Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra helps you easily aggregate content from a variety of content repositories into a centralized index that lets you quickly search all your enterprise data and find the most accurate answer. Drupal is a content management software. It’s used to make many of the websites and applications we use every day. Drupal has a great feature set, like straightforward content authoring, reliable performance, and security. Many organizations use Drupal to store their content. One of the key requirements for many customers using Drupal is the ability to easily and securely find accurate information across all the documents in the data source.
With the Amazon Kendra Drupal connector, you can index Drupal content, filter the types of custom content you want to index, and easily search through Drupal content using Amazon Kendra intelligent search.
This post shows you how to use the Amazon Kendra Drupal connector to configure the connector as a data source for your Amazon Kendra index and search your Drupal documents. Based on the configuration of the Drupal connector, you can synchronize the connector to crawl and index different types of Drupal content such as blogs and wikis. The connector also ingests the access control list (ACL) information for each file. The ACL information is used for user context filtering, where search results for a query are filtered by what a user has authorized access to.
Prerequisites
To try out the Amazon Kendra connector for Drupal using this post as a reference, you need the following:

Configure the data source using the Amazon Kendra connector for Drupal
To add a data source to your Amazon Kendra index using the Drupal connector, you can use an existing index or create a new index. Then complete the following steps. For more information on this topic, refer to the Amazon Kendra Developer Guide.
- On the Amazon Kendra console, open your index and choose Data sources in the navigation pane.
- Choose Add data source.
- Under Drupal, choose Add connector.

- In the Specify data source details section, enter a name and description and choose Next.
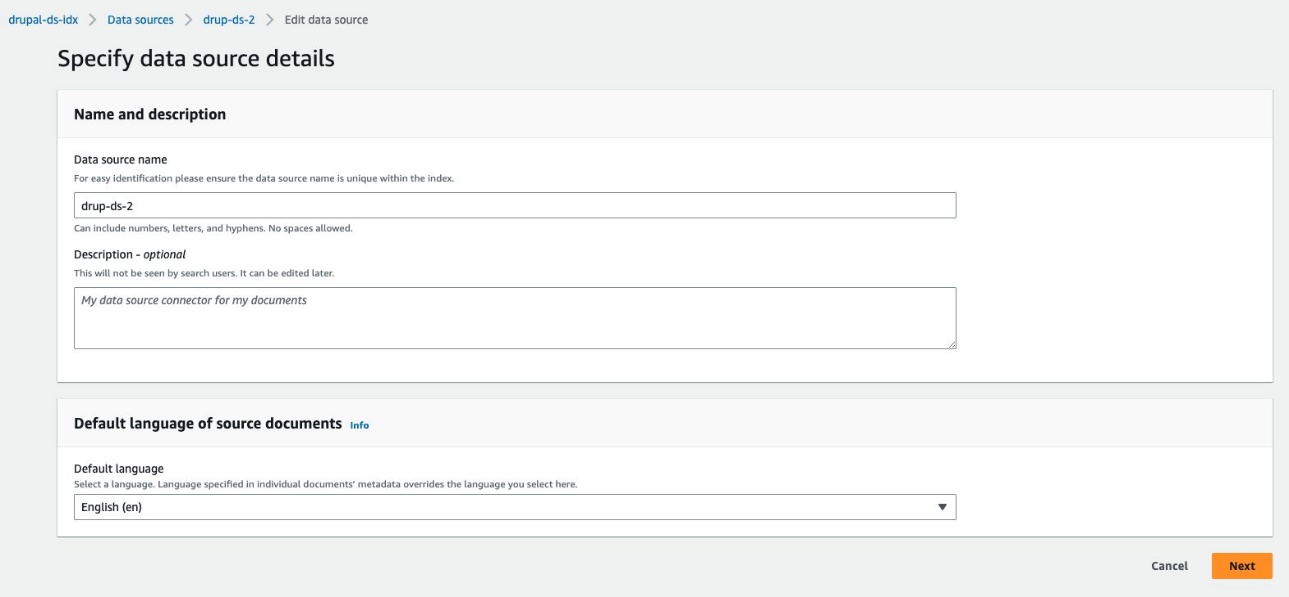
- On the Define access and security section, for Drupal Host URL, enter the Drupal site URL.
- To configure the SSL certificates, you can create a self-signed certificate for this setup using the
openssl x509 -in mydrupalsite.pem -out drupal.crtcommand and store the certificate in an Amazon Simple Storage Service (Amazon S3) bucket. For more details on generating a private key and the certificate, refer to Generating Certificates. - Choose Browse S3 and choose the S3 bucket with the SSL certificate.
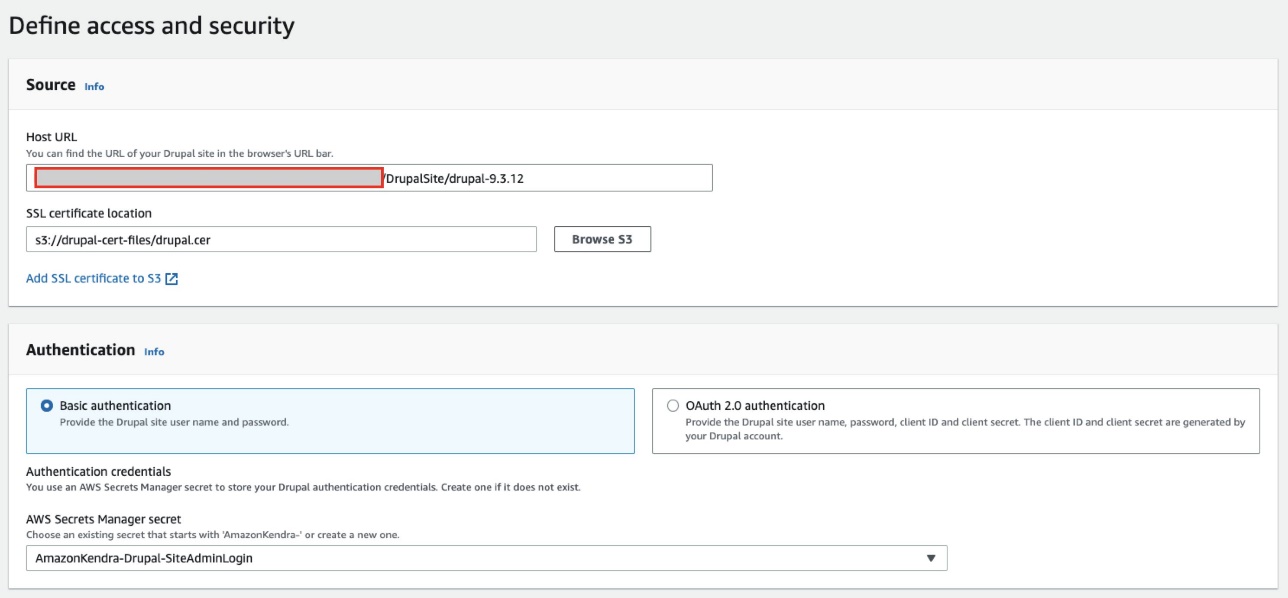
- Under Authentication, you have two options:
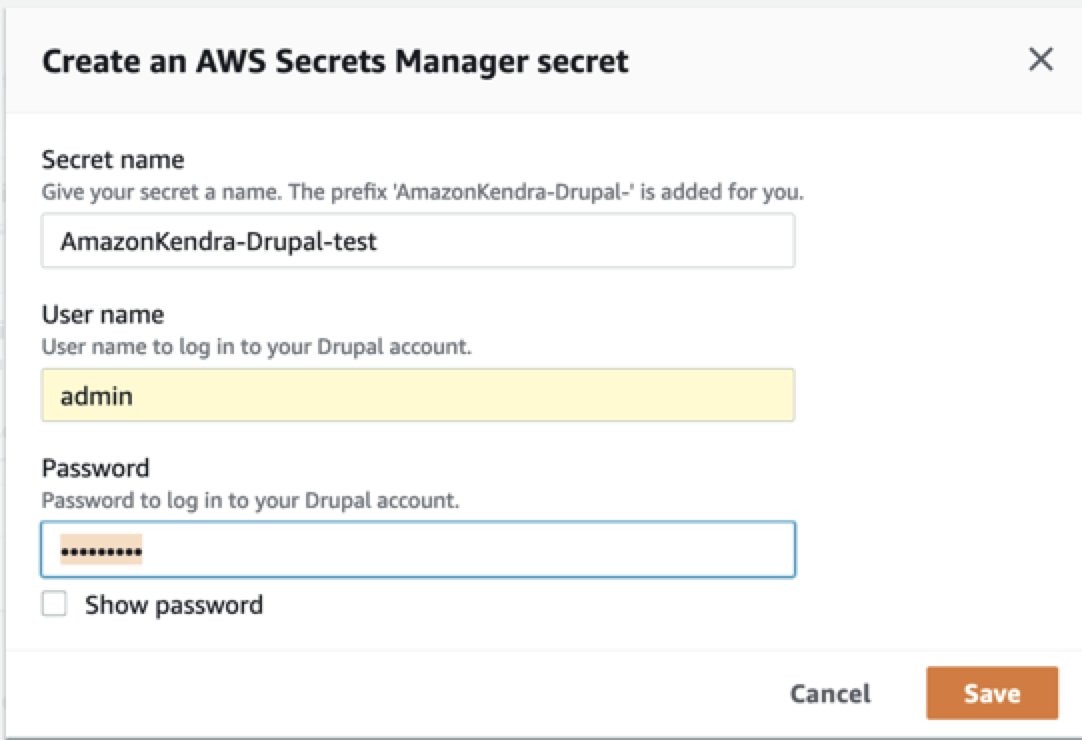
- Use Secrets Manager to create new Drupal authentication credentials. You need a Drupal admin user name and password (additionally, a client ID and client secret for OAuth 2.0 authentication).
- Use an existing Secrets Manager secret that has the Drupal authentication credentials you want the connector to access (additionally, a client ID and client secret for OAuth 2.0 authentication).
- Choose Save and add secret.
- For IAM role, choose Create a new role or choose an existing IAM role configured with appropriate IAM policies to access the Secrets Manager secret, Amazon Kendra index, and data source.
Refer to IAM roles for data sources for the required permissions for the IAM role.
- Choose Next.

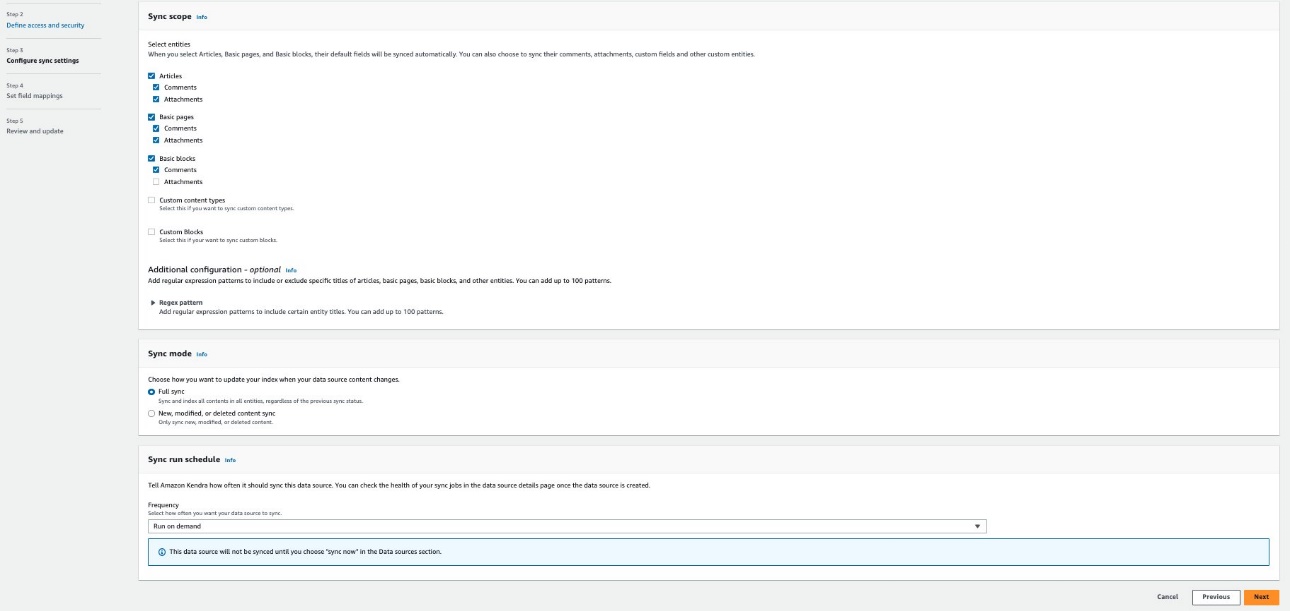
- In the Configure sync settings section, select Articles, Basic pages, Basic blocks, Custom content types, and Custom Blocks along with options to crawl comments and attachments as needed.
- Optionally, enter the include/exclude patterns for the entity titles.
- Provide information about your sync scope (full or delta only) and specify the run schedule.
- Choose Next.

- In the Set field mappings section, add custom Drupal fields you want to sync and their respective Amazon Kendra field mappings. The required fields are pre-mapped by Amazon Kendra.
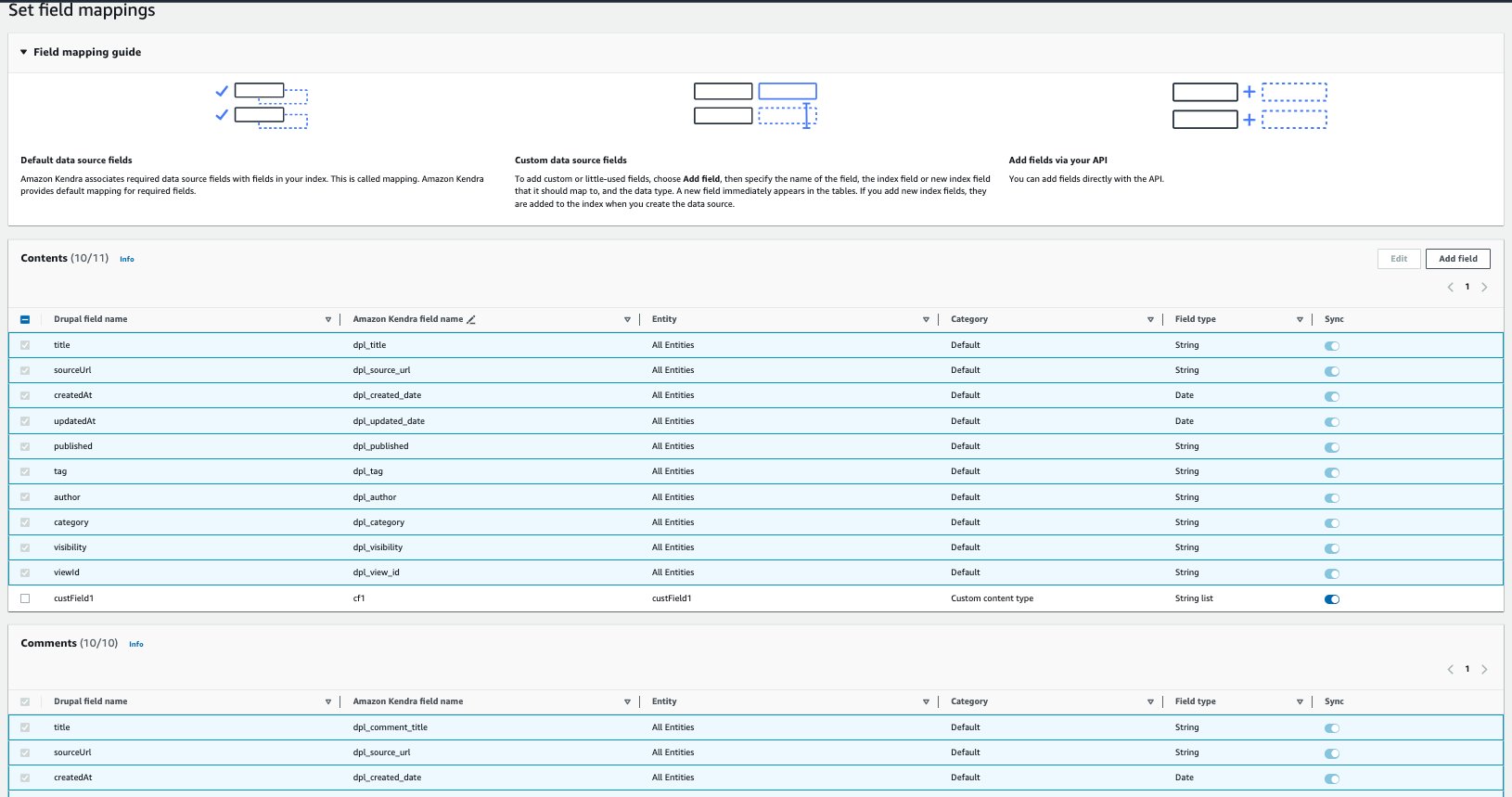
- Choose Next.
- Review the configuration settings and save the data source.
- Choose Sync now on the created data source to start data synchronization with the Amazon Kendra Index.
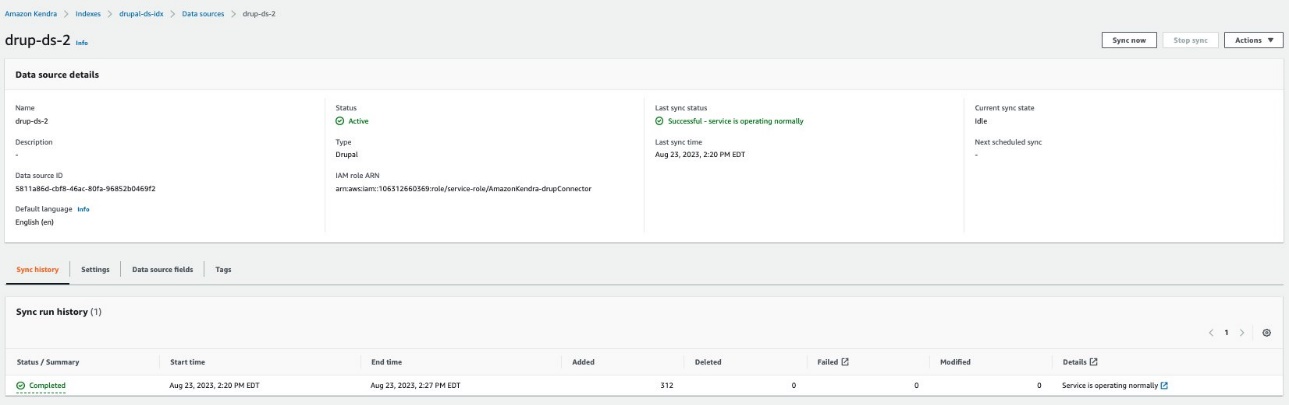
The time required to crawl and sync the contents into Amazon Kendra varies based on the volume of content and the throughput.

You can now search the indexed Drupal content using the search console or a search application. Optionally, you can search with ACL with the following additional steps.
- Go to the index page that you created and on the User access control tab, choose Edit settings.

- Under Access control settings, select Yes, keep the default values for Username and Groups, choose JSON for Token type, and keep the user-group expansion as None.
- On the next page, retain the default values (or change them based on your capacity requirements) and choose Update.
Perform intelligent search with Amazon Kendra
Before you try searching on the Amazon Kendra console or using the API, make sure that the data source sync is complete. To check, view the data sources and verify if the last sync was successful.
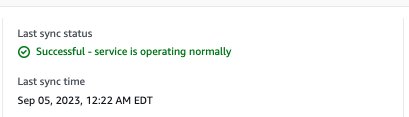
- To start your search, on the Amazon Kendra console, choose Search indexed content in the navigation pane.
You’re redirected to the Amazon Kendra search console. Now you can search information from the Drupal documents you indexed using Amazon Kendra.
- For this post, we search for a document stored in the Drupal data source.
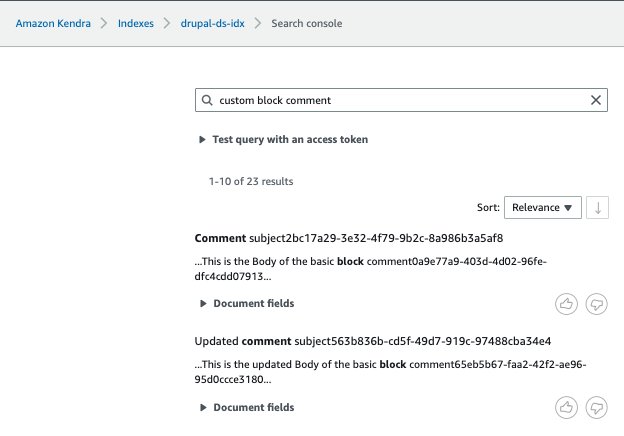
- Expand Test query with an access token and choose Apply token.
- For Username, enter the email address associated with your Drupal account.
- Choose Apply.
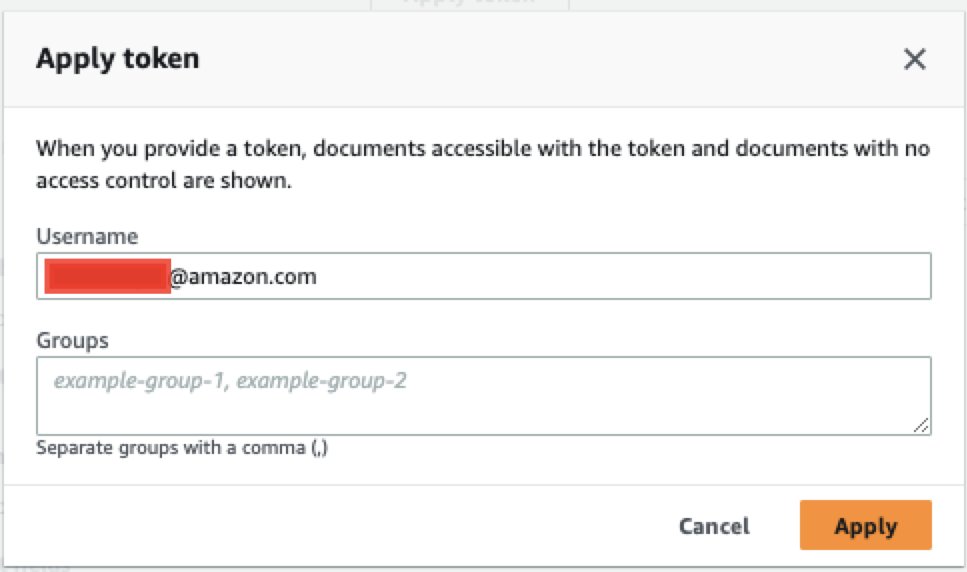
Now the user can only see the content they have access based on the user name or groups specified. In our example, the Drupal user with the [email protected] email doesn’t have access to any documents on Drupal, so none are displayed.

Limitations
Note the following limitations when using this solution:
- The content types (such as article, or basic page) that aren’t associated with any view cannot be crawled.
- If an administrator doesn’t have access to a block, then you can’t crawl the data from the block.
- The document body for article, basic page, basic block, user-defined content type, and user-defined block type is displayed in HTML format. If the HTML content is not well-formed, then the HTML related tags will appear in the document body and therefore can be seen on the Amazon Kendra search results. This is the same with comments of article, basic page, basic block, user-defined content type, user-defined block type.
- The content type or block type without description or body will not be injected into the Amazon Kendra index because there is a validation on the Amazon Kendra SDK side. However, Drupal allows you to create the content type without description or body. Only the comments and attachments of the respective content types or block types (if they exist) will be injected into the Amazon Kendra index.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it. If you only added a new data source using the Amazon Kendra connector for Drupal, delete that data source. Delete any IAM users created.
Conclusion
With the Amazon Kendra Drupal connector, your organization can search contents stored in a Drupal site securely using intelligent search powered by Amazon Kendra. In this post, we introduced you to the integration, but there are many additional features that we didn’t cover, such as the following:
- You can map additional fields to Amazon Kendra index attributes and enable them for faceting, search, and display in the search results
- You can integrate the Drupal data source with the Custom Document Enrichment (CDE) capability in Amazon Kendra to perform additional attribute mapping logic and even custom content transformation during ingestion
To learn more about the possibilities with Drupal, refer to the Amazon Kendra Developer Guide.
For more information on other Amazon Kendra built-in connectors for popular data sources, refer to the Amazon Kendra Connectors page.
About the authors
 Channa Basavaraja is a Senior Solutions Architect at AWS with over 2 decades of experience building distributed business solutions. His areas of depth span Machine Learning, app/mobile dev, event-driven architecture, and IoT/edge computing.
Channa Basavaraja is a Senior Solutions Architect at AWS with over 2 decades of experience building distributed business solutions. His areas of depth span Machine Learning, app/mobile dev, event-driven architecture, and IoT/edge computing.
 Yuanhua Wang is a software engineer at AWS with more than 15 years of experience in the technology industry. His interests are software architecture and build tools on cloud computing.
Yuanhua Wang is a software engineer at AWS with more than 15 years of experience in the technology industry. His interests are software architecture and build tools on cloud computing.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/intelligently-search-drupal-content-using-amazon-kendra/

