Conversational Artificial Intelligence (AI)-assistenter er konstruert for å gi presise svar i sanntid gjennom intelligent ruting av spørringer til de best egnede AI-funksjonene. Med AWS generative AI-tjenester som Amazonas grunnfjell, kan utviklere lage systemer som ekspertstyrer og svarer på brukerforespørsler. Amazon Bedrock er en fullt administrert tjeneste som tilbyr et utvalg av høyytende fundamentmodeller (FM-er) fra ledende AI-selskaper som AI21 Labs, Anthropic, Cohere, Meta, Stability AI og Amazon ved hjelp av en enkelt API, sammen med et bredt sett av funksjoner du trenger for å bygge generative AI-applikasjoner med sikkerhet, personvern og ansvarlig AI.
Dette innlegget vurderer to primære tilnærminger for å utvikle AI-assistenter: bruk av administrerte tjenester som f.eks Agenter for Amazon Bedrock, og bruke åpen kildekode-teknologi som Langkjede. Vi utforsker fordelene og utfordringene ved hver enkelt, slik at du kan velge den mest passende veien for dine behov.
Hva er en AI-assistent?
En AI-assistent er et intelligent system som forstår naturlige språkspørsmål og samhandler med ulike verktøy, datakilder og APIer for å utføre oppgaver eller hente informasjon på vegne av brukeren. Effektive AI-assistenter har følgende nøkkelegenskaper:
- Naturlig språkbehandling (NLP) og samtaleflyt
- Kunnskapsbaseintegrasjon og semantiske søk for å forstå og hente relevant informasjon basert på nyansene i samtalekontekst
- Kjørende oppgaver, for eksempel databasespørringer og egendefinerte AWS Lambda funksjoner
- Håndtering av spesialiserte samtaler og brukerforespørsler
Vi demonstrerer fordelene med AI-assistenter som bruker Internet of Things (IoT) enhetsadministrasjon som et eksempel. I dette tilfellet kan AI hjelpe teknikere med å administrere maskineri effektivt med kommandoer som henter data eller automatiserer oppgaver, og effektiviserer operasjoner i produksjonen.
Agenter for Amazon Bedrock-tilnærming
Agenter for Amazon Bedrock lar deg bygge generative AI-applikasjoner som kan kjøre flertrinnsoppgaver på tvers av et selskaps systemer og datakilder. Den tilbyr følgende nøkkelfunksjoner:
- Automatisk oppretting av spørsmål fra instruksjoner, API-detaljer og datakildeinformasjon, sparer uker med rask ingeniørarbeid
- Retrieval Augmented Generation (RAG) for å sikkert koble agenter til et selskaps datakilder og gi relevante svar
- Orkestrering og kjøring av flertrinnsoppgaver ved å bryte ned forespørsler i logiske sekvenser og kalle nødvendige APIer
- Synlighet i agentens resonnement gjennom en kjede-of-thought (CoT)-sporing, som tillater feilsøking og styring av modellatferd
- Spør tekniske evner til å endre den automatisk genererte ledetekstmalen for forbedret kontroll over agenter
Du kan bruke Agents for Amazon Bedrock og Kunnskapsbaser for Amazon Bedrock å bygge og distribuere AI-assistenter for komplekse rutingbrukssaker. De gir en strategisk fordel for utviklere og organisasjoner ved å forenkle infrastrukturadministrasjonen, forbedre skalerbarheten, forbedre sikkerheten og redusere udifferensierte tunge løft. De tillater også enklere applikasjonslagskode fordi rutinglogikken, vektoriseringen og minnet er fullstendig administrert.
Løsningsoversikt
Denne løsningen introduserer en samtale-AI-assistent skreddersydd for IoT-enhetsadministrasjon og -operasjoner når du bruker Anthropics Claude v2.1 på Amazon Bedrock. AI-assistentens kjernefunksjonalitet styres av et omfattende sett med instruksjoner, kjent som en systemmelding, som avgrenser dens evner og ekspertiseområder. Denne veiledningen sørger for at AI-assistenten kan håndtere et bredt spekter av oppgaver, fra å administrere enhetsinformasjon til å kjøre operative kommandoer.
Utstyrt med disse egenskapene, som beskrevet i systemmeldingen, følger AI-assistenten en strukturert arbeidsflyt for å svare på brukerspørsmål. Følgende figur gir en visuell representasjon av denne arbeidsflyten, og illustrerer hvert trinn fra den første brukerinteraksjonen til den endelige responsen.

Arbeidsflyten består av følgende trinn:
- Prosessen starter når en bruker ber assistenten om å utføre en oppgave; for eksempel å be om maksimalt antall datapunkter for en spesifikk IoT-enhet
device_xxx. Denne teksten fanges opp og sendes til AI-assistenten. - AI-assistenten tolker brukerens tekstinndata. Den bruker den oppgitte samtalehistorikken, handlingsgruppene og kunnskapsbasene for å forstå konteksten og bestemme de nødvendige oppgavene.
- Etter at brukerens hensikt er analysert og forstått, definerer AI-assistenten oppgaver. Dette er basert på instruksjonene som tolkes av assistenten i henhold til systemmeldingen og brukerens input.
- Oppgavene kjøres deretter gjennom en rekke API-kall. Dette gjøres ved hjelp av Reagere spørring, som deler opp oppgaven i en rekke trinn som behandles sekvensielt:
- For kontroll av enhetsberegninger bruker vi
check-device-metricshandlingsgruppe, som involverer et API-kall til Lambda-funksjoner som deretter spør Amazonas Athena for de forespurte dataene. - For direkte enhetshandlinger som start, stopp eller omstart, bruker vi
action-on-deviceaksjonsgruppe, som påkaller en Lambda-funksjon. Denne funksjonen starter en prosess som sender kommandoer til IoT-enheten. For dette innlegget sender Lambda-funksjonen varsler ved hjelp av Enkel e -posttjeneste fra Amazon (Amazon SES). - Vi bruker kunnskapsbaser for Amazon Bedrock for å hente fra historiske data lagret som innebygging i Amazon OpenSearch-tjeneste vektor database.
- For kontroll av enhetsberegninger bruker vi
- Etter at oppgavene er fullført, genereres det endelige svaret av Amazon Bedrock FM og sendes tilbake til brukeren.
- Agenter for Amazon Bedrock lagrer automatisk informasjon ved hjelp av en stateful økt for å opprettholde den samme samtalen. Tilstanden slettes etter at en konfigurerbar inaktiv timeout har gått.
Teknisk oversikt
Følgende diagram illustrerer arkitekturen for å distribuere en AI-assistent med Agents for Amazon Bedrock.
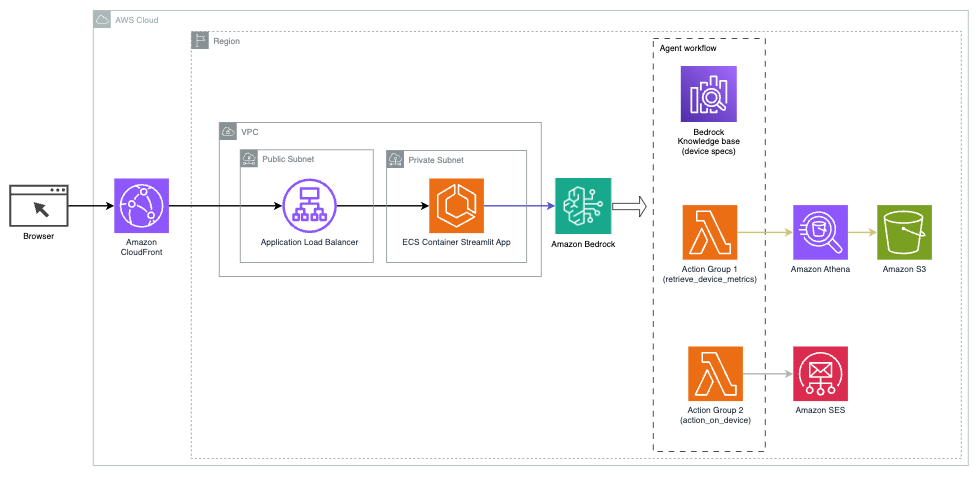
Den består av følgende nøkkelkomponenter:
- Samtalegrensesnitt – Samtalegrensesnittet bruker Streamlit, et åpen kildekode Python-bibliotek som forenkler opprettelsen av tilpassede, visuelt tiltalende nettapper for maskinlæring (ML) og datavitenskap. Det er vert på Amazon Elastic Container Service (Amazon ECS) med AWS Fargate, og den er tilgjengelig ved hjelp av en Application Load Balancer. Du kan bruke Fargate med Amazon ECS for å kjøre containere uten å måtte administrere servere, klynger eller virtuelle maskiner.
- Agenter for Amazon Bedrock – Agenter for Amazon Bedrock fullfører brukerforespørslene gjennom en rekke resonnementtrinn og tilsvarende handlinger basert på React-forespørsel:
- Kunnskapsbaser for Amazon Bedrock – Kunnskapsbaser for Amazon Bedrock gir fullt administrert FILLE for å gi AI-assistenten tilgang til dataene dine. I vårt brukstilfelle lastet vi opp enhetsspesifikasjoner til en Amazon enkel lagringstjeneste (Amazon S3) bøtte. Den fungerer som datakilden til kunnskapsbasen.
- Aksjonsgrupper – Dette er definerte API-skjemaer som påkaller spesifikke Lambda-funksjoner for å samhandle med IoT-enheter og andre AWS-tjenester.
- Antropiske Claude v2.1 på Amazon Bedrock – Denne modellen tolker brukerforespørsler og orkestrerer flyten av oppgaver.
- Amazon Titan-innbygginger – Denne modellen fungerer som en tekstinnbyggingsmodell, som transformerer naturlig språktekst – fra enkeltord til komplekse dokumenter – til numeriske vektorer. Dette muliggjør vektorsøkefunksjoner, som lar systemet semantisk matche brukersøk med de mest relevante kunnskapsbaseoppføringene for effektivt søk.
Løsningen er integrert med AWS-tjenester som Lambda for kjøring av kode som svar på API-kall, Athena for spørring av datasett, OpenSearch Service for søk gjennom kunnskapsbaser og Amazon S3 for lagring. Disse tjenestene jobber sammen for å gi en sømløs opplevelse for drift av IoT-enheter gjennom kommandoer med naturlige språk.
Fordeler
Denne løsningen gir følgende fordeler:
- Implementeringskompleksitet:
- Færre kodelinjer kreves, fordi Agents for Amazon Bedrock abstraherer bort mye av den underliggende kompleksiteten, noe som reduserer utviklingsinnsatsen
- Å administrere vektordatabaser som OpenSearch Service er forenklet, fordi kunnskapsbaser for Amazon Bedrock håndterer vektorisering og lagring
- Integrasjon med ulike AWS-tjenester er mer strømlinjeformet gjennom forhåndsdefinerte handlingsgrupper
- Utviklererfaring:
- Amazon Bedrock-konsollen gir et brukervennlig grensesnitt for rask utvikling, testing og rotårsaksanalyse (RCA), som forbedrer den generelle utvikleropplevelsen
- Smidighet og fleksibilitet:
- Agenter for Amazon Bedrock gir mulighet for sømløse oppgraderinger til nyere FM-er (som Claude 3.0) når de blir tilgjengelige, slik at løsningen din holder seg oppdatert med de siste fremskritt
- Tjenestekvoter og begrensninger administreres av AWS, noe som reduserer kostnadene ved overvåking og skalering av infrastruktur
- Sikkerhet:
- Amazon Bedrock er en fullt administrert tjeneste som følger AWSs strenge sikkerhets- og samsvarsstandarder, noe som potensielt forenkler organisatoriske sikkerhetsvurderinger
Selv om Agents for Amazon Bedrock tilbyr en strømlinjeformet og administrert løsning for å bygge samtale-AI-applikasjoner, kan noen organisasjoner foretrekke en åpen kildekode-tilnærming. I slike tilfeller kan du bruke rammeverk som LangChain, som vi diskuterer i neste avsnitt.
LangChain dynamisk ruting tilnærming
LangChain er et åpen kildekode-rammeverk som forenkler bygging av konversasjons-AI ved å tillate integrering av store språkmodeller (LLM) og dynamiske rutingfunksjoner. Med LangChain Expression Language (LCEL), kan utviklere definere ruting, som lar deg lage ikke-deterministiske kjeder der utdataene fra et tidligere trinn definerer neste trinn. Ruting bidrar til å gi struktur og konsistens i interaksjoner med LLM-er.
For dette innlegget bruker vi samme eksempel som AI-assistenten for IoT-enhetsadministrasjon. Hovedforskjellen er imidlertid at vi må håndtere systemmeldingene separat og behandle hver kjede som en separat enhet. Rutingkjeden bestemmer destinasjonskjeden basert på brukerens input. Beslutningen tas med støtte fra en LLM ved å sende systemmeldingen, chatteloggen og brukerens spørsmål.
Løsningsoversikt
Følgende diagram illustrerer arbeidsflyten for dynamisk rutingsløsning.

Arbeidsflyten består av følgende trinn:
- Brukeren presenterer et spørsmål til AI-assistenten. For eksempel «Hva er de maksimale beregningene for enhet 1009?»
- En LLM evaluerer hvert spørsmål sammen med chattehistorikken fra den samme økten for å bestemme dets natur og hvilket fagområde det faller inn under (som SQL, handling, søk eller SME). LLM klassifiserer inngangen og LCEL-rutingkjeden tar denne inngangen.
- Ruterkjeden velger destinasjonskjeden basert på inndata, og LLM er utstyrt med følgende systemmelding:
LLM evaluerer brukerens spørsmål sammen med chat-historikken for å finne ut hva spørringen er og hvilket fagområde den faller inn under. LLM klassifiserer deretter inngangen og sender ut et JSON-svar i følgende format:
Ruterkjeden bruker dette JSON-svaret til å påkalle den tilsvarende destinasjonskjeden. Det er fire fagspesifikke destinasjonskjeder, hver med sin egen systemforespørsel:
- SQL-relaterte spørringer sendes til SQL-destinasjonskjeden for databaseinteraksjoner. Du kan bruke LCEL til å bygge SQL-kjede.
- Handlingsorienterte spørsmål påkaller den tilpassede Lambda-destinasjonskjeden for løpende operasjoner. Med LCEL kan du definere din egen tilpasset funksjon; i vårt tilfelle er det en funksjon å kjøre en forhåndsdefinert Lambda-funksjon for å sende en e-post med en enhets-ID parset. Eksempel på brukerinndata kan være «Slå av enhet 1009».
- Søkefokuserte henvendelser fortsetter til FILLE destinasjonskjede for informasjonsinnhenting.
- SMB-relaterte spørsmål går til SMB/ekspertdestinasjonskjeden for spesialisert innsikt.
- Hver destinasjonskjede tar innspillene og kjører de nødvendige modellene eller funksjonene:
- SQL-kjeden bruker Athena for å kjøre spørringer.
- RAG-kjeden bruker OpenSearch Service for semantisk søk.
- Den tilpassede Lambda-kjeden kjører Lambda-funksjoner for handlinger.
- SMB/ekspertkjeden gir innsikt ved hjelp av Amazon Bedrock-modellen.
- Svar fra hver destinasjonskjede er formulert til sammenhengende innsikt av LLM. Denne innsikten blir deretter levert til brukeren, og fullfører spørringssyklusen.
- Brukerinndata og svar lagres i Amazon DynamoDB å gi kontekst til LLM for gjeldende økt og fra tidligere interaksjoner. Varigheten av vedvarende informasjon i DynamoDB styres av applikasjonen.
Teknisk oversikt
Følgende diagram illustrerer arkitekturen til LangChain dynamisk ruting-løsning.
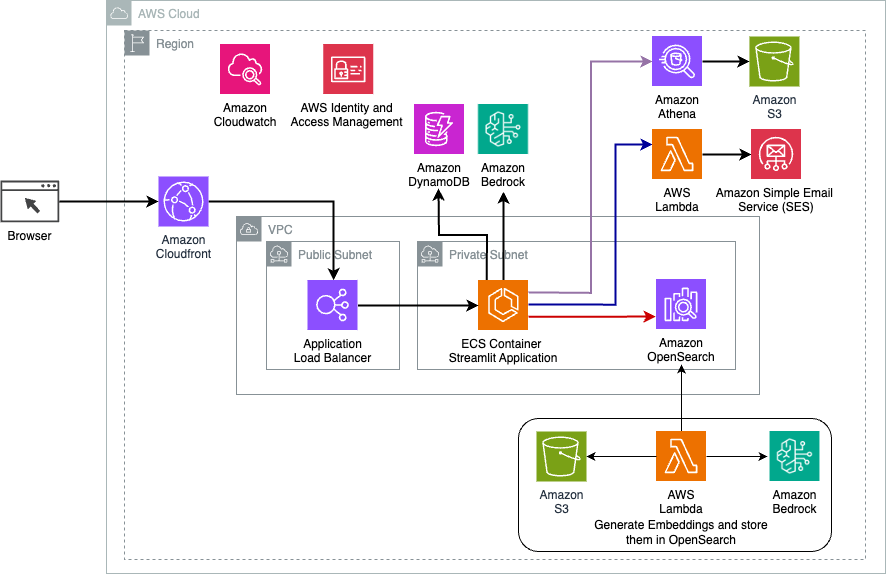
Nettapplikasjonen er bygget på Streamlit hostet på Amazon ECS med Fargate, og den er tilgjengelig ved hjelp av en Application Load Balancer. Vi bruker Anthropics Claude v2.1 på Amazon Bedrock som vår LLM. Nettapplikasjonen samhandler med modellen ved hjelp av LangChain-biblioteker. Den samhandler også med en rekke andre AWS-tjenester, som OpenSearch Service, Athena og DynamoDB for å oppfylle sluttbrukernes behov.
Fordeler
Denne løsningen gir følgende fordeler:
- Implementeringskompleksitet:
- Selv om det krever mer kode og tilpasset utvikling, gir LangChain større fleksibilitet og kontroll over rutinglogikken og integrasjonen med ulike komponenter.
- Å administrere vektordatabaser som OpenSearch Service krever ekstra oppsett og konfigurasjon. Vektoriseringsprosessen er implementert i kode.
- Integrering med AWS-tjenester kan innebære mer tilpasset kode og konfigurasjon.
- Utviklererfaring:
- LangChains Python-baserte tilnærming og omfattende dokumentasjon kan appellere til utviklere som allerede er kjent med Python og åpen kildekode-verktøy.
- Rask utvikling og feilsøking kan kreve mer manuell innsats sammenlignet med å bruke Amazon Bedrock-konsollen.
- Smidighet og fleksibilitet:
- LangChain støtter et bredt spekter av LLM-er, slik at du kan bytte mellom ulike modeller eller leverandører, noe som fremmer fleksibilitet.
- Den åpne kildekoden til LangChain muliggjør fellesskapsdrevne forbedringer og tilpasninger.
- Sikkerhet:
- Som et rammeverk med åpen kildekode kan LangChain kreve strengere sikkerhetsgjennomganger og undersøkelser i organisasjoner, noe som potensielt kan legge til overhead.
konklusjonen
Conversational AI-assistenter er transformative verktøy for å effektivisere driften og forbedre brukeropplevelsen. Dette innlegget utforsket to kraftige tilnærminger ved bruk av AWS-tjenester: de administrerte agentene for Amazon Bedrock og den fleksible, åpen kildekode LangChain dynamisk ruting. Valget mellom disse tilnærmingene avhenger av organisasjonens krav, utviklingspreferanser og ønsket tilpasningsnivå. Uansett hvilken vei du går, gir AWS deg mulighet til å lage intelligente AI-assistenter som revolusjonerer forretnings- og kundeinteraksjoner
Finn løsningskoden og distribusjonselementene i vår GitHub repository, hvor du kan følge de detaljerte trinnene for hver samtale-AI-tilnærming.
Om forfatterne
 Ameer Hakme er en AWS Solutions Architect basert i Pennsylvania. Han samarbeider med uavhengige programvareleverandører (ISV) i Nordøst-regionen, og hjelper dem med å designe og bygge skalerbare og moderne plattformer på AWS Cloud. Ameer er en ekspert på AI/ML og generativ AI, og hjelper kundene med å frigjøre potensialet til disse banebrytende teknologiene. På fritiden liker han å kjøre motorsykkel og tilbringe kvalitetstid med familien.
Ameer Hakme er en AWS Solutions Architect basert i Pennsylvania. Han samarbeider med uavhengige programvareleverandører (ISV) i Nordøst-regionen, og hjelper dem med å designe og bygge skalerbare og moderne plattformer på AWS Cloud. Ameer er en ekspert på AI/ML og generativ AI, og hjelper kundene med å frigjøre potensialet til disse banebrytende teknologiene. På fritiden liker han å kjøre motorsykkel og tilbringe kvalitetstid med familien.
 Sharon Lic er en AI/ML Solutions Architect hos Amazon Web Services basert i Boston, med en lidenskap for å designe og bygge Generative AI-applikasjoner på AWS. Hun samarbeider med kunder for å utnytte AWS AI/ML-tjenester for innovative løsninger.
Sharon Lic er en AI/ML Solutions Architect hos Amazon Web Services basert i Boston, med en lidenskap for å designe og bygge Generative AI-applikasjoner på AWS. Hun samarbeider med kunder for å utnytte AWS AI/ML-tjenester for innovative løsninger.
 Kawsar Kamal er en senior løsningsarkitekt hos Amazon Web Services med over 15 års erfaring innen automatisering av infrastruktur og sikkerhetsområdet. Han hjelper kunder med å designe og bygge skalerbare DevSecOps og AI/ML-løsninger i skyen.
Kawsar Kamal er en senior løsningsarkitekt hos Amazon Web Services med over 15 års erfaring innen automatisering av infrastruktur og sikkerhetsområdet. Han hjelper kunder med å designe og bygge skalerbare DevSecOps og AI/ML-løsninger i skyen.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

