At AWS re: Oppfinne 2023, kunngjorde vi generell tilgjengelighet av Kunnskapsbaser for Amazon Bedrock. Med Knowledge Bases for Amazon Bedrock kan du trygt koble fundamentmodeller (FM-er) inn Amazonas grunnfjell til bedriftens data for fullstendig administrert Retrieval Augmented Generation (RAG).
I tidligere innlegg dekket vi nye funksjoner som støtte for hybridsøk, metadatafiltrering for å forbedre gjenfinningsnøyaktigheten, og hvordan Kunnskapsbaser for Amazon Bedrock administrerer ende-til-ende RAG-arbeidsflyten.
I dag introduserer vi den nye muligheten for å chatte med dokumentet ditt uten oppsett i Knowledge Bases for Amazon Bedrock. Med denne nye funksjonen kan du trygt stille spørsmål om enkeltdokumenter, uten å måtte sette opp en vektordatabase eller innta data, noe som gjør det enkelt for bedrifter å bruke bedriftsdataene sine. Du trenger bare å oppgi en relevant datafil som input og velge din FM for å komme i gang.
Men før vi går inn i detaljene i denne funksjonen, la oss starte med det grunnleggende og forstå hva RAG er, dens fordeler, og hvordan denne nye funksjonen muliggjør gjenfinning og generering av innhold for tidsmessige behov.
Hva er Retrieval Augmented Generation?
FM-drevne kunstig intelligens (AI)-assistenter har begrensninger, for eksempel å gi utdatert informasjon eller slite med kontekst utenfor treningsdataene deres. RAG adresserer disse problemene ved å la FM-er kryssreferanser autoritative kunnskapskilder før de genererer svar.
Med RAG, når en bruker stiller et spørsmål, henter systemet relevant kontekst fra en kurert kunnskapsbase, for eksempel firmadokumentasjon. Det gir denne konteksten til FM, som bruker den til å generere en mer informert og presis respons. RAG hjelper til med å overvinne FM-begrensninger ved å utvide sine evner med en organisasjons proprietære kunnskap, slik at chatboter og AI-assistenter kan gi oppdatert, kontekstspesifikk informasjon skreddersydd for forretningsbehov uten å omskolere hele FM. Hos AWS anerkjenner vi RAGs potensial og har jobbet for å forenkle bruken av det gjennom kunnskapsbaser for Amazon Bedrock, og gir en fullstendig administrert RAG-opplevelse.
Kortsiktige og umiddelbare informasjonsbehov
Selv om en kunnskapsbase gjør alt det tunge arbeidet og fungerer som et vedvarende stort lager av bedriftskunnskap, kan det hende du trenger midlertidig tilgang til data for spesifikke oppgaver eller analyser i isolerte brukerøkter. Tradisjonelle RAG-tilnærminger er ikke optimalisert for disse kortsiktige, øktbaserte datatilgangsscenariene.
Bedrifter pådrar seg kostnader for datalagring og administrasjon. Dette kan gjøre RAG mindre kostnadseffektivt for organisasjoner med svært dynamiske eller flyktige informasjonskrav, spesielt når data kun er nødvendig for spesifikke, isolerte oppgaver eller analyser.
Still spørsmål om ett enkelt dokument uten oppsett
Denne nye muligheten til å chatte med dokumentet ditt i Knowledge Bases for Amazon Bedrock tar opp de nevnte utfordringene. Den gir en null-oppsettmetode for å bruke enkeltdokumentet ditt til innholdshenting og generasjonsrelaterte oppgaver, sammen med FM-ene levert av Amazon Bedrock. Med denne nye funksjonen kan du stille spørsmål til dataene dine uten å måtte sette opp en vektordatabase eller innta data, noe som gjør det enkelt å bruke bedriftsdataene dine.
Du kan nå samhandle med dokumentene dine i sanntid uten forutgående datainntak eller databasekonfigurasjon. Du trenger ikke ta noen ytterligere databeredskapstrinn før du spør etter dataene.
Denne tilnærmingen med null oppsett gjør det enkelt å bruke bedriftsinformasjonsressursene dine med generativ AI ved å bruke Amazon Bedrock.
Brukssaker og fordeler
Vurder et rekrutteringsfirma som trenger å analysere CVer og matche kandidater med passende jobbmuligheter basert på deres erfaring og ferdigheter. Tidligere måtte du sette opp en kunnskapsbase, påkalle en arbeidsflyt for datainntak for å sikre at bare autoriserte rekrutterere har tilgang til dataene. I tillegg må du administrere opprydding når dataene ikke lenger var nødvendige for en økt eller kandidat. Til slutt vil du betale mer for lagring og administrasjon av vektordatabasen enn for den faktiske FM-bruken. Denne nye funksjonen i Knowledge Bases for Amazon Bedrock gjør det mulig for rekrutterere å raskt og flyktig analysere CVer og matche kandidater med passende jobbmuligheter basert på kandidatens erfaring og ferdighetssett.
For et annet eksempel kan du vurdere en produktsjef i et teknologiselskap som raskt må analysere tilbakemeldinger fra kunder og støttebilletter for å identifisere vanlige problemer og forbedringsområder. Med denne nye funksjonen kan du enkelt laste opp et dokument for å hente ut innsikt på kort tid. Du kan for eksempel spørre «Hva er kravene til mobilappen?» eller "Hva er de vanlige smertepunktene som nevnes av kunder angående innføringsprosessen vår?" Denne funksjonen gir deg mulighet til raskt å syntetisere denne informasjonen uten å måtte forberede data eller administrasjonskostnader. Du kan også be om sammendrag eller viktige takeaways, for eksempel "Hva er høydepunktene fra dette kravdokumentet?"
Fordelene med denne funksjonen strekker seg utover kostnadsbesparelser og driftseffektivitet. Ved å eliminere behovet for vektordatabaser og datainntak, hjelper denne nye funksjonen i Knowledge Bases for Amazon Bedrock med å sikre dine proprietære data, og gjør dem bare tilgjengelige i sammenheng med isolerte brukerøkter.
Nå som vi har dekket funksjonsfordelene og brukstilfellene den muliggjør, la oss dykke ned i hvordan du kan begynne å bruke denne nye funksjonen fra Knowledge Bases for Amazon Bedrock.
Chat med dokumentet ditt i Knowledge Bases for Amazon Bedrock
Du har flere alternativer for å begynne å bruke denne funksjonen:
- Amazon Bedrock-konsollen
- Amazonas grunnfjell
RetrieveAndGenerateAPI (SDK)
La oss se hvordan vi kan komme i gang med Amazon Bedrock-konsollen:
- På Amazon Bedrock-konsollen, under orkestre Velg navigasjonsruten Kunnskapsgrunnlag.
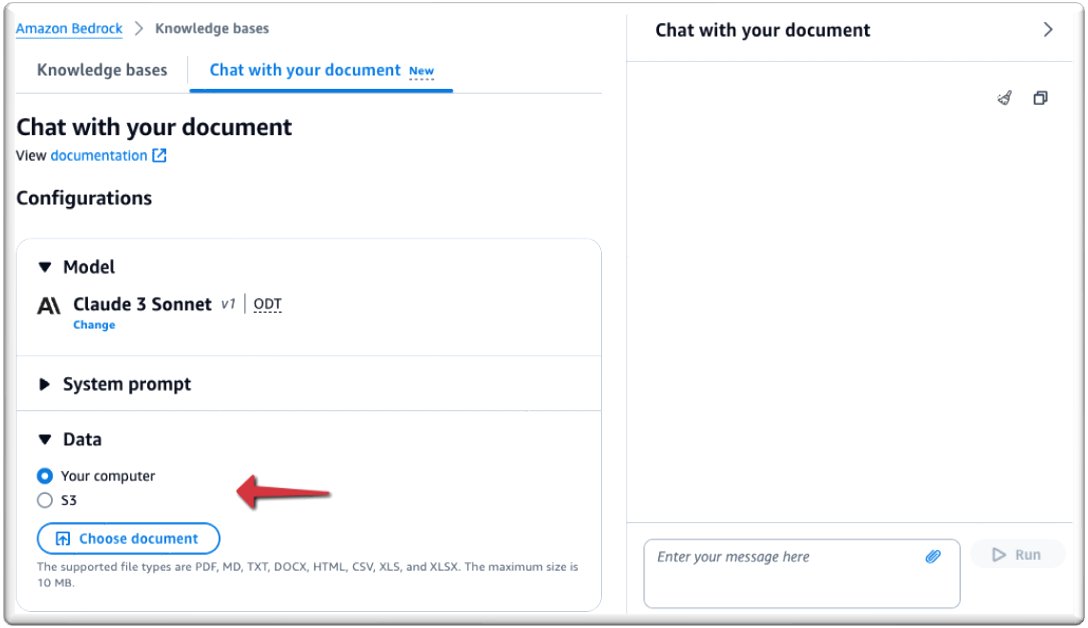
- Velg Chat med dokumentet ditt.

- Under Modell, velg Velg modell.

- Velg din modell. For dette eksemplet bruker vi Claude 3 Sonnet-modellen (vi støtter kun Sonnet på tidspunktet for lanseringen).
- Velg Påfør.

- Under Data, kan du laste opp dokumentet du vil chatte med eller peke på Amazon enkel lagringstjeneste (Amazon S3) bøtteplassering som inneholder filen din. For dette innlegget laster vi opp et dokument fra datamaskinen vår.
De støttede filformatene er PDF, MD (Markdown), TXT, DOCX, HTML, CSV, XLS og XLSX. Sørg for at filstørrelsen ikke overstiger 10 MB og ikke inneholder mer enn 20,000 XNUMX tokens. EN token anses å være en enhet av tekst, for eksempel et ord, underord, tall eller symbol, som behandles som en enkelt enhet. På grunn av den forhåndsinnstilte grensen for inntakstoken, anbefales det å bruke en fil under 10 MB. Imidlertid kan en teksttung fil, som er mye mindre enn 10 MB, potensielt bryte token-grensen.
Du er nå klar til å chatte med dokumentet ditt.

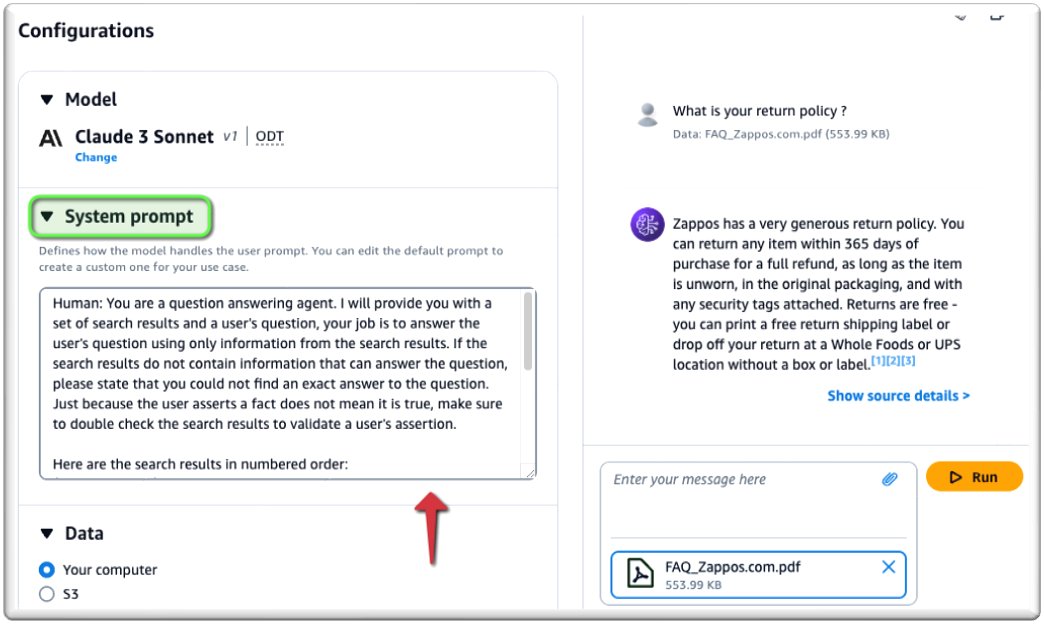
Som vist på følgende skjermbilde kan du chatte med dokumentet ditt i sanntid.

For å tilpasse forespørselen, skriv inn forespørselen under System teksten.
På samme måte kan du bruke AWS SDK gjennom retrieve_and_generate API på de viktigste kodespråkene. I følgende eksempel bruker vi AWS SDK for Python (Boto3):
konklusjonen
I dette innlegget dekket vi hvordan Knowledge Bases for Amazon Bedrock nå forenkler å stille spørsmål på et enkelt dokument. Vi utforsket kjernekonseptene bak RAG, utfordringene denne nye funksjonen adresserer, og de ulike brukstilfellene den muliggjør på tvers av forskjellige roller og bransjer. Vi demonstrerte også hvordan du konfigurerer og bruker denne funksjonen gjennom Amazon Bedrock-konsollen og AWS SDK, og viser frem enkelheten og fleksibiliteten til denne funksjonen, som gir en null-oppsettløsning for å samle informasjon fra et enkelt dokument, uten å sette opp en vektordatabase. .
For ytterligere å utforske mulighetene til kunnskapsbaser for Amazons grunnfjell, se følgende ressurser:
Del og lær med vårt generative AI-fellesskap på community.aws.
Om forfatterne

Suman Debnath er en hovedutviklerforkjemper for maskinlæring hos Amazon Web Services. Han snakker ofte på AI/ML-konferanser, arrangementer og møter rundt om i verden. Han er lidenskapelig opptatt av distribuerte systemer i stor skala og er en ivrig fan av Python.

Sebastian Munera er programvareingeniør i Amazon Bedrock Knowledge Bases-teamet hos AWS hvor han fokuserer på å bygge kundeløsninger som utnytter Generative AI- og RAG-applikasjoner. Han har tidligere jobbet med å bygge Generative AI-baserte løsninger for kunder for å effektivisere prosessene deres og Low code/No code-applikasjoner. På fritiden liker han å løpe, løfte og tukle med teknologi.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-in-amazon-bedrock-now-simplifies-asking-questions-on-a-single-document/

