ZOO digitaalinen tarjoaa päästä päähän lokalisointi- ja mediapalveluita alkuperäisen TV- ja elokuvasisällön mukauttamiseen eri kielille, alueille ja kulttuureille. Se helpottaa globalisaatiota maailman parhaiden sisällöntuottajien kannalta. Viihteen suurimpien nimien luottama ZOO Digital tarjoaa korkealaatuisia lokalisointi- ja mediapalveluita laajassa mittakaavassa, mukaan lukien jälkiäänitys, tekstitys, komentosarjat ja vaatimustenmukaisuus.
Tyypilliset lokalisointityönkulut edellyttävät kaiuttimen manuaalista diaarisointia, jolloin äänivirta segmentoidaan kaiuttimen identiteetin perusteella. Tämä aikaa vievä prosessi on suoritettava loppuun, ennen kuin sisältöä voidaan kopioida toiselle kielelle. Manuaalisilla menetelmillä 30 minuutin jakson paikantaminen voi kestää 1–3 tuntia. Automaation avulla ZOO Digital pyrkii lokalisointiin alle 30 minuutissa.
Tässä viestissä keskustelemme skaalautuvien koneoppimismallien (ML) käyttöönotosta mediasisällön päiväkirjaamiseen Amazon Sage Maker, jossa keskitytään WhisperX malli.
Tausta
ZOO Digitalin visiona on tarjota lokalisoidun sisällön nopeampi käsittely. Tämän tavoitteen pullonkaulaa tekee harjoituksen manuaalisesti intensiivinen luonne yhdistettynä siihen, että ammattitaitoisten ihmisten pieni työvoima pystyy lokalisoimaan sisällön manuaalisesti. ZOO Digital työskentelee yli 11,000 600 freelancerin kanssa ja lokalisoi yli 2022 miljoonaa sanaa pelkästään vuonna XNUMX. Ammattitaitoisten ihmisten tarjonta kuitenkin ylittää sisällön kasvavan kysynnän, mikä edellyttää automaatiota lokalisoinnin työnkuluissa.
Tavoitteena on nopeuttaa sisällön työnkulkujen lokalisointia koneoppimisen avulla. ZOO Digital otti käyttöön AWS Prototypingin, AWS:n investointiohjelman, jonka tarkoituksena on rakentaa työkuormia yhdessä asiakkaiden kanssa. Toimeksiannossa keskityttiin toimittamaan toiminnallinen ratkaisu lokalisointiprosessiin ja tarjoamaan samalla käytännön koulutusta ZOO Digital -kehittäjille SageMakerissa, Amazonin transkriptioja Amazon Käännä.
Asiakkaan haaste
Kun nimi (elokuva tai TV-sarjan jakso) on litteroitu, jokaiselle puheosalle on määritettävä kaiuttimet, jotta ne voidaan määrittää oikein äänitaiteilijoille, jotka on valettu näyttelemään hahmoja. Tätä prosessia kutsutaan puhujan päiväkirjaksi. ZOO Digitalin haasteena on päivittää sisältöä suuressa mittakaavassa ja olla samalla taloudellisesti kannattavaa.
Ratkaisun yleiskatsaus
Tässä prototyypissä tallensimme alkuperäiset mediatiedostot määritettyyn paikkaan Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ämpäri. Tämä S3-säilö on määritetty lähettämään tapahtuma, kun siinä havaitaan uusia tiedostoja, jotka laukaisevat tapahtuman AWS Lambda toiminto. Katso ohjeet tämän liipaisimen määrittämisestä opetusohjelmasta Amazon S3 -laukaisimen käyttäminen Lambda-toiminnon käynnistämiseen. Myöhemmin Lambda-funktio kutsui SageMaker-päätepisteen päättelemiseksi käyttämällä Boto3 SageMaker Runtime -asiakas.
- WhisperX malliin perustuva OpenAI:n Whisper, suorittaa mediasisällön transkriptioita ja päiväkirjaa. Se on rakennettu päälle Nopeampi kuiskaus uudelleentoteutus, joka tarjoaa jopa neljä kertaa nopeamman transkription ja parannetun sanatason aikaleiman kohdistuksen Whisperiin verrattuna. Lisäksi se ottaa käyttöön kaiuttimen diarisoinnin, jota ei ole alkuperäisessä Whisper-mallissa. WhisperX käyttää Whisper-mallia transkriptioissa Wav2Vec2 malli parantaa aikaleiman kohdistusta (varmistaa litteroidun tekstin synkronoinnin ääniaikaleimojen kanssa) ja pyannote malli päiväkirjaan. FFmpeg käytetään äänen lataamiseen lähdemediasta, joka tukee erilaisia mediamuodot. Läpinäkyvä ja modulaarinen malliarkkitehtuuri mahdollistaa joustavuuden, koska jokainen mallin komponentti voidaan vaihtaa tarpeen mukaan tulevaisuudessa. On kuitenkin tärkeää huomata, että WhisperX:stä puuttuu kaikki hallintaominaisuudet, eikä se ole yritystason tuote. Ilman huoltoa ja tukea se ei välttämättä sovellu tuotantokäyttöön.
Tässä yhteistyössä otimme käyttöön ja arvioimme WhisperX:n SageMakerissa käyttämällä asynkronisen päättelyn päätepiste isännöidä mallia. SageMakerin asynkroniset päätepisteet tukevat jopa 1 Gt:n latauskokoja ja sisältävät automaattisia skaalausominaisuuksia, jotka vähentävät tehokkaasti liikennepiikkejä ja säästävät kustannuksia ruuhka-aikojen ulkopuolella. Asynkroniset päätepisteet sopivat käyttötapauksessamme erityisen hyvin suurten tiedostojen, kuten elokuvien ja TV-sarjojen, käsittelyyn.
Seuraava kaavio havainnollistaa tässä yhteistyössä tekemiemme kokeiden ydinelementtejä.

Seuraavissa osioissa perehdymme WhisperX-mallin käyttöönoton yksityiskohtiin SageMakerissa ja arvioimme diarisoinnin suorituskykyä.
Lataa malli ja sen osat
WhisperX on järjestelmä, joka sisältää useita malleja transkriptiota, pakotettua kohdistusta ja diarisointia varten. Jotta SageMaker toimii sujuvasti ilman, että mallin artefakteja tarvitsee hakea päättelyn aikana, on välttämätöntä ladata kaikki malliesineet. Nämä artefaktit ladataan sitten SageMaker-annostelusäiliöön aloituksen aikana. Koska nämä mallit eivät ole suoraan käytettävissä, tarjoamme WhisperX-lähteestä peräisin olevia kuvauksia ja esimerkkikoodia, joka sisältää ohjeet mallin ja sen komponenttien lataamiseen.
WhisperX käyttää kuutta mallia:
Suurin osa näistä malleista on saatavilla Halaaminen kasvot käyttämällä huggingface_hub-kirjastoa. Käytämme seuraavaa download_hf_model() toiminto noutaa nämä malliesineet. Hugging Facen käyttöoikeustunnus, joka luodaan seuraavien pyannote-mallien käyttäjäsopimusten hyväksymisen jälkeen, vaaditaan:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
VAD-malli haetaan Amazon S3:sta ja Wav2Vec2-malli torchaudio.pipelines-moduulista. Seuraavan koodin perusteella voimme hakea kaikki mallien artefaktit, mukaan lukien Hugging Facesta, ja tallentaa ne määritettyyn paikalliseen mallihakemistoon:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Valitse mallin palvelemiseen sopiva AWS Deep Learning Container
Kun mallin artefaktit on tallennettu käyttämällä edellistä esimerkkikoodia, voit valita valmiiksi rakennetun AWS Deep Learning Containers (DLC:t) seuraavista GitHub repo. Kun valitset Docker-kuvan, ota huomioon seuraavat asetukset: kehys (hugging Face), tehtävä (päätelmä), Python-versio ja laitteisto (esimerkiksi GPU). Suosittelemme seuraavan kuvan käyttöä: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Tässä kuvassa on valmiiksi asennettuna kaikki tarvittavat järjestelmäpaketit, kuten ffmpeg. Muista korvata [REGION] käyttämäsi AWS-alue.
Luo muita vaadittavia Python-paketteja varten a requirements.txt tiedosto, jossa on luettelo paketeista ja niiden versioista. Nämä paketit asennetaan, kun AWS DLC rakennetaan. Seuraavat ovat lisäpaketit, joita tarvitaan WhisperX-mallin isännöimiseen SageMakerissa:
Luo päättelykomentosarja mallien lataamiseksi ja päättelyn suorittamiseksi
Seuraavaksi luomme mukautetun inference.py komentosarja, joka hahmottaa, kuinka WhisperX-malli ja sen komponentit ladataan säiliöön ja miten päättelyprosessi tulee suorittaa. Skripti sisältää kaksi toimintoa: model_fn ja transform_fn. model_fn toimintoa kutsutaan lataamaan mallit niiden vastaavista paikoista. Myöhemmin nämä mallit siirretään transform_fn toiminto päättelyn aikana, jossa suoritetaan transkriptio-, kohdistus- ja diarisointiprosessit. Seuraava on esimerkki koodista inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Mallin hakemistossa, rinnalla requirements.txt tiedosto, varmista sen olemassaolo inference.py koodialihakemistossa. The models hakemiston tulee olla seuraavanlainen:
Luo malleista tarball
Kun olet luonut mallit ja koodihakemistot, voit käyttää seuraavia komentoriviä pakataksesi mallin tarballiksi (.tar.gz-tiedostoksi) ja ladataksesi sen Amazon S3:een. Kirjoitushetkellä, kun käytetään nopeampaa kuiskausta Large V2 -mallia, tuloksena oleva SageMaker-mallia edustava tarball on kooltaan 3 Gt. Lisätietoja on kohdassa Mallin isännöintimallit Amazon SageMakerissa, osa 2: Reaaliaikaisten mallien käyttöönoton aloittaminen SageMakerissa.
Luo SageMaker-malli ja ota käyttöön päätepiste asynkronisella ennustajalla
Nyt voit luoda SageMaker-mallin, päätepisteen konfiguroinnin ja asynkronisen päätepisteen kanssa AsyncPredictor käyttämällä edellisessä vaiheessa luotua mallia. Katso ohjeet kohdasta Luo asynkroninen päättelypäätepiste.
Arvioi diarisoinnin suorituskykyä
Arvioidaksemme WhisperX-mallin diarisointisuorituskykyä eri skenaarioissa valitsimme kolme jaksoa kahdesta englanninkielisestä nimestä: yksi draamanimi, joka koostuu 30 minuutin jaksoista, ja yksi dokumenttinimi, joka koostuu 45 minuutin jaksoista. Käytimme pyannoten metriikkatyökalupakkia, pyannote.metrics, laskea diarisation error rate (DER). Arvioinnissa ZOO:n toimittamat manuaalisesti litteroidut ja päiväkirjalliset transkriptit toimivat pohjatotuutena.
Määritimme DER:n seuraavasti:
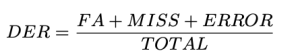
Yhteensä on maan totuuden videon pituus. FA (Väärä hälytys) on niiden segmenttien pituus, joita pidetään puheena ennusteissa, mutta ei pohjatotuuksissa. neiti on niiden segmenttien pituus, joita pidetään puheena pohjatotuudessa, mutta ei ennustuksessa. Virhe, Jota kutsutaan myös Sekaannus, on niiden segmenttien pituus, jotka on määritetty eri kaiuttimille ennustuksessa ja totuuden perusteella. Kaikki yksiköt mitataan sekunneissa. DER:n tyypilliset arvot voivat vaihdella tietyn sovelluksen, tietojoukon ja diarisointijärjestelmän laadun mukaan. Huomaa, että DER voi olla suurempi kuin 1.0. Alempi DER on parempi.
Jotta tietovälineen DER-arvo voidaan laskea, tarvitaan perustotuuspäiväkirjaus sekä WhisperX-transkriptio- ja päiväkirjatulosteet. Nämä on jäsennettävä, ja tuloksena on luettelo monista, jotka sisältävät puhujatunnisteen, puhesegmentin aloitusajan ja puhesegmentin päättymisajan jokaiselle median puhesegmentille. Kaiutinmerkintöjen ei tarvitse vastata WhisperX:n ja maan totuusdiarisaatioiden välillä. Tulokset perustuvat pääosin segmenttien aikaan. pyannote.metrics ottaa nämä joukot perustotuusdiarisaatioita ja lähtödiarisaatioita (viitataan pyannote.metrics-dokumentaatiossa nimellä viite ja hypoteesi) laskeaksesi DER-arvon. Seuraavassa taulukossa on yhteenveto tuloksistamme.
| Videotyyppi | DER | Oikea | neiti | Virhe | Väärä hälytys |
| Draama | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Dokumenttielokuva | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Keskimäärin | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Nämä tulokset paljastavat merkittävän suorituskyvyn eron draaman ja dokumentin otsikoiden välillä, sillä malli saavutti huomattavasti parempia tuloksia (käyttäen DER:tä aggregaattimittarina) draaman jaksoissa verrattuna dokumentin otsikkoon. Nimikkeiden tarkempi analyysi antaa käsityksen mahdollisista tekijöistä, jotka vaikuttavat tähän suorituskykyvajeeseen. Yksi keskeinen tekijä voisi olla usein esiintyvä taustamusiikki, joka on päällekkäinen puheen kanssa dokumentin nimessä. Vaikka median esikäsittely diarisoinnin tarkkuuden parantamiseksi, kuten taustamelun poistaminen puheen eristämiseksi, ei kuulunut tämän prototyypin soveltamisalaan, se avaa mahdollisuuksia tulevalle työlle, joka voisi mahdollisesti parantaa WhisperX:n suorituskykyä.
Yhteenveto
Tässä viestissä tutkimme AWS:n ja ZOO Digitalin välistä yhteistyökumppanuutta käyttämällä koneoppimistekniikoita SageMakerin ja WhisperX-mallin kanssa parantaaksemme diarisointityönkulkua. AWS-tiimillä oli keskeinen rooli auttaessaan ZOO:ta prototyyppien luomisessa, arvioinnissa ja räätälöityjen ML-mallien tehokkaan käyttöönoton ymmärtämisessä, jotka on suunniteltu erityisesti diarisaatioon. Tämä sisälsi automaattisen skaalauksen sisällyttämisen skaalautumiseen SageMakerin avulla.
Tekoälyn hyödyntäminen diarisaatiossa johtaa huomattaviin säästöihin sekä kustannuksissa että ajassa luotaessa lokalisoitua sisältöä ZOO:lle. Tämä tekniikka auttaa kirjoittajia luomaan ja tunnistamaan kaiuttimet nopeasti ja tarkasti, joten se käsittelee tehtävän perinteisesti aikaa vievää ja virhealtista luonnetta. Perinteinen prosessi sisältää usein useita videon läpikulkuja ja ylimääräisiä laadunvalvontavaiheita virheiden minimoimiseksi. Tekoälyn käyttöönotto diarisaatiossa mahdollistaa kohdennetumman ja tehokkaamman lähestymistavan, mikä lisää tuottavuutta lyhyemmässä ajassa.
Olemme hahmotelleet tärkeimmät vaiheet WhisperX-mallin käyttöönottamiseksi asynkronisessa SageMaker-päätepisteessä ja rohkaisemme sinua kokeilemaan sitä itse toimitetun koodin avulla. Lisätietoja ZOO Digitalin palveluista ja teknologiasta on osoitteessa ZOO Digitalin virallinen sivusto. Katso lisätietoja OpenAI Whisper -mallin käyttöönotosta SageMakerissa ja erilaisista päättelyvaihtoehdoista Isännöi Whisper-mallia Amazon SageMakerissa: päättelyvaihtoehtojen tutkiminen. Voit vapaasti jakaa ajatuksesi kommenteissa.
Tietoja Tekijät
 Ying Hou, tohtori, on AWS:n koneoppimisen prototyyppiarkkitehti. Hänen ensisijaisia kiinnostuksen kohteitaan ovat Deep Learning, joka keskittyy GenAI:hen, Computer Visioniin, NLP:hen ja aikasarjatietojen ennustamiseen. Vapaa-ajallaan hän viettää laadukkaita hetkiä perheensä kanssa, uppoutuu romaaneihin ja vaeltelee Ison-Britannian kansallispuistoissa.
Ying Hou, tohtori, on AWS:n koneoppimisen prototyyppiarkkitehti. Hänen ensisijaisia kiinnostuksen kohteitaan ovat Deep Learning, joka keskittyy GenAI:hen, Computer Visioniin, NLP:hen ja aikasarjatietojen ennustamiseen. Vapaa-ajallaan hän viettää laadukkaita hetkiä perheensä kanssa, uppoutuu romaaneihin ja vaeltelee Ison-Britannian kansallispuistoissa.
 Ethan Cumberland on tekoälytutkimusinsinööri ZOO Digitalissa, jossa hän työskentelee tekoälyn ja koneoppimisen käyttämiseksi aputekniikoina puheen, kielen ja lokalisoinnin työnkulkujen parantamiseksi. Hänellä on tausta tietoturva- ja valvonta-alan ohjelmistosuunnittelusta ja tutkimuksesta. Hän keskittyy strukturoidun tiedon poimimiseen verkosta ja hyödyntää avoimen lähdekoodin ML-malleja kerätyn tiedon analysointiin ja rikastamiseen.
Ethan Cumberland on tekoälytutkimusinsinööri ZOO Digitalissa, jossa hän työskentelee tekoälyn ja koneoppimisen käyttämiseksi aputekniikoina puheen, kielen ja lokalisoinnin työnkulkujen parantamiseksi. Hänellä on tausta tietoturva- ja valvonta-alan ohjelmistosuunnittelusta ja tutkimuksesta. Hän keskittyy strukturoidun tiedon poimimiseen verkosta ja hyödyntää avoimen lähdekoodin ML-malleja kerätyn tiedon analysointiin ja rikastamiseen.
 Gaurav Kaila johtaa AWS Prototyping -tiimiä Isossa-Britanniassa ja Irlannissa. Hänen tiiminsä työskentelee asiakkaiden kanssa eri toimialoilla ideoidakseen ja kehittääkseen yhdessä liiketoiminnan kannalta kriittisiä työkuormia, joiden tehtävänä on nopeuttaa AWS-palvelujen käyttöönottoa.
Gaurav Kaila johtaa AWS Prototyping -tiimiä Isossa-Britanniassa ja Irlannissa. Hänen tiiminsä työskentelee asiakkaiden kanssa eri toimialoilla ideoidakseen ja kehittääkseen yhdessä liiketoiminnan kannalta kriittisiä työkuormia, joiden tehtävänä on nopeuttaa AWS-palvelujen käyttöönottoa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

