Generative KI hat im Bereich KI viel Potenzial eröffnet. Wir sehen zahlreiche Einsatzmöglichkeiten, darunter Textgenerierung, Codegenerierung, Zusammenfassung, Übersetzung, Chatbots und mehr. Ein solcher Bereich, der sich weiterentwickelt, ist die Verwendung natürlicher Sprachverarbeitung (NLP), um neue Möglichkeiten für den Zugriff auf Daten durch intuitive SQL-Abfragen zu erschließen. Anstatt sich mit komplexem technischen Code auseinanderzusetzen, können Geschäftsanwender und Datenanalysten Fragen zu Daten und Erkenntnissen in einfacher Sprache stellen. Das Hauptziel besteht darin, automatisch SQL-Abfragen aus Text in natürlicher Sprache zu generieren. Dazu wird die Texteingabe in eine strukturierte Darstellung umgewandelt und aus dieser Darstellung eine SQL-Abfrage erstellt, mit der auf eine Datenbank zugegriffen werden kann.
In diesem Beitrag bieten wir eine Einführung in Text to SQL (Text2SQL) und untersuchen Anwendungsfälle, Herausforderungen, Entwurfsmuster und Best Practices. Konkret besprechen wir Folgendes:
- Warum brauchen wir Text2SQL?
- Schlüsselkomponenten für Text to SQL
- Schnelle technische Überlegungen für natürliche Sprache oder Text zu SQL
- Optimierungen und Best Practices
- Architekturmuster
Warum brauchen wir Text2SQL?
Heutzutage sind in herkömmlichen Datenanalysen, Data Warehousing und Datenbanken große Datenmengen verfügbar, die für die Mehrheit der Organisationsmitglieder möglicherweise nicht einfach abzufragen oder zu verstehen sind. Das Hauptziel von Text2SQL besteht darin, abfragende Datenbanken für technisch nicht versierte Benutzer zugänglicher zu machen, die ihre Abfragen in natürlicher Sprache stellen können.
Mit NLP SQL können Geschäftsanwender Daten analysieren und Antworten erhalten, indem sie Fragen in natürlicher Sprache eingeben oder sprechen, wie zum Beispiel die folgenden:
- „Gesamtverkäufe für jedes Produkt im letzten Monat anzeigen“
- „Welche Produkte haben mehr Umsatz generiert?“
- „Wie viel Prozent der Kunden kommen aus den einzelnen Regionen?“
Amazonas Grundgestein ist ein vollständig verwalteter Dienst, der über eine einzige API eine Auswahl an leistungsstarken Basismodellen (FMs) bietet und so die einfache Erstellung und Skalierung von Gen-KI-Anwendungen ermöglicht. Es kann genutzt werden, um SQL-Abfragen basierend auf Fragen zu generieren, die den oben aufgeführten ähneln, organisatorische strukturierte Daten abzufragen und Antworten in natürlicher Sprache aus den Abfrage-Antwortdaten zu generieren.
Schlüsselkomponenten für Text zu SQL
Text-to-SQL-Systeme umfassen mehrere Schritte, um Abfragen in natürlicher Sprache in ausführbares SQL umzuwandeln:
- Verarbeitung natürlicher Sprache:
- Analysieren Sie die Eingabeabfrage des Benutzers
- Extrahieren Sie Schlüsselelemente und Absichten
- In ein strukturiertes Format konvertieren
- SQL-Generierung:
- Ordnen Sie extrahierte Details der SQL-Syntax zu
- Generieren Sie eine gültige SQL-Abfrage
- Datenbankabfrage:
- Führen Sie die von der KI generierte SQL-Abfrage in der Datenbank aus
- Ergebnisse abrufen
- Geben Sie Ergebnisse an den Benutzer zurück
Eine bemerkenswerte Fähigkeit von Large Language Models (LLMs) ist die Generierung von Code, einschließlich Structured Query Language (SQL) für Datenbanken. Diese LLMs können genutzt werden, um die Frage in natürlicher Sprache zu verstehen und eine entsprechende SQL-Abfrage als Ausgabe zu generieren. Die LLMs werden von der Übernahme kontextbezogener Lern- und Feinabstimmungseinstellungen profitieren, wenn mehr Daten bereitgestellt werden.
Das folgende Diagramm veranschaulicht einen grundlegenden Text2SQL-Ablauf.

Schnelle technische Überlegungen für natürliche Sprache in SQL
Die Eingabeaufforderung ist von entscheidender Bedeutung, wenn LLMs zum Übersetzen natürlicher Sprache in SQL-Abfragen verwendet werden, und es gibt mehrere wichtige Überlegungen für die Eingabeaufforderungsentwicklung.
Effektiv schnelles Engineering ist der Schlüssel zur Entwicklung natürlicher Sprache für SQL-Systeme. Klare, unkomplizierte Eingabeaufforderungen bieten bessere Anweisungen für das Sprachmodell. Durch die Angabe des Kontexts, dass der Benutzer eine SQL-Abfrage anfordert, zusammen mit relevanten Datenbankschemadetails kann das Modell die Absicht genau übersetzen. Das Einbeziehen einiger kommentierter Beispiele natürlichsprachlicher Eingabeaufforderungen und entsprechender SQL-Abfragen hilft dem Modell dabei, eine syntaxkonforme Ausgabe zu erzeugen. Darüber hinaus verbessert die Integration von Retrieval Augmented Generation (RAG), bei dem das Modell während der Verarbeitung ähnliche Beispiele abruft, die Zuordnungsgenauigkeit weiter. Gut gestaltete Eingabeaufforderungen, die dem Modell ausreichend Anweisungen, Kontext, Beispiele und Abruferweiterungen bieten, sind für die zuverlässige Übersetzung natürlicher Sprache in SQL-Abfragen von entscheidender Bedeutung.
Im Folgenden finden Sie ein Beispiel für eine Baseline-Eingabeaufforderung mit Codedarstellung der Datenbank aus dem Whitepaper Verbesserung der Few-Shot-Text-to-SQL-Fähigkeiten großer Sprachmodelle: Eine Studie zu Prompt-Design-Strategien.
Wie in diesem Beispiel veranschaulicht, stellt das auf Eingabeaufforderungen basierende Lernen mit wenigen Schüssen dem Modell eine Handvoll annotierter Beispiele in der Eingabeaufforderung selbst zur Verfügung. Dies demonstriert die Zielzuordnung zwischen natürlicher Sprache und SQL für das Modell. Normalerweise enthält die Eingabeaufforderung etwa zwei bis drei Paare, die eine Abfrage in natürlicher Sprache und die entsprechende SQL-Anweisung anzeigen. Diese wenigen Beispiele helfen dem Modell, syntaxkonforme SQL-Abfragen aus natürlicher Sprache zu generieren, ohne dass umfangreiche Trainingsdaten erforderlich sind.
Feinabstimmung vs. zeitnahes Engineering
Wenn wir natürliche Sprache in SQL-Systeme integrieren, diskutieren wir oft darüber, ob die Feinabstimmung des Modells die richtige Technik ist oder ob effektives Prompt Engineering der richtige Weg ist. Beide Ansätze könnten auf der Grundlage der richtigen Anforderungen in Betracht gezogen und ausgewählt werden:
-
- Feintuning – Das Basismodell wird auf einem großen allgemeinen Textkorpus vorab trainiert und kann dann verwendet werden anleitungsbasierte Feinabstimmung, das beschriftete Beispiele verwendet, um die Leistung eines vorab trainierten Basismodells für Text-SQL zu verbessern. Dadurch wird das Modell an die Zielaufgabe angepasst. Durch die Feinabstimmung wird das Modell direkt auf die Endaufgabe trainiert, es sind jedoch viele Text-SQL-Beispiele erforderlich. Sie können eine überwachte Feinabstimmung basierend auf Ihrem LLM verwenden, um die Effektivität von Text-to-SQL zu verbessern. Hierfür können Sie mehrere Datensätze verwenden, z Spiders, WikiSQL, VERFOLGUNGSJAGD, BIRD-SQL, oder CoSQL.
- Schnelles Engineering – Das Modell ist darauf trainiert, Eingabeaufforderungen auszuführen, die darauf ausgelegt sind, die Ziel-SQL-Syntax aufzufordern. Bei der Generierung von SQL aus natürlicher Sprache mithilfe von LLMs ist die Bereitstellung klarer Anweisungen in der Eingabeaufforderung wichtig, um die Ausgabe des Modells zu steuern. In der Eingabeaufforderung können Sie verschiedene Komponenten mit Anmerkungen versehen, z. B. Verweise auf Spalten und Schemata, und dann angeben, welcher SQL-Typ erstellt werden soll. Diese fungieren wie Anweisungen, die dem Modell mitteilen, wie die SQL-Ausgabe formatiert werden soll. Die folgende Eingabeaufforderung zeigt ein Beispiel, in dem Sie auf Tabellenspalten zeigen und anweisen, eine MySQL-Abfrage zu erstellen:
Ein effektiver Ansatz für Text-zu-SQL-Modelle besteht darin, zunächst mit einem Basis-LLM ohne aufgabenspezifische Feinabstimmung zu beginnen. Gut gestaltete Eingabeaufforderungen können dann verwendet werden, um das Basismodell anzupassen und zu steuern, um die Text-zu-SQL-Zuordnung zu handhaben. Dieses zeitnahe Engineering ermöglicht es Ihnen, die Fähigkeit zu entwickeln, ohne eine Feinabstimmung vornehmen zu müssen. Wenn das Prompt-Engineering auf dem Basismodell keine ausreichende Genauigkeit erreicht, kann die Feinabstimmung anhand eines kleinen Satzes von Text-SQL-Beispielen zusammen mit weiterem Prompt-Engineering untersucht werden.
Die Kombination aus Feinabstimmung und schnellem Engineering kann erforderlich sein, wenn das schnelle Engineering auf dem vorab trainierten Rohmodell allein die Anforderungen nicht erfüllt. Allerdings ist es am besten, zunächst ein schnelles Engineering ohne Feinabstimmung zu versuchen, da dies eine schnelle Iteration ohne Datenerfassung ermöglicht. Sollte dies nicht zu einer ausreichenden Leistung führen, ist eine Feinabstimmung zusammen mit einem zeitnahen Engineering ein sinnvoller nächster Schritt. Dieser Gesamtansatz maximiert die Effizienz und ermöglicht gleichzeitig eine Anpassung, wenn rein auf Eingabeaufforderungen basierende Methoden nicht ausreichen.
Optimierung und Best Practices
Optimierung und Best Practices sind unerlässlich, um die Effektivität zu steigern und sicherzustellen, dass Ressourcen optimal genutzt werden und die richtigen Ergebnisse auf die bestmögliche Weise erzielt werden. Die Techniken helfen dabei, die Leistung zu verbessern, die Kosten zu kontrollieren und ein besseres Ergebnis zu erzielen.
Bei der Entwicklung von Text-to-SQL-Systemen mithilfe von LLMs können Optimierungstechniken die Leistung und Effizienz verbessern. Im Folgenden sind einige wichtige Bereiche aufgeführt, die es zu berücksichtigen gilt:
- Caching – Um die Latenz, Kostenkontrolle und Standardisierung zu verbessern, können Sie das analysierte SQL und die erkannten Abfrageaufforderungen vom Text-zu-SQL-LLM zwischenspeichern. Dadurch wird die erneute Verarbeitung wiederholter Abfragen vermieden.
- Netzwerk Performance – Zur Überwachung des Text-zu-SQL-LLM-Systems sollten Protokolle und Metriken rund um das Abfrageparsen, die Eingabeaufforderungserkennung, die SQL-Generierung und die SQL-Ergebnisse gesammelt werden. Dies bietet Sichtbarkeit für das Optimierungsbeispiel, indem die Eingabeaufforderung aktualisiert oder die Feinabstimmung mit einem aktualisierten Datensatz erneut überprüft wird.
- Materialisierte Ansichten vs. Tabellen – Materialisierte Ansichten können die SQL-Generierung vereinfachen und die Leistung für gängige Text-zu-SQL-Abfragen verbessern. Das direkte Abfragen von Tabellen kann zu komplexem SQL und auch zu Leistungsproblemen führen, einschließlich der ständigen Erstellung von Leistungstechniken wie Indizes. Darüber hinaus können Sie Performanceprobleme vermeiden, wenn dieselbe Tabelle gleichzeitig für andere Anwendungsbereiche verwendet wird.
- Aktualisierte Daten – Materialisierte Ansichten müssen nach einem Zeitplan aktualisiert werden, um die Daten für Text-zu-SQL-Abfragen auf dem neuesten Stand zu halten. Sie können Batch- oder inkrementelle Aktualisierungsansätze verwenden, um den Overhead auszugleichen.
- Zentraler Datenkatalog – Durch die Erstellung eines zentralisierten Datenkatalogs erhalten Sie einen zentralen Überblick über die Datenquellen einer Organisation und können LLMs bei der Auswahl geeigneter Tabellen und Schemata unterstützen, um genauere Antworten zu liefern. Vektor Einbettungen Aus einem zentralen Datenkatalog erstellte Dokumente können zusammen mit den angeforderten Informationen an ein LLM übermittelt werden, um relevante und präzise SQL-Antworten zu generieren.
Durch die Anwendung von Best Practices zur Optimierung wie Caching, Überwachung, materialisierte Ansichten, geplante Aktualisierungen und einen zentralen Katalog können Sie die Leistung und Effizienz von Text-to-SQL-Systemen mithilfe von LLMs erheblich verbessern.
Architekturmuster
Schauen wir uns einige Architekturmuster an, die für einen Text-zu-SQL-Workflow implementiert werden können.
Schnelles Engineering
Das folgende Diagramm veranschaulicht die Architektur zum Generieren von Abfragen mit einem LLM mithilfe von Prompt Engineering.
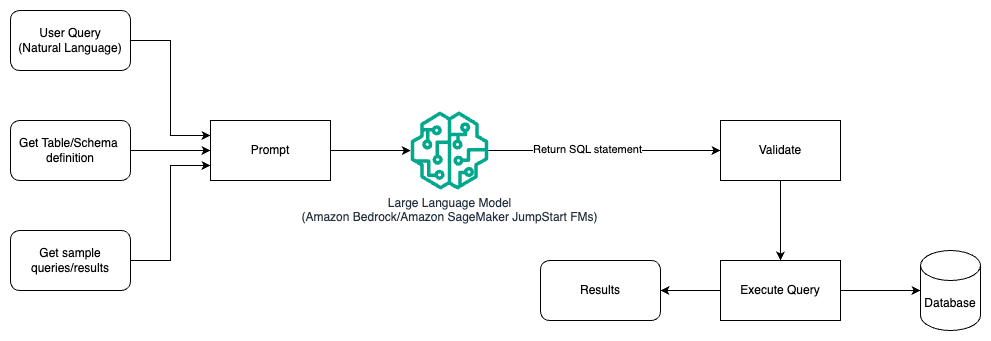
Bei diesem Muster erstellt der Benutzer ein auf Eingabeaufforderungen basierendes Lernen mit wenigen Schüssen, das dem Modell kommentierte Beispiele in der Eingabeaufforderung selbst bereitstellt, die die Tabellen- und Schemadetails sowie einige Beispielabfragen mit den Ergebnissen enthält. Das LLM verwendet die bereitgestellte Eingabeaufforderung, um das von der KI generierte SQL zurückzugeben, das validiert und dann in der Datenbank ausgeführt wird, um die Ergebnisse zu erhalten. Dies ist das einfachste Muster für den Einstieg in das Prompt Engineering. Hierfür können Sie verwenden Amazonas Grundgestein or Gründungsmodelle in Amazon SageMaker-JumpStart.
In diesem Muster erstellt der Benutzer ein auf Eingabeaufforderungen basierendes Fear-Shot-Learning, das dem Modell kommentierte Beispiele in der Eingabeaufforderung selbst bereitstellt, die die Tabellen- und Schemadetails sowie einige Beispielabfragen mit seinen Ergebnissen enthält. Das LLM verwendet die bereitgestellte Eingabeaufforderung, um das von der KI generierte SQL zurückzugeben, das validiert und in der Datenbank ausgeführt wird, um die Ergebnisse zu erhalten. Dies ist das einfachste Muster für den Einstieg in das Prompt Engineering. Hierfür können Sie verwenden Amazonas Grundgestein Hierbei handelt es sich um einen vollständig verwalteten Dienst, der über eine einzige API eine Auswahl an leistungsstarken Basismodellen (FMs) führender KI-Unternehmen sowie eine breite Palette an Funktionen bietet, die Sie zum Erstellen generativer KI-Anwendungen mit Sicherheit, Datenschutz und verantwortungsvoller KI benötigen oder JumpStart Foundation-Modelle das hochmoderne Grundmodelle für Anwendungsfälle wie Inhaltserstellung, Codegenerierung, Beantwortung von Fragen, Texterstellung, Zusammenfassung, Klassifizierung, Informationsabruf und mehr bietet
Schnelles Engineering und Feintuning
Das folgende Diagramm veranschaulicht die Architektur zum Generieren von Abfragen mit einem LLM unter Verwendung von Prompt Engineering und Feinabstimmung.
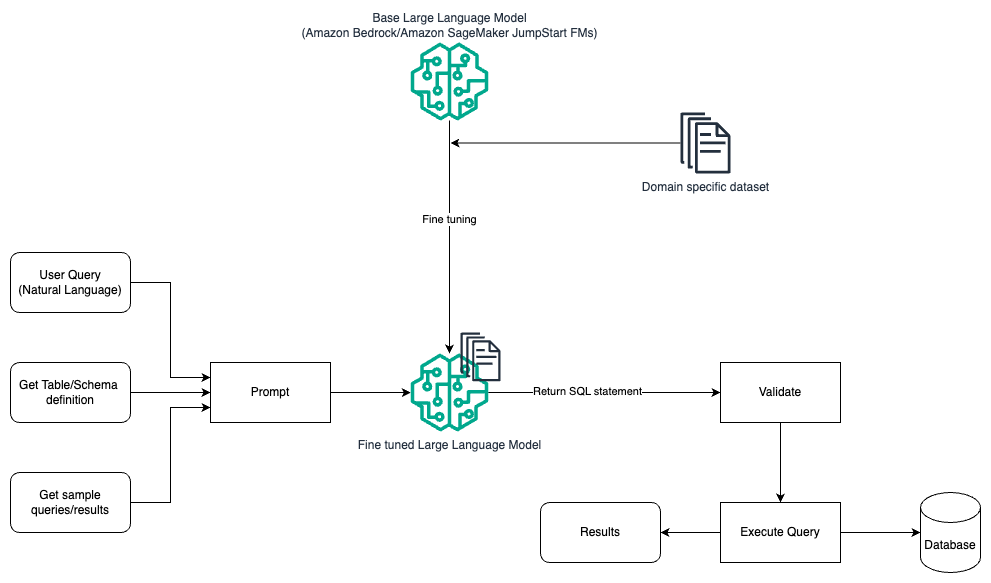
Dieser Ablauf ähnelt dem vorherigen Muster, das hauptsächlich auf schnellem Engineering basiert, jedoch mit einem zusätzlichen Ablauf zur Feinabstimmung des domänenspezifischen Datensatzes. Das fein abgestimmte LLM wird verwendet, um die SQL-Abfragen mit minimalem Kontextwert für die Eingabeaufforderung zu generieren. Zu diesem Zweck können Sie SageMaker JumpStart verwenden, um ein LLM für einen domänenspezifischen Datensatz auf die gleiche Weise zu optimieren, wie Sie jedes andere Modell trainieren und bereitstellen würden Amazon Sage Maker.
Prompt Engineering und RAG
Das folgende Diagramm veranschaulicht die Architektur zum Generieren von Abfragen mit einem LLM unter Verwendung von Prompt Engineering und RAG.
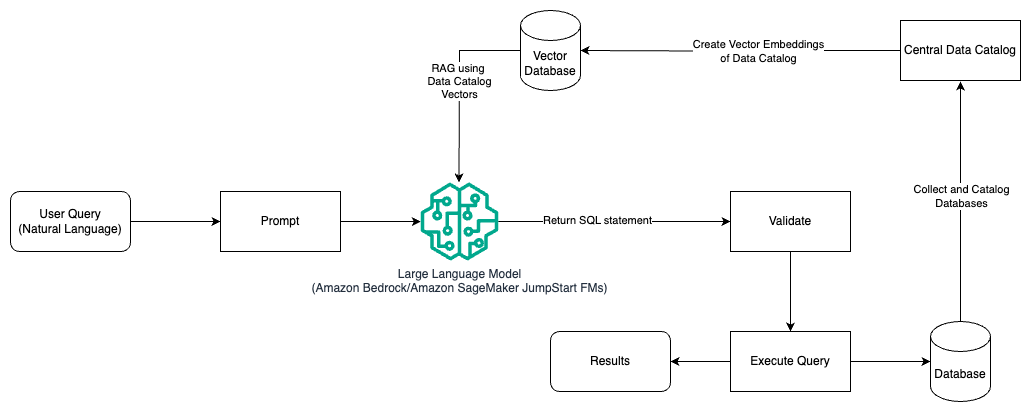
In diesem Muster verwenden wir Augmented Generation abrufen Verwenden von Stores für Vektoreinbettungen, z Amazon Titan-Einbettungen or Kohärente EinbettungAuf Amazonas Grundgestein aus einem zentralen Datenkatalog, z AWS-Kleber Datenkatalog, von Datenbanken innerhalb einer Organisation. Die Vektoreinbettungen werden in Vektordatenbanken gespeichert Vector Engine für Amazon OpenSearch Serverless, Amazon Relational Database Service (Amazon RDS) für PostgreSQL an. Nach der Installation können Sie HEIC-Dateien mit der pgvector Erweiterung, oder Amazon Kendra. LLMs nutzen die Vektoreinbettungen, um beim Erstellen von SQL-Abfragen schneller die richtige Datenbank, Tabellen und Spalten aus Tabellen auszuwählen. Die Verwendung von RAG ist hilfreich, wenn Daten und relevante Informationen, die von LLMs abgerufen werden müssen, in mehreren separaten Datenbanksystemen gespeichert sind und das LLM in der Lage sein muss, Daten aus all diesen verschiedenen Systemen zu suchen oder abzufragen. Hier führt die Bereitstellung von Vektoreinbettungen eines zentralisierten oder einheitlichen Datenkatalogs für die LLMs zu genaueren und umfassenderen Informationen, die von den LLMs zurückgegeben werden.
Zusammenfassung
In diesem Beitrag haben wir besprochen, wie wir mithilfe natürlicher Sprache und SQL-Generierung einen Mehrwert aus Unternehmensdaten generieren können. Wir haben uns mit Schlüsselkomponenten, Optimierung und Best Practices befasst. Wir haben auch Architekturmuster gelernt, vom grundlegenden Prompt Engineering bis hin zur Feinabstimmung und RAG. Weitere Informationen finden Sie unter Amazonas Grundgestein um generative KI-Anwendungen mit Basismodellen einfach zu erstellen und zu skalieren
Über die Autoren
 Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Im Jahr 2013 stieg ich in den Big-Data-Bereich ein und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Im Jahr 2013 stieg ich in den Big-Data-Bereich ein und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
 Nitin Eusebius ist Sr. Enterprise Solutions Architect bei AWS, erfahren in Software Engineering, Unternehmensarchitektur und KI/ML. Ihm liegt die Erforschung der Möglichkeiten generativer KI sehr am Herzen. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau gut strukturierter Anwendungen auf der AWS-Plattform zu helfen, und widmet sich der Lösung technologischer Herausforderungen und der Unterstützung bei ihrer Cloud-Reise.
Nitin Eusebius ist Sr. Enterprise Solutions Architect bei AWS, erfahren in Software Engineering, Unternehmensarchitektur und KI/ML. Ihm liegt die Erforschung der Möglichkeiten generativer KI sehr am Herzen. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau gut strukturierter Anwendungen auf der AWS-Plattform zu helfen, und widmet sich der Lösung technologischer Herausforderungen und der Unterstützung bei ihrer Cloud-Reise.
 Arghya Banerjee ist Senior Solutions Architect bei AWS in der San Francisco Bay Area und konzentriert sich darauf, Kunden bei der Einführung und Nutzung der AWS Cloud zu unterstützen. Arghya konzentriert sich auf Big Data, Data Lakes, Streaming, Batch Analytics sowie KI/ML-Dienste und -Technologien.
Arghya Banerjee ist Senior Solutions Architect bei AWS in der San Francisco Bay Area und konzentriert sich darauf, Kunden bei der Einführung und Nutzung der AWS Cloud zu unterstützen. Arghya konzentriert sich auf Big Data, Data Lakes, Streaming, Batch Analytics sowie KI/ML-Dienste und -Technologien.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

