データの準備はあらゆる機械学習 (ML) ワークフローにおいて重要なステップですが、多くの場合、退屈で時間のかかる作業が伴います。 Amazon SageMaker キャンバス を活用した包括的なデータ準備機能をサポートするようになりました。 AmazonSageMakerデータラングラー。 この統合により、SageMaker Canvas は、データを準備し、ML および基盤モデルを構築および使用して、データからビジネスの洞察を得るまでの時間を短縮するためのエンドツーエンドのノーコードワークスペースを顧客に提供します。 50 を超えるデータ ソースからデータを簡単に検出して集計し、SageMaker Canvas のビジュアル インターフェイスで 300 を超える組み込みの分析と変換を使用してデータを探索および準備できるようになりました。 また、変換と分析のパフォーマンスが高速化され、ML 用にデータを探索および変換するための自然言語インターフェイスも表示されます。
この投稿では、SageMaker Canvas でエンドツーエンドのモデルを構築するためのデータを準備するプロセスについて説明します。
ソリューションの概要
このユースケースでは、金融サービス会社のデータ専門家の役割を想定しています。 XNUMX つのサンプル データセットを使用して、ローンが借り手によって全額返済されるかどうかを予測する ML モデルを構築します。これは信用リスクを管理するために重要です。 SageMaker Canvas のノーコード環境により、コーディングを必要とせずに、データの準備、機能の設計、ML モデルのトレーニング、エンドツーエンドのワークフローでのモデルのデプロイを迅速に行うことができます。
前提条件
このチュートリアルを進めるには、次の説明に従って前提条件を実装していることを確認してください。
- Amazon SageMaker Canvas を起動する。 すでに SageMaker Canvas ユーザーである場合は、次のことを確認してください。 ログアウト この新機能を使用できるようにするには、再度ログインしてください。
- Snowflake からデータをインポートするには、次の手順に従います。 Snowflake の OAuth をセットアップする.
インタラクティブデータの準備
セットアップが完了したら、対話型のデータ準備を可能にするデータ フローを作成できるようになります。 データ フローは、データをラングリングするための組み込みの変換とリアルタイムの視覚化を提供します。 次の手順を実行します。
- 次のいずれかの方法を使用して、新しいデータ フローを作成します。
- 選択する データラングラー, データフロー、を選択します 創造する.
- SageMaker Canvas データセットを選択し、 データフローを作成する.
- 選択する インポート日 をクリックして 表形式 ドロップダウンリストから選択します。
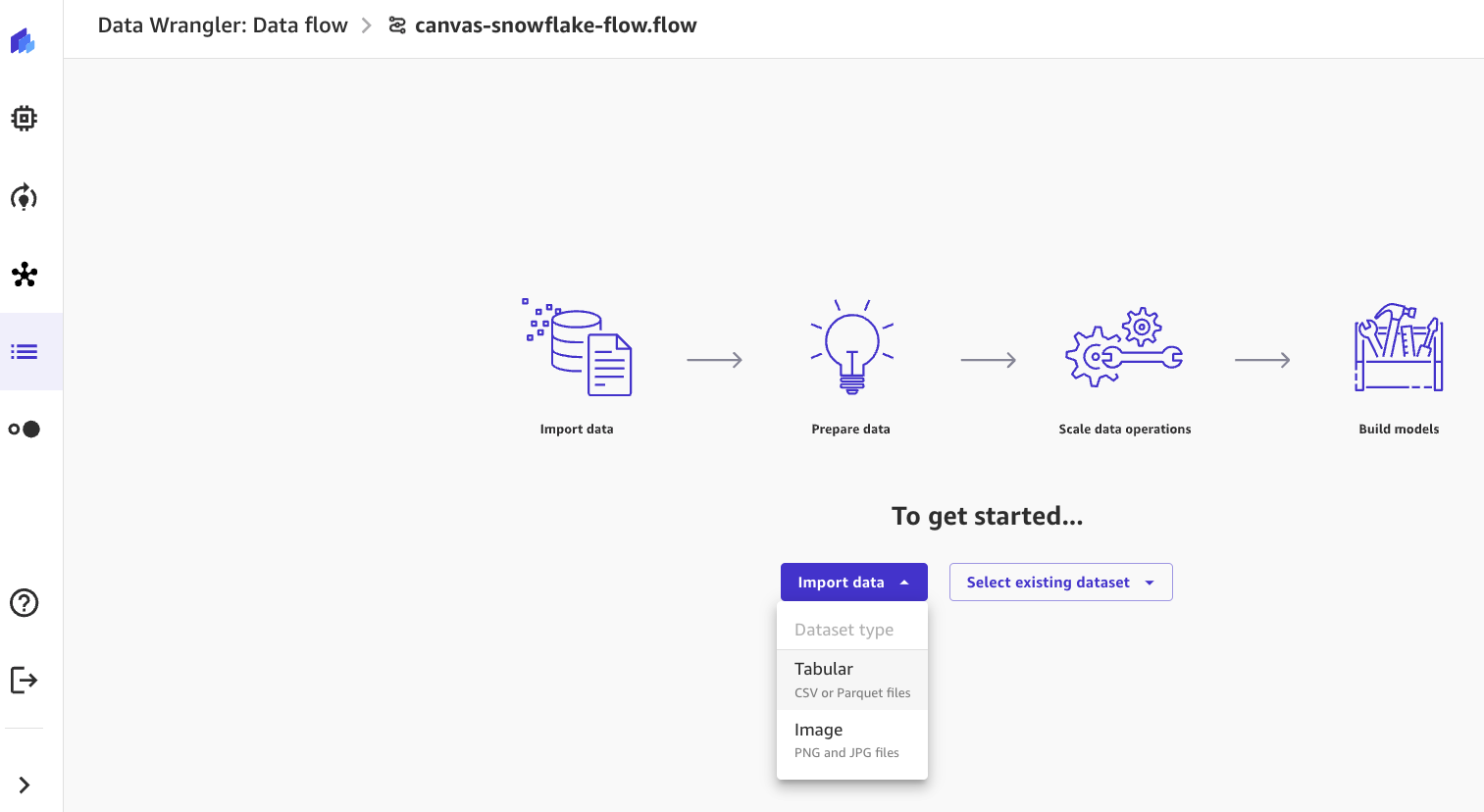
- 次のような 50 以上のデータ コネクタを介してデータを直接インポートできます。 Amazon シンプル ストレージ サービス (Amazon S3)、 アマゾンアテナ, Amazonレッドシフト、スノーフレーク、Salesforce。 このチュートリアルでは、Snowflake からデータを直接インポートする方法について説明します。
あるいは、ローカル マシンから同じデータセットをアップロードすることもできます。 データセットをダウンロードできます ローン-パート-1.csv および ローン-パート-2.csv.
- [データのインポート] ページで、リストから Snowflake を選択し、 接続を追加します。
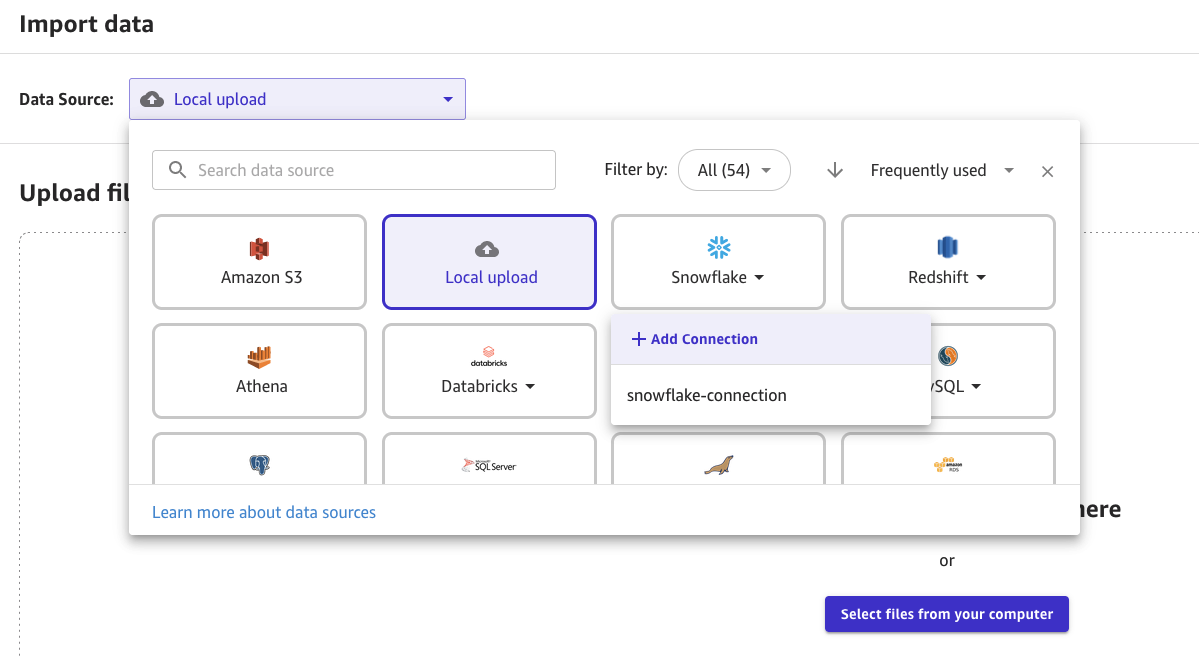
- 接続の名前を入力し、選択します OAuth 認証方法ドロップダウン リストからオプションを選択します。 okta アカウント ID を入力し、[接続の追加] を選択します。

- Okta ログイン画面にリダイレクトされ、認証のための Okta 資格情報を入力します。 認証が成功すると、データ フロー ページにリダイレクトされます。

- Snowflake データベースからローン データセットを参照して見つけます
XNUMX つのローン データセットを画面の左側から右側にドラッグ アンド ドロップして選択します。 XNUMX つのデータセットが接続され、赤い感嘆符の付いた結合記号が表示されます。 それをクリックして、両方のデータセットに対して id 鍵。 結合タイプはそのままにしておきます Inner(インナー)。 次のようになります。
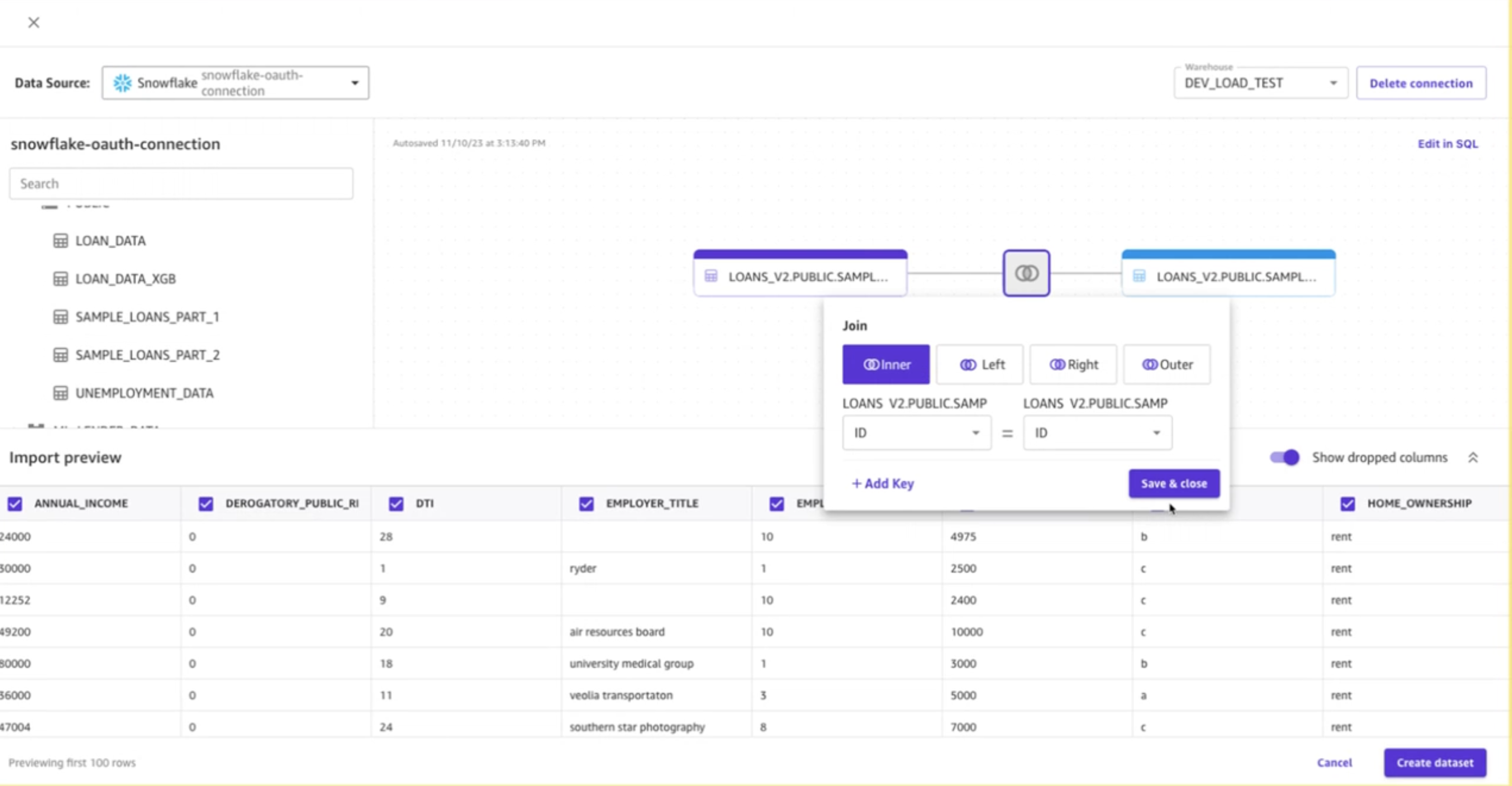
- 選択する 保存して閉じる.
- 選択する データセットを作成する。 データセットに名前を付けます。
- データ フローに移動すると、次のようになります。

- ローン データをすばやく探索するには、次の項目を選択します。 データの洞察を得る 選択
loan_statusターゲット列と Classification 問題のタイプ。
生成された データ品質と洞察レポート 主要な統計、視覚化、および機能の重要性分析を提供します。
- データセットを理解して改善するには、データ品質の問題と不均衡なクラスに関する警告を確認してください。
このユースケースのデータセットについては、「クイック モデル スコアが非常に低い」という優先度の高い警告が表示され、少数クラス (チャージオフおよび現行) ではモデルの有効性が非常に低く、データのクリーンアップとバランスをとる必要があることが示されることが予想されます。 参照する Canvas のドキュメント データ分析レポートの詳細については、こちらをご覧ください。


SageMaker Data Wrangler を活用した 300 を超える組み込み変換を備えた SageMaker Canvas を使用すると、ローン データを迅速にラングリングできます。 をクリックできます ステップを追加をクリックして、適切な変換を参照または検索します。 このデータセットには、次を使用します。 ドロップがありません および 外れ値を処理する データをクリーンアップしてから適用します ワンホットエンコード、 および テキストのベクトル化 ML 用の機能を作成します。
データ準備のためのチャット は、リクエストを平易な英語で記述することで直感的なデータ分析を可能にする新しい自然言語機能です。 たとえば、自然なフレーズを使用してローン データの統計と特徴相関分析を取得できます。 SageMaker Canvas は、会話型の対話を通じてアクションを理解して実行し、データの準備を次のレベルに引き上げます。


我々は使用することができます データ準備のためのチャット ローンデータのバランスをとるための組み込み変換。
- まず、次の指示を入力します。
replace “charged off” and “current” in loan_status with “default”
データ準備のためのチャット XNUMX つの少数クラスを XNUMX つにマージするコードを生成します default とに提供されます。
- 内蔵を選択してください スモート デフォルトクラスの合成データを生成するtransform関数。
これで、バランスの取れたターゲット列が完成しました。

- ローン データをクリーニングおよび処理した後、 データ品質と洞察レポート 改善点を検討します。
優先度の高い警告が消え、データ品質が向上したことがわかります。 必要に応じてさらに変換を追加して、モデル トレーニングのデータ品質を向上させることができます。


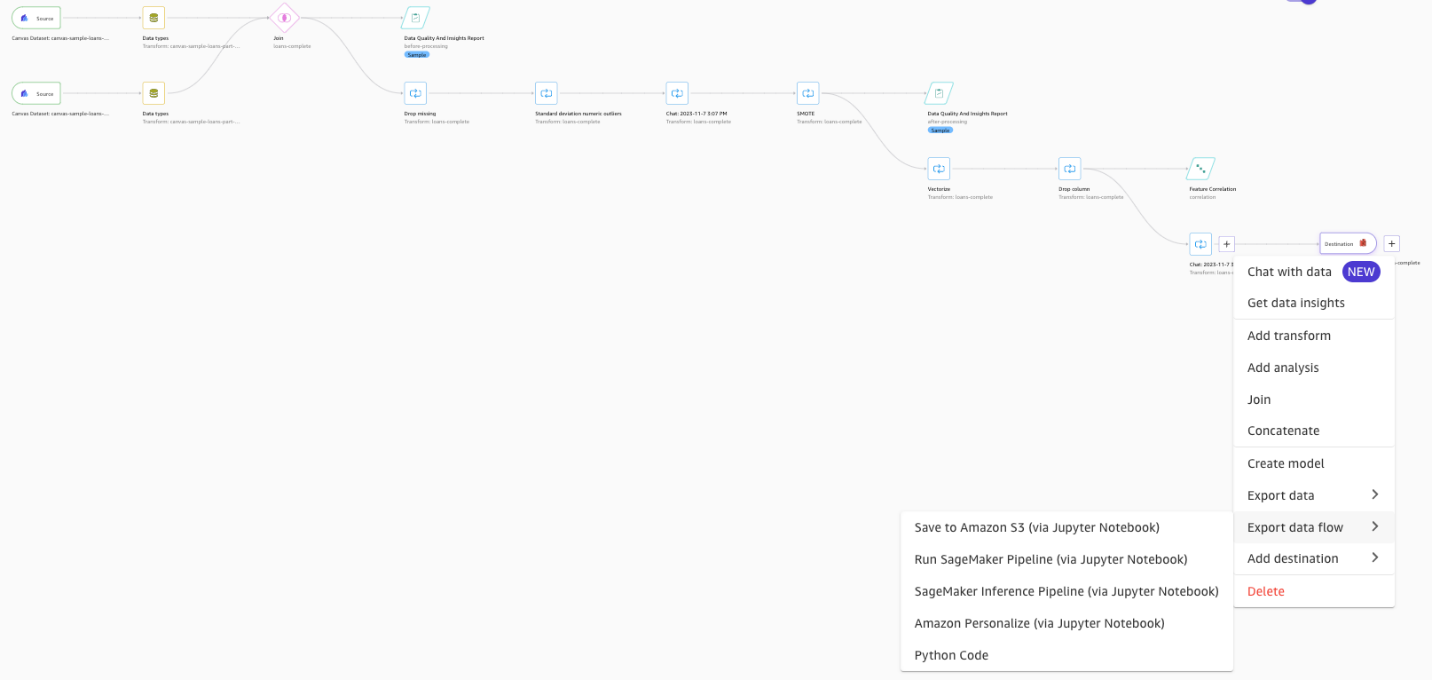
データ処理の拡張と自動化
データの準備を自動化するには、ワークフロー全体を分散 Spark 処理ジョブとして実行またはスケジュールして、データセット全体または新しいデータセットを大規模に処理できます。
- データ フロー内に、Amazon S3 宛先ノードを追加します。
- を選択して、SageMaker Processing ジョブを起動します。 ジョブを作成.
- 処理ジョブを構成して選択します 創造するにより、サンプリングなしでフローを数百 GB のデータで実行できるようになります。
データ フローをエンドツーエンドの MLOps パイプラインに組み込んで、ML ライフサイクルを自動化できます。 データフローは、SageMaker パイプラインのデータ処理ステップとして、または SageMaker 推論パイプラインをデプロイするために、SageMaker Studio ノートブックにフィードできます。 これにより、データの準備から SageMaker のトレーニングおよびホスティングまでのフローを自動化できます。
SageMaker Canvas でモデルを構築してデプロイする
データの準備後、最終データセットを SageMaker Canvas にシームレスにエクスポートして、ローン支払い予測モデルを構築、トレーニング、デプロイできます。
- 選択する モデルを作成する データ フローの最後のノードまたはノード ペイン内。
これにより、データセットがエクスポートされ、ガイド付きモデル作成ワークフローが開始されます。
- エクスポートされたデータセットに名前を付けて選択します 輸出.

- 選択する モデルを作成する 通知より。

- モデルに名前を付けて選択します 予測分析、選択して 創造する.
これにより、モデル構築ページにリダイレクトされます。

- ターゲット列とモデル タイプを選択して、SageMaker Canvas モデルの構築エクスペリエンスを続行し、次に クイックビルド or 標準ビルド.
モデル構築エクスペリエンスの詳細については、以下を参照してください。 モデルを構築する.

トレーニングが完了したら、モデルを使用して新しいデータを予測したり、デプロイしたりできます。 参照する Amazon SageMaker Canvas に構築された ML モデルを Amazon SageMaker リアルタイムエンドポイントにデプロイする SageMaker Canvas からモデルをデプロイする方法について詳しくは、こちらをご覧ください。

まとめ
この投稿では、SageMaker Data Wrangler を利用してローン支払いを予測するデータを準備する金融データ専門家の役割を引き受けることで、SageMaker Canvas のエンドツーエンド機能を実証しました。 インタラクティブなデータ準備により、ローン データを迅速にクリーニング、変換、分析して、有益な機能を設計できるようになりました。 SageMaker Canvas を使用すると、コーディングの複雑さが解消され、迅速に反復して高品質のトレーニング データセットを作成できるようになりました。 この加速されたワークフローは、ビジネスに影響を与えるパフォーマンスの高い ML モデルの構築、トレーニング、デプロイに直接つながります。 SageMaker Canvas は、包括的なデータ準備とデータから洞察までの統合エクスペリエンスを備えており、ML の成果を向上させることができます。 データからビジネスの洞察への移行を加速する方法の詳細については、以下を参照してください。 SageMaker Canvas のイマージョンデー および AWS ユーザーガイド.
著者について
 博士 長沙馬 AWS の AI/ML スペシャリストです。 彼女はコンピューター サイエンスの博士号、教育心理学の修士号を取得した技術者であり、データ サイエンスと AI/ML の独立系コンサルティングで長年の経験があります。 彼女は、機械と人間の知能のための方法論的アプローチの研究に情熱を注いでいます。 仕事以外では、ハイキング、料理、食べ物探し、友人や家族と時間を過ごすことが大好きです。
博士 長沙馬 AWS の AI/ML スペシャリストです。 彼女はコンピューター サイエンスの博士号、教育心理学の修士号を取得した技術者であり、データ サイエンスと AI/ML の独立系コンサルティングで長年の経験があります。 彼女は、機械と人間の知能のための方法論的アプローチの研究に情熱を注いでいます。 仕事以外では、ハイキング、料理、食べ物探し、友人や家族と時間を過ごすことが大好きです。
 アジャイ・ゴビンダラム AWS のシニア ソリューション アーキテクトです。 彼は、AI/ML を使用して複雑なビジネス上の問題を解決している戦略的な顧客と協力しています。 彼の経験は、中規模から大規模の AI / ML アプリケーションの展開に対して、技術的な方向性と設計支援を提供することにあります。 彼の知識は、アプリケーション アーキテクチャからビッグ データ、分析、機械学習にまで及びます。 休息中に音楽を聴いたり、アウトドアを体験したり、愛する人と過ごす時間を楽しんでいます。
アジャイ・ゴビンダラム AWS のシニア ソリューション アーキテクトです。 彼は、AI/ML を使用して複雑なビジネス上の問題を解決している戦略的な顧客と協力しています。 彼の経験は、中規模から大規模の AI / ML アプリケーションの展開に対して、技術的な方向性と設計支援を提供することにあります。 彼の知識は、アプリケーション アーキテクチャからビッグ データ、分析、機械学習にまで及びます。 休息中に音楽を聴いたり、アウトドアを体験したり、愛する人と過ごす時間を楽しんでいます。
 フォングエン AWS のシニア プロダクト マネージャーです。 彼女は、顧客中心でデータ駆動型の製品を構築した 15 年の経験を持ち、SageMaker Canvas および SageMaker Data Wrangler の ML データ準備を主導しています。
フォングエン AWS のシニア プロダクト マネージャーです。 彼女は、顧客中心でデータ駆動型の製品を構築した 15 年の経験を持ち、SageMaker Canvas および SageMaker Data Wrangler の ML データ準備を主導しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/accelerate-data-preparation-for-ml-with-comprehensive-data-preparation-capabilities-and-a-natural-language-interface-in-amazon-sagemaker-canvas/

