几年前开始学习数据分析的时候,最先学的是SQL和Pandas。 作为一名数据分析师,拥有使用 SQL 和 Pandas 的坚实基础至关重要。 两者都是强大的工具,可以帮助数据分析师高效地分析和操作数据库中存储的数据。
SQL 和 Pandas 概述
SQL(结构化查询语言)是一种用于管理和操作关系数据库的编程语言。 另一方面,Pandas 是一个用于数据操作和分析的 Python 库。
数据分析涉及处理大量数据,而数据库通常用于存储这些数据。 SQL 和 Pandas 为处理数据库提供了强大的工具,使数据分析师能够高效地提取、操作和分析数据。 通过利用这些工具,数据分析师可以从数据中获得有价值的见解,否则很难获得这些见解。
在本文中,我们将探索如何使用 SQL 和 Pandas 来读写数据库。
连接到数据库
安装库
我们必须先安装必要的库,然后才能使用 Pandas 连接到 SQL 数据库。 所需的两个主要库是 Pandas 和 SQLAlchemy。 Pandas 是一种流行的数据操作库,它允许存储大型数据结构,如简介中所述。 相比之下,SQLAlchemy 提供了一个 API 用于连接到 SQL 数据库并与之交互。
我们可以使用 Python 包管理器 pip 安装这两个库,方法是在命令提示符下运行以下命令。
$ pip install pandas
$ pip install sqlalchemy
建立连接
安装库后,我们现在可以使用 Pandas 连接到 SQL 数据库。
首先,我们将创建一个 SQLAlchemy 引擎对象 create_engine()。 该 create_engine() 函数将 Python 代码连接到数据库。 它以指定数据库类型和连接详细信息的连接字符串作为参数。 在此示例中,我们将使用 SQLite 数据库类型和数据库文件的路径。
使用以下示例为 SQLite 数据库创建引擎对象:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db')
如果 SQLite 数据库文件,在我们的例子中是 student.db,与 Python 脚本位于同一目录中,我们可以直接使用文件名,如下所示。
engine = create_engine('sqlite:///student.db')
使用 Pandas 读取 SQL 文件
现在我们已经建立了连接,让我们读取数据。 在本节中,我们将查看 read_sql, read_sql_table及 read_sql_query 函数以及如何使用它们来处理数据库。
使用 Panda 执行 SQL 查询 读_sql() 功能
read_sql() 是一个 Pandas 库函数,它允许我们执行 SQL 查询并将结果检索到 Pandas 数据框中。 这 read_sql() 函数连接 SQL 和 Python,使我们能够利用这两种语言的强大功能。 函数换行 read_sql_table() 和 read_sql_query()。 该 read_sql() 函数根据提供的输入进行内部路由,这意味着如果输入是执行 SQL 查询,它将被路由到 read_sql_query(),如果它是数据库表,它将被路由到 read_sql_table().
read_sql() 语法如下:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
SQL 和 con 参数是必需的; 其余的是可选的。 但是,我们可以使用这些可选参数来操纵结果。 让我们仔细看看每个参数。
sql: SQL查询或数据库表名con: 连接对象或连接 URLindex_col:该参数允许我们使用 SQL 查询结果中的一个或多个列作为数据框索引。 它可以采用单个列或列列表。coerce_float:此参数指定是否应将非数字值转换为浮点数或保留为字符串。 它默认设置为 true。 如果可能,它会将非数字值转换为浮点类型。params: 参数提供了一种将动态值传递给 SQL 查询的安全方法。 我们可以使用 params 参数来传递字典、元组或列表。 根据数据库的不同,params 的语法会有所不同。parse_dates:这允许我们指定结果数据框中的哪一列将被解释为日期。 它接受单个列、列列表或以键作为列名称、以值作为列格式的字典。columns:这允许我们只从列表中获取选定的列。chunksize:在处理大型数据集时,chunksize 很重要。 它以较小的块检索查询结果,从而提高性能。
这是一个使用方法的例子 read_sql():
代码:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype) engine.dispose()
输出:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson [email protected] 2000-02-23
2 Peter Griffen [email protected] 2001-04-15
3 Meg Aniston [email protected] 2001-09-20
Date type of dateOfBirth: datetime64[ns]
连接到数据库后,我们执行一个查询,从中返回所有记录 Student 表并将它们存储在 DataFrame 中 df. “卷号”列使用 index_col 参数,并且“dateOfBirth”数据类型是“datetime64[ns]”由于 parse_dates. 我们可以用 read_sql() 不仅可以检索数据,还可以执行其他操作,例如插入、删除和更新。 read_sql() 是一个泛型函数。
从数据库加载特定表或视图
使用 Pandas 加载特定表或视图 read_sql_table() 是另一种将数据从数据库读取到 Pandas 数据框的技术。
什么是 读_sql_表?
Pandas 库提供了 read_sql_table 函数,专门设计用于在不执行任何查询的情况下读取整个 SQL 表并将结果作为 Pandas 数据框返回。
的语法 read_sql_table() 如下:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
除了 table_name 和模式,参数的解释方式与 read_sql().
table_name: 参数table_name是数据库中 SQL 表的名称。schema:此可选参数是包含表名的架构名称。
创建到数据库的连接后,我们将使用 read_sql_table 加载函数 Student 将表格放入 Pandas DataFrame 中。
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Student', engine)
print(df.head()) engine.dispose()
输出:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
1 2 Peter Griffen [email protected] 2001-04-15
2 3 Meg Aniston [email protected] 2001-09-20
我们假设它是一个可能会占用大量内存的大表。 让我们探索如何使用 chunksize 参数来解决这个问题。
查看我们的 Git 学习实践指南,其中包含最佳实践、行业认可的标准以及随附的备忘单。 停止谷歌搜索 Git 命令,实际上 学习 它!
代码:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df_iterator = pd.read_sql_table('Student', engine, chunksize = 1) for df in df_iterator: print(df.head()) engine.dispose()
输出:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
0 2 Peter Griffen [email protected] 2001-04-15
0 3 Meg Aniston [email protected] 2001-09-20
请记住, chunksize 我在这里使用的是 1,因为我的表中只有 3 条记录。
使用 Pandas 的 SQL 语法直接查询数据库
从数据库中提取见解是数据分析师和科学家的重要组成部分。 为此,我们将利用 read_sql_query() 功能。
什么是 read_sql_query()?
使用熊猫 read_sql_query() 函数,我们可以运行 SQL 查询并将结果直接放入 DataFrame 中。 这 read_sql_query() 函数是专门为创建的 SELECT 声明。 它不能用于任何其他操作,例如 DELETE or UPDATE.
语法:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
所有参数说明同 read_sql() 功能。 这是一个例子 read_sql_query():
代码:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df) engine.dispose()
输出:
firstName lastName
0 Mark Simson
使用 Pandas 编写 SQL 文件
在分析数据时,假设我们发现需要修改一些条目,或者需要一个包含数据的新表或视图。 要更新或插入新记录,一种方法是使用 read_sql() 并写一个查询。 但是,该方法可能很冗长。 Pandas 提供了一个很棒的方法,叫做 to_sql() 对于这样的情况。
在本节中,我们将首先在数据库中建立一个新表,然后编辑一个现有的表。
在 SQL 数据库中创建新表
在我们创建一个新表之前,让我们先讨论一下 to_sql() 详细。
什么是 to_sql()?
to_sql() Pandas 库的功能允许我们编写或更新数据库。 这 to_sql() 函数可以将DataFrame数据保存到SQL数据库中。
语法为 to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
只有 name 和 con 参数是必须运行的 to_sql(); 但是,其他参数提供了额外的灵活性和自定义选项。 让我们详细讨论每个参数:
name:要创建或更改的 SQL 表的名称。con: 数据库的连接对象。schema:表的架构(可选)。if_exists:该参数的默认值为“失败”。 如果表已经存在,此参数允许我们决定要采取的操作。 选项包括“失败”、“替换”和“追加”。index:索引参数接受一个布尔值。 默认情况下,它设置为 True,这意味着 DataFrame 的索引将被写入 SQL 表。index_label:这个可选参数允许我们为索引列指定列标签。 默认情况下,索引被写入表中,但可以使用此参数指定一个特定的名称。chunksize:SQL数据库中一次写入的行数。dtype:此参数接受一个字典,其中键作为列名,值作为它们的数据类型。method: 方法参数允许指定用于将数据插入到 SQL 中的方法。 默认情况下,它设置为 None,这意味着 pandas 将根据数据库找到最有效的方法。 方法参数有两个主要选项:multi: 它允许在单个 SQL 查询中插入多行。 但是,并非所有数据库都支持多行插入。- 可调用函数:在这里,我们可以编写一个用于插入的自定义函数,并使用方法参数调用它。
这是一个使用示例 to_sql():
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') data = {'Name': ['Paul', 'Tom', 'Jerry'], 'Age': [9, 8, 7]}
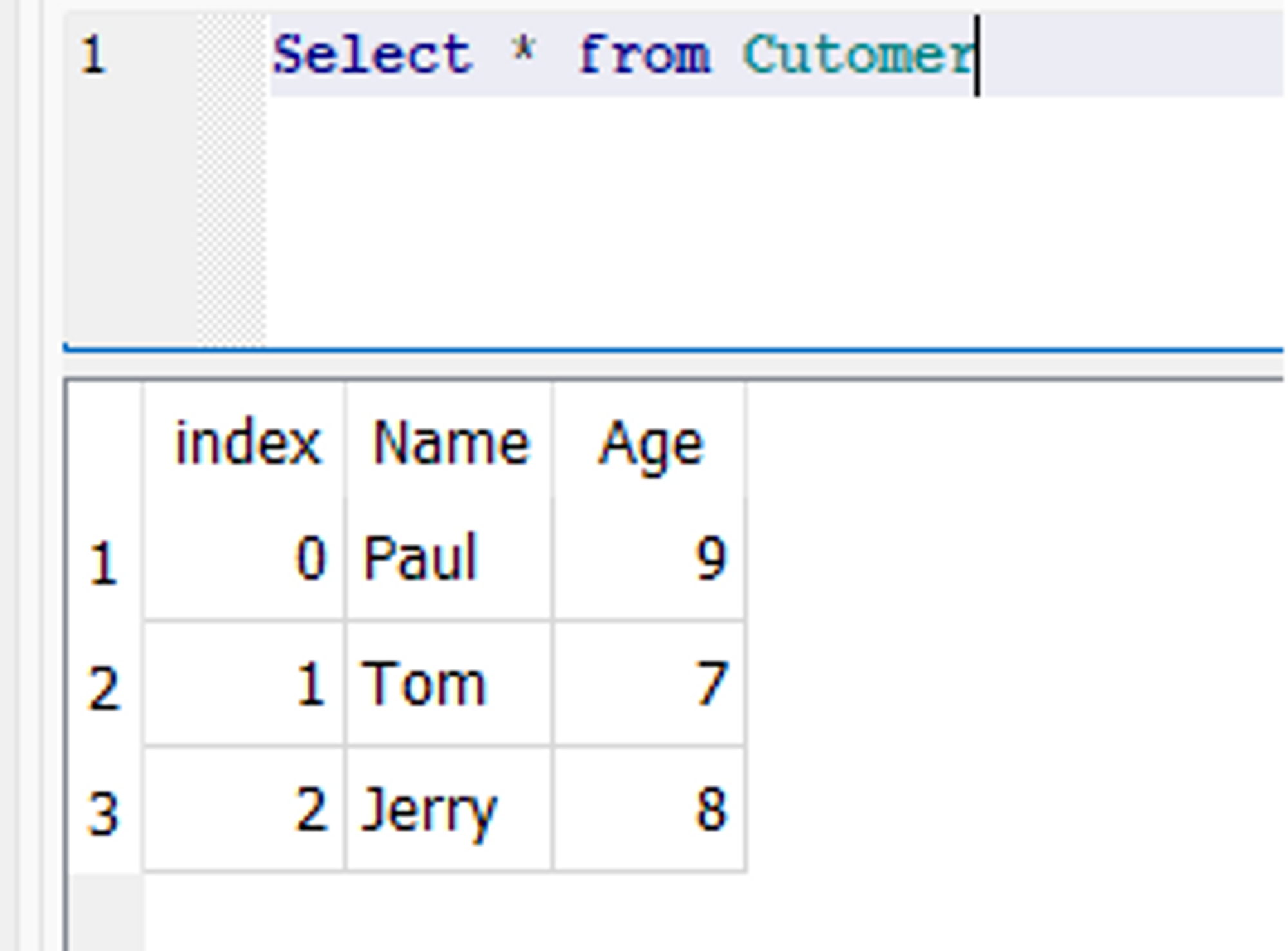
df = pd.DataFrame(data) df.to_sql('Customer', con=engine, if_exists='fail') engine.dispose()
在数据库中创建了一个名为 Customer 的新表,其中包含两个字段,分别称为“姓名”和“年龄”。
数据库快照:
使用 Pandas Dataframes 更新现有表
更新数据库中的数据是一项复杂的任务,尤其是在处理大数据时。 但是,使用 to_sql() Pandas 中的函数可以使这项任务变得更加容易。 要更新数据库中的现有表, to_sql() 函数可以与 if_exists 参数设置为“替换”。 这将用新数据覆盖现有表。
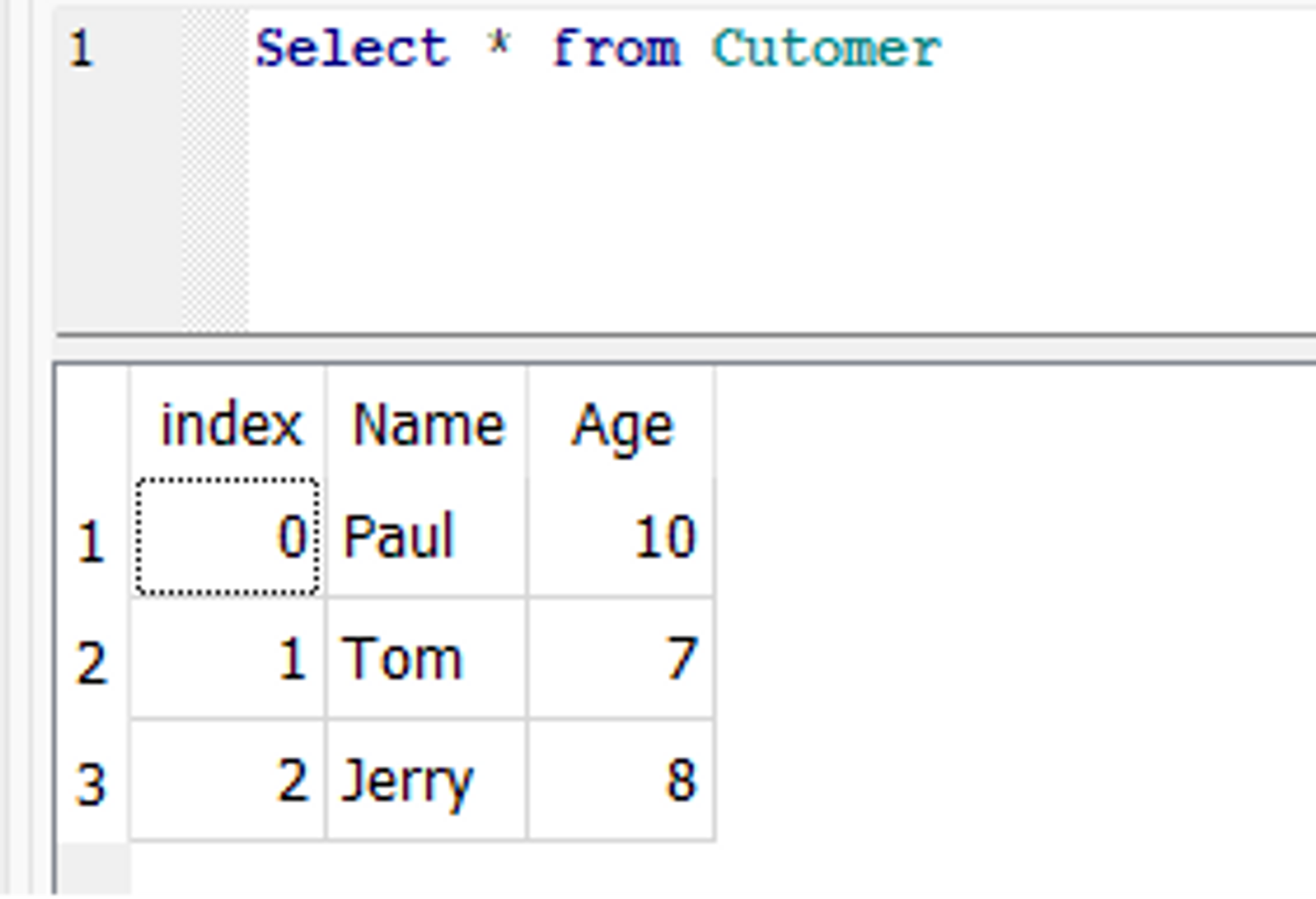
这是一个例子 to_sql() 更新先前创建的 Customer 桌子。 假设,在 Customer 我们要将名为 Paul 的客户的年龄从 9 岁更新到 10 岁的表。为此,首先,我们可以修改 DataFrame 中的相应行,然后使用 to_sql() 更新数据库的函数。
代码:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Customer', engine) df.loc[df['Name'] == 'Paul', 'Age'] = 10 df.to_sql('Customer', con=engine, if_exists='replace') engine.dispose()
在数据库中,更新了 Paul 的年龄:
结论
总之,Pandas 和 SQL 都是数据分析任务的强大工具,例如在 SQL 数据库中读取和写入数据。 Pandas 提供了一种简单的方法来连接到 SQL 数据库,将数据从数据库读取到 Pandas 数据框中,并将数据框数据写回数据库。
Pandas 库使操作数据框中的数据变得容易,而 SQL 提供了一种强大的语言来查询数据库中的数据。 同时使用 Pandas 和 SQL 来读写数据可以节省数据分析任务的时间和精力,尤其是在数据非常大的时候。 总的来说,结合使用 SQL 和 Pandas 可以帮助数据分析师和科学家简化他们的工作流程。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- 与 Adryenn Ashley 一起铸造未来。 访问这里。
- 使用 PREIPO® 买卖 PRE-IPO 公司的股票。 访问这里。
- Sumber: https://stackabuse.com/reading-and-writing-sql-files-in-pandas/

