Tänään meillä on ilo ilmoittaa, että Meta pystyy hienosäätämään Code Llama -malleja Amazon SageMaker JumpStart. Code Llama suurten kielimallien (LLM) perhe on kokoelma esikoulutettuja ja hienosäädettyjä koodinluontimalleja, joiden mittakaava vaihtelee 7 miljardista 70 miljardiin parametriin. Hienosäädetyt Code Llama -mallit tarjoavat paremman tarkkuuden ja selitettävyyden verrattuna Code Llama -perusmalleihin, mikä käy ilmi sen testauksesta. HumanEval ja MBPP-tietojoukot. Voit hienosäätää ja ottaa käyttöön Code Llama -malleja SageMaker JumpStart -ohjelman avulla Amazon SageMaker Studio Käyttöliittymä muutamalla napsautuksella tai käyttämällä SageMaker Python SDK:ta. Llama-mallien hienosäätö perustuu julkaisussa annettuihin skripteihin laama-reseptit GitHub repo Metasta PyTorch FSDP-, PEFT/LoRA- ja Int8-kvantisointitekniikoilla.
Tässä viestissä käymme läpi Code Llaman esikoulutettujen mallien hienosäätämisen SageMaker JumpStartin avulla yhden napsautuksen käyttöliittymän ja SDK-kokemuksen avulla, jotka ovat saatavilla seuraavissa osissa GitHub-arkisto.
Mikä on SageMaker JumpStart
SageMaker JumpStartin avulla koneoppimisen (ML) harjoittajat voivat valita laajasta valikoimasta julkisesti saatavilla olevia perusmalleja. ML-ammattilaiset voivat ottaa käyttöön perustamismalleja omistettuihin Amazon Sage Maker instansseja verkosta eristetystä ympäristöstä ja mukauta malleja SageMakerin avulla mallin koulutusta ja käyttöönottoa varten.
Mikä on Code Llama
Code Llama on koodiin erikoistunut versio Laama 2 joka luotiin kouluttamalla Llama 2:ta sen koodikohtaisissa tietojoukoissa ja ottamalla enemmän dataa samasta tietojoukosta pidempään. Code Llamassa on parannetut koodausominaisuudet. Se voi luoda koodia ja luonnollista kieltä koodista sekä koodin että luonnollisen kielen kehotteista (esimerkiksi "Kirjoita minulle funktio, joka tulostaa Fibonacci-sekvenssin"). Voit käyttää sitä myös koodin viimeistelyyn ja virheenkorjaukseen. Se tukee monia suosituimpia nykyään käytettyjä ohjelmointikieliä, mukaan lukien Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash ja paljon muuta.
Miksi hienosäätää Code Llama -malleja
Meta julkaisi Code Llaman suorituskyvyn vertailuarvot HumanEval ja MBPP yleisille koodauskielille, kuten Python, Java ja JavaScript. Code Llama Python -mallien suorituskyky HumanEvalissa osoitti vaihtelevaa suorituskykyä eri koodauskielissä ja -tehtävissä, jotka vaihtelivat 38 %:sta 7B Python -mallissa 57 %:iin 70B Python -malleissa. Lisäksi hienosäädetyt Code Llama -mallit SQL-ohjelmointikielellä ovat osoittaneet parempia tuloksia, mikä käy ilmi SQL-arvioinnin vertailuarvoista. Nämä julkaistut vertailuarvot korostavat Code Llama -mallien hienosäädön mahdollisia etuja, jotka mahdollistavat paremman suorituskyvyn, mukauttamisen ja mukauttamisen tiettyihin koodausalueisiin ja tehtäviin.
Kooditon hienosäätö SageMaker Studio -käyttöliittymän kautta
Aloita Llama-mallien hienosäätö SageMaker Studion avulla suorittamalla seuraavat vaiheet:
- Valitse SageMaker Studio -konsolissa Kaapelikäynnistys navigointipaneelissa.
Löydät luettelot yli 350 mallista avoimen lähdekoodin malleista patentoituihin malleihin.
- Etsi Code Llama -malleja.

Jos et näe Code Llama -malleja, voit päivittää SageMaker Studio -versiosi sammuttamalla ja käynnistämällä uudelleen. Lisätietoja versiopäivityksistä on kohdassa Sammuta ja päivitä Studio-sovellukset. Voit etsiä myös muita mallivaihtoehtoja valitsemalla Tutustu kaikkiin koodinluontimalleihin tai etsimällä Code Lama hakukentästä.

SageMaker JumpStart tukee tällä hetkellä Code Llama -mallien ohjeiden hienosäätöä. Seuraava kuvakaappaus näyttää Code Llama 2 70B -mallin hienosäätösivun.
- varten Harjoittelutietojoukon sijainti, voit osoittaa Amazonin yksinkertainen tallennuspalvelu (Amazon S3) -ämpäri, joka sisältää koulutus- ja validointitietojoukot hienosäätöä varten.
- Määritä käyttöönottokokoonpanosi, hyperparametrit ja suojausasetukset hienosäätöä varten.
- Valita Juna aloittaaksesi hienosäätötyön SageMaker ML -esiintymässä.
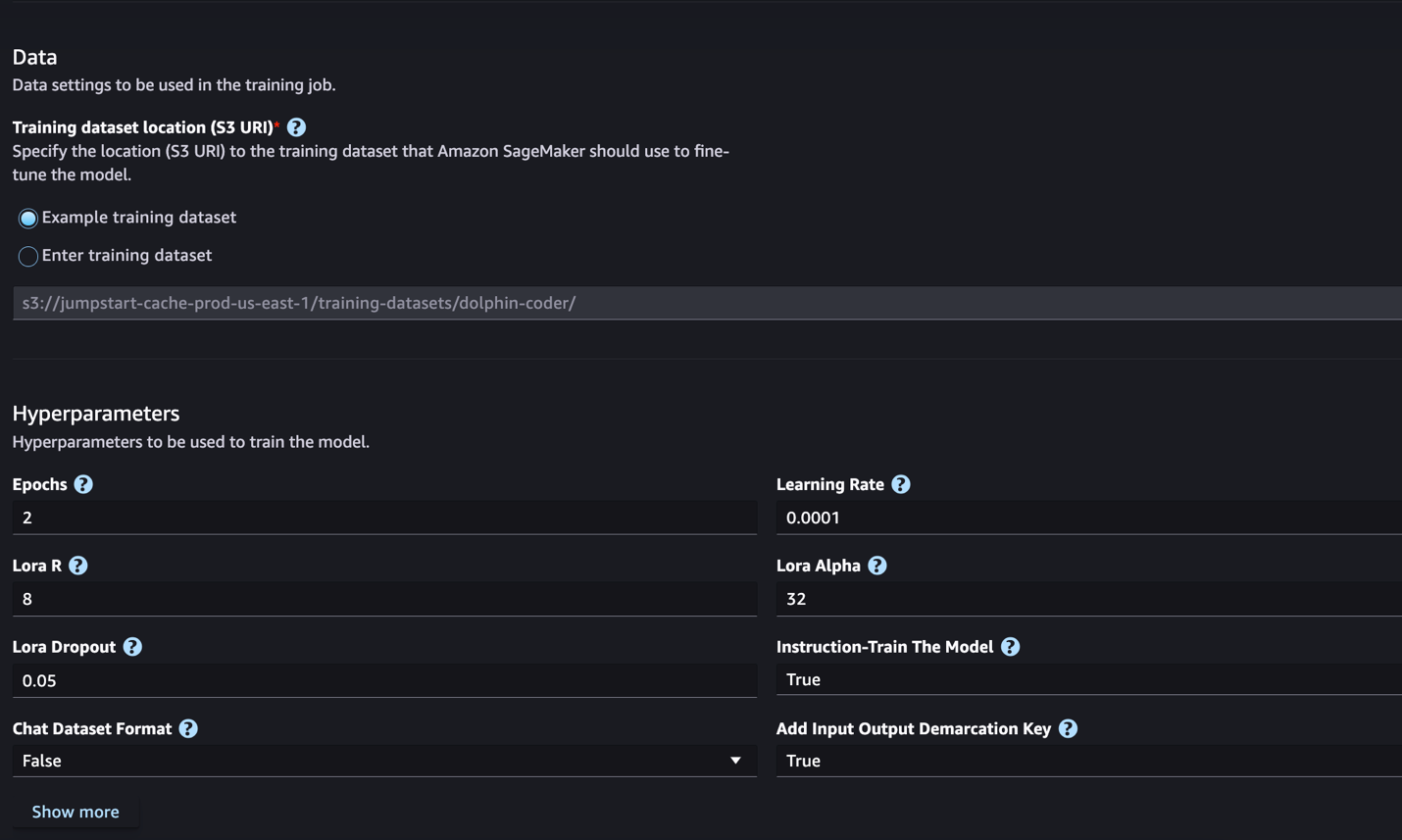
Käsittelemme seuraavassa osiossa tietojoukkomuotoa, jonka tarvitset valmistautuessasi ohjeiden hienosäätöön.
- Kun malli on hienosäädetty, voit ottaa sen käyttöön SageMaker JumpStartin mallisivulla.
Hienosäädetyn mallin käyttöönottovaihtoehto tulee näkyviin, kun hienosäätö on valmis, kuten seuraavassa kuvakaappauksessa näkyy.

Hienosäädä SageMaker Python SDK:n kautta
Tässä osiossa näytämme, miten Code LIama -malleja hienosäädetään SageMaker Python SDK:n avulla käskymuotoisessa tietojoukossa. Erityisesti malli on hienosäädetty joukolle luonnollisen kielen käsittelyn (NLP) tehtäviä, jotka kuvataan ohjeiden avulla. Tämä auttaa parantamaan mallin suorituskykyä näkymättömissä tehtävissä nollakuvakehotteilla.
Suorita seuraavat vaiheet viimeistelläksesi hienosäätötyösi. Voit saada koko hienosäätökoodin osoitteesta GitHub-arkisto.
Ensin tarkastellaan ohjeiden hienosäätöön vaadittavaa tietojoukkomuotoa. Harjoitustiedot tulee muotoilla JSON lines (.jsonl) -muotoon, jossa jokainen rivi on sanakirja, joka edustaa datanäytettä. Kaikkien harjoitustietojen on oltava yhdessä kansiossa. Se voidaan kuitenkin tallentaa useisiin .jsonl-tiedostoihin. Seuraava on esimerkki JSON-rivimuodossa:
Harjoituskansio voi sisältää a template.json tiedosto, joka kuvaa tulo- ja tulostusmuodot. Seuraava on esimerkkimalli:
Jokaisen JSON-rivitiedostojen näytteen on sisällettävä mallia vastaavat system_prompt, questionja response kentät. Tässä esittelyssä käytämme Dolphin Coder -tietojoukko Hugging Facesta.
Kun olet valmistellut tietojoukon ja ladannut sen S3-säilöyn, voit aloittaa hienosäädön seuraavalla koodilla:
Voit ottaa hienosäädetyn mallin käyttöön suoraan estimaattorista seuraavan koodin mukaisesti. Katso lisätietoja muistikirjasta osoitteessa GitHub-arkisto.
Hienosäätötekniikat
Kielimallit, kuten Llama, ovat kooltaan yli 10 Gt tai jopa 100 Gt. Tällaisten suurten mallien hienosäätö vaatii ilmentymiä, joissa on huomattavasti korkea CUDA-muisti. Lisäksi näiden mallien koulutus voi olla hyvin hidasta mallin koosta johtuen. Siksi käytämme seuraavia optimointeja tehokkaaseen hienosäätöön:
- Low-Rank Adaption (LoRA) – Tämä on eräänlainen parametritehokas hienosäätö (PEFT) suurten mallien tehokkaaseen hienosäätöön. Tällä menetelmällä jäähdytät koko mallin ja lisäät malliin vain pienen joukon säädettäviä parametreja tai kerroksia. Esimerkiksi sen sijaan, että harjoittaisit kaikkia 7 miljardia parametria Llama 2 7B:lle, voit hienosäätää alle 1 % parametreista. Tämä auttaa vähentämään muistin tarvetta merkittävästi, koska sinun tarvitsee tallentaa vain 1 %:n parametreista kaltevuudet, optimointitilat ja muut harjoitteluun liittyvät tiedot. Lisäksi tämä auttaa vähentämään harjoitusaikaa ja kustannuksia. Lisätietoja tästä menetelmästä on kohdassa LoRA: Suurien kielimallien matala-arvoinen mukautus.
- Int8 kvantisointi – Jopa optimoinnilla, kuten LoRA, mallit, kuten Llama 70B, ovat edelleen liian suuria harjoitteluun. Voit vähentää muistijalanjälkeä harjoituksen aikana käyttämällä Int8-kvantisointia harjoituksen aikana. Kvantisointi tyypillisesti vähentää liukulukutietotyyppien tarkkuutta. Vaikka tämä vähentää mallin painojen tallentamiseen tarvittavaa muistia, se heikentää suorituskykyä tietojen menettämisen vuoksi. Int8-kvantisointi käyttää vain neljänneksen tarkkuutta, mutta se ei aiheuta suorituskyvyn heikkenemistä, koska se ei yksinkertaisesti pudota bittejä. Se pyöristää tiedot tyypistä toiseen. Lisätietoja Int8-kvantisoinnista on kohdassa LLM.int8(): 8-bittinen matriisikertolasku muuntajille mittakaavassa.
- Täysin jaettu datan rinnakkaistiedot (FSDP) – Tämä on eräänlainen data-rinnakkaisopetusalgoritmi, joka sirpalee mallin parametrit tietojen rinnakkaisten työntekijöiden kesken ja voi valinnaisesti siirtää osan opetuslaskennasta suorittimille. Vaikka parametrit on jaettu eri grafiikkasuorittimille, kunkin mikroerän laskenta on GPU-työntekijän paikallista. Se sirpalee parametreja tasaisemmin ja saavuttaa optimaalisen suorituskyvyn tiedonsiirron ja laskennan päällekkäisyyksien avulla harjoituksen aikana.
Seuraavassa taulukossa on yhteenveto kunkin mallin yksityiskohdista eri asetuksilla.
| Malli | Oletusasetus | LORA + FSDP | LORA + Ei FSDP:tä | Int8 kvantisointi + LORA + ei FSDP:tä |
| Koodi Llama 2 7B | LORA + FSDP | Kyllä | Kyllä | Kyllä |
| Koodi Llama 2 13B | LORA + FSDP | Kyllä | Kyllä | Kyllä |
| Koodi Llama 2 34B | INT8 + LORA + EI FSDP:tä | Ei | Ei | Kyllä |
| Koodi Llama 2 70B | INT8 + LORA + EI FSDP:tä | Ei | Ei | Kyllä |
Llama-mallien hienosäätö perustuu seuraaviin skripteihin GitHub repo.
Tuetut hyperparametrit harjoitteluun
Code Llama 2 -hienosäätö tukee useita hyperparametreja, joista jokainen voi vaikuttaa hienosäädetyn mallin muistitarpeeseen, harjoitusnopeuteen ja suorituskykyyn:
- aikakausi – Kulkujen määrä, jonka hienosäätöalgoritmi suorittaa harjoitustietojoukon läpi. On oltava kokonaisluku, joka on suurempi kuin 1. Oletusarvo on 5.
- oppimisnopeus – Nopeus, jolla mallin painot päivitetään jokaisen harjoitusesimerkkierän käsittelyn jälkeen. Positiivinen float on oltava suurempi kuin 0. Oletusarvo on 1e-4.
- ohje_viritetty – Opastaako mallia vai ei. Täytyy olla
TrueorFalse. Oletus onFalse. - per_device_train_batch_size – Erän koko GPU-ydintä/prosessoria kohti harjoittelua varten. On oltava positiivinen kokonaisluku. Oletusarvo on 4.
- per_device_eval_batch_size – Erän koko GPU-ydintä/suoritinta kohti arvioitavaksi. On oltava positiivinen kokonaisluku. Oletusarvo on 1.
- max_train_samples – Vähennä harjoitusesimerkkien määrä tähän arvoon virheenkorjausta tai nopeampaa harjoittelua varten. Arvo -1 tarkoittaa kaikkien harjoitusnäytteiden käyttöä. On oltava positiivinen kokonaisluku tai -1. Oletusarvo on -1.
- max_val_samples – Katkaise tarkistusesimerkkien määrä tähän arvoon virheenkorjausta tai nopeampaa koulutusta varten. Arvo -1 tarkoittaa kaikkien vahvistusnäytteiden käyttöä. On oltava positiivinen kokonaisluku tai -1. Oletusarvo on -1.
- max_input_length – Syöttösekvenssin enimmäispituus tokenoinnin jälkeen. Tätä pidemmät sekvenssit katkaistaan. Jos -1,
max_input_lengthon asetettu minimiin 1024 ja tokenisaattorin määrittelemään mallin enimmäispituuteen. Jos asetettu arvo on positiivinen,max_input_lengthon asetettu annetun arvon minimiin jamodel_max_lengthtokenisaattorin määrittelemä. On oltava positiivinen kokonaisluku tai -1. Oletusarvo on -1. - validation_split_ratio – Jos vahvistuskanava on
none, junatiedoista jaetun junan vahvistuksen suhteen on oltava välillä 0–1. Oletusarvo on 0.2. - train_data_split_seed – Jos validointitietoja ei ole, tämä korjaa syötetyn harjoitusdatan satunnaisen jakamisen algoritmin käyttämiin opetus- ja validointitietoihin. Täytyy olla kokonaisluku. Oletusarvo on 0.
- preprocessing_num_workers – Esikäsittelyyn käytettävien prosessien määrä. Jos
None, pääprosessia käytetään esikäsittelyyn. Oletus onNone. - lora_r – Lora R. Täytyy olla positiivinen kokonaisluku. Oletusarvo on 8.
- lora_alpha – Lora Alpha. On oltava positiivinen kokonaisluku. Oletusarvo on 32
- lora_dropout – Lora Dropout. on oltava positiivinen float välillä 0 ja 1. Oletus on 0.05.
- int8_quantization - Jos
True, malli on ladattu 8-bittisellä tarkkuudella harjoittelua varten. 7B:n ja 13B:n oletusarvo onFalse. 70B:n oletusarvo onTrue. - enable_fsdp – Jos totta, koulutus käyttää FSDP:tä. 7B:n ja 13B:n oletusarvo on Tosi. 70B:n oletusarvo on False. Ota huomioon, että
int8_quantizationFSDP ei tue sitä.
Kun valitset hyperparametreja, ota huomioon seuraavat seikat:
- Asetus
int8_quantization=Truevähentää muistin tarvetta ja nopeuttaa harjoittelua. - Vähentämällä
per_device_train_batch_sizejamax_input_lengthvähentää muistin tarvetta ja siksi sitä voidaan käyttää pienemmissä tapauksissa. Hyvin alhaisten arvojen asettaminen voi kuitenkin pidentää harjoitusaikaa. - Jos et käytä Int8-kvantisointia (
int8_quantization=False), käytä FSDP:tä (enable_fsdp=True) nopeampaa ja tehokkaampaa harjoittelua varten.
Koulutukseen tuetut ilmentymätyypit
Seuraavassa taulukossa on yhteenveto tuetuista ilmentymätyypeistä eri mallien koulutuksessa.
| Malli | Oletusinstanssityyppi | Tuetut ilmentymätyypit |
| Koodi Llama 2 7B | ml.g5.12xsuuri |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Koodi Llama 2 13B | ml.g5.12xsuuri |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Koodi Llama 2 70B | ml.g5.48xsuuri |
ml.g5.48xsuuri ml.p4d.24xlarge |
Kun valitset ilmentymän tyyppiä, ota huomioon seuraavat seikat:
- G5-instanssit tarjoavat tehokkaimman koulutuksen tuetuista ilmentymätyypeistä. Siksi, jos sinulla on G5-esiintymiä käytettävissä, sinun tulee käyttää niitä.
- Harjoitteluaika riippuu pitkälti GPU:iden määrästä ja käytettävissä olevasta CUDA-muistista. Siksi koulutus instansseissa, joissa on sama määrä GPU:ita (esimerkiksi ml.g5.2xlarge ja ml.g5.4xlarge), on suunnilleen sama. Siksi voit käyttää halvempaa esiintymää harjoitteluun (ml.g5.2xlarge).
- Käytettäessä p3-instanssia koulutus suoritetaan 32-bittisellä tarkkuudella, koska bfloat16:ta ei tueta näissä tapauksissa. Siksi koulutustyö kuluttaa kaksinkertaisen määrän CUDA-muistia, kun harjoittelet p3-esiintymillä verrattuna g5-esiintymiin.
Lisätietoja koulutuksen kustannuksista tapauskohtaisesti on kohdassa Amazon EC2 G5 -esiintymät.
Arviointi
Arviointi on tärkeä askel arvioitaessa hienosäädettyjen mallien suorituskykyä. Esittelemme sekä laadullisia että kvantitatiivisia arvioita, jotka osoittavat hienosäädetyissä malleissa parannuksia ei-hienosäätöihin verrattuna. Kvalitatiivisessa arvioinnissa näytämme esimerkkivastauksen sekä hienosäädetyistä että ei-hienoviritetyistä malleista. Kvantitatiivisessa arvioinnissa käytämme HumanEval, OpenAI:n kehittämä testipaketti Python-koodin luomiseksi testatakseen kykyä tuottaa oikeita ja tarkkoja tuloksia. HumanEval-arkisto on MIT-lisenssin alainen. Hienosäädimme Python-versioita kaikista Code LIama -malleista erikokoisina (koodi LIama Python 7B, 13B, 34B ja 70B Dolphin Coder -tietojoukko) ja esittele arvioinnin tulokset seuraavissa osissa.
Laadullinen arviointi
Kun hienosäädetty mallisi on otettu käyttöön, voit alkaa käyttää päätepistettä koodin luomiseen. Seuraavassa esimerkissä esitämme vastaukset sekä perus- että hienosäädetyistä Code LIama 34B Python -varianteista testinäytteessä Dolphin Coder -tietojoukko:
Hienosäädetty Code Llama -malli tuottaa edellisen kyselyn koodin lisäksi yksityiskohtaisen selityksen lähestymistavasta ja pseudokoodin.
Code Llama 34b Python ei hienosäädetty vastaus:
Code Llama 34B Python hienosäädetty vastaus
Maa totuus
Mielenkiintoista on, että hienosäädetymme Code Llama 34B Python -versiomme tarjoaa dynaamisen ohjelmointipohjaisen ratkaisun pisimpään palindromiseen osamerkkijonoon, joka eroaa valitun testiesimerkin pohjatotuuden tarjoamasta ratkaisusta. Hienosäädetty mallimme perustelee ja selittää yksityiskohtaisesti dynaamisen ohjelmointipohjaisen ratkaisun. Toisaalta hienosäätämätön malli hallusinoi mahdollisia tuotoksia heti sen jälkeen print lauseke (näkyy vasemmassa solussa), koska tulos axyzzyx ei ole pisin palindromi annetussa merkkijonossa. Ajan monimutkaisuuden kannalta dynaaminen ohjelmointiratkaisu on yleensä parempi kuin alkuperäinen lähestymistapa. Dynaamisen ohjelmointiratkaisun aikamonimutkaisuus on O(n^2), missä n on syötemerkkijonon pituus. Tämä on tehokkaampi kuin alkuperäinen ratkaisu ei-hienoviritetystä mallista, jonka neliöllinen aikamonimutkaisuus oli myös O(n^2), mutta jossa lähestymistapa oli vähemmän optimoitu.
Tämä näyttää lupaavalta! Muista, että hienosääsimme vain Code LIama Python -versiota 10 prosentilla Dolphin Coder -tietojoukko. On paljon muutakin tutkittavaa!
Huolimatta vastauksen perusteellisista ohjeista, meidän on vielä tarkastettava ratkaisussa olevan Python-koodin oikeellisuus. Seuraavaksi käytämme arviointikehystä nimeltä Human Eval suorittaa integrointitestejä Code LIaman luodulle vastaukselle ja tutkia sen laatua järjestelmällisesti.
Kvantitatiivinen arviointi HumanEvalin avulla
HumanEval on arviointivaljaat, joilla voidaan arvioida LLM:n ongelmanratkaisukykyä Python-pohjaisissa koodausongelmissa, kuten artikkelissa on kuvattu. Koodiin koulutettujen suurten kielimallien arviointi. Tarkemmin sanottuna se koostuu 164 alkuperäisestä Python-pohjaisesta ohjelmointiongelmasta, jotka arvioivat kielimallin kykyä luoda koodia toimitettujen tietojen, kuten funktion allekirjoituksen, dokumenttijonon, rungon ja yksikkötestien, perusteella.
Jokaisen Python-pohjaisen ohjelmointikysymyksen kohdalla lähetämme sen Code LIama -malliin, joka on otettu käyttöön SageMaker-päätepisteessä saadaksemme k vastausta. Seuraavaksi suoritamme jokaisen k vastauksen integrointitesteissä HumanEval-arkistossa. Jos jokin k vastauksesta läpäisee integrointitestit, lasketaan testitapaus onnistuneeksi; muuten epäonnistui. Sitten toistamme prosessin laskeaksemme onnistuneiden tapausten suhteen lopullisena arviointipisteenä pass@k. Normaalin käytännön mukaisesti asetimme arvioinnissamme k:ksi 1, jotta voimme luoda vain yhden vastauksen per kysymys ja testata, läpäiseekö se integrointitestin.
Seuraavassa on esimerkkikoodi HumanEval-arkiston käyttöä varten. Voit käyttää tietojoukkoa ja luoda yhden vastauksen käyttämällä SageMaker-päätepistettä. Katso lisätietoja muistikirjasta osoitteessa GitHub-arkisto.
Seuraavassa taulukossa on esitetty hienosäädettyjen Code LIama Python -mallien parannukset verrattuna hienosäätämättömiin malleihin eri mallikokoissa. Oikeuden varmistamiseksi otamme käyttöön myös hienosäätämättömät Code LIama -mallit SageMaker-päätepisteissä ja suoritamme Human Eval -arvioinnit. The pass@1 numerot (seuraavan taulukon ensimmäinen rivi) vastaavat taulukossa ilmoitettuja numeroita Code Lama -tutkimuspaperi. Päättelyparametrit asetetaan johdonmukaisesti muotoon "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Kuten tuloksista näemme, kaikki hienosäädetyt Code LIama Python -versiot osoittavat merkittävää parannusta hienosäätämättömiin malleihin verrattuna. Erityisesti Code LIama Python 70B ylittää hienosäätämättömän mallin noin 12 %.
| . | 7B Python | 13B Python | 34B | 34B Python | 70B Python |
| Esikoulutettu mallin suorituskyky (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Hienosäädetty mallin suorituskyky (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Nyt voit kokeilla Code LIama -mallien hienosäätöä omassa tietojoukossasi.
Puhdistaa
Jos päätät, että et enää halua pitää SageMaker-päätepistettä käynnissä, voit poistaa sen käyttämällä AWS SDK Pythonille (Boto3), AWS-komentoriviliitäntä (AWS CLI) tai SageMaker-konsoli. Katso lisätietoja Poista päätepisteet ja resurssit. Lisäksi voit sulje SageMaker Studion resurssit joita ei enää tarvita.
Yhteenveto
Tässä viestissä keskustelimme Metan Code Llama 2 -mallien hienosäädöstä SageMaker JumpStartin avulla. Osoitimme, että voit käyttää SageMaker Studion SageMaker JumpStart -konsolia tai SageMaker Python SDK:ta näiden mallien hienosäätämiseen ja käyttöönottoon. Keskustelimme myös hienosäätötekniikasta, ilmentymätyypeistä ja tuetuista hyperparametreistä. Lisäksi hahmottelimme suosituksia koulutuksen optimointiin erilaisten tekemiemme testien perusteella. Kuten näemme näiden kolmen mallin hienosäädön tuloksista kahdessa tietojoukossa, hienosäätö parantaa yhteenvetoa verrattuna hienosäätämättömiin malleihin. Seuraavana vaiheena voit yrittää hienosäätää näitä malleja omassa tietojoukossasi käyttämällä GitHub-arkistossa olevaa koodia testataksesi ja vertaillaksesi tuloksia käyttötapauksiesi mukaan.
Tietoja Tekijät
 Tohtori Xin Huang on vanhempi soveltuva tutkija Amazon SageMaker JumpStart ja Amazon SageMaker sisäänrakennetuille algoritmeille. Hän keskittyy skaalautuvien koneoppimisalgoritmien kehittämiseen. Hänen tutkimusintressiään ovat luonnollisen kielen prosessointi, selitettävissä oleva syvä oppiminen taulukkotiedoista ja ei-parametrisen aika-avaruusklusteroinnin robusti analyysi. Hän on julkaissut monia artikkeleita ACL-, ICDM-, KDD-konferensseissa ja Royal Statistical Society: Series A.
Tohtori Xin Huang on vanhempi soveltuva tutkija Amazon SageMaker JumpStart ja Amazon SageMaker sisäänrakennetuille algoritmeille. Hän keskittyy skaalautuvien koneoppimisalgoritmien kehittämiseen. Hänen tutkimusintressiään ovat luonnollisen kielen prosessointi, selitettävissä oleva syvä oppiminen taulukkotiedoista ja ei-parametrisen aika-avaruusklusteroinnin robusti analyysi. Hän on julkaissut monia artikkeleita ACL-, ICDM-, KDD-konferensseissa ja Royal Statistical Society: Series A.
 Vishaal Yalamanchali on Startup Solutions -arkkitehti, joka työskentelee varhaisen vaiheen generatiivisen tekoälyn, robotiikan ja autonomisten ajoneuvojen yritysten kanssa. Vishaal työskentelee asiakkaidensa kanssa toimittaakseen huippuluokan ML-ratkaisuja ja on henkilökohtaisesti kiinnostunut vahvistusoppimisesta, LLM-arvioinnista ja koodin luomisesta. Ennen AWS:ää Vishaal opiskeli UCI:ssa, keskittyen bioinformatiikkaan ja älykkäisiin järjestelmiin.
Vishaal Yalamanchali on Startup Solutions -arkkitehti, joka työskentelee varhaisen vaiheen generatiivisen tekoälyn, robotiikan ja autonomisten ajoneuvojen yritysten kanssa. Vishaal työskentelee asiakkaidensa kanssa toimittaakseen huippuluokan ML-ratkaisuja ja on henkilökohtaisesti kiinnostunut vahvistusoppimisesta, LLM-arvioinnista ja koodin luomisesta. Ennen AWS:ää Vishaal opiskeli UCI:ssa, keskittyen bioinformatiikkaan ja älykkäisiin järjestelmiin.
 Meenakshisundaram Thandavarayan työskentelee AWS:ssä AI/ML-asiantuntijana. Hänellä on intohimo suunnitella, luoda ja edistää ihmiskeskeisiä data- ja analytiikkakokemuksia. Meena keskittyy kehittämään kestäviä järjestelmiä, jotka tuottavat mitattavissa olevia kilpailuetuja AWS:n strategisille asiakkaille. Meena on yhdistäjä ja design-ajattelija, joka pyrkii ohjaamaan yrityksiä uusille tavoille toimia innovaation, hautomisen ja demokratisoinnin kautta.
Meenakshisundaram Thandavarayan työskentelee AWS:ssä AI/ML-asiantuntijana. Hänellä on intohimo suunnitella, luoda ja edistää ihmiskeskeisiä data- ja analytiikkakokemuksia. Meena keskittyy kehittämään kestäviä järjestelmiä, jotka tuottavat mitattavissa olevia kilpailuetuja AWS:n strategisille asiakkaille. Meena on yhdistäjä ja design-ajattelija, joka pyrkii ohjaamaan yrityksiä uusille tavoille toimia innovaation, hautomisen ja demokratisoinnin kautta.
 Tohtori Ashish Khetan on vanhempi soveltuva tutkija, jolla on sisäänrakennetut Amazon SageMaker -algoritmit ja auttaa kehittämään koneoppimisalgoritmeja. Hän sai tohtorin tutkinnon Illinois Urbana-Champaignin yliopistosta. Hän on aktiivinen koneoppimisen ja tilastollisen päättelyn tutkija, ja hän on julkaissut monia artikkeleita NeurIPS-, ICML-, ICLR-, JMLR-, ACL- ja EMNLP-konferensseissa.
Tohtori Ashish Khetan on vanhempi soveltuva tutkija, jolla on sisäänrakennetut Amazon SageMaker -algoritmit ja auttaa kehittämään koneoppimisalgoritmeja. Hän sai tohtorin tutkinnon Illinois Urbana-Champaignin yliopistosta. Hän on aktiivinen koneoppimisen ja tilastollisen päättelyn tutkija, ja hän on julkaissut monia artikkeleita NeurIPS-, ICML-, ICLR-, JMLR-, ACL- ja EMNLP-konferensseissa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

