यह एम्बेडिंग को संग्रहीत करने और पुनर्प्राप्त करने के लिए वेक्टर डेटाबेस है।
- ओएसआई पाइपलाइन - यह ओपनसर्च सर्वरलेस में डेटा अंतर्ग्रहण के लिए पाइपलाइन है।
- S3 बाल्टी - इस पोस्ट का सारा डेटा इस बकेट में संग्रहीत है।
- एसक्यूएस कतार - ओएसआई पाइपलाइन रन को ट्रिगर करने की घटनाओं को इस कतार में रखा गया है।
क्लाउडफ़ॉर्मेशन टेम्प्लेट OSI पाइपलाइन को Amazon S3 और Amazon SQS प्रोसेसिंग के साथ स्रोत के रूप में और एक OpenSearch सर्वरलेस इंडेक्स को सिंक के रूप में कॉन्फ़िगर करता है। निर्दिष्ट S3 बकेट और उपसर्ग में बनाई गई कोई भी वस्तु (multimodal/osi-embeddings-json) एसक्यूएस नोटिफिकेशन को ट्रिगर करेगा, जिसका उपयोग ओएसआई पाइपलाइन द्वारा ओपनसर्च सर्वरलेस में डेटा डालने के लिए किया जाता है।
CloudFormation टेम्पलेट भी बनाता है नेटवर्क, एन्क्रिप्शन, तथा डेटा प्राप्त करना ओपनसर्च सर्वर रहित संग्रह के लिए आवश्यक नीतियां। न्यूनतम-विशेषाधिकार अनुमतियाँ लागू करने के लिए इन नीतियों को अद्यतन करें।
ध्यान दें कि क्लाउडफॉर्मेशन टेम्पलेट नाम सेजमेकर नोटबुक में संदर्भित है। यदि डिफ़ॉल्ट टेम्प्लेट नाम बदल गया है, तो सुनिश्चित करें कि आपने उसे अपडेट कर दिया है ग्लोबल्स.पी.ई
समाधान का परीक्षण करें
आवश्यक चरण पूरे होने और क्लाउडफ़ॉर्मेशन स्टैक सफलतापूर्वक बन जाने के बाद, अब आप समाधान का परीक्षण करने के लिए तैयार हैं:
- SageMaker कंसोल पर, चुनें नोटबुक नेविगेशन फलक में
- चयन
MultimodalNotebookInstanceनोटबुक उदाहरण और चुनें जुपिटरलैब खोलें.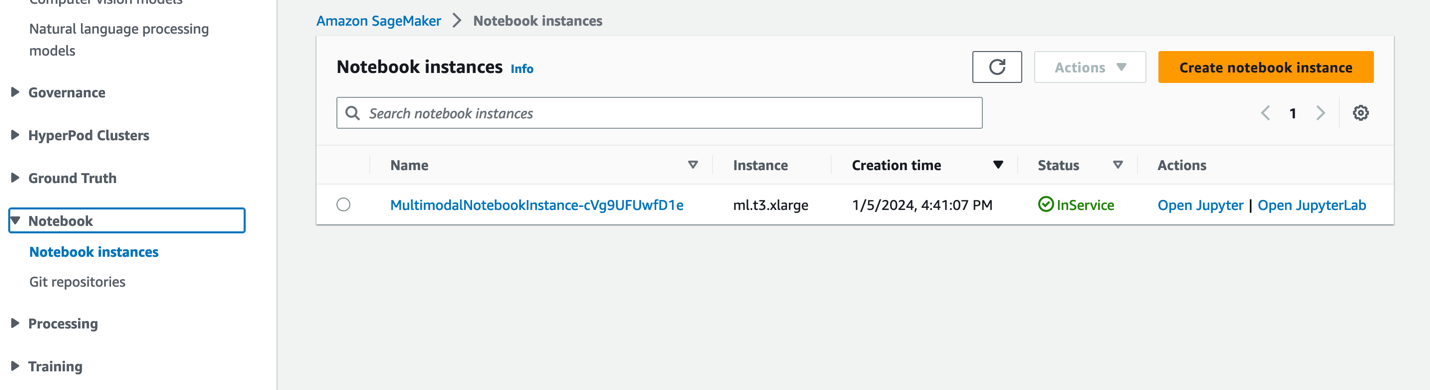
- In फ़ाइल ब्राउज़र, नोटबुक और सहायक फ़ाइलें देखने के लिए नोटबुक फ़ोल्डर में जाएँ।
नोटबुक को चलाने के क्रम में क्रमांकित किया जाता है। प्रत्येक नोटबुक में निर्देश और टिप्पणियाँ उस नोटबुक द्वारा किए गए कार्यों का वर्णन करती हैं। हम इन नोटबुक्स को एक-एक करके चलाते हैं।
- चुनें 0_तैनाती_llava.ipynb इसे JupyterLab में खोलने के लिए।
- पर रन मेनू, चुनें सभी सेल चलाएं इस नोटबुक में कोड चलाने के लिए.
यह नोटबुक LLaVA-v1.5-7B मॉडल को सेजमेकर एंडपॉइंट पर तैनात करता है। इस नोटबुक में, हम HuggingFace हब से LLaVA-v1.5-7B मॉडल डाउनलोड करते हैं, inference.py स्क्रिप्ट को प्रतिस्थापित करते हैं llava_inference.py, और इस मॉडल के लिए एक model.tar.gz फ़ाइल बनाएं। model.tar.gz फ़ाइल को Amazon S3 पर अपलोड किया गया है और SageMaker एंडपॉइंट पर मॉडल को तैनात करने के लिए उपयोग किया जाता है। llava_inference.py स्क्रिप्ट में अमेज़ॅन S3 से एक छवि फ़ाइल को पढ़ने और उस पर अनुमान चलाने की अनुमति देने के लिए अतिरिक्त कोड है।
- चुनें 1_data_prep.ipynb इसे JupyterLab में खोलने के लिए।
- पर रन मेनू, चुनें सभी सेल चलाएं इस नोटबुक में कोड चलाने के लिए.
यह नोटबुक डाउनलोड करता है सरकाने का पटाव, प्रत्येक स्लाइड को JPG फ़ाइल स्वरूप में परिवर्तित करता है, और इन्हें इस पोस्ट के लिए उपयोग की जाने वाली S3 बकेट में अपलोड करता है।
- चुनें 2_data_ingestion.ipynb इसे JupyterLab में खोलने के लिए।
- पर रन मेनू, चुनें सभी सेल चलाएं इस नोटबुक में कोड चलाने के लिए.
हम इस नोटबुक में निम्नलिखित कार्य करते हैं:
- हम OpenSearch सर्वर रहित संग्रह में एक इंडेक्स बनाते हैं। यह इंडेक्स स्लाइड डेक के लिए एम्बेडिंग डेटा संग्रहीत करता है। निम्नलिखित कोड देखें:
- हम पिछली नोटबुक में बनाई गई JPG छवियों को वेक्टर एम्बेडिंग में बदलने के लिए टाइटन मल्टीमॉडल एंबेडिंग मॉडल का उपयोग करते हैं। ये एम्बेडिंग और अतिरिक्त मेटाडेटा (जैसे छवि फ़ाइल का S3 पथ) एक JSON फ़ाइल में संग्रहीत किए जाते हैं और Amazon S3 पर अपलोड किए जाते हैं। ध्यान दें कि एक एकल JSON फ़ाइल बनाई गई है, जिसमें एम्बेडिंग में परिवर्तित सभी स्लाइड्स (छवियों) के दस्तावेज़ शामिल हैं। निम्नलिखित कोड स्निपेट दिखाता है कि कैसे एक छवि (बेस64 एन्कोडेड स्ट्रिंग के रूप में) को एम्बेडिंग में परिवर्तित किया जाता है:
- यह क्रिया OpenSearch Ingestion पाइपलाइन को ट्रिगर करती है, जो फ़ाइल को संसाधित करती है और इसे OpenSearch सर्वरलेस इंडेक्स में सम्मिलित करती है। निम्नलिखित बनाई गई JSON फ़ाइल का एक नमूना है। (उदाहरण कोड में चार आयामों वाला एक वेक्टर दिखाया गया है। टाइटन मल्टीमॉडल एंबेडिंग मॉडल 1,024 आयाम उत्पन्न करता है।)
- चुनें 3_rag_inference.ipynb इसे JupyterLab में खोलने के लिए।
- पर रन मेनू, चुनें सभी सेल चलाएं इस नोटबुक में कोड चलाने के लिए.
यह नोटबुक RAG समाधान लागू करता है: हम उपयोगकर्ता के प्रश्न को एम्बेडिंग में परिवर्तित करते हैं, वेक्टर डेटाबेस से एक समान छवि (स्लाइड) ढूंढते हैं, और उपयोगकर्ता के प्रश्न का उत्तर उत्पन्न करने के लिए LLaVA को पुनर्प्राप्त छवि प्रदान करते हैं। हम निम्नलिखित प्रॉम्प्ट टेम्पलेट का उपयोग करते हैं:
निम्नलिखित कोड स्निपेट RAG वर्कफ़्लो प्रदान करता है:
परिणाम
निम्नलिखित हमारे कार्यान्वयन द्वारा उत्पन्न कुछ उपयोगकर्ता प्रश्नों और प्रतिक्रियाओं का संकलन है। सवाल कॉलम उपयोगकर्ता के प्रश्न को कैप्चर करता है, और उत्तर कॉलम LLaVA द्वारा उत्पन्न पाठ्य प्रतिक्रिया है। छवि ओपनसर्च सर्वरलेस वेक्टर खोज द्वारा लौटाया गया k-निकटतम (k=1) स्लाइड मिलान है। उत्तर प्रदान करने के लिए इस स्लाइड की व्याख्या LLaVA द्वारा की गई है।
मल्टीमॉडल आरएजी परिणाम
| सवाल | उत्तर | छवि |
|---|---|---|
| प्रदर्शन में Inf2 की तुलना तुलनीय EC2 उदाहरणों से कैसे की जाती है? मुझे नंबर चाहिए. | स्लाइड डेक के अनुसार, AWS Inferentia2 द्वारा Inf2 उदाहरण तुलनीय EC4 उदाहरणों की तुलना में 10x अधिक थ्रूपुट और 2x कम विलंबता प्रदान करते हैं। |  |
| एआई/एमएल फ्लाईव्हील के अनुसार, एडब्ल्यूएस एआई/एमएल सेवाएं क्या प्रदान करती हैं? | AWS AI/ML सेवाएँ बेहतर $/perfer क्षमताएँ, नई क्षमताएँ और नवाचार में निवेश प्रदान करती हैं। |  |
| GPT-2 की तुलना में GPT-3 में कितने अधिक पैरामीटर हैं? GPT-2 और GPT-3 के पैरामीटर आकार के बीच संख्यात्मक अंतर क्या है? | स्लाइड के अनुसार, GPT-3 में 175 बिलियन पैरामीटर हैं, जबकि GPT-2 में 1.5 बिलियन पैरामीटर हैं। GPT-2 और GPT-3 के पैरामीटर आकार के बीच संख्यात्मक अंतर 173.5 बिलियन है। |  |
| कण भौतिकी में क्वार्क क्या हैं? | मुझे इस प्रश्न का उत्तर स्लाइड डेक में नहीं मिला। |  |
बेझिझक इस समाधान को अपने स्लाइड डेक तक विस्तारित करें। बस अपने स्लाइड डेक के URL के साथ Globals.py में SLIDE_DECK वैरिएबल को अपडेट करें और पिछले अनुभाग में विस्तृत अंतर्ग्रहण चरणों को चलाएँ।
टिप
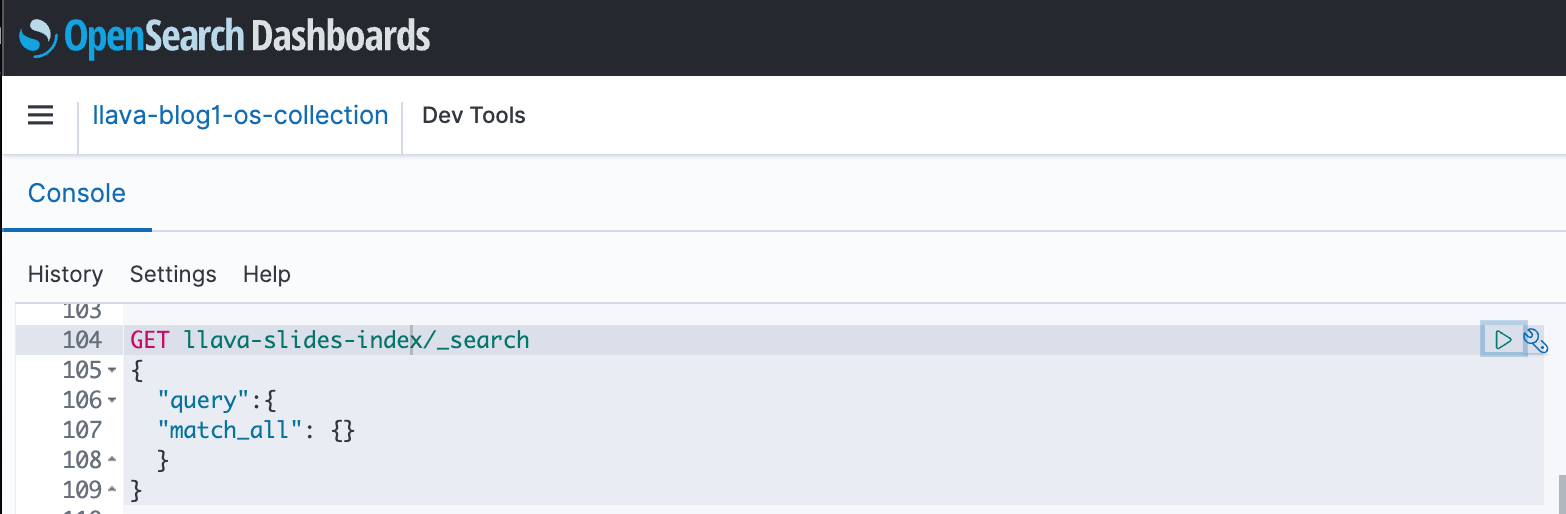
आप अपने सूचकांक और अंतर्ग्रहण डेटा पर त्वरित परीक्षण चलाने के लिए ओपनसर्च एपीआई के साथ इंटरैक्ट करने के लिए ओपनसर्च डैशबोर्ड का उपयोग कर सकते हैं। निम्नलिखित स्क्रीनशॉट एक ओपनसर्च डैशबोर्ड GET उदाहरण दिखाता है।
क्लीन अप
भविष्य में शुल्क लगने से बचने के लिए, अपने द्वारा बनाए गए संसाधनों को हटा दें। आप CloudFormation कंसोल के माध्यम से स्टैक को हटाकर ऐसा कर सकते हैं।

इसके अतिरिक्त, LLaVA अनुमान के लिए बनाए गए SageMaker अनुमान समापन बिंदु को हटा दें। आप क्लीनअप चरण को अनटिप्पणी करके ऐसा कर सकते हैं 3_rag_inference.ipynb और सेल को चलाना, या सेजमेकर कंसोल के माध्यम से समापन बिंदु को हटाकर: चुनें अनुमान और endpoints नेविगेशन फलक में, फिर समापन बिंदु का चयन करें और इसे हटा दें।
निष्कर्ष
उद्यम हर समय नई सामग्री उत्पन्न करते हैं, और स्लाइड डेक एक सामान्य तंत्र है जिसका उपयोग संगठन के साथ आंतरिक रूप से और ग्राहकों के साथ या सम्मेलनों में जानकारी साझा करने और प्रसारित करने के लिए किया जाता है। समय के साथ, समृद्ध जानकारी इन स्लाइड डेक में ग्राफ़ और तालिकाओं जैसी गैर-पाठ पद्धतियों में दबी और छिपी रह सकती है। आप नई जानकारी खोजने या स्लाइड डेक में सामग्री पर नए दृष्टिकोण को उजागर करने के लिए इस समाधान और मल्टीमॉडल एफएम जैसे टाइटन मल्टीमॉडल एंबेडिंग मॉडल और एलएलएवीए की शक्ति का उपयोग कर सकते हैं।
हम आपको एक्सप्लोर करके और जानने के लिए प्रोत्साहित करते हैं अमेज़न SageMaker जम्पस्टार्ट, अमेज़ॅन टाइटन मॉडल, अमेज़ॅन बेडरॉक, और ओपनसर्च सेवा, और इस पोस्ट में दिए गए नमूना कार्यान्वयन का उपयोग करके एक समाधान तैयार करना।
इस श्रृंखला के भाग के रूप में दो अतिरिक्त पोस्ट देखें। भाग 2 में एक और दृष्टिकोण शामिल है जिसे आप अपने स्लाइड डेक से बात करने के लिए अपना सकते हैं। यह दृष्टिकोण एलएलएवीए अनुमानों को उत्पन्न और संग्रहीत करता है और उपयोगकर्ता प्रश्नों का उत्तर देने के लिए उन संग्रहीत अनुमानों का उपयोग करता है। भाग 3 दो दृष्टिकोणों की तुलना करता है।
लेखक के बारे में
 अमित अरोड़ा Amazon Web Services में एक AI और ML स्पेशलिस्ट आर्किटेक्ट है, जो उद्यम ग्राहकों को अपने नवाचारों को तेजी से बढ़ाने के लिए क्लाउड-आधारित मशीन लर्निंग सेवाओं का उपयोग करने में मदद करता है। वह वाशिंगटन डीसी में जॉर्जटाउन यूनिवर्सिटी में एमएस डेटा साइंस एंड एनालिटिक्स प्रोग्राम में सहायक व्याख्याता भी हैं
अमित अरोड़ा Amazon Web Services में एक AI और ML स्पेशलिस्ट आर्किटेक्ट है, जो उद्यम ग्राहकों को अपने नवाचारों को तेजी से बढ़ाने के लिए क्लाउड-आधारित मशीन लर्निंग सेवाओं का उपयोग करने में मदद करता है। वह वाशिंगटन डीसी में जॉर्जटाउन यूनिवर्सिटी में एमएस डेटा साइंस एंड एनालिटिक्स प्रोग्राम में सहायक व्याख्याता भी हैं
 मंजू प्रसाद अमेज़ॅन वेब सर्विसेज में रणनीतिक खातों के भीतर एक वरिष्ठ समाधान वास्तुकार हैं। वह प्रमुख एम एंड ई ग्राहकों को एआई/एमएल सहित विभिन्न डोमेन में तकनीकी मार्गदर्शन प्रदान करने पर ध्यान केंद्रित करती है। AWS में शामिल होने से पहले, उन्होंने वित्तीय सेवा क्षेत्र की कंपनियों और एक स्टार्टअप के लिए समाधान डिज़ाइन और निर्माण किया।
मंजू प्रसाद अमेज़ॅन वेब सर्विसेज में रणनीतिक खातों के भीतर एक वरिष्ठ समाधान वास्तुकार हैं। वह प्रमुख एम एंड ई ग्राहकों को एआई/एमएल सहित विभिन्न डोमेन में तकनीकी मार्गदर्शन प्रदान करने पर ध्यान केंद्रित करती है। AWS में शामिल होने से पहले, उन्होंने वित्तीय सेवा क्षेत्र की कंपनियों और एक स्टार्टअप के लिए समाधान डिज़ाइन और निर्माण किया।
 अर्चना इनापुडी रणनीतिक ग्राहकों का समर्थन करने वाले AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनके पास ग्राहकों को डेटा एनालिटिक्स और डेटाबेस समाधान डिजाइन करने और बनाने में मदद करने का एक दशक से अधिक का अनुभव है। वह ग्राहकों को मूल्य प्रदान करने और व्यावसायिक परिणाम प्राप्त करने के लिए प्रौद्योगिकी का उपयोग करने को लेकर उत्साहित हैं।
अर्चना इनापुडी रणनीतिक ग्राहकों का समर्थन करने वाले AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनके पास ग्राहकों को डेटा एनालिटिक्स और डेटाबेस समाधान डिजाइन करने और बनाने में मदद करने का एक दशक से अधिक का अनुभव है। वह ग्राहकों को मूल्य प्रदान करने और व्यावसायिक परिणाम प्राप्त करने के लिए प्रौद्योगिकी का उपयोग करने को लेकर उत्साहित हैं।
 अंतरा रायसा अमेज़ॅन वेब सर्विसेज में एक एआई और एमएल सॉल्यूशंस आर्किटेक्ट है जो डलास, टेक्सास में स्थित रणनीतिक ग्राहकों का समर्थन करता है। उनके पास AWS में बड़े उद्यम भागीदारों के साथ काम करने का पिछला अनुभव भी है, जहां उन्होंने डिजिटल मूल ग्राहकों के लिए पार्टनर सक्सेस सॉल्यूशंस आर्किटेक्ट के रूप में काम किया था।
अंतरा रायसा अमेज़ॅन वेब सर्विसेज में एक एआई और एमएल सॉल्यूशंस आर्किटेक्ट है जो डलास, टेक्सास में स्थित रणनीतिक ग्राहकों का समर्थन करता है। उनके पास AWS में बड़े उद्यम भागीदारों के साथ काम करने का पिछला अनुभव भी है, जहां उन्होंने डिजिटल मूल ग्राहकों के लिए पार्टनर सक्सेस सॉल्यूशंस आर्किटेक्ट के रूप में काम किया था।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

