Much like a biological species, languages spread, evolve, compete and even go extinct. To understand these mechanisms, physicists are applying their methods to linguistics, creating the interdisciplinary field of language dynamics, as Marco Patriarca, Els Heinsalu and David Sánchez explain

If the world of research were an ecosystem, with scientists of different disciplines representing different species, then physicists would be classified as invaders. After all, they’ve spread their methods and tools to many other fields over the years, infiltrating not only other natural sciences but the social sciences too.
Born from this invasion, interdisciplinary fields such as sociophysics and econophysics have been developed, in which mathematical models from physics are applied to social contexts, including traffic, crowds and financial markets. These new areas – and the models involved – are part of what’s known as complex systems theory. It concerns systems composed of many elements that interact with each other, producing a collective behaviour that could not be understood if the properties of the individual components were considered in isolation.
But while sociophysics and econophysics are now recognized disciplines, the application of physics to linguistics – known as language dynamics – is less familiar. In fact, we have come across referee reports that have questioned the seriousness of research papers by physicists on this topic. So if you’re one of these strange physicists studying problems that traditionally are part of linguistics, how should you react? Well, swearing is one option.
Spreading the word
Swear words are in fact a great example of how physics can be applied to linguistics. In 2011 a group of physicists from the Niels Bohr Institute in Denmark and Kyushu University in Japan studied how Japanese swear words spread across the country (Phys. Rev. E 83 066116). This is a relatively simple scenario because it involves no linguistic complexity – there’s no grammar, syntax or phonetics to complicate the picture. It’s just a question of how words disperse, which is very similar to standard diffusion. Furthermore, the thin and long shape of Japan’s main islands gives it a quasi-one-dimensional geography, greatly simplifying the diffusion process.
The study analysed linguistic maps (built from past surveys) for 21 swear words, revealing that the majority had spread out from the city of Kyoto, which is often regarded as the cultural capital of Japan. In fact, most of the words studied were found north and south of Kyoto along wave fronts located at comparable distances (figure 1). Using a simple cultural diffusion model – in which a linguistic innovation expands randomly in all directions until it meets and possibly replaces (with a given probability) older innovations – the team was able to reproduce not only the spatial distributions of the 21 swear words but also the variable distances between consecutive wave fronts.
For example, figure 1 shows that the swear word “aho” (dumb) is predominantly used in Kyoto, while “baka” (stupid person) is more prevalent in the capital, Tokyo. This discrepancy is a consequence of the propagation of linguistic innovations that appeared in the Kyoto area at different times, rather than it being a cultural competition between the two big cities. In other words, “baka” used to exist in Kyoto but at some point was overrun by the new “aho”, which has not reached Toyko yet.
1 Rings of swear words
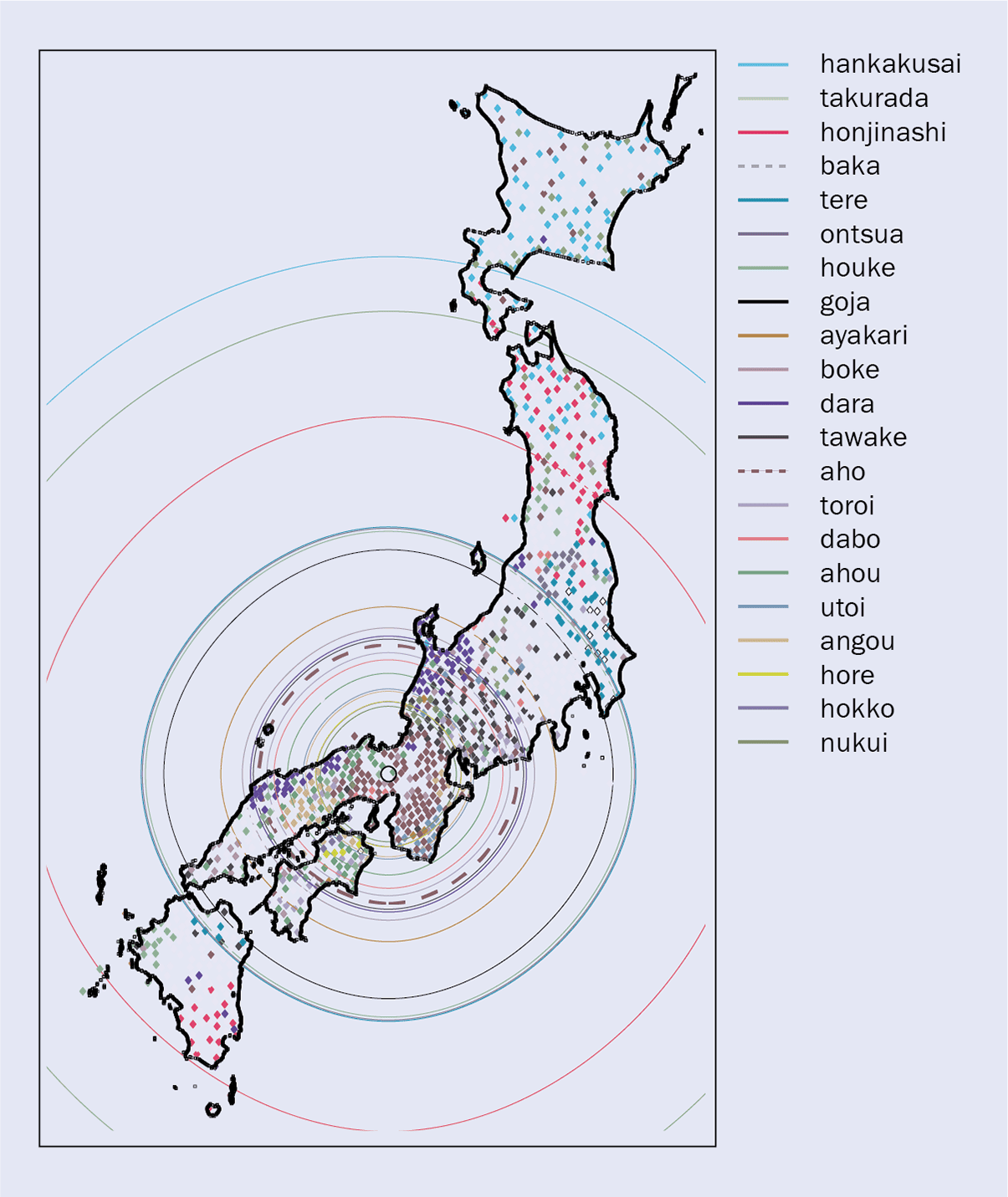
A map showing the spread of Japanese swear words (see key). Each word is represented by wave fronts (circles) that centre on the city of Kyoto (marked by the small ring). It is noticeable how each word spreads at equal rates in all directions and that the newer the word, the smaller the spread from Kyoto. The area of word usage, meanwhile, grows with increasing distance from Kyoto. The study also revealed how new words replaced old ones rather than existing alongside them. “Baka”, for example, used to exist in Kyoto but had been overrun by the newer “aho”, which had not reached Toyko. The words “aho” and “baka” are shown with dashed lines.
Scenarios that resemble typical reaction-diffusion wave fronts like those seen in figure 1 are also found in ecology representing, for example, a species colonizing a new territory or invading an area already occupied by another species. In fact, there are many mathematical similarities between language dynamics and ecology.
Dispersal and evolution
Besides words and idiomatic expressions, language features – such as phonetic traits and different syntactic structures – can spread too. This process can take place across a population, when a linguistic innovation appears in the language community, or through contact between communities with different languages. It is not necessarily connected to human migration. Instead, the spreading of a language as a whole usually occurs in addition to language community migration, which is when people speaking a language living in one place move to another location where a different language is spoken. As a result, this region can then have a bilingual community, or the original language can even become extinct.
Furthermore, language dispersal typically occurs in parallel with language evolution, possibly causing it to split into dialects. This is similar to what happens in biology when a group within a species separates from the other members, developing its own characteristics and becoming a new species.
Take, for example, the Mazatec languages – a group of closely related indigenous languages spoken by about 240,000 people in areas of northern Oaxaca in south-east Mexico. This is an important case study because the Mazatec languages exhibit on a small scale a level of diversity and complexity that is comparable to larger groups, such as the Romance languages in Europe (which include French, Spanish and Italian).

Maths meets myths
When the Mazatec people migrated from their homeland, they first spread through the lowlands before moving across the mountains of the Sierra Mazateca region. What is peculiar is that some languages spoken in the lowlands are more similar to other languages in the mountains than they are to other lowland languages that are geographically closer.
To work out why this is the case, a study in 2019 (involving authors Marco Patriarca and Els Heinsalu) used a simple spreading-evolution model (Complexity Applications in Language and Communication Sciences 10.1007/978-3-030-04598-2_9). The work showed that the two-dimensional nature of the lowlands geography makes languages diffuse more slowly, and therefore a larger diversity is observed because there is more time for mutations to appear and spread. In contrast, the quasi-one-dimensional nature of the valleys connecting the lowlands to the mountains forces a faster dispersal, preventing mutations.
Another interesting example of language dispersal and evolution involves the Numic languages – a group of seven languages spoken by Native Americans in western US. In this case, it is believed that the proto-Numic language evolved into multiple varieties within the Numic homeland (the southern part of the Sierra Nevada mountain range and Death Valley). Then, when the speakers started their rapid spread across the Great Basin, it created a fan-like distribution of the different languages (figure 2a).
2 Fanning out
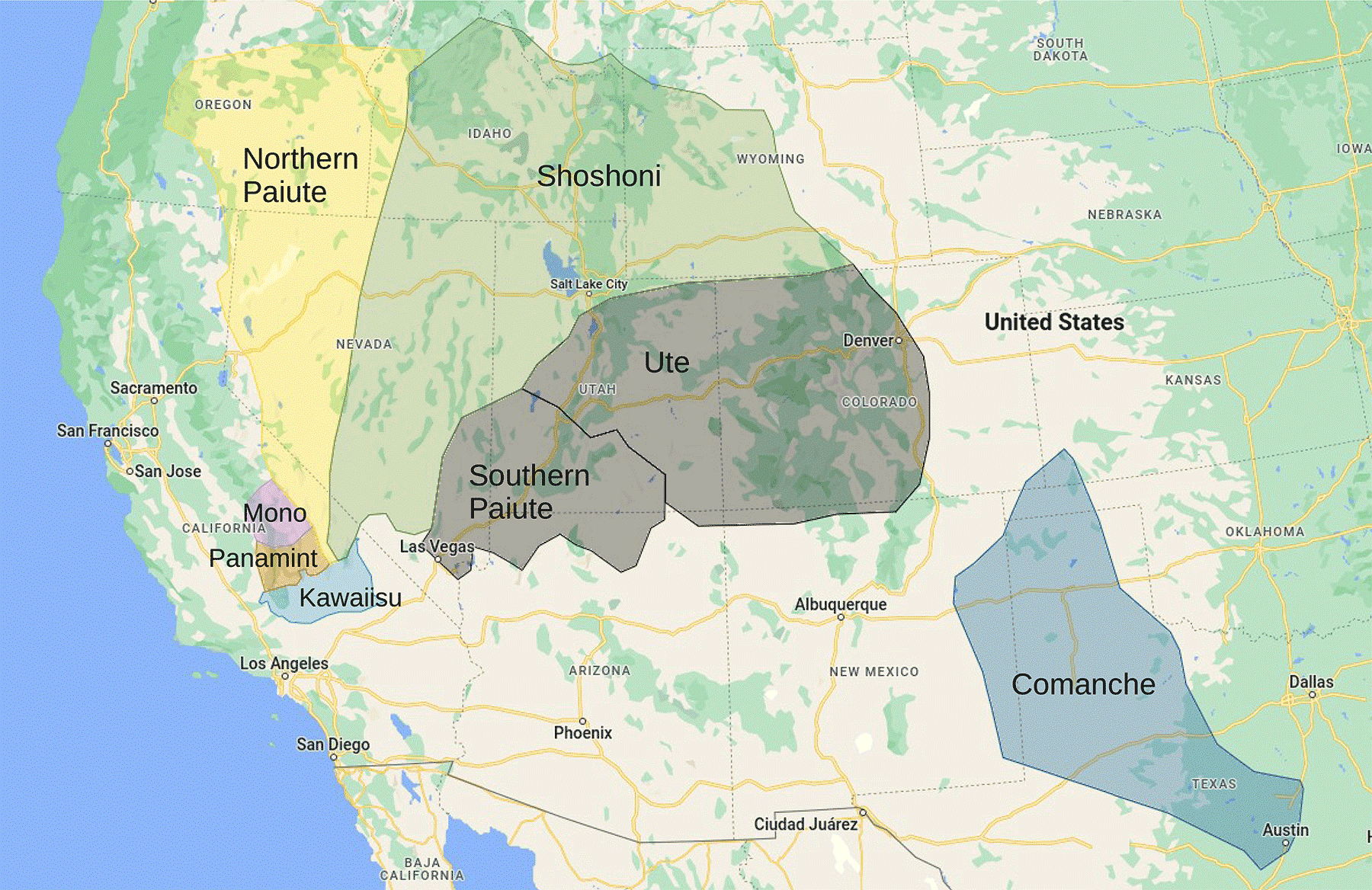

The seven Numic languages, spoken by Native Americans in western US, spread out from the Numic homeland and across the Great Basin in a fan-like distribution, as demonstrated in (a), a map built from field data. A team at Universidade Federal de Pernambuco in Brazil reproduced this structure using a minimal model that simultaneously describes the diffusion and evolution of languages (b).
In 2006 researchers from the Universidade Federal de Pernambuco in Brazil were able to reproduce this pattern using computer simulations (Physica A 361 361). Using a minimal model of a population reproducing and expanding across a territory, they showed that its language changes and splits into different ones, leading to a spatial distribution of languages that is similar to the one observed for the Numic case study (figure 2b).
Evolution versus competition
Language evolution is an important and complex side of language dynamics. The corresponding mathematical description is mostly inspired by ecological and genetic evolution models, but also those used in social sciences, such as game theory. Some language-evolution models are abstract and focus on the statistics of the evolution process, whereas others take into account the rules known from linguistics, such as the phonetic laws describing the evolution of sounds.
On short timescales, however, we can neglect evolution, and consider languages as fixed species competing for speakers. In language competition, which was one of the first topics discussed in language dynamics, we do not have just two competing species – i.e. monolinguals speaking language A or B. Instead, there are also bilinguals, who speak both languages. So, could a language be likened to a parasite that can coexist with another within a host?
Another interpretation could be that speakers are nodes of a temporal network, and the language used by speakers to communicate is a link between two nodes. Now, if we have a multilingual community, speakers have to decide which language to use where, with whom and for what. In order to understand how a minority language survives or goes extinct depending on the speaker’s choices, one can employ models of language use, possibly also incorporating information from real situations (PLOS ONE 16 e0252453).
Language complexity and levels of description
In the case of languages and linguistic analysis, there are two different types of complexity. One is related to structural features of the language itself, such as phonemes, morphemes and lexical stems, while the other is linked to social interactions, such as conversations in person or communication through social networks. These different aspects of complexity can be described in terms of interacting complex networks. Unifying the two dimensions of language complexity – the structural and the social – is a major challenge for mathematical modelling of languages.
Furthermore, the modelling can be done at different levels of detail. In terms of structural complexity, one can study units of sounds (phonology), words (morphology), sentences (syntax) and global meaning (semantics). As for social complexity, one can consider it at a macroscopic level in terms of population sizes of the language communities; at a mesoscopic level in which noise and disorder is added to the mathematical description; or at the detailed microscopic level of individuals, in which single speakers are simulated taking into account their diversity and random fluctuations.
Collecting information about languages
Traditionally, information about natural languages – those that have developed simply by humans speaking it – is collected through field work, which was the case for the studies of the Mazatec and Numic languages. It involves interviewing speakers to document the language, focusing on the spoken languages not the written texts. The data can then be analysed statistically using different mathematical methods and tools to estimate the linguistic distances between languages and to reveal language groups.
However, written texts offer another view on language, and is another part of linguistics that physicists can get involved in. By applying statistical physics, one can reveal regularities and statistical laws, such as Zipf’s law of brevity, which states that more frequently used words tend to be shorter. Today this type of study can be made using numerical tools and fast computers, allowing easy analysis of large digital databases. Doing this, the brevity law has been shown to hold for around 1000 languages from 80 different linguistic families.
The rise of social media has also opened up new ways of collecting linguistic data. People on Twitter, for example, communicate in real time, providing lots of data in the form of millions of geotagged posts from across the world and in a plethora of languages. Such data may be somewhat biased – users are predominantly young (12–34) and male – but they do contain a lot of interesting and intriguing information.
In one recent study, physicists from the Institute for Cross-Disciplinary Physics and Complex Systems (IFISC) in Spain (including author David Sánchez) built a high-resolution linguistic picture of various multilingual regions to capture the diversity of these societies and understand what drives language extinction (Phys. Rev. Research 3 043146). To do this, they used a dataset of 100 million Tweets, which were collected between 2015 and 2019 in 16 countries and regions. Language and location attribution was done automatically – with Twitter providing the location and the researchers using automatic tools to determine language – allowing the team to calculate the proportion of speakers in a given language and geographical location.
3 Mixing monolinguals

Belgium (top) and Catalonia (bottom) are both multilingual territories that contain monolingual communities. By analysing Tweets collected between 2015 and 2019, researchers were able to calculate the proportion of speakers of a given language in 100 km2 areas (the squares) for both countries. These maps show the proportions of (a) French, (b) Dutch, (c) Catalan and (d) Spanish speakers, where dark purple means there are no speakers of that language, and yellow indicates areas where only that language is spoken. Black means there were insufficient Tweets from that area to constitute a data set.
In Belgium, there is an obvious language divide between the regions of Flanders in the north where Dutch is dominant, and Wallonia in the south where French is mostly spoken. The most language mixing happens at the border (indicated by a black line). Brussels is also marked on the map and shows a concentration of French speakers. In contrast, the Catalonia map shows much more widespread mixing, with a slight difference between the central countryside and large coastal cities in the east.
Countries including Belgium or Switzerland were found to have monolingual communities separated by clear-cut boundaries, whereas in regions such as Catalonia speakers of the various languages appeared to be mixed (figure 3). The reasons behind these different distributions are mainly historical, but also related to language similarity and prestige.
Tweets can also provide valuable information about geographical lexical variation – when different words and phrases are used in different areas to refer to the same thing. One approach is to create a list of word variations for the same definition and study their spatial occurrences using clustering algorithms. By looking for similarities among elements with given lexical features and seeing how they form clusters, it is possible to find the dialect areas. Alternatively, one can take into account all words in the dataset of Tweets, not only those that show alternate forms.
In a recent study, the group at IFISC used this second method to map cultural regions in the US (Humanities and Social Sciences Communications 10 133). Based on the idea that cultural affiliation can be inferred from the topics that people discuss, the researchers looked at the frequency distributions of words in geotagged Tweets to find regional hotspots for them. From there, they were able to derive the main clusters of topical variation (figure 4).
4 Word culture
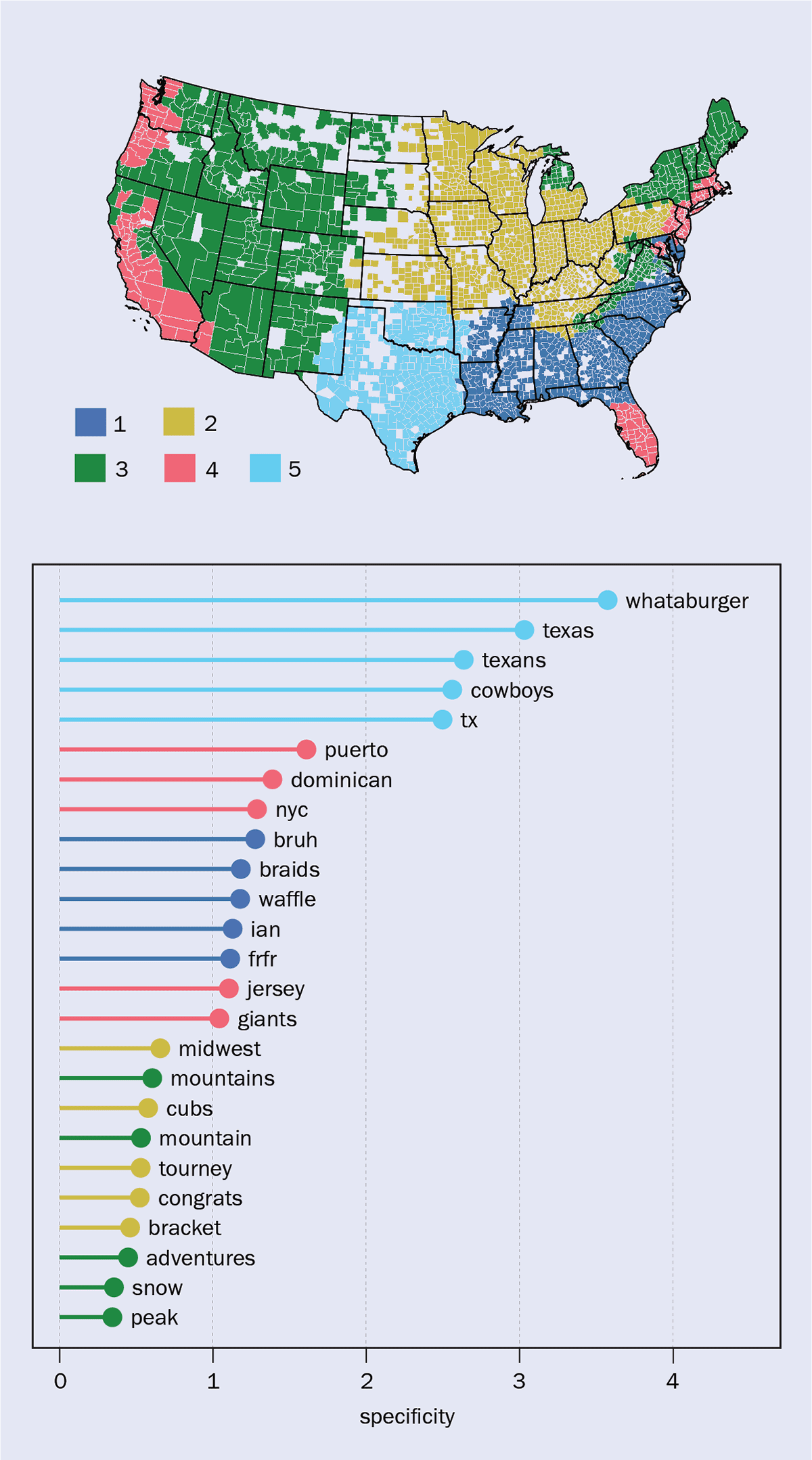
By looking at the contents of nine billion geotagged Tweets posted in the US from 2015 to 2021, researchers were able to build frequency distributions of words to find regional hotspots corresponding to their usage. From these words, and therefore the topics people discussed, the team was able to map out cultural regions (a). Each segment is a county, and those coloured white did not have enough data. The topics most frequently discussed in the different regions are: cuisine, fashion, music (blue); sports, school (yellow); nature, weather, outdoor activities (green); urban life, immigration, violence (red); self-reference, Hispanic culture (cyan). The most specific words for each region are displayed in (b).
Although such studies of social-media data can provide linguistic pictures over short time periods, the future challenge will be to track how languages, and the competition between them, evolve in time. Doing so, however, one has to remember that the way languages are used in real life and online can be different. Most online information is in English, but offline it is only the third most spoken native language, with Chinese far more common (even though it accounts for less than 2% of online language). Furthermore, many existing languages are not represented in online communication platforms at all.
Linguistic diversity
When we give talks to non-physicists about language dynamics, we have noticed that the link between physics and linguistics always triggers lively discussions. Language, of course, concerns us all. Sadly, however, many languages are dying. It has been estimated that 50–90% of the approximately 6000 languages spoken currently in the world will disappear by the end of this century. In other words, on average about every two weeks a language dies. Interestingly, areas with high biodiversity also have high linguistic diversity, and the loss of both occurs in parallel.
Returning to the notion of the research world as an ecosystem, we hope that physics spreading into linguistics does not have a negative effect, as is usually the case when one species invades another. Instead, we foresee a fruitful symbiosis, in which the tools and models of complex systems theory let us understand the mechanisms that drive how languages evolve and spread. This knowledge is not only interesting scientifically but also has a clear social impact that may help shape and support societies that are linguistically more inclusive.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- EVM Finance. Unified Interface for Decentralized Finance. Access Here.
- Quantum Media Group. IR/PR Amplified. Access Here.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Source: https://physicsworld.com/a/the-physics-of-languages/

