Trong loạt bài gồm hai phần này, chúng tôi trình bày cách gắn nhãn và đào tạo mô hình cho các nhiệm vụ phát hiện đối tượng 3D. Trong phần 1, chúng tôi thảo luận về tập dữ liệu chúng tôi đang sử dụng, cũng như bất kỳ bước tiền xử lý nào, để hiểu và gắn nhãn dữ liệu. Trong phần 2, chúng ta sẽ tìm hiểu cách huấn luyện một mô hình trên tập dữ liệu của bạn và triển khai mô hình đó vào sản xuất.
LiDAR (phát hiện ánh sáng và phạm vi) là phương pháp xác định phạm vi bằng cách nhắm mục tiêu một vật thể hoặc bề mặt bằng tia laser và đo thời gian để ánh sáng phản xạ quay trở lại máy thu. Các công ty xe tự lái thường sử dụng cảm biến LiDAR để tạo ra hiểu biết 3D về môi trường xung quanh xe của họ.
Khi các cảm biến LiDAR trở nên dễ tiếp cận hơn và tiết kiệm chi phí hơn, khách hàng ngày càng sử dụng dữ liệu đám mây điểm trong các không gian mới như rô-bốt, ánh xạ tín hiệu và thực tế tăng cường. Một số thiết bị di động mới thậm chí còn bao gồm cảm biến LiDAR. Tính khả dụng ngày càng tăng của các cảm biến LiDAR đã làm tăng sự quan tâm đến dữ liệu đám mây điểm cho các tác vụ học máy (ML), như phát hiện và theo dõi đối tượng 3D, phân đoạn 3D, tổng hợp và tái tạo đối tượng 3D cũng như sử dụng dữ liệu 3D để xác thực ước tính độ sâu 2D.
Trong loạt bài này, chúng tôi chỉ cho bạn cách đào tạo mô hình phát hiện đối tượng chạy trên dữ liệu đám mây điểm để dự đoán vị trí của các phương tiện trong cảnh 3D. Bài đăng này, chúng tôi tập trung cụ thể vào việc dán nhãn dữ liệu LiDAR. Đầu ra của cảm biến LiDAR tiêu chuẩn là một chuỗi các khung đám mây điểm 3D, với tốc độ chụp thông thường là 10 khung hình mỗi giây. Để dán nhãn đầu ra cảm biến này, bạn cần một công cụ dán nhãn có thể xử lý dữ liệu 3D. Sự thật về mặt đất của Amazon SageMaker giúp dễ dàng gắn nhãn các đối tượng trong một khung 3D duy nhất hoặc trên một chuỗi các khung đám mây điểm 3D để xây dựng bộ dữ liệu đào tạo ML. Ground Truth cũng hỗ trợ kết hợp cảm biến của dữ liệu máy ảnh và LiDAR với tối đa tám đầu vào máy quay video.
Dữ liệu là điều cần thiết cho bất kỳ dự án ML nào. Dữ liệu 3D nói riêng có thể khó tìm nguồn, trực quan hóa và gắn nhãn. chúng tôi sử dụng tập dữ liệu A2D2 trong bài đăng này và hướng dẫn bạn các bước để trực quan hóa và gắn nhãn cho nó.
A2D2 chứa 40,000 khung với phân đoạn ngữ nghĩa và nhãn đám mây điểm, bao gồm 12,499 khung với nhãn hộp giới hạn 3D. Vì chúng tôi đang tập trung vào phát hiện đối tượng nên chúng tôi quan tâm đến 12,499 khung có nhãn hộp giới hạn 3D. Những chú thích này bao gồm 14 lớp liên quan đến lái xe như ô tô, người đi bộ, xe tải, xe buýt, v.v.
Bảng sau đây hiển thị danh sách lớp đầy đủ:
| Chỉ số | danh sách lớp |
| 1 | động vật |
| 2 | xe đạp |
| 3 | xe buýt |
| 4 | xe hơi |
| 5 | vận chuyển đoàn lữ hành |
| 6 | người đi xe đạp |
| 7 | trường hợp khẩn cấp xe |
| 8 | người đi xe máy |
| 9 | xe mô tô |
| 10 | người đi bộ |
| 11 | Trailer |
| 12 | xe tải |
| 13 | xe tiện ích |
| 14 | xe van/SUV |
Chúng tôi sẽ đào tạo máy dò của mình để phát hiện cụ thể ô tô vì đó là loại phổ biến nhất trong tập dữ liệu của chúng tôi (32616 trong tổng số 42816 đối tượng trong tập dữ liệu được gắn nhãn là ô tô).
Tổng quan về giải pháp
Trong loạt bài này, chúng tôi đề cập đến cách trực quan hóa và gắn nhãn dữ liệu của bạn bằng Amazon SageMaker Ground Truth và trình bày cách sử dụng dữ liệu này trong công việc đào tạo Amazon SageMaker để tạo mô hình phát hiện đối tượng, được triển khai cho Điểm cuối Amazon SageMaker. Cụ thể, chúng tôi sẽ sử dụng sổ ghi chép Amazon SageMaker để vận hành giải pháp và khởi chạy mọi công việc ghi nhãn hoặc đào tạo.
Sơ đồ sau đây mô tả toàn bộ luồng dữ liệu cảm biến từ ghi nhãn đến đào tạo đến triển khai:
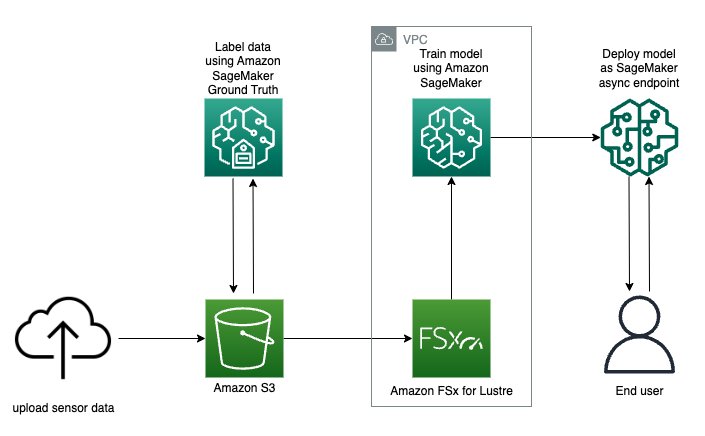
Bạn sẽ học cách đào tạo và triển khai mô hình phát hiện đối tượng 3D thời gian thực với Amazon SageMaker Ground Truth với các bước sau:
- Tải xuống và trực quan hóa tập dữ liệu đám mây điểm
- Chuẩn bị dữ liệu để được gắn nhãn với Công cụ đám mây điểm chân lý trên mặt đất Amazon SageMaker
- Khởi chạy công việc đào tạo Amazon SageMaker Ground Truth phân tán với MMDetection3D
- Đánh giá kết quả công việc đào tạo của bạn và lập hồ sơ sử dụng tài nguyên của bạn với Trình gỡ lỗi Amazon SageMaker
- Triển khai không đồng bộ Điểm cuối SageMaker
- Gọi điểm cuối và trực quan hóa dự đoán đối tượng 3D
Các dịch vụ AWS được sử dụng để triển khai giải pháp này
Điều kiện tiên quyết
Sơ đồ sau đây minh họa cách tạo lực lượng lao động tư nhân. Để biết hướng dẫn bằng văn bản, từng bước, hãy xem Tạo lực lượng lao động ẩn danh của Amazon bằng cách sử dụng trang đội ngũ nhân công gắn nhãn.

Khởi chạy ngăn xếp AWS CloudFormation
Bây giờ bạn đã thấy cấu trúc của giải pháp, bạn triển khai nó vào tài khoản của mình để bạn có thể chạy quy trình làm việc mẫu. Tất cả các bước triển khai liên quan đến quy trình ghi nhãn đều do AWS CloudFormation quản lý. Điều này có nghĩa là AWS Cloudformation tạo phiên bản sổ ghi chép của bạn cũng như mọi vai trò hoặc Bộ chứa Amazon S3 để hỗ trợ chạy giải pháp.
Bạn có thể khởi chạy ngăn xếp trong Khu vực AWS us-east-1 trên bảng điều khiển AWS CloudFormation bằng cách sử dụng Khởi chạy Stack
cái nút. Để khởi chạy ngăn xếp ở một Khu vực khác, hãy sử dụng các hướng dẫn có trong README của Kho GitHub.
![]()
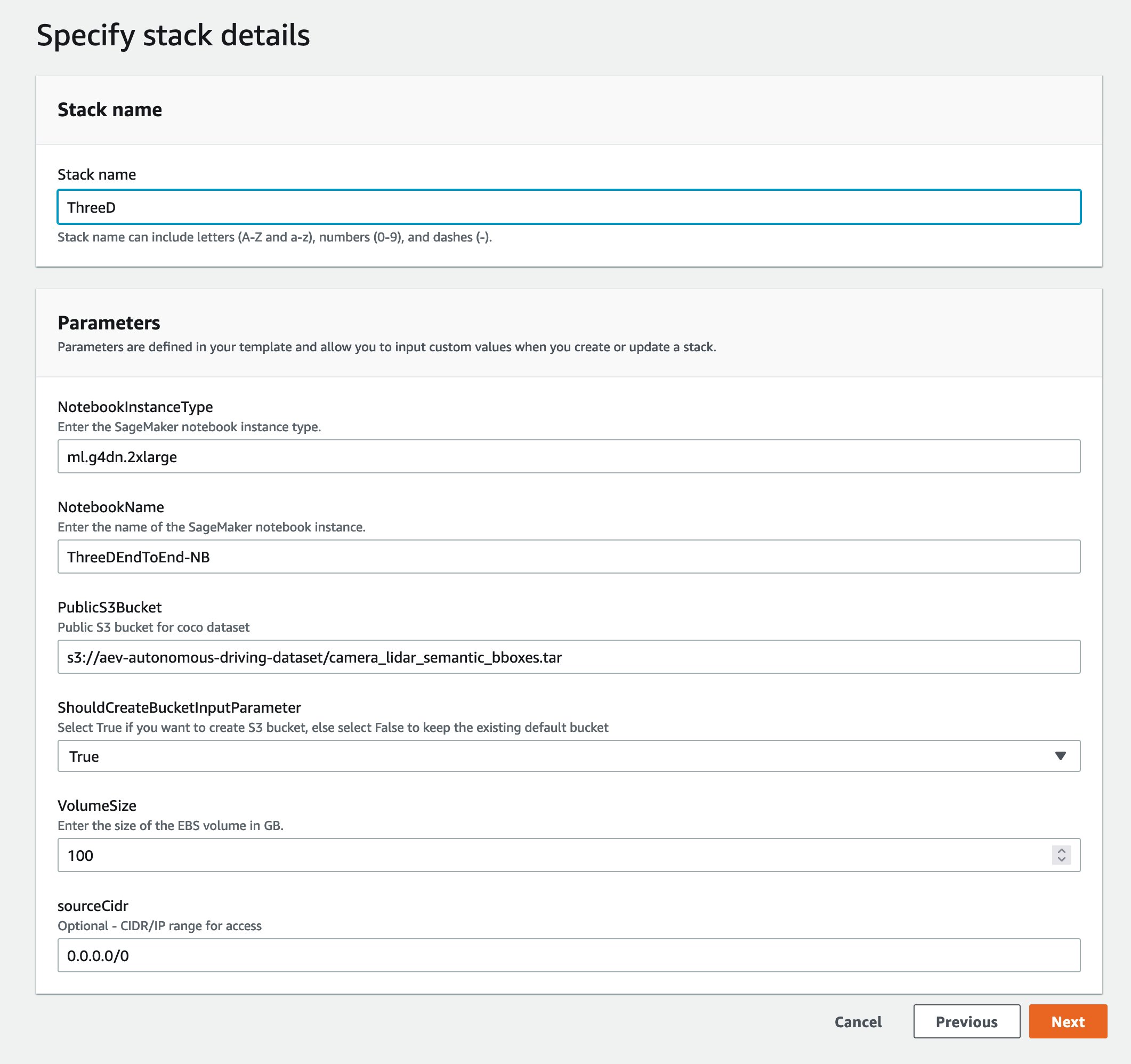
Quá trình này mất khoảng 20 phút để tạo tất cả các tài nguyên. Bạn có thể theo dõi tiến trình từ giao diện người dùng (UI) của AWS CloudFormation.
Khi mẫu CloudFormation của bạn chạy xong, hãy quay lại Bảng điều khiển AWS.
Mở sổ ghi chép
Phiên bản Amazon SageMaker Notebook là phiên bản điện toán ML chạy trên Ứng dụng Jupyter Notebook. Amazon SageMaker quản lý việc tạo phiên bản và các tài nguyên liên quan. Sử dụng sổ ghi chép Jupyter trong phiên bản sổ ghi chép của bạn để chuẩn bị và xử lý dữ liệu, viết mã để huấn luyện mô hình, triển khai mô hình lên dịch vụ lưu trữ Amazon SageMaker cũng như kiểm tra hoặc xác thực mô hình của bạn.
Làm theo các bước tiếp theo để truy cập vào môi trường Amazon SageMaker Notebook:
- Dưới dịch vụ tìm kiếm cho Amazon SageMaker.
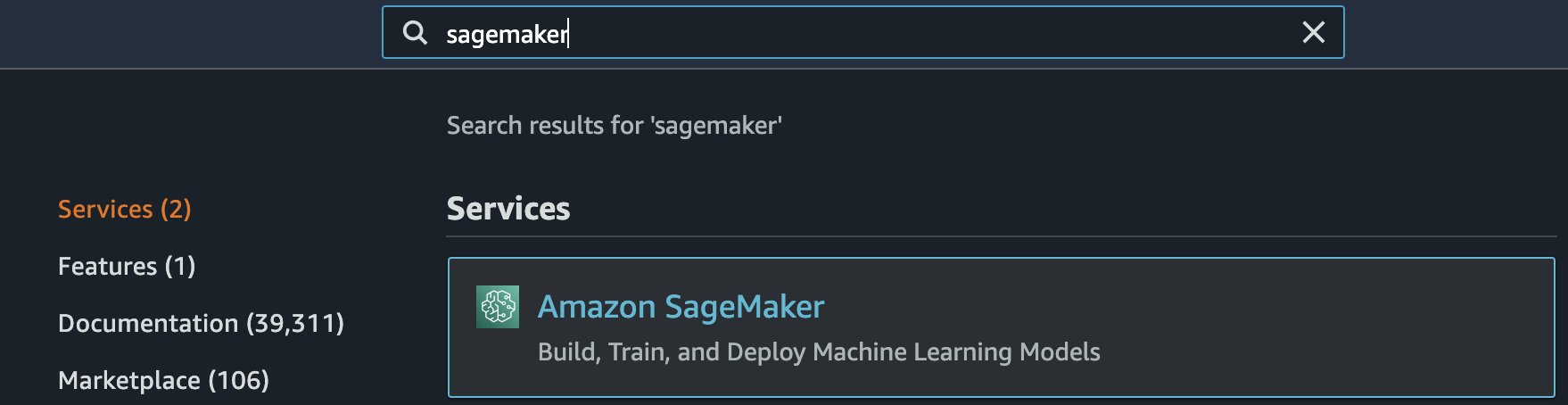
- Theo Sổ tay, lựa chọn Trường hợp máy tính xách tay.

- Phiên bản Notebook phải được cung cấp. Chọn Mở phòng thí nghiệm jupyter, nằm ở phía bên phải của phiên bản Notebook được cung cấp trước trong Hoạt động.

- Bạn sẽ thấy một biểu tượng như thế này khi tải trang:

- Bạn sẽ được chuyển hướng đến một tab trình duyệt mới giống như sơ đồ sau:
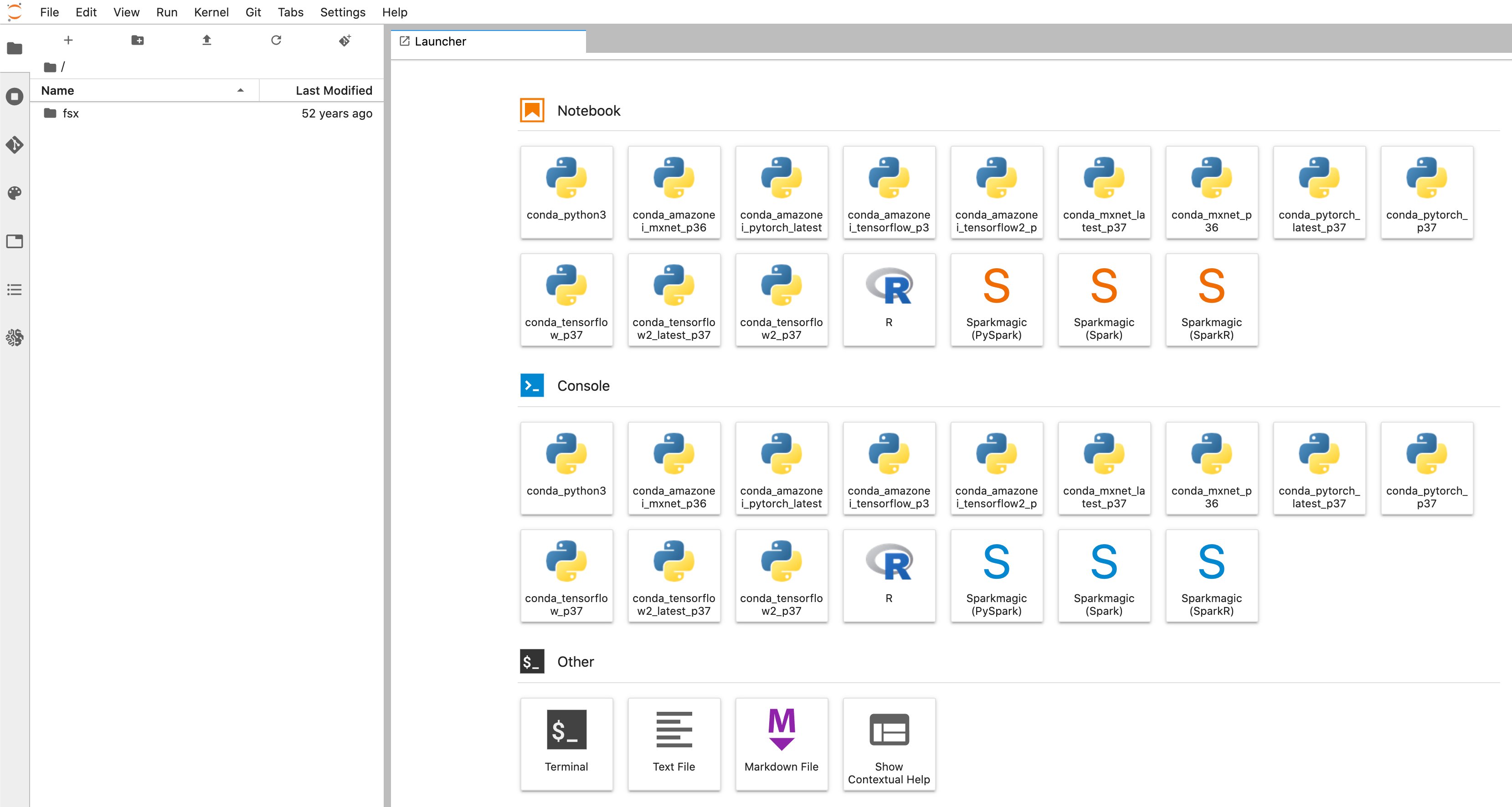
- Khi bạn đang ở trong giao diện người dùng Trình khởi chạy phiên bản Amazon SageMaker Notebook. Từ thanh bên trái, chọn đi biểu tượng như trong sơ đồ sau.
- Chọn Sao chép kho lưu trữ tùy chọn.
- Nhập URL GitHub (https://github.com/aws-samples/end-2-end-3d-ml) trong cửa sổ bật lên và chọn nhân bản.
- Chọn Trình duyệt tệp để xem thư mục GitHub.
- Mở sổ tay có tiêu đề
1_visualization.ipynb.
Vận hành Notebook
Giới thiệu chung
Một vài ô đầu tiên của sổ ghi chép trong phần có tiêu đề Tệp đã tải xuống hướng dẫn cách tải xuống tập dữ liệu và kiểm tra các tệp trong đó. Sau khi các ô được thực hiện, sẽ mất vài phút để tải xong dữ liệu.
Sau khi tải xuống, bạn có thể xem lại cấu trúc tệp của A2D2, đây là danh sách các cảnh hoặc ổ đĩa. Một cảnh là một bản ghi ngắn dữ liệu cảm biến từ xe của chúng tôi. A2D2 cung cấp 18 cảnh trong số này để chúng tôi luyện tập, tất cả đều được xác định theo ngày duy nhất. Mỗi cảnh chứa dữ liệu camera 2D, nhãn 2D, chú thích hình khối 3D và đám mây điểm 3D.
Bạn có thể xem cấu trúc tệp cho tập dữ liệu A2D2 như sau:
Thiết lập cảm biến A2D2
Phần tiếp theo sẽ hướng dẫn cách đọc một số dữ liệu đám mây điểm này để đảm bảo rằng chúng tôi đang diễn giải chính xác và có thể trực quan hóa dữ liệu đó trong sổ ghi chép trước khi thử chuyển đổi dữ liệu đó sang định dạng sẵn sàng để gắn nhãn dữ liệu.
Đối với bất kỳ loại thiết lập lái xe tự động nào mà chúng tôi có dữ liệu cảm biến 2D và 3D, việc thu thập dữ liệu hiệu chỉnh cảm biến là điều cần thiết. Ngoài dữ liệu thô, chúng tôi cũng đã tải xuống cams_lidar.json. Tệp này chứa bản dịch và hướng của từng cảm biến so với khung tọa độ của xe, đây cũng có thể được gọi là tư thế hoặc vị trí của cảm biến trong không gian. Điều này rất quan trọng để chuyển đổi các điểm từ khung tọa độ của cảm biến sang khung tọa độ của xe. Nói cách khác, điều quan trọng là phải trực quan hóa các cảm biến 2D và 3D khi xe chạy. Khung tọa độ của xe được định nghĩa là một điểm tĩnh ở chính giữa xe, với trục x là chiều chuyển động tịnh tiến của xe, trục y biểu thị trái và phải với left là dương, trục z- trục chỉ qua nóc xe. Điểm (X,Y,Z) của (5,2,1) có nghĩa là điểm này cách xe của chúng ta 5 mét, bên trái 2 mét và cao hơn xe của chúng ta 1 mét. Việc có các hiệu chỉnh này cũng cho phép chúng tôi chiếu các điểm 3D lên hình ảnh 2D của mình, điều này đặc biệt hữu ích cho các tác vụ ghi nhãn đám mây điểm.
Để xem thiết lập cảm biến trên xe, hãy kiểm tra sơ đồ sau.
Dữ liệu đám mây điểm mà chúng tôi đang đào tạo được căn chỉnh cụ thể với camera phía trước hoặc trung tâm phía trước: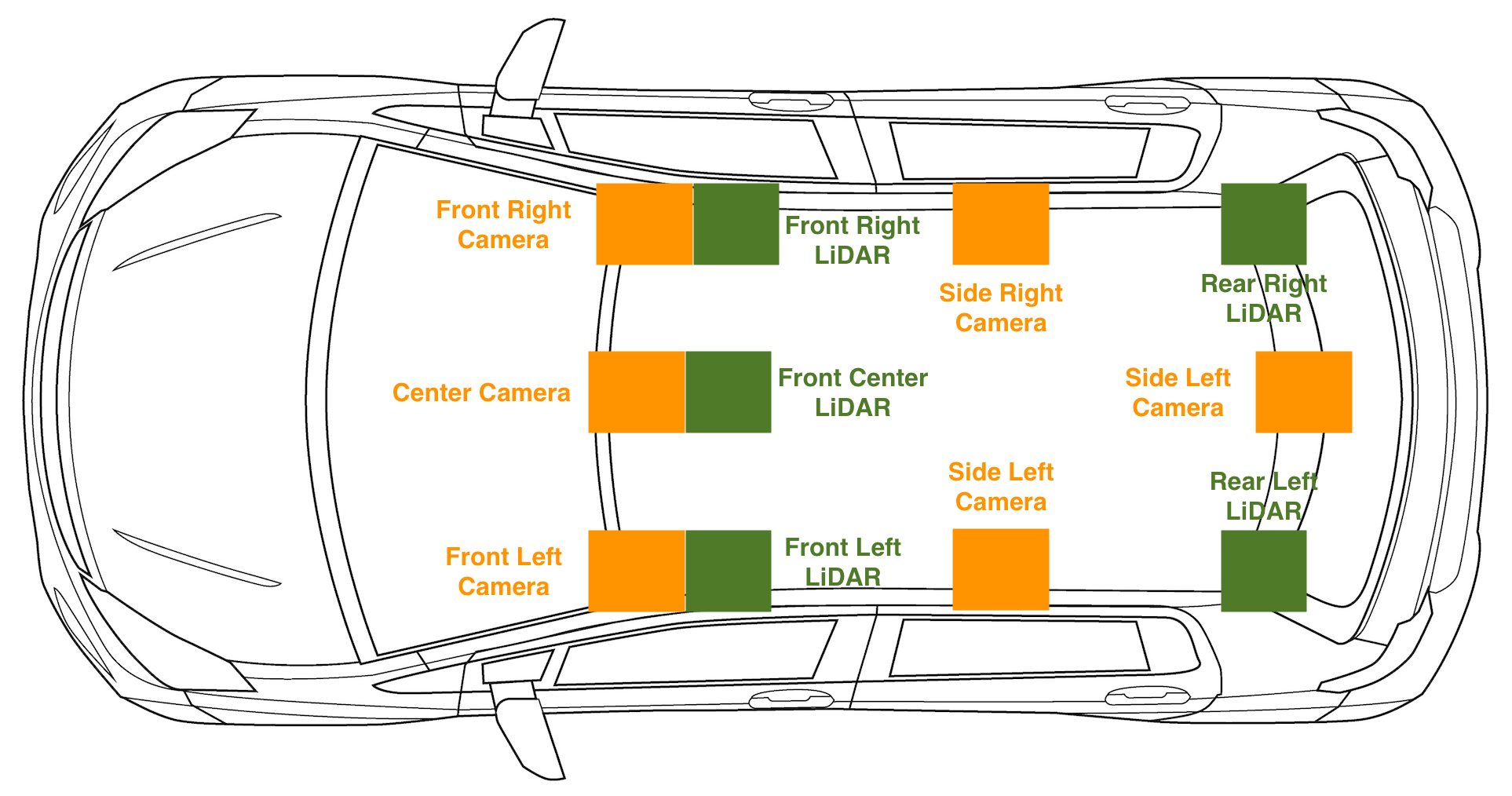
Điều này phù hợp với hình dung của chúng tôi về cảm biến máy ảnh ở chế độ 3D: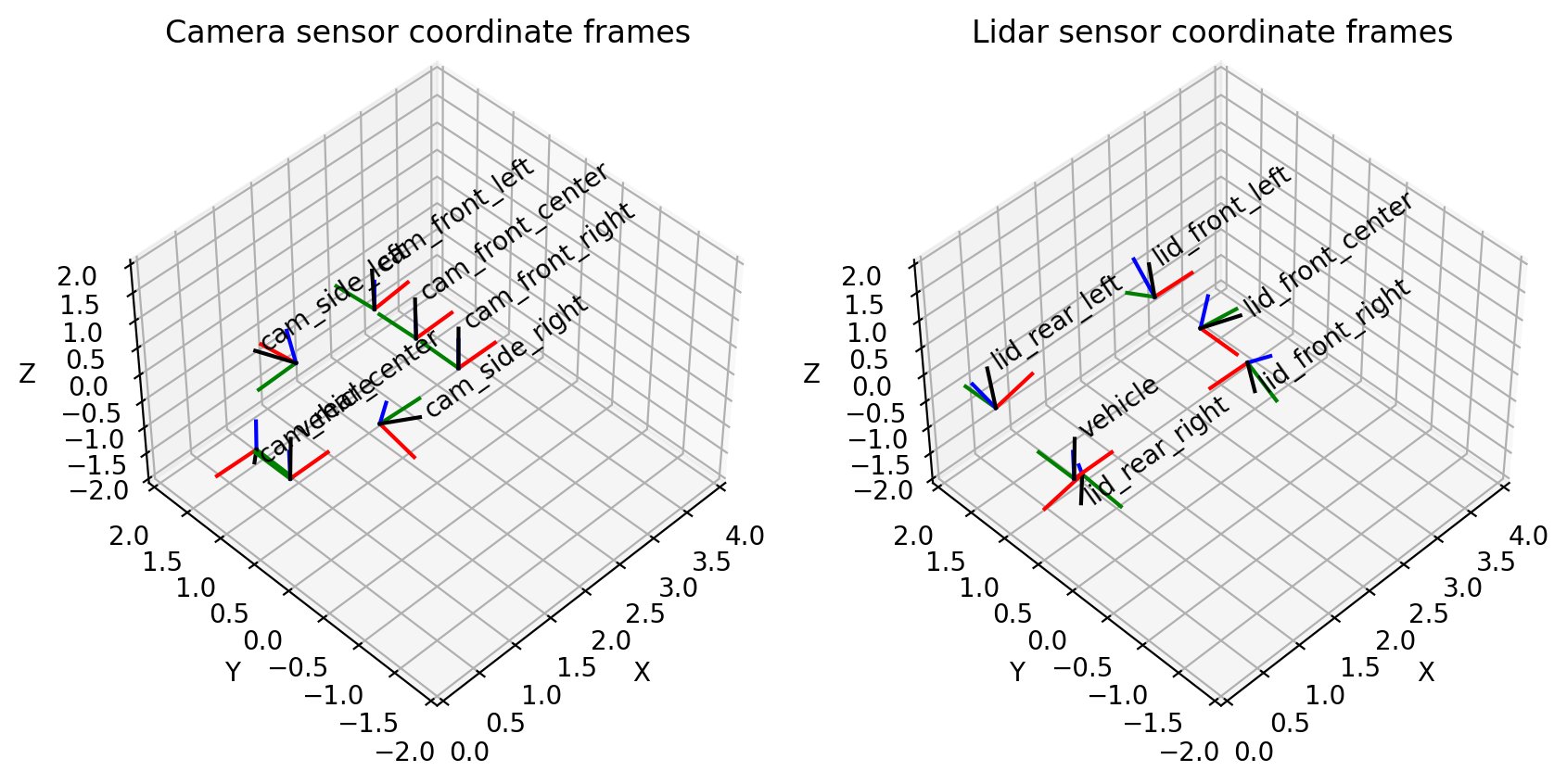
Phần này của sổ ghi chép hướng dẫn xác thực rằng tập dữ liệu A2D2 phù hợp với mong đợi của chúng tôi về vị trí cảm biến và chúng tôi có thể căn chỉnh dữ liệu từ các cảm biến đám mây điểm vào khung máy ảnh. Vui lòng chạy tất cả các ô thông qua ô có tiêu đề Chiếu từ 3D sang 2D để xem lớp phủ dữ liệu đám mây điểm của bạn trên hình ảnh camera sau.
Chuyển đổi sang Amazon SageMaker Ground Truth

Sau khi trực quan hóa dữ liệu của chúng tôi trong sổ ghi chép, chúng tôi có thể tự tin chuyển đổi các đám mây điểm của mình thành Amazon Định dạng 3D của SageMaker Ground Truth để xác minh và điều chỉnh nhãn của chúng tôi. Phần này hướng dẫn chuyển đổi từ định dạng dữ liệu của A2D2 sang định dạng dữ liệu của Amazon Tệp trình tự SageMaker Ground Truth, với định dạng đầu vào được sử dụng bởi phương thức theo dõi đối tượng.
Định dạng tệp trình tự bao gồm các định dạng đám mây điểm, hình ảnh được liên kết với từng đám mây điểm và tất cả dữ liệu định hướng và vị trí cảm biến cần thiết để căn chỉnh hình ảnh với các đám mây điểm. Những chuyển đổi này được thực hiện bằng cách sử dụng thông tin cảm biến được đọc từ phần trước. Ví dụ sau đây là định dạng tệp trình tự từ Amazon SageMaker Ground Truth, mô tả một trình tự chỉ có một dấu thời gian.
Đám mây điểm cho dấu thời gian này được đặt tại s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/20180807145028_lidar_frontcenter_000000091.txt và có định dạng là <x coordinate> <y coordinate> <z coordinate>.
Được liên kết với đám mây điểm, là một hình ảnh camera duy nhất được đặt tại s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/undistort_20180807145028_camera_frontcenter_000000091.png. Lưu ý rằng chúng tôi lấy tệp trình tự xác định tất cả các tham số của máy ảnh để cho phép chiếu từ đám mây điểm tới máy ảnh và ngược lại.
Chuyển đổi sang định dạng đầu vào này yêu cầu chúng tôi viết chuyển đổi từ định dạng dữ liệu của A2D2 sang định dạng dữ liệu được Amazon SageMaker Ground Truth hỗ trợ. Đây là quy trình tương tự mà bất kỳ ai cũng phải trải qua khi mang dữ liệu của chính họ để dán nhãn. Chúng tôi sẽ hướng dẫn từng bước cách hoạt động của chuyển đổi này. Nếu theo dõi trong sổ ghi chép, hãy xem chức năng có tên a2d2_scene_to_smgt_sequence_and_seq_label.
Chuyển đổi đám mây điểm
Bước đầu tiên là chuyển đổi dữ liệu từ tệp được nén có định dạng Numpy (NPZ), được tạo bằng tệp numpy.biết rôi phương pháp, đến một định dạng 3D thô được chấp nhận cho Amazon SageMaker Ground Truth. Cụ thể, chúng tôi tạo một tệp có một hàng trên mỗi điểm. Mỗi điểm 3D được xác định bởi ba tọa độ dấu phẩy động X, Y và Z. Khi chúng tôi chỉ định định dạng của mình trong tệp trình tự, chúng tôi sử dụng chuỗi text/xyz để đại diện cho định dạng này. Amazon SageMaker Ground Truth cũng hỗ trợ thêm giá trị cường độ hoặc điểm Red Green Blue (RGB).
Các tệp NPZ của A2D2 chứa nhiều mảng Numpy, mỗi mảng có tên riêng. Để thực hiện chuyển đổi, chúng tôi tải tệp NPZ bằng Numpy's tải phương thức, truy cập vào mảng được gọi là điểm (nghĩa là một mảng Nx3, trong đó N là số điểm trong đám mây điểm) và lưu dưới dạng văn bản vào một tệp mới bằng Numpy's lưu văn bản phương pháp.
Xử lý trước hình ảnh
Tiếp theo, chúng tôi chuẩn bị các tập tin hình ảnh của chúng tôi. A2D2 cung cấp hình ảnh PNG và Amazon SageMaker Ground Truth hỗ trợ hình ảnh PNG; tuy nhiên, những hình ảnh này bị bóp méo. Hiện tượng méo ảnh thường xảy ra do thấu kính chụp ảnh không được căn chỉnh song song với mặt phẳng tạo ảnh, khiến một số vùng trong ảnh trông gần hơn mong đợi. Sự biến dạng này mô tả sự khác biệt giữa máy ảnh vật lý và máy ảnh mô hình máy ảnh pinhole lý tưởng hóa. Nếu độ méo không được tính đến, thì Amazon SageMaker Ground Truth sẽ không thể hiển thị các điểm 3D của chúng tôi trên các chế độ xem camera, điều này khiến việc thực hiện ghi nhãn trở nên khó khăn hơn. Để biết hướng dẫn về hiệu chỉnh máy ảnh, hãy xem tài liệu này từ OpenCV.
Mặc dù Amazon SageMaker Ground Truth hỗ trợ các hệ số biến dạng trong tệp đầu vào của nó, nhưng bạn cũng có thể thực hiện tiền xử lý trước công việc ghi nhãn. Vì A2D2 cung cấp mã trợ giúp để thực hiện khử biến dạng, chúng tôi áp dụng mã này cho hình ảnh và loại bỏ các trường liên quan đến biến dạng khỏi tệp trình tự của chúng tôi. Lưu ý rằng các trường liên quan đến biến dạng bao gồm k1, k2, k3, k4, p1, p2 và xiên.
Chuyển đổi vị trí, hướng và hình chiếu của camera
Ngoài các tệp dữ liệu thô cần thiết để ghi nhãn, tệp trình tự cũng yêu cầu thông tin về vị trí và hướng của camera để thực hiện phép chiếu các điểm 3D vào chế độ xem camera 2D. Chúng ta cần biết máy ảnh đang nhìn vào đâu trong không gian 3D để tìm ra cách các nhãn hình khối 3D và các điểm 3D sẽ được hiển thị trên hình ảnh của chúng ta.
Vì chúng tôi đã tải các vị trí cảm biến của mình vào trình quản lý biến đổi chung trong phần thiết lập cảm biến A2D2, chúng tôi có thể dễ dàng truy vấn trình quản lý biến đổi để biết thông tin mà chúng tôi muốn. Trong trường hợp của chúng tôi, chúng tôi coi vị trí xe là (0, 0, 0) trong mỗi khung vì chúng tôi không có thông tin vị trí của cảm biến được cung cấp bởi bộ dữ liệu phát hiện đối tượng của A2D2. Vì vậy, so với phương tiện của chúng tôi, hướng và vị trí của máy ảnh được mô tả bằng mã sau:
Bây giờ, vị trí và hướng đã được chuyển đổi, chúng ta cũng cần cung cấp các giá trị cho fx, fy, cx và cy, tất cả các tham số cho mỗi camera ở định dạng tệp trình tự.
Các tham số này đề cập đến các giá trị trong ma trận máy ảnh. Trong khi vị trí và hướng mô tả hướng quay của camera, ma trận camera mô tả trường nhìn của camera và chính xác cách một điểm 3D so với camera được chuyển đổi thành vị trí pixel 2D trong ảnh.
A2D2 cung cấp một ma trận camera. Một ma trận máy ảnh tham chiếu được hiển thị trong mã sau đây, cùng với cách sổ ghi chép của chúng tôi lập chỉ mục ma trận này để nhận các trường thích hợp.
Với tất cả các trường được phân tích cú pháp từ định dạng của A2D2, chúng tôi có thể lưu tệp trình tự và sử dụng nó trong Amazon Tệp kê khai đầu vào SageMaker Ground Truth để bắt đầu công việc dán nhãn. Công việc ghi nhãn này cho phép chúng tôi tạo nhãn hộp giới hạn 3D để sử dụng xuôi dòng cho đào tạo mô hình 3D.
Chạy tất cả các ô cho đến hết sổ ghi chép và đảm bảo bạn thay thế ô workteam ARN với Amazon SageMaker Ground Truth workteam ARN bạn đã tạo điều kiện tiên quyết. Sau khoảng 10 phút ghi nhãn thời gian tạo công việc, bạn sẽ có thể đăng nhập vào cổng nhân viên và sử dụng ghi nhãn giao diện người dùng để hình dung cảnh của bạn.
Làm sạch
Xóa ngăn xếp AWS CloudFormation mà bạn đã triển khai bằng cách sử dụng Khởi chạy Stack nút có tên ThreeD trong bảng điều khiển AWS CloudFormation để xóa tất cả tài nguyên được sử dụng trong bài đăng này, bao gồm mọi phiên bản đang chạy.
Chi phí ước tính
Chi phí gần đúng là $5 cho 2 giờ.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách lấy dữ liệu 3D và chuyển đổi nó thành một biểu mẫu sẵn sàng để gắn nhãn trong Amazon SageMaker Ground Truth. Với các bước này, bạn có thể gắn nhãn dữ liệu 3D của riêng mình để huấn luyện các mô hình phát hiện đối tượng. Trong bài đăng tiếp theo của loạt bài này, chúng tôi sẽ chỉ cho bạn cách sử dụng A2D2 và huấn luyện một mô hình phát hiện đối tượng trên các nhãn đã có trong tập dữ liệu.
Tòa nhà hạnh phúc!
Về các tác giả
 Isaac Privitera là một nhà khoa học dữ liệu cao cấp tại Phòng thí nghiệm Giải pháp Máy học của Amazon, nơi anh ấy phát triển các giải pháp học máy và học sâu theo yêu cầu để giải quyết các vấn đề kinh doanh của khách hàng. Anh ấy làm việc chủ yếu trong lĩnh vực thị giác máy tính, tập trung vào việc tạo điều kiện cho khách hàng AWS đào tạo phân tán và học tập tích cực.
Isaac Privitera là một nhà khoa học dữ liệu cao cấp tại Phòng thí nghiệm Giải pháp Máy học của Amazon, nơi anh ấy phát triển các giải pháp học máy và học sâu theo yêu cầu để giải quyết các vấn đề kinh doanh của khách hàng. Anh ấy làm việc chủ yếu trong lĩnh vực thị giác máy tính, tập trung vào việc tạo điều kiện cho khách hàng AWS đào tạo phân tán và học tập tích cực.
 Vidya Sagar Ravipati là Quản lý tại Phòng thí nghiệm Giải pháp Máy học của Amazon, nơi anh ấy tận dụng kinh nghiệm rộng lớn của mình trong các hệ thống phân tán quy mô lớn và niềm đam mê học máy của mình để giúp khách hàng AWS trên các ngành dọc khác nhau đẩy nhanh việc áp dụng AI và đám mây của họ. Trước đây, anh ấy là Kỹ sư Máy học trong Dịch vụ Kết nối tại Amazon, người đã giúp xây dựng các nền tảng bảo trì dự đoán và cá nhân hóa.
Vidya Sagar Ravipati là Quản lý tại Phòng thí nghiệm Giải pháp Máy học của Amazon, nơi anh ấy tận dụng kinh nghiệm rộng lớn của mình trong các hệ thống phân tán quy mô lớn và niềm đam mê học máy của mình để giúp khách hàng AWS trên các ngành dọc khác nhau đẩy nhanh việc áp dụng AI và đám mây của họ. Trước đây, anh ấy là Kỹ sư Máy học trong Dịch vụ Kết nối tại Amazon, người đã giúp xây dựng các nền tảng bảo trì dự đoán và cá nhân hóa.
 Jeremy Feltracco là Kỹ sư phát triển phần mềm với th Phòng thí nghiệm Giải pháp Máy học của Amazon tại Dịch vụ web của Amazon. Anh ấy sử dụng nền tảng kiến thức của mình về tầm nhìn máy tính, rô-bốt và học máy để giúp các khách hàng của AWS đẩy nhanh quá trình áp dụng AI của họ.
Jeremy Feltracco là Kỹ sư phát triển phần mềm với th Phòng thí nghiệm Giải pháp Máy học của Amazon tại Dịch vụ web của Amazon. Anh ấy sử dụng nền tảng kiến thức của mình về tầm nhìn máy tính, rô-bốt và học máy để giúp các khách hàng của AWS đẩy nhanh quá trình áp dụng AI của họ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/using-amazon-sagemaker-with-point-clouds-part-1-ground-truth-for-3d-labeling/

