Die Modebranche ist ein hoch lukratives Geschäft, mit einem geschätzten Wert von 2.1 Billionen US-Dollar bis 2025, wie von der Weltbank gemeldet. Dieser Bereich umfasst eine Vielzahl von Segmenten, wie z. B. die Kreation, Herstellung, den Vertrieb und den Verkauf von Bekleidung, Schuhen und Accessoires. Die Branche befindet sich in einem ständigen Wandel, wobei häufig neue Stile und Trends auftauchen. Daher müssen Modeunternehmen flexibel und anpassungsfähig sein, um ihre Relevanz zu erhalten und am Markt erfolgreich zu sein.
Generative künstliche Intelligenz (KI) bezieht sich auf KI-Algorithmen, die entwickelt wurden, um neue Inhalte wie Bilder, Text, Audio oder Video auf der Grundlage einer Reihe erlernter Muster und Daten zu generieren. Es kann verwendet werden, um neue und innovative Bekleidungsdesigns zu generieren und bietet gleichzeitig eine verbesserte Personalisierung und Kosteneffizienz. KI-gesteuerte Designtools können einzigartige Bekleidungsdesigns basierend auf Eingabeparametern oder Stilen erstellen, die von potenziellen Kunden durch Textaufforderungen angegeben werden. Darüber hinaus kann KI verwendet werden, um Designs an die Vorlieben des Kunden anzupassen. Beispielsweise könnte ein Kunde aus einer Vielzahl von Farben, Mustern und Stilen auswählen, und KI-Modelle würden auf der Grundlage dieser Auswahl ein einzigartiges Design erstellen. Die Einführung von KI in der Modebranche wird derzeit durch verschiedene technische, Machbarkeits- und Kostenherausforderungen behindert. Diese Hindernisse können jetzt jedoch durch den Einsatz fortschrittlicher generativer KI-Methoden wie der auf natürlicher Sprache basierenden semantischen Segmentierung und Diffusion von Bildern für das virtuelle Styling gemildert werden.
Dieser Blogbeitrag beschreibt die Implementierung von generativem KI-unterstütztem Mode-Online-Styling mithilfe von Texteingabeaufforderungen. Ingenieure für maschinelles Lernen (ML) können Text-zu-Semantik-Segmentierung und In-Painting-Modelle basierend auf vortrainiertem CLIPSeq und Stable Diffusion optimieren und bereitstellen Amazon Sage Maker. Dies ermöglicht Modedesignern und Verbrauchern, virtuelle Modellierungsbilder basierend auf Texteingabeaufforderungen zu erstellen und ihre bevorzugten Stile auszuwählen.
Generative KI-Lösungen
Das CLIPSeg model führte eine neuartige Methode zur semantischen Segmentierung von Bildern ein, mit der Sie Modeartikel in Bildern mit einfachen Textbefehlen leicht identifizieren können. Es verwendet eine Textaufforderung oder einen Bildcodierer, um Text- und visuelle Informationen in einen multimodalen Einbettungsraum zu codieren, wodurch eine hochgenaue Segmentierung von Zielobjekten basierend auf der Aufforderung ermöglicht wird. Das Modell wurde mit Techniken wie Zero-Shot-Transfer, Überwachung natürlicher Sprache und multimodalem selbstüberwachtem kontrastivem Lernen an einer großen Datenmenge trainiert. Das bedeutet, dass Sie ein vorab trainiertes Modell verwenden können, das öffentlich verfügbar ist Timo Lüddecke et al. ohne die Notwendigkeit einer Anpassung.
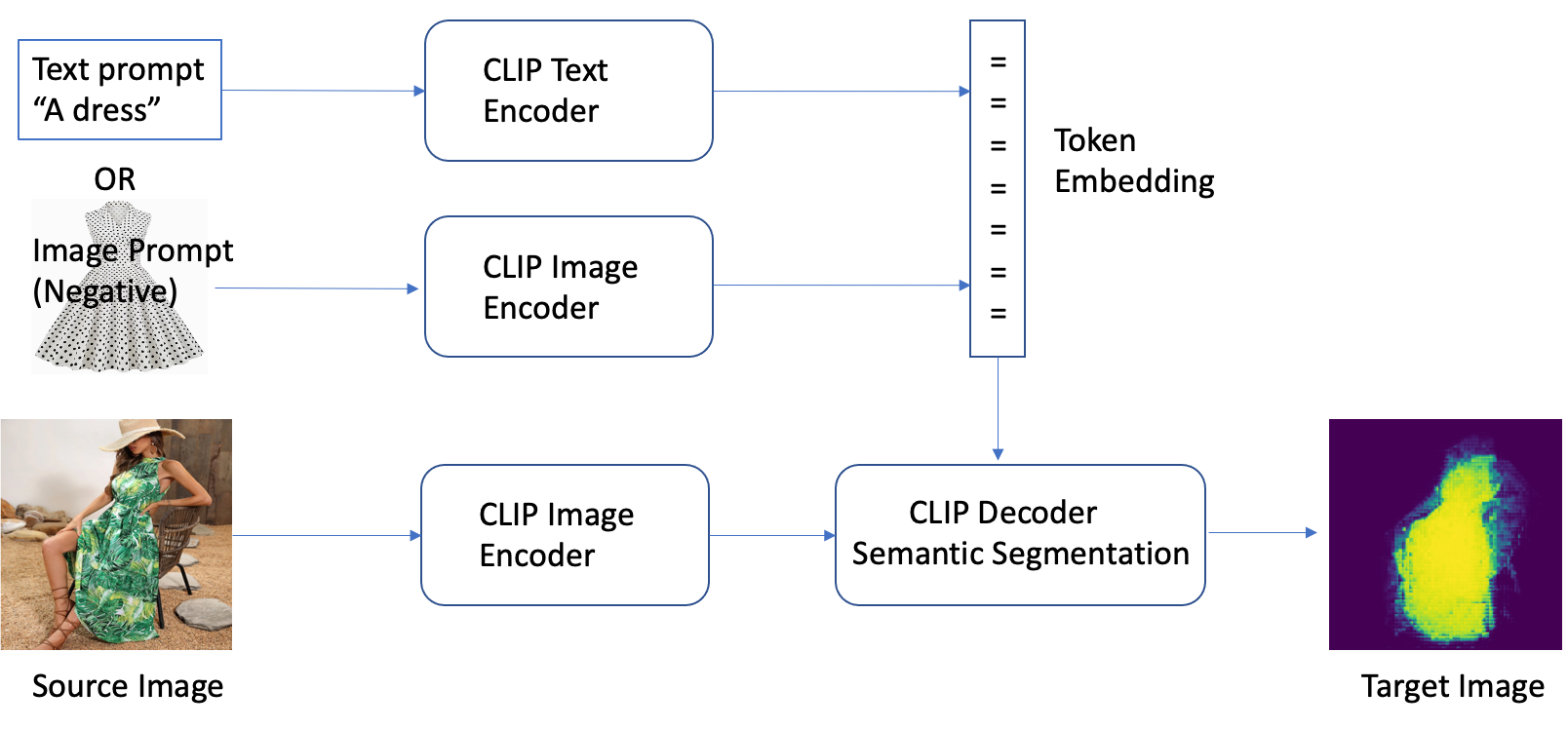
CLIPSeg ist ein Modell, das einen Text- und Bildcodierer verwendet, um Text- und visuelle Informationen in einen multimodalen Einbettungsraum zu codieren, um eine semantische Segmentierung basierend auf einer Texteingabeaufforderung durchzuführen. Die Architektur von CLIPSeg besteht aus zwei Hauptkomponenten: einem Textkodierer und einem Bildkodierer. Der Textcodierer nimmt die Textaufforderung auf und wandelt sie in eine Texteinbettung um, während der Bildcodierer das Bild aufnimmt und es in eine Bildeinbettung umwandelt. Beide Einbettungen werden dann verkettet und durch eine vollständig verbundene Schicht geleitet, um die endgültige Segmentierungsmaske zu erzeugen.
Hinsichtlich des Datenflusses wird das Modell mit einem Datensatz von Bildern und entsprechenden Text-Prompts trainiert, wobei die Text-Prompts das zu segmentierende Zielobjekt beschreiben. Während des Trainingsprozesses werden der Textkodierer und der Bildkodierer optimiert, um die Zuordnung zwischen den Textaufforderungen und dem Bild zu lernen, um die endgültige Segmentierungsmaske zu erzeugen. Sobald das Modell trainiert ist, kann es einen neuen Text-Prompt und ein Bild aufnehmen und eine Segmentierungsmaske für das in dem Prompt beschriebene Objekt erzeugen.
Stable Diffusion ist eine Technik, die es Modedesignern ermöglicht, hochrealistische Bilder in großen Mengen ausschließlich auf der Grundlage von Textbeschreibungen zu erstellen, ohne dass langwierige und teure Anpassungen erforderlich sind. Dies ist vorteilhaft für Designer, die schnell Modestile erstellen möchten, und für Hersteller, die personalisierte Produkte zu geringeren Kosten herstellen möchten.
Das folgende Diagramm veranschaulicht die Architektur und den Datenfluss von Stable Diffusion.
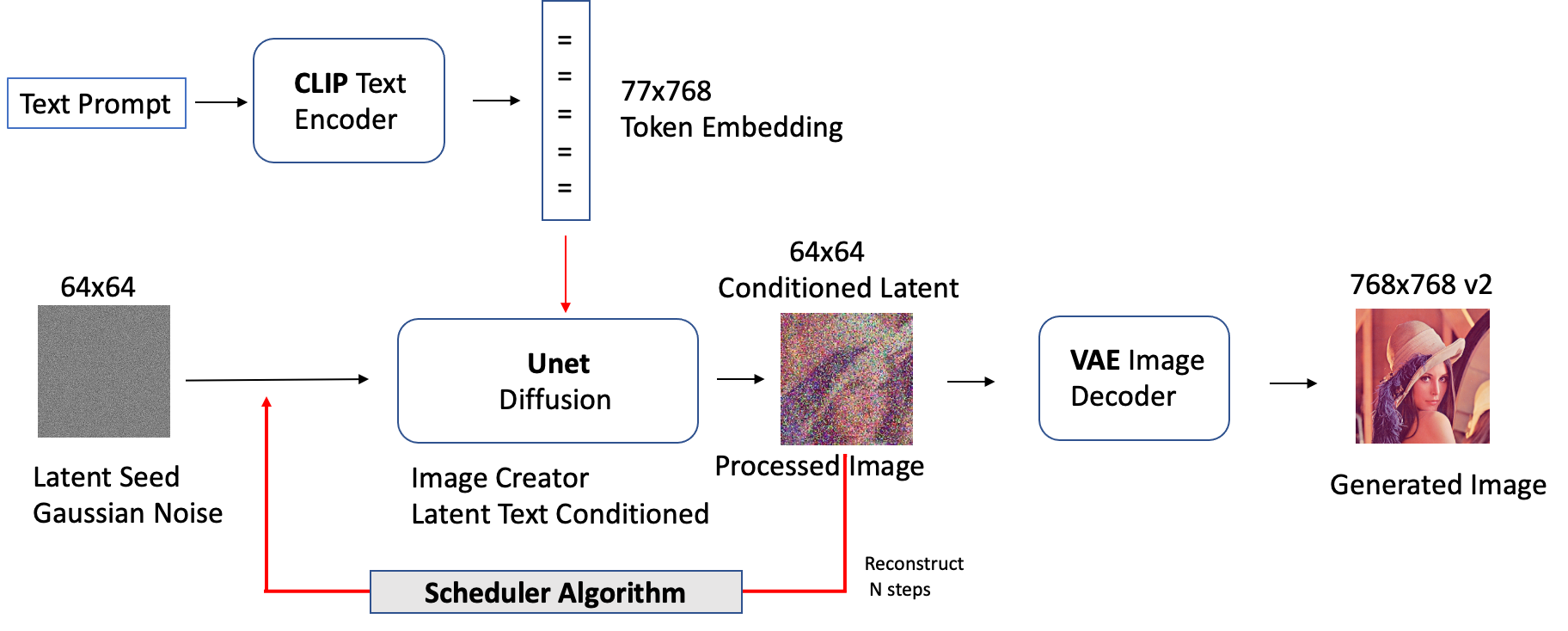
Im Vergleich zu herkömmlichen GAN-basierten Methoden ist Stable Diffusion eine generative KI, die in der Lage ist, stabilere und fotorealistischere Bilder zu erzeugen, die der Verteilung des Originalbildes entsprechen. Das Modell kann für eine Vielzahl von Zwecken konditioniert werden, wie z. B. Text für die Text-zu-Bild-Erzeugung, Begrenzungsrahmen für die Layout-zu-Bild-Erzeugung, maskierte Bilder zum In-Painting und Bilder mit niedrigerer Auflösung für Superauflösung. Diffusionsmodelle haben eine breite Palette von Geschäftsanwendungen, und ihre praktischen Anwendungen entwickeln sich ständig weiter. Von diesen Modellen werden verschiedene Branchen wie Mode, Einzelhandel und E-Commerce, Unterhaltung, soziale Medien, Marketing und mehr profitieren.
Generieren Sie Masken aus Texteingabeaufforderungen mit CLIPSeg
Vogue Online Styling ist ein Service, der es Kunden ermöglicht, Modeberatung und Empfehlungen von AI über eine Online-Plattform zu erhalten. Dies geschieht durch die Auswahl von Kleidung und Accessoires, die das Erscheinungsbild des Kunden ergänzen, in sein Budget passen und seinen persönlichen Vorlieben entsprechen. Durch den Einsatz von generativer KI können Aufgaben einfacher erledigt werden, was zu einer höheren Kundenzufriedenheit und geringeren Kosten führt.
Die Lösung kann auf einem bereitgestellt werden Amazon Elastic Compute-Cloud (EC2) p3.2xlarge-Instanz, die über eine einzelne V100-GPU mit 16 GB Speicher verfügt. Es wurden verschiedene Techniken eingesetzt, um die Leistung zu verbessern und die GPU-Speichernutzung zu reduzieren, was zu einer schnelleren Bilderzeugung führte. Dazu gehören die Verwendung von fp16 und die Aktivierung der speichereffizienten Aufmerksamkeit, um die Bandbreite im Aufmerksamkeitsblock zu verringern.
Wir begannen damit, den Benutzer ein Modebild hochladen zu lassen, gefolgt vom Herunterladen und Extrahieren des vortrainierten Modells von CLIPSeq. Das Bild wird dann normalisiert und in der Größe angepasst, um die Größenbeschränkung einzuhalten. Stable Diffusion V2 unterstützt eine Bildauflösung von bis zu 768 × 768, während V1 bis zu 512 × 512 unterstützt. Siehe folgenden Code:
from models.clipseg import CLIPDensePredT # The original image
image = download_image(img_url).resize((768, 768)) # Download pre-trained CLIPSeq model and unzip the pkg
! wget https://owncloud.gwdg.de/index.php/s/ioHbRzFx6th32hn/download -O weights.zip
! unzip -d weights -j weights.zip # Load CLIP model. Available models = ['RN50', 'RN101', 'RN50x4', # 'RN50x16', 'RN50x64', 'ViT-B/32', 'ViT-B/16', 'ViT-L/14', 'ViT-L/14@336px']
model = CLIPDensePredT(version='ViT-B/16', reduce_dim=64)
model.eval() # non-strict, because we only stored decoder weights (not CLIP weights)
model.load_state_dict(torch.load('weights/rd64-uni.pth', map_location=torch.device('cuda')), strict=False) # Image normalization and resizing
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), transforms.Resize((768, 768)),
])
img = transform(image).unsqueeze(0)Mithilfe des vortrainierten CLIPSeq-Modells können wir das Zielobjekt mithilfe einer Texteingabeaufforderung aus einem Bild extrahieren. Dies erfolgt durch Eingabe des Text-Prompts in den Text-Encoder, der ihn in eine Texteinbettung umwandelt. Das Bild wird dann in den Bildcodierer eingegeben, der es in eine Bildeinbettung umwandelt. Beide Einbettungen werden dann verkettet und durch eine vollständig verbundene Schicht geleitet, um die endgültige Segmentierungsmaske zu erzeugen, die das in der Texteingabeaufforderung beschriebene Zielobjekt hervorhebt. Siehe folgenden Code:
# Text prompt
prompt = 'Get the dress only.' # predict
mask_image_filename = 'the_mask_image.png'
with torch.no_grad(): preds = model(img.repeat(4,1,1,1), prompt)[0] # save the mask image after computing the area under the standard # Gaussian probability density function and calculates the cumulative # distribution function of the normal distribution with ndtr. plt.imsave(mask_image_filename,torch.special.ndtr(preds[0][0]))Mit dem genauen Maskenbild aus der semantischen Segmentierung können wir In-Painting für die Inhaltsersetzung verwenden. In-Painting ist der Prozess der Verwendung eines trainierten generativen Modells, um fehlende Teile eines Bildes auszufüllen. Indem wir das Maskenbild verwenden, um das Zielobjekt zu identifizieren, können wir die In-Painting-Technik anwenden, um das Zielobjekt durch etwas anderes zu ersetzen, wie z. B. ein anderes Kleidungsstück oder Accessoire. Das Stable Diffusion V2-Modell kann für diesen Zweck verwendet werden, da es in der Lage ist, hochauflösende, fotorealistische Bilder zu erzeugen, die der Verteilung des Originalbildes entsprechen.
Feinabstimmung von vortrainierten Modellen mit DreamBooth
Feinabstimmung ist ein Prozess im Deep Learning, bei dem ein vortrainiertes Modell anhand einer kleinen Menge gekennzeichneter Daten für eine neue Aufgabe weiter trainiert wird. Anstatt von Grund auf neu zu trainieren, besteht die Idee darin, ein Netzwerk, das bereits mit einem großen Datensatz für eine ähnliche Aufgabe trainiert wurde, mit einem neuen Datensatz weiter zu trainieren, um es für diese bestimmte Aufgabe zu spezialisieren.
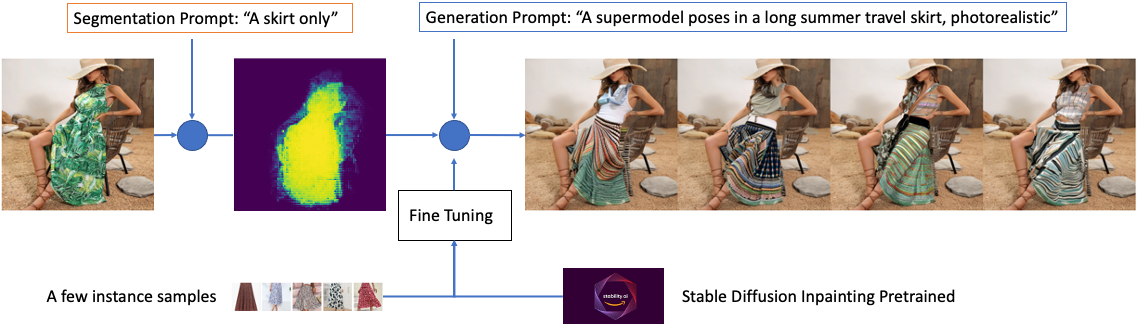
Modedesigner können auch ein themenorientiertes, fein abgestimmtes Stable Diffusion-In-Painting-Modell verwenden, um eine bestimmte Stilklasse zu erzeugen, z. B. lässige lange Röcke für Damen. Dazu besteht der erste Schritt darin, eine Reihe von Beispielbildern in der Zieldomäne bereitzustellen, ungefähr 1 Dutzend, mit geeigneten Textetiketten wie den folgenden und sie an eine eindeutige Kennung zu binden, die auf Design, Stil, Farbe und Stoff verweist . Die Beschriftung des Textes spielt eine entscheidende Rolle bei der Bestimmung der Ergebnisse des feinabgestimmten Modells. Es gibt mehrere Möglichkeiten, die Feinabstimmung durch Effektivierung zu verbessern schnelles Engineering und hier sind ein paar beispiele.
Sample text prompts to descibe some of the most common design elements of casual long skirts for ladies: Design Style: A-line, wrap, maxi, mini, and pleated skirts are some of the most popular styles for casual wear. A-line skirts are fitted at the waist and flare out at the hem, creating a flattering silhouette. Wrap skirts have a wrap closure and can be tied at the waist for a customizable fit. Maxi skirts are long and flowy, while mini skirts are short and flirty. Pleated skirts have folds that add texture and movement to the garment.
Pattern: Casual skirts can feature a variety of patterns, including stripes, florals, polka dots, and solids. These patterns can range from bold and graphic to subtle and understated.
Colors: Casual skirts come in a range of colors, including neutral shades likeblack, white, and gray, as well as brighter hues like pink, red, and blue. Some skirts may also feature multiple colors in a single garment, such asa skirt with a bold pattern that incorporates several shades.
Fabrics: Common fabrics used in casual skirts include cotton, denim, linen, and rayon. These materials offer different levels of comfort and durability, making it easy to find a skirt that suits your personal style and needs.
Die Verwendung eines kleinen Satzes von Bildern zur Feinabstimmung von Stable Diffusion kann zu einer Überanpassung des Modells führen. DreamBooth[5] adressiert dies durch die Verwendung eines klassenspezifischen Vorerhaltungsverlusts. Es lernt in zwei Schritten, eine eindeutige Kennung mit diesem bestimmten Thema zu verknüpfen. Zunächst wird das niedrigauflösende Modell mit den Eingabebildern gepaart mit einer Texteingabeaufforderung feinabgestimmt, die eine eindeutige Kennung und den Namen der Klasse enthält, zu der das Subjekt gehört, z. B. „Rock“. In der Praxis bedeutet dies, dass die modellangepassten Bilder und die Bilder, die aus dem visuellen Prior der nicht feinabgestimmten Klasse abgetastet werden, gleichzeitig vorhanden sind. Diese vorbewahrenden Bilder werden abgetastet und unter Verwendung der Eingabeaufforderung „class noun“ gekennzeichnet. Zweitens werden die superhochauflösenden Komponenten feinabgestimmt, indem niedrigauflösende und hochaufgelöste Bilder aus dem Eingabebildsatz gepaart werden, wodurch die Ausgaben des feinabgestimmten Modells die Treue zu kleinen Details beibehalten können.
Die Feinabstimmung eines vortrainierten In-Painting-Textcodierers mit dem UNet für Bilder mit einer Auflösung von 512 × 512 erfordert ungefähr 22 GB VRAM oder mehr für eine Auflösung von 768 × 768. Im Idealfall sollten feinabgestimmte Proben in der Größe angepasst werden, um sie an die gewünschte Ausgabebildauflösung anzupassen, um Leistungseinbußen zu vermeiden. Der Text-Encoder erzeugt genauere Details wie Modellgesichter. Eine Option ist die Ausführung auf einer einzelnen AWS EC2 g5.2xlarge-Instance, jetzt verfügbar in acht Regionen oder verwenden Sie Hugging Face Accelerate, um den fein abgestimmten Code in einer verteilten Konfiguration auszuführen. Für zusätzliche Speichereinsparungen können Sie eine Sliced-Version von Attention wählen, die die Berechnung in Schritten statt auf einmal durchführt, indem Sie einfach das Trainingsskript train_dreambooth_inpaint.py von DreamBooth ändern, um die Pipeline-Funktion enable_attention_slicing() hinzuzufügen.
Accelerate ist eine Bibliothek, die es ermöglicht, einen Code zur Feinabstimmung über jede verteilte Konfiguration hinweg auszuführen. Hugging Face und Amazon eingeführt Hugging Face Deep Learning Container (DLCs) um Feinabstimmungsaufgaben über mehrere GPUs und Knoten hinweg zu skalieren. Sie können die Startkonfiguration für Amazon SageMaker mit einem einzigen CLI-Befehl konfigurieren.
# From your aws account, install the sagemaker sdk for Accelerate
pip install "accelerate[sagemaker]" --upgrade # Configure the launch configuration for Amazon SageMaker accelerate config # List and verify Accelerate configuration
accelerate env # Make necessary modification of the training script as the following to save # output on S3, if needed
# - torch.save('/opt/ml/model`)
# + accelerator.save('/opt/ml/model')Um einen Feinabstimmungsjob zu starten, überprüfen Sie die Konfiguration von Accelerate mit CLI und geben Sie die erforderlichen Trainingsargumente an, und verwenden Sie dann das folgende Shell-Skript.
# Instance images — Custom images that represents the specific # concept for dreambooth training. You should collect # high #quality images based on your use cases.
# Class images — Regularization images for prior-preservation # loss to prevent overfitting. You should generate these # images directly from the base pre-trained model. # You can choose to generate them on your own or generate # them on the fly when running the training script.
# # You can access train_dreambooth_inpaint.py from huggingface/diffuser export MODEL_NAME="stabilityai/stable-diffusion-2-inpainting"
export INSTANCE_DIR="/data/fashion/gowns/highres/"
export CLASS_DIR="/opt/data/fashion/generated_gowns/imgs"
export OUTPUT_DIR="/opt/model/diffuser/outputs/inpainting/" accelerate launch train_dreambooth_inpaint.py --pretrained_model_name_or_path=$MODEL_NAME --train_text_encoder --instance_data_dir=$INSTANCE_DIR --class_data_dir=$CLASS_DIR --output_dir=$OUTPUT_DIR --with_prior_preservation --prior_loss_weight=1.0 --instance_prompt="A supermodel poses in long summer travel skirt, photorealistic" --class_prompt="A supermodel poses in skirt, photorealistic" --resolution=512 --train_batch_size=1 --use_8bit_adam --gradient_checkpointing --learning_rate=2e-6 --lr_scheduler="constant" --lr_warmup_steps=0 --num_class_images=200 --max_train_steps=800Das fein abgestimmte In-Painting-Modell ermöglicht die Generierung spezifischerer Bilder zu der durch die Texteingabeaufforderung beschriebenen Modeklasse. Da es mit einer Reihe von hochauflösenden Bildern und Textanweisungen fein abgestimmt wurde, kann das Modell Bilder erstellen, die besser auf die Klasse zugeschnitten sind, z. B. formelle Abendkleider. Es ist wichtig zu beachten, dass die Ausgabebilder umso genauer und realistischer sind, je spezifischer die Klasse ist und je mehr Daten für die Feinabstimmung verwendet werden.
%tree -d ./finetuned-stable-diffusion-v2-1-inpainting
finetuned-stable-diffusion-v2-1-inpainting
├── 512-inpainting-ema.ckpt
├── feature_extractor
├── code
│ └──inference.py
│ ├──requirements.txt
├── scheduler
├── text_encoder ├── tokenizer
├── unet
└── vae
Stellen Sie ein fein abgestimmtes In-Painting-Modell mit SageMaker für die Inferenz bereit
Mit Amazon SageMaker können Sie die fein abgestimmten Stable Diffusion-Modelle für Echtzeit-Inferenz bereitstellen. Um das Modell hochzuladen Amazon Simple Storage-Dienst (S3) Für die Bereitstellung muss ein model.tar.gz-Archiv-Tarball erstellt werden. Stellen Sie sicher, dass das Archiv direkt alle Dateien enthält, nicht einen Ordner, der sie enthält. Der DreamBooth-Feinabstimmungsarchivordner sollte nach dem Beseitigen der intermittierenden Prüfpunkte wie folgt aussehen:
Der erste Schritt bei der Erstellung unseres Inferenz-Handlers umfasst die Erstellung der Datei inference.py. Diese Datei dient als zentraler Knotenpunkt zum Laden des Modells und zum Verarbeiten aller eingehenden Inferenzanforderungen. Nachdem das Modell geladen ist, wird die Funktion model_fn() ausgeführt. Wenn es erforderlich ist, eine Inferenz durchzuführen, wird die Funktion predict_fn() aufgerufen. Zusätzlich wird die decode_base64()-Funktion verwendet, um eine JSON-Zeichenfolge, die in der Nutzlast enthalten ist, in einen PIL-Bilddatentyp umzuwandeln.
%%writefile code/inference.py
import base64
import torch
from PIL import Image
from io import BytesIO
from diffusers import EulerDiscreteScheduler, StableDiffusionInpaintPipeline def decode_base64(base64_string): decoded_string = BytesIO(base64.b64decode(base64_string)) img = Image.open(decoded_string) return img def model_fn(model_dir): # Load stable diffusion and move it to the GPU scheduler = EulerDiscreteScheduler.from_pretrained(model_dir, subfolder="scheduler") pipe = StableDiffusionInpaintPipeline.from_pretrained(model_dir, scheduler=scheduler, revision="fp16", torch_dtype=torch.float16) pipe = pipe.to("cuda") pipe.enable_xformers_memory_efficient_attention() #pipe.enable_attention_slicing() return pipe def predict_fn(data, pipe): # get prompt & parameters prompt = data.pop("inputs", data) # Require json string input. Inference to convert imge to string. input_img = data.pop("input_img", data) mask_img = data.pop("mask_img", data) # set valid HP for stable diffusion num_inference_steps = data.pop("num_inference_steps", 25) guidance_scale = data.pop("guidance_scale", 6.5) num_images_per_prompt = data.pop("num_images_per_prompt", 2) image_length = data.pop("image_length", 512) # run generation with parameters generated_images = pipe( prompt, image = decode_base64(input_img), mask_image = decode_base64(mask_img), num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, num_images_per_prompt=num_images_per_prompt, height=image_length, width=image_length, #)["images"] # for Stabel Diffusion v1.x ).images # create response encoded_images = [] for image in generated_images: buffered = BytesIO() image.save(buffered, format="JPEG") encoded_images.append(base64.b64encode(buffered.getvalue()).decode()) return {"generated_images": encoded_images}
Um das Modell in einen Amazon S3-Bucket hochzuladen, muss zuerst ein model.tar.gz-Archiv erstellt werden. Es ist wichtig zu beachten, dass das Archiv direkt aus den Dateien bestehen sollte und nicht aus einem Ordner, der sie enthält. Die Datei sollte beispielsweise wie folgt aussehen:
import tarfile
import os # helper to create the model.tar.gz
def compress(tar_dir=None,output_file="model.tar.gz"): parent_dir=os.getcwd() os.chdir(tar_dir) with tarfile.open(os.path.join(parent_dir, output_file), "w:gz") as tar: for item in os.listdir('.'): print(item) tar.add(item, arcname=item) os.chdir(parent_dir) compress(str(model_tar)) # After we created the model.tar.gz archive we can upload it to Amazon S3. We will # use the sagemaker SDK to upload the model to our sagemaker session bucket.
from sagemaker.s3 import S3Uploader # upload model.tar.gz to s3
s3_model_uri=S3Uploader.upload(local_path="model.tar.gz", desired_s3_uri=f"s3://{sess.default_bucket()}/finetuned-stable-diffusion-v2-1-inpainting")Nachdem das Modellarchiv hochgeladen wurde, können wir es auf Amazon SageMaker bereitstellen, indem wir HuggingfaceModel für Echtzeit-Inferenz verwenden. Sie können den Endpunkt mit einer g4dn.xlarge-Instance hosten, die mit einer einzelnen NVIDIA Tesla T4-GPU mit 16 GB VRAM ausgestattet ist. Autoscaling kann aktiviert werden, um unterschiedliche Verkehrsanforderungen zu bewältigen. Informationen zum Integrieren von Autoscaling in Ihren Endpunkt finden Sie unter Going Production: Automatische Skalierung von Hugging Face Transformers mit Amazon SageMaker.
from sagemaker.huggingface.model import HuggingFaceModel # create Hugging Face Model Class
huggingface_model = HuggingFaceModel( model_data=s3_model_uri, # path to your model and script role=role, # iam role with permissions to create an Endpoint transformers_version="4.17", # transformers version used pytorch_version="1.10", # pytorch version used py_version='py38', # python version used
) # deploy the endpoint endpoint
predictor = huggingface_model.deploy( initial_instance_count=1, instance_type="ml.g4dn.xlarge" )Die Methode huggingface_model.deploy() gibt ein HuggingFacePredictor-Objekt zurück, das verwendet werden kann, um eine Inferenz anzufordern. Der Endpunkt erfordert ein JSON mit einem Eingabeschlüssel, der die Eingabeaufforderung für das Modell darstellt, um ein Bild zu generieren. Sie können die Generierung auch mit Parametern wie „num_inference_steps“, „guidance_scale“ und „num_images_per_prompt“ steuern. Die Funktion optimizer.predict() gibt einen JSON-Code mit dem Schlüssel „generated_images“ zurück, der die vier generierten Bilder als base64-codierte Zeichenfolgen enthält. Wir haben zwei Hilfsfunktionen hinzugefügt, decode_base64_to_image und display_images, um die Antwort zu decodieren und die Bilder anzuzeigen. Ersteres decodiert die base64-codierte Zeichenfolge und gibt ein PIL.Image-Objekt zurück, und letzteres zeigt eine Liste von PIL.Image-Objekten an. Siehe folgenden Code:
import PIL
from io import BytesIO
from IPython.display import display
import base64
import matplotlib.pyplot as plt
import json # Encoder to convert an image to json string
def encode_base64(file_name): with open(file_name, "rb") as image: image_string = base64.b64encode(bytearray(image.read())).decode() return image_string # Decode to to convert a json str to an image def decode_base64_image(base64_string): decoded_string = BytesIO(base64.b64decode(base64_string)) img = PIL.Image.open(decoded_string) return img # display PIL images as grid
def display_images(images=None,columns=3, width=100, height=100): plt.figure(figsize=(width, height)) for i, image in enumerate(images): plt.subplot(int(len(images) / columns + 1), columns, i + 1) plt.axis('off') plt.imshow(image) # Display images in a row/col grid
def image_grid(imgs, rows, cols): assert len(imgs) == rows*cols w, h = imgs[0].size grid = PIL.Image.new('RGB', size=(cols*w, rows*h)) grid_w, grid_h = grid.size for i, img in enumerate(imgs): grid.paste(img, box=(i%cols*w, i//cols*h)) return gridLassen Sie uns mit der In-Painting-Aufgabe fortfahren. Es wurde geschätzt, dass es ungefähr 15 Sekunden dauern wird, um drei Bilder zu erzeugen, wenn man das Eingangsbild und die mit CLIPSeg erstellte Maske mit der zuvor besprochenen Texteingabe voraussetzt. Siehe folgenden Code:
num_images_per_prompt = 3
prompt = "A female super-model poses in a casual long vacation skirt, with full body length, bright colors, photorealistic, high quality, highly detailed, elegant, sharp focus" # Convert image to string
input_image_filename = "./imgs/skirt-model-2.jpg"
encoded_input_image = encode_base64(input_image_filename)
encoded_mask_image = encode_base64("./imgs/skirt-model-2-mask.jpg") # Set in-painint parameters
guidance_scale = 6.7
num_inference_steps = 45 # run prediction
response = predictor.predict(data={ "inputs": prompt, "input_img": encoded_input_image, "mask_img": encoded_mask_image, "num_images_per_prompt" : num_images_per_prompt, "image_length": 768 }
) # decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]] # visualize generation
display_images(decoded_images, columns=num_images_per_prompt, width=100, height=100) # insert initial image in the list so we can compare side by side
image = PIL.Image.open(input_image_filename).convert("RGB")
decoded_images.insert(0, image) # Display inpainting images in grid
image_grid(decoded_images, 1, num_images_per_prompt + 1)
Die eingemalten Bilder können zusammen mit dem Originalbild zum visuellen Vergleich angezeigt werden. Zusätzlich kann der In-Painting-Prozess unter Verwendung verschiedener Parameter, wie beispielsweise guidance_scale, eingeschränkt werden, der die Stärke des Führungsbilds während des In-Painting-Prozesses steuert. Dadurch kann der Benutzer das Ausgabebild anpassen und die gewünschten Ergebnisse erzielen.
Amazon SageMaker-Jumpstart bietet stabile Diffusionsvorlagen für verschiedene Modelle, einschließlich Text-zu-Bild und Hochskalierung. Weitere Informationen finden Sie unter SageMaker JumpStart bietet jetzt stabile Diffusions- und Bloom-Modelle. Weitere Jumpstart-Vorlagen werden in Kürze verfügbar sein.
Einschränkungen
Obwohl CLIPSeg in der Regel gute Leistungen beim Erkennen gewöhnlicher Objekte erbringt, hat es bei abstrakteren oder systematischeren Aufgaben wie dem Zählen der Anzahl von Objekten in einem Bild und bei komplexeren Aufgaben wie der Vorhersage, wie nahe das nächste Objekt wie eine Handtasche auf einem Foto ist, Probleme. Zero-Shot CLIPSeq kämpft im Vergleich zu aufgabenspezifischen Modellen auch mit einer sehr feinkörnigen Klassifizierung, wie z. B. der Unterscheidung zwischen zwei vagen Designs, Kleidungsvarianten oder Stilklassifizierungen. CLIPSeq hat auch immer noch eine schlechte Verallgemeinerung auf Bilder, die nicht in seinem Pre-Training-Datensatz enthalten sind. Schließlich wurde beobachtet, dass die Zero-Shot-Klassifikatoren von CLIP empfindlich auf Formulierungen oder Formulierungen reagieren können und manchmal „Prompt Engineering“ durch Versuch und Irrtum erfordern, um gut zu funktionieren. Wechseln zu einem anderen semantischen Segmentierungsmodell für das Rückgrat von CLIPSeq, wie z Sei es, das im ADE62.8K-Datensatz 20 % mIOU aufweist, könnte die Ergebnisse möglicherweise verbessern.
Es wurde festgestellt, dass Modedesigns, die mit Stable Diffusion erstellt wurden, auf Teile von Kleidungsstücken beschränkt sind, die mindestens so vorhersehbar im breiteren Kontext der Modemodelle platziert sind und die hochgradigen Einbettungen entsprechen, die Sie vernünftigerweise erwarten können ein Hyperscale-Dataset, das während des Trainings des vorab trainierten Modells verwendet wird. Die wirkliche Grenze der generativen KI besteht darin, dass das Modell letztendlich völlig imaginäre und weniger authentische Ergebnisse produziert. Daher sind die von KI generierten Modedesigns möglicherweise nicht so vielfältig oder einzigartig wie die von menschlichen Designern erstellten.
Zusammenfassung
Generative KI bietet der Modebranche die Möglichkeit, ihre Praktiken durch bessere Benutzererfahrungen und kosteneffiziente Geschäftsstrategien zu transformieren. In diesem Beitrag zeigen wir, wie sich generative KI nutzen lässt, um Modedesignern und Verbrauchern die Möglichkeit zu geben, mithilfe virtueller Modellierung personalisierte Modestile zu erstellen. Mithilfe vorhandener und künftiger Amazon SageMaker-Jumpstart-Vorlagen können Benutzer diese fortschrittlichen Techniken schnell anwenden, ohne tiefgreifendes technisches Fachwissen zu benötigen, während gleichzeitig die Vielseitigkeit erhalten bleibt und die Kosten gesenkt werden.
Diese innovative Technologie bietet neue Möglichkeiten für Unternehmen und Fachleute, die an der Erstellung von Inhalten in verschiedenen Branchen beteiligt sind. Die generative KI bietet umfangreiche Möglichkeiten zur Verbesserung und Erstellung von Inhalten. Probieren Sie die neuesten Ergänzungen zu den Jumpstart-Vorlagen in Ihrem aus SageMaker-Studio, wie z. B. die Feinabstimmung von Text-zu-Bild und Upscale-Funktionen.
Wir möchten Li Zhang, Karl Albertsen, Kristine Pearce, Nikhil Velpanur, Aaron Sengstacken, James Wu und Neelam Koshiya für ihre Unterstützung und ihre wertvollen Beiträge danken, die zur Verbesserung dieser Arbeit beigetragen haben.
Über die Autoren
 Alfred Shen ist Senior AI/ML-Spezialist bei AWS. Er war im Silicon Valley tätig und hatte technische und leitende Positionen in verschiedenen Sektoren wie Gesundheitswesen, Finanzen und Hightech inne. Er ist ein engagierter Forscher für angewandte KI/ML, der sich auf CV, NLP und Multimodalität konzentriert. Seine Arbeit wurde in Publikationen wie EMNLP, ICLR und Public Health vorgestellt.
Alfred Shen ist Senior AI/ML-Spezialist bei AWS. Er war im Silicon Valley tätig und hatte technische und leitende Positionen in verschiedenen Sektoren wie Gesundheitswesen, Finanzen und Hightech inne. Er ist ein engagierter Forscher für angewandte KI/ML, der sich auf CV, NLP und Multimodalität konzentriert. Seine Arbeit wurde in Publikationen wie EMNLP, ICLR und Public Health vorgestellt.
 Vivek Madan ist ein angewandter Wissenschaftler im Amazon SageMaker JumpStart-Team. Er promovierte an der University of Illinois at Urbana-Champaign und war Postdoktorand an der Georgia Tech. Er ist ein aktiver Forscher in den Bereichen maschinelles Lernen und Algorithmendesign und hat Artikel auf Konferenzen von EMNLP, ICLR, COLT, FOCS und SODA veröffentlicht
Vivek Madan ist ein angewandter Wissenschaftler im Amazon SageMaker JumpStart-Team. Er promovierte an der University of Illinois at Urbana-Champaign und war Postdoktorand an der Georgia Tech. Er ist ein aktiver Forscher in den Bereichen maschinelles Lernen und Algorithmendesign und hat Artikel auf Konferenzen von EMNLP, ICLR, COLT, FOCS und SODA veröffentlicht
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/virtual-fashion-styling-with-generative-ai-using-amazon-sagemaker/

