This post is co-written with Stanislav Yeshchenko from Q4 Inc.
Enterprises turn to Retrieval Augmented Generation (RAG) as a mainstream approach to building Q&A chatbots. We continue to see emerging challenges stemming from the nature of the assortment of datasets available. These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured.
Q4 Inc. needed to address some of these challenges in one of their many AI use cases built on AWS. In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. Finally, we take a closer look at how the Q4 team used Amazon Bedrock and SQLDatabaseChain to implement a RAG-based solution with SQL generation.
Use case overview
Q4 Inc., headquartered in Toronto, with offices in New York and London, is a leading capital markets access platform that is transforming how issuers, investors, and sellers efficiently connect, communicate, and engage with each other. The Q4 Platform facilitates interactions across the capital markets through IR website products, virtual events solutions, engagement analytics, investor relations Customer Relationship Management (CRM), shareholder and market analysis, surveillance, and ESG tools.
In today’s fast-paced and data-driven financial landscape, Investor Relations Officers (IROs) play a critical role in fostering communication between a company and its shareholders, analysts, and investors. As part of their daily duties, IROs analyze diverse datasets, including CRM, ownership records, and stock market data. The aggregate of this data is used to generate financial reports, set investor relations goals, and manage communication with existing and potential investors.
To meet the growing demand for efficient and dynamic data retrieval, Q4 aimed to create a chatbot Q&A tool that would provide an intuitive and straightforward method for IROs to access the necessary information they need in a user-friendly format.
The end goal was to create a chatbot that would seamlessly integrate publicly available data, along with proprietary customer-specific Q4 data, while maintaining the highest level of security and data privacy. As for performance, the goal was to maintain a query response time of seconds to ensure a positive experience for end-users.
Financial markets is a regulated industry with high stakes involved. Providing incorrect or outdated information can impact investors’ and shareholders’ trust, in addition to other possible data privacy risks. Understanding the industry and the requirements, Q4 sets data privacy and response accuracy as its guiding principles in evaluating any solution before it can be taken to market.
For the proof of concept, Q4 decided to use a financial ownership dataset. The dataset consists of time series data points representing the number of assets owned; the transaction history between investment institutions, individuals, and public companies; and many more elements.
Because Q4 wanted to ensure it could satisfy all the functional and non-functional requirements we’ve discussed, the project also needed to stay commercially feasible. This was respected throughout the process of deciding on the approach, architecture, choice of technology, and solution-specific elements.
Experimentation and challenges
It was clear from the beginning that to understand a human language question and generate accurate answers, Q4 would need to use large language models (LLMs).
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned:
- Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. It quickly became obvious that this approach is resource intensive with many non-trivial steps, such as data preprocessing, training, and evaluation. In addition to the effort involved, it would be cost prohibitive. Considering the nature of the time series dataset, Q4 also realized that it would have to continuously perform incremental pre-training as new data came in. This would have required a dedicated cross-disciplinary team with expertise in data science, machine learning, and domain knowledge.
- Fine-tuning – Fine-tuning a pre-trained foundation model (FM) involved using several labeled examples. This approach showed some initial success, but in many cases, model hallucination was a challenge. The model struggled to understand nuanced contextual cues and returned incorrect results.
- RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation. The team experimented with using search, semantic search, and embeddings to extract context. During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The retrieved context in any of the three experiments was then used to augment the original prompt as an input to the LLM. This approach worked well for text-based content, where the data consists of natural language with words, sentences, and paragraphs. Considering the nature of Q4’s dataset, which is mostly financial data consisting of numbers, financial transactions, stock quotes, and dates, the results in all three cases were suboptimal. Even when using embeddings, the embeddings generated from numbers struggled with similarity ranking, and in many cases led to retrieving incorrect information.
Q4’s conclusion: Generating SQL is the path forward
Considering the challenges faced using conventional RAG methodology, the team started to consider SQL generation. The idea was to use the LLM to first generate a SQL statement from the user question, presented to the LLM in natural language. The generated query is then run against the database to fetch the relevant context. The context is finally used to augment the input prompt for a summarization step.
Q4’s hypothesis was that in order to get higher recall for the retrieval step, specifically for the numerical dataset, they needed to first generate SQL from the user question. This was believed to not only increase accuracy, but also keep the context within the business domain for a given question. For the query generation, and to generate accurate SQL, Q4 needed to make the LLM fully context aware of their dataset structure. This meant the prompt needed to include the database schema, a few sample data rows, and human-readable field explanations for the fields that are not easy to comprehend.
Based on the initial tests, this method showed great results. The LLM equipped with all the necessary information was able to generate the correct SQL, which was then run against the database to retrieve the correct context. After experimenting with the idea, Q4 decided that SQL generation was the way forward to address context extraction challenges for their own specific dataset.
Let’s start with describing the overall solution approach, break it down to its components, and then put the pieces together.
Solution overview
LLMs are large models with billions of parameters that are pre-trained using very large amounts of data from a variety of sources. Due to the breadth of the training datasets, LLMs are expected to have general knowledge in a variety of domains. LLMs are also known for their reasoning abilities, which vary from one model to another. This general behavior can be optimized to a specific domain or industry by further optimizing a foundation model using additional domain-specific pre-training data or by fine-tuning using labeled data. Given the right context, metadata, and instructions, a well-selected general purpose LLM can produce good-quality SQL as long as it has access to the right domain-specific context.
In Q4’s use case, we start with translating the customer question into SQL. We do this by combining the user question, database schema, some sample database rows, and detailed instructions as a prompt to the LLM to generate SQL. After we have the SQL, we can run a validation step if deemed necessary. When we’re happy with the quality of the SQL, we run the query against the database to retrieve the relevant context that we need for the following step. Now that we have the relevant context, we can send the user’s original question, the context retrieved, and a set of instructions back to the LLM to produce a final summarized response. The goal of the last step is to have the LLM summarize the results and provide a contextual and accurate answer that can be then passed along to the user.
The choice of LLM used at every stage of the process highly impacts the accuracy, cost, and performance. Choosing a platform or technology that can allow you the flexibility to switch between LLMs within the same use case (multiple LLM trips for different tasks), or across different use cases, can be beneficial in optimizing the quality of the output, latency, and cost. We address the choice of LLM later in this post.
Solution building blocks
Now that we have highlighted the approach at a high level, let’s dive into the details, starting with the solution building blocks.
Amazon Bedrock
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. Amazon Bedrock also offers a broad set of tools that are needed to build generative AI applications, simplify the development process, and maintain privacy and security. In addition, with Amazon Bedrock you can choose from various FM options, and you can further fine-tune the models privately using your own data to align models’ responses with your use case requirements. Amazon Bedrock is fully serverless with no underlying infrastructure to manage extending access to available models through a single API. Lastly, Amazon Bedrock supports several security and privacy requirements, including HIPAA eligibility and GDPR compliance.
In Q4’s solution, we use Amazon Bedrock as a serverless, API-based, multi-foundation model building block. Because we intend to make multiple trips to the LLM within the same use case, based on the task type, we can choose the model that is most optimal for a specific task, be it SQL generation, validation, or summarization.
LangChain
LangChain is an open source integration and orchestration framework with a set of pre-built modules (I/O, retrieval, chains, and agents) that you can use to integrate and orchestrate tasks between FMs, data sources, and tools. The framework facilitates building generative AI applications that require orchestrating multiple steps to produce the desired output, without having to write code from scratch. LangChain supports Amazon Bedrock as a multi-foundation model API.
Specific to Q4’s use case, we use LangChain for coordinating and orchestrating tasks in our workflow, including connecting to data sources and LLMs. This approach has simplified our code because we can use the existing LangChain modules.
SQLDatabaseChain
SQLDatabaseChain is a LangChain chain that can be imported from langchain_experimental. SLDatabaseChain makes it straightforward to create, implement, and run SQL queries, using its effective text-to-SQL conversions and implementations.
In our use case, we use SQLDatabaseChain in the SQL generation, simplifying and orchestrating interactions between the database and the LLM.
The dataset
Our structured dataset can reside in a SQL database, data lake, or data warehouse as long as we have support for SQL. In our solution, we can use any dataset type with SQL support; this should be abstracted from the solution and shouldn’t change the solution in any way.
Implementation details
Now that we have explored the solution approach, solution components, the choice of technology, and tools, we can put the pieces together. The following diagram highlights the end-to-end solution.
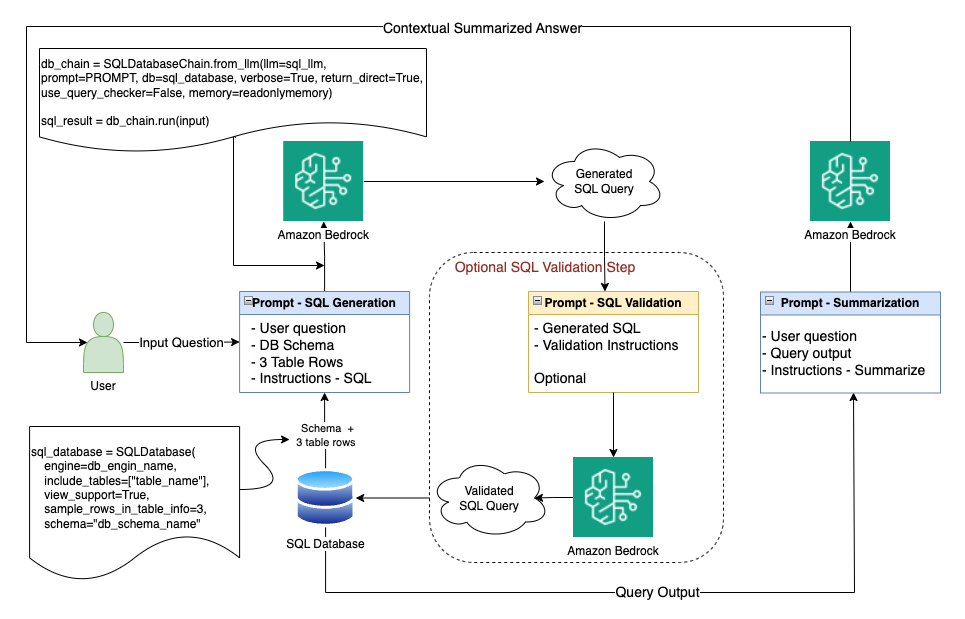
Let’s walk through the implementation details and the process flow.
Generate the SQL query
To simplify coding, we use existing frameworks. We use LangChain as an orchestration framework. We start with the input stage, where we receive the user question in natural language.
In this first stage, we take this input and generate an equivalent SQL that we can run against the database for context extraction. To generate SQL, we use SQLDatabaseChain, which relies on Amazon Bedrock for access to our desired LLM. With Amazon Bedrock, using a single API, we get access to a number of underlying LLMs and can pick the right one for each LLM trip we make. We first establish a connection to the database and retrieve the required table schema along with some sample rows from the tables we intend to use.
In our testing, we found 2–5 rows of table data to be sufficient to give enough information to the model without adding too much unnecessary overhead. Three rows were just enough to provide context, without overwhelming the model with too much input. In our use case, we started with Anthropic Claude V2. The model is known for its advanced reasoning and articulate contextual responses when provided with the right context and instructions. As part of the instructions, we can include more clarifying details to the LLM. For example, we can describe that column Comp_NAME stands for the company name. We now can construct the prompt by combining the user question as is, the database schema, three sample rows from the table we intend to use, and a set of instructions to generate the required SQL in clean SQL format without comments or additions.
All the input elements combined are considered as the model input prompt. A well-engineered input prompt that is tailored to the model’s preferred syntax highly impacts both the quality and performance of the output. The choice of model to use for a specific task is also important, not only because it impacts the output quality, but also because it has cost and performance implications.
We discuss model selection and prompt engineering and optimization later in this post, but it’s worth noting that for the query generation stage, we noticed that Claude Instant was able to produce comparable results, especially when the user question is well phrased and not as sophisticated. However, Claude V2 produced better results even with more complex and indirect user input. We learned that although in some cases Claude Instant may provide sufficient accuracy at a better latency and price point, our case for query generation was better suited for Claude V2.
Verify the SQL query
Our next step is to verify that the LLM has successfully generated the right query syntax and that the query makes contextual sense considering the database schemas and the example rows provided. For this verification step, we can revert to native query validation within SQLDatabaseChain, or we can run a second trip to the LLM including the query generated along with validation instruction.
If we use an LLM for the validation step, we can use the same LLM as before (Claude V2) or a smaller, more performant LLM for a simpler task, such as Claude Instant. Because we’re using Amazon Bedrock, this should be a very simple adjustment. Using the same API, we can change the model name in our API call, which takes care of the change. It’s important to note that in most cases, a smaller LLM can provide better efficiency in both cost and latency and should be considered—as long as you’re getting the accuracy desired. In our case, testing proved the query generated to be consistently accurate and with the right syntax. Knowing that, we were able to skip this validation step and save on latency and cost.
Run the SQL query
Now that we have the verified SQL query, we can run the SQL query against the database and retrieve the relevant context. This should be a straightforward step.
We take the generated context, provide it to the LLM of our choice with the initial user question and some instruction, and ask the model to generate a contextual and articulate summary. We then present the generated summary to the user as an answer to the initial question, all aligned with the context extracted from our dataset.
For the LLM involved in the summarization step, we can use either Titan Text Express or Claude Instant. They would both present good options for the summarization task.
Application integration
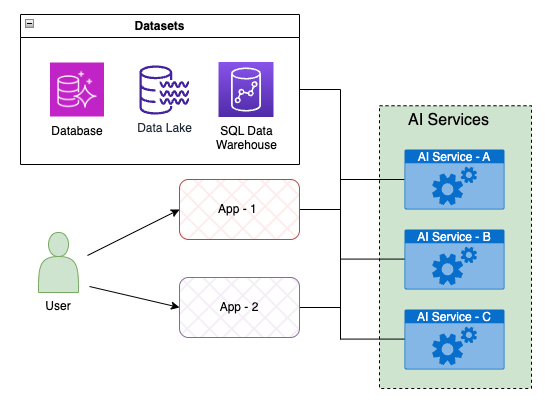
The Q&A chatbot capability is one of Q4’s AI services. To ensure modularity and scalability, Q4 builds AI services as microservices that are accessible to Q4 applications through APIs. This API-based approach enables seamless integration with the Q4 Platform ecosystem and facilitates exposing the AI services’ capabilities to the full suite of platform applications.
The main objective of the AI services is to provide straightforward capabilities for retrieving data from any public or proprietary data source using natural language as input. In addition, the AI services provide additional layers of abstraction to ensure that functional and non-functional requirements, such as data privacy and security are met. The following diagram demonstrates the integration concept.
Implementation challenges
In addition to the challenges presented by the nature of the structured, numerical dataset that we discussed earlier, Q4 was faced with a number of other implementation challenges that needed to be addressed.
LLM selection and performance
Selecting the right LLM for the task is crucial because it directly impacts the quality of output as well as the performance (round trip latency). Here are some factors that play into the LLM selection process:
- Type of LLM – The way the FMs are architected and the initial data the model has been pre-trained on determines the types of tasks the LLM would be good at and how good it will be. For example, a text LLM would be good at text generation and summarization, whereas a text-to-image or image-to-text model would be more geared towards image analytics and generation tasks.
- LLM size – FM sizes are measured by the number of model parameters a particular model has, typically in billions for modern LLMs. Typically, the larger the model, the more expensive to initially train or subsequently fine-tune. On the other hand, in general, for the same model architecture, the larger the model is, the smarter we expect it to be in performing the type of task it is geared towards.
- LLM performance – Typically, the larger the model, the more time it takes to generate output, assuming you’re using the same compute and I/O parameters (prompt and output size). In addition, for the same model size, performance is highly impacted by how optimized your prompt is, the size of the I/O tokens, and the clarity and syntax of the prompt. A well-engineered prompt, along with an optimized I/O token size, can improve the model response time.
Therefore, when optimizing your task, consider the following best practices:
- Choose a model that is suitable for the task at hand
- Select the smallest model size that can produce the accuracy you’re looking for
- Optimize your prompt structure and be as specific as possible with the instructions in a way that is easy for the model to understand
- Use the smallest input prompt that can provide enough instruction and context to produce the accuracy level you’re looking for
- Limit the output size to the smallest size that can be meaningful for you and satisfy your output requirements
Taking the model selection and performance optimization factors into account, we went to work to optimize our SQL generation use case. After some testing, we noticed that, provided we have the right context and instructions, Claude Instant, with the same prompt data, would produce comparable quality of SQL as Claude V2 at a much better performance and price point. This stands true when the user input is more direct and simpler in nature. For more sophisticated input, Claude V2 was necessary to produce the desired accuracy.
Applying the same logic on the summarization task led us to conclude that using Claude Instant or Titan Text Express would produce the accuracy required at a much better performance point than if we use a larger model such as Claude V2. Titan Text Expressed also offered better price-performance, as we discussed earlier.
The orchestration challenge
We realized that there is a lot to orchestrate before we can get a meaningful output response for the user question. As shown in the solution overview, the process involved multiple database trips and multiple LLM trips that are intertwined. If we were to build from scratch, we would have had to make a significant investment in the undifferentiated heavy lifting just to get the basic code ready. We quickly pivoted to using LangChain as an orchestration framework, taking advantage of the power of the open source community, and reusing existing modules without reinventing the wheel.
The SQL challenge
We also realized that generating SQL is not as simple as context extraction mechanisms like semantic search or using embeddings. We need to first get the database schema and a few sample rows to include in our prompt to the LLM. There is also the SQL validation stage, where we needed to interact with both the database and the LLM. SQLDatabaseChain was the obvious choice of tool. Because it’s part of LangChain, it was straightforward to adapt, and now we can manage the SQL generation and verification assisted with the chain, minimizing the amount of work we needed to do.
Performance challenges
With the use of Claude V2, and after proper prompt engineering (which we discuss in the next section), we were able to produce high-quality SQL. Considering the quality of the SQL generated, we started to look at how much value the validation stage is actually adding. After further analyzing the results, it became clear that the quality of the SQL generated was consistently accurate in a way that made the cost/benefit of adding an SQL validation stage unfavorable. We ended up eliminating the SQL validation stage without negatively impacting the quality of our output and shaved off the SQL validation round trip time.
In addition to optimizing for a more cost- and performance-efficient LLM for the summarization step, we were able to use Titan Text Express to get better performance and cost-efficiency.
Further performance optimization involved fine-tuning the query generation process using efficient prompt engineering techniques. Rather than providing an abundance of tokens, the focus was on providing the least amount of input tokens, in the right syntax that the model is trained to understand, and with the minimal yet optimal set of instructions. We discuss this more in the next section—it’s an important topic that is applicable not only here but also in other use cases.
Prompt engineering and optimization
You can adjust Claude on Amazon Bedrock for various business use cases if the right prompt engineering techniques are employed. Claude mainly acts as a conversational assistant that utilizes a human/assistant format. Claude is trained to fill in text for the assistant role. Given the instructions and prompt completions desired, we can optimize our prompts for Claude using several techniques.
We start with a proper formatted prompt template that gives a valid completion, then we can further optimize the responses experimenting with prompting with various sets of inputs that are representative of real-world data. It’s recommended to get many inputs while developing a prompt template. You can also use separate sets of prompt development data and test data.
Another way to optimize the Claude response is to experiment and iterate by adding rules, instructions, and useful optimizations. From these optimizations, you can view different types of completions by, for example, telling Claude to mention “I don’t know” to prevent hallucinations, thinking step by step, using prompt chaining, giving room to “think” as it generates responses, and double-checking for comprehension and accuracy.
Let’s use our query generation task and discuss some of the techniques we used to optimize our prompt. There were a few core elements that benefited our query generation efforts:
- Using the proper human/assistant syntax
- Utilizing XML tags (Claude respects and understands XML tags)
- Adding clear instructions for the model to prevent hallucination
The following generic example shows how we used the human/assistant syntax, applied XML tags, and added instructions to restrict the output to SQL and instruct the model to say “sorry, I am unable to help” if it can’t produce relevant SQL. The XML tags were used to frame the instructions, additional hints, database schema, additional table explanations, and example rows.
The final working solution
After we had addressed all the challenges identified during the proof of concept, we had fulfilled all the solution requirements. Q4 was satisfied with the quality of the SQL generated by the LLM. This stands true for simple tasks that required only a WHERE clause to filter the data, and also with more complex tasks that required context-based aggregations with GROUP BY and mathematical functions. The end-to-end latency of the overall solution came within what was defined as acceptable for the use case—single-digit seconds. This was all thanks to the choice of an optimal LLM at every stage, proper prompt engineering, eliminating the SQL verification step, and using an efficient LLM for the summarization step (Titan Text Express or Claude Instant).
It’s worth noting that using Amazon Bedrock as a fully managed service and the ability to have access to a suite of LLMs through the same API allowed for experimentation and seamless switching between LLMs by changing the model name in the API call. With this level of flexibility, Q4 was able to choose the most performant LLM for each LLM call based on the nature of the task, be it query generation, verification, or summarization.
Conclusion
There is no one solution that fits all use cases. In a RAG approach, the quality of the output highly depends on providing the right context. Extracting the right context is key, and every dataset is different with its unique characteristics.
In this post, we demonstrated that for numerical and structured datasets, using SQL to extract the context used for augmentation can lead to more favorable results. We also demonstrated that frameworks like LangChain can minimize the coding effort. Additionally, we discussed the need to be able to switch between LLMs within the same use case in order to achieve the most optimal accuracy, performance, and cost. Finally, we highlighted how Amazon Bedrock, being serverless and with a variety of LLMs under the hood, provides the flexibility needed to build secure, performant, and cost-optimized applications with the least amount of heavy lifting.
Start your journey towards building generative AI-enabled applications by identifying a use case of value to your business. SQL generation, as the Q4 team learned, can be a game changer in building smart applications that integrate with your data stores, unlocking revenue potential.
About the authors
 Tamer Soliman is a Senior Solutions Architect at AWS. He helps Independent Software Vendor (ISV) customers innovate, build, and scale on AWS. He has over two decades of industry experience in consulting, training, and professional services. He is a multi patent inventor with three granted patents and his experience spans multiple technology domains including telecom, networking, application integration, AI/ML, and cloud deployments. He specializes in AWS Networking and has a profound passion for machine leaning, AI, and Generative AI.
Tamer Soliman is a Senior Solutions Architect at AWS. He helps Independent Software Vendor (ISV) customers innovate, build, and scale on AWS. He has over two decades of industry experience in consulting, training, and professional services. He is a multi patent inventor with three granted patents and his experience spans multiple technology domains including telecom, networking, application integration, AI/ML, and cloud deployments. He specializes in AWS Networking and has a profound passion for machine leaning, AI, and Generative AI.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book – Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning (ML) projects in various domains such as computer vision, natural language processing and generative AI. She helps customers to build, train and deploy large machine learning models at scale. She speaks in internal and external conferences such re:Invent, Women in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book – Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning (ML) projects in various domains such as computer vision, natural language processing and generative AI. She helps customers to build, train and deploy large machine learning models at scale. She speaks in internal and external conferences such re:Invent, Women in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for long runs along the beach.
 Stanislav Yeshchenko is a Software Architect at Q4 Inc.. He has over a decade of industry experience in software development and system architecture. His diverse background spanning roles such as Technical Lead and Senior Full Stack Developer, powers his contributions to advancing innovation of the Q4 Platform. Stanislav is dedicated to driving technical innovation and shaping strategic solutions in the field.
Stanislav Yeshchenko is a Software Architect at Q4 Inc.. He has over a decade of industry experience in software development and system architecture. His diverse background spanning roles such as Technical Lead and Senior Full Stack Developer, powers his contributions to advancing innovation of the Q4 Platform. Stanislav is dedicated to driving technical innovation and shaping strategic solutions in the field.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/how-q4-inc-used-amazon-bedrock-rag-and-sqldatabasechain-to-address-numerical-and-structured-dataset-challenges-building-their-qa-chatbot/

