Quando comecei a aprender Análise de Dados há alguns anos, a primeira coisa que aprendi foi SQL e Pandas. Como analista de dados, é crucial ter uma base sólida para trabalhar com SQL e Pandas. Ambos são ferramentas poderosas que ajudam os analistas de dados a analisar e manipular com eficiência os dados armazenados nos bancos de dados.
Visão geral de SQL e Pandas
SQL (Structured Query Language) é uma linguagem de programação usada para gerenciar e manipular bancos de dados relacionais. Por outro lado, Pandas é uma biblioteca Python usada para manipulação e análise de dados.
A análise de dados envolve trabalhar com grandes quantidades de dados, e os bancos de dados costumam ser usados para armazenar esses dados. SQL e Pandas fornecem ferramentas poderosas para trabalhar com bancos de dados, permitindo que analistas de dados extraiam, manipulem e analisem dados com eficiência. Ao aproveitar essas ferramentas, os analistas de dados podem obter insights valiosos de dados que, de outra forma, seriam difíceis de obter.
Neste artigo, exploraremos como usar SQL e Pandas para ler e gravar em um banco de dados.
Conectando ao banco de dados
Instalando as Bibliotecas
Devemos primeiro instalar as bibliotecas necessárias antes de podermos nos conectar ao banco de dados SQL com Pandas. As duas principais bibliotecas necessárias são Pandas e SQLAlchemy. Pandas é uma biblioteca popular de manipulação de dados que permite o armazenamento de grandes estruturas de dados, conforme mencionado na introdução. Em contraste, o SQLAlchemy fornece uma API para conectar e interagir com o banco de dados SQL.
Podemos instalar ambas as bibliotecas usando o gerenciador de pacotes Python, pip, executando os seguintes comandos no prompt de comando.
$ pip install pandas
$ pip install sqlalchemy
Fazendo a conexão
Com as bibliotecas instaladas, agora podemos usar o Pandas para conectar ao banco de dados SQL.
Para começar, criaremos um objeto de mecanismo SQLAlchemy com create_engine(). O create_engine() A função conecta o código Python ao banco de dados. Ele usa como argumento uma string de conexão que especifica o tipo de banco de dados e os detalhes da conexão. Neste exemplo, usaremos o tipo de banco de dados SQLite e o caminho do arquivo do banco de dados.
Crie um objeto de mecanismo para um banco de dados SQLite usando o exemplo abaixo:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db')
Se o arquivo do banco de dados SQLite, student.db no nosso caso, estiver no mesmo diretório do script Python, podemos usar o nome do arquivo diretamente, conforme mostrado abaixo.
engine = create_engine('sqlite:///student.db')
Lendo arquivos SQL com Pandas
Vamos ler os dados agora que estabelecemos uma conexão. Nesta seção, veremos o read_sql, read_sql_table e read_sql_query funções e como usá-las para trabalhar com um banco de dados.
Executando consultas SQL usando Panda's leitura_sql() função
A read_sql() é uma função da biblioteca do Pandas que nos permite executar uma consulta SQL e recuperar os resultados em um dataframe do Pandas. O read_sql() A função conecta SQL e Python, permitindo-nos aproveitar o poder de ambas as linguagens. A função envolve read_sql_table() e read_sql_query(). O read_sql() função é roteada internamente com base na entrada fornecida, o que significa que se a entrada for para executar uma consulta SQL, ela será roteada para read_sql_query(), e se for uma tabela de banco de dados, será roteada para read_sql_table().
A read_sql() a sintaxe é a seguinte:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
Parâmetros SQL e con são obrigatórios; o resto é opcional. No entanto, podemos manipular o resultado usando esses parâmetros opcionais. Vamos dar uma olhada em cada parâmetro.
sql: consulta SQL ou nome da tabela do banco de dadoscon: Objeto de conexão ou URL de conexãoindex_col: Este parâmetro nos permite usar uma ou mais colunas do resultado da consulta SQL como um índice de quadro de dados. Pode levar uma única coluna ou uma lista de colunas.coerce_float: Este parâmetro especifica se valores não numéricos devem ser convertidos em números flutuantes ou deixados como strings. Ele é definido como verdadeiro por padrão. Se possível, ele converte valores não numéricos em tipos flutuantes.params: os parâmetros fornecem um método seguro para passar valores dinâmicos para a consulta SQL. Podemos usar o parâmetro params para passar um dicionário, tupla ou lista. Dependendo do banco de dados, a sintaxe dos parâmetros varia.parse_dates: Isso nos permite especificar qual coluna no dataframe resultante será interpretada como uma data. Ele aceita uma única coluna, uma lista de colunas ou um dicionário com a chave como o nome da coluna e o valor como o formato da coluna.columns: Isso nos permite buscar apenas as colunas selecionadas da lista.chunksize: ao trabalhar com um grande conjunto de dados, o tamanho do bloco é importante. Ele recupera o resultado da consulta em blocos menores, melhorando o desempenho.
Aqui está um exemplo de como usar read_sql():
Código:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype) engine.dispose()
Saída:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson [email protected] 2000-02-23
2 Peter Griffen [email protected] 2001-04-15
3 Meg Aniston [email protected] 2001-09-20
Date type of dateOfBirth: datetime64[ns]
Após a conexão com o banco de dados, executamos uma consulta que retorna todos os registros do Student tabela e os armazena no DataFrame df. A coluna “Roll Number” é convertida em um índice usando o index_col parâmetro, e o tipo de dados “dateOfBirth” é “datetime64[ns]” devido a parse_dates. Podemos usar read_sql() não apenas para recuperar dados, mas também para executar outras operações, como inserir, excluir e atualizar. read_sql() é uma função genérica.
Carregando tabelas ou visualizações específicas do banco de dados
Carregando uma tabela ou visualização específica com Pandas read_sql_table() é outra técnica para ler dados do banco de dados em um dataframe do Pandas.
O que é a read_sql_table?
A biblioteca Pandas fornece a read_sql_table função, que é projetada especificamente para ler uma tabela SQL inteira sem executar nenhuma consulta e retornar o resultado como um quadro de dados do Pandas.
A sintaxe de read_sql_table() é como abaixo:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
Exceto por table_name e esquema, os parâmetros são explicados da mesma forma que read_sql().
table_name: O parâmetrotable_nameé o nome da tabela SQL no banco de dados.schema: Este parâmetro opcional é o nome do esquema que contém o nome da tabela.
Depois de criar uma conexão com o banco de dados, usaremos o read_sql_table função para carregar o Student tabela em um Pandas DataFrame.
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Student', engine)
print(df.head()) engine.dispose()
Saída:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
1 2 Peter Griffen [email protected] 2001-04-15
2 3 Meg Aniston [email protected] 2001-09-20
Vamos assumir que é uma tabela grande que pode consumir muita memória. Vamos explorar como podemos usar o chunksize parâmetro para resolver esse problema.
Confira nosso guia prático e prático para aprender Git, com práticas recomendadas, padrões aceitos pelo setor e folha de dicas incluída. Pare de pesquisar comandos Git no Google e realmente aprender -lo!
Código:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df_iterator = pd.read_sql_table('Student', engine, chunksize = 1) for df in df_iterator: print(df.head()) engine.dispose()
Saída:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
0 2 Peter Griffen [email protected] 2001-04-15
0 3 Meg Aniston [email protected] 2001-09-20
Por favor, tenha em mente que o chunksize Estou usando aqui é 1 porque só tenho 3 registros na minha tabela.
Consultando o banco de dados diretamente com a sintaxe SQL do Pandas
Extrair insights do banco de dados é uma parte importante para analistas de dados e cientistas. Para isso, vamos aproveitar o read_sql_query() função.
O que é read_sql_query ()?
Usando Pandas' read_sql_query() função, podemos executar consultas SQL e obter os resultados diretamente em um DataFrame. O read_sql_query() função é criada especificamente para SELECT declarações. Não pode ser usado para nenhuma outra operação, como DELETE or UPDATE.
Sintaxe:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
Todas as descrições de parâmetros são iguais às read_sql() função. Aqui está um exemplo de read_sql_query():
Código:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df) engine.dispose()
Saída:
firstName lastName
0 Mark Simson
Escrevendo arquivos SQL com Pandas
Ao analisar os dados, suponha que descobrimos que algumas entradas precisam ser modificadas ou que uma nova tabela ou exibição com os dados é necessária. Para atualizar ou inserir um novo registro, um método é usar read_sql() e escreva uma consulta. No entanto, esse método pode ser demorado. Pandas fornecem um ótimo método chamado to_sql() para situações como esta.
Nesta seção, primeiro criaremos uma nova tabela no banco de dados e depois editaremos uma existente.
Criando uma nova tabela no banco de dados SQL
Antes de criarmos uma nova tabela, vamos primeiro discutir to_sql() em detalhe.
O que é a to_sql()?
A to_sql() função da biblioteca Pandas nos permite escrever ou atualizar o banco de dados. O to_sql() A função pode salvar dados DataFrame em um banco de dados SQL.
Sintaxe para to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
Somente name e con parâmetros são obrigatórios para executar to_sql(); no entanto, outros parâmetros oferecem flexibilidade adicional e opções de personalização. Vamos discutir cada parâmetro em detalhes:
name: O nome da tabela SQL a ser criada ou alterada.con: O objeto de conexão do banco de dados.schema: O esquema da tabela (opcional).if_exists: O valor padrão deste parâmetro é “fail”. Este parâmetro nos permite decidir a ação a ser tomada caso a tabela já exista. As opções incluem "falha", "substituir" e "acrescentar".index: O parâmetro index aceita um valor booleano. Por padrão, é definido como True, o que significa que o índice do DataFrame será gravado na tabela SQL.index_label: Este parâmetro opcional nos permite especificar um rótulo de coluna para as colunas de índice. Por padrão, o índice é gravado na tabela, mas um nome específico pode ser fornecido usando este parâmetro.chunksize: O número de linhas a serem gravadas por vez no banco de dados SQL.dtype: Este parâmetro aceita um dicionário com chaves como nomes de coluna e valores como seus tipos de dados.method: O parâmetro method permite especificar o método usado para inserir dados no SQL. Por padrão, é definido como Nenhum, o que significa que os pandas encontrarão a maneira mais eficiente com base no banco de dados. Existem duas opções principais para os parâmetros do método:multi: Permite inserir várias linhas em uma única consulta SQL. No entanto, nem todos os bancos de dados oferecem suporte à inserção de várias linhas.- função chamável: Aqui, podemos escrever uma função personalizada para inserir e chamá-la usando os parâmetros do método.
Aqui está um exemplo usando to_sql():
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') data = {'Name': ['Paul', 'Tom', 'Jerry'], 'Age': [9, 8, 7]}
df = pd.DataFrame(data) df.to_sql('Customer', con=engine, if_exists='fail') engine.dispose()
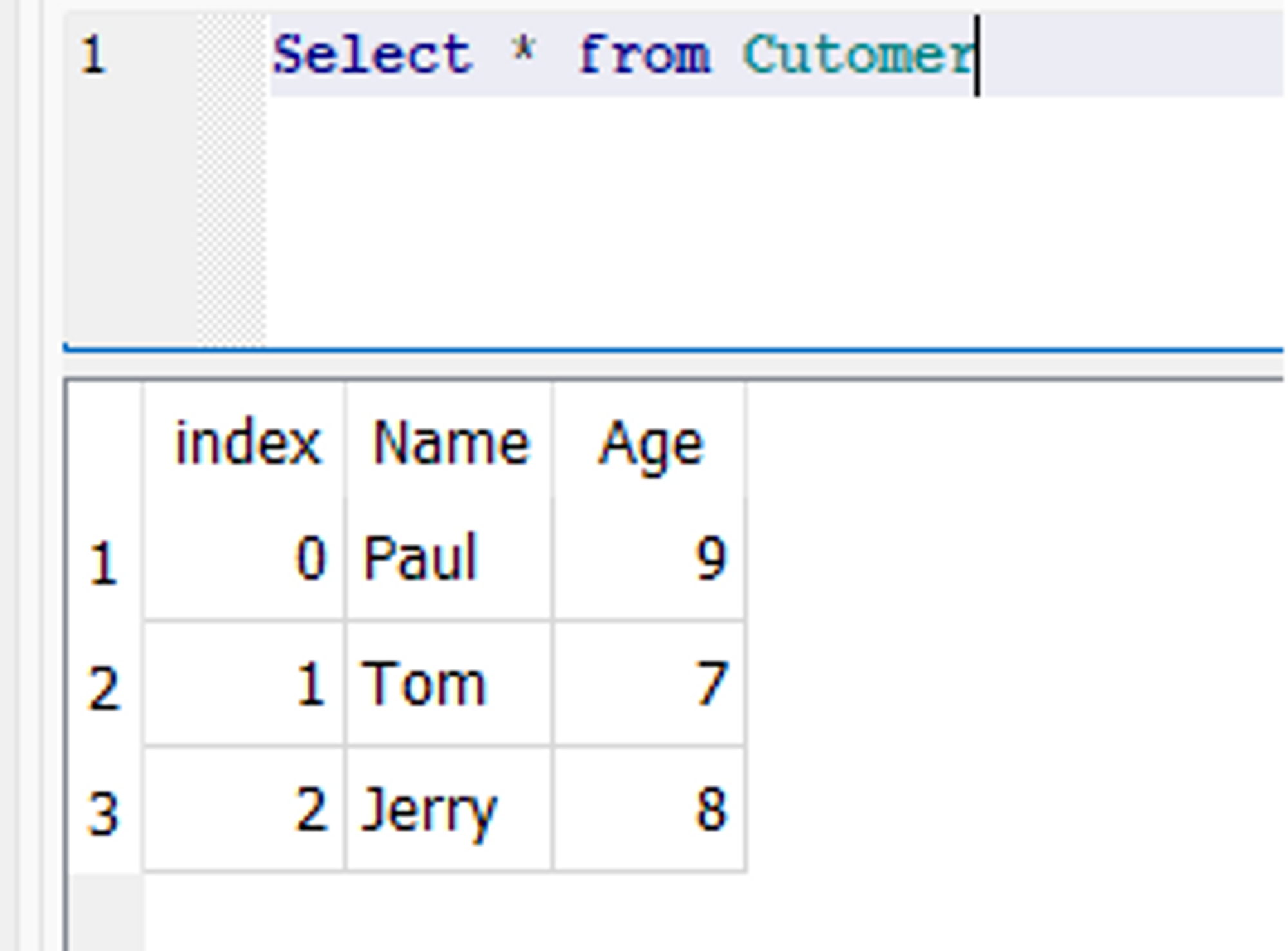
Uma nova tabela chamada Cliente é criada no banco de dados, com dois campos chamados “Nome” e “Idade”.
Instantâneo do banco de dados:
Atualizando Tabelas Existentes com Pandas Dataframes
A atualização de dados em um banco de dados é uma tarefa complexa, principalmente ao lidar com grandes volumes de dados. No entanto, usando o to_sql() função em Pandas pode tornar esta tarefa muito mais fácil. Para atualizar a tabela existente no banco de dados, o to_sql() função pode ser usada com o if_exists parâmetro definido como “substituir”. Isso substituirá a tabela existente pelos novos dados.
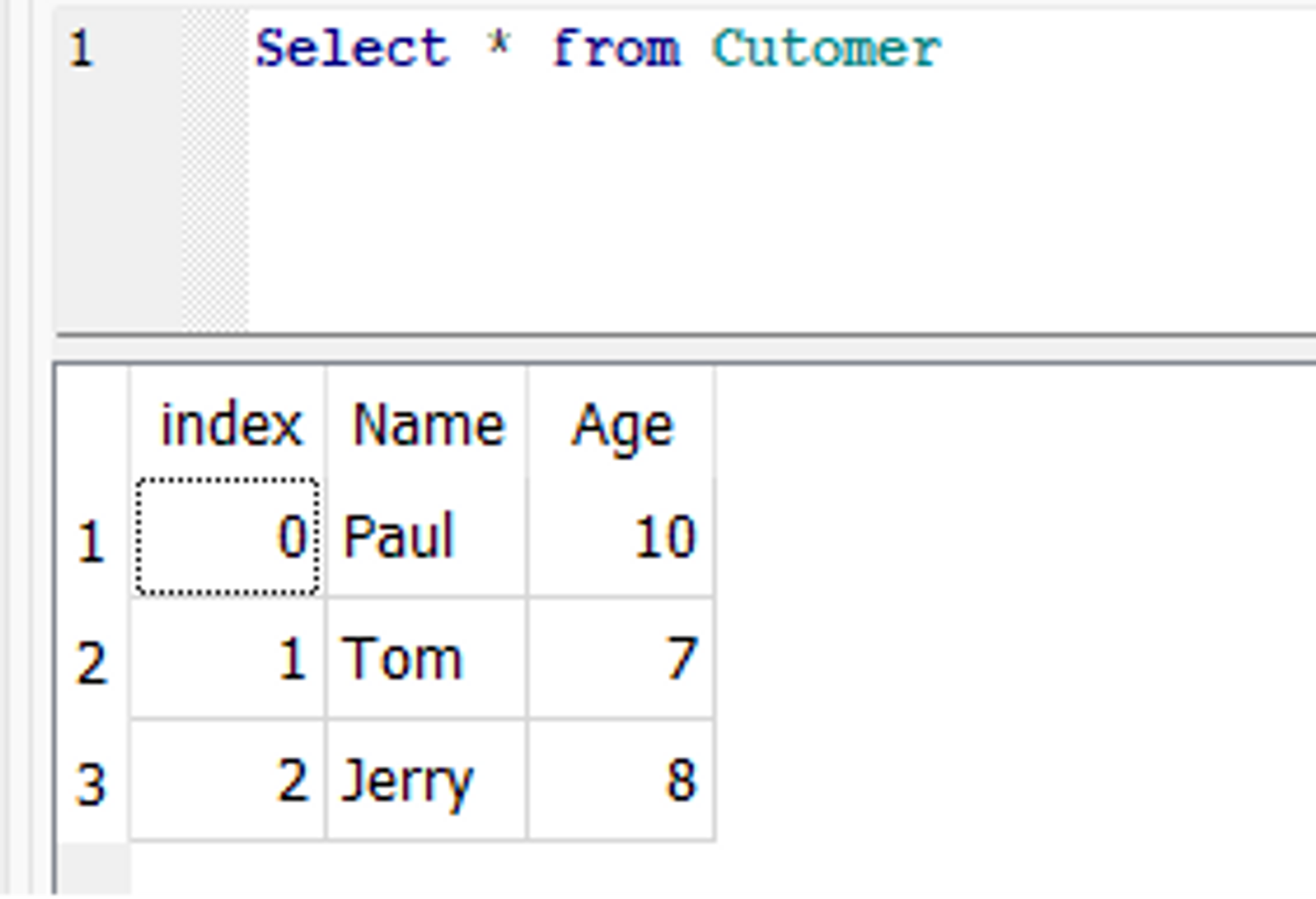
Aqui está um exemplo de to_sql() que atualiza o criado anteriormente Customer mesa. Suponha que, no Customer tabela, queremos atualizar a idade de um cliente chamado Paul de 9 para 10. Para isso, primeiro podemos modificar a linha correspondente no DataFrame e, em seguida, usar o to_sql() função para atualizar o banco de dados.
Código:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Customer', engine) df.loc[df['Name'] == 'Paul', 'Age'] = 10 df.to_sql('Customer', con=engine, if_exists='replace') engine.dispose()
No banco de dados, a idade de Paul é atualizada:
Conclusão
Em conclusão, Pandas e SQL são ferramentas poderosas para tarefas de análise de dados, como leitura e gravação de dados no banco de dados SQL. O Pandas fornece uma maneira fácil de se conectar ao banco de dados SQL, ler dados do banco de dados em um dataframe do Pandas e gravar dados do dataframe de volta no banco de dados.
A biblioteca Pandas facilita a manipulação de dados em um dataframe, enquanto o SQL fornece uma linguagem poderosa para consultar dados em um banco de dados. Usar Pandas e SQL para ler e gravar os dados pode economizar tempo e esforço nas tarefas de análise de dados, especialmente quando os dados são muito grandes. No geral, alavancar SQL e Pandas juntos pode ajudar analistas de dados e cientistas a simplificar seu fluxo de trabalho.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://stackabuse.com/reading-and-writing-sql-files-in-pandas/

