Оцінка пози — це техніка комп’ютерного зору, яка виявляє набір точок на об’єктах (наприклад, людях або транспортних засобах) на зображеннях або відео. Оцінка пози має реальне застосування у спорті, робототехніці, безпеці, доповненій реальності, медіа та розвагах, медичних програмах тощо. Моделі оцінки пози тренуються на зображеннях або відео, які анотовані послідовним набором точок (координат), визначених установкою. Щоб навчити точні моделі оцінки пози, спочатку потрібно отримати великий набір даних анотованих зображень; багато наборів даних містять десятки чи сотні тисяч анотованих зображень і потребують значних ресурсів для створення. Помилки в маркуванні важливо виявляти та запобігати їм, оскільки продуктивність моделі для моделей оцінки пози значною мірою залежить від якості мічених даних і обсягу даних.
У цій публікації ми покажемо, як можна використовувати робочий процес настроюваного маркування Основна правда Amazon SageMaker спеціально розроблений для маркування ключових точок. Цей спеціальний робочий процес допомагає оптимізувати процес маркування та мінімізувати помилки маркування, тим самим зменшуючи витрати на отримання високоякісних етикеток поз.
Важливість високоякісних даних і зменшення помилок маркування
Високоякісні дані є основоположними для підготовки надійних і надійних моделей оцінки пози. Точність цих моделей безпосередньо пов’язана з правильністю та точністю міток, призначених кожній ключовий точці пози, що, у свою чергу, залежить від ефективності процесу анотації. Крім того, наявність значного обсягу різноманітних і добре анотованих даних гарантує, що модель може вивчати широкий спектр поз, варіацій і сценаріїв, що призводить до покращеного узагальнення та продуктивності в різних реальних програмах. Отримання цих великих анотованих наборів даних залучає людей-анотаторів, які ретельно позначають зображення інформацією про пози. Під час позначення визначних місць на зображенні корисно бачити скелетну структуру об’єкта під час позначення, щоб надати візуальні вказівки анотатору. Це корисно для виявлення помилок міток до того, як вони будуть включені в набір даних, як-от заміна лівого-правого місця або неправильні мітки (наприклад, позначення ноги як плеча). Наприклад, помилку маркування, як-от заміну лівого-правого, зроблену в наступному прикладі, можна легко ідентифікувати за перетином ліній скелетної установки та невідповідністю кольорів. Ці візуальні підказки допомагають особам, які займаються етикетками, розпізнавати помилки та створюють чистіший набір етикеток.
Через те, що маркування виконується вручну, отримання великих і точних наборів даних із мітками може виявитися непомірно дорогим, і тим більше через неефективну систему маркування. Тому ефективність і точність маркування є критично важливими при розробці робочого процесу маркування. У цій публікації ми демонструємо, як використовувати спеціальний робочий процес маркування SageMaker Ground Truth для швидкого й точного анотування зображень, зменшуючи навантаження на розробку великих наборів даних для робочих процесів оцінки пози.

Огляд рішення
Це рішення надає онлайновий веб-портал, де працівники етикеток можуть використовувати веб-браузер для входу, доступу до завдань маркування та коментування зображень за допомогою інтерфейсу користувача (UI) crowd-2d-skeleton, спеціального інтерфейсу користувача, призначеного для маркування ключових точок і поз за допомогою SageMaker Ground Truth. Анотації або мітки, створені робочою силою з маркування, потім експортуються до Служба простого зберігання Amazon (Amazon S3), де їх можна використовувати для подальших процесів, як-от навчання моделей комп’ютерного зору глибокого навчання. Це рішення допоможе вам налаштувати та розгорнути необхідні компоненти для створення веб-порталу, а також як створити завдання маркування для цього робочого процесу маркування.
Нижче наведено діаграму загальної архітектури.

Ця архітектура складається з кількох ключових компонентів, кожен з яких ми пояснюємо більш детально в наступних розділах. Ця архітектура надає робочій силі етикеток онлайновий веб-портал, розміщений на SageMaker Ground Truth. Цей портал дозволяє кожному етикетувальнику увійти в систему та переглянути свої завдання з етикетування. Увійшовши в систему, етикетувальник може вибрати завдання з маркування та почати анотувати зображення за допомогою спеціального інтерфейсу користувача, розміщеного на Amazon CloudFront. Ми використовуємо AWS Lambda функції для обробки даних до анотації та після анотації.
Наступний знімок екрана є прикладом інтерфейсу користувача.
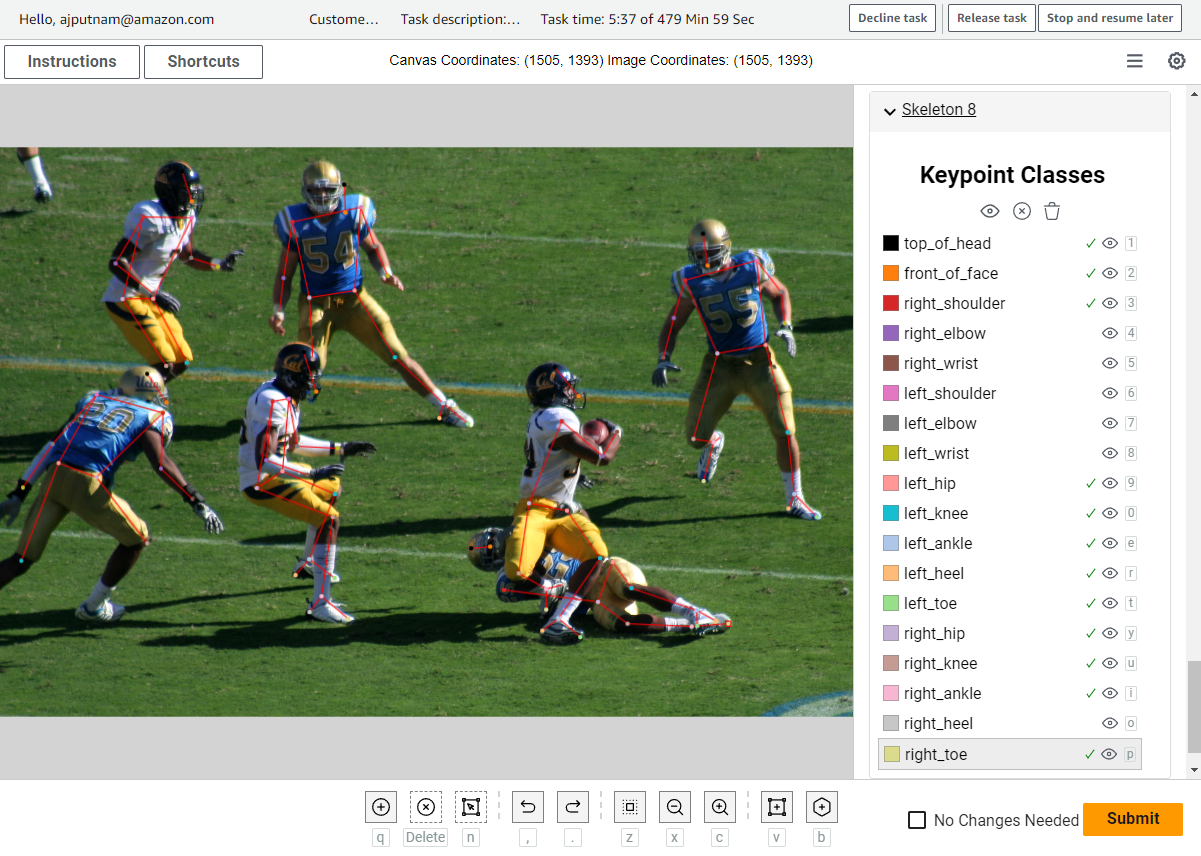
Розміщувач може позначати певні ключові точки на зображенні за допомогою інтерфейсу користувача. Лінії між ключовими точками будуть автоматично накреслені для користувача на основі визначення скелетної установки, яке використовує інтерфейс користувача. Інтерфейс користувача дозволяє багато налаштувань, наприклад:
- Спеціальні імена ключових точок
- Настроювані кольори ключових точок
- Настроювані кольори ліній установки
- Конфігуровані скелетні та бурові конструкції
Кожна з цих функцій призначена для полегшення та гнучкості маркування. Конкретні деталі налаштування інтерфейсу користувача можна знайти в GitHub репо і підсумовані далі в цій публікації. Зауважте, що в цій публікації ми використовуємо оцінку пози людини як базове завдання, але ви можете розширити її до позначення пози об’єкта за допомогою попередньо визначеної установки також для інших об’єктів, наприклад тварин або транспортних засобів. У наступному прикладі ми показуємо, як це можна застосувати для позначення точок фургона.

SageMaker Ground Truth
У цьому рішенні ми використовуємо SageMaker Ground Truth, щоб надати робочій силі етикеток онлайн-портал і спосіб керування завданнями маркування. Ця публікація передбачає, що ви знайомі з SageMaker Ground Truth. Для отримання додаткової інформації див Основна правда Amazon SageMaker.
Дистрибутив CloudFront
Для цього рішення інтерфейсу користувача для маркування потрібен спеціально створений компонент JavaScript, який називається компонентом crowd-2d-skeleton. Цей компонент можна знайти на GitHub в рамках ініціатив Amazon з відкритим кодом. Дистрибутив CloudFront використовуватиметься для розміщення crowd-2d-skeleton.js, який потрібен інтерфейсу користувача SageMaker Ground Truth. Дистрибутиву CloudFront буде призначено ідентифікатор доступу до джерела, що дозволить дистрибутиву CloudFront отримувати доступ до crowd-2d-skeleton.js, що знаходиться в сегменті S3. Відро S3 залишатиметься приватним, і жодні інші об’єкти в цьому відрі не будуть доступні через розповсюдження CloudFront через обмеження, які ми накладаємо на ідентифікатор джерела доступу через політику відра. Це рекомендована практика для дотримання принципу найменших привілеїв.
Відро Amazon S3
Ми використовуємо відро S3 для зберігання вхідних і вихідних файлів маніфесту SageMaker Ground Truth, користувацького шаблону інтерфейсу користувача, зображень для завдань маркування та коду JavaScript, необхідного для користувацького інтерфейсу користувача. Це відро буде приватним і недоступним для громадськості. Відро також матиме політику відра, яка обмежує дистрибутив CloudFront лише можливістю доступу до коду JavaScript, необхідного для інтерфейсу користувача. Це запобігає розповсюдженню CloudFront на розміщення будь-яких інших об’єктів у сегменті S3.
Лямбда-функція перед анотацією
Завдання маркування SageMaker Ground Truth зазвичай використовують вхідний файл маніфесту у форматі рядків JSON. Цей вхідний файл маніфесту містить метадані для завдання маркування, діє як посилання на дані, які потрібно позначити, і допомагає налаштувати спосіб представлення даних для анотаторів. Функція Lambda перед анотацією обробляє елементи з вхідного файлу маніфесту перед тим, як дані маніфесту буде введено в настроюваний шаблон інтерфейсу користувача. Тут можна виконати будь-яке форматування або спеціальні зміни до елементів перед представленням даних для анотаторів в інтерфейсі користувача. Додаткову інформацію про лямбда-функції перед анотацією див Попередня анотація Лямбда.
Лямбда-функція після анотації
Подібно до функції Lambda перед анотацією, функція після анотації обробляє додаткову обробку даних, яку ви можете виконати після того, як усі розміщувачі завершать маркування, але перед написанням остаточних результатів анотації. Ця обробка виконується функцією лямбда, яка відповідає за форматування даних для результатів виводу завдання маркування. У цьому рішенні ми просто використовуємо його для повернення даних у бажаному вихідному форматі. Для отримання додаткової інформації про лямбда-функції після анотації див Лямбда після анотації.
Роль лямбда-функції після анотації
Ми використовуємо Управління ідентифікацією та доступом AWS (IAM), щоб надати лямбда-функції після анотації доступ до сегмента S3. Це потрібно для читання результатів анотації та внесення будь-яких змін перед записом остаточних результатів у вихідний файл маніфесту.
Роль SageMaker Ground Truth
Ми використовуємо цю роль IAM, щоб надати завданням маркування SageMaker Ground Truth можливість викликати функції Lambda та читати зображення, файли маніфесту та спеціальний шаблон інтерфейсу користувача в сегменті S3.
Передумови
Для цього покрокового керівництва ви повинні мати такі передумови:
Для цього рішення ми використовуємо AWS CDK для розгортання архітектури. Потім ми створюємо зразок завдання маркування, використовуємо портал анотацій для маркування зображень у завданні маркування та перевіряємо результати маркування.
Створіть стек AWS CDK
Після того як ви виконаєте всі передумови, ви готові до розгортання рішення.
Налаштуйте свої ресурси
Виконайте наступні кроки, щоб налаштувати ресурси:
- Завантажте приклад стека з GitHub репо.
- Використовуйте команду cd, щоб перейти до сховища.
- Створіть своє середовище Python і встановіть необхідні пакунки (додаткову інформацію див. у репозиторії README.md).
- Активувавши середовище Python, виконайте таку команду:
- Виконайте таку команду, щоб розгорнути AWS CDK:
- Виконайте таку команду, щоб запустити сценарій після розгортання:
Створіть завдання маркування
Після того, як ви налаштували свої ресурси, ви готові створити завдання маркування. Для цілей цієї публікації ми створюємо роботу з мітками за допомогою прикладів сценаріїв і зображень, наданих у сховищі.
- CD в
scriptsкаталог у сховищі. - Завантажте зразки зображень з Інтернету, виконавши такий код:
Цей сценарій завантажує набір із 10 зображень, які ми використовуємо в нашому прикладі роботи з маркуванням. Далі в цьому дописі ми розглянемо, як використовувати ваші власні дані введення.
- Створіть завдання маркування, виконавши такий код:
Цей сценарій приймає ARN приватної робочої сили SageMaker Ground Truth як аргумент, який має бути ARN для вашої робочої сили в тому самому обліковому записі, у якому ви розгорнули цю архітектуру. Сценарій створить вхідний файл маніфесту для нашого завдання маркування, завантажить його в Amazon S3 і створить спеціальне завдання маркування SageMaker Ground Truth. Далі в цій публікації ми детальніше зануримося в деталі цього сценарію.
Позначте набір даних
Після того, як ви запустите приклад завдання маркування, воно з’явиться на консолі SageMaker, а також на порталі робочої сили.

На порталі робочої сили виберіть завдання з маркування та виберіть Початок роботи.

Вам буде запропоновано зображення з прикладу набору даних. На цьому етапі ви можете використовувати спеціальний інтерфейс користувача crowd-2d-skeleton, щоб додавати анотації до зображень. Ви можете ознайомитися з інтерфейсом користувача crowd-2d-skeleton, звернувшись до Огляд інтерфейсу користувача. Ми використовуємо визначення бурової установки з Завдання набору даних виявлення ключових точок COCO як людська поза. Повторюємо, що ви можете налаштувати це без нашого спеціального компонента інтерфейсу користувача, щоб видалити або додати точки відповідно до ваших вимог.
Коли ви закінчите анотувати зображення, виберіть Надіслати. Це переведе вас до наступного зображення в наборі даних, доки всі зображення не будуть позначені.

Доступ до результатів маркування
Коли ви завершите маркування всіх зображень у завданні маркування, SageMaker Ground Truth викличе функцію Lambda після анотації та створить файл output.manifest, що містить усі анотації. Це output.manifest буде зберігатися у відрі S3. У нашому випадку розташування вихідного маніфесту має відповідати шляху S3 URI s3://<bucket name> /labeling_jobs/output/<labeling job name>/manifests/output/output.manifest. Файл output.manifest — це файл JSON Lines, де кожен рядок відповідає одному зображенню та його анотаціям від робочої сили з маркування. Кожен рядок JSON — це об’єкт JSON із багатьма полями. Поле, яке нас цікавить, називається label-results. Значення цього поля є об’єктом, що містить такі поля:
- dataset_object_id – Ідентифікатор або індекс вхідного елемента маніфесту
- data_object_s3_uri – URI Amazon S3 зображення
- ім'я_файлу_зображення – Ім’я файлу зображення
- image_s3_location – URL-адреса зображення Amazon S3
- оригінальні_анотації – Оригінальні анотації (встановлюються та використовуються, лише якщо ви використовуєте робочий процес до створення анотацій)
- оновлені_анотації – Анотації до зображення
- worker_id – Працівник, який складав анотації
- жодних_змін_не потрібно – Чи встановлено прапорець «Зміни не потрібні».
- was_modified – Чи відрізняються дані анотації від оригінальних вхідних даних
- загальний_час_в_секундах – Час, який знадобився працівнику, щоб анотувати зображення
За допомогою цих полів ви можете отримати доступ до результатів анотацій для кожного зображення та виконати обчислення, як-от середній час для позначення зображення.
Створюйте власні завдання для маркування
Тепер, коли ми створили приклад завдання маркування та ви розумієте загальний процес, ми ознайомимо вас із кодом, відповідальним за створення файлу маніфесту та запуск завдання маркування. Ми зосереджуємося на ключових частинах сценарію, які ви можете змінити, щоб запускати власні завдання маркування.
Ми розглядаємо фрагменти коду з create_example_labeling_job.py сценарій, розташований у GitHub сховище. Сценарій починається з налаштування змінних, які використовуються пізніше в сценарії. Деякі змінні жорстко закодовані для простоти, тоді як інші, які залежать від стеку, імпортуватимуться динамічно під час виконання шляхом отримання значень, створених із нашого стеку AWS CDK.
Першим ключовим розділом у цьому сценарії є створення файлу маніфесту. Пам’ятайте, що файл маніфесту – це файл рядків JSON, який містить відомості про завдання маркування SageMaker Ground Truth. Кожен об’єкт JSON Lines представляє один елемент (наприклад, зображення), який потрібно позначити. Для цього робочого циклу об’єкт має містити такі поля:
- джерело-реф – URI Amazon S3 для зображення, яке ви хочете позначити.
- анотації – Список об’єктів анотації, який використовується для попереднього анотування робочих процесів. Див документація crowd-2d-skeleton щоб дізнатися більше про очікувані значення.
Сценарій створює рядок маніфесту для кожного зображення в каталозі зображень, використовуючи такий розділ коду:
Якщо ви хочете використовувати різні зображення або вказати на інший каталог зображень, ви можете змінити цей розділ коду. Крім того, якщо ви використовуєте робочий процес перед створенням анотацій, ви можете оновити масив анотацій за допомогою рядка JSON, що складається з масиву та всіх його об’єктів анотації. Деталі формату цього масиву задокументовано в документація crowd-2d-skeleton.
Завдяки створеним рядкам-позиціям маніфесту ви можете створити та завантажити файл маніфесту до сегмента S3, який ви створили раніше:
Тепер, коли ви створили файл маніфесту, що містить зображення, які потрібно позначити, ви можете створити завдання позначення. Ви можете створити завдання маркування програмним шляхом за допомогою AWS SDK для Python (Boto3). Код для створення завдання маркування виглядає наступним чином:
Аспекти цього коду, які ви можете змінити: LabelingJobName, TaskTitle та TaskDescription, LabelingJobName це унікальна назва завдання маркування, яке SageMaker використовуватиме для посилання на ваше завдання. Це також ім’я, яке з’являтиметься на консолі SageMaker. TaskTitle виконує подібну мету, але не обов’язково має бути унікальним і буде назвою вакансії, яка з’являється на порталі робочої сили. Можливо, ви захочете зробити це більш конкретним для того, що ви маркуєте або для чого призначене завдання маркування. Нарешті, ми маємо TaskDescription поле. Це поле відображається на порталі робочої сили, щоб надати додатковий контекст для розміщувачів міток щодо того, що таке завдання, наприклад інструкції та вказівки щодо завдання. Для отримання додаткової інформації про ці поля, а також про інші, зверніться до документація create_labeling_job.
Внесіть корективи в інтерфейс користувача
У цьому розділі ми розглянемо деякі способи налаштування інтерфейсу користувача. Нижче наведено список найпоширеніших можливих налаштувань інтерфейсу користувача, щоб адаптувати його до вашого завдання моделювання:
- Ви можете визначити, які ключові точки можна позначати. Це включає назву ключової точки та її колір.
- Ви можете змінити структуру скелета (які ключові точки з'єднані).
- Ви можете змінити кольори ліній для окремих ліній між певними ключовими точками.
Усі ці налаштування інтерфейсу користувача можна налаштувати за допомогою аргументів, що передаються в компонент crowd-2d-skeleton, який є компонентом JavaScript, який використовується в цьому спеціальний шаблон робочого процесу. У цьому шаблоні ви знайдете використання компонента crowd-2d-skeleton. Спрощену версію показано в наступному коді:
У попередньому прикладі коду ви можете побачити такі атрибути компонента: imgSrc, keypointClasses, skeletonRig, skeletonBoundingBox та intialValues. Ми описуємо призначення кожного атрибута в наступних розділах, але налаштувати інтерфейс користувача так само просто, як змінити значення цих атрибутів, зберегти шаблон і повторно запустити post_deployment_script.py ми використовували раніше.
атрибут imgSrc
Команда imgSrc Атрибут визначає, яке зображення відображати в інтерфейсі користувача під час позначення. Зазвичай для кожної позиції маніфесту використовується різне зображення, тому цей атрибут часто заповнюється динамічно за допомогою вбудованого Рідина мова шаблонів. Ви можете бачити в попередньому прикладі коду, що значення атрибута встановлено на {{ task.input.image_s3_uri | grant_read_access }}, яка є змінною шаблону Liquid, яку буде замінено на фактичну image_s3_uri значення під час візуалізації шаблону. Процес візуалізації починається, коли користувач відкриває зображення для анотації. Цей процес захоплює елемент рядка з вхідного файлу маніфесту та надсилає його до функції лямбда перед анотацією як event.dataObject. Функція попередньої анотації бере потрібну інформацію з позиції та повертає a taskInput словник, який потім передається механізму візуалізації Liquid, який замінить будь-які змінні Liquid у вашому шаблоні. Наприклад, скажімо, у вас є файл маніфесту з таким рядком:
Ці дані будуть передані до функції попередньої анотації. Наступний код показує, як функція витягує значення з об’єкта події:
У цьому випадку об’єкт, повернутий функцією, виглядатиме так:
Повернуті функцією дані потім доступні механізму шаблонів Liquid, який замінює значення шаблону в шаблоні на значення даних, які повертає функція. Результатом буде приблизно такий код:
атрибут keypointClasses
Команда keypointClasses Атрибут визначає, які ключові точки відображатимуться в інтерфейсі користувача та використовуватимуться анотаторами. Цей атрибут приймає рядок JSON, що містить список об’єктів. Кожен об’єкт представляє ключову точку. Кожен об’єкт keypoint повинен містити такі поля:
- id – Унікальне значення для визначення цієї ключової точки.
- color – Колір ключової точки, представлений як шістнадцятковий колір HTML.
- етикетка – Ім’я або клас ключової точки.
- x – Цей необов’язковий атрибут потрібен, лише якщо ви хочете використовувати функціональність малювати скелет в інтерфейсі користувача. Значенням цього атрибута є положення x ключової точки відносно обмежувальної рамки скелета. Це значення зазвичай отримують Інструмент Skeleton Rig Creator. Якщо ви робите анотації ключових точок і вам не потрібно малювати весь скелет одразу, ви можете встановити це значення на 0.
- y – Цей додатковий атрибут подібний до x, але для вертикального розміру.
Для отримання додаткової інформації про keypointClasses атрибут див документація keypointClasses.
атрибут skeletonRig
Команда skeletonRig Атрибут контролює, між якими ключовими точками повинні бути проведені лінії. Цей атрибут приймає рядок JSON, що містить список пар міток ключових точок. Кожна пара повідомляє інтерфейсу користувача, між якими ключовими точками малювати лінії. Наприклад, '[["left_ankle","left_knee"],["left_knee","left_hip"]]' інформує користувальницький інтерфейс, щоб провести лінії між ними "left_ankle" та "left_knee" і проведіть лінії між ними "left_knee" та "left_hip". Це може бути створено Інструмент Skeleton Rig Creator.
атрибут skeletonBoundingBox
Команда skeletonBoundingBox Атрибут необов’язковий і потрібен, лише якщо ви хочете використовувати функціональні можливості малювати скелет в інтерфейсі користувача. Функціональність малювати скелет — це можливість анотувати цілі скелети за допомогою однієї дії анотації. Ми не розглядаємо цю функцію в цій публікації. Значенням цього атрибута є розміри обмежувальної рамки скелета. Це значення зазвичай отримують Інструмент Skeleton Rig Creator. Якщо ви робите анотації ключових точок і вам не потрібно малювати весь скелет одразу, ви можете встановити це значення на нуль. Щоб отримати це значення, рекомендується використовувати інструмент Skeleton Rig Creator.
атрибут intialValues
Команда initialValues Атрибут використовується для попереднього заповнення інтерфейсу користувача анотаціями, отриманими з іншого процесу (наприклад, іншого завдання маркування або моделі машинного навчання). Це корисно під час виконання коригування або перегляду робіт. Дані для цього поля зазвичай заповнюються динамічно в тому самому описі для imgSrc атрибут. Більш детальну інформацію можна знайти в документація crowd-2d-skeleton.
Прибирати
Щоб уникнути майбутніх витрат, вам слід видалити об’єкти в сегменті S3 і стек AWS CDK. Ви можете видалити свої об’єкти S3 за допомогою консолі Amazon SageMaker або Інтерфейс командного рядка AWS (AWS CLI). Після видалення всіх об’єктів S3 у відрі ви можете знищити AWS CDK, виконавши такий код:
Це призведе до видалення ресурсів, які ви створили раніше.
Міркування
Можливо, знадобляться додаткові кроки, щоб створити робочий процес. Ось деякі зауваження залежно від профілю ризику вашої організації:
- Додавання доступу та журналювання програми
- Додавання брандмауера веб-програм (WAF)
- Налаштування дозволів IAM відповідно до найменших привілеїв
Висновок
У цьому дописі ми поділилися важливістю ефективності та точності маркування для створення наборів даних оцінки пози. Щоб допомогти з обома елементами, ми показали, як ви можете використовувати SageMaker Ground Truth для створення користувальницьких робочих процесів маркування для підтримки завдань маркування на основі скелетної пози, щоб підвищити ефективність і точність під час процесу маркування. Ми показали, як можна додатково розширити код і приклади до різних користувацьких вимог до маркування оцінки пози.
Ми рекомендуємо вам використовувати це рішення для завдань маркування та звертатися до AWS для отримання допомоги чи запитів, пов’язаних із робочими процесами спеціального маркування.
Про авторів
 Артур Патнем є Full-Stack Data Scientist в AWS Professional Services. Досвід Артура зосереджений на розробці та інтеграції зовнішніх і внутрішніх технологій у системи ШІ. Поза роботою Артур любить досліджувати останні досягнення в галузі технологій, проводити час із сім’єю та насолоджуватися природою.
Артур Патнем є Full-Stack Data Scientist в AWS Professional Services. Досвід Артура зосереджений на розробці та інтеграції зовнішніх і внутрішніх технологій у системи ШІ. Поза роботою Артур любить досліджувати останні досягнення в галузі технологій, проводити час із сім’єю та насолоджуватися природою.
 Бен Фенкер є старшим спеціалістом із обробки даних у AWS Professional Services і допомагав клієнтам створювати та розгортати рішення ML у різних галузях – від спорту до охорони здоров’я та виробництва. Має ступінь доктора філософії. ступінь магістра фізики в Техаському університеті A&M і 6 років досвіду роботи в галузі. Бен любить бейсбол, читає та виховує дітей.
Бен Фенкер є старшим спеціалістом із обробки даних у AWS Professional Services і допомагав клієнтам створювати та розгортати рішення ML у різних галузях – від спорту до охорони здоров’я та виробництва. Має ступінь доктора філософії. ступінь магістра фізики в Техаському університеті A&M і 6 років досвіду роботи в галузі. Бен любить бейсбол, читає та виховує дітей.
 Джарвіс Лі є старшим спеціалістом із обробки даних у AWS Professional Services. Він працює в AWS більше шести років, працюючи з клієнтами над проблемами машинного навчання та комп’ютерного зору. Поза роботою захоплюється їздою на велосипеді.
Джарвіс Лі є старшим спеціалістом із обробки даних у AWS Professional Services. Він працює в AWS більше шести років, працюючи з клієнтами над проблемами машинного навчання та комп’ютерного зору. Поза роботою захоплюється їздою на велосипеді.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/skeleton-based-pose-annotation-labeling-using-amazon-sagemaker-ground-truth/

