資産管理において、ポートフォリオマネージャーは、リスクと機会を特定し、投資決定を導くために、投資ユニバース内の企業を注意深く監視する必要があります。収益レポートや信用格下げなどの直接イベントの追跡は簡単です。会社名を含むニュースを管理者に通知するアラートを設定できます。ただし、サプライヤー、顧客、パートナー、または企業のエコシステム内のその他のエンティティにおけるイベントから生じる二次および三次の影響を検出することは困難です。
たとえば、主要ベンダーでのサプライチェーンの混乱は、下流のメーカーに悪影響を与える可能性があります。あるいは、大手顧客のトップ顧客を失うと、サプライヤーにとって需要リスクが生じます。多くの場合、このような出来事は影響を受けた企業を直接特集する見出しにはなりませんが、依然として注意を払うことが重要です。この投稿では、ナレッジ グラフと 生成人工知能 (AI) リアルタイム ニュースと関係マップを相互参照することで、そのようなリスクを表面化します。
これには大まかに 2 つのステップが必要です。まず、企業 (顧客、サプライヤー、取締役) 間の複雑な関係をナレッジ グラフに構築します。 2 番目に、このグラフ データベースと生成 AI を併用して、ニュース イベントからの二次および三次の影響を検出します。たとえば、このソリューションは、部品サプライヤーの遅延により、ポートフォリオの下流の自動車メーカーの生産が混乱する可能性があることを強調できますが、直接参照されているものはありません。
AWS を使用すると、このソリューションをサーバーレスでスケーラブルな完全なイベント駆動型のアーキテクチャにデプロイできます。この投稿では、グラフ知識表現と自然言語処理に適した 2 つの主要な AWS サービスに基づいて構築された概念実証を示します。 アマゾン海王星 & アマゾンの岩盤。 Neptune は、高速で信頼性の高い、フルマネージドのグラフ データベース サービスで、高度に接続されたデータセットを操作するアプリケーションの構築と実行を簡単にします。 Amazon Bedrock は、単一の API を通じて、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon などの主要 AI 企業の高性能基盤モデル (FM) の選択肢を提供するフルマネージド サービスです。セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築する機能。
全体として、このプロトタイプは、ナレッジ グラフと生成 AI で可能な技術、つまり異種のドットを接続することで信号を導き出す技術を示しています。投資の専門家にとって重要なのは、ノイズを回避しながらシグナルに近い動向を常に把握できることです。
ナレッジグラフを構築する
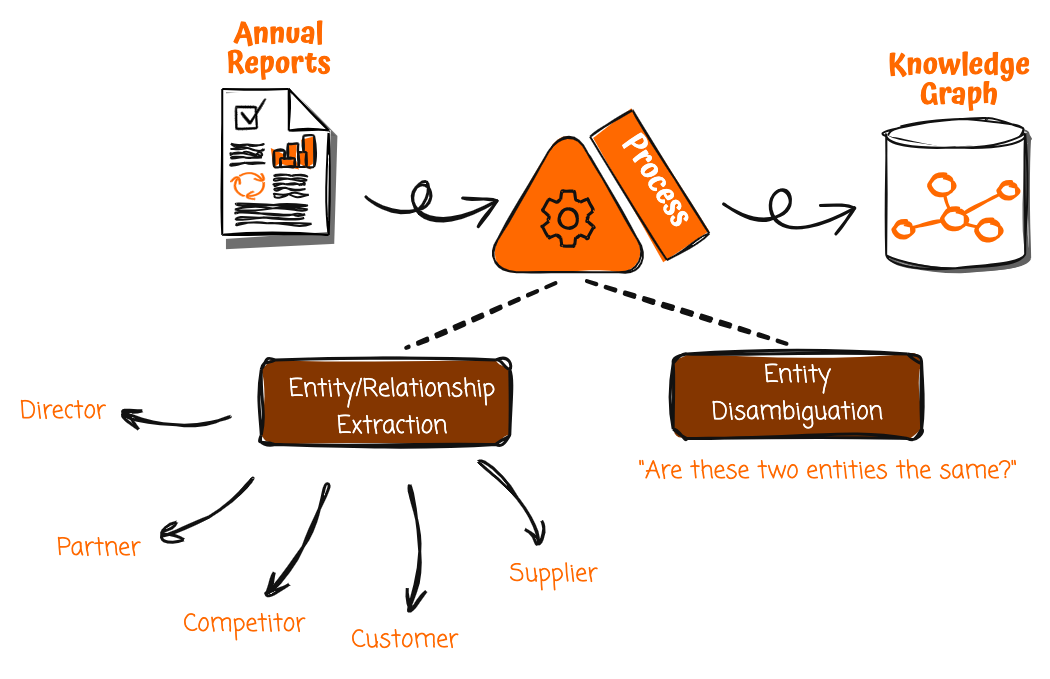
このソリューションの最初のステップはナレッジ グラフを構築することです。ナレッジ グラフの貴重でありながら見落とされがちなデータ ソースは、企業の年次報告書です。企業の公式出版物は発売前に精査されるため、そこに含まれる情報は正確で信頼できるものである可能性が高くなります。ただし、年次報告書は、機械で使用するのではなく、人間が読むことを目的とした非構造化フォーマットで作成されています。その可能性を引き出すには、そこに含まれる豊富な事実と関係を体系的に抽出して構造化する方法が必要です。
Amazon Bedrock のような生成 AI サービスを使用すると、このプロセスを自動化できるようになります。年次レポートを取得し、処理パイプラインをトリガーしてレポートを取り込み、より小さなチャンクに分割し、自然言語理解を適用して顕著なエンティティと関係を引き出すことができます。
たとえば、「[会社 A] は [会社 B] からの 1,800 台の電気バンの注文により、ヨーロッパの電気配達車両を拡大しました」という文によって、Amazon Bedrock は次のことを特定できるようになります。
- [A社] 顧客として
- サプライヤーとしての[B社]
- [A社]と[B社]のサプライヤー関係
- 「電動配送バンの供給業者」の関係詳細
非構造化ドキュメントからこのような構造化データを抽出するには、大規模言語モデル (LLM) に注意深く作成されたプロンプトを提供する必要があります。これにより、テキストを分析して企業や人物などのエンティティ、および顧客、サプライヤーなどの関係を抽出できるようになります。プロンプトには、何に注意すべきか、およびデータを返す構造についての明確な指示が含まれています。年次報告書全体にわたってこのプロセスを繰り返すことで、関連するエンティティと関係を抽出して豊富なナレッジ グラフを構築できます。
ただし、抽出された情報をナレッジ グラフにコミットする前に、まずエンティティの曖昧さを解消する必要があります。たとえば、ナレッジ グラフには別の「[会社 A]」エンティティがすでに存在している可能性がありますが、それは同じ名前の別の組織を表している可能性があります。 Amazon Bedrock は、ビジネスの重点領域、業界、収益を生み出す業界、および他のエンティティとの関係などの属性を推論して比較し、2 つのエンティティが実際に異なるかどうかを判断できます。これにより、関連のない企業が不正確に 1 つの事業体に統合されることが防止されます。
曖昧さの解消が完了すると、新しいエンティティと関係を Neptune ナレッジ グラフに確実に追加し、年次報告書から抽出した事実でグラフを充実させることができます。時間の経過とともに、信頼性の高いデータの取り込みとより信頼性の高いデータ ソースの統合は、グラフ クエリと分析を通じて洞察を明らかにすることをサポートできる包括的なナレッジ グラフの構築に役立ちます。
生成 AI によって実現されたこの自動化により、何千もの年次報告書の処理が可能になり、法外に多くの手作業が必要となるために利用されなかったナレッジ グラフのキュレーションのための貴重な資産が解放されます。
次のスクリーンショットは、Neptune グラフ データベースで可能な視覚的な探索の例を示しています。 グラフエクスプローラー ツール。

ニュース記事の処理

このソリューションの次のステップは、ポートフォリオ マネージャーのニュース フィードを自動的に充実させ、彼らの興味や投資に関連する記事を強調表示することです。ニュース フィードについては、ポートフォリオ マネージャーは、次の方法でサードパーティのニュース プロバイダーを購読できます。 AWSデータ交換 または選択した別のニュース API。
ニュース記事がシステムに入力されると、取り込みパイプラインが呼び出されてコンテンツが処理されます。年次報告書の処理と同様の手法を使用して、Amazon Bedrock を使用してニュース記事からエンティティ、属性、および関係を抽出します。その後、これらの情報をナレッジ グラフに対して曖昧さをなくし、ナレッジ グラフ内の対応するエンティティを識別するために使用されます。
ナレッジ グラフには企業と人々の間のつながりが含まれており、記事エンティティを既存のノードにリンクすることで、ポートフォリオ マネージャーが投資している企業または関心のある企業の 2 ホップ以内に主題があるかどうかを識別できます。そのようなつながりが見つかると、記事はポートフォリオ マネージャーに関連する可能性があり、基礎となるデータがナレッジ グラフで表現されるため、このコンテキストがなぜ、どのように関連するかをポートフォリオ マネージャーが理解するのに役立つように視覚化できます。ポートフォリオへの接続を特定するだけでなく、Amazon Bedrock を使用して、参照されているエンティティのセンチメント分析を実行することもできます。
最終的な出力は、ポートフォリオ マネージャーの関心分野や投資に影響を与える可能性のある記事を表示する充実したニュース フィードです。
ソリューションの概要
ソリューションの全体的なアーキテクチャは次の図のようになります。
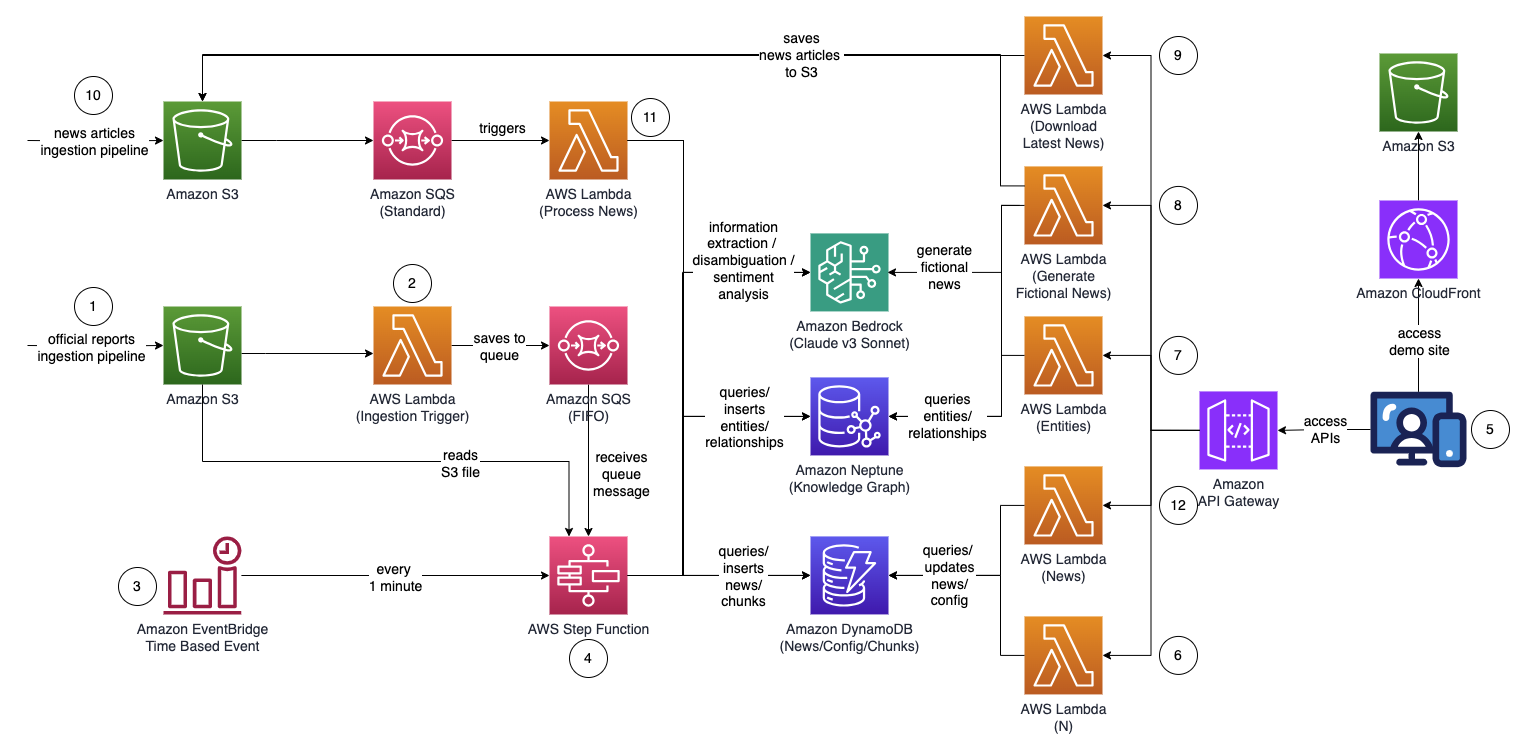
ワークフローは次の手順で構成されます。
- ユーザーは公式レポート (PDF 形式) を Amazon シンプル ストレージ サービス (Amazon S3) バケット。 (ニュースやタブロイド紙ではなく) ナレッジ グラフに不正確なデータが含まれることを最小限に抑えるために、レポートは公式に公開されたレポートである必要があります。
- S3 イベント通知は、 AWSラムダ S3 バケットとファイル名を Amazon シンプル キュー サービス (Amazon SQS) キュー。先入れ先出し (FIFO) キューにより、レポート取り込みプロセスが確実に順番に実行され、ナレッジ グラフに重複データが取り込まれる可能性が低くなります。
- An アマゾンイベントブリッジ 時間ベースのイベントは毎分実行され、 AWSステップ関数 ステートマシンを非同期的に実行します。
- Step Functions ステート マシンは一連のタスクを実行して、重要な情報を抽出してナレッジ グラフに挿入することで、アップロードされたドキュメントを処理します。
- Amazon SQS からキュー メッセージを受信します。
- Amazon S3 から PDF レポート ファイルをダウンロードし、処理のために複数の小さなテキスト チャンク (約 1,000 ワード) に分割し、テキスト チャンクを次の場所に保存します。 Amazon DynamoDB.
- Amazon Bedrock で Anthropic の Claude v3 Sonnet を使用して最初のいくつかのテキストチャンクを処理し、レポートが参照している主要なエンティティと関連する属性 (業界など) を特定します。
- DynamoDB からテキストチャンクを取得し、テキストチャンクごとに Lambda 関数を呼び出して、Amazon Bedrock を使用してエンティティ (会社や個人など) とその主要エンティティとの関係 (顧客、サプライヤー、パートナー、競合他社、ディレクター) を抽出します。 。
- 抽出されたすべての情報を統合します。
- Amazon Bedrock を使用して、ノイズや無関係なエンティティ (たとえば、「消費者」などの一般的な用語) を除外します。
- Amazon Bedrock を使用して、ナレッジグラフからの類似エンティティのリストに対して抽出された情報を使用して推論することにより、曖昧さを解消します。エンティティが存在しない場合は、エンティティを挿入します。それ以外の場合は、ナレッジ グラフにすでに存在するエンティティを使用します。抽出されたすべての関係を挿入します。
- SQS キュー メッセージと S3 ファイルを削除してクリーンアップします。
- ユーザーは React ベースの Web アプリケーションにアクセスして、エンティティ、感情、接続パスの情報が補足されたニュース記事を表示します。
- Web アプリケーションを使用して、ユーザーは監視する接続パス上のホップ数 (デフォルトは N=2) を指定します。
- Web アプリケーションを使用して、ユーザーは追跡するエンティティのリストを指定します。
- 架空のニュースを生成するには、ユーザーは次のことを選択します サンプルニュースの生成 ニュース取り込みプロセスにフィードされるランダムなコンテンツを含む 10 個のサンプル金融ニュース記事を生成します。コンテンツは Amazon Bedrock を使用して生成されており、純粋にフィクションです。
- 実際のニュースをダウンロードするには、ユーザーが選択します 最新ニュースをダウンロード 今日起こったトップニュースをダウンロードします (NewsAPI.org を利用)。
- ニュースファイル(TXT形式)がS3バケットにアップロードされます。ステップ 8 と 9 では、ニュースを S3 バケットに自動的にアップロードしますが、AWS Data Exchange やサードパーティのニュースプロバイダーなどの好みのニュースプロバイダーとの統合を構築して、ニュース記事をファイルとして S3 バケットにドロップすることもできます。ニュース データ ファイルの内容は次のようにフォーマットする必要があります。
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - S3 イベント通知は、S3 バケットまたはファイル名を Amazon SQS (標準) に送信し、複数の Lambda 関数を呼び出してニュースデータを並列処理します。
- Amazon Bedrock を使用して、ニュースで言及されたエンティティを、言及されたエンティティの関連情報、関係、感情とともに抽出します。
- ナレッジグラフと照合し、Amazon Bedrock を使用して、ニュースおよびナレッジグラフ内から入手可能な情報を使用して推論することで曖昧さを排除し、対応するエンティティを特定します。
- エンティティが見つかったら、 でマークされたエンティティに接続する接続パスを検索して返します。
INTERESTED=YESN=2 ホップ以内にあるナレッジ グラフ内。
- Web アプリケーションは 1 秒ごとに自動更新され、最新の処理済みニュースのセットが取得されて Web アプリケーションに表示されます。
プロトタイプをデプロイする
プロトタイプ ソリューションをデプロイして、自分で実験を開始できます。プロトタイプは以下から入手できます GitHubの 次の詳細が含まれます。
- 展開の前提条件
- 展開手順
- クリーンアップ手順
まとめ
この投稿では、ポートフォリオ マネージャーが追跡対象の企業に直接言及することなく、ニュース イベントから二次および三次のリスクを検出できるようにする概念実証ソリューションを実証しました。複雑な企業関係のナレッジ グラフと生成 AI を使用したリアルタイム ニュース分析を組み合わせることで、サプライヤーの障害による生産の遅延など、下流への影響を浮き彫りにすることができます。
これは単なるプロトタイプではありますが、このソリューションは、点を結び、ノイズから信号を導き出すナレッジ グラフと言語モデルの可能性を示しています。これらのテクノロジーは、関係マッピングと推論を通じてリスクをより迅速に明らかにすることで、投資専門家を支援します。全体として、これはグラフ データベースと AI の有望なアプリケーションであり、投資分析と意思決定を強化するための探求が正当化されます。
金融サービスにおける生成 AI のこの例が貴社のビジネスに興味がある場合、または同様のアイデアをお持ちの場合は、AWS アカウントマネージャーにご連絡ください。喜んでご一緒にさらに詳しく調査させていただきます。
著者について
 サンファン AWS のシニア ソリューション アーキテクトで、シンガポールに拠点を置いています。彼は大手金融機関と協力して、クラウド上で安全かつスケーラブルで可用性の高いソリューションを設計および構築しています。仕事以外では、ザンは自由時間のほとんどを家族と過ごし、3 歳の娘に振り回されています。 Xan は次の場所で見つけることができます LinkedIn.
サンファン AWS のシニア ソリューション アーキテクトで、シンガポールに拠点を置いています。彼は大手金融機関と協力して、クラウド上で安全かつスケーラブルで可用性の高いソリューションを設計および構築しています。仕事以外では、ザンは自由時間のほとんどを家族と過ごし、3 歳の娘に振り回されています。 Xan は次の場所で見つけることができます LinkedIn.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

