A vagyonkezelés során a portfóliókezelőknek szorosan figyelemmel kell kísérniük a befektetési univerzum vállalatait, hogy azonosítsák a kockázatokat és lehetőségeket, és irányítsák a befektetési döntéseket. A közvetlen események, például a bevételi jelentések vagy a hitelminősítések követése egyszerű – riasztásokat állíthat be, hogy értesítse a vezetőket a cégneveket tartalmazó hírekről. A beszállítóknál, vevőknél, partnereknél vagy a vállalati ökoszisztémán belüli egyéb entitásoknál bekövetkező eseményekből eredő másod- és harmadrendű hatások észlelése azonban kihívást jelent.
Például az ellátási lánc megszakadása egy kulcsfontosságú szállítónál valószínűleg negatív hatással lenne a későbbi gyártókra. Vagy egy nagy ügyfél elvesztése keresleti kockázatot jelent a szállító számára. Nagyon gyakran az ilyen események nem kerülnek olyan címlapokra, amelyek közvetlenül az érintett vállalatot mutatják be, de mégis fontos odafigyelni rájuk. Ebben a bejegyzésben egy automatizált megoldást mutatunk be, amely tudásgráfokat és generatív mesterséges intelligencia (AI) az ilyen kockázatok felszínre hozása kapcsolati térképek és valós idejű hírek kereszthivatkozásával.
Általánosságban ez két lépésből áll: Először is, a vállalatok (vevők, beszállítók, igazgatók) közötti bonyolult kapcsolatok tudásgráfba építése. Másodszor, használja ezt a grafikonadatbázist a generatív mesterséges intelligencia mellett a híresemények másod- és harmadrendű hatásainak észlelésére. Ez a megoldás például rávilágíthat arra, hogy az alkatrész-beszállítóknál tapasztalható késések megzavarhatják a portfólióban lévő későbbi autógyártók termelését, bár egyikre sem hivatkoznak közvetlenül.
Az AWS segítségével ezt a megoldást kiszolgáló nélküli, méretezhető és teljes mértékben eseményvezérelt architektúrában telepítheti. Ez a bejegyzés két kulcsfontosságú AWS-szolgáltatásra épülő koncepció bizonyítását mutatja be, amelyek jól alkalmasak gráfos tudásábrázolásra és természetes nyelvi feldolgozásra: Amazon Neptun és a Amazon alapkőzet. A Neptune egy gyors, megbízható, teljesen felügyelt grafikon adatbázis-szolgáltatás, amely egyszerűvé teszi az olyan alkalmazások létrehozását és futtatását, amelyek szorosan összekapcsolt adatkészletekkel működnek. Az Amazon Bedrock egy teljesen felügyelt szolgáltatás, amely egyetlen API-n keresztül számos nagy teljesítményű alapozó modellt (FM) kínál olyan vezető mesterséges intelligencia-cégektől, mint az AI21 Labs, az Anthropic, a Cohere, a Meta, a Stability AI és az Amazon. képességek generatív AI-alkalmazások létrehozására biztonsággal, adatvédelemmel és felelősségteljes mesterségesintelligencia-alkalmazásokkal.
Összességében ez a prototípus bemutatja a tudásgráfok és a generatív mesterséges intelligencia lehetséges művészetét – a jelek származtatása különböző pontok összekapcsolásával. A befektetési szakemberek számára az a lehetőség, hogy a jelhez közelebb kerüljenek a fejleményekhez, miközben elkerülik a zajt.
Készítse el a tudásgráfot
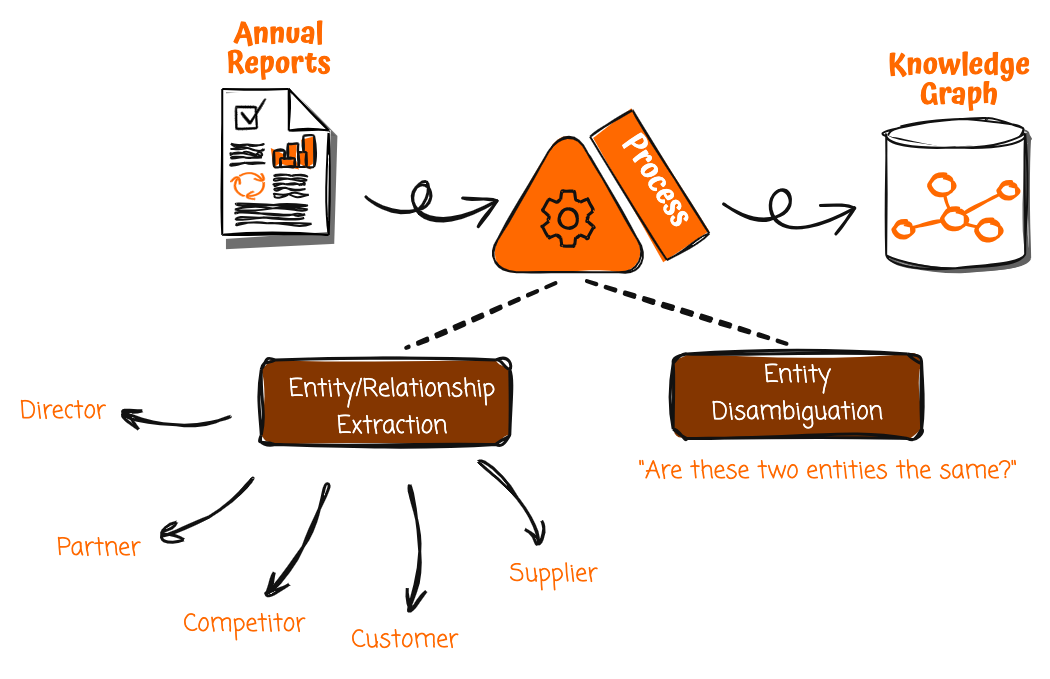
Ennek a megoldásnak az első lépése a tudásgráf felépítése, és a tudásgrafikonok értékes, de gyakran figyelmen kívül hagyott adatforrása a vállalati éves jelentések. Mivel a hivatalos vállalati kiadványokat megjelenés előtt alaposan megvizsgálják, a bennük lévő információk valószínűleg pontosak és megbízhatóak. Az éves jelentések azonban strukturálatlan formátumban készülnek, nem gépi fogyasztásra, hanem emberi olvasásra. A bennük rejlő lehetőségek kiaknázásához olyan módszerre van szükség, amellyel szisztematikusan kinyerhetjük és strukturálhatjuk a bennük rejlő rengeteg tényt és összefüggést.
Az olyan generatív mesterséges intelligencia szolgáltatásokkal, mint az Amazon Bedrock, most már automatizálhatja ezt a folyamatot. Elkészíthet egy éves jelentést, és elindíthat egy feldolgozási folyamatot a jelentés feldolgozásához, kisebb részekre bontásához, és a természetes nyelv megértését alkalmazva kiemelheti a kiemelkedő entitásokat és kapcsolatokat.
Például egy mondat, amely kimondja, hogy „[A vállalat] 1,800 elektromos kisteherautó megrendelésével bővítette európai elektromos szállítási flottáját [B vállalattól]”, lehetővé tenné az Amazon Bedrock számára, hogy azonosítsa a következőket:
- [A vállalat] ügyfélként
- [B vállalat] mint beszállító
- Szállítói kapcsolat [A vállalat] és [B vállalat] között
- Az „elektromos szállítókocsik szállítója” kapcsolati adatai
Az ilyen strukturált adatok strukturálatlan dokumentumokból való kinyeréséhez gondosan megtervezett promptokat kell biztosítani a nagy nyelvi modellekhez (LLM), hogy szövegelemzést végezhessenek az entitások, például a vállalatok és személyek, valamint a kapcsolatok, például az ügyfelek, beszállítók stb. A promptok egyértelmű utasításokat tartalmaznak arra vonatkozóan, hogy mire kell figyelni, és milyen struktúrában kell visszaküldeni az adatokat. Ha ezt a folyamatot a teljes éves jelentésben megismétli, kivonhatja a releváns entitásokat és kapcsolatokat egy gazdag tudásgráf összeállításához.
Mielőtt azonban a kinyert információt a tudásgráfba helyezné, először egyértelművé kell tennie az entitásokat. Előfordulhat például, hogy már van egy másik „[A vállalat]” entitás a tudásgráfban, de ez egy másik, azonos nevű szervezetet is képviselhet. Az Amazon Bedrock képes megfontolni és összehasonlítani az olyan attribútumokat, mint például az üzleti fókuszterület, az ipar, a bevételt termelő iparágak és a kapcsolatok más entitásokkal, hogy megállapítsa, a két entitás ténylegesen különbözik-e egymástól. Ez megakadályozza, hogy a független vállalatokat pontatlanul egyetlen egységbe vonják össze.
Miután az egyértelműsítés befejeződött, megbízhatóan hozzáadhat új entitásokat és kapcsolatokat a Neptune tudásgráfjához, gazdagítva azt az éves jelentésekből kivont tényekkel. Idővel a megbízható adatok feldolgozása és a megbízhatóbb adatforrások integrálása segít egy átfogó tudásgráf felépítésében, amely grafikonlekérdezéseken és elemzéseken keresztül képes feltárni a betekintést.
Ez a generatív mesterséges intelligencia által lehetővé tett automatizálás éves jelentések ezrei feldolgozását teszi lehetővé, és felbecsülhetetlen értékű erőforrást tesz lehetővé a tudásgráfok kezeléséhez, amely egyébként kihasználatlan maradna a túlzottan nagy manuális erőfeszítés miatt.
A következő képernyőkép egy példát mutat be a vizuális felfedezésre, amely lehetséges egy Neptune gráf adatbázisban a Graph Explorer eszköz.

Hírcikkek feldolgozása

A megoldás következő lépése a portfóliókezelők hírfolyamainak automatikus gazdagítása és az érdeklődési körüknek és befektetéseiknek megfelelő cikkek kiemelése. A hírfolyamhoz a portfóliókezelők bármely harmadik fél hírszolgáltatóra feliratkozhatnak ezen keresztül AWS adatcsere vagy egy másik általuk választott hír API.
Amikor egy hírcikk belép a rendszerbe, egy feldolgozási folyamatot hívunk meg a tartalom feldolgozásához. Az éves jelentések feldolgozásához hasonló technikák alkalmazásával az Amazon Bedrock entitások, attribútumok és kapcsolatok kinyerésére szolgál a hírcikkből, amelyek azután a tudásgráfhoz képest egyértelművé teszik, hogy azonosítsák a megfelelő entitást a tudásgráfban.
A tudásgráf cégek és személyek közötti kapcsolatokat tartalmaz, és a cikk entitások meglévő csomópontokhoz való kapcsolásával azonosíthatja, hogy van-e téma két ugráson belül azon vállalatokhoz képest, amelyekbe a portfóliómenedzser befektetett, vagy amelyek iránt érdeklődik. Egy ilyen kapcsolat megtalálása azt jelzi, hogy cikk releváns lehet a portfóliókezelő számára, és mivel az alapul szolgáló adatok tudásgráfban vannak ábrázolva, megjeleníthető, hogy segítsen a portfóliókezelőnek megérteni, miért és hogyan releváns ez a kontextus. A portfólióval való kapcsolatok azonosítása mellett az Amazon Bedrock segítségével hangulatelemzést is végezhet a hivatkozott entitásokon.
A végső kimenet egy gazdag hírfolyam, amely olyan cikkeket jelenít meg, amelyek valószínűleg hatással lesznek a portfóliókezelő érdeklődési területeire és befektetéseire.
Megoldás áttekintése
A megoldás általános architektúrája az alábbi ábrán látható.
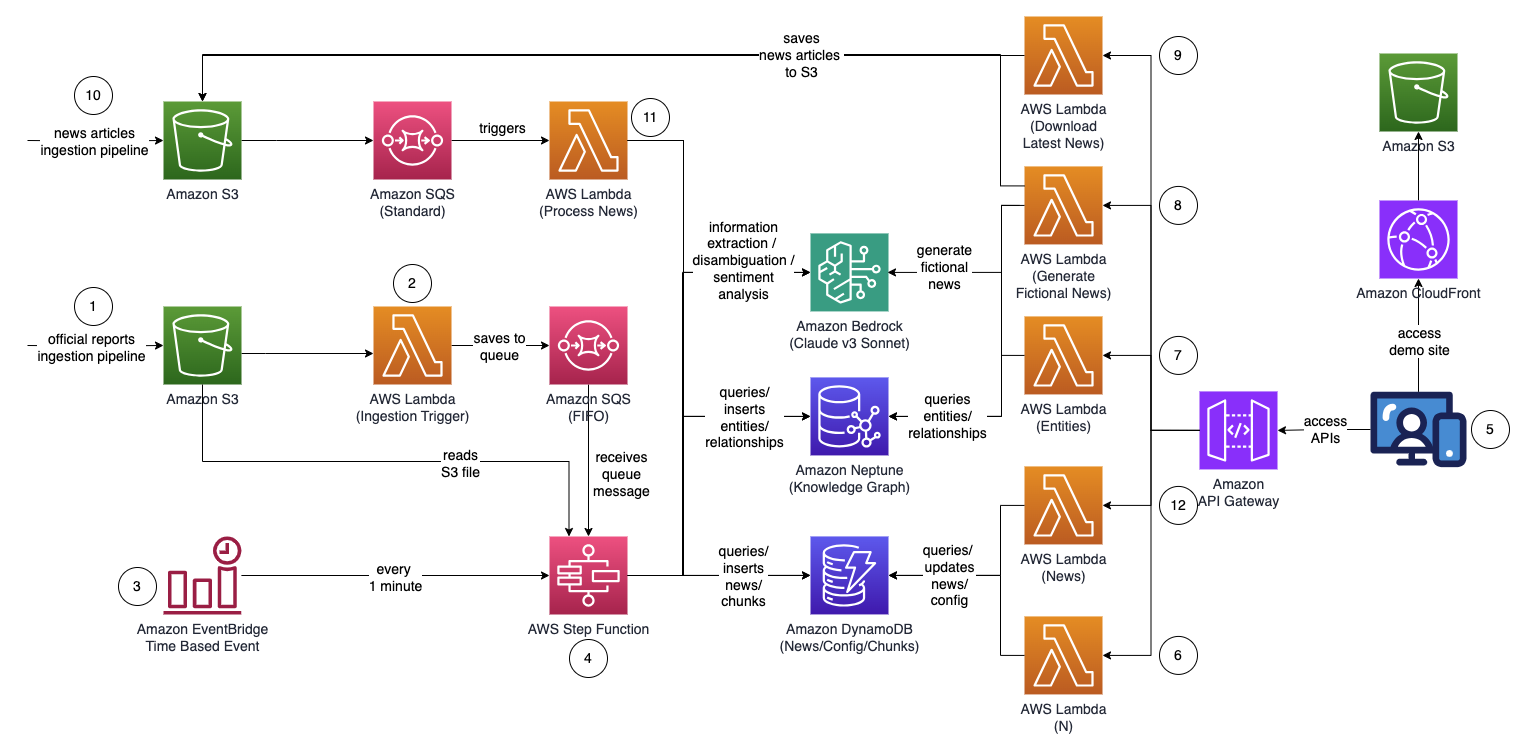
A munkafolyamat a következő lépésekből áll:
- A felhasználó hivatalos jelentéseket tölt fel (PDF formátumban) egy Amazon egyszerű tárolási szolgáltatás (Amazon S3) vödör. A jelentéseknek hivatalosan közzétett jelentéseknek kell lenniük, hogy minimálisra csökkentsék a pontatlan adatok felvételét a tudásgrafikonba (szemben a hírekkel és bulvárlapokkal).
- Az S3 eseményértesítés meghív egy AWS Lambda funkciót, amely elküldi az S3 tárolót és a fájl nevét egy Amazon Simple Queue Service (Amazon SQS) sor. A FIFO (First-In-First-Out) sor gondoskodik arról, hogy a jelentések feldolgozási folyamata egymás után kerüljön végrehajtásra, hogy csökkentse annak valószínűségét, hogy ismétlődő adatok kerüljenek a tudásgráfba.
- An Amazon EventBridge időalapú esemény minden percben lefut, hogy elindítsa egy AWS lépésfunkciók állapotgép aszinkron módon.
- A Step Functions állapotgép egy sor feladaton keresztül dolgozza fel a feltöltött dokumentumot a kulcsfontosságú információk kinyerésével és a tudásgráfba való beszúrásával:
- Várólista üzenet fogadása az Amazon SQS-től.
- Töltse le a PDF jelentésfájlt az Amazon S3-ról, ossza fel több kisebb szövegrészre (körülbelül 1,000 szóból) a feldolgozáshoz, és tárolja a szövegrészeket Amazon DynamoDB.
- Használja az Anthropic Claude v3 Sonnetjét az Amazon Bedrock webhelyen az első néhány szövegrész feldolgozásához, hogy meghatározza a fő entitást, amelyre a jelentés hivatkozik, valamint a releváns attribútumokat (például az iparágat).
- Töltse le a szövegrészeket a DynamoDB-ből, és minden egyes szövegrészhez hívjon meg egy Lambda-függvényt az entitások (például vállalat vagy személy) és kapcsolatának (ügyfél, szállító, partner, versenytárs vagy igazgató) a fő entitáshoz való kinyeréséhez az Amazon Bedrock használatával. .
- Konszolidálja az összes kivont információt.
- Szűrje ki a zajt és az irreleváns entitásokat (például olyan általános kifejezéseket, mint a „fogyasztók”) az Amazon Bedrock segítségével.
- Használja az Amazon Bedrock-ot az egyértelműsítés végrehajtásához úgy, hogy a kinyert információkat a tudásgráf hasonló entitásainak listájához használja. Ha az entitás nem létezik, illessze be. Ellenkező esetben használja azt az entitást, amely már létezik a tudásgráfban. Szúrja be az összes kibontott kapcsolatot.
- Tisztítsa meg az SQS várólista üzenet és az S3 fájl törlésével.
- A felhasználó hozzáfér egy React-alapú webalkalmazáshoz, hogy megtekinthesse azokat a hírcikkeket, amelyek az entitás, a hangulat és a kapcsolati útvonal információival vannak kiegészítve.
- A webalkalmazás segítségével a felhasználó megadja az ugrások számát (alapértelmezett N=2) a figyelni kívánt kapcsolati úton.
- A webalkalmazás segítségével a felhasználó megadja a nyomon követendő entitások listáját.
- A kitalált hírek generálásához a felhasználó választ Minta hírek generálása 10 minta pénzügyi hírcikket generál, véletlenszerű tartalommal, amelyeket betáplál a hírfeldolgozási folyamatba. A tartalom az Amazon Bedrock segítségével készült, és pusztán kitalált.
- Az aktuális hírek letöltését a felhasználó választja Töltse le a legfrissebb híreket letöltheti a mai nap legfontosabb híreit (a NewsAPI.org segítségével).
- A hírfájl (TXT formátum) feltöltődik egy S3 tárolóba. A 8. és 9. lépés automatikusan feltölti a híreket az S3 tárolóba, de integrációkat is létrehozhat a preferált hírszolgáltatóhoz, például az AWS Data Exchange-hez vagy bármely harmadik fél hírszolgáltatóhoz, hogy a hírcikkeket fájlként helyezze az S3 tárolóba. A híradatfájl tartalmát a következőre kell formázni
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - Az S3 eseményértesítés elküldi az S3 tárolót vagy fájlnevet az Amazon SQS-nek (standard), amely több Lambda funkciót hív meg a híradatok párhuzamos feldolgozásához:
- Az Amazon Bedrock segítségével kinyerheti a hírekben említett entitásokat, valamint az említett entitáshoz kapcsolódó kapcsolódó információkat, kapcsolatokat és hangulatot.
- Ellenőrizze a tudásgráfot, és használja az Amazon Bedrock-ot, hogy a hírekből és a tudásgráfon belülről elérhető információk alapján érvelés segítségével azonosítsa a megfelelő entitást.
- Miután megtalálta az entitást, keresse meg és adja vissza a jellel jelölt entitásokhoz csatlakozó összes csatlakozási útvonalat
INTERESTED=YESa tudásgráfban, amelyek N=2 ugrásnyi távolságon belül vannak.
- A webalkalmazás 1 másodpercenként automatikusan frissül, hogy előhívja a legfrissebb feldolgozott híreket, hogy megjelenjen a webalkalmazásban.
Telepítse a prototípust
Telepítheti a prototípus-megoldást, és elkezdheti a kísérletezést. A prototípus elérhető innen GitHub és részleteket tartalmaz a következőkről:
- Telepítési előfeltételek
- Telepítési lépések
- Tisztítási lépések
Összegzésként
Ez a bejegyzés egy olyan megoldást mutatott be, amely a portfóliómenedzsereket segíti a híreseményekből eredő másod- és harmadrendű kockázatok észlelésében, anélkül, hogy az általuk nyomon követett vállalatokra utalna közvetlen hivatkozás. A bonyolult vállalati kapcsolatok tudásgrafikonjának kombinálásával a generatív mesterséges intelligencia segítségével valós idejű hírelemzéssel kiemelhetők a downstream hatások, például a beszállítói akadozások miatti gyártási késések.
Bár ez csak egy prototípus, ez a megoldás tudásgráfok és nyelvi modellek ígéretét mutatja a pontok összekapcsolására és a zajból származó jelek levezetésére. Ezek a technológiák segíthetik a befektetési szakembereket azáltal, hogy a kapcsolatok feltérképezése és érvelése révén gyorsabban felfedik a kockázatokat. Összességében ez a gráfadatbázisok és a mesterséges intelligencia ígéretes alkalmazása, amely indokolja a feltárást a befektetéselemzés és a döntéshozatal bővítése érdekében.
Ha a pénzügyi szolgáltatásokban a generatív mesterségesintelligencia ezen példája érdekli az Ön vállalkozását, vagy hasonló ötlete van, forduljon AWS-fiókkezelőjéhez, és örömmel folytatjuk a további kutatásokat.
A szerzőről
 Xan Huang az AWS vezető megoldások építésze, székhelye Szingapúr. A nagy pénzintézetekkel együttműködve biztonságos, méretezhető és magasan elérhető megoldásokat tervez és épít a felhőben. A munkán kívül Xan szabadidejének nagy részét a családjával tölti, és 3 éves lánya irányítja őt. Xant megtalálod itt LinkedIn.
Xan Huang az AWS vezető megoldások építésze, székhelye Szingapúr. A nagy pénzintézetekkel együttműködve biztonságos, méretezhető és magasan elérhető megoldásokat tervez és épít a felhőben. A munkán kívül Xan szabadidejének nagy részét a családjával tölti, és 3 éves lánya irányítja őt. Xant megtalálod itt LinkedIn.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

