What is RAG?
Here’s the simple 30 second definition, A deeper dive will follow.
RAG (Retrieval Augmented Generation) is the buzziest word on the GenAI right now, more jargon to confuse the uninitiated.
RAG, stands for retrieval augmented generation. It simpy means you can apply and RETRIEVE knowledge in front of the LLM, to AUGMENT your LLM prompt and its response. This way, you can help give guardrails (more jargon) against out-of-date responses and deploy your enterprise (private) knowledge store with security.
What is the problem RAG solves?
The large language models – or foundation models (yes, there’s a difference. Foundation models include language models but also other types of models, e.g. imagery) are “pre trained,” what some describe beautifully as stochastic parrots Think “pre-trained” in GPT, the model that powers ChatGPT – GPT stands for “Generative Pre-trained Transformer. Pre-trained means static, moment-in-time training. It’s why when you ask the model “what price is Share X trading at?,” it won’t know because the information is too new, and worse still, it might not know what it doesn’t know so worst case will hallucinate. Now, I’m stretching a point – ChatGPT will tell you that it doesn’t know the latest price – it is trained to know that the information being asked for is too immediate and it will tell you to find another way. However, the point is that philosophically speaking LLMs don’t have epistemological boundaries. There are many instances that they don’t know what they don’t know. RAG can allow you to wrap your boundaries around the missing LLM boundaries.
On the subject of jargon around human/tech interfaces and consciousness, I find “knowledge store” a particularly interesting term increasingly used in GenAI conversations. It basically means a technical database or a vector store, most likely a “vector database”, but note how the term tries to bring humanity – knowledge, knowledge in a store, like those stores you read about in Stephen King horror novels – to a automated technical construct. Marketing and subjective semantics in a nutshell.
Where’s that Deeper Dive You Promised?
Here’s a diagram of RAG.
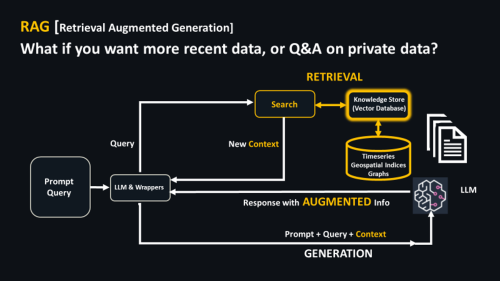
Note the sequential process, top to bottom, in the diagram. There are two key parts.
- RETRIEVAL: Put a knowledge store with search (some sort of vector database or store) in front of the LLM. When you query, the vector database helps ascertain if it has relevant information, let’s say up-to-date financial information which the LLM likely won’t have.
- This informs a prompt which AUGMENTS additional VectorDB/Knowledge Store information, that bit of your enterprise or the new bit of information which the LLM doesn’t know. In conjunction with the LLM’s “knowledge,” comprehensive content
GENERATION gets returned.
Why Now?
And that sequencing kind of explains why it’s the all the buzz. The term, RAG, originated in about 2020 I think in
this paper from Lewis et al. However, until about three months ago was not part part of the lexicon, certainly like it is today. My Google adwords dashboard shows 900% increase over the last 3 months and 9900% over 3 years. What’s likely the instigator is a tool called
LangChain which is all the rage in the GenAI circles, a development environment for LLM architectures. For those of you with a software background, think if it as a VS Code for GenAI. The relevance of RAG is as being part of the “Chain” of LangChain (while Lang = Language). Given the sequential chain-like nature of RAG described earlier, RAG slots into the tooling beautifully.
Where will RAG be deployed and how is it being deployed?
As described, it overcomes some pretty fundamental limitations of LLMs and Foundation Models, so it has pretty ubiquitous applicability. However, it is already having impact in industries:
- driven by time and real-time – think capital markets
- regulated, because they cannot go wrong and need controls of response, I’ll use the word “guardrails,” for largely public-facing and risk-impacting enterprise processes. Think legal services, Government applications (the US DoD has already produced docs and presentations), possibly healthcare.
- that require (up-to-the-minute) enterprise knowledge – that’s pretty much anything in reality but think retail and e-commerce for example.
Anywhere where all three requirements come together, think the legal services division running up-to-the-minute contracts in a regulated financial services industry, and that’s your sweet spot.
This is also where, reputable sources tell me, deployments are already active of RAG infrastructures, contract summarization, report summarization and related chatbot activities. I’ve argued elsewhere for
“golden” use cases
here and how to deploy them robustly and with stickiness here. These golden use cases typically combine Generative AI and Discriminative AI, the “discriminative” in latter meaning the AI that’s been done for years, for example the machine learning that determines your credit card rating and that identifies when your credit provider rings you with a suspicion around fraudulent use of your card. In my experience, those fraud phone calls are typically those you get on a Saturday or Sunday morning when traveling abroad somewhere new. Such golden use cases are being worked on and will land somewhere near you soon, the first simply with chat interfaces around traditional problems, and in more advanced fashion with incremental analytics deployed via both types of AI.
What tools do I need for RAG?
RAG is the new primary reason for deploying a vector database, a store of searchable knowledge in vector form. Vectors have been around for years, both mathematical vectors (measures of distance) and vectors-as-arrays-of-numbers (think of a daily time-series of a stock). By search, think of those brute force search methods that you’ve used for years, when you search in Google for example. Search algorithms got popularized by the
Apache Lucene library, commonly implemented in tools like Elasticsearch and Solr, and they’re finding
a new lease of life in conjunction with the vector databases or vector stores.
I use the term vector stores because for some instances, it doesn’t need to be a vector database. Vectors can be stored in any applicable high-level mathematical programming language that handles memory and can deploy search relatively well (better, some would say). That includes Python/NumPy/Pandas, Julia, MATLAB, q or R for example. I was on a call last week where someone alluded to their homebrew Pandas vector store, not an industrial scale application but something to kick start a project before migrating to a vector database.
I’ve been waiting to hear the Python thing for some time, and to be sure GenAI is Pythonic (see the LangChain link above, for example). The numerical programming vendors and supporters have been politely quiet while every data vendor has screamed from the rooftops “we’re a vector database”. Rockset at their Index Conference last week announced they were now a vector database and alongside Rockset, the bevvy of multimodal databases – Datastax (Cassandra), KDB.AI, the graph databases, Redis Labs – is now beginning to outnumber the specialist new vector database kids – Qdrant, Pinecone, Weaviate. For me, how MathWorks, JuliaHub and Anaconda approach this market could define the next generation of this industry. Much easier to get started at least with a commodity multi-purpose vector-friendly math tool every data scientist knows, then migrate to a fully fledged vector database powerhouse.
Does RAG deserve the hype?
Most people I speak too, even those commonly skeptical of jargon, get RAG. It’s a simple, standard way of getting enterprise and up-to-the-minute control of foundation model prompts. I suspect it’s not going away soon.
However, I’ve started to see instances where Silicon Valley firms used the phrase “reduce to RAG”, or “reduce machine learning problems to a search problem.” It’s almost too tempting to throw anything and everything into a RAG/foundation model GenAI search process, but there are instances where traditional AI does better. The blogosphere is not talking about this, but I saw leaders at 3 high tech Silicon Valley leaders discuss this last week. Where Silicon valley discusses on the circuit, banking leaders discuss privately, away from prying eyes and ears like mine. It’s one reason why discriminative AI, which I alluded to earlier, matters. Infrastructures that apply both will serve more use cases than those which deploy brute force RAG. Traditional machine learning is not done for, yet, far from it.
I also heard a case made that the very largest firms will maintain their own LLMs and foundation models in order to get around the enterprise, time and privacy problem. so modeling and training is also not yet done for. This is why Databricks bought Mosaic, it transpires. The AWS work with Bedrock and open source foundation models is also interesting. Data scientists will, it seems, get to keep some of the work that kept them busy before BigCorp trained the biggest models for us. In other words, some parts of RAG effort may get superceded by model development at the biggest firms, but I suspect this will be a partial pushback only.
Finally, RAG too has known limits. Common challenges include:
- having performant similarity search,
- the ability to add/delete documents
- ensuring the veracity and timelinesss – or newness – of data
- incorporating key data types in an optimal way, time-series, (relational) directed graph information for example (those of us in vectorized time-series and graph ecosystems are positive; it’s an opportunity)
But new challenges are also getting raised, predominantly around performance and compute. For example:
- chunking documents before inputting to vector databases (where documents are needed)
- returning suitably “diverse” chunks (alleviating the stochastic parrot problem)
- running sequential queries, chaining
- embedding functions may change; how do you manage changes without re-embedding all inputs.
- The
environmental (and geopolitcal) impacts about, well, everything to do with staggeringly massive compute requirements.
In Conclusion
RAG, like much of the GenAI technobabble, is jargon. However, it sensibly and clearly shows how you can add a level of control, aka
retrieve useful information, to augment and
generate LLM/Foundation model prompts and output. Ecosystems and tooling are developing and evolving rapidly around the nomenclature.
However, it’s still early days. What will be the buzz term in three months time?
I suspect we’re going to see a stream of environmental consciousness come across the industry as the impacts of large model compute and consumption, and possibly an international conflict or two, get realized.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.finextra.com/blogposting/25150/from-rag-to-riches-in-a-genai-world-some-jargon-explainers-amp-current-trends?utm_medium=rssfinextra&utm_source=finextrablogs

