In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch, making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. Since then, this feature has been integrated into many of our managed Amazon Machine Images (AMIs), such as the Deep Learning AMI and the AWS ParallelCluster AMI. To obtain instance-level metrics of GPU utilization, you can use Packer or the Amazon ImageBuilder to bootstrap your own custom AMI and use it in various managed service offerings like AWS Batch, Amazon Elastic Container Service (Amazon ECS), or Amazon Elastic Kubernetes Service (Amazon EKS). However, for many container-based service offerings and workloads, it’s ideal to capture utilization metrics on the container, pod, or namespace level.
This post details how to set up container-based GPU metrics and provides an example of collecting these metrics from EKS pods.
Solution overview
To demonstrate container-based GPU metrics, we create an EKS cluster with g5.2xlarge instances; however, this will work with any supported NVIDIA accelerated instance family.
We deploy the NVIDIA GPU operator to enable use of GPU resources and the NVIDIA DCGM Exporter to enable GPU metrics collection. Then we explore two architectures. The first one connects the metrics from NVIDIA DCGM Exporter to CloudWatch via a CloudWatch agent, as shown in the following diagram.
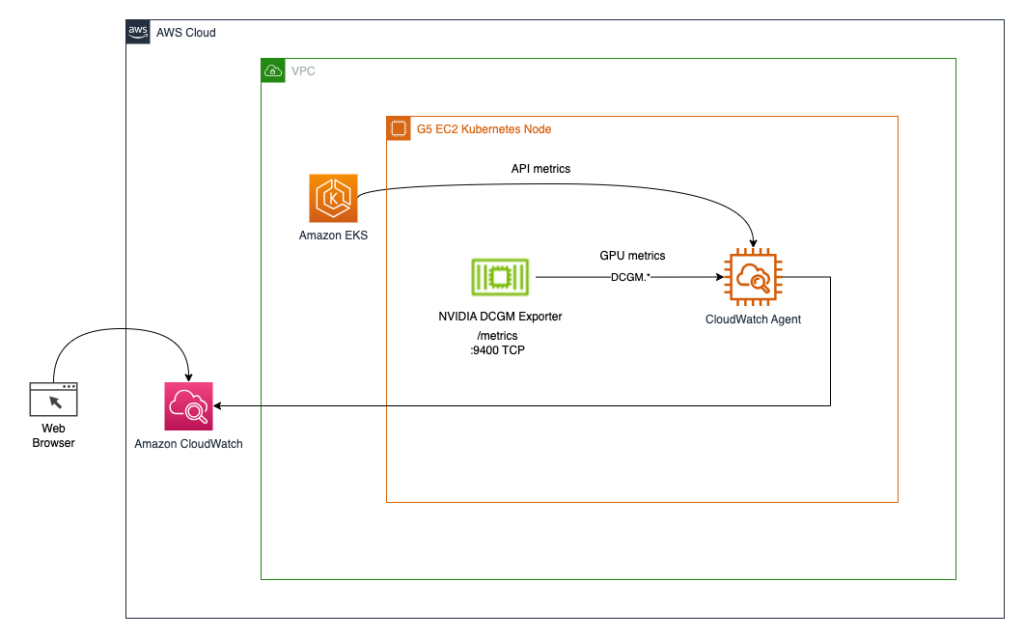
The second architecture (see the following diagram) connects the metrics from DCGM Exporter to Prometheus, then we use a Grafana dashboard to visualize those metrics.
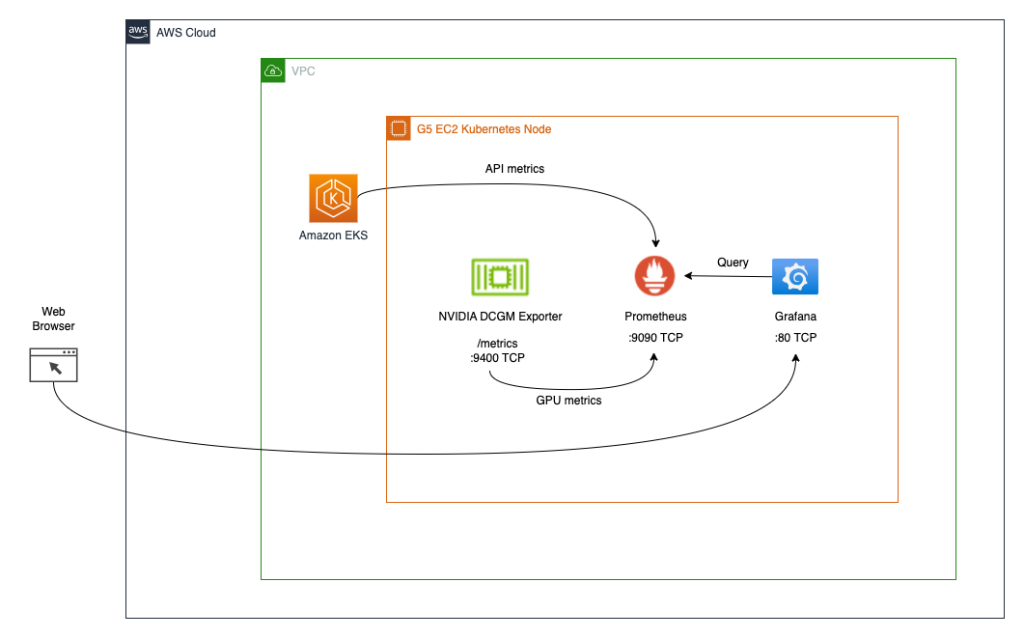
Prerequisites
To simplify reproducing the entire stack from this post, we use a container that has all the required tooling (aws cli, eksctl, helm, etc.) already installed. In order to clone the container project from GitHub, you will need git. To build and run the container, you will need Docker. To deploy the architecture, you will need AWS credentials. To enable access to Kubernetes services using port-forwarding, you will also need kubectl.
These prerequisites can be installed on your local machine, EC2 instance with NICE DCV, or AWS Cloud9. In this post, we will use a c5.2xlarge Cloud9 instance with a 40GB local storage volume. When using Cloud9, please disable AWS managed temporary credentials by visiting Cloud9->Preferences->AWS Settings as shown on the screenshot below.

Build and run the aws-do-eks container
Open a terminal shell in your preferred environment and run the following commands:
git clone https://github.com/aws-samples/aws-do-eks
cd aws-do-eks
./build.sh
./run.sh
./exec.sh
The result is as follows:
You now have a shell in a container environment that has all the tools needed to complete the tasks below. We will refer to it as “aws-do-eks shell”. You will be running the commands in the following sections in this shell, unless specifically instructed otherwise.
Create an EKS cluster with a node group
This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type.
The aws-do-eks project comes with a collection of cluster configurations. You can set your desired cluster configuration with a single configuration change.
- In the container shell, run
./env-config.sh and then set CONF=conf/eksctl/yaml/eks-gpu-g5.yaml
- To verify the cluster configuration, run
./eks-config.sh
You should see the following cluster manifest:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata: name: do-eks-yaml-g5 version: "1.25" region: us-east-1
availabilityZones: - us-east-1a - us-east-1b - us-east-1c - us-east-1d
managedNodeGroups: - name: sys instanceType: m5.xlarge desiredCapacity: 1 iam: withAddonPolicies: autoScaler: true cloudWatch: true - name: g5 instanceType: g5.2xlarge instancePrefix: g5-2xl privateNetworking: true efaEnabled: false minSize: 0 desiredCapacity: 1 maxSize: 10 volumeSize: 80 iam: withAddonPolicies: cloudWatch: true
iam: withOIDC: true
- To create the cluster, run the following command in the container
The output is as follows:
root@e5ecb162812f:/eks# ./eks-create.sh /eks/impl/eksctl/yaml /eks ./eks-create.sh Mon May 22 20:50:59 UTC 2023
Creating cluster using /eks/conf/eksctl/yaml/eks-gpu-g5.yaml ... eksctl create cluster -f /eks/conf/eksctl/yaml/eks-gpu-g5.yaml 2023-05-22 20:50:59 [ℹ] eksctl version 0.133.0
2023-05-22 20:50:59 [ℹ] using region us-east-1
2023-05-22 20:50:59 [ℹ] subnets for us-east-1a - public:192.168.0.0/19 private:192.168.128.0/19
2023-05-22 20:50:59 [ℹ] subnets for us-east-1b - public:192.168.32.0/19 private:192.168.160.0/19
2023-05-22 20:50:59 [ℹ] subnets for us-east-1c - public:192.168.64.0/19 private:192.168.192.0/19
2023-05-22 20:50:59 [ℹ] subnets for us-east-1d - public:192.168.96.0/19 private:192.168.224.0/19
2023-05-22 20:50:59 [ℹ] nodegroup "sys" will use "" [AmazonLinux2/1.25]
2023-05-22 20:50:59 [ℹ] nodegroup "g5" will use "" [AmazonLinux2/1.25]
2023-05-22 20:50:59 [ℹ] using Kubernetes version 1.25
2023-05-22 20:50:59 [ℹ] creating EKS cluster "do-eks-yaml-g5" in "us-east-1" region with managed nodes
2023-05-22 20:50:59 [ℹ] 2 nodegroups (g5, sys) were included (based on the include/exclude rules)
2023-05-22 20:50:59 [ℹ] will create a CloudFormation stack for cluster itself and 0 nodegroup stack(s)
2023-05-22 20:50:59 [ℹ] will create a CloudFormation stack for cluster itself and 2 managed nodegroup stack(s)
2023-05-22 20:50:59 [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-east-1 --cluster=do-eks-yaml-g5'
2023-05-22 20:50:59 [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "do-eks-yaml-g5" in "us-east-1"
2023-05-22 20:50:59 [ℹ] CloudWatch logging will not be enabled for cluster "do-eks-yaml-g5" in "us-east-1"
2023-05-22 20:50:59 [ℹ] you can enable it with 'eksctl utils update-cluster-logging --enable-types={SPECIFY-YOUR-LOG-TYPES-HERE (e.g. all)} --region=us-east-1 --cluster=do-eks-yaml-g5'
2023-05-22 20:50:59 [ℹ] 2 sequential tasks: { create cluster control plane "do-eks-yaml-g5", 2 sequential sub-tasks: { 4 sequential sub-tasks: { wait for control plane to become ready, associate IAM OIDC provider, 2 sequential sub-tasks: { create IAM role for serviceaccount "kube-system/aws-node", create serviceaccount "kube-system/aws-node", }, restart daemonset "kube-system/aws-node", }, 2 parallel sub-tasks: { create managed nodegroup "sys", create managed nodegroup "g5", }, } }
2023-05-22 20:50:59 [ℹ] building cluster stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:51:00 [ℹ] deploying stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:51:30 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:52:00 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:53:01 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:54:01 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:55:01 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:56:02 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:57:02 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:58:02 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 20:59:02 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 21:00:03 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 21:01:03 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 21:02:03 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 21:03:04 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-cluster"
2023-05-22 21:05:07 [ℹ] building iamserviceaccount stack "eksctl-do-eks-yaml-g5-addon-iamserviceaccount-kube-system-aws-node"
2023-05-22 21:05:10 [ℹ] deploying stack "eksctl-do-eks-yaml-g5-addon-iamserviceaccount-kube-system-aws-node"
2023-05-22 21:05:10 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-addon-iamserviceaccount-kube-system-aws-node"
2023-05-22 21:05:40 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-addon-iamserviceaccount-kube-system-aws-node"
2023-05-22 21:05:40 [ℹ] serviceaccount "kube-system/aws-node" already exists
2023-05-22 21:05:41 [ℹ] updated serviceaccount "kube-system/aws-node"
2023-05-22 21:05:41 [ℹ] daemonset "kube-system/aws-node" restarted
2023-05-22 21:05:41 [ℹ] building managed nodegroup stack "eksctl-do-eks-yaml-g5-nodegroup-sys"
2023-05-22 21:05:41 [ℹ] building managed nodegroup stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:05:42 [ℹ] deploying stack "eksctl-do-eks-yaml-g5-nodegroup-sys"
2023-05-22 21:05:42 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-sys"
2023-05-22 21:05:42 [ℹ] deploying stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:05:42 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:06:12 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-sys"
2023-05-22 21:06:12 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:06:55 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-sys"
2023-05-22 21:07:11 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:08:29 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:08:45 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-sys"
2023-05-22 21:09:52 [ℹ] waiting for CloudFormation stack "eksctl-do-eks-yaml-g5-nodegroup-g5"
2023-05-22 21:09:53 [ℹ] waiting for the control plane to become ready
2023-05-22 21:09:53 [✔] saved kubeconfig as "/root/.kube/config"
2023-05-22 21:09:53 [ℹ] 1 task: { install Nvidia device plugin }
W0522 21:09:54.155837 1668 warnings.go:70] spec.template.metadata.annotations[scheduler.alpha.kubernetes.io/critical-pod]: non-functional in v1.16+; use the "priorityClassName" field instead
2023-05-22 21:09:54 [ℹ] created "kube-system:DaemonSet.apps/nvidia-device-plugin-daemonset"
2023-05-22 21:09:54 [ℹ] as you are using the EKS-Optimized Accelerated AMI with a GPU-enabled instance type, the Nvidia Kubernetes device plugin was automatically installed. to skip installing it, use --install-nvidia-plugin=false.
2023-05-22 21:09:54 [✔] all EKS cluster resources for "do-eks-yaml-g5" have been created
2023-05-22 21:09:54 [ℹ] nodegroup "sys" has 1 node(s)
2023-05-22 21:09:54 [ℹ] node "ip-192-168-18-137.ec2.internal" is ready
2023-05-22 21:09:54 [ℹ] waiting for at least 1 node(s) to become ready in "sys"
2023-05-22 21:09:54 [ℹ] nodegroup "sys" has 1 node(s)
2023-05-22 21:09:54 [ℹ] node "ip-192-168-18-137.ec2.internal" is ready
2023-05-22 21:09:55 [ℹ] kubectl command should work with "/root/.kube/config", try 'kubectl get nodes'
2023-05-22 21:09:55 [✔] EKS cluster "do-eks-yaml-g5" in "us-east-1" region is ready Mon May 22 21:09:55 UTC 2023
Done creating cluster using /eks/conf/eksctl/yaml/eks-gpu-g5.yaml /eks
- To verify that your cluster is created successfully, run the following command
kubectl get nodes -L node.kubernetes.io/instance-type
The output is similar to the following:
NAME STATUS ROLES AGE VERSION INSTANCE_TYPE
ip-192-168-18-137.ec2.internal Ready <none> 47m v1.25.9-eks-0a21954 m5.xlarge
ip-192-168-214-241.ec2.internal Ready <none> 46m v1.25.9-eks-0a21954 g5.2xlarge
In this example, we have one m5.xlarge and one g5.2xlarge instance in our cluster; therefore, we see two nodes listed in the preceding output.
During the cluster creation process, the NVIDIA device plugin will get installed. You will need to remove it after cluster creation because we will use the NVIDIA GPU Operator instead.
- Delete the plugin with the following command
kubectl -n kube-system delete daemonset nvidia-device-plugin-daemonset
We get the following output:
daemonset.apps "nvidia-device-plugin-daemonset" deleted
Install the NVIDIA Helm repo
Install the NVIDIA Helm repo with the following command:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
Deploy the DCGM exporter with the NVIDIA GPU Operator
To deploy the DCGM exporter, complete the following steps:
- Prepare the DCGM exporter GPU metrics configuration
curl https://raw.githubusercontent.com/NVIDIA/dcgm-exporter/main/etc/dcp-metrics-included.csv > dcgm-metrics.csv
You have the option to edit the dcgm-metrics.csv file. You can add or remove any metrics as needed.
- Create the gpu-operator namespace and DCGM exporter ConfigMap
kubectl create namespace gpu-operator && /
kubectl create configmap metrics-config -n gpu-operator --from-file=dcgm-metrics.csv
The output is as follows:
namespace/gpu-operator created
configmap/metrics-config created
- Apply the GPU operator to the EKS cluster
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator --set dcgmExporter.config.name=metrics-config --set dcgmExporter.env[0].name=DCGM_EXPORTER_COLLECTORS --set dcgmExporter.env[0].value=/etc/dcgm-exporter/dcgm-metrics.csv --set toolkit.enabled=false
The output is as follows:
NAME: gpu-operator-1684795140
LAST DEPLOYED: Day Month Date HH:mm:ss YYYY
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
- Confirm that the DCGM exporter pod is running
kubectl -n gpu-operator get pods | grep dcgm
The output is as follows:
nvidia-dcgm-exporter-lkmfr 1/1 Running 0 1m
If you inspect the logs, you should see the “Starting webserver” message:
kubectl -n gpu-operator logs -f $(kubectl -n gpu-operator get pods | grep dcgm | cut -d ' ' -f 1)
The output is as follows:
Defaulted container "nvidia-dcgm-exporter" out of: nvidia-dcgm-exporter, toolkit-validation (init)
time="2023-05-22T22:40:08Z" level=info msg="Starting dcgm-exporter"
time="2023-05-22T22:40:08Z" level=info msg="DCGM successfully initialized!"
time="2023-05-22T22:40:08Z" level=info msg="Collecting DCP Metrics"
time="2023-05-22T22:40:08Z" level=info msg="No configmap data specified, falling back to metric file /etc/dcgm-exporter/dcgm-metrics.csv"
time="2023-05-22T22:40:08Z" level=info msg="Initializing system entities of type: GPU"
time="2023-05-22T22:40:09Z" level=info msg="Initializing system entities of type: NvSwitch"
time="2023-05-22T22:40:09Z" level=info msg="Not collecting switch metrics: no switches to monitor"
time="2023-05-22T22:40:09Z" level=info msg="Initializing system entities of type: NvLink"
time="2023-05-22T22:40:09Z" level=info msg="Not collecting link metrics: no switches to monitor"
time="2023-05-22T22:40:09Z" level=info msg="Kubernetes metrics collection enabled!"
time="2023-05-22T22:40:09Z" level=info msg="Pipeline starting"
time="2023-05-22T22:40:09Z" level=info msg="Starting webserver"
NVIDIA DCGM Exporter exposes a Prometheus metrics endpoint, which can be ingested by the CloudWatch agent. To see the endpoint, use the following command:
kubectl -n gpu-operator get services | grep dcgm
We get the following output:
nvidia-dcgm-exporter ClusterIP 10.100.183.207 <none> 9400/TCP 10m
- To generate some GPU utilization, we deploy a pod that runs the gpu-burn binary
kubectl apply -f https://raw.githubusercontent.com/aws-samples/aws-do-eks/main/Container-Root/eks/deployment/gpu-metrics/gpu-burn-deployment.yaml
The output is as follows:
deployment.apps/gpu-burn created
This deployment uses a single GPU to produce a continuous pattern of 100% utilization for 20 seconds followed by 0% utilization for 20 seconds.
- To make sure the endpoint works, you can run a temporary container that uses curl to read the content of
https://nvidia-dcgm-exporter:9400/metrics
kubectl -n gpu-operator run -it --rm curl --restart='Never' --image=curlimages/curl --command -- curl https://nvidia-dcgm-exporter:9400/metrics
We get the following output:
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
DCGM_FI_DEV_SM_CLOCK{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 1455
# HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz).
# TYPE DCGM_FI_DEV_MEM_CLOCK gauge
DCGM_FI_DEV_MEM_CLOCK{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 6250
# HELP DCGM_FI_DEV_GPU_TEMP GPU temperature (in C).
# TYPE DCGM_FI_DEV_GPU_TEMP gauge
DCGM_FI_DEV_GPU_TEMP{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 65
# HELP DCGM_FI_DEV_POWER_USAGE Power draw (in W).
# TYPE DCGM_FI_DEV_POWER_USAGE gauge
DCGM_FI_DEV_POWER_USAGE{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 299.437000
# HELP DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION Total energy consumption since boot (in mJ).
# TYPE DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION counter
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 15782796862
# HELP DCGM_FI_DEV_PCIE_REPLAY_COUNTER Total number of PCIe retries.
# TYPE DCGM_FI_DEV_PCIE_REPLAY_COUNTER counter
DCGM_FI_DEV_PCIE_REPLAY_COUNTER{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_GPU_UTIL GPU utilization (in %).
# TYPE DCGM_FI_DEV_GPU_UTIL gauge
DCGM_FI_DEV_GPU_UTIL{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 100
# HELP DCGM_FI_DEV_MEM_COPY_UTIL Memory utilization (in %).
# TYPE DCGM_FI_DEV_MEM_COPY_UTIL gauge
DCGM_FI_DEV_MEM_COPY_UTIL{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 38
# HELP DCGM_FI_DEV_ENC_UTIL Encoder utilization (in %).
# TYPE DCGM_FI_DEV_ENC_UTIL gauge
DCGM_FI_DEV_ENC_UTIL{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_DEC_UTIL Decoder utilization (in %).
# TYPE DCGM_FI_DEV_DEC_UTIL gauge
DCGM_FI_DEV_DEC_UTIL{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_XID_ERRORS Value of the last XID error encountered.
# TYPE DCGM_FI_DEV_XID_ERRORS gauge
DCGM_FI_DEV_XID_ERRORS{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_FB_FREE Framebuffer memory free (in MiB).
# TYPE DCGM_FI_DEV_FB_FREE gauge
DCGM_FI_DEV_FB_FREE{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 2230
# HELP DCGM_FI_DEV_FB_USED Framebuffer memory used (in MiB).
# TYPE DCGM_FI_DEV_FB_USED gauge
DCGM_FI_DEV_FB_USED{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 20501
# HELP DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL Total number of NVLink bandwidth counters for all lanes.
# TYPE DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL counter
DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_VGPU_LICENSE_STATUS vGPU License status
# TYPE DCGM_FI_DEV_VGPU_LICENSE_STATUS gauge
DCGM_FI_DEV_VGPU_LICENSE_STATUS{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS Number of remapped rows for uncorrectable errors
# TYPE DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS counter
DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS Number of remapped rows for correctable errors
# TYPE DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS counter
DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_DEV_ROW_REMAP_FAILURE Whether remapping of rows has failed
# TYPE DCGM_FI_DEV_ROW_REMAP_FAILURE gauge
DCGM_FI_DEV_ROW_REMAP_FAILURE{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0
# HELP DCGM_FI_PROF_GR_ENGINE_ACTIVE Ratio of time the graphics engine is active (in %).
# TYPE DCGM_FI_PROF_GR_ENGINE_ACTIVE gauge
DCGM_FI_PROF_GR_ENGINE_ACTIVE{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0.808369
# HELP DCGM_FI_PROF_PIPE_TENSOR_ACTIVE Ratio of cycles the tensor (HMMA) pipe is active (in %).
# TYPE DCGM_FI_PROF_PIPE_TENSOR_ACTIVE gauge
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0.000000
# HELP DCGM_FI_PROF_DRAM_ACTIVE Ratio of cycles the device memory interface is active sending or receiving data (in %).
# TYPE DCGM_FI_PROF_DRAM_ACTIVE gauge
DCGM_FI_PROF_DRAM_ACTIVE{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 0.315787
# HELP DCGM_FI_PROF_PCIE_TX_BYTES The rate of data transmitted over the PCIe bus - including both protocol headers and data payloads - in bytes per second.
# TYPE DCGM_FI_PROF_PCIE_TX_BYTES gauge
DCGM_FI_PROF_PCIE_TX_BYTES{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 3985328
# HELP DCGM_FI_PROF_PCIE_RX_BYTES The rate of data received over the PCIe bus - including both protocol headers and data payloads - in bytes per second.
# TYPE DCGM_FI_PROF_PCIE_RX_BYTES gauge
DCGM_FI_PROF_PCIE_RX_BYTES{gpu="0",UUID="GPU-ff76466b-22fc-f7a9-abe2-ce3ac453b8b3",device="nvidia0",modelName="NVIDIA A10G",Hostname="nvidia-dcgm-exporter-48cwd",DCGM_FI_DRIVER_VERSION="470.182.03",container="main",namespace="kube-system",pod="gpu-burn-c68d8c774-ltg9s"} 21715174
pod "curl" deleted
Configure and deploy the CloudWatch agent
To configure and deploy the CloudWatch agent, complete the following steps:
- Download the YAML file and edit it
curl -O https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/k8s/1.3.15/k8s-deployment-manifest-templates/deployment-mode/service/cwagent-prometheus/prometheus-eks.yaml
The file contains a cwagent configmap and a prometheus configmap. For this post, we edit both.
- Edit the
prometheus-eks.yaml file
Open the prometheus-eks.yaml file in your favorite editor and replace the cwagentconfig.json section with the following content:
apiVersion: v1
data: # cwagent json config cwagentconfig.json: | { "logs": { "metrics_collected": { "prometheus": { "prometheus_config_path": "/etc/prometheusconfig/prometheus.yaml", "emf_processor": { "metric_declaration": [ { "source_labels": ["Service"], "label_matcher": ".*dcgm.*", "dimensions": [["Service","Namespace","ClusterName","job","pod"]], "metric_selectors": [ "^DCGM_FI_DEV_GPU_UTIL$", "^DCGM_FI_DEV_DEC_UTIL$", "^DCGM_FI_DEV_ENC_UTIL$", "^DCGM_FI_DEV_MEM_CLOCK$", "^DCGM_FI_DEV_MEM_COPY_UTIL$", "^DCGM_FI_DEV_POWER_USAGE$", "^DCGM_FI_DEV_ROW_REMAP_FAILURE$", "^DCGM_FI_DEV_SM_CLOCK$", "^DCGM_FI_DEV_XID_ERRORS$", "^DCGM_FI_PROF_DRAM_ACTIVE$", "^DCGM_FI_PROF_GR_ENGINE_ACTIVE$", "^DCGM_FI_PROF_PCIE_RX_BYTES$", "^DCGM_FI_PROF_PCIE_TX_BYTES$", "^DCGM_FI_PROF_PIPE_TENSOR_ACTIVE$" ] } ] } } }, "force_flush_interval": 5 } }
- In the
prometheus config section, append the following job definition for the DCGM exporter
- job_name: 'kubernetes-pod-dcgm-exporter' sample_limit: 10000 metrics_path: /api/v1/metrics/prometheus kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_container_name] action: keep regex: '^DCGM.*$' - source_labels: [__address__] action: replace regex: ([^:]+)(?::d+)? replacement: ${1}:9400 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: Namespace - source_labels: [__meta_kubernetes_pod] action: replace target_label: pod - action: replace source_labels: - __meta_kubernetes_pod_container_name target_label: container_name - action: replace source_labels: - __meta_kubernetes_pod_controller_name target_label: pod_controller_name - action: replace source_labels: - __meta_kubernetes_pod_controller_kind target_label: pod_controller_kind - action: replace source_labels: - __meta_kubernetes_pod_phase target_label: pod_phase - action: replace source_labels: - __meta_kubernetes_pod_node_name target_label: NodeName
- Save the file and apply the
cwagent-dcgm configuration to your cluster
kubectl apply -f ./prometheus-eks.yaml
We get the following output:
namespace/amazon-cloudwatch created
configmap/prometheus-cwagentconfig created
configmap/prometheus-config created
serviceaccount/cwagent-prometheus created
clusterrole.rbac.authorization.k8s.io/cwagent-prometheus-role created
clusterrolebinding.rbac.authorization.k8s.io/cwagent-prometheus-role-binding created
deployment.apps/cwagent-prometheus created
- Confirm that the CloudWatch agent pod is running
kubectl -n amazon-cloudwatch get pods
We get the following output:
NAME READY STATUS RESTARTS AGE
cwagent-prometheus-7dfd69cc46-s4cx7 1/1 Running 0 15m
Visualize metrics on the CloudWatch console
To visualize the metrics in CloudWatch, complete the following steps:
- On the CloudWatch console, under Metrics in the navigation pane, choose All metrics
- In the Custom namespaces section, choose the new entry for ContainerInsights/Prometheus
For more information about the ContainerInsights/Prometheus namespace, refer to Scraping additional Prometheus sources and importing those metrics.
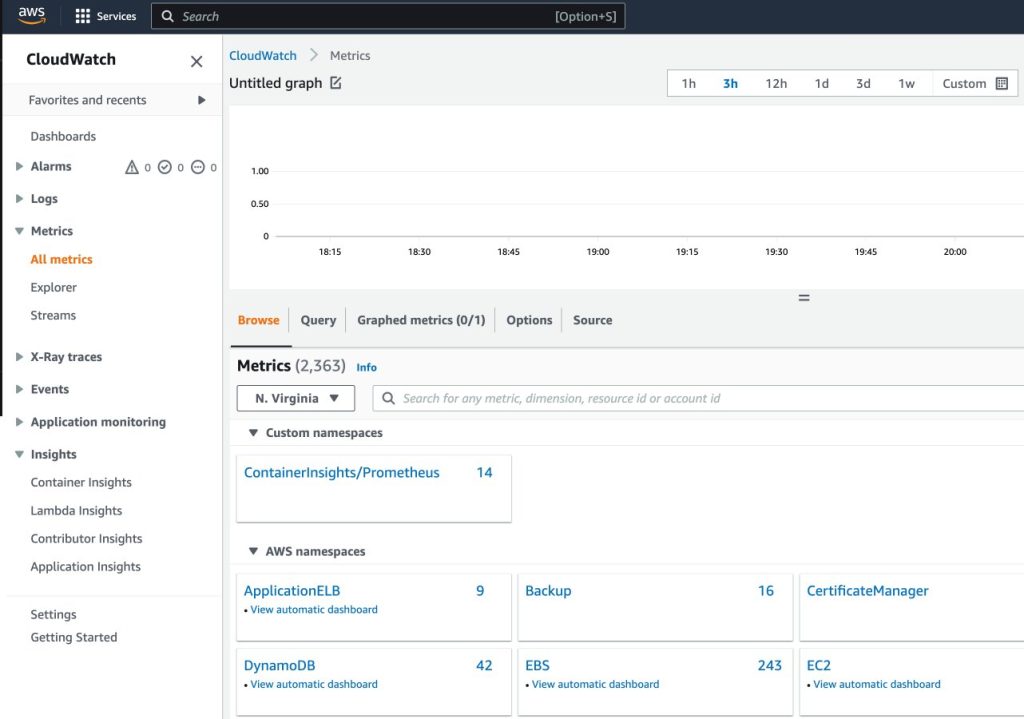
- Drill down to the metric names and choose
DCGM_FI_DEV_GPU_UTIL
- On the Graphed metrics tab, set Period to 5 seconds

- Set the refresh interval to 10 seconds
You will see the metrics collected from DCGM exporter that visualize the gpu-burn pattern on and off each 20 seconds.
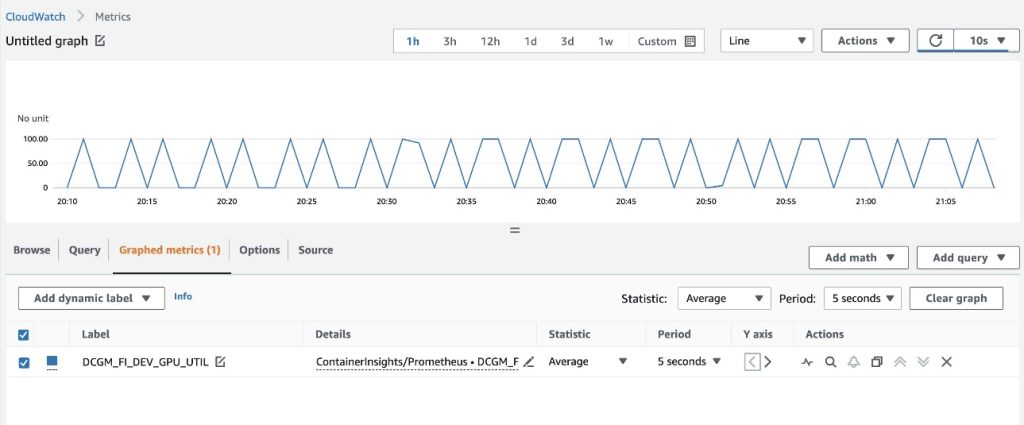
On the Browse tab, you can see the data, including the pod name for each metric.
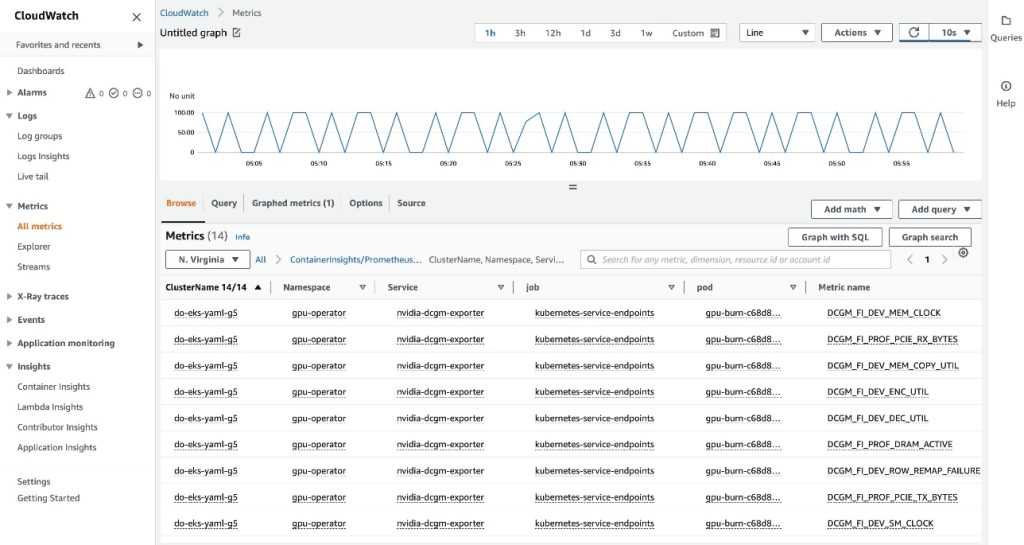
The EKS API metadata has been combined with the DCGM metrics data, resulting in the provided pod-based GPU metrics.
This concludes the first approach of exporting DCGM metrics to CloudWatch via the CloudWatch agent.
In the next section, we configure the second architecture, which exports the DCGM metrics to Prometheus, and we visualize them with Grafana.
Use Prometheus and Grafana to visualize GPU metrics from DCGM
Complete the following steps:
- Add the Prometheus community helm chart
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
This chart deploys both Prometheus and Grafana. We need to make some edits to the chart before running the install command.
- Save the chart configuration values to a file in
/tmp
helm inspect values prometheus-community/kube-prometheus-stack > /tmp/kube-prometheus-stack.values
- Edit the char configuration file
Edit the saved file (/tmp/kube-prometheus-stack.values) and set the following option by looking for the setting name and setting the value:
prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
- Add the following ConfigMap to the
additionalScrapeConfigs section
additionalScrapeConfigs:
- job_name: gpu-metrics scrape_interval: 1s metrics_path: /metrics scheme: http kubernetes_sd_configs: - role: endpoints namespaces: names: - gpu-operator relabel_configs: - source_labels: [__meta_kubernetes_pod_node_name] action: replace target_label: kubernetes_node
- Deploy the Prometheus stack with the updated values
helm install prometheus-community/kube-prometheus-stack
--create-namespace --namespace prometheus
--generate-name
--values /tmp/kube-prometheus-stack.values
We get the following output:
NAME: kube-prometheus-stack-1684965548
LAST DEPLOYED: Wed May 24 21:59:14 2023
NAMESPACE: prometheus
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running: kubectl --namespace prometheus get pods -l "release=kube-prometheus-stack-1684965548" Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
- Confirm that the Prometheus pods are running
kubectl get pods -n prometheus
We get the following output:
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-1684-alertmanager-0 2/2 Running 0 6m55s
kube-prometheus-stack-1684-operator-6c87649878-j7v55 1/1 Running 0 6m58s
kube-prometheus-stack-1684965548-grafana-dcd7b4c96-bzm8p 3/3 Running 0 6m58s
kube-prometheus-stack-1684965548-kube-state-metrics-7d856dptlj5 1/1 Running 0 6m58s
kube-prometheus-stack-1684965548-prometheus-node-exporter-2fbl5 1/1 Running 0 6m58s
kube-prometheus-stack-1684965548-prometheus-node-exporter-m7zmv 1/1 Running 0 6m58s
prometheus-kube-prometheus-stack-1684-prometheus-0 2/2 Running 0 6m55s
Prometheus and Grafana pods are in the Running state.
Next, we validate that DCGM metrics are flowing into Prometheus.
- Port-forward the Prometheus UI
There are different ways to expose the Prometheus UI running in EKS to requests originating outside of the cluster. We will use kubectl port-forwarding. So far, we have been executing commands inside the aws-do-eks container. To access the Prometheus service running in the cluster, we will create a tunnel from the host. Here the aws-do-eks container is running by executing the following command outside of the container, in a new terminal shell on the host. We will refer to this as “host shell”.
kubectl -n prometheus port-forward svc/$(kubectl -n prometheus get svc | grep prometheus | grep -v alertmanager | grep -v operator | grep -v grafana | grep -v metrics | grep -v exporter | grep -v operated | cut -d ' ' -f 1) 8080:9090 &
While the port-forwarding process is running, we are able to access the Prometheus UI from the host as described below.
- Open the Prometheus UI
- If you are using Cloud9, please navigate to
Preview->Preview Running Application to open the Prometheus UI in a tab inside the Cloud9 IDE, then click the  icon in the upper-right corner of the tab to pop out in a new window.
icon in the upper-right corner of the tab to pop out in a new window.
- If you are on your local host or connected to an EC2 instance via remote desktop open a browser and visit the URL
https://localhost:8080.
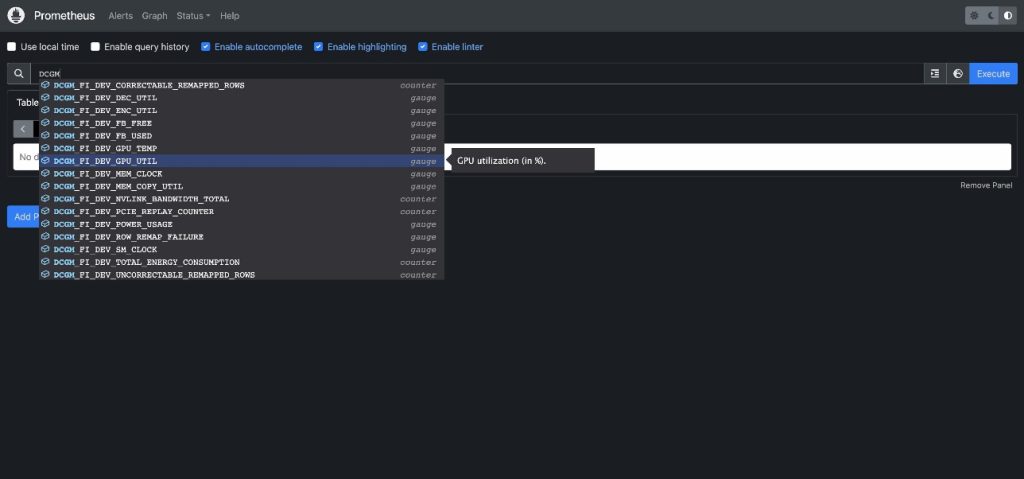
- Enter
DCGM to see the DCGM metrics that are flowing into Prometheus
- Select
DCGM_FI_DEV_GPU_UTIL, choose Execute, and then navigate to the Graph tab to see the expected GPU utilization pattern
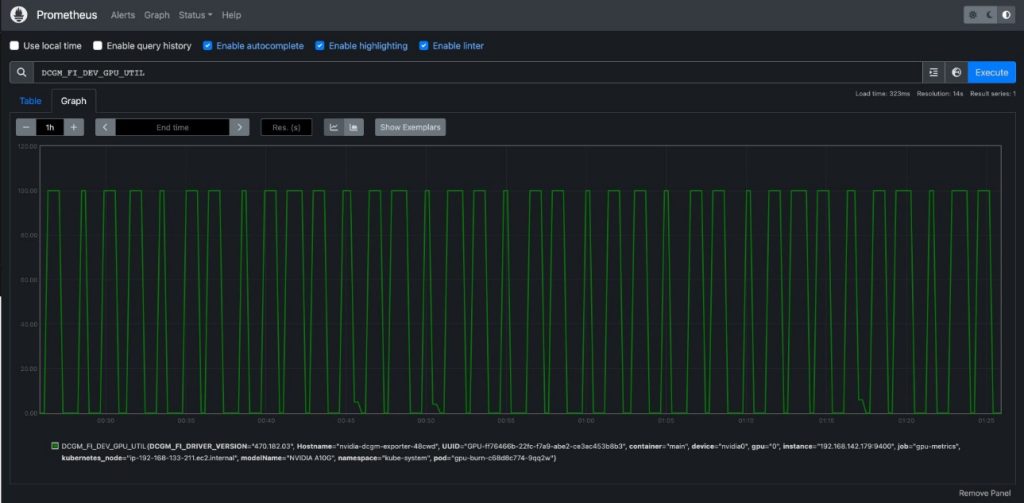
- Stop the Prometheus port-forwarding process
Run the following command line in your host shell:
kill -9 $(ps -aef | grep port-forward | grep -v grep | grep prometheus | awk '{print $2}')
Now we can visualize the DCGM metrics via Grafana Dashboard.
- Retrieve the password to log in to the Grafana UI
kubectl -n prometheus get secret $(kubectl -n prometheus get secrets | grep grafana | cut -d ' ' -f 1) -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
- Port-forward the Grafana service
Run the following command line in your host shell:
kubectl port-forward -n prometheus svc/$(kubectl -n prometheus get svc | grep grafana | cut -d ' ' -f 1) 8080:80 &
- Log in to the Grafana UI
Access the Grafana UI login screen the same way as you accessed the Prometheus UI earlier. If using Cloud9, select Preview->Preview Running Application, then pop out in a new window. If using your local host or an EC2 instance with remote desktop visit URL https://localhost:8080. Login with the user name admin and the password you retrieved earlier.
- In the navigation pane, choose Dashboards
- Choose New and Import
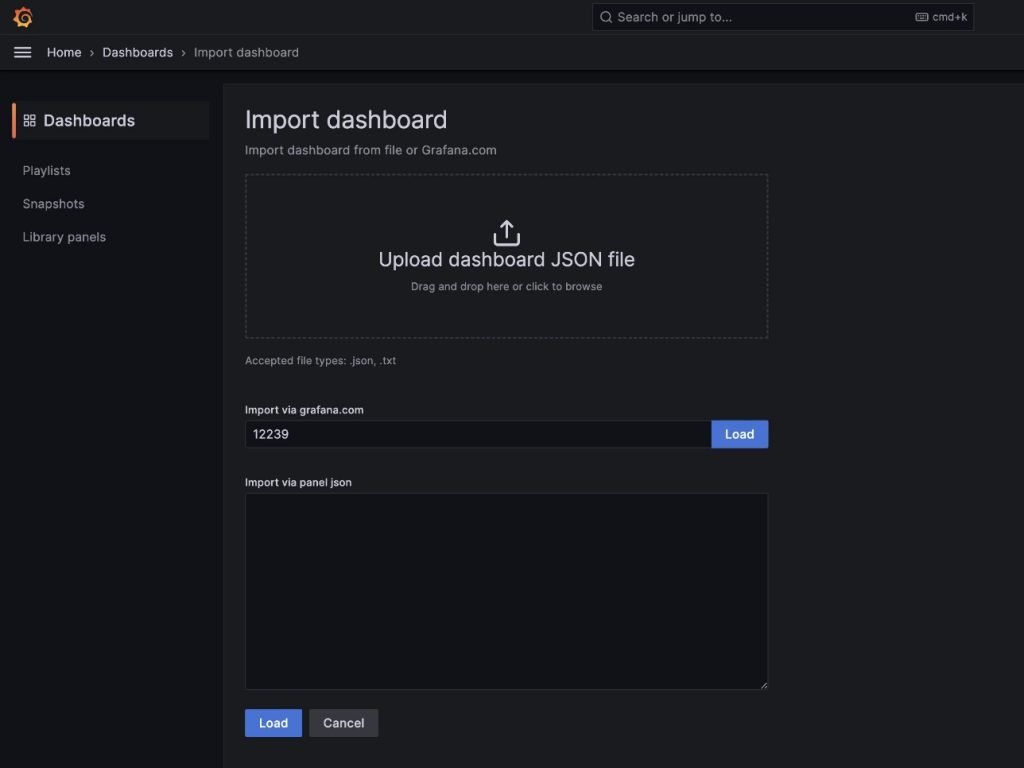
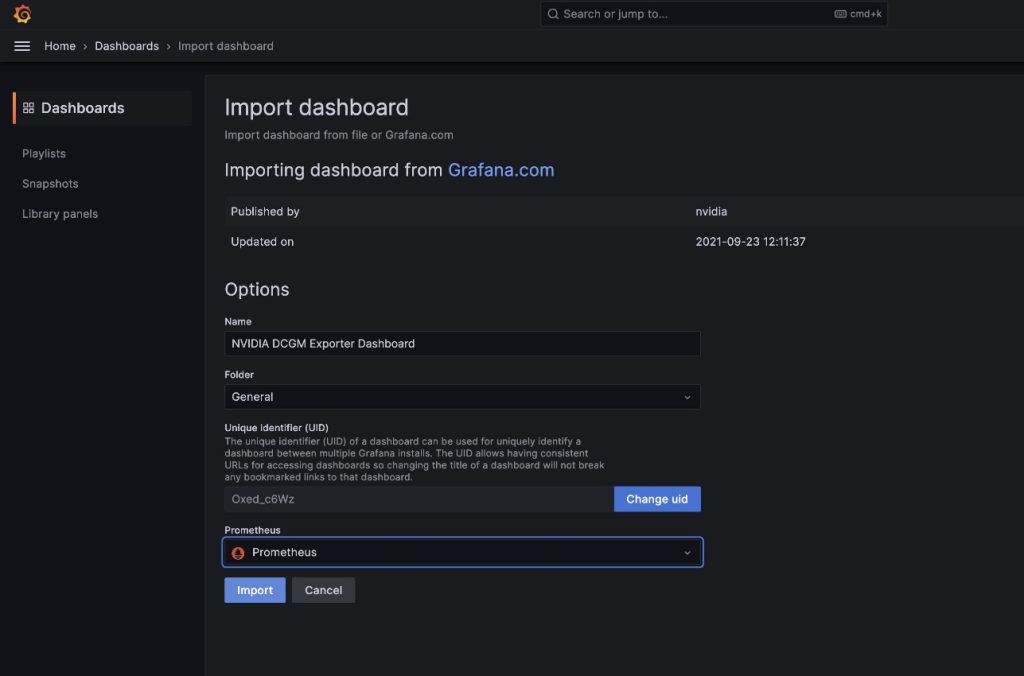
We are going to import the default DCGM Grafana dashboard described in NVIDIA DCGM Exporter Dashboard.
- In the field
import via grafana.com, enter 12239 and choose Load
- Choose Prometheus as the data source
- Choose Import
You will see a dashboard similar to the one in the following screenshot.
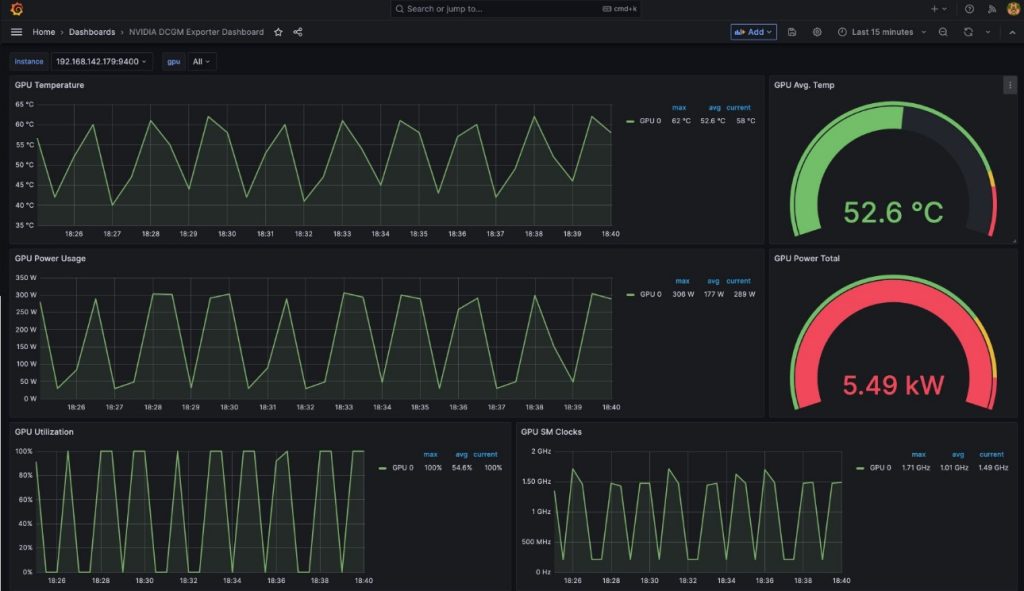
To demonstrate that these metrics are pod-based, we are going to modify the GPU Utilization pane in this dashboard.
- Choose the pane and the options menu (three dots)
- Expand the Options section and edit the Legend field
- Replace the value there with
Pod {{pod}}, then choose Save
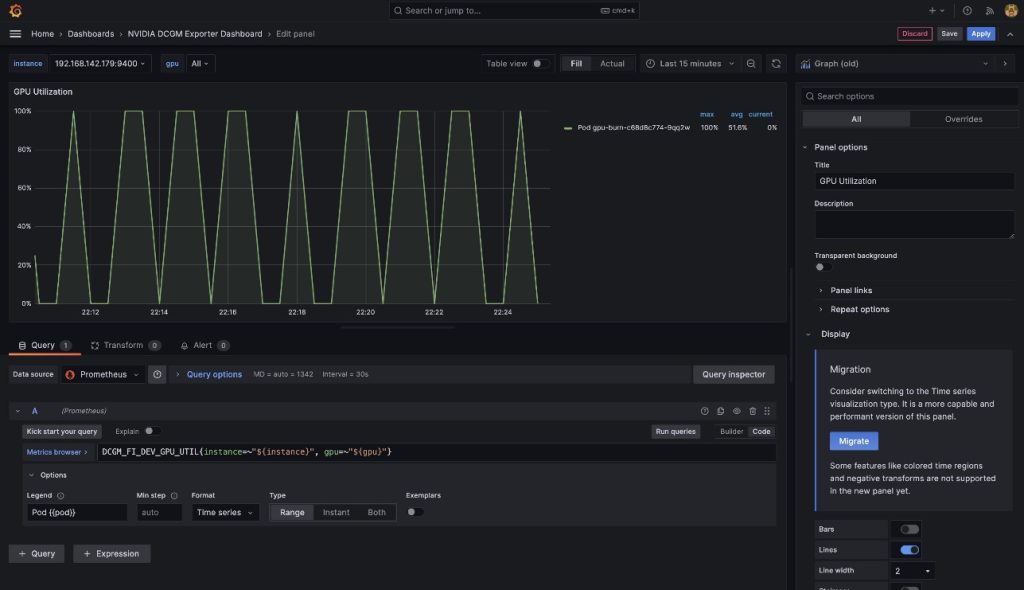
The legend now shows the gpu-burn pod name associated with the displayed GPU utilization.
- Stop port-forwarding the Grafana UI service
Run the following in your host shell:
kill -9 $(ps -aef | grep port-forward | grep -v grep | grep prometheus | awk '{print $2}')
In this post, we demonstrated using open-source Prometheus and Grafana deployed to the EKS cluster. If desired, this deployment can be substituted with Amazon Managed Service for Prometheus and Amazon Managed Grafana.
Clean up
To clean up the resources you created, run the following script from the aws-do-eks container shell:
Conclusion
In this post, we utilized NVIDIA DCGM Exporter to collect GPU metrics and visualize them with either CloudWatch or Prometheus and Grafana. We invite you to use the architectures demonstrated here to enable GPU utilization monitoring with NVIDIA DCGM in your own AWS environment.
Additional resources
About the authors
 Amr Ragab is a former Principal Solutions Architect, EC2 Accelerated Computing at AWS. He is devoted to helping customers run computational workloads at scale. In his spare time, he likes traveling and finding new ways to integrate technology into daily life.
Amr Ragab is a former Principal Solutions Architect, EC2 Accelerated Computing at AWS. He is devoted to helping customers run computational workloads at scale. In his spare time, he likes traveling and finding new ways to integrate technology into daily life.
 Alex Iankoulski is a Principal Solutions Architect, Self-managed Machine Learning at AWS. He’s a full-stack software and infrastructure engineer who likes to do deep, hands-on work. In his role, he focuses on helping customers with containerization and orchestration of ML and AI workloads on container-powered AWS services. He is also the author of the open-source do framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges. During the past 10 years, Alex has worked on democratizing AI and ML, combating climate change, and making travel safer, healthcare better, and energy smarter.
Alex Iankoulski is a Principal Solutions Architect, Self-managed Machine Learning at AWS. He’s a full-stack software and infrastructure engineer who likes to do deep, hands-on work. In his role, he focuses on helping customers with containerization and orchestration of ML and AI workloads on container-powered AWS services. He is also the author of the open-source do framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges. During the past 10 years, Alex has worked on democratizing AI and ML, combating climate change, and making travel safer, healthcare better, and energy smarter.
 Keita Watanabe is a Senior Solutions Architect of Frameworks ML Solutions at Amazon Web Services where he helps develop the industry’s best cloud based Self-managed Machine Learning solutions. His background is in Machine Learning research and development. Prior to joining AWS, Keita was working in the e-commerce industry. Keita holds a Ph.D. in Science from the University of Tokyo.
Keita Watanabe is a Senior Solutions Architect of Frameworks ML Solutions at Amazon Web Services where he helps develop the industry’s best cloud based Self-managed Machine Learning solutions. His background is in Machine Learning research and development. Prior to joining AWS, Keita was working in the e-commerce industry. Keita holds a Ph.D. in Science from the University of Tokyo.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- ChartPrime. Elevate your Trading Game with ChartPrime. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/enable-pod-based-gpu-metrics-in-amazon-cloudwatch/

