Does your heart sink when you see ‘PFA the document’, only to discover it’s a PDF with data and tables, which you’d need to copy to Excel? It’s something many of us can relate to. As much as we love the format for its portability and interoperability, PDFs are not user-friendly when it comes to editing and extracting data, especially tables.
The manual process of copying tables from PDFs to Excel can be tedious and time-consuming. Wonky formatting, lost data, and other inconsistencies can make this simple task a real headache.
Thankfully, there are ways to get around this problem. From invoices to reports and more, let’s look at the different ways to copy those pesky PDF tables into Excel effortlessly.
1. Copy PDF tables to Excel without any additional software
Sometimes you may not have the time or permission to install or sign up for new software. You want to quickly get the data into Excel and move on with your work.
Here are a few different ways to do it:
a. The standard copy-paste method
The standard copy-paste method is the most straightforward way to copy tables from PDF to Excel spreadsheets. However, this method might not preserve the table’s structure and almost always require manual work to clean the data.
The standard copy-paste method could work for you if the data you need to extract from a PDF is relatively simple and small in volume. Here’s how you can use this:
- Open your PDF document.
- Select the data table you want to copy.
- Right-click and choose ‘Copy’ or press Ctrl+C (Cmd+C on a Mac). Open a new Excel spreadsheet.
- Right-click on the cell where you want to paste the data and choose ‘Paste’ or press Ctrl+V (Cmd+V on a Mac).
The data will then be pasted into your Excel spreadsheet, ready for you to work with. While this method is quick and requires no special tools, it usually doesn’t preserve the table format, especially for more complex tables.
The copy-paste method doesn’t work well with scanned images or PDFs with complex layouts. Consider one of the other methods discussed below for larger or more complex tasks.
Note: If the PDF is read-only or password-protected, you may not have permission to select or copy the content. In such cases, you must first ask the PDF owner for the password or a copy of the PDF with the necessary permissions.
b. Open the PDF with Google Docs or MS Word
Both Google Docs and Microsoft Word now have built-in capabilities for opening and editing PDF files. This can be handy if you need to quickly copy data or text from PDFs.
To use this method with Google Docs, follow these steps:
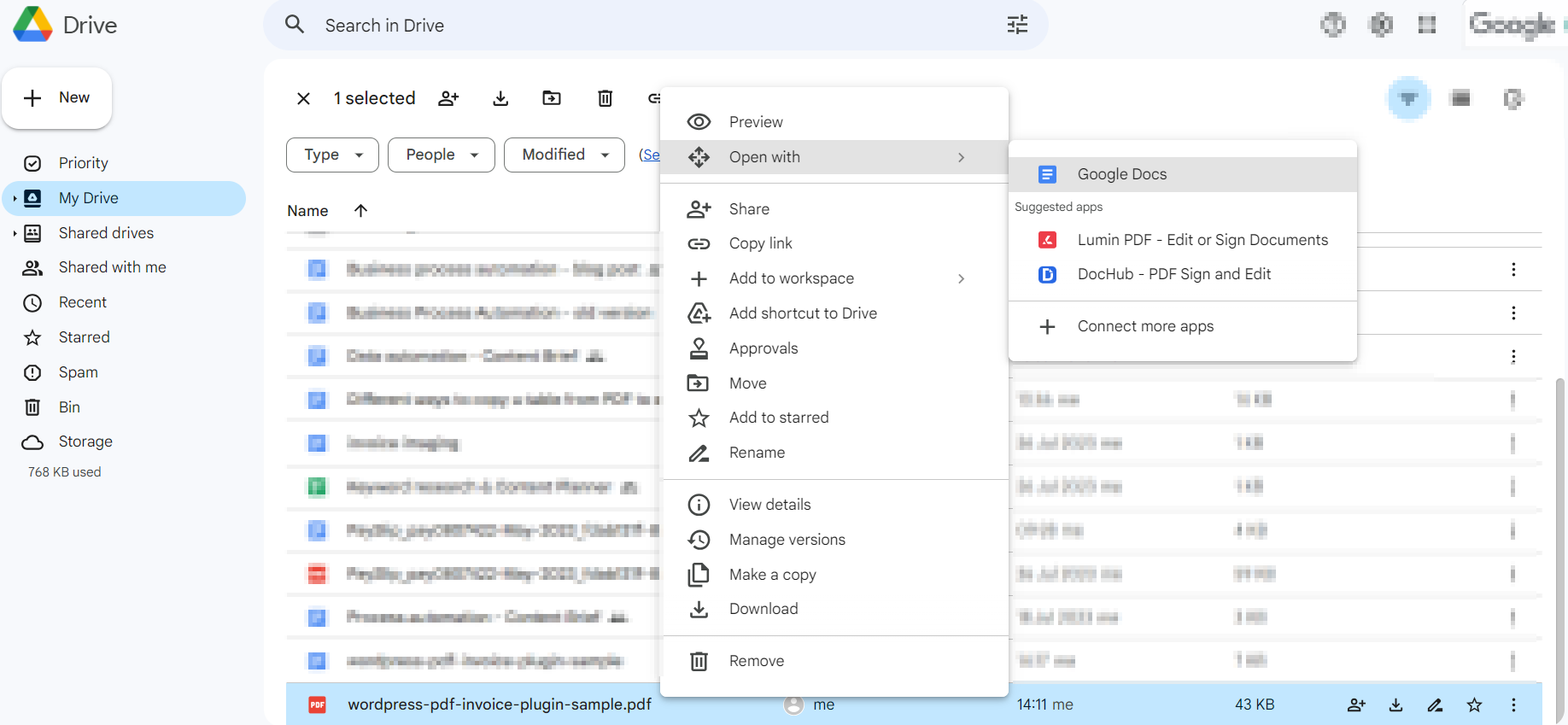
- Go to your Google Drive.
- Upload your PDF.
- Right-click the file and select ‘Open with > Google Docs’.
- Find the PDF content will be imported into a new Google Docs document
- Copy, paste, or edit the content as needed
- Copy the relevant tables and paste them into the Excel spreadsheet you’re working on.
For Microsoft Word:
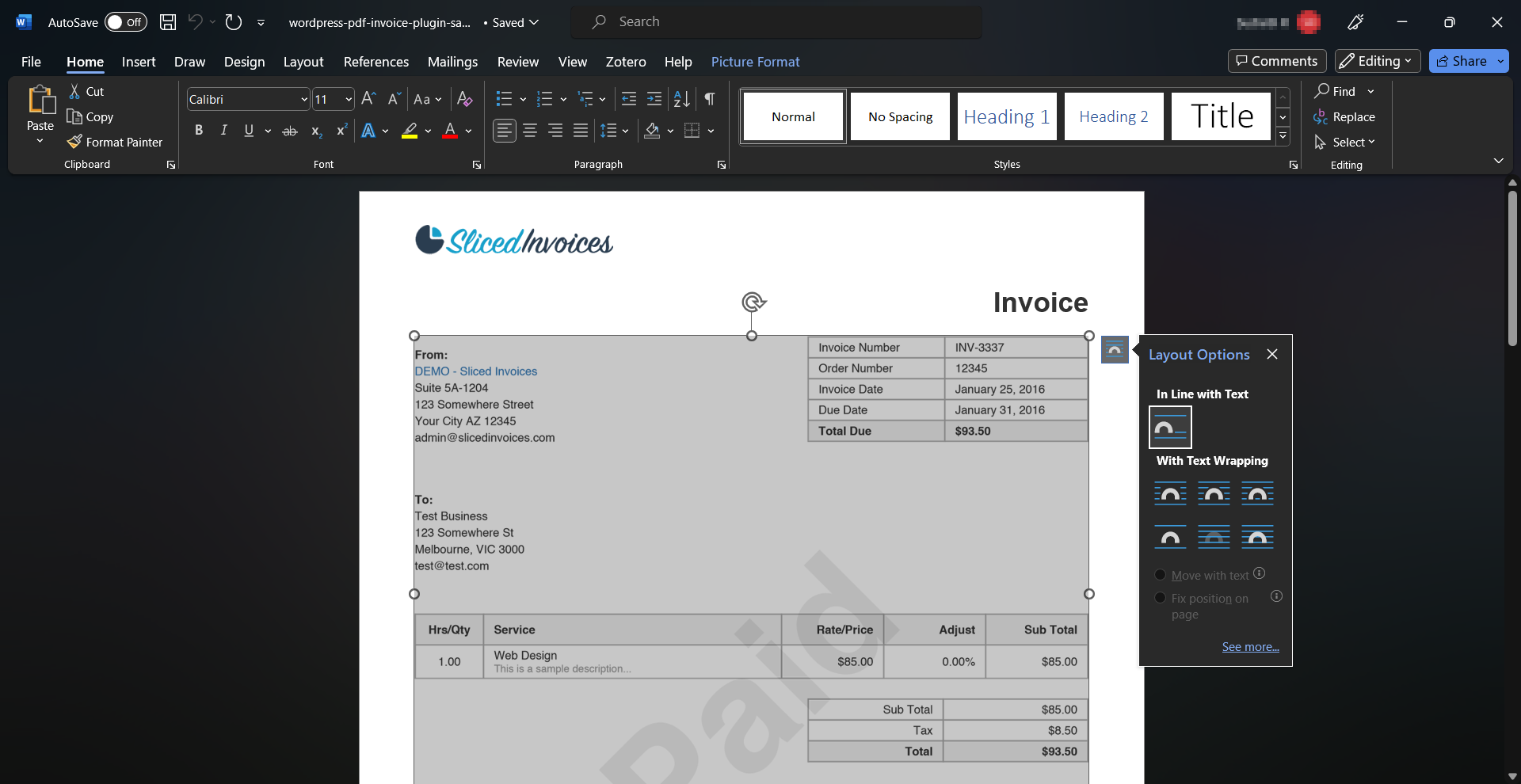
- Go to ‘File’ > ‘Open’ > ‘Browse’.
- Select the PDF file you want to open.
- The PDF is opened in an editable Word document.
- Copy the relevant tables and paste them into your Excel spreadsheet.
Using Google Docs or Microsoft Word for this task is free and requires no additional software. However, the conversion from PDF to Word or Google Docs may not be perfect. You can expect jumbled paragraphs, distorted images, and misaligned fields. You may need to spend additional time fixing and adjusting the formatting.
These tools struggle with complex tables, scanned images, and PDFs with intricate layouts. They are better suited for simple, text-heavy files.
c. Adobe Acrobat Pro’s conversion feature
If you are looking for a way to copy tables inside your Acrobat Reader DC, here’s a handy feature you might not know about. It has a built-in feature that enables you to convert PDF files into editable Excel documents.

Here’s how you do it:
- Open your PDF file in Acrobat.
- Click on the ‘Export PDF’ tool in the right-hand pane.
- Choose ‘Spreadsheet’ as your export format, then select ‘Microsoft Excel Workbook’.
- Click ‘Export’, and Acrobat will automatically recognize and convert any scanned text within your PDF.
- Save the converted file.
This works great if your PDF has simple, well-structured tables. But for complex tabular data or multipage tables, the results may not always be perfect. You might need to clean up before your data is ready to use. And since it doesn’t support batch processing, you can only convert one file at a time, which may not be ideal for larger tasks.
Please note that this feature is only available in Adobe Acrobat Pro. It is not available with the accessible version of Adobe Acrobat Reader. You must purchase a license or subscribe to Adobe Acrobat Pro to use this feature.
d. Excel’s internal PDF import feature
Let’s face it, sometimes, you just need to copy a table from a PDF into Excel. Without any bells and whistles, you want a straightforward solution.
That’s where Microsoft Excel’s internal PDF import feature comes into play. It’s quick, easy, and doesn’t require any additional software.
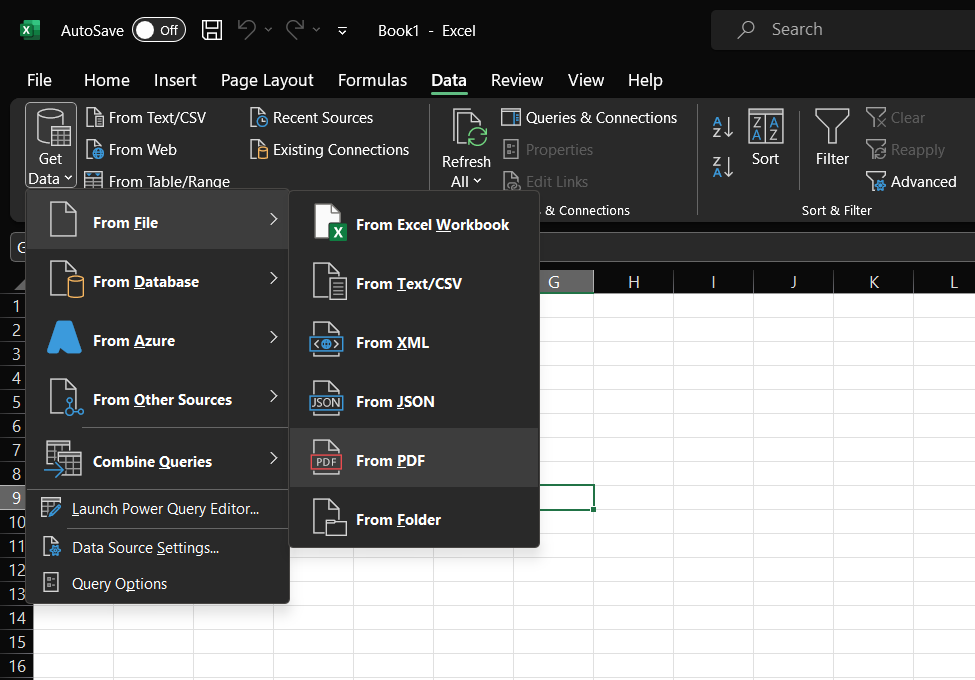
Here’s how to do it:
- Open an Excel spreadsheet
- Click on the Data tab in the upper menu.
- Click on the Get Data menu, followed by ‘From File’ and then ‘From PDF’
- Select and upload the PDF file
- Review the different tables that Excel has identified.
- Select the table(s) you want to import and click ‘Load’
The data from your PDF will then be imported into your spreadsheet. You have the option to select individual tables or all the tables present on a single page. What’s more, you can also transform the sheet using a Power Query editor.
The Excel internal PDF import feature is quick and direct but might not work well with complex tables or scanned images. Plus, it only allows you to convert one PDF at a time, which could be time-consuming for larger tasks.
There are a ton of simple web-based conversion tools that can simplify your PDF table copying or extraction workflow. Whether you want the output in CSV, XLS, or XLSX format, these tools can manage it all.
All you have to do is upload the PDF, let the tool process and convert the file, and then download the resultant spreadsheet. The reliability, functionality, and accuracy of these tools can vary greatly, but they generally work well for simple tasks.

Some of the most popular PDFs to Excel converters include:
- PDF to Excel
- PDF to CSV
- ilovepdf
- Acrobat’s PDF converter tools
- SodaPDF
- Smallpdf
- Pdf2go
- Pdftoexcelonline
- Freepdfconvert
- Freepdftoexcel
Here’s what the typical workflow looks like:
- Go to the website of the online conversion tool.
- Click on ‘Upload file’ or ‘Choose file’.
- Select the PDF file you want to convert.
- Choose the output format (usually CSV, XLS, or XLSX).
- Click ‘Convert’.
Most of these tools offer a free tier, but you might need to subscribe to their premium plans for more advanced features or to remove limitations. Remember that uploading sensitive information to these online tools might pose a security risk. Make sure to read their privacy policies before using them.
Despite being easy to use, these tools have their limitations. If you are dealing with complex tables, image-based PDFs, or multi-page tables, these online converters might not yield the best results. More importantly, these tools won’t be adequate if you need to convert a large number of files regularly or if you require batch-processing capabilities.
3. Deploy dedicated open-source software
Open-source software can provide powerful solutions for extracting tables from PDFs to Excel. These tools are free to use and can often handle more complex tasks than the abovementioned methods.
The best part is that you’ll have a great deal of control over your data and its security, as all processing is done locally on your own machine.
If you are an open-source enthusiast, then Tabula is an excellent choice. This Java-based tool allows you to extract tables from PDF files and convert them into CSV or Microsoft Excel format.
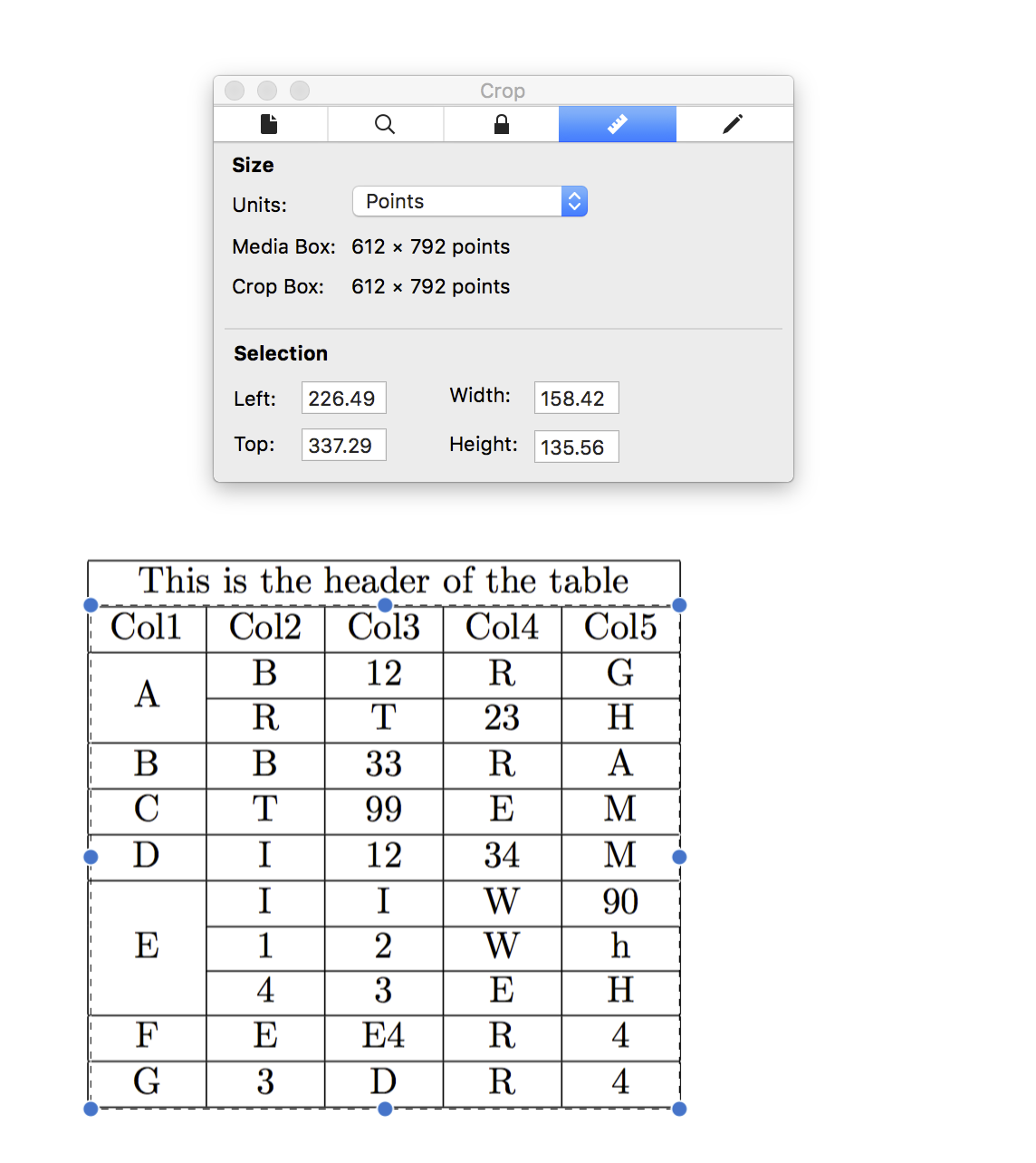
Since it is a desktop application, you must download and install it on your computer. Then follow these steps to convert your PDF table to Excel:
- Import your PDF file
- Snip the area of the table you want to extract.
- Click on the ‘Preview & Export Extracted Data’ button.
- Verify the data in the preview; if it looks good, click ‘Export’.
- Choose your preferred format (CSV or Excel) and save the file.
Tabula works best for PDFs with simple and well-structured tables. It doesn’t work on PDFs with scanned images or complex layouts, nor does it support batch processing. It may not be the best choice for copying large volumes of data or dealing with intricate table structures.
Excalibur might suit you if you are a tech-savvy individual who doesn’t mind getting your hands dirty. Excalibur is a web interface for extracting tabular data from PDFs, built on top of Camelot, a Python library known for its high accuracy and speed.
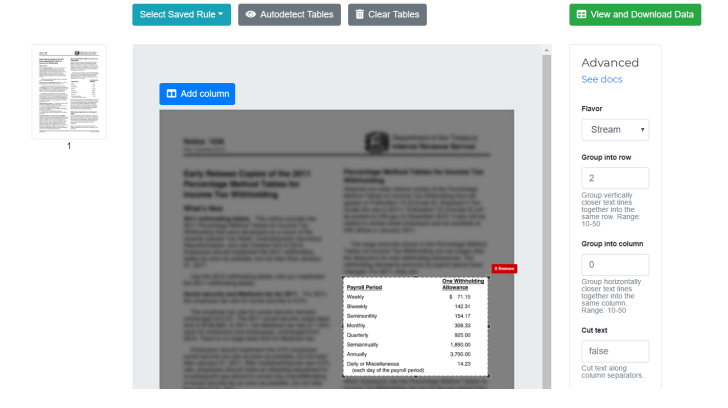
You need first to set up Excalibur on your machine to use it. Once that’s done, you can open any PDF using Excalibur, enter the page numbers where your tables are located, snip the area of each table, or use its auto-detect feature, and extract the data. The extracted data can then be downloaded as a CSV or Excel file.
Excalibur gives you much control over the extraction process — allowing you to autodetect tables, export in multiple formats, and even fine-tune the extraction settings. However, it requires technical knowledge and installation, which might not be suitable for everyone. It’s also worth noting that, like Tabula, Excalibur might struggle with PDFs containing scanned images or complex tables and doesn’t support batch processing.
Manual methods and simple tools might not cut it when you have to process tens and thousands of PDFs. More than data extraction, you need tools to identify, classify, and extract data at scale. This is where AI-powered automated tools come in.
If you are looking for a user-friendly yet robust document automation solution, Nanonets might be the perfect fit. Nanonets is a powerful machine learning-based tool that can extract data from various documents, including PDFs with complex table structures.
Use Nanonets PDF data extraction tool to capture data from multiple PDF documents all at once and get them in Excel sheets (or any other popular spreadsheet format) in no time. Whether you’re dealing with large volumes of invoices, receipts, reports, or other documents, this tool makes your life much easier.
The process of extracting tables from PDFs using Nanonets is relatively straightforward:
- Upload your PDF file to the platform
- Choose the type of data you want to extract
- Review and correct the extraction results if needed
- Download the extracted data as a CSV, Excel, or JSON file
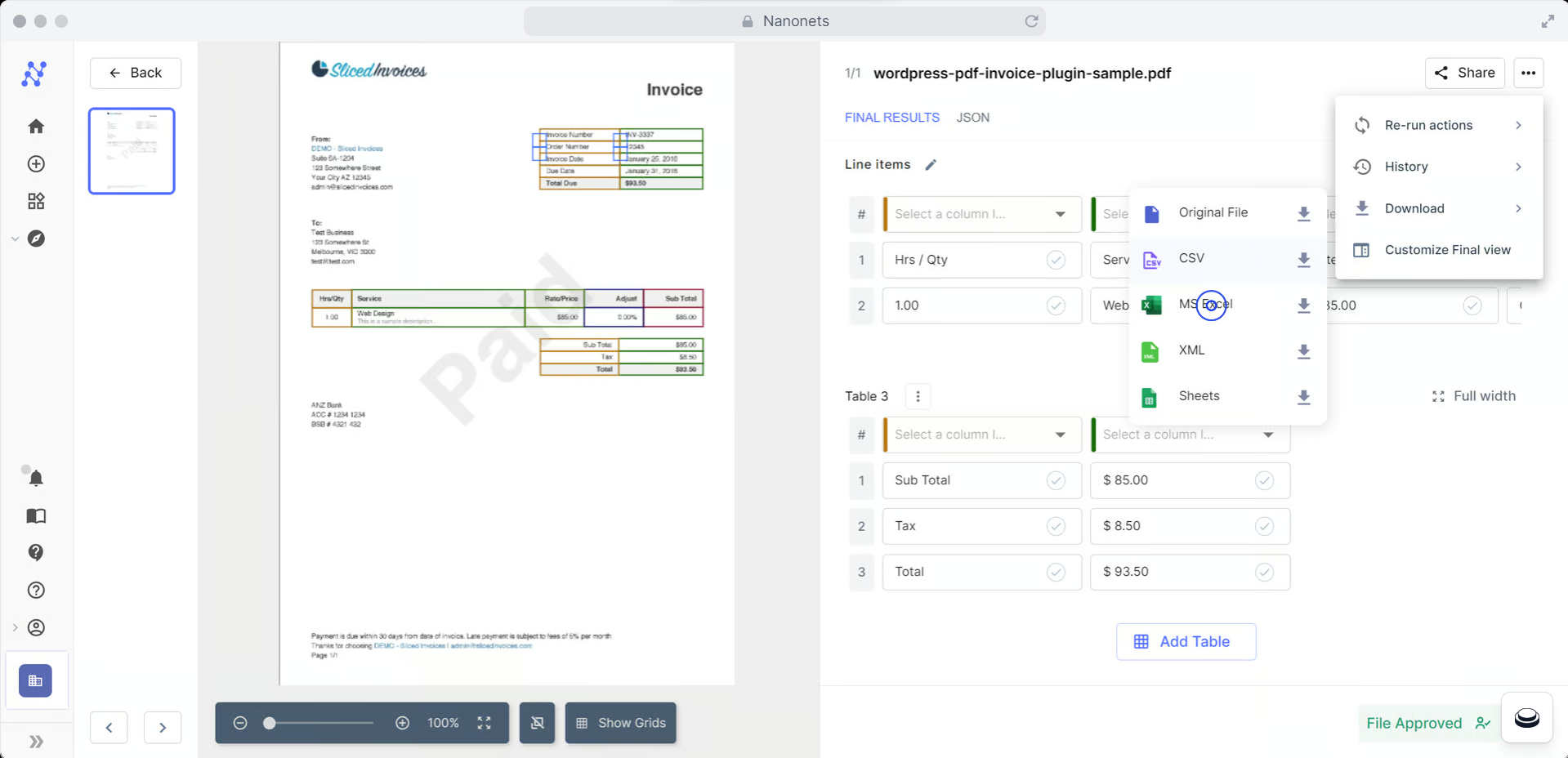
Nanonets offers a web interface that is easy to use, even for non-technical users. It also supports batch processing and API integration, enabling you to automate the table extraction process.
You can rename the data fields and ensure it remains consistent across all your documents. Moreover, it comes with approval workflows and internal task assignments to help you review and approve the extracted data before exporting. You can even set up automated importing of PDFs from an email inbox, Google Drive, One Drive, or using API calls.
Let’s look at a simple example. Suppose you work in the accounts department and want to process the invoices of all the tech tools your organization uses. Each invoice will be different – various layouts, structures, and formats. It can be a nightmare to manually check each invoice, copy the necessary data, and input it into an Excel sheet for analysis.
With the Nanonets PDF data extraction tool, you only need to upload all these invoices onto the platform. It will do the rest – automatically recognizes the structure of each invoice, extracts the relevant data fields (such as invoice number, date, vendor name, amount, etc.), and populates them into an Excel sheet.
The best part about the Nanonets PDF data extraction tool is that it also learns from your edits. The AI gets smarter with each interaction, making future extractions more accurate. So, even if your PDF has unstructured data or complex tables, it can handle the tasks with ease.
Wrapping up
We’ve listed different methods to copy tables from PDF files into Excel, each with strengths and limitations. There is obviously more than one way to handle this task. However, these methods provide an excellent balance of ease of use, functionality, and cost-effectiveness.
The right method for you will depend on your specific needs and circumstances. It is up to you to evaluate the complexity of your tables, the volume of PDFs you need to convert, and how much time you’re willing to spend on the process.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://nanonets.com/blog/copy-tables-from-pdfs-excel/

