Tekoälyn ja koneoppimisen (ML) muutosvoima on ilmeinen tuotannon kehittyvässä ympäristössä, mikä johtaa digitaaliseen vallankumoukseen, joka virtaviivaistaa toimintaa ja lisää tuottavuutta. Tämä edistys tuo kuitenkin ainutlaatuisia haasteita yrityksille, jotka navigoivat datapohjaisissa ratkaisuissa. Teollisuuslaitokset kamppailevat valtavien määrien jäsentämätöntä dataa, joka saadaan antureista, telemetriajärjestelmistä ja tuotantolinjoille hajallaan olevista laitteista. Reaaliaikainen data on kriittistä sovelluksissa, kuten ennakoivassa kunnossapidossa ja poikkeamien havaitsemisessa, mutta räätälöityjen ML-mallien kehittäminen jokaiseen teolliseen käyttötapaukseen tällaisilla aikasarjatiedoilla vaatii paljon aikaa ja resursseja datatieteilijöiltä, mikä estää laajan käyttöönoton.
Generatiivinen AI käyttämällä suuria esikoulutettuja perusmalleja (FM), kuten Claude voi luoda nopeasti monenlaista sisältöä keskustelutekstistä tietokonekoodiin yksinkertaisten tekstikehotteiden perusteella nolla laukaus -kehote. Tämä eliminoi datatieteilijöiden tarpeen kehittää manuaalisesti tiettyjä ML-malleja jokaista käyttötapausta varten, ja siksi tekoälyn käyttö demokratisoituu, mikä hyödyttää jopa pieniä valmistajia. Työntekijät lisäävät tuottavuutta tekoälyn luomien oivallusten avulla, insinöörit voivat havaita poikkeamat ennakoivasti, toimitusketjun johtajat optimoivat varastot ja tehtaan johto tekee tietoon perustuvia, dataan perustuvia päätöksiä.
Siitä huolimatta erilliset FM-laitteet kohtaavat rajoituksia monimutkaisen teollisuusdatan käsittelyssä kontekstin kokorajoitusten kanssa (tyypillisesti alle 200,000 XNUMX merkkiä), mikä asettaa haasteita. Voit korjata tämän käyttämällä FM:n kykyä luoda koodia vastauksena luonnollisen kielen kyselyihin (NLQ). Agentit pitävät PandasAI tulevat peliin, suorittamalla tätä koodia korkearesoluutioisille aikasarjatiedoille ja käsittelemällä virheitä FM:illä. PandasAI on Python-kirjasto, joka lisää generatiivisia tekoälyominaisuuksia pandoille, suosittuun tietojen analysointi- ja käsittelytyökaluun.
Monimutkaiset NLQ:t, kuten aikasarjojen tietojenkäsittely, monitasoinen aggregointi ja pivot- tai yhteistaulukkooperaatiot, voivat kuitenkin tuottaa epäjohdonmukaista Python-komentosarjan tarkkuutta nolla-kehotteella.
Koodin luomisen tarkkuuden parantamiseksi ehdotamme dynaamista rakentamista usean laukauksen kehotteet NLQ:ille. Monikuvakehote tarjoaa lisäkontekstia FM:lle näyttämällä sille useita esimerkkejä halutuista lähdöistä samanlaisille kehotteille, mikä parantaa tarkkuutta ja johdonmukaisuutta. Tässä viestissä usean otoksen kehotteet noudetaan upotuksesta, joka sisältää onnistuneen Python-koodin, joka on suoritettu samanlaisella tietotyypillä (esimerkiksi korkean resoluution aikasarjadata Internet of Things -laitteista). Dynaamisesti rakennettu monikuvakehote tarjoaa FM:lle oleellisimman kontekstin ja parantaa FM:n kykyä edistyneessä matemaattisessa laskennassa, aikasarjatietojen käsittelyssä ja datalyhenteiden ymmärtämisessä. Tämä parannettu vastaus helpottaa yritysten työntekijöiden ja operatiivisten ryhmien käyttöä datan kanssa ja saa oivalluksia vaatimatta laajoja datatieteen taitoja.
Aikasarjatietoanalyysin lisäksi FM:t osoittautuvat arvokkaiksi erilaisissa teollisissa sovelluksissa. Ylläpitotiimit arvioivat omaisuuden kunnon ja ottavat kuvia Amazonin tunnistus-pohjaiset toiminnallisuuden yhteenvedot ja poikkeamien perussyyanalyysi käyttämällä älykkäitä hakuja Haku laajennettu sukupolvi (RÄTTI). Näiden työnkulkujen yksinkertaistamiseksi AWS on ottanut käyttöön Amazonin kallioperä, jonka avulla voit rakentaa ja skaalata generatiivisia tekoälysovelluksia huippuluokan esikoulutetuilla FM-laitteilla, kuten Claude v2. Kanssa Amazon Bedrockin tietokannat, voit yksinkertaistaa RAG-kehitysprosessia ja tarjota tarkempaa poikkeamien perussyyanalyysiä tehtaan työntekijöille. Viestimme esittelee Amazon Bedrockin käyttämän älykkään avustajan teollisuuskäyttöön, joka vastaa NLQ-haasteisiin, luo kuvista osien yhteenvetoja ja parantaa FM-vastauksia laitediagnoosissa RAG-lähestymistavan avulla.
Ratkaisun yleiskatsaus
Seuraava kaavio kuvaa ratkaisuarkkitehtuuria.

Työnkulku sisältää kolme erillistä käyttötapausta:
Käyttötapaus 1: NLQ aikasarjatietojen kanssa
NLQ:n työnkulku aikasarjadatan kanssa koostuu seuraavista vaiheista:
- Käytämme poikkeamien havaitsemiseen ML-ominaisuuksilla varustettua kunnonvalvontajärjestelmää, esim Amazon Monitron, valvoa teollisuuslaitteiden kuntoa. Amazon Monitron pystyy havaitsemaan mahdolliset laiteviat laitteiden tärinä- ja lämpötilamittauksista.
- Keräämme aikasarjatietoja käsittelemällä Amazon Monitron tiedot läpi Amazon Kinesis -tietovirrat ja Amazon Data Firehose, muuntaa sen taulukkomuotoiseen CSV-muotoon ja tallentaa sen Amazonin yksinkertainen tallennuspalvelu (Amazon S3)-kauha.
- Loppukäyttäjä voi aloittaa keskustelun aikasarjatietojensa kanssa Amazon S3:ssa lähettämällä luonnollisen kielen kyselyn Streamlit-sovellukseen.
- Streamlit-sovellus välittää käyttäjien kyselyt eteenpäin Amazon Bedrock Titan -tekstin upotusmalli upottaaksesi tämän kyselyn ja suorittaa samankaltaisuushaun Amazon OpenSearch-palvelu indeksi, joka sisältää aikaisemmat NLQ:t ja esimerkkikoodit.
- Samankaltaisuushaun jälkeen suosituimmat samankaltaiset esimerkit, mukaan lukien NLQ-kysymykset, dataskeema ja Python-koodit, lisätään mukautettuun kehotteeseen.
- PandasAI lähettää tämän mukautetun kehotteen Amazon Bedrock Claude v2 -malliin.
- Sovellus käyttää PandasAI-agenttia vuorovaikutuksessa Amazon Bedrock Claude v2 -mallin kanssa luoden Python-koodia Amazon Monitron -datan analysointia ja NLQ-vastauksia varten.
- Kun Amazon Bedrock Claude v2 -malli palauttaa Python-koodin, PandasAI suorittaa Python-kyselyn sovelluksesta ladatuille Amazon Monitron -tiedoille, kerää koodituloksia ja vastaa mahdollisiin epäonnistuneisiin ajoihin.
- Streamlit-sovellus kerää vastauksen PandasAI:n kautta ja tarjoaa tulosteen käyttäjille. Jos tulos on tyydyttävä, käyttäjä voi merkitä sen hyödylliseksi ja tallentaa NLQ:n ja Clauden luoman Python-koodin OpenSearch-palveluun.
Käyttötapaus 2: Yhteenveto viallisista osista
Yhteenveto sukupolven käyttötapauksestamme koostuu seuraavista vaiheista:
- Kun käyttäjä tietää, mikä teollisuuskohde käyttäytyy epänormaalia, hän voi ladata kuvia viallisesta osasta tunnistaakseen, onko tässä osassa jotain fyysistä vikaa sen teknisten eritelmien ja toimintakunnon mukaisesti.
- Käyttäjä voi käyttää Amazon Recognition DetectText API poimimaan tekstidataa näistä kuvista.
- Poimitut tekstitiedot sisältyvät Amazon Bedrock Claude v2 -mallin kehotteeseen, jolloin malli voi luoda 200 sanan yhteenvedon viallisesta osasta. Käyttäjä voi käyttää näitä tietoja osan lisätarkastukseen.
Käyttötapaus 3: Perussyyn diagnoosi
Perussyydiagnoosimme käyttötapaus koostuu seuraavista vaiheista:
- Käyttäjä hankkii virheelliseen omaisuuteen liittyviä yritystietoja eri asiakirjamuodoissa (PDF, TXT ja niin edelleen) ja lataa ne S3-ämpäriin.
- Näiden tiedostojen tietokanta luodaan Amazon Bedrockissa Titan-tekstiupotusmallilla ja OpenSearch-palvelun oletusvektorisäilöllä.
- Käyttäjä esittää kysymyksiä, jotka liittyvät viallisten laitteiden perussyyn diagnosointiin. Vastaukset luodaan Amazon Bedrock -tietokannan kautta RAG-lähestymistapalla.
Edellytykset
Jotta voit seurata tätä viestiä, sinun tulee täyttää seuraavat edellytykset:
Ota käyttöön ratkaisuinfrastruktuuri
Määritä ratkaisuresurssit suorittamalla seuraavat vaiheet:
- Ota käyttöön AWS-pilven muodostuminen sapluuna opensearchsagemaker.yml, joka luo OpenSearch Service -kokoelman ja -hakemiston, Amazon Sage Maker kannettava tietokoneesimerkki ja S3-ämpäri. Voit nimetä tämän AWS CloudFormation -pinon seuraavasti:
genai-sagemaker. - Avaa SageMaker-muistikirjan esiintymä JupyterLabissa. Löydät seuraavat tiedot GitHub repo jo ladattu tässä tapauksessa: generatiivisten toimintojen potentiaalin vapauttaminen teollisessa toiminnassa.
- Suorita muistikirja seuraavasta tämän arkiston hakemistosta: generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb-potentiaalin vapauttaminen. Tämä muistikirja lataa OpenSearch Service -hakemiston käyttämällä SageMaker-muistikirjaa avainarvoparien tallentamiseen olemassa olevat 23 NLQ-esimerkkiä.
- Lataa asiakirjat tietokansiosta omaisuusosadoc GitHub-arkistossa CloudFormation-pinon lähdöissä lueteltuun S3-alueeseen.

Seuraavaksi luot tietokannan asiakirjoille Amazon S3:ssa.
- Valitse Amazon Bedrock -konsolista Tietoa navigointipaneelissa.
- Valita Luo tietopohja.
- varten Tietopohjan nimi, kirjoita nimi.
- varten Suorituksen roolivalitse Luo uusi palvelurooli ja käytä sitä.

- varten Tietolähteen nimi, anna tietolähteesi nimi.
- varten S3 URI, kirjoita sen ryhmän S3-polku, johon latasit syyasiakirjat.
- Valita seuraava.
 Titan-upotusmalli valitaan automaattisesti.
Titan-upotusmalli valitaan automaattisesti. - valita Luo nopeasti uusi vektorikauppa.

- Tarkista asetuksesi ja luo tietokanta valitsemalla Luo tietopohja.
- Kun tietokanta on luotu onnistuneesti, valitse Synkronoi synkronoidaksesi S3-ämpäri tietokannan kanssa.

- Kun olet luonut tietokannan, voit testata RAG-lähestymistapaa perussyyn diagnosoimiseksi esittämällä kysymyksiä, kuten "Toimurini liikkuu hitaasti, mikä voi olla ongelmana?"

Seuraava vaihe on ottaa sovellus käyttöön tarvittavilla kirjastopaketteilla joko tietokoneellasi tai EC2-esiintymässä (Ubuntu Server 22.04 LTS).
- Määritä AWS-kirjautumistietosi paikallisen PC:n AWS CLI:n kanssa. Yksinkertaisuuden vuoksi voit käyttää samaa järjestelmänvalvojan roolia, jota käytit CloudFormation-pinon käyttöönotossa. Jos käytät Amazon EC2:ta, liitä ilmentymään sopiva IAM-rooli.
- klooni GitHub repo:
- Muuta hakemistoksi
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcja suoritasetup.shkomentosarja tähän kansioon asentaaksesi tarvittavat paketit, mukaan lukien LangChain ja PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Suorita Streamlit-sovellus seuraavalla komennolla:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Anna OpenSearch-palvelukokoelma ARN, jonka loit Amazon Bedrockissa edellisessä vaiheessa.
Keskustele omaisuuden terveysassistentin kanssa
Kun olet suorittanut päästä päähän -asennuksen, voit käyttää sovellusta portin 8501 paikallispalvelimen kautta, joka avaa selainikkunan, jossa on verkkokäyttöliittymä. Jos otit sovelluksen käyttöön EC2-esiintymässä, salli portin 8501 pääsy suojausryhmän saapuvan säännön kautta. Voit siirtyä eri välilehdille eri käyttötapauksissa.
Tutustu käyttötapaukseen 1
Tutustu ensimmäiseen käyttötapaukseen valitsemalla Data Insight ja kaavio. Aloita lataamalla aikasarjatiedot. Jos sinulla ei ole aikasarjatietotiedostoa käytettäväksi, voit ladata seuraavan esimerkki CSV-tiedostosta anonyymien Amazon Monitron -projektitietojen kanssa. Jos sinulla on jo Amazon Monitron -projekti, katso Luo käyttökelpoisia oivalluksia ennakoivaan ylläpidon hallintaan Amazon Monitronin ja Amazon Kinesiksen avulla suoratoistaaksesi Amazon Monitron -tietosi Amazon S3:een ja käyttääksesi tietojasi tämän sovelluksen kanssa.
Kun lataus on valmis, aloita keskustelu tiedoillasi kirjoittamalla kysely. Vasemmassa sivupalkissa on useita esimerkkikysymyksiä avuksesi. Seuraavat kuvakaappaukset havainnollistavat vastausta ja Python-koodia, jonka FM on luonut syötettäessä kysymystä, kuten "Kerro minulle kunkin varoituksena tai hälytyksenä näkyvän sivuston tunnistimien yksilöllinen lukumäärä?" (kovan tason kysymys) tai "Voitko laskea antureille, joiden lämpötilasignaali on EI terveenä, ajan keston päivinä jokaiselle anturille, joka näyttää epänormaalia värinäsignaalia?" (haastetason kysymys). Sovellus vastaa kysymykseesi ja näyttää myös Python-komentosarjan data-analyysistä, jonka se suoritti tällaisten tulosten luomiseksi.


Jos olet tyytyväinen vastaukseen, voit merkitä sen nimellä Avulias, tallentaa NLQ:n ja Clauden luoman Python-koodin OpenSearch Service -hakemistoon.

Tutustu käyttötapaukseen 2
Voit tutkia toista käyttötapausta valitsemalla Kaapatun kuvan yhteenveto -välilehti Streamlit-sovelluksessa. Voit ladata kuvan teollisista kohteistasi, ja sovellus luo kuvatietojen perusteella 200-sanaisen yhteenvedon sen teknisestä tiedosta ja toimintakunnosta. Seuraava kuvakaappaus näyttää yhteenvedon, joka on luotu kuvasta hihnamoottorikäytöstä. Jos sinulla ei ole sopivaa kuvaa, voit testata tätä ominaisuutta käyttämällä seuraavaa esimerkkikuva.
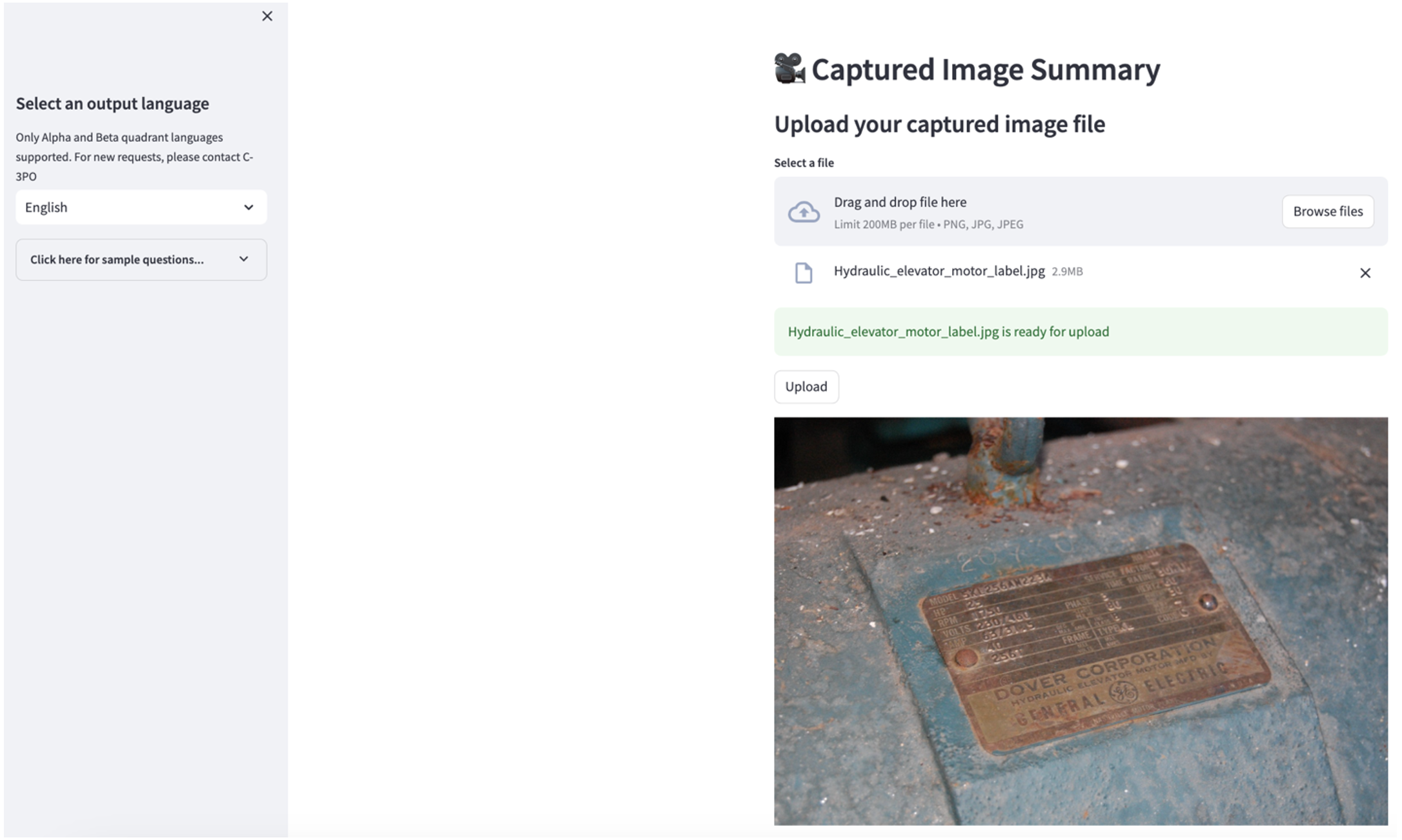
Hydraulisen hissin moottorin etiketti” by Clarence Risher on lisensoitu alla CC BY-SA 2.0.

Tutustu käyttötapaukseen 3
Voit tutkia kolmatta käyttötapausta valitsemalla Perimmäisen syyn diagnoosi -välilehti. Syötä kysely, joka liittyy rikkoutuneeseen teolliseen omaisuuteen, kuten "Toimurini liikkuu hitaasti, mikä voi olla ongelmana?" Kuten seuraavassa kuvakaappauksessa näkyy, sovellus toimittaa vastauksen lähdedokumentin otteen kanssa, jota käytetään vastauksen luomiseen.

Käyttötapaus 1: Suunnittelun yksityiskohdat
Tässä osiossa käsittelemme sovelluksen työnkulun suunnittelun yksityiskohtia ensimmäistä käyttötapausta varten.
Räätälöity nopea rakennus
Käyttäjän luonnollisen kielen kyselyssä on erilaisia vaikeita tasoja: helppo, vaikea ja haasteellinen.
Suorat kysymykset voivat sisältää seuraavat pyynnöt:
- Valitse yksilölliset arvot
- Laske kokonaismäärät
- Lajittele arvot
Näissä kysymyksissä PandasAI voi olla suoraan vuorovaikutuksessa FM:n kanssa ja luoda Python-skriptejä käsittelyä varten.
Vaikeat kysymykset vaativat perusaggregointitoiminnon tai aikasarjaanalyysin, kuten seuraavat:
- Valitse arvo ensin ja ryhmittele tulokset hierarkkisesti
- Tee tilastot alustavan tietueen valinnan jälkeen
- Aikaleimamäärä (esimerkiksi min ja max)
Vaikeissa kysymyksissä nopea malli, jossa on yksityiskohtaiset vaiheittaiset ohjeet, auttaa FM:itä tarjoamaan tarkkoja vastauksia.
Haastetason kysymykset vaativat edistyneen matemaattisen laskennan ja aikasarjakäsittelyn, kuten seuraavat:
- Laske poikkeaman kesto jokaiselle anturille
- Laske paikan poikkeavuusanturit kuukausittain
- Vertaa anturin lukemia normaalikäytössä ja epänormaaleissa olosuhteissa
Näissä kysymyksissä voit käyttää useita laukauksia mukautetussa kehotteessa vastauksen tarkkuuden parantamiseksi. Tällaiset useat otokset näyttävät esimerkkejä edistyneestä aikasarjan käsittelystä ja matemaattisesta laskennasta, ja ne tarjoavat kontekstin FM:lle, jotta se voi tehdä merkityksellisiä päätelmiä samanlaisesta analyysistä. Asianmukaisimpien esimerkkien lisääminen NLQ-kysymyspankista kehotteeseen voi olla haasteellista. Yksi ratkaisu on rakentaa upotuksia olemassa olevista NLQ-kysymysnäytteistä ja tallentaa nämä upotukset vektorisäilöön, kuten OpenSearch Service -palveluun. Kun kysymys lähetetään Streamlit-sovellukseen, kysymys vektorisoidaan Bedrock Embeddings. Kysymykseen liittyvät N tärkeimmät upotteet haetaan käyttämällä opensearch_vector_search.similarity_search ja lisätty kehotemalliin usean otoksen kehotteena.
Seuraava kaavio kuvaa tätä työnkulkua.

Upotuskerros rakennetaan kolmella avaintyökalulla:
- Upotusmalli – Käytämme Amazon Bedrockin kautta saatavia Amazon Titan Embeddingsia (amazon.titan-embed-text-v1) luodaksesi numeerisia esityksiä tekstidokumenteista.
- Vector kauppa – Käytämme vektorivarastossamme OpenSearch-palvelua LangChain-kehyksen kautta, mikä virtaviivaistaa NLQ-esimerkeistä luotujen upotusten tallentamista tähän muistikirjaan.
- indeksi – OpenSearch Service -hakemistolla on keskeinen rooli syötetyn upotuksen vertaamisessa dokumenttien upottamiseen ja asiaankuuluvien asiakirjojen hakemisen helpottamisessa. Koska Python-esimerkkikoodit tallennettiin JSON-tiedostona, ne indeksoitiin OpenSearch Servicessä vektoreina OpenSearchVevtorSearch.fromtexts API-kutsu.
Jatkuva kokoelma ihmisten tarkastamia esimerkkejä Streamlitin kautta
Sovellusten kehittämisen alussa aloitimme vain 23 tallennetulla esimerkillä OpenSearch-palvelun hakemistoon upotuksina. Kun sovellus tulee käyttöön kentällä, käyttäjät alkavat syöttää NLQ-tietoja sovelluksen kautta. Koska mallissa on kuitenkin vain vähän esimerkkejä, jotkin NLQ:t eivät välttämättä löydä samanlaisia kehotteita. Voit jatkuvasti rikastaa näitä upotuksia ja tarjota osuvampia käyttäjäkehotteita käyttämällä Streamlit-sovellusta ihmisten tarkastamien esimerkkien keräämiseen.
Sovelluksessa seuraava toiminto palvelee tätä tarkoitusta. Kun loppukäyttäjät pitävät tulosta hyödyllisenä ja valitsevat Avulias, sovellus noudattaa näitä vaiheita:
- Käytä PandasAI:n takaisinsoittomenetelmää Python-komentosarjan keräämiseen.
- Muotoile Python-skripti, syötä kysymys ja CSV-metatiedot uudelleen merkkijonoksi.
- Tarkista, onko tämä NLQ-esimerkki jo olemassa nykyisessä OpenSearch Service -hakemistossa käyttämällä opensearch_vector_search.similarity_search_with_score.
- Jos vastaavaa esimerkkiä ei ole, tämä NLQ lisätään OpenSearch Service -hakemistoon käyttämällä opensearch_vector_search.add_texts.
Siinä tapauksessa, että käyttäjä valitsee Ei hyödyllistä, mitään toimenpiteitä ei tehdä. Tämä iteratiivinen prosessi varmistaa, että järjestelmä paranee jatkuvasti sisällyttämällä siihen käyttäjien lisäämiä esimerkkejä.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Sisällyttämällä ihmisen auditoinnin, OpenSearch-palvelussa olevien esimerkkien määrä, joka on käytettävissä nopeaan upottamiseen, kasvaa sovelluksen käytön lisääntyessä. Tämä laajennettu upotettu tietojoukko parantaa haun tarkkuutta ajan myötä. Erityisesti haastavissa NLQ:issa FM:n vastaustarkkuus saavuttaa noin 90 %, kun samanlaisia esimerkkejä lisätään dynaamisesti muokattujen kehotteiden luomiseksi jokaiselle NLQ-kysymykselle. Tämä merkitsee huomattavaa 28 %:n kasvua verrattuna skenaarioihin, joissa ei käytetä usean otoksen kehotteita.
Käyttötapaus 2: Suunnittelun yksityiskohdat
Streamlit-sovelluksessa Kaapatun kuvan yhteenveto -välilehti, voit ladata kuvatiedoston suoraan. Tämä käynnistää Amazon Rekognition API (detektion_teksti API), poimii kuvatarrasta tekstin, joka sisältää koneen tekniset tiedot. Myöhemmin poimitut tekstitiedot lähetetään Amazon Bedrock Claude -malliin kehotteen yhteydessä, jolloin saadaan 200 sanan yhteenveto.
Käyttäjäkokemuksen näkökulmasta suoratoistotoimintojen salliminen tekstin yhteenvetotehtävää varten on ensiarvoisen tärkeää, jolloin käyttäjät voivat lukea FM-luoman yhteenvedon pienempinä paloina sen sijaan, että odottaisivat koko tulostetta. Amazon Bedrock helpottaa suoratoistoa API:nsa kautta (bedrock_runtime.invoke_model_with_response_stream).
Käyttötapaus 3: Suunnittelun yksityiskohdat
Tässä skenaariossa olemme kehittäneet chatbot-sovelluksen, joka keskittyy perussyyanalyysiin ja jossa käytetään RAG-lähestymistapaa. Tämä chatbot hyödyntää useita laakerivarusteisiin liittyviä asiakirjoja helpottaakseen perussyyanalyysiä. Tämä RAG-pohjainen perussyyanalyysin chatbot käyttää tietokantoja vektoritekstiesitysten tai upotusten luomiseen. Knowledge Bases for Amazon Bedrock on täysin hallittu ominaisuus, joka auttaa sinua toteuttamaan koko RAG-työnkulun käsittelystä hakuun ja nopeaan lisäykseen ilman, että sinun tarvitsee rakentaa mukautettuja integraatioita tietolähteisiin tai hallita tietovirtoja ja RAG-toteutustietoja.
Kun olet tyytyväinen Amazon Bedrockin tietokannan vastaukseen, voit integroida perussyyreaktion tietokannasta Streamlit-sovellukseen.
Puhdistaa
Kustannusten säästämiseksi poista tässä viestissä luomasi resurssit:
- Poista tietokanta Amazon Bedrockista.
- Poista OpenSearch-palvelun hakemisto.
- Poista genai-sagemaker CloudFormation -pino.
- Pysäytä EC2-ilmentymä, jos käytit Streamlit-sovellusta EC2-instanssilla.
Yhteenveto
Generatiiviset tekoälysovellukset ovat jo muuttaneet erilaisia liiketoimintaprosesseja ja parantaneet työntekijöiden tuottavuutta ja taitoja. FM-laitteiden rajoitukset aikasarjadata-analyysin käsittelyssä ovat kuitenkin estäneet niiden täyden hyödyntämisen teollisissa asiakkaissa. Tämä rajoitus on estänyt generatiivisen tekoälyn soveltamisen vallitsevaan tietotyyppiin, jota käsitellään päivittäin.
Tässä viestissä esittelimme generatiivisen AI-sovellusratkaisun, joka on suunniteltu helpottamaan tätä haastetta teollisuuskäyttäjille. Tämä sovellus käyttää avoimen lähdekoodin agenttia, PandasAI, vahvistaakseen FM:n aikasarjaanalyysikykyä. Sen sijaan, että sovellus lähettäisi aikasarjatietoja suoraan FM-laitteille, sovellus käyttää PandasAI:ta Python-koodin luomiseen strukturoimattomien aikasarjatietojen analysointiin. Python-koodin luomisen tarkkuuden parantamiseksi on otettu käyttöön mukautettu kehotteen luomisen työnkulku, jossa on ihmisen tarkastus.
Teollisuustyöntekijät voivat hyödyntää täysin generatiivisen tekoälyn potentiaalia erilaisissa käyttötilanteissa, kuten perussyyn diagnosoinnissa ja osien vaihtosuunnittelussa, koska heillä on oivalluksia omaisuutensa terveydestä. Amazon Bedrockin Knowledge Bases -tietokannan avulla kehittäjät voivat helposti rakentaa ja hallita RAG-ratkaisua.
Yritystietojen hallinnan ja toiminnan kehityssuunta on erehtymättä siirtymässä syvempään integraatioon generatiivisen tekoälyn kanssa kattavan näkemyksen saamiseksi toiminnan terveydestä. Tätä Amazon Bedrockin keihäänjohtajana olevaa muutosta vahvistaa merkittävästi LLM-yritysten, kuten Amazon Bedrock Claude 3 nostaa ratkaisuja entisestään. Saat lisätietoja vierailemalla osoitteessa Amazon Bedrockin dokumentaatio, ja tutustu Amazon Bedrock -työpaja.
Tietoja kirjoittajista
 Julia Hu on vanhempi AI/ML Solutions -arkkitehti Amazon Web Servicesissä. Hän on erikoistunut generatiiviseen tekoälyyn, soveltavaan datatieteeseen ja IoT-arkkitehtuuriin. Tällä hetkellä hän on osa Amazon Q -tiimiä ja aktiivinen jäsen/mentori Machine Learning Technical Field Communityssä. Hän työskentelee asiakkaiden kanssa, aloittavista yrityksistä yrityksiin, kehittääkseen AWSome generatiivisia tekoälyratkaisuja. Hän on erityisen intohimoinen suurten kielimallien hyödyntämiseen edistyneessä data-analytiikassa ja käytännön sovellusten tutkimisessa, jotka vastaavat todellisiin haasteisiin.
Julia Hu on vanhempi AI/ML Solutions -arkkitehti Amazon Web Servicesissä. Hän on erikoistunut generatiiviseen tekoälyyn, soveltavaan datatieteeseen ja IoT-arkkitehtuuriin. Tällä hetkellä hän on osa Amazon Q -tiimiä ja aktiivinen jäsen/mentori Machine Learning Technical Field Communityssä. Hän työskentelee asiakkaiden kanssa, aloittavista yrityksistä yrityksiin, kehittääkseen AWSome generatiivisia tekoälyratkaisuja. Hän on erityisen intohimoinen suurten kielimallien hyödyntämiseen edistyneessä data-analytiikassa ja käytännön sovellusten tutkimisessa, jotka vastaavat todellisiin haasteisiin.
 Sudeesh Sasidharan on Senior Solutions Arkkitehti AWS:ssä Energy-tiimissä. Sudeesh rakastaa kokeilla uusia teknologioita ja rakentaa innovatiivisia ratkaisuja, jotka ratkaisevat monimutkaisia liiketoiminnan haasteita. Kun hän ei suunnittele ratkaisuja tai puuhaile uusimpien teknologioiden parissa, voit löytää hänet tenniskentältä työstämässä kättäänsä.
Sudeesh Sasidharan on Senior Solutions Arkkitehti AWS:ssä Energy-tiimissä. Sudeesh rakastaa kokeilla uusia teknologioita ja rakentaa innovatiivisia ratkaisuja, jotka ratkaisevat monimutkaisia liiketoiminnan haasteita. Kun hän ei suunnittele ratkaisuja tai puuhaile uusimpien teknologioiden parissa, voit löytää hänet tenniskentältä työstämässä kättäänsä.
 Neil Desai on teknologiajohtaja, jolla on yli 20 vuoden kokemus tekoälystä (AI), datatieteestä, ohjelmistosuunnittelusta ja yritysarkkitehtuurista. Hän johtaa AWS:ssä maailmanlaajuisten tekoälypalveluihin erikoistuneiden ratkaisuarkkitehtien tiimiä, joka auttaa asiakkaita rakentamaan innovatiivisia generatiiviseen tekoälyyn perustuvia ratkaisuja, jakamaan parhaita käytäntöjä asiakkaiden kanssa ja laatimaan tuotesuunnitelmaa. Aiemmissa rooleissaan Vestasissa, Honeywellissa ja Quest Diagnosticsissa Neil on toiminut johtotehtävissä sellaisten innovatiivisten tuotteiden ja palveluiden kehittämisessä ja lanseerauksessa, jotka ovat auttaneet yrityksiä parantamaan toimintaansa, alentamaan kustannuksia ja lisäämään liikevaihtoa. Hän on intohimoinen teknologian käyttämiseen todellisten ongelmien ratkaisemiseen, ja hän on strateginen ajattelija, jolla on todistetusti menestystä.
Neil Desai on teknologiajohtaja, jolla on yli 20 vuoden kokemus tekoälystä (AI), datatieteestä, ohjelmistosuunnittelusta ja yritysarkkitehtuurista. Hän johtaa AWS:ssä maailmanlaajuisten tekoälypalveluihin erikoistuneiden ratkaisuarkkitehtien tiimiä, joka auttaa asiakkaita rakentamaan innovatiivisia generatiiviseen tekoälyyn perustuvia ratkaisuja, jakamaan parhaita käytäntöjä asiakkaiden kanssa ja laatimaan tuotesuunnitelmaa. Aiemmissa rooleissaan Vestasissa, Honeywellissa ja Quest Diagnosticsissa Neil on toiminut johtotehtävissä sellaisten innovatiivisten tuotteiden ja palveluiden kehittämisessä ja lanseerauksessa, jotka ovat auttaneet yrityksiä parantamaan toimintaansa, alentamaan kustannuksia ja lisäämään liikevaihtoa. Hän on intohimoinen teknologian käyttämiseen todellisten ongelmien ratkaisemiseen, ja hän on strateginen ajattelija, jolla on todistetusti menestystä.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

