개요
일부 데이터 구조는 다목적이며 광범위한 응용 프로그램에서 사용할 수 있지만 다른 데이터 구조는 특정 문제를 처리하도록 전문화되고 설계되었습니다. 단순하면서도 뛰어난 유용성으로 알려진 이러한 특수 구조 중 하나는 스택.
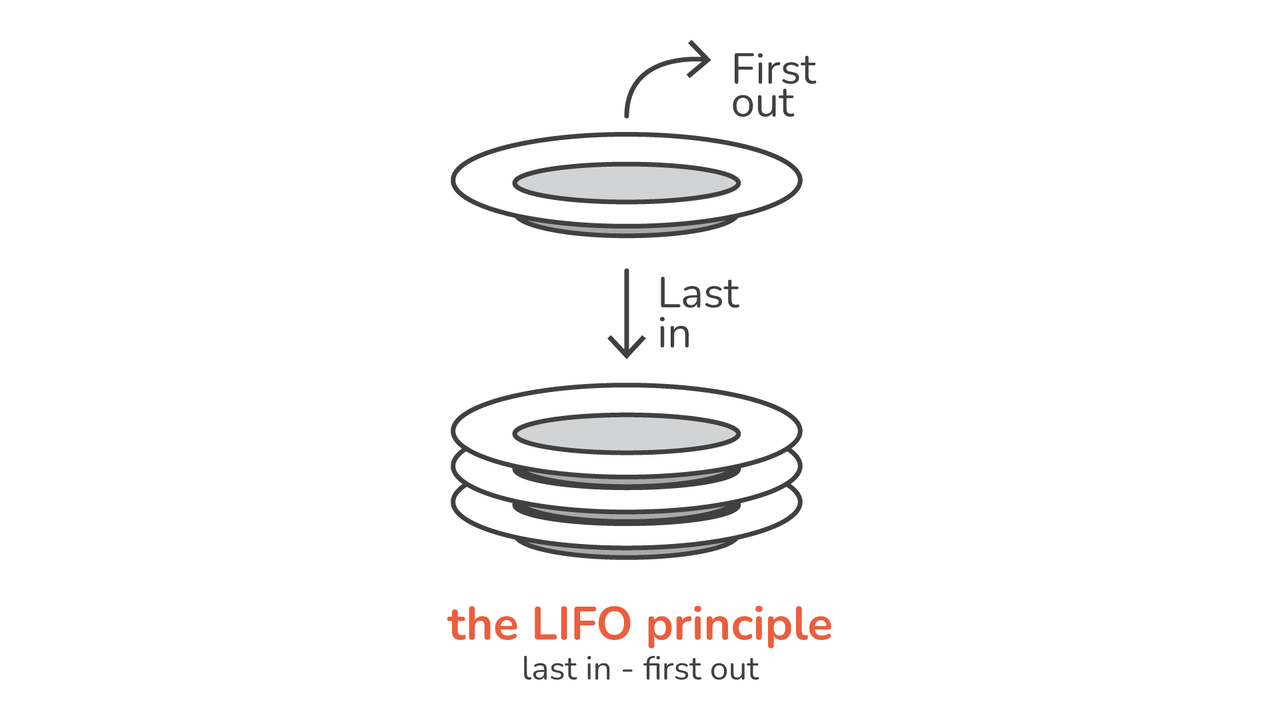
그렇다면 스택이란 무엇입니까? 기본적으로 스택은 다음을 따르는 선형 데이터 구조입니다. LIFO (후입선출) 원칙. 구내식당의 접시 더미라고 생각해보세요. 맨 위에 있는 접시만 가져오고, 새 접시를 놓으면 스택의 맨 위로 이동합니다.
마지막으로 추가된 요소가 제거될 첫 번째 요소입니다.
그런데 스택을 이해하는 것이 왜 중요한가요? 수년에 걸쳐 스택은 즐겨 사용하는 프로그래밍 언어의 메모리 관리부터 웹 브라우저의 뒤로 버튼 기능에 이르기까지 다양한 영역에서 애플리케이션을 찾아냈습니다. 이러한 본질적인 단순성과 광범위한 적용 가능성이 결합되어 스택은 개발자의 무기고에 없어서는 안 될 도구가 됩니다.
이 가이드에서는 스택의 개념, 구현, 사용 사례 등에 대해 자세히 알아봅니다. 스택이 무엇인지, 어떻게 작동하는지 정의한 다음 Python에서 스택 데이터 구조를 구현하는 가장 일반적인 두 가지 방법을 살펴보겠습니다.
스택 데이터 구조의 기본 개념
본질적으로 스택은 믿을 수 없을 정도로 단순하지만 계산 영역에서 다용도로 응용할 수 있는 미묘한 차이를 가지고 있습니다. 구현 및 실제 사용법을 살펴보기 전에 스택을 둘러싼 핵심 개념을 확실하게 이해해 봅시다.
LIFO(후입선출) 원칙
LIFO 스택의 기본 원칙입니다. 이는 스택에 마지막으로 들어간 항목이 가장 먼저 나가는 항목임을 의미합니다. 이러한 특성은 스택을 큐와 같은 다른 선형 데이터 구조와 차별화합니다.
참고 : 스택이 작동하는 방식에 대한 개념을 이해하는 데 도움이 되는 또 다른 유용한 예는 사람들이 스택에 들어오고 나가는 것을 상상하는 것입니다. 엘리베이터 - 엘리베이터에 마지막으로 들어간 사람이 가장 먼저 나가는 사람입니다!
기본 작업
모든 데이터 구조는 지원하는 작업에 의해 정의됩니다. 스택의 경우 이러한 작업은 간단하지만 중요합니다.
- 푸시 – 스택의 맨 위에 요소를 추가합니다. 스택이 가득 찬 경우 이 작업으로 인해 스택 오버플로가 발생할 수 있습니다.

- 팝 – 스택의 최상위 요소를 제거하고 반환합니다. 스택이 비어 있는 경우 팝을 시도하면 스택 언더플로가 발생할 수 있습니다.

- 엿보기(또는 상단) – 최상위 요소를 제거하지 않고 관찰합니다. 이 작업은 스택 상태를 변경하지 않고 현재 최상위 요소를 검사하려는 경우에 유용합니다.
이제 스택 데이터 구조의 중요성과 기본 개념이 분명해졌습니다. 앞으로 나아가면서 구현에 대해 자세히 알아보고 이러한 기본 원칙이 어떻게 실용적인 코드로 변환되는지 조명할 것입니다.
Python에서 처음부터 스택을 구현하는 방법
스택의 기본 원칙을 파악했다면 이제 소매를 걷어붙이고 실용적인 측면을 탐구할 차례입니다. 스택 구현은 간단하지만 다양한 방법으로 접근할 수 있습니다. 이 섹션에서는 배열과 연결 목록을 사용하여 스택을 구현하는 두 가지 기본 방법을 살펴보겠습니다.
배열을 사용하여 스택 구현
배열, 존재 연속된 메모리 위치, 스택을 나타내는 직관적인 수단을 제공합니다. 인덱스별로 요소에 액세스하는 데 O(1) 시간 복잡성을 허용하여 신속한 푸시, 팝 및 픽 작업을 보장합니다. 또한 배열은 연결된 목록처럼 포인터에 대한 오버헤드가 없기 때문에 메모리 효율성이 더 높습니다.
반면에 기존 배열은 크기가 고정되어 있습니다. 즉, 일단 초기화되면 크기를 조정할 수 없습니다. 이로 인해 다음이 발생할 수 있습니다. 스택 오버플로 모니터링되지 않으면. 이는 Python의 배열과 같은 동적 배열로 극복할 수 있습니다. list), 크기를 조정할 수 있지만 이 작업에는 비용이 많이 듭니다.
모든 것을 마치고 Python에서 배열을 사용하여 스택 클래스 구현을 시작하겠습니다. 우선, 스택 크기를 매개변수로 사용하는 생성자를 사용하여 클래스 자체를 생성해 보겠습니다.
class Stack: def __init__(self, size): self.size = size self.stack = [None] * size self.top = -1
보시다시피, 우리는 클래스에 세 개의 값을 저장했습니다. 그만큼 size 는 원하는 스택 크기입니다. stack 스택 데이터 구조를 나타내는 데 사용되는 실제 배열이며, top 는 마지막 요소의 인덱스입니다. stack 배열(스택의 맨 위)
이제부터 기본적인 스택 연산 각각에 대해 하나의 메소드를 생성하여 설명하겠습니다. 이러한 각 방법은 Stack 우리가 방금 만든 클래스입니다.
시작하자. push() 방법. 이전에 설명한 대로 푸시 작업은 스택의 맨 위에 요소를 추가합니다. 먼저 추가하려는 요소를 위한 공간이 스택에 남아 있는지 확인합니다. 스택이 가득 차면 우리는 Stack Overflow 예외. 그렇지 않으면 요소를 추가하고 top 및 stack 따라서:
def push(self, item): if self.top == self.size - 1: raise Exception("Stack Overflow") self.top += 1 self.stack[self.top] = item
이제 스택 상단에서 요소를 제거하는 방법을 정의할 수 있습니다. pop() 방법. 요소를 제거하기 전에 스택에 요소가 있는지 확인해야 합니다. 빈 스택에서 요소를 팝하려고 할 필요가 없기 때문입니다.
def pop(self): if self.top == -1: raise Exception("Stack Underflow") item = self.stack[self.top] self.top -= 1 return item
마지막으로 우리는 peek() 현재 스택의 맨 위에 있는 요소의 값을 반환하는 메서드:
def peek(self): if self.top == -1: raise Exception("Stack is empty") return self.stack[self.top]
그리고 그게 다야! 이제 Python에서 목록을 사용하여 스택의 동작을 구현하는 클래스가 있습니다.
연결 목록을 사용하여 스택 구현
연결리스트, 존재 동적 데이터 구조, 쉽게 확장하고 축소할 수 있어 스택 구현에 도움이 될 수 있습니다. 연결된 목록은 필요에 따라 메모리를 할당하므로 명시적인 크기 조정 없이 스택을 동적으로 늘리거나 줄일 수 있습니다. 연결된 목록을 사용하여 스택을 구현하는 또 다른 이점은 푸시 및 팝 작업에 간단한 포인터 변경만 필요하다는 것입니다. 단점은 연결된 목록의 모든 요소에 추가 포인터가 있어 배열에 비해 더 많은 메모리를 소비한다는 것입니다.
우리가 이미 논의한 것처럼 “파이썬 연결리스트” 기사에서 실제 연결 목록을 구현하기 전에 가장 먼저 구현해야 할 것은 단일 노드에 대한 클래스입니다.
class Node: def __init__(self, data): self.data = data self.next = None
모범 사례, 업계에서 인정하는 표준 및 포함된 치트 시트가 포함된 Git 학습에 대한 실습 가이드를 확인하십시오. 인터넷 검색 Git 명령을 중지하고 실제로 배움 이것!
이 구현은 두 개의 데이터 포인트, 즉 노드에 저장된 값(data) 및 다음 노드에 대한 참조(next).
Python의 연결 목록에 대한 3부 시리즈:
이제 실제 스택 클래스 자체로 이동할 수 있습니다. 생성자는 이전 생성자와 약간 다릅니다. 여기에는 스택 상단에 있는 노드에 대한 참조라는 하나의 변수만 포함됩니다.
class Stack: def __init__(self): self.top = None
예상대로 push() 메서드는 스택 상단에 새 요소(이 경우 노드)를 추가합니다.
def push(self, item): node = Node(item) if self.top: node.next = self.top self.top = node
XNUMXD덴탈의 pop() 메서드는 스택에 요소가 있는지 확인하고 스택이 비어 있지 않으면 맨 위 요소를 제거합니다.
def pop(self): if not self.top: raise Exception("Stack Underflow") item = self.top.data self.top = self.top.next return item
마지막으로, peek() 메소드는 단순히 스택의 맨 위에서 요소의 값을 읽습니다(있는 경우).
def peek(self): if not self.top: raise Exception("Stack is empty") return self.top.data
참고 : 둘 다의 인터페이스 Stack 클래스는 동일합니다. 유일한 차이점은 클래스 메서드의 내부 구현입니다. 즉, 클래스 내부에 대한 걱정 없이 다양한 구현 간에 쉽게 전환할 수 있습니다.
배열과 연결 목록 간의 선택은 애플리케이션의 특정 요구 사항과 제약 조건에 따라 달라집니다.
Python의 내장 구조를 사용하여 스택을 구현하는 방법
많은 개발자에게 처음부터 스택을 구축하는 것은 교육적이지만 실제 애플리케이션에서 스택을 사용하는 가장 효율적인 방법이 아닐 수도 있습니다. 다행히도 널리 사용되는 많은 프로그래밍 언어에는 스택 작업을 자연스럽게 지원하는 내장 데이터 구조와 클래스가 탑재되어 있습니다. 이 섹션에서는 이와 관련하여 Python이 제공하는 기능을 살펴보겠습니다.
다재다능하고 동적인 언어인 Python에는 전용 스택 클래스가 없습니다. 그러나 내장 데이터 구조, 특히 목록과 deque 클래스는 collections 모듈은 손쉽게 스택 역할을 할 수 있습니다.
Python 목록을 스택으로 사용
Python 목록은 동적 특성과 다음과 같은 메서드의 존재로 인해 스택을 매우 효과적으로 에뮬레이트할 수 있습니다. append() 및 pop().
-
푸시 작업 – 스택의 맨 위에 요소를 추가하는 것은 다음을 사용하는 것만큼 간단합니다.
append()방법:stack = [] stack.append('A') stack.append('B') -
팝 오퍼레이션 – 최상위 요소 제거는 다음을 사용하여 수행할 수 있습니다.
pop()인수가 없는 메소드:top_element = stack.pop() -
엿보기 작업 팝핑 없이 상단에 접근하는 것은 음수 인덱싱을 사용하여 수행할 수 있습니다:
top_element = stack[-1]
사용 데크 수업 출처: 컬렉션 모듈
XNUMXD덴탈의 deque (double-ended queue의 약어) 클래스는 스택 구현을 위한 또 다른 다목적 도구입니다. 양쪽 끝에서 빠른 추가 및 팝에 최적화되어 있어 목록보다 스택 작업에 약간 더 효율적입니다.
-
초기화:
from collections import deque stack = deque() -
푸시 작업 – 목록과 유사합니다.
append()방법이 사용됩니다:stack.append('A') stack.append('B') -
팝 오퍼레이션 – 좋아요 목록,
pop()메소드가 작업을 수행합니다.top_element = stack.pop() -
엿보기 작업 – 접근 방식은 목록과 동일합니다.
top_element = stack[-1]
언제 어느 것을 사용해야 할까요?
목록과 데크 모두 스택으로 사용할 수 있지만 주로 구조를 스택(한쪽 끝에서 추가 및 팝 포함)으로 사용하는 경우 deque 최적화로 인해 약간 더 빨라질 수 있습니다. 그러나 대부분의 실용적인 목적과 성능이 중요한 응용 프로그램을 다루지 않는 한 Python의 목록으로 충분합니다.
참고 : 이 섹션에서는 스택과 유사한 동작을 위한 Python의 내장 기능을 자세히 살펴봅니다. 이러한 강력한 도구를 손쉽게 사용할 수 있다고 해서 처음부터 스택을 구현하여 바퀴를 다시 만들 필요는 없습니다.
잠재적인 스택 관련 문제와 이를 극복하는 방법
스택은 다른 데이터 구조와 마찬가지로 매우 다양하고 효율적이지만 잠재적인 위험에 면역되지는 않습니다. 스택으로 작업할 때 이러한 문제를 인식하고 이를 해결하기 위한 전략을 마련하는 것이 중요합니다. 이 섹션에서는 몇 가지 일반적인 스택 관련 문제를 살펴보고 이를 극복하는 방법을 살펴보겠습니다.
스택 오버플로
이는 최대 용량에 도달한 스택에 요소를 푸시하려고 할 때 발생합니다. 특히 특정 저수준 프로그래밍 시나리오나 재귀 함수 호출과 같이 스택 크기가 고정된 환경에서 문제가 됩니다.
배열 기반 스택을 사용하는 경우 크기가 자동으로 조정되는 동적 배열 또는 연결 목록 구현으로 전환하는 것을 고려해 보세요. 스택 오버플로를 방지하는 또 다른 단계는 특히 푸시 작업 전에 스택 크기를 지속적으로 모니터링하고 명확한 오류 메시지나 스택 오버플로에 대한 프롬프트를 제공하는 것입니다.
과도한 재귀 호출로 인해 스택 오버플로가 발생하는 경우 반복 솔루션을 고려하거나 환경이 허용하는 경우 재귀 제한을 늘리십시오.
스택 언더플로우
이는 빈 스택에서 요소를 팝하려고 할 때 발생합니다. 이런 일이 발생하지 않도록 하려면 팝 또는 픽 작업을 실행하기 전에 항상 스택이 비어 있는지 확인하십시오. 명확한 오류 메시지를 반환하거나 프로그램 충돌 없이 언더플로를 정상적으로 처리합니다.
허용되는 환경에서는 작업의 무효성을 나타내기 위해 빈 스택에서 팝할 때 특수 값을 반환하는 것을 고려하세요.
메모리 제약
메모리가 제한된 환경에서는 스택 크기를 동적으로 조정하더라도(예: 연결 목록 기반) 스택이 너무 커지면 메모리가 고갈될 수 있습니다. 따라서 애플리케이션의 전체 메모리 사용량과 스택 증가를 주시하십시오. 아마도 스택 크기에 소프트 캡을 도입할 수도 있습니다.
스레드 안전 문제
멀티스레드 환경에서 서로 다른 스레드가 공유 스택에서 동시에 작업을 수행하면 데이터 불일치 또는 예상치 못한 동작이 발생할 수 있습니다. 이 문제에 대한 잠재적인 해결책은 다음과 같습니다.
- 뮤텍스 및 잠금 – 뮤텍스(상호 배제 개체) 또는 잠금을 사용하여 주어진 시간에 하나의 스레드만 스택에서 작업을 수행할 수 있도록 합니다.
- 원자적 작업 – 환경에서 지원하는 경우 원자성 작업을 활용하여 푸시 및 팝 작업 중 데이터 일관성을 보장합니다.
- 스레드 로컬 스택 – 각 스레드에 스택이 필요한 시나리오에서는 스레드 로컬 스토리지를 사용하여 각 스레드에 별도의 스택 인스턴스를 제공하는 것이 좋습니다.
스택은 실제로 강력하지만 잠재적인 문제를 인식하고 솔루션을 적극적으로 구현하면 강력하고 오류 없는 애플리케이션을 보장할 수 있습니다. 이러한 함정을 인식하는 것이 전투의 절반이고, 나머지 절반은 이를 효과적으로 해결하기 위한 모범 사례를 채택하는 것입니다.
결론
스택은 단순해 보이는 특성에도 불구하고 컴퓨팅 세계의 많은 기본 작업을 뒷받침합니다. 복잡한 수학적 표현을 분석하는 것부터 함수 호출을 관리하는 것까지 그 유용성은 광범위하고 필수적입니다. 우리가 이 데이터 구조의 안팎을 여행하면서 그 강점은 효율성뿐만 아니라 다양성에도 있다는 것이 분명해졌습니다.
그러나 모든 도구와 마찬가지로 그 효과는 사용 방법에 따라 달라집니다. 스택의 진정한 힘을 활용할 수 있도록 원칙, 잠재적인 함정, 모범 사례를 철저히 이해했는지 확인하세요. 처음부터 구현하든, Python과 같은 언어로 내장된 기능을 활용하든, 솔루션을 차별화하는 것은 이러한 데이터 구조를 신중하게 적용하는 것입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://stackabuse.com/guide-to-stacks-in-python/

