นี่เป็นโพสต์รับเชิญที่เขียนร่วมกับทีมผู้นำของ Iambic Therapeutics
การบำบัดด้วยไอแอมบิก เป็นสตาร์ทอัพด้านการค้นพบยาที่มีพันธกิจในการสร้างเทคโนโลยีที่ขับเคลื่อนด้วย AI ที่เป็นนวัตกรรมเพื่อนำยาที่ดีกว่ามาสู่ผู้ป่วยโรคมะเร็งได้เร็วขึ้น
เครื่องมือปัญญาประดิษฐ์ (AI) เชิงสร้างสรรค์และเชิงคาดการณ์ขั้นสูงของเราช่วยให้เราสามารถค้นหาโมเลกุลยาที่เป็นไปได้ในอวกาศอันกว้างใหญ่ได้รวดเร็วและมีประสิทธิภาพยิ่งขึ้น เทคโนโลยีของเรามีความหลากหลายและใช้ได้กับการรักษา ประเภทของโปรตีน และกลไกการออกฤทธิ์ นอกเหนือจากการสร้างเครื่องมือ AI ที่แตกต่างแล้ว เราได้สร้างแพลตฟอร์มบูรณาการที่ผสานรวมซอฟต์แวร์ AI ข้อมูลบนคลาวด์ โครงสร้างพื้นฐานการคำนวณที่ปรับขนาดได้ และความสามารถทางเคมีและชีววิทยาที่มีปริมาณงานสูง แพลตฟอร์มดังกล่าวช่วยให้ AI ของเรา—โดยการจัดหาข้อมูลเพื่อปรับแต่งแบบจำลองของเรา— และเปิดใช้งานโดยมัน โดยใช้ประโยชน์จากโอกาสในการตัดสินใจแบบอัตโนมัติและการประมวลผลข้อมูล
เราวัดความสำเร็จด้วยความสามารถของเราในการผลิตผู้สมัครทางคลินิกที่เหนือกว่า เพื่อตอบสนองความต้องการเร่งด่วนของผู้ป่วยด้วยความเร็วที่ไม่เคยมีมาก่อน: เราก้าวหน้าจากการเปิดตัวโปรแกรมไปสู่ผู้สมัครทางคลินิกในเวลาเพียง 24 เดือน ซึ่งเร็วกว่าคู่แข่งของเราอย่างมาก
ในโพสต์นี้ เราเน้นไปที่วิธีที่เราใช้ คาร์เพนเตอร์ on บริการ Amazon Elastic Kubernetes (Amazon EKS) เพื่อปรับขนาดการฝึกอบรมและการอนุมาน AI ซึ่งเป็นองค์ประกอบหลักของแพลตฟอร์มการค้นพบ Iambic
ความจำเป็นในการฝึกอบรมและการอนุมาน AI ที่ปรับขนาดได้
ทุกสัปดาห์ Iambic ดำเนินการอนุมาน AI ในแบบจำลองหลายสิบแบบและโมเลกุลนับล้าน โดยให้บริการกรณีการใช้งานหลักสองกรณี:
- นักเคมีทางการแพทย์และนักวิทยาศาสตร์คนอื่นๆ ใช้เว็บแอปพลิเคชัน Insight ของเราในการสำรวจพื้นที่ทางเคมี เข้าถึงและตีความข้อมูลการทดลอง และทำนายคุณสมบัติของโมเลกุลที่ออกแบบใหม่ งานทั้งหมดนี้ดำเนินการแบบโต้ตอบแบบเรียลไทม์ ทำให้ต้องมีการอนุมานที่มีความหน่วงต่ำและมีปริมาณงานปานกลาง
- ในเวลาเดียวกัน โมเดล AI เจนเนอเรชั่นของเราจะออกแบบโมเลกุลโดยอัตโนมัติโดยกำหนดเป้าหมายไปที่การปรับปรุงคุณสมบัติต่างๆ มากมาย ค้นหาผู้สมัครนับล้าน และต้องการปริมาณงานมหาศาลและมีเวลาแฝงปานกลาง
นำโดยเทคโนโลยี AI และนักล่ายาผู้เชี่ยวชาญ แพลตฟอร์มทดลองของเราสร้างโมเลกุลที่ไม่ซ้ำกันหลายพันโมเลกุลในแต่ละสัปดาห์ และแต่ละโมเลกุลจะต้องผ่านการตรวจวิเคราะห์ทางชีวภาพหลายครั้ง จุดข้อมูลที่สร้างขึ้นจะได้รับการประมวลผลโดยอัตโนมัติและใช้เพื่อปรับแต่งโมเดล AI ของเราทุกสัปดาห์ ในตอนแรก การปรับแต่งโมเดลอย่างละเอียดของเราใช้เวลาหลายชั่วโมงของ CPU ดังนั้นเฟรมเวิร์กสำหรับการปรับขนาดโมเดลอย่างละเอียดบน GPU จึงเป็นสิ่งจำเป็น
โมเดลการเรียนรู้เชิงลึกของเรามีข้อกำหนดที่ไม่สำคัญ: มีขนาดกิกะไบต์ จำนวนมากและต่างกัน และต้องใช้ GPU เพื่อการอนุมานที่รวดเร็วและการปรับแต่งอย่างละเอียด เมื่อพิจารณาถึงโครงสร้างพื้นฐานระบบคลาวด์ เราต้องการระบบที่ช่วยให้เราสามารถเข้าถึง GPU ปรับขนาดขึ้นและลงได้อย่างรวดเร็วเพื่อจัดการกับปริมาณงานที่แหลมคมและต่างกัน และเรียกใช้อิมเมจ Docker ขนาดใหญ่
เราต้องการสร้างระบบที่ปรับขนาดได้เพื่อรองรับการฝึกอบรมและการอนุมานของ AI เราใช้ Amazon EKS และกำลังมองหาโซลูชันที่ดีที่สุดในการปรับขนาดโหนดผู้ปฏิบัติงานของเราโดยอัตโนมัติ เราเลือก Karpenter สำหรับการปรับขนาดโหนด Kubernetes อัตโนมัติด้วยเหตุผลหลายประการ:
- บูรณาการกับ Kubernetes ได้ง่ายโดยใช้ความหมายของ Kubernetes เพื่อกำหนดข้อกำหนดของโหนดและข้อมูลจำเพาะของพ็อดสำหรับการปรับขนาด
- การขยายขนาดโหนดที่มีเวลาแฝงต่ำ
- ความง่ายในการบูรณาการกับโครงสร้างพื้นฐานของเราในฐานะเครื่องมือโค้ด (Terraform)
ตัวจัดเตรียมโหนดรองรับการผสานรวมกับ Amazon EKS และทรัพยากร AWS อื่นๆ ได้อย่างง่ายดาย เช่น อเมซอน อีลาสติก คอมพิวท์ คลาวด์ (Amazon EC2) อินสแตนซ์และ ร้านค้า Amazon Elastic Block เล่ม ซีแมนทิกส์ของ Kubernetes ที่ผู้จัดเตรียมใช้สนับสนุนการจัดกำหนดการโดยตรงโดยใช้โครงสร้าง Kubernetes เช่น เทนท์หรือความคลาดเคลื่อน และข้อกำหนดเฉพาะของความสัมพันธ์หรือการต่อต้านความสัมพันธ์ นอกจากนี้ยังอำนวยความสะดวกในการควบคุมจำนวนและประเภทของอินสแตนซ์ GPU ที่ Karpenter อาจกำหนดเวลาไว้
ภาพรวมโซลูชัน
ในส่วนนี้ เรานำเสนอสถาปัตยกรรมทั่วไปที่คล้ายกับสถาปัตยกรรมที่เราใช้กับปริมาณงานของเราเอง ซึ่งช่วยให้ปรับใช้โมเดลได้อย่างยืดหยุ่นโดยใช้การปรับขนาดอัตโนมัติที่มีประสิทธิภาพตามตัววัดแบบกำหนดเอง
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมโซลูชัน

สถาปัตยกรรมปรับใช้ก บริการที่เรียบง่าย ในพ็อด Kubernetes ภายในไฟล์ คลัสเตอร์ EKS- นี่อาจเป็นการอนุมานแบบจำลอง การจำลองข้อมูล หรือบริการแบบคอนเทนเนอร์อื่นๆ ที่เข้าถึงได้โดยคำขอ HTTP บริการนี้แสดงอยู่หลังการใช้พร็อกซีย้อนกลับ ทราฟิก. พร็อกซีย้อนกลับรวบรวมตัววัดเกี่ยวกับการเรียกบริการและเปิดเผยผ่าน API ตัววัดมาตรฐาน โพร- ตัวปรับขนาดอัตโนมัติที่ขับเคลื่อนด้วยเหตุการณ์ Kubernetes (เคด้า) ได้รับการกำหนดค่าให้ปรับขนาดจำนวนพ็อดบริการโดยอัตโนมัติ โดยอิงตามตัววัดแบบกำหนดเองที่มีอยู่ใน Prometheus ที่นี่เราใช้จำนวนคำขอต่อวินาทีเป็นหน่วยวัดที่กำหนดเอง ใช้แนวทางสถาปัตยกรรมเดียวกันหากคุณเลือกตัววัดอื่นสำหรับปริมาณงานของคุณ
Karpenter จะตรวจสอบพ็อดที่ค้างอยู่ซึ่งไม่สามารถทำงานได้เนื่องจากขาดทรัพยากรเพียงพอในคลัสเตอร์ หากตรวจพบพ็อดดังกล่าว Karpenter จะเพิ่มโหนดเพิ่มเติมให้กับคลัสเตอร์เพื่อจัดหาทรัพยากรที่จำเป็น ในทางกลับกัน หากมีโหนดในคลัสเตอร์มากกว่าที่พ็อดที่กำหนดเวลาไว้ต้องการ Karpenter จะลบโหนดของผู้ปฏิบัติงานบางส่วนออก และพ็อดจะถูกจัดกำหนดการใหม่ โดยจะรวมเข้าด้วยกันในอินสแตนซ์ที่น้อยลง จำนวนคำขอ HTTP ต่อวินาทีและจำนวนโหนดสามารถแสดงภาพได้โดยใช้ กราฟาน่า แผงควบคุม. เพื่อสาธิตการปรับขนาดอัตโนมัติ เราเรียกใช้อย่างน้อยหนึ่งรายการ พ็อดที่สร้างภาระอย่างง่ายซึ่งส่งคำขอ HTTP ไปยังบริการโดยใช้ โค้ง.
การปรับใช้โซลูชัน
ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร คำแนะนำแบบทีละขั้นตอน, เราใช้ AWS Cloud9 เป็นสภาพแวดล้อมในการปรับใช้สถาปัตยกรรม ซึ่งช่วยให้สามารถดำเนินการทุกขั้นตอนให้เสร็จสิ้นได้จากเว็บเบราว์เซอร์ คุณยังสามารถปรับใช้โซลูชันจากคอมพิวเตอร์เฉพาะที่หรืออินสแตนซ์ EC2 ได้อีกด้วย
เพื่อให้การปรับใช้ง่ายขึ้นและปรับปรุงความสามารถในการทำซ้ำ เราปฏิบัติตามหลักการของ ทำกรอบ และโครงสร้างของ เทมเพลตที่พึ่งพานักเทียบท่า- เราโคลน aws-ทำ-eks โครงการและการใช้ นักเทียบท่าเราสร้างคอนเทนเนอร์อิมเมจที่ติดตั้งเครื่องมือและสคริปต์ที่จำเป็น ภายในคอนเทนเนอร์ เราดำเนินการผ่านทุกขั้นตอนของการแนะนำตั้งแต่ต้นจนจบ ตั้งแต่การสร้างคลัสเตอร์ EKS ด้วย Karpenter ไปจนถึงการปรับขนาด อินสแตนซ์ EC2.
สำหรับตัวอย่างในโพสต์นี้ เราใช้ดังต่อไปนี้ รายการคลัสเตอร์ EKS:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueรายการนี้จะกำหนดคลัสเตอร์ที่ชื่อ do-eks-yaml-karpenter โดยติดตั้งไดรเวอร์ EBS CSI เป็นส่วนเสริม กลุ่มโหนดที่ได้รับการจัดการที่มีสองกลุ่ม c5.xlarge โหนดถูกรวมไว้เพื่อเรียกใช้พ็อดระบบที่คลัสเตอร์ต้องการ โหนดของผู้ปฏิบัติงานโฮสต์อยู่ในเครือข่ายย่อยส่วนตัว และจุดสิ้นสุด API ของคลัสเตอร์จะเป็นสาธารณะตามค่าเริ่มต้น
คุณยังสามารถใช้คลัสเตอร์ EKS ที่มีอยู่แทนการสร้างคลัสเตอร์ได้ เราปรับใช้ Karpenter โดยปฏิบัติตาม คำแนะนำการใช้ ในเอกสารประกอบของ Karpenter หรือโดยการรันสิ่งต่อไปนี้ ต้นฉบับซึ่งจะทำให้คำแนะนำการใช้งานเป็นแบบอัตโนมัติ
รหัสต่อไปนี้แสดงการกำหนดค่า Karpenter ที่เราใช้ในตัวอย่างนี้:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueเรากำหนด Karpenter NodePool เริ่มต้นโดยมีข้อกำหนดต่อไปนี้:
- Karpenter สามารถเรียกใช้อินสแตนซ์จากทั้งสองอย่างได้
spotและon-demandพูลความจุ - อินสแตนซ์จะต้องมาจาก “
c” (เพิ่มประสิทธิภาพการประมวลผล) “m" (จุดประสงค์ทั่วไป), "r” (เพิ่มประสิทธิภาพหน่วยความจำ) หรือ “g"และ"p” (เร่ง GPU) ตระกูลการประมวลผล - การสร้างอินสแตนซ์ต้องมากกว่า 2; ตัวอย่างเช่น,
g3เป็นที่ยอมรับแต่g2ไม่ใช่
NodePool เริ่มต้นยังกำหนดนโยบายการหยุดชะงักด้วย โหนดที่มีการใช้งานน้อยเกินไปจะถูกลบออกเพื่อให้สามารถรวมพ็อดเพื่อให้ทำงานบนโหนดน้อยลงหรือเล็กลงได้ หรืออีกทางหนึ่ง เราสามารถกำหนดค่าโหนดว่างที่จะลบออกหลังจากระยะเวลาที่กำหนดได้ ที่ expireAfter การตั้งค่าจะระบุอายุการใช้งานสูงสุดของโหนดใดๆ ก่อนที่จะหยุดและเปลี่ยนใหม่หากจำเป็น ซึ่งช่วยลดช่องโหว่ด้านความปลอดภัย รวมทั้งหลีกเลี่ยงปัญหาที่มักเกิดขึ้นกับโหนดที่มีเวลาทำงานนาน เช่น การแตกแฟรกเมนต์ของไฟล์หรือหน่วยความจำรั่ว
ตามค่าเริ่มต้น Karpenter จะจัดเตรียมโหนดด้วยปริมาณรูทที่น้อย ซึ่งอาจไม่เพียงพอสำหรับการรันปริมาณงาน AI หรือ Machine Learning (ML) อิมเมจคอนเทนเนอร์การเรียนรู้เชิงลึกบางอิมเมจอาจมีขนาดได้หลายสิบ GB และเราจำเป็นต้องตรวจสอบให้แน่ใจว่ามีพื้นที่เก็บข้อมูลเพียงพอบนโหนดเพื่อเรียกใช้พ็อดโดยใช้อิมเมจเหล่านี้ เพื่อทำเช่นนั้นเรากำหนด EC2NodeClass กับ blockDeviceMappingsดังที่แสดงในโค้ดก่อนหน้า
Karpenter มีหน้าที่รับผิดชอบในการปรับขนาดอัตโนมัติในระดับคลัสเตอร์ ในการกำหนดค่าการปรับขนาดอัตโนมัติที่ระดับพ็อด เราใช้ KEDA เพื่อกำหนดทรัพยากรที่กำหนดเองที่เรียกว่า ScaledObjectดังแสดงในรหัสต่อไปนี้:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])รายการก่อนหน้านี้กำหนดก ScaledObject ชื่อ keda-prometheus-hpaซึ่งมีหน้าที่รับผิดชอบในการปรับขนาดการปรับใช้ php-apache และคอยจำลองอย่างน้อยหนึ่งรายการอยู่เสมอ โดยจะปรับขนาดพ็อดของการปรับใช้นี้ตามเมตริก http_requests_total มีอยู่ใน Prometheus ที่ได้รับจากการสืบค้นที่ระบุ และมีเป้าหมายที่จะขยายขนาดพ็อดเพื่อให้แต่ละพ็อดให้บริการได้ไม่เกินหนึ่งคำขอต่อวินาที โดยจะลดขนาดแบบจำลองลงหลังจากที่โหลดคำขอต่ำกว่าเกณฑ์เป็นเวลานานกว่า 30 วินาที
พื้นที่ ข้อมูลจำเพาะการใช้งาน สำหรับบริการตัวอย่างของเรามีดังต่อไปนี้ คำขอและขีดจำกัดทรัพยากร:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1ด้วยการกำหนดค่านี้ แต่ละพ็อดบริการจะใช้ NVIDIA GPU เพียงตัวเดียว เมื่อมีการสร้างพ็อดใหม่ พ็อดเหล่านั้นจะอยู่ในสถานะรอดำเนินการจนกว่า GPU จะพร้อมใช้งาน Karpenter เพิ่มโหนด GPU ให้กับคลัสเตอร์ตามความจำเป็นเพื่อรองรับพ็อดที่ค้างอยู่
A พ็อดที่สร้างภาระ ส่งคำขอ HTTP ไปยังบริการด้วยความถี่ที่ตั้งไว้ล่วงหน้า เราเพิ่มจำนวนคำขอโดยการเพิ่มจำนวนแบบจำลองใน การปรับใช้เครื่องกำเนิดโหลด.
วงจรการปรับขนาดเต็มรูปแบบพร้อมการรวมโหนดตามการใช้งานจะแสดงเป็นภาพในแดชบอร์ด Grafana แดชบอร์ดต่อไปนี้แสดงจำนวนโหนดในคลัสเตอร์ตามประเภทอินสแตนซ์ (บนสุด) จำนวนคำขอต่อวินาที (ซ้ายล่าง) และจำนวนพ็อด (ขวาล่าง)
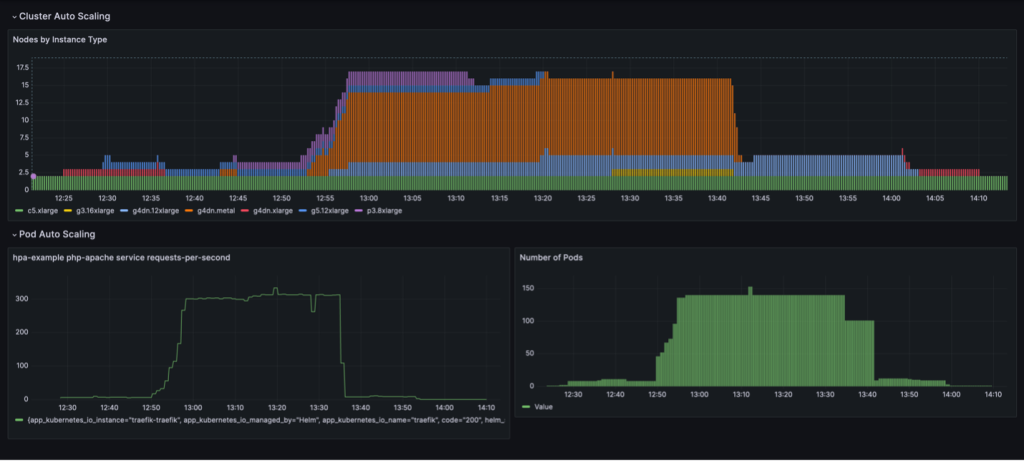
เราเริ่มต้นด้วยอินสแตนซ์ CPU c5.xlarge เพียงสองตัวที่ใช้สร้างคลัสเตอร์ จากนั้นเราจะปรับใช้อินสแตนซ์บริการหนึ่งอินสแตนซ์ซึ่งต้องใช้ GPU ตัวเดียว Karpenter เพิ่มอินสแตนซ์ g4dn.xlarge เพื่อรองรับความต้องการนี้ จากนั้นเราจะปรับใช้ตัวสร้างโหลด ซึ่งทำให้ KEDA เพิ่มพ็อดบริการเพิ่มเติม และ Karpenter เพิ่มอินสแตนซ์ GPU มากขึ้น หลังจากการเพิ่มประสิทธิภาพ สถานะจะตัดสินบนอินสแตนซ์ p3.8xlarge หนึ่งอินสแตนซ์ที่มี GPU 8 ตัว และอินสแตนซ์ g5.12xlarge หนึ่งอินสแตนซ์ที่มี GPU 4 ตัว
เมื่อเราปรับขนาดการใช้งานที่สร้างโหลดเป็น 40 เรพลิกา KEDA จะสร้างพ็อดบริการเพิ่มเติมเพื่อรักษาโหลดคำขอที่ต้องการต่อพ็อด Karpenter เพิ่มโหนด g4dn.metal และ g4dn.12xlarge ให้กับคลัสเตอร์เพื่อจัดเตรียม GPU ที่จำเป็นสำหรับพ็อดเพิ่มเติม ในสถานะที่ปรับขนาด คลัสเตอร์จะมีโหนด GPU 16 โหนด และให้บริการคำขอประมาณ 300 รายการต่อวินาที เมื่อเราลดขนาดตัวสร้างโหลดลงเหลือ 1 เรพลิกา กระบวนการย้อนกลับจะเกิดขึ้น หลังจากช่วงคูลดาวน์ KEDA จะลดจำนวนพ็อดบริการ จากนั้นเมื่อพ็อดทำงานน้อยลง Karpenter จะลบโหนดที่ไม่ได้ใช้งานออกจากคลัสเตอร์ และพ็อดบริการจะถูกรวมเข้าด้วยกันเพื่อให้ทำงานบนโหนดน้อยลง เมื่อลบพ็อดตัวสร้างโหลดแล้ว พ็อดบริการเดียวบนอินสแตนซ์ g4dn.xlarge เดียวที่มี 1 GPU จะยังคงทำงานอยู่ เมื่อเราลบพ็อดบริการด้วย คลัสเตอร์จะคงอยู่ในสถานะเริ่มต้นโดยมีโหนด CPU เพียงสองโหนดเท่านั้น
เราสามารถสังเกตพฤติกรรมนี้ได้เมื่อ NodePool มีการตั้งค่า consolidationPolicy: WhenUnderutilized.
ด้วยการตั้งค่านี้ Karpenter จะกำหนดค่าคลัสเตอร์แบบไดนามิกโดยใช้โหนดน้อยที่สุดเท่าที่จะทำได้ ในขณะเดียวกันก็จัดหาทรัพยากรที่เพียงพอสำหรับพ็อดทั้งหมดในการทำงานและยังลดต้นทุนให้เหลือน้อยที่สุดอีกด้วย
พฤติกรรมการปรับขนาดที่แสดงในแดชบอร์ดต่อไปนี้จะถูกสังเกตเมื่อ NodePool นโยบายการรวมถูกตั้งค่าเป็น WhenEmpty, พร้อมด้วย consolidateAfter: 30s.
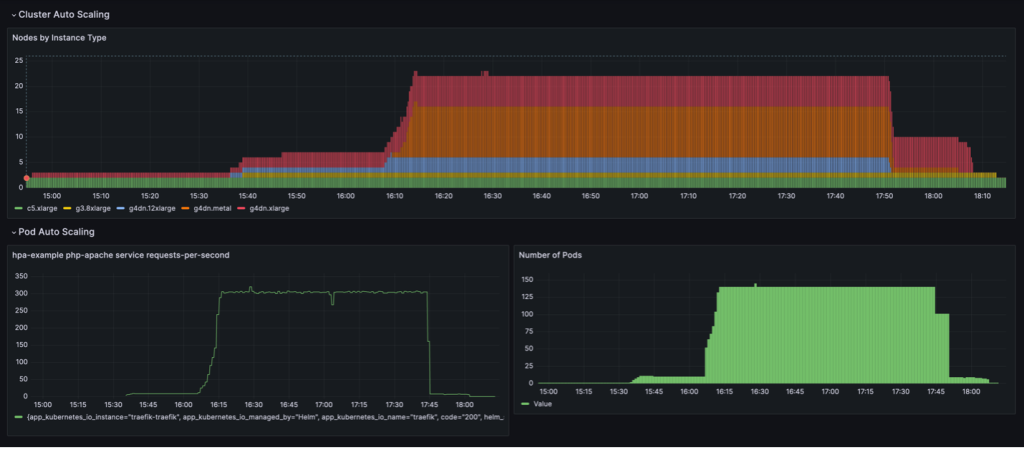
ในสถานการณ์สมมตินี้ โหนดจะหยุดเฉพาะเมื่อไม่มีพ็อดที่ทำงานอยู่หลังจากช่วงพักเครื่อง เส้นโค้งมาตราส่วนดูราบรื่น เมื่อเทียบกับนโยบายการรวมตามการใช้งาน อย่างไรก็ตามจะเห็นได้ว่ามีการใช้โหนดมากขึ้นในสถานะที่ปรับขนาด (22 ต่อ 16)
โดยรวมแล้ว การรวมการปรับขนาดอัตโนมัติของพ็อดและคลัสเตอร์เข้าด้วยกันทำให้แน่ใจได้ว่าคลัสเตอร์จะปรับขนาดแบบไดนามิกตามปริมาณงาน โดยจัดสรรทรัพยากรเมื่อจำเป็นและลบออกเมื่อไม่ได้ใช้งาน จึงช่วยเพิ่มการใช้งานสูงสุดและลดค่าใช้จ่ายให้เหลือน้อยที่สุด
ผลลัพธ์
Iambic ใช้สถาปัตยกรรมนี้เพื่อให้สามารถใช้งาน GPU อย่างมีประสิทธิภาพบน AWS และย้ายปริมาณงานจาก CPU ไปยัง GPU ด้วยการใช้อินสแตนซ์ที่ขับเคลื่อนด้วย EC2 GPU, Amazon EKS และ Karpenter เราสามารถเปิดใช้งานการอนุมานที่รวดเร็วยิ่งขึ้นสำหรับแบบจำลองทางฟิสิกส์ของเรา และเวลาทำซ้ำการทดสอบที่รวดเร็วสำหรับนักวิทยาศาสตร์ประยุกต์ที่ต้องอาศัยการฝึกอบรมเป็นบริการ
ตารางต่อไปนี้สรุปเมตริกเวลาบางส่วนในการย้ายข้อมูลนี้
| งาน | ซีพียู | GPUs |
| การอนุมานโดยใช้แบบจำลองการแพร่กระจายสำหรับแบบจำลอง ML ตามหลักฟิสิกส์ | วินาที 3,600 |
วินาที 100 (เนื่องจากการแบทช์ GPU โดยธรรมชาติ) |
| การฝึกอบรมโมเดล ML เป็นบริการ | 180 นาที | 4 นาที |
ตารางต่อไปนี้สรุปเมตริกเวลาและต้นทุนบางส่วนของเรา
| งาน | ประสิทธิภาพ/ต้นทุน | |
| ซีพียู | GPUs | |
| การฝึกอบรมโมเดล ML |
240 นาที เฉลี่ย $0.70 ต่องานการฝึกอบรม |
20 นาที เฉลี่ย $0.38 ต่องานการฝึกอบรม |
สรุป
ในโพสต์นี้ เราได้แสดงให้เห็นว่า Iambic ใช้ Karpenter และ KEDA เพื่อปรับขนาดโครงสร้างพื้นฐาน Amazon EKS ของเราอย่างไรให้ตรงตามข้อกำหนดด้านเวลาแฝงของการอนุมาน AI และปริมาณงานการฝึกอบรมของเรา Karpenter และ KEDA เป็นเครื่องมือโอเพ่นซอร์สที่ทรงพลังที่ช่วยปรับขนาดคลัสเตอร์ EKS และปริมาณงานที่ทำงานอยู่โดยอัตโนมัติ ซึ่งช่วยปรับต้นทุนการประมวลผลให้เหมาะสมในขณะที่ตอบสนองความต้องการด้านประสิทธิภาพ คุณสามารถตรวจสอบโค้ดและปรับใช้สถาปัตยกรรมเดียวกันในสภาพแวดล้อมของคุณเองโดยทำตามคำแนะนำแบบสมบูรณ์ในสิ่งนี้ repo GitHub.
เกี่ยวกับผู้เขียน
 แมทธิว เวลบอร์น เป็นผู้อำนวยการฝ่าย Machine Learning ที่ Iambic Therapeutics เขาและทีมใช้ประโยชน์จาก AI เพื่อเร่งการระบุและพัฒนาวิธีการรักษาแบบใหม่ โดยนำยาช่วยชีวิตมาสู่ผู้ป่วยได้เร็วขึ้น
แมทธิว เวลบอร์น เป็นผู้อำนวยการฝ่าย Machine Learning ที่ Iambic Therapeutics เขาและทีมใช้ประโยชน์จาก AI เพื่อเร่งการระบุและพัฒนาวิธีการรักษาแบบใหม่ โดยนำยาช่วยชีวิตมาสู่ผู้ป่วยได้เร็วขึ้น
 พอล วิทเทมอร์ เป็นวิศวกรหลักที่ Iambic Therapeutics เขาสนับสนุนการส่งมอบโครงสร้างพื้นฐานสำหรับแพลตฟอร์มการค้นพบยาที่ขับเคลื่อนด้วย Iambic AI
พอล วิทเทมอร์ เป็นวิศวกรหลักที่ Iambic Therapeutics เขาสนับสนุนการส่งมอบโครงสร้างพื้นฐานสำหรับแพลตฟอร์มการค้นพบยาที่ขับเคลื่อนด้วย Iambic AI
 อเล็กซ์ เอียนคูลสกี้ เป็นสถาปนิกโซลูชันหลัก เฟรมเวิร์ก ML/AI ซึ่งมุ่งเน้นที่การช่วยลูกค้าจัดการปริมาณงาน AI โดยใช้คอนเทนเนอร์และโครงสร้างพื้นฐานการประมวลผลแบบเร่งบน AWS
อเล็กซ์ เอียนคูลสกี้ เป็นสถาปนิกโซลูชันหลัก เฟรมเวิร์ก ML/AI ซึ่งมุ่งเน้นที่การช่วยลูกค้าจัดการปริมาณงาน AI โดยใช้คอนเทนเนอร์และโครงสร้างพื้นฐานการประมวลผลแบบเร่งบน AWS
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

