Käytettäessä suurta kielimallia (LLM) koneoppimisen (ML) harjoittajat huolehtivat yleensä kahdesta mallin suorituskyvyn mittauksesta: latenssista, joka määritellään yhden tunnuksen luomiseen kuluvan ajan mukaan, ja suorituskyvystä, jonka määrittää luotujen tunnisteiden määrä. sekunnissa. Vaikka yksittäinen pyyntö käyttöön otettuun päätepisteeseen vastaisi suunnilleen mallin latenssin käänteisarvoa, näin ei välttämättä ole, kun päätepisteeseen lähetetään samanaikaisesti useita samanaikaisia pyyntöjä. Mallinkäyttötekniikoista, kuten asiakaspuolen samanaikaisten pyyntöjen jatkuvasta erästä johtuen, latenssilla ja suorituskyvyllä on monimutkainen suhde, joka vaihtelee huomattavasti malliarkkitehtuurin, palvelukokoonpanojen, ilmentymän tyypin laitteiston, samanaikaisten pyyntöjen lukumäärän ja syötteiden hyötykuormien vaihteluiden mukaan. syöttö- ja lähtömerkkien lukumääränä.
Tämä viesti tutkii näitä suhteita Amazon SageMaker JumpStartissa saatavilla olevien LLM-yritysten kattavan vertailun avulla, mukaan lukien Llama 2, Falcon ja Mistral. SageMaker JumpStartin avulla ML-harjoittajat voivat valita laajasta valikoimasta julkisesti saatavilla olevia perustusmalleja käytettäväksi omistetuissa Amazon Sage Maker esiintymiä verkosta eristetyssä ympäristössä. Tarjoamme teoreettisia periaatteita siitä, miten kiihdytinmääritykset vaikuttavat LLM-benchmarkingiin. Osoitamme myös useiden esiintymien käyttöönoton vaikutuksen yhden päätepisteen taakse. Lopuksi tarjoamme käytännön suosituksia SageMaker JumpStart -käyttöönottoprosessin räätälöimiseksi vastaamaan vaatimuksiasi viiveen, suorituskyvyn, kustannusten ja käytettävissä olevien ilmentymien tyyppien rajoitusten suhteen. Kaikki benchmarking-tulokset sekä suositukset perustuvat monipuoliseen muistikirja joita voit mukauttaa käyttötilanteeseesi.
Käytetty päätepisteen vertailu
Seuraavassa kuvassa näkyvät pienimmät viiveet (vasemmalla) ja suurimmat suorituskyvyn (oikealla) arvot käyttöönottokokoonpanoissa useissa eri malli- ja ilmentymätyypeissä. Tärkeää on, että jokainen näistä mallin käyttöönotoista käyttää SageMaker JumpStartin toimittamia oletuskokoonpanoja, joissa on haluttu mallin tunnus ja ilmentymän tyyppi käyttöönottoa varten.
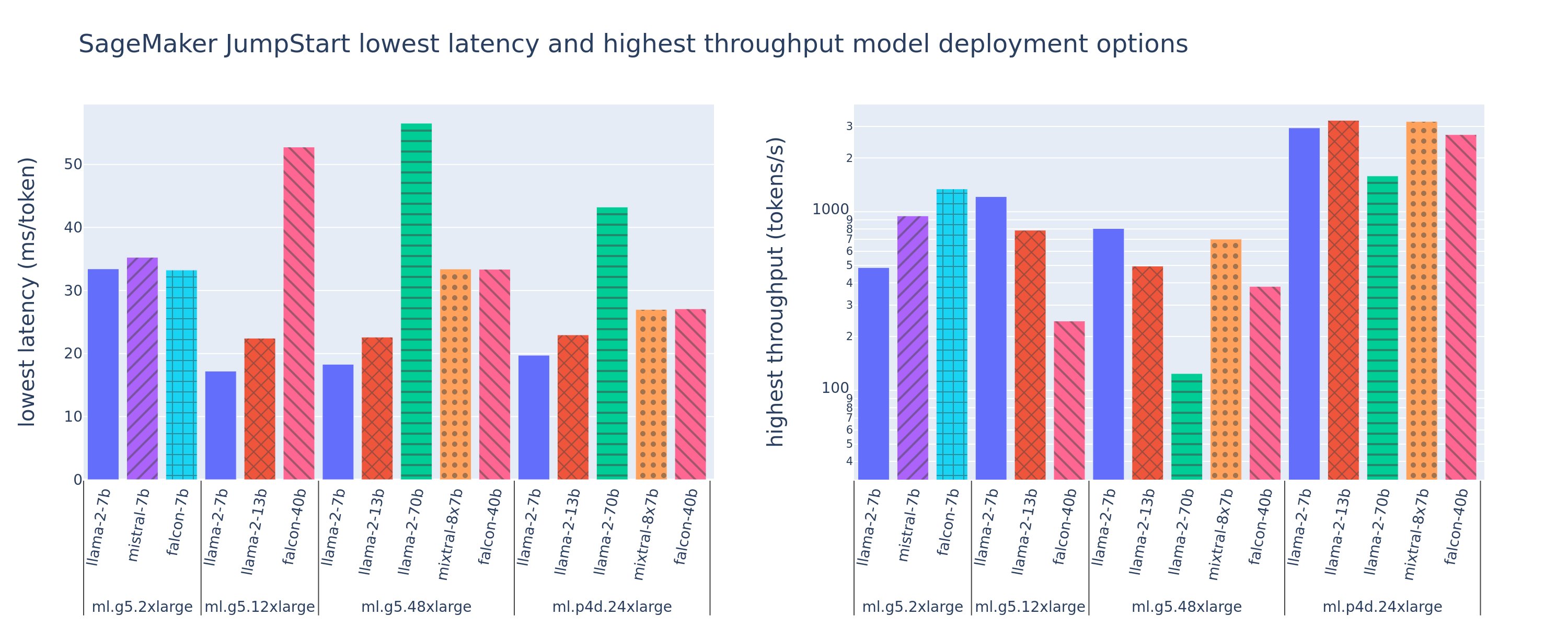
Nämä latenssi- ja suoritustehoarvot vastaavat hyötykuormia, joissa on 256 syöttötunnusta ja 256 lähtötunnusta. Pienin viivemääritys rajoittaa mallin, joka palvelee yhtä samanaikaista pyyntöä, ja suurin suorituskyvyn määritys maksimoi samanaikaisten pyyntöjen mahdollisen määrän. Kuten voimme nähdä vertailussamme, samanaikaisten pyyntöjen lisääntyminen monotonisesti lisää suorituskykyä ja pienenee suurten samanaikaisten pyyntöjen parannusta. Lisäksi mallit ovat täysin sirpaloituja tuettuun ilmentymään. Esimerkiksi koska ml.g5.48xlarge -esiintymässä on 8 grafiikkasuoritinta, kaikki tätä ilmentymää käyttävät SageMaker JumpStart -mallit jaetaan tensorin rinnakkaisuuden avulla kaikissa kahdeksassa käytettävissä olevassa kiihdytinässä.
Voimme huomata muutamia poimintoja tästä luvusta. Ensinnäkin kaikkia malleja ei tueta kaikissa tapauksissa; jotkin pienemmät mallit, kuten Falcon 7B, eivät tue mallien sirpalointia, kun taas suuremmissa malleissa on korkeammat laskentaresurssit. Toiseksi, kun sirpalointi lisääntyy, suorituskyky yleensä paranee, mutta ei välttämättä paranna pienissä malleissa. Tämä johtuu siitä, että pienet mallit, kuten 7B ja 13B, aiheuttavat huomattavia tiedonsiirtokustannuksia, kun niitä jaetaan liian monen kiihdytin välillä. Keskustelemme tästä tarkemmin myöhemmin. Lopuksi ml.p4d.24xlarge-esiintymillä on yleensä huomattavasti parempi suorituskyky, koska A100:n muistin kaistanleveys on parantunut A10G-grafiikkasuorittimiin verrattuna. Kuten kerromme myöhemmin, päätös tietyn ilmentymän tyypin käyttämisestä riippuu käyttöönottovaatimuksistasi, mukaan lukien viiveestä, suorituskyvystä ja kustannusrajoituksista.
Kuinka saat nämä pienimmän latenssin ja suurimman suorituskyvyn määritysarvot? Aloitetaan piirtämällä latenssi vs. suorituskyky Llama 2 7B -päätepisteelle ml.g5.12xlarge-esiintymässä hyötykuormalle, jossa on 256 syöttötunnusta ja 256 lähtötunnusta, kuten seuraavasta käyrästä näkyy. Samanlainen käyrä on olemassa jokaiselle käyttöönotetulle LLM-päätepisteelle.
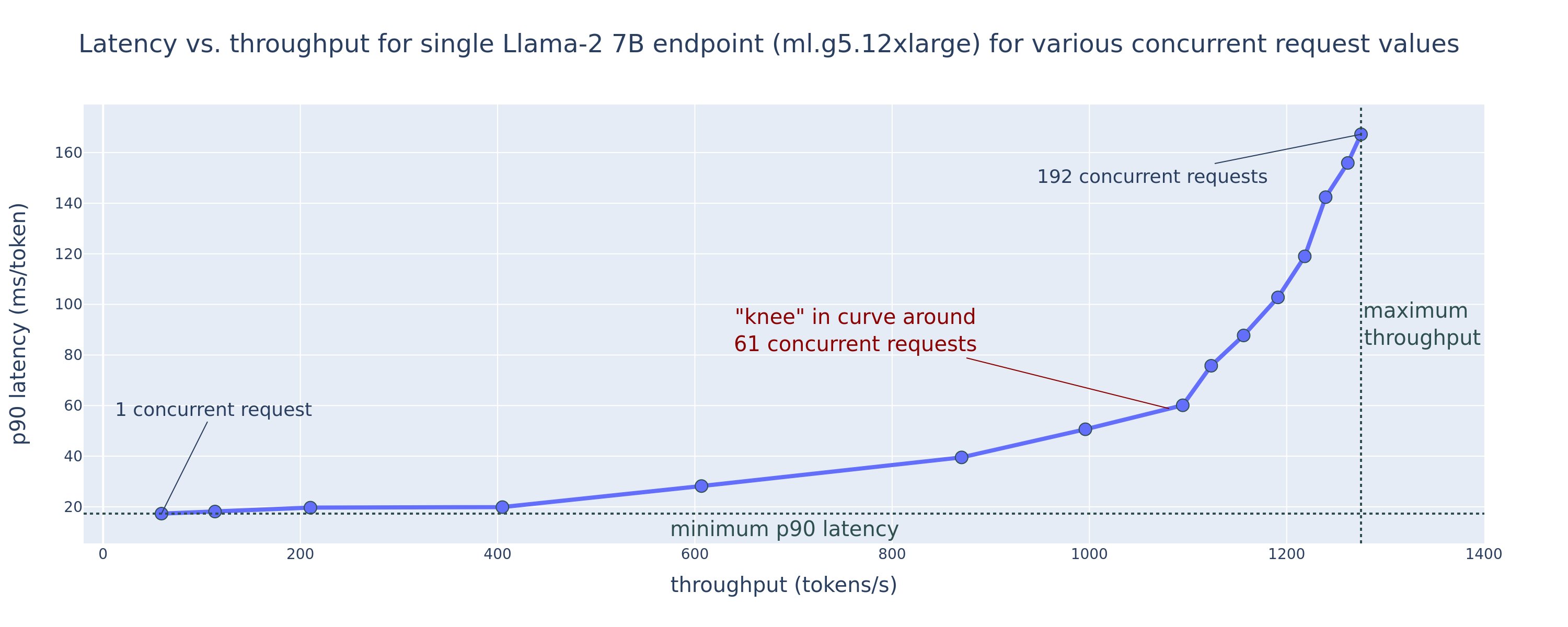
Samanaikaisuuden kasvaessa myös suorituskyky ja latenssi kasvavat monotonisesti. Siksi alin latenssipiste esiintyy samanaikaisen pyynnön arvolla 1, ja voit kustannustehokkaasti lisätä järjestelmän suorituskykyä lisäämällä samanaikaisia pyyntöjä. Tässä käyrässä on selvä "polvi", jossa on ilmeistä, että lisäyhtenäisyyteen liittyvät suorituskyvyn lisäykset eivät paina siihen liittyvää latenssin kasvua. Tämän polven tarkka sijainti on käyttötapauskohtainen; Jotkut harjoittajat voivat määrittää polven kohdassa, jossa ennalta määritetty latenssivaatimus ylittyy (esimerkiksi 100 ms/token), kun taas toiset voivat käyttää kuormitustestivertailuja ja jonoteoriamenetelmiä, kuten puolilatenssisääntöä, ja toiset voivat käyttää teoreettiset kiihdytinvaatimukset.
Huomaa myös, että samanaikaisten pyyntöjen enimmäismäärä on rajoitettu. Edellisessä kuvassa linjan jäljitys päättyy 192 samanaikaiseen pyyntöön. Tämän rajoituksen lähde on SageMakerin kutsun aikakatkaisuraja, jossa SageMaker aikakatkaisee kutsuvastauksen 60 sekunnin kuluttua. Tämä asetus on tilikohtainen, eikä sitä voi määrittää yksittäiselle päätepisteelle. LLM:illä suuren määrän tulostokenien luominen voi kestää sekunteja tai jopa minuutteja. Siksi suuret tulo- tai lähtöhyötykuormat voivat aiheuttaa kutsupyyntöjen epäonnistumisen. Lisäksi, jos samanaikaisten pyyntöjen määrä on erittäin suuri, monien pyyntöjen jonotusajat ovat pitkiä, mikä lisää tätä 60 sekunnin aikarajaa. Tässä tutkimuksessa käytämme aikakatkaisurajaa mallin käyttöönoton suurimman mahdollisen suorituskyvyn määrittämiseen. Tärkeää on, että vaikka SageMaker-päätepiste voi käsitellä suuren määrän samanaikaisia pyyntöjä ilman, että havaitset kutsuvastauksen aikakatkaisua, saatat haluta määrittää samanaikaisten pyyntöjen enimmäismäärän polven suhteen latenssi-läpäisytehokäyrässä. Tämä on todennäköisesti kohta, jolloin alat harkita vaakasuuntaista skaalausta, jossa yksi päätepiste varaa useita ilmentymiä mallireplikoilla ja tasapainottaa saapuvat pyynnöt replikoiden välillä samanaikaisempien pyyntöjen tukemiseksi.
Kun tämä viedään askeleen pidemmälle, seuraava taulukko sisältää vertailutuloksia Llama 2 7B -mallin eri kokoonpanoille, mukaan lukien erilaiset tulo- ja lähtötunnisteet, ilmentymätyypit ja samanaikaisten pyyntöjen lukumäärä. Huomaa, että edellinen kuva piirtää vain yhden rivin tästä taulukosta.
| . | Suorituskyky (tunteja/s) | Latenssi (ms/tunnus) | ||||||||||||||||||
| Samanaikaiset pyynnöt | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Tokenien kokonaismäärä: 512, Tulostettujen tokenien määrä: 256 | ||||||||||||||||||||
| ml.g5.2xsuuri | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xsuuri | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xsuuri | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Tokenien kokonaismäärä: 4096, Tulostettujen tokenien määrä: 256 | ||||||||||||||||||||
| ml.g5.2xsuuri | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xsuuri | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xsuuri | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Näissä tiedoissa havaitsemme joitain lisämalleja. Kun kontekstin kokoa kasvatetaan, latenssi kasvaa ja suorituskyky pienenee. Esimerkiksi tiedostossa ml.g5.2xlarge, kun samanaikaisuus on 1, läpijuoksu on 30 merkkiä/s, kun merkkien kokonaismäärä on 512, vs. 20 merkkiä/s, jos merkkien kokonaismäärä on 4,096 2. Tämä johtuu siitä, että suuremman syötteen käsittely vie enemmän aikaa. Näemme myös, että grafiikkasuorittimen kapasiteetin lisääminen ja jakaminen vaikuttavat maksimaaliseen suorituskykyyn ja tuettujen samanaikaisten pyyntöjen enimmäismäärään. Taulukko osoittaa, että Llama 7 5.12B:llä on huomattavasti erilaiset maksimiläpäisyarvot eri ilmentymätyypeille, ja nämä maksimiläpäisyarvot esiintyvät samanaikaisten pyyntöjen eri arvoilla. Nämä ominaisuudet saisivat ML-ammattilaisen perustelemaan yhden ilmentymän kustannukset toiseen verrattuna. Esimerkiksi alhaisen latenssivaatimuksen vuoksi lääkäri voi valita ml.g4xlarge-esiintymän (10 A5.2G GPU:ta) ml.g1xlarge-esiintymän (10 A4G GPU) sijaan. Korkean suorituskyvyn vaatimuksen vuoksi ml.p24d.8xlarge-esiintymän (100 A7 GPU:ta) käyttö täydellä shardingilla olisi perusteltua vain suuren samanaikaisuuden yhteydessä. Huomaa kuitenkin, että sen sijaan on usein hyödyllistä ladata useita 4B-mallin päättelykomponentteja yhteen ml.p24d.XNUMXxlarge-esiintymään; tällaista usean mallin tukea käsitellään myöhemmin tässä viestissä.
Edelliset havainnot tehtiin Llama 2 7B -mallille. Samanlaiset mallit ovat kuitenkin päteviä myös muille malleille. Ensisijainen huomio on, että latenssi- ja suoritusteholuvut riippuvat hyötykuormasta, ilmentymän tyypistä ja samanaikaisten pyyntöjen määrästä, joten sinun on löydettävä ihanteellinen kokoonpano sovelluksellesi. Luodaksesi edelliset numerot käyttötapaukseesi, voit suorittaa linkitetyn muistikirja, jossa voit määrittää tämän kuormitustestianalyysin mallillesi, ilmentymätyypille ja hyötykuormallesi.
Kiihdyttimen teknisten tietojen järkeä
Sopivan laitteiston valinta LLM-päätelmää varten riippuu suuresti erityisistä käyttötapauksista, käyttökokemuksen tavoitteista ja valitusta LLM:stä. Tässä osiossa yritetään luoda käsitys polvesta latenssi-läpäisykykykäyrässä korkean tason periaatteiden mukaisesti, jotka perustuvat kiihdytinspesifikaatioihin. Nämä periaatteet eivät yksinään riitä päätöksentekoon: tarvitaan todellisia vertailuarvoja. Termi laite käytetään tässä kattamaan kaikki ML-laitteistokiihdyttimet. Väitämme, että latenssi-läpäisykykykäyrän polvi perustuu jompaankumpaan kahdesta tekijästä:
- Kiihdytin on käyttänyt muistia KV-matriisien välimuistiin, joten seuraavat pyynnöt ovat jonossa
- Kiihdyttimessä on vielä ylimääräistä muistia KV-välimuistia varten, mutta se käyttää riittävän suurta eräkokoa, jotta käsittelyaika määräytyy laskennan viiveen sijaan muistin kaistanleveyden perusteella.
Tyypillisesti pidämme parempana toisen tekijän rajoittamista, koska tämä tarkoittaa, että kiihdytinresurssit ovat kyllästyneet. Periaatteessa maksimoit maksamasi resurssit. Tutkitaanpa tätä väitettä tarkemmin.
KV-välimuisti ja laitemuisti
Tavalliset muuntajan huomiomekanismit laskevat huomion jokaiselle uudelle tunnukselle kaikkia aiempia tokeneita vastaan. Useimmat nykyaikaiset ML-palvelimet tallentavat huomioavaimet ja arvot laitteen muistiin (DRAM) välttääkseen uudelleenlaskennan jokaisessa vaiheessa. Tätä kutsutaan nimellä KV-välimuisti, ja se kasvaa erän koon ja sarjan pituuden mukaan. Se määrittää, kuinka monta käyttäjän pyyntöä voidaan palvella rinnakkain, ja määrittää latenssi-läpäisytehokäyrän polven, jos aiemmin mainitun toisen skenaarion laskentaan sidottu järjestelmä ei vielä täyty, kun otetaan huomioon käytettävissä oleva DRAM. Seuraava kaava on karkea arvio KV-välimuistin enimmäiskoosta.

Tässä kaavassa B on eräkoko ja N on kiihdyttimien lukumäärä. Esimerkiksi Llama 2 7B -malli FP16:ssa (2 tavua/parametri), jota käytetään A10G-grafiikkasuorittimessa (24 Gt DRAM), kuluttaa noin 14 Gt, joten KV-välimuistille jää 10 Gt. Kun mallin koko kontekstin pituus (N = 4096) ja loput parametrit (n_layers=32, n_kv_attention_heads=32 ja d_attention_head=128) kytketään, tämä lauseke osoittaa, että DRAM-rajoitusten vuoksi rajoitamme palvelemaan neljän käyttäjän eräkokoa rinnakkain. . Jos tarkastelet edellisen taulukon vastaavia vertailuarvoja, tämä on hyvä arvio havaitulle polvelle tässä latenssi-läpäisykykykäyrässä. Menetelmät, kuten ryhmäkyselyn huomio (GQA) voi pienentää KV-välimuistin kokoa, GQA:n tapauksessa samalla kertoimella se vähentää KV-päiden määrää.
Aritmeettinen intensiteetti ja laitteen muistin kaistanleveys
ML-kiihdyttimien laskentatehon kasvu on ylittänyt niiden muistin kaistanleveyden, mikä tarkoittaa, että ne voivat suorittaa paljon enemmän laskutoimituksia jokaiselle datatavulle siinä ajassa, joka kuluu kyseisen tavun käyttämiseen.
- aritmeettinen voimakkuus, tai laskentatoimintojen suhde muistin käyttöihin, määrittää, rajoittaako sitä muistin kaistanleveys tai valitun laitteiston laskentakapasiteetti. Esimerkiksi A10G GPU (g5-instanssityyppiperhe), jossa on 70 TFLOPS FP16 ja 600 Gt/s kaistanleveys, voi laskea noin 116 operaatiota/tavu. A100 GPU (p4d-ilmentymätyyppiperhe) voi laskea noin 208 ops/tavu. Jos muuntajamallin aritmeettinen intensiteetti on tämän arvon alapuolella, se on muistiin sidottu; jos se on edellä, se on laskennallisesti sidottu. Llama 2 7B:n huomiomekanismi vaatii 62 toimintoa/tavu eräkoolla 1 (selitys, katso Opas LLM-johtopäätökseen ja suorituskykyyn), mikä tarkoittaa, että se on sidottu muistiin. Kun huomiomekanismi on sidottu muistiin, kalliit FLOPSit jäävät käyttämättä.
On kaksi tapaa hyödyntää kiihdytintä paremmin ja lisätä aritmeettista intensiteettiä: vähentää operaatioon tarvittavia muistin käyttöjä (tämä on mitä FlashAttention keskittyy) tai suurenna eräkokoa. Emme kuitenkaan ehkä pysty kasvattamaan eräkokoamme tarpeeksi saavuttaaksemme laskentaan sidotun järjestelmän, jos DRAM-muistimme on liian pieni vastaavan KV-välimuistin säilyttämiseen. Karkea likiarvo kriittisestä eräkoon B*, joka erottaa laskennalliset ja muistiin sidotut järjestelmät standardi GPT-dekooderin päättelyssä, kuvataan seuraavalla lausekkeella, jossa A_mb on kiihdytinmuistin kaistanleveys, A_f on kiihdytin FLOPS ja N on luku. kiihdyttimistä. Tämä kriittinen eräkoko voidaan johtaa etsimällä, missä muistin käyttöaika on yhtä suuri kuin laskentaaika. Viitata tämä blogikirja ymmärtääksesi yhtälöä 2 ja sen oletuksia yksityiskohtaisemmin.

Tämä on sama operaatio/tavu-suhde, jonka laskemme aiemmin A10G:lle, joten tämän GPU:n kriittinen eräkoko on 116. Yksi tapa lähestyä tätä teoreettista, kriittistä eräkokoa on lisätä mallin jakamista ja jakaa välimuisti useammille N kiihdyttimille. Tämä lisää tehokkaasti KV-välimuistin kapasiteettia sekä muistiin sidottua eräkokoa.
Toinen mallin jakamisen etu on malliparametrien ja tietojen lataustyön jakaminen N kiihdyttimien kesken. Tämän tyyppinen sirpalointi on eräänlainen mallin rinnakkaisuus, jota kutsutaan myös nimellä tensorin rinnakkaisuus. Naiivisti, muistin kaistanleveys ja laskentateho on N kertaa yhteensä. Olettaen, ettei mitään ylimääräisiä kuluja (viestintä, ohjelmisto ja niin edelleen) ole, tämä vähentäisi dekoodausviivettä merkkiä kohti N:llä, jos olemme muistiin sidottu, koska tunnuksen dekoodausviive tässä järjestelmässä on sidottu mallin lataamiseen kuluvaan aikaan. painot ja kätkö. Todellisessa elämässä sirpalointiasteen lisääminen johtaa kuitenkin lisääntyneeseen kommunikaatioon laitteiden välillä, jotta väliaktivoinnit voidaan jakaa jokaisessa mallikerroksessa. Tätä tiedonsiirtonopeutta rajoittaa laitteen yhteenliittämisen kaistanleveys. Sen vaikutusta on vaikea arvioida tarkasti (katso lisätietoja Malli rinnakkaisuus), mutta tämä voi lopulta lakata tuomasta etuja tai heikentää suorituskykyä – tämä pätee erityisesti pienempiin malleihin, koska pienemmät tiedonsiirrot johtavat alhaisempaan siirtonopeuteen.
ML-kiihdyttimien vertaamiseksi niiden teknisten tietojen perusteella suosittelemme seuraavaa. Ensin lasketaan likimääräinen kriittinen eräkoko kullekin kiihdytintyypille toisen yhtälön mukaisesti ja KV-välimuistin koko kriittiselle eräkoolle ensimmäisen yhtälön mukaisesti. Voit sitten käyttää kiihdytin käytettävissä olevaa DRAM-muistia laskeaksesi vähimmäismäärän kiihdyttimiä, jotka tarvitaan KV-välimuistiin ja malliparametreihin. Jos päätät useiden kiihdyttimien välillä, priorisoi kiihdykkeet alimman hinnan mukaan muistin kaistanleveyden gigatavua sekunnissa. Vertaile lopuksi näitä kokoonpanoja ja varmista, mikä on paras hinta/tunnus halutun viiveen ylärajalle.
Valitse päätepisteen käyttöönottokokoonpano
Monet SageMaker JumpStartin jakamat LLM:t käyttävät teksti-sukupolvi-päätelmä (TGI) SageMaker-säiliö mallin tarjoilua varten. Seuraavassa taulukossa käsitellään useita mallin käyttöparametreja säätämällä joko viive-läpäisykykykäyrään vaikuttavaa mallin käyttöä tai päätepisteen suojaamista pyynnöiltä, jotka ylikuormittaisivat päätepistettä. Nämä ovat ensisijaiset parametrit, joita voit käyttää päätepisteen käyttöönoton määrittämiseen käyttötapauksesi mukaan. Ellei toisin mainita, käytämme oletusarvoa tekstin luomisen hyötykuorman parametrit ja TGI-ympäristömuuttujat.
| Ympäristömuuttuja | Kuvaus | SageMaker JumpStart -oletusarvo |
| Mallin käyttökokoonpanot | . | . |
MAX_BATCH_PREFILL_TOKENS |
Rajoittaa merkkien määrää esitäyttötoiminnossa. Tämä toiminto luo KV-välimuistin uudelle syöttökehotesekvenssille. Se on muistiintensiivinen ja sidottu laskentaan, joten tämä arvo rajoittaa yhdessä esitäyttötoiminnossa sallittujen merkkien määrän. Muiden kyselyiden dekoodausvaiheet keskeytyvät esitäytön aikana. | 4096 (TGI-oletus) tai mallikohtainen suurin tuettu kontekstin pituus (SageMaker JumpStart mukana), kumpi on suurempi. |
MAX_BATCH_TOTAL_TOKENS |
Ohjaa joukkoon sisällytettävien merkkien enimmäismäärää dekoodauksen aikana tai yksittäisen mallin läpi kulkevan eteenpäin. Ihannetapauksessa tämä on asetettu maksimoimaan kaikkien saatavilla olevien laitteistojen käyttö. | Ei määritetty (TGI-oletus). TGI asettaa tämän arvon suhteessa jäljellä olevaan CUDA-muistiin mallin lämpenemisen aikana. |
SM_NUM_GPUS |
Käytettävien sirpaleiden määrä. Toisin sanoen niiden GPU:iden määrä, joita käytetään mallin suorittamiseen tensoririnnakkaisuudella. | Instanssiriippuvainen (SageMaker JumpStart toimitetaan). Jokaiselle tietyn mallin tuetulle ilmentymälle SageMaker JumpStart tarjoaa parhaan asetuksen tensorin rinnakkaisuudelle. |
| Määritykset päätepisteesi suojaamiseksi (määritä nämä käyttötapaustasi varten) | . | . |
MAX_TOTAL_TOKENS |
Tämä rajoittaa yksittäisen asiakaspyynnön muistibudjetin rajoittamalla syöttösekvenssissä olevien merkkien määrää sekä tulostejonon merkkien määrää ( max_new_tokens hyötykuormaparametri). |
Mallikohtainen suurin tuettu kontekstin pituus. Esimerkiksi 4096 Llama 2:lle. |
MAX_INPUT_LENGTH |
Tunnistaa suurimman sallitun vuoromerkkien määrän syöttösekvenssissä yksittäiselle asiakaspyynnölle. Asioita, jotka on otettava huomioon tätä arvoa suurettaessa: pidemmät syöttösekvenssit vaativat enemmän muistia, mikä vaikuttaa jatkuvaan eräajon, ja monilla malleilla on tuettu kontekstin pituus, jota ei pitäisi ylittää. | Mallikohtainen suurin tuettu kontekstin pituus. Esimerkiksi 4095 Llama 2:lle. |
MAX_CONCURRENT_REQUESTS |
Käytetyn päätepisteen sallima samanaikaisten pyyntöjen enimmäismäärä. Tämän rajan ylittävät uudet pyynnöt aiheuttavat välittömästi mallin ylikuormitusvirheen estääkseen nykyisten käsittelypyyntöjen huonon latenssin. | 128 (TGI-oletus). Tämän asetuksen avulla voit saavuttaa suuren suorituskyvyn useisiin käyttötapauksiin, mutta sinun tulee kiinnittää tarvittaessa SageMaker-kutsujen aikakatkaisuvirheiden vähentämiseksi. |
TGI-palvelin käyttää jatkuvaa eräajoa, joka dynaamisesti yhdistää samanaikaiset pyynnöt jakaakseen yhden mallin päättelyn eteenpäin. Eteenpäinkulkuja on kahta tyyppiä: esitäyttö ja dekoodaus. Jokaisen uuden pyynnön on suoritettava yksi esitäytön välitys KV-välimuistin täyttämiseksi syöttösekvenssitokeneille. Sen jälkeen, kun KV-välimuisti on täytetty, dekoodauksen eteenpäinkulku suorittaa yhden seuraavan merkin ennusteen kaikille eräpyynnöille, joka toistetaan iteratiivisesti tulossekvenssin tuottamiseksi. Kun uusia pyyntöjä lähetetään palvelimelle, seuraavan dekoodausvaiheen on odotettava, jotta esitäyttövaihe voidaan suorittaa uusille pyynnöille. Tämän on tapahduttava ennen kuin nämä uudet pyynnöt sisällytetään seuraaviin jatkuvasti eriteltyihin dekoodausvaiheisiin. Laitteiston rajoituksista johtuen dekoodaukseen käytetty jatkuva erä ei välttämättä sisällä kaikkia pyyntöjä. Tässä vaiheessa pyynnöt siirtyvät prosessointijonoon ja päättelyviive alkaa kasvaa merkittävästi vain pienellä suorituskyvyn vahvistuksella.
On mahdollista jakaa LLM-viiveen vertailuanalyysit esitäytön latenssiin, dekoodauksen latenssiin ja jonoviiveeseen. Kunkin näistä komponenteista kuluma aika on luonteeltaan pohjimmiltaan erilainen: esitäyttö on kertaluonteinen laskenta, dekoodaus tapahtuu kerran jokaiselle lähtösekvenssissä olevalle tokenille ja jonotukseen liittyy palvelimen eräprosesseja. Kun useita samanaikaisia pyyntöjä käsitellään, on vaikeaa erottaa viiveet kustakin näistä komponenteista, koska minkä tahansa asiakaspyynnön kokemaan latenssiin liittyy jonoviiveitä, jotka johtuvat tarpeesta esitäytä uusia samanaikaisia pyyntöjä sekä sisällyttämisen aiheuttamia jonoviiveitä. pyynnöstä erädekoodausprosesseissa. Tästä syystä tämä viesti keskittyy päästä päähän -käsittelyn latenssiin. Latenssi-läpivirtauskäyrän polvi tapahtuu kyllästymispisteessä, jossa jonolatenssit alkavat kasvaa merkittävästi. Tämä ilmiö esiintyy kaikissa mallien päättelypalvelimissa, ja sitä ohjaavat kiihdytin tekniset tiedot.
Yleisiä vaatimuksia käyttöönoton aikana ovat vaaditun vähimmäissuorituskyvyn, suurimman sallitun latenssin, enimmäishinnan tuntikohtaisen ja maksimikustannusten täyttäminen miljoonan tunnuksen luomiseen. Sinun tulee asettaa nämä vaatimukset hyötykuormille, jotka edustavat loppukäyttäjien pyyntöjä. Nämä vaatimukset täyttävässä suunnittelussa tulee ottaa huomioon monia tekijöitä, mukaan lukien tietty malliarkkitehtuuri, mallin koko, ilmentymien tyypit ja ilmentymien määrä (vaakasuuntainen skaalaus). Seuraavissa osissa keskitymme päätepisteiden käyttöönottoon viiveen minimoimiseksi, suorituskyvyn maksimoimiseksi ja kustannusten minimoimiseksi. Tämä analyysi ottaa huomioon yhteensä 1 merkkiä ja 512 tulostetunnusta.
Minimoi latenssi
Latenssi on tärkeä vaatimus monissa reaaliaikaisissa käyttötapauksissa. Seuraavassa taulukossa tarkastellaan kunkin mallin ja kunkin ilmentymän tyypin vähimmäisviivettä. Voit saavuttaa vähimmäisviiveen asettamalla MAX_CONCURRENT_REQUESTS = 1.
| Minimiviive (ms/tunnus) | |||||
| Model ID | ml.g5.2xsuuri | ml.g5.12xsuuri | ml.g5.48xsuuri | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Laama 2 7B | 33 | 17 | 18 | 20 | - |
| Llama 2 7B Chat | 33 | 17 | 18 | 20 | - |
| Laama 2 13B | - | 22 | 23 | 23 | - |
| Llama 2 13B Chat | - | 23 | 23 | 23 | - |
| Laama 2 70B | - | - | 57 | 43 | - |
| Llama 2 70B Chat | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Mistral 7B -ohje | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Falcon 7B -ohje | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Falcon 40B -ohje | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Falcon 180B Chat | - | - | - | - | 42 |
Mallin vähimmäisviiveen saavuttamiseksi voit käyttää seuraavaa koodia samalla, kun korvaat haluamasi mallitunnuksen ja ilmentymän tyypin:
Huomaa, että latenssinumerot vaihtelevat tulo- ja lähtötunnisteiden lukumäärän mukaan. Käyttöönottoprosessi pysyy kuitenkin samana ympäristömuuttujia lukuun ottamatta MAX_INPUT_TOKENS ja MAX_TOTAL_TOKENS. Tässä nämä ympäristömuuttujat on asetettu takaamaan päätepisteen latenssivaatimukset, koska suuremmat syöttösekvenssit voivat rikkoa latenssivaatimusta. Huomaa, että SageMaker JumpStart tarjoaa jo muita optimaalisia ympäristömuuttujia valittaessa ilmentymän tyyppiä; esimerkiksi käyttämällä ml.g5.12xlarge asetetaan SM_NUM_GPUS 4:ään malliympäristössä.
Maksimoi suorituskyky
Tässä osiossa maksimoimme luotujen merkkien määrän sekunnissa. Tämä saavutetaan tyypillisesti mallin ja ilmentymän tyypin enimmäiskelvollisilla samanaikaisilla pyynnöillä. Seuraavassa taulukossa raportoimme suorituskyvyn, joka saavutettiin suurimmalla samanaikaisen pyynnön arvolla, ennen kuin havaitaan SageMaker-kutsujen aikakatkaisu mille tahansa pyynnölle.
| Suurin suoritusteho (tunnuksia/sek), samanaikaiset pyynnöt | |||||
| Model ID | ml.g5.2xsuuri | ml.g5.12xsuuri | ml.g5.48xsuuri | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Laama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Llama 2 7B Chat | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Laama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Llama 2 13B Chat | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Laama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Llama 2 70B Chat | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Mistral 7B -ohje | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Falcon 7B -ohje | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B -ohje | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Falcon 180B Chat | - | - | - | - | 1081 (128) |
Voit saavuttaa mallin suurimman suorituskyvyn käyttämällä seuraavaa koodia:
Huomaa, että samanaikaisten pyyntöjen enimmäismäärä riippuu mallin tyypistä, ilmentymän tyypistä, syöttötunnisteiden enimmäismäärästä ja lähtötunnisteiden enimmäismäärästä. Siksi sinun tulee asettaa nämä parametrit ennen asetusta MAX_CONCURRENT_REQUESTS.
Huomaa myös, että viiveen minimoimisesta kiinnostunut käyttäjä on usein ristiriidassa suorituskyvyn maksimoimisesta kiinnostuneen käyttäjän kanssa. Edellinen on kiinnostunut reaaliaikaisista vastauksista, kun taas jälkimmäinen on kiinnostunut eräkäsittelystä siten, että päätepistejono on aina kyllästetty, mikä minimoi käsittelyn seisokit. Käyttäjät, jotka haluavat maksimoida läpäisykyvyn latenssivaatimusten perusteella, ovat usein kiinnostuneita toimimaan polven kohdalla latenssi-läpäisytehokäyrässä.
Minimoi kustannukset
Ensimmäinen vaihtoehto kustannusten minimoimiseksi sisältää tuntikustannusten minimoimisen. Tämän avulla voit ottaa käyttöön valitun mallin SageMaker-esiintymässä alhaisin tuntikustannuksin. Katso SageMaker-esiintymien reaaliaikainen hinnoittelu kohdasta Amazon SageMaker -hinnoittelu. Yleensä SageMaker JumpStart LLM:iden oletusilmentymätyyppi on halvin käyttöönottovaihtoehto.
Toinen vaihtoehto kustannusten minimoimiseksi sisältää 1 miljoonan merkin luomiskustannusten minimoimisen. Tämä on yksinkertainen muunnos taulukosta, josta keskustelimme aiemmin suorituskyvyn maksimoimiseksi, jossa voit ensin laskea tunnin, joka kuluu miljoonan tunnuksen luomiseen (1e1 / suorituskyky / 6). Voit sitten kertoa tämän ajan luodaksesi miljoona merkkiä määritetyn SageMaker-esiintymän tuntihinnalla.
Huomaa, että esiintymät, joiden tuntikohtainen hinta on alhaisin, eivät ole samoja kuin tapaukset, joiden kustannukset ovat alhaisimmat luoda miljoona tokenia. Jos esimerkiksi kutsupyynnöt ovat satunnaisia, alhaisimman tuntihinnan omaava ilmentymä saattaa olla optimaalinen, kun taas kuritusskenaarioissa alhaisin kustannus miljoonan tunnuksen luomiseksi saattaa olla sopivampi.
Tensorin rinnakkainen vs. monen mallin kompromissi
Kaikissa aiemmissa analyyseissä harkitsimme yhden mallireplikan käyttöönottoa, jonka tensorin rinnakkaisaste on yhtä suuri kuin käyttöönottoinstanssityypin GPU:iden lukumäärä. Tämä on oletusarvoinen SageMaker JumpStart -käyttäytyminen. Kuten aiemmin todettiin, mallin jakaminen voi kuitenkin parantaa mallin latenssia ja suorituskykyä vain tiettyyn rajaan asti, jonka ylittyessä laitteiden väliset viestintävaatimukset hallitsevat laskenta-aikaa. Tämä tarkoittaa, että on usein hyödyllistä ottaa käyttöön useita malleja, joilla on pienempi tensorin rinnakkaisaste, yhteen esiintymään sen sijaan, että yksi malli, jolla on korkeampi tensorin rinnakkaisaste, ottaa käyttöön.
Tässä otamme käyttöön Llama 2 7B- ja 13B -päätepisteitä ml.p4d.24xlarge-esiintymissä, joiden tensorisuuntaiset (TP) asteet ovat 1, 2, 4 ja 8. Mallin toiminnan selkeyden vuoksi jokainen näistä päätepisteistä lataa vain yhden mallin.
| . | Suorituskyky (tunteja/s) | Latenssi (ms/tunnus) | ||||||||||||||||||
| Samanaikaiset pyynnöt | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| TP tutkinto | Laama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Laama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Aiemmat analyysimme osoittivat jo merkittäviä suorituskykyetuja ml.p4d.24xlarge-esiintymissä, mikä usein tarkoittaa parempaa suorituskykyä kustannusten kannalta miljoonan tunnuksen luomiseksi g1-ilmentymäperheeseen verrattuna korkean samanaikaisen pyynnön kuormitusolosuhteissa. Tämä analyysi osoittaa selvästi, että sinun tulee harkita mallin jakamisen ja mallin replikoinnin välistä kompromissia yhdessä esiintymässä. toisin sanoen täysin sirpaloitu malli ei tyypillisesti ole paras käyttötarkoitus ml.p5d.4xlarge-laskentaresursseille 24B- ja 7B-malliperheille. Itse asiassa 13B-malliperheessä saat parhaan suorituskyvyn yksittäiselle mallireplikalle, jonka tensorin rinnakkaisaste on 7 4:n sijaan.
Tästä voit ekstrapoloida, että 7B-mallin suurin suorituskyvyn konfiguraatio sisältää tensorin rinnakkaisasteen 1 kahdeksalla mallikopiolla, ja 13B-mallin suurin suorituskyvyn konfiguraatio on todennäköisesti tensorin rinnakkaisaste 2 neljällä mallikopiolla. Lisätietoja tämän suorittamisesta on kohdassa Vähennä mallin käyttöönottokustannuksia keskimäärin 50 % käyttämällä Amazon SageMakerin uusimpia ominaisuuksia, joka osoittaa päättelykomponenttipohjaisten päätepisteiden käytön. Kuormantasaustekniikoiden, palvelimen reitityksen ja suoritinresurssien jakamisen vuoksi et välttämättä saavuta täydellisiä suorituskyvyn parannuksia, jotka ovat täsmälleen yhtä suuria kuin replikoiden määrä kertaa yhden replikan suoritusteho.
Vaakasuuntainen skaalaus
Kuten aiemmin todettiin, jokaisella päätepisteen käyttöönotolla on rajoitus samanaikaisten pyyntöjen lukumäärälle tulo- ja lähtötunnisteiden määrästä sekä ilmentymän tyypistä riippuen. Jos tämä ei täytä suorituskyvyn tai samanaikaisen pyynnön vaatimuksiasi, voit skaalata useampaa kuin yhtä esiintymää käyttöönotetun päätepisteen takana. SageMaker suorittaa automaattisesti kuormituksen tasauksen kyselyille esiintymien välillä. Esimerkiksi seuraava koodi ottaa käyttöön päätepisteen, jota tukee kolme esiintymää:
Seuraava taulukko näyttää suorituskyvyn vahvistuksen kertoimena esiintymien lukumäärällä Llama 2 7B -mallissa.
| . | . | Suorituskyky (tunteja/s) | Latenssi (ms/tunnus) | ||||||||||||||
| . | Samanaikaiset pyynnöt | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Ilmentymien lukumäärä | Esimerkkilaji | Tokenien kokonaismäärä: 512, Tulostettujen tokenien määrä: 256 | |||||||||||||||
| 1 | ml.g5.2xsuuri | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xsuuri | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xsuuri | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Erityisesti latenssi-läpäisykykykäyrän polvi siirtyy oikealle, koska korkeammat esiintymämäärät voivat käsitellä suurempia määriä samanaikaisia pyyntöjä usean esiintymän päätepisteessä. Tässä taulukossa samanaikaisen pyynnön arvo koskee koko päätepistettä, ei kunkin yksittäisen esiintymän vastaanottamien samanaikaisten pyyntöjen määrää.
Voit myös käyttää automaattista skaalausta, ominaisuutta, jolla voit seurata työkuormituksiasi ja säätää kapasiteettia dynaamisesti tasaisen ja ennustettavan suorituskyvyn ylläpitämiseksi mahdollisimman alhaisin kustannuksin. Tämä ei kuulu tämän postauksen piiriin. Lisätietoja automaattisesta skaalauksesta on kohdassa Autoscaling johtopäätösten päätepisteiden määrittäminen Amazon SageMakerissa.
Kutsu päätepiste samanaikaisilla pyynnöillä
Oletetaan, että sinulla on suuri joukko kyselyjä, joita haluat käyttää vastausten luomiseen käyttöönotetusta mallista suuren suorituskyvyn olosuhteissa. Esimerkiksi seuraavassa koodilohkossa kokoamme luettelon 1,000 100 hyötykuormasta, ja jokainen hyötykuorma pyytää 100,000 tokenin luomista. Kaiken kaikkiaan pyydämme XNUMX XNUMX tokenin luomista.
Kun lähetät suuren määrän pyyntöjä SageMaker runtime API:lle, saatat kohdata kuristusvirheitä. Voit lieventää tätä luomalla mukautetun SageMaker-ajonaikaisen asiakasohjelman, joka lisää uudelleenyritysten määrää. Voit antaa tuloksena olevan SageMaker-istuntoobjektin jommallekummalle JumpStartModel rakentaja tai sagemaker.predictor.retrieve_default jos haluat liittää uuden ennustajan jo käyttöön otettuun päätepisteeseen. Seuraavassa koodissa käytämme tätä istuntoobjektia, kun otamme käyttöön Llama 2 -mallin SageMaker JumpStart -oletuskokoonpanoilla:
Tällä käyttöönotetulla päätepisteellä on MAX_CONCURRENT_REQUESTS = 128 oletuksena. Seuraavassa lohkossa käytämme samanaikaista futuurikirjastoa toistamaan päätepisteen kutsumista kaikille hyötykuormille, joissa on 128 työntekijäsäiettä. Päätepiste käsittelee enintään 128 samanaikaista pyyntöä, ja aina kun pyyntö palauttaa vastauksen, suorittaja lähettää välittömästi uuden pyynnön päätepisteelle.
Tämä johtaa 100,000 1255 tunnuksen kokonaismäärään luomiseen 5.2 tokenin/sek:n suorituskyvyllä yhdessä ml.g80xlarge-esiintymässä. Tämän käsittely kestää noin XNUMX sekuntia.
Huomaa, että tämä suoritusarvo poikkeaa huomattavasti tämän viestin aiemmissa taulukoissa olevasta Llama 2 7B:n enimmäisläpäisykyvystä ml.g5.2xlargessa (486 merkkiä/s 64 samanaikaisella pyynnöllä). Tämä johtuu siitä, että syöttöhyötykuorma käyttää 8 merkkiä 256 sijasta, lähtömerkkien määrä on 100 256 sijasta ja pienemmät merkkien määrät mahdollistavat 128 samanaikaista pyyntöä. Tämä on viimeinen muistutus siitä, että kaikki latenssi- ja suoritusteholuvut ovat hyötykuormasta riippuvaisia! Hyötykuorman tunnuslukujen muuttaminen vaikuttaa eräprosesseihin mallin käytön aikana, mikä puolestaan vaikuttaa sovelluksesi esitäyttö-, dekoodaus- ja jonoaikoihin.
Yhteenveto
Tässä viestissä esittelimme SageMaker JumpStart LLM:ien, mukaan lukien Llama 2:n, Mistralin ja Falconin, vertailua. Esitimme myös oppaan, jonka avulla voit optimoida päätepisteen käyttöönottokokoonpanon latenssin, suorituskyvyn ja kustannusten. Voit aloittaa suorittamalla liittyvä muistikirja vertailla käyttötapaustasi.
Tietoja Tekijät
 Tohtori Kyle Ulrich on soveltuva tutkija Amazon SageMaker JumpStart -tiimin kanssa. Hänen tutkimusalueitaan ovat skaalautuvat koneoppimisalgoritmit, tietokonenäkö, aikasarjat, Bayesin ei-parametrit ja Gaussin prosessit. Hänen tohtorinsa on Duken yliopistosta ja hän on julkaissut artikkeleita NeurIPS-, Cell- ja Neuron-julkaisuissa.
Tohtori Kyle Ulrich on soveltuva tutkija Amazon SageMaker JumpStart -tiimin kanssa. Hänen tutkimusalueitaan ovat skaalautuvat koneoppimisalgoritmit, tietokonenäkö, aikasarjat, Bayesin ei-parametrit ja Gaussin prosessit. Hänen tohtorinsa on Duken yliopistosta ja hän on julkaissut artikkeleita NeurIPS-, Cell- ja Neuron-julkaisuissa.
 Dr. Vivek Madan on soveltuva tutkija Amazon SageMaker JumpStart -tiimin kanssa. Hän sai tohtorin tutkinnon Illinoisin yliopistosta Urbana-Champaignissa ja oli tutkijatohtorina Georgia Techissä. Hän on aktiivinen koneoppimisen ja algoritmisuunnittelun tutkija ja julkaissut julkaisuja EMNLP-, ICLR-, COLT-, FOCS- ja SODA-konferensseissa.
Dr. Vivek Madan on soveltuva tutkija Amazon SageMaker JumpStart -tiimin kanssa. Hän sai tohtorin tutkinnon Illinoisin yliopistosta Urbana-Champaignissa ja oli tutkijatohtorina Georgia Techissä. Hän on aktiivinen koneoppimisen ja algoritmisuunnittelun tutkija ja julkaissut julkaisuja EMNLP-, ICLR-, COLT-, FOCS- ja SODA-konferensseissa.
 Tohtori Ashish Khetan on vanhempi soveltuva tutkija Amazon SageMaker JumpStartissa ja auttaa kehittämään koneoppimisalgoritmeja. Hän sai tohtorin tutkinnon Illinois Urbana-Champaignin yliopistosta. Hän on aktiivinen koneoppimisen ja tilastollisen päättelyn tutkija, ja hän on julkaissut monia artikkeleita NeurIPS-, ICML-, ICLR-, JMLR-, ACL- ja EMNLP-konferensseissa.
Tohtori Ashish Khetan on vanhempi soveltuva tutkija Amazon SageMaker JumpStartissa ja auttaa kehittämään koneoppimisalgoritmeja. Hän sai tohtorin tutkinnon Illinois Urbana-Champaignin yliopistosta. Hän on aktiivinen koneoppimisen ja tilastollisen päättelyn tutkija, ja hän on julkaissut monia artikkeleita NeurIPS-, ICML-, ICLR-, JMLR-, ACL- ja EMNLP-konferensseissa.
 João Moura on AWS:n vanhempi AI/ML Specialist Solutions -arkkitehti. João auttaa AWS-asiakkaita – pienistä startupeista suuriin yrityksiin – kouluttamaan ja ottamaan käyttöön suuria malleja tehokkaasti sekä rakentamaan laajemmin ML-alustoja AWS:lle.
João Moura on AWS:n vanhempi AI/ML Specialist Solutions -arkkitehti. João auttaa AWS-asiakkaita – pienistä startupeista suuriin yrityksiin – kouluttamaan ja ottamaan käyttöön suuria malleja tehokkaasti sekä rakentamaan laajemmin ML-alustoja AWS:lle.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

