Predstavitev
Delate v svetovalnem podjetju kot podatkovni znanstvenik. Projekt, ki ste mu trenutno dodeljeni, vsebuje podatke študentov, ki so pred kratkim končali tečaje o financah. Finančna družba, ki izvaja tečaje, želi razumeti, ali obstajajo skupni dejavniki, ki vplivajo na študente, da kupijo iste ali različne tečaje. Z razumevanjem teh dejavnikov lahko podjetje ustvari profil študenta, razvrsti vsakega študenta po profilu in priporoči seznam tečajev.
Pri pregledovanju podatkov iz različnih skupin študentov ste naleteli na tri razporeditve točk, kot v 1, 2 in 3 spodaj:

Upoštevajte, da so na risbi 1 vijolične točke, organizirane v polkrogu, z množico rožnatih točk znotraj tega kroga, majhno koncentracijo oranžnih točk zunaj tega polkroga in pet sivih točk, ki so daleč od vseh drugih.
Na risbi 2 je okrogla množica vijoličnih točk, druga oranžnih točk in tudi štiri sive točke, ki so daleč od vseh ostalih.
In na grafu 3 lahko vidimo štiri koncentracije točk, vijolično, modro, oranžno, rožnato in še tri oddaljene sive točke.
Zdaj, če bi izbrali model, ki bi lahko razumel nove podatke študentov in določil podobne skupine, ali obstaja algoritem za združevanje v gruče, ki bi lahko dal zanimive rezultate za to vrsto podatkov?
Pri opisovanju parcel smo omenjali izraze kot so masa točk in koncentracija točk, kar kaže, da so v vseh grafih področja z večjo gostoto. Sklicevali smo se tudi na Krožna in polkrožna oblike, ki jih je težko prepoznati z risanjem ravne črte ali zgolj s pregledovanjem najbližjih točk. Poleg tega obstajajo nekatere oddaljene točke, ki verjetno odstopajo od glavne distribucije podatkov, kar predstavlja več izzivov oz. hrupa pri določanju skupin.
Algoritem na podlagi gostote, ki lahko filtrira hrup, kot je npr DBSCAN (Dentiteta-Based Spacialno Cluster of Applikacije z Noise), je dobra izbira za razmere z gostejšimi območji, zaobljenimi oblikami in hrupom.
O DBSCAN
DBSCAN je eden najbolj citiranih algoritmov v raziskavah, njegova prva objava se pojavi leta 1996, to je izvirni papir DBSCAN. V prispevku raziskovalci prikazujejo, kako lahko algoritem identificira nelinearne prostorske skupine in učinkovito obravnava podatke z višjimi dimenzijami.
Glavna ideja za DBSCAN je, da obstaja minimalno število točk, ki bodo znotraj določene razdalje oz polmer od najbolj »centralne« točke grozda, imenovane osrednja točka. Točke znotraj tega radija so točke soseske, točke na robu te soseske pa so mejne točke or mejne točke. Imenuje se polmer ali sosedska razdalja epsilon soseska, ε-soseska ali samo ε (simbol za grško črko epsilon).
Poleg tega, če obstajajo točke, ki niso jedrne točke ali mejne točke, ker presegajo polmer za pripadnost določeni gruči in tudi nimajo najmanjšega števila točk, da bi bile jedrna točka, se štejejo točke hrupa.
To pomeni, da imamo tri različne vrste točk, in sicer jedro, meja in hrupa. Poleg tega je pomembno omeniti, da glavna ideja v osnovi temelji na polmeru ali razdalji, zaradi česar je DBSCAN – tako kot večina modelov združevanja v gruče – odvisen od te metrike razdalje. Ta metrika je lahko Evklidska, Manhattanska, Mahalanobisova in še veliko več. Zato je ključnega pomena izbrati ustrezno metriko razdalje, ki upošteva kontekst podatkov. Na primer, če uporabljate podatke o razdalji vožnje iz GPS-a, bi bilo morda zanimivo uporabiti meritev, ki upošteva razporeditev ulic, kot je razdalja Manhattan.

Opomba: Ker DBSCAN preslika točke, ki predstavljajo hrup, ga je mogoče uporabiti tudi kot algoritem za odkrivanje izstopov. Če na primer poskušate ugotoviti, katere bančne transakcije so morda goljufive in je stopnja goljufivih transakcij majhna, je DBSCAN morda rešitev za prepoznavanje teh točk.
Za iskanje jedrne točke bo DBSCAN najprej naključno izbral točko, preslikal vse točke v njeni ε-soseski in primerjal število sosedov izbrane točke z najmanjšim številom točk. Če ima izbrana točka enako ali več sosedov od minimalnega števila točk, bo označena kot jedrna točka. Ta osrednja točka in njene sosedske točke bodo tvorile prvi grozd.
Algoritem bo nato pregledal vsako točko prve gruče in ugotovil, ali ima enako ali več sosednjih točk od minimalnega števila točk znotraj ε. Če se, bodo te sosednje točke prav tako dodane v prvo gručo. Ta proces se bo nadaljeval, dokler bodo imele točke prvega grozda manj sosedov od najmanjšega števila točk znotraj ε. Ko se to zgodi, algoritem preneha dodajati točke tej gruči, identificira drugo jedrno točko zunaj te gruče in ustvari novo gručo za to novo jedrno točko.
DBSCAN bo nato ponavljal prvi postopek gruče iskanja vseh točk, povezanih z novo osrednjo točko druge gruče, dokler ne bo več točk, ki bi jih bilo treba dodati tej gruči. Nato bo naletel na drugo osrednjo točko in ustvaril tretjo gručo ali pa bo ponovil vse točke, ki jih prej ni pogledal. Če so te točke na razdalji ε od gruče, se dodajo tej gruči in postanejo mejne točke. Če niso, se štejejo za točke hrupa.
Nasvet: V zamisel o DBSCAN je vključenih veliko pravil in matematičnih predstavitev. Če se želite poglobiti, si boste morda želeli ogledati izvirni dokument, ki je na zgornji povezavi.
Zanimivo je vedeti, kako deluje algoritem DBSCAN, čeprav na srečo algoritma ni treba kodirati, ko Pythonova knjižnica Scikit-Learn že ima izvedbo.
Poglejmo, kako deluje v praksi!
Uvažanje podatkov za združevanje v gruče
Da bi videli, kako DBSCAN deluje v praksi, bomo nekoliko spremenili projekte in uporabili majhen nabor podatkov o strankah, ki ima žanr, starost, letni dohodek in oceno porabe 200 strank.
Ocena porabe se giblje od 0 do 100 in predstavlja, kako pogosto oseba porabi denar v nakupovalnem središču na lestvici od 1 do 100. Z drugimi besedami, če ima stranka oceno 0, nikoli ne porabi denarja, če pa je ocena 100, so največji porabniki.
Opomba: Nabor podatkov lahko prenesete tukaj.
Ko prenesete nabor podatkov, boste videli, da gre za datoteko CSV (vrednosti, ločene z vejicami), imenovano shopping-data.csv, ga bomo naložili v DataFrame z uporabo Pandas in shranili v customer_data spremenljivka:
import pandas as pd path_to_file = '../../datasets/dbscan/dbscan-with-python-and-scikit-learn-shopping-data.csv'
customer_data = pd.read_csv(path_to_file)
Če si želite ogledati prvih pet vrstic naših podatkov, lahko izvedete customer_data.head():
Rezultat tega je:
CustomerID Genre Age Annual Income (k$) Spending Score (1-100)
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40
S pregledovanjem podatkov lahko vidimo ID številke stranke, žanr, starost, prihodke v tisoč $ in rezultate porabe. Upoštevajte, da bodo nekatere ali vse te spremenljivke uporabljene v modelu. Na primer, če bi uporabili Age in Spending Score (1-100) kot spremenljivke za DBSCAN, ki uporablja metriko razdalje, je pomembno, da jih spravite v skupno lestvico, da se izognete vnašanju popačenj, saj Age se meri v letih in Spending Score (1-100) ima omejen obseg od 0 do 100. To pomeni, da bomo izvedli neke vrste skaliranje podatkov.
Prav tako lahko preverimo, ali podatki potrebujejo dodatno predprocesiranje poleg skaliranja, tako da preverimo, ali je vrsta podatkov skladna, in preverimo, ali obstajajo kakšne manjkajoče vrednosti, ki jih je treba obdelati z izvajanjem Pandinega info() metoda:
customer_data.info()
To prikaže:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CustomerID 200 non-null int64 1 Genre 200 non-null object 2 Age 200 non-null int64 3 Annual Income (k$) 200 non-null int64 4 Spending Score (1-100) 200 non-null int64 dtypes: int64(4), object(1)
memory usage: 7.9+ KB
Opazimo lahko, da ni manjkajočih vrednosti, ker je za vsako funkcijo stranke 200 vnosov, ki niso ničelni. Vidimo lahko tudi, da ima samo žanrski stolpec besedilno vsebino, saj gre za kategorično spremenljivko, ki je prikazana kot object, vse druge funkcije pa so numerične, tipa int64. Tako so naši podatki pripravljeni za nadaljnjo analizo v smislu doslednosti tipov podatkov in odsotnosti ničelnih vrednosti.
Lahko nadaljujemo z vizualizacijo podatkov in ugotovimo, katere funkcije bi bile zanimive za uporabo v DBSCAN. Ko izberemo te funkcije, jih lahko prilagodimo.
Ta nabor podatkov o strankah je enak tistemu, uporabljenemu v našem dokončnem vodniku za hierarhično združevanje v gruče. Če želite izvedeti več o teh podatkih, kako jih raziskati in o meritvah razdalje, si lahko ogledate Dokončni vodnik za hierarhično združevanje v gruče s Pythonom in Scikit-Learn!
Vizualizacija podatkov
Z uporabo Seabornovega pairplot(), lahko narišemo raztreseni graf za vsako kombinacijo funkcij. Od CustomerID je samo identifikacija in ne funkcija, odstranili jo bomo z drop() pred risanjem:
import seaborn as sns customer_data = customer_data.drop('CustomerID', axis=1) sns.pairplot(customer_data);
To ustvari:
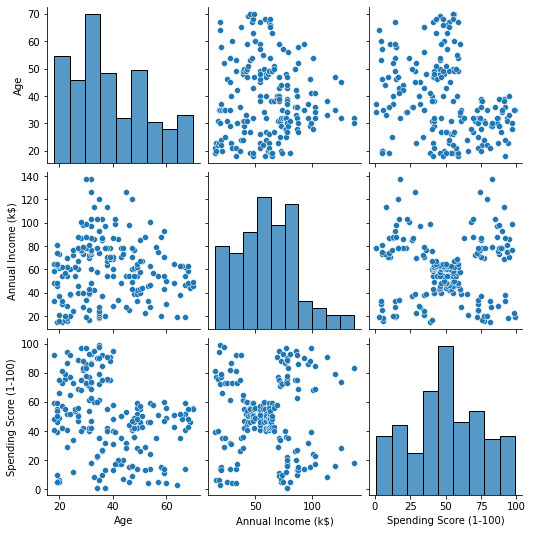
Če pogledamo kombinacijo funkcij, ki jih proizvaja pairplot, graf od Annual Income (k$) z Spending Score (1-100) zdi se, da prikazuje približno 5 skupin točk. Zdi se, da je to najbolj obetavna kombinacija lastnosti. Ustvarimo lahko seznam z njihovimi imeni, jih izberemo iz customer_data DataFrame in shranite izbor v customer_data spet spremenljivko za uporabo v našem prihodnjem modelu.
selected_cols = ['Annual Income (k$)', 'Spending Score (1-100)']
customer_data = customer_data[selected_cols]
Ko izberemo stolpce, lahko izvedemo skaliranje, o katerem smo govorili v prejšnjem razdelku. Da značilnosti spravimo v enako merilo oz standardizirati jih lahko uvozimo Scikit-Learn's StandardScaler, ga ustvarimo, prilagodimo naše podatke za izračun njegove srednje vrednosti in standardnega odklona ter transformiramo podatke tako, da odštejemo njihovo povprečje in ga delimo s standardnim odklonom. To lahko storite v enem koraku z fit_transform() metoda:
from sklearn.preprocessing import StandardScaler ss = StandardScaler() scaled_data = ss.fit_transform(customer_data)
Spremenljivke so zdaj skalirane in jih lahko pregledamo tako, da preprosto natisnemo vsebino scaled_data spremenljivka. Lahko pa jih tudi dodamo v novo scaled_customer_data DataFrame skupaj z imeni stolpcev in uporabite head() spet metoda:
scaled_customer_data = pd.DataFrame(columns=selected_cols, data=scaled_data)
scaled_customer_data.head()
To ustvari:
Annual Income (k$) Spending Score (1-100)
0 -1.738999 -0.434801
1 -1.738999 1.195704
2 -1.700830 -1.715913
3 -1.700830 1.040418
4 -1.662660 -0.395980 Ti podatki so pripravljeni za združevanje v gruče! Pri predstavitvi DBSCAN smo omenili minimalno število točk in epsilon. Ti dve vrednosti je treba izbrati pred ustvarjanjem modela. Poglejmo, kako se to naredi.
Izbira min. Vzorci in Epsilon
Če želite izbrati najmanjše število točk za združevanje v gruče DBSCAN, obstaja pravilo, ki navaja, da mora biti enako ali večje od števila dimenzij v podatkih plus ena, kot v:
$$
besedilo{min. točke} >= besedilo{dimenzije podatkov} + 1
$$
Dimenzije so število stolpcev v podatkovnem okviru, uporabljamo 2 stolpca, tako da min. točke naj bodo 2+1, kar je 3, ali višje. Za ta primer uporabimo 5 min. točke.
$$
besedilo{5 (min. točk)} >= besedilo{2 (dimenzije podatkov)} + 1
$$
Oglejte si naš praktični, praktični vodnik za učenje Gita z najboljšimi praksami, standardi, sprejetimi v panogi, in priloženo goljufijo. Nehajte Googlati ukaze Git in pravzaprav naučiti it!
Za izbiro vrednosti za ε obstaja metoda, pri kateri a Najbližji sosedje algoritem se uporablja za iskanje razdalj vnaprej določenega števila najbližjih točk za vsako točko. To vnaprej določeno število sosedov je min. točke, ki smo jih pravkar izbrali minus 1. Torej bo v našem primeru algoritem našel 5-1 ali 4 najbližje točke za vsako točko naših podatkov. to so k-sosedi in naše k enako 4.
$$
besedilo{k-sosedi} = besedilo{min. točke} – 1
$$
Ko najdemo sosede, bomo njihove razdalje razporedili od največjega do najmanjšega in narisali razdalje osi y in točk na osi x. Če pogledamo graf, bomo ugotovili, kje je podoben upognjenosti komolca in točka osi y, ki opisuje ta upognjen komolec, je predlagana vrednost ε.
Opombe: možno je, da ima graf za iskanje vrednosti ε enega ali več "ukrivljenih komolcev", bodisi velikih ali majhnih, ko se to zgodi, lahko poiščete vrednosti, jih preizkusite in izberete tiste z rezultati, ki najbolje opisujejo grozde, bodisi z ogledom metrike ploskev.
Za izvedbo teh korakov lahko uvozimo algoritem, ga prilagodimo podatkom, nato pa lahko ekstrahiramo razdalje in indekse vsake točke z kneighbors() metoda:
from sklearn.neighbors import NearestNeighbors
import numpy as np nn = NearestNeighbors(n_neighbors=4) nbrs = nn.fit(scaled_customer_data)
distances, indices = nbrs.kneighbors(scaled_customer_data)
Ko najdemo razdalje, jih lahko razvrstimo od največje do najmanjše. Ker je prvi stolpec niza razdalj točen sam sebi (kar pomeni, da so vse 0), drugi stolpec pa vsebuje najmanjše razdalje, sledi tretji stolpec, ki ima večje razdalje od drugega, in tako naprej, lahko izberemo samo vrednosti drugega stolpca in jih shranite v distances spremenljivka:
distances = np.sort(distances, axis=0)
distances = distances[:,1] Zdaj, ko imamo razvrščene najmanjše razdalje, lahko uvozimo matplotlib, narišite razdalje in narišite rdečo črto tam, kjer je "upogib komolca":
import matplotlib.pyplot as plt plt.figure(figsize=(6,3))
plt.plot(distances)
plt.axhline(y=0.24, color='r', linestyle='--', alpha=0.4) plt.title('Kneighbors distance graph')
plt.xlabel('Data points')
plt.ylabel('Epsilon value')
plt.show();
To je rezultat:
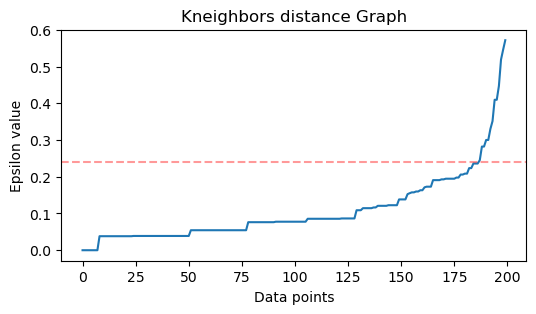
Upoštevajte, da bomo pri risanju črte ugotovili vrednost ε, v tem primeru je 0.24.
Končno imamo minimalne točke in ε. Z obema spremenljivkama lahko ustvarimo in zaženemo model DBSCAN.
Ustvarjanje modela DBSCAN
Če želite ustvariti model, ga lahko uvozimo iz Scikit-Learn, ga ustvarimo z ε, ki je enak kot eps argument in minimalne točke, do katerih je mean_samples prepir. Nato ga lahko shranimo v spremenljivko, pokličimo jo dbs in ga prilagodite pomanjšanim podatkom:
from sklearn.cluster import DBSCAN dbs = DBSCAN(eps=0.24, min_samples=5)
dbs.fit(scaled_customer_data)
Tako je bil naš model DBSCAN ustvarjen in učen na podlagi podatkov! Za pridobivanje rezultatov dostopamo do labels_ premoženje. Ustvarimo lahko tudi novo labels stolpec v scaled_customer_data podatkovni okvir in ga napolnite s predvidenimi oznakami:
labels = dbs.labels_ scaled_customer_data['labels'] = labels
scaled_customer_data.head()
To je končni rezultat:
Annual Income (k$) Spending Score (1-100) labels
0 -1.738999 -0.434801 -1
1 -1.738999 1.195704 0
2 -1.700830 -1.715913 -1
3 -1.700830 1.040418 0
4 -1.662660 -0.395980 -1
Upoštevajte, da imamo oznake z -1 vrednote; to so točke hrupa, tiste, ki ne pripadajo nobeni skupini. Da bi vedeli, koliko šumnih točk je našel algoritem, lahko preštejemo, kolikokrat se vrednost -1 pojavi na našem seznamu oznak:
labels_list = list(scaled_customer_data['labels'])
n_noise = labels_list.count(-1)
print("Number of noise points:", n_noise)
To ustvari:
Number of noise points: 62
Že vemo, da je bilo 62 točk naših prvotnih podatkov 200 točk obravnavanih kot hrup. To je veliko šuma, kar nakazuje, da morda združevanje v gruče DBSCAN ni upoštevalo veliko točk kot del gruče. Kaj se je zgodilo, bomo razumeli kmalu, ko bomo narisali podatke.
Na začetku, ko smo opazovali podatke, se je zdelo, da ima 5 skupin točk. Da bi vedeli, koliko gruč je oblikoval DBSCAN, lahko preštejemo število oznak, ki niso -1. Obstaja veliko načinov za pisanje te kode; tukaj smo napisali zanko for, ki bo delovala tudi za podatke, v katerih je DBSCAN našel veliko gruč:
total_labels = np.unique(labels) n_labels = 0
for n in total_labels: if n != -1: n_labels += 1
print("Number of clusters:", n_labels)
To ustvari:
Number of clusters: 6
Vidimo lahko, da je algoritem predvidel, da bodo imeli podatki 6 skupin z veliko točkami šuma. Predstavimo si to tako, da narišemo s seabornovimi scatterplot:
sns.scatterplot(data=scaled_customer_data, x='Annual Income (k$)', y='Spending Score (1-100)', hue='labels', palette='muted').set_title('DBSCAN found clusters');
Rezultat tega je:

Če pogledamo graf, lahko vidimo, da je DBSCAN zajel točke, ki so bile bolj gosto povezane, točke, ki bi jih lahko šteli za del istega grozda, pa so bile bodisi šum ali pa se je menilo, da tvorijo drug manjši grozd.

Če označimo gruče, opazite, kako DBSCAN v celoti pridobi gručo 1, ki je gruča z manj prostora med točkami. Nato dobi dele grozdov 0 in 3, kjer sta točki tesno skupaj, bolj razmaknjene točke obravnava kot šum. Prav tako upošteva točke v spodnji levi polovici kot šum in točke v spodnjem desnem kotu razdeli na 3 skupine, pri čemer ponovno zajame skupine 4, 2 in 5, kjer so točke bližje skupaj.
Začnemo lahko sklepati, da je bil DBSCAN odličen za zajem gostih območij gruč, ne pa toliko za identifikacijo večje sheme podatkov, razmejitev 5 gruč. Zanimivo bi bilo preizkusiti več algoritmov združevanja v gruče z našimi podatki. Poglejmo, ali bo metrika potrdila to hipotezo.
Ocenjevanje algoritma
Za ovrednotenje DBSCAN bomo uporabili rezultat silhuete ki bo upošteval razdalje med točkami istega grozda in razdalje med grozdi.
Opomba: Trenutno večina meritev združevanja v gruče v resnici ni primerna za uporabo za ovrednotenje DBSCAN, ker ne temeljijo na gostoti. Tu uporabljamo partituro silhuete, ker je že implementirana v Scikit-learn in ker poskuša pogledati obliko gruče.
Če želite imeti bolj prilagojeno oceno, jo lahko uporabite ali kombinirate z Validacija združevanja v gruče na podlagi gostote (DBCV), ki je bila zasnovana posebej za združevanje v gruče na podlagi gostote. Za to je na voljo izvedba za DBCV GitHub.
Prvič, lahko uvozimo silhouette_score iz Scikit-Learn, nato posredujte naše stolpce in oznake:
from sklearn.metrics import silhouette_score s_score = silhouette_score(scaled_customer_data, labels)
print(f"Silhouette coefficient: {s_score:.3f}")
To ustvari:
Silhouette coefficient: 0.506
Glede na to oceno se zdi, da bi DBSCAN lahko zajel približno 50 % podatkov.
zaključek
Prednosti in slabosti DBSCAN
DBSCAN je zelo edinstven algoritem ali model združevanja v gruče.
Če pogledamo njegove prednosti, je zelo dober pri zajemanju gostih območij podatkov in točk, ki so daleč od drugih. To pomeni, da ni treba, da imajo podatki točno določeno obliko in so lahko obdani z drugimi točkami, če so le te tudi gosto povezane.
Od nas zahteva, da določimo minimalne točke in ε, vendar ni potrebe, da vnaprej določimo število grozdov, kot na primer pri K-Means. Uporablja se lahko tudi z zelo velikimi zbirkami podatkov, saj je bil zasnovan za visokodimenzionalne podatke.
Kar zadeva njegove slabosti, smo videli, da ne more zajeti različnih gostot v isti gruči, zato ima težave z velikimi razlikami v gostotah. Odvisno je tudi od metrike razdalje in skaliranja točk. To pomeni, da če podatki niso dobro razumljeni, z razlikami v obsegu in z metriko razdalje, ki nima smisla, jih verjetno ne bo razumel.
Razširitve DBSCAN
Obstajajo še drugi algoritmi, kot npr Hierarhični DBSCAN (HDBSCAN) in Točke naročanja za identifikacijo strukture gručevanja (OPTIKA), ki veljajo za razširitve DBSCAN.
Tako HDBSCAN kot OPTICS lahko običajno delujeta bolje, če so v podatkih grozdi z različnimi gostotami in sta tudi manj občutljiva na izbiro ali začetno min. točke in parametre ε.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://stackabuse.com/dbscan-with-scikit-learn-in-python/

