Asiakkaat haluavat yhä enemmän käyttää syväoppimisen lähestymistapoja, kuten suuria kielimalleja (LLM) tietojen ja oivallusten poimimisen automatisoimiseksi. Monilla toimialoilla koneoppimisen (ML) kannalta hyödyllinen data voi sisältää henkilökohtaisia tunnistetietoja (PII). Asiakkaiden yksityisyyden takaamiseksi ja säännösten noudattamisen ylläpitämiseksi koulutuksen, hienosäädön ja syväoppimismallien käytön aikana on usein välttämätöntä ensin poistaa henkilötiedot lähdetiedoista.
Tämä viesti osoittaa, kuinka sitä käytetään Amazon SageMaker Data Wrangler ja Amazonin käsitys poistaaksesi henkilötiedot automaattisesti taulukkotiedoista osana sinun koneoppimisoperaatiot (ML Ops) työnkulku.
Ongelma: ML-tiedot, jotka sisältävät henkilökohtaisia tunnistetietoja
PII määritellään minkä tahansa tiedon esitykseksi, jonka avulla voidaan kohtuudella päätellä sen henkilön henkilöllisyys, jota tiedot koskevat, joko suorilla tai epäsuoralla tavalla. Henkilökohtaiset tunnistetiedot ovat tietoja, jotka joko tunnistavat henkilön suoraan (nimi, osoite, sosiaaliturvatunnus tai muu tunnistenumero tai koodi, puhelinnumero, sähköpostiosoite ja niin edelleen) tai tietoja, joita virasto aikoo käyttää tunnistaakseen tiettyjä henkilöitä yhdessä muiden kanssa. tietoelementit, nimittäin epäsuora tunnistaminen.
Asiakkaat, jotka toimivat liiketoiminta-alueilla, kuten rahoitus-, vähittäiskauppa-, laki- ja valtionhallinnossa, käsittelevät henkilökohtaisia tunnistetietoja säännöllisesti. Erilaisten viranomaisten määräysten ja sääntöjen vuoksi asiakkaiden on löydettävä mekanismi näiden arkaluontoisten tietojen käsittelemiseksi asianmukaisin turvatoimin välttääkseen säännösten mukaiset sakot, mahdolliset petokset ja kunnianloukkaukset. Henkilökohtaisten tunnistetietojen poistaminen on prosessi, jossa arkaluontoiset tiedot peitetään tai poistetaan asiakirjasta, jotta niitä voidaan käyttää ja jakaa samalla kun luottamukselliset tiedot suojataan.
Yritysten on tarjottava ilahduttavia asiakaskokemuksia ja parempia liiketoimintatuloksia käyttämällä ML:ää. Henkilökohtaisten tunnistetietojen poistaminen on usein tärkeä ensimmäinen askel suurempien ja monipuolisempien tietovirtojen avaamiseksi, joita tarvitaan käyttöä tai hienosäätöä varten. generatiivisia tekoälymalleja, murehtimatta siitä, vaarantuvatko heidän yrityksensä (tai asiakkaidensa) tiedot.
Ratkaisun yleiskatsaus
Tämä ratkaisu käyttää Amazon Comprehendia ja SageMaker Data Wrangleria PII-tietojen automaattiseen poistamiseen esimerkkitietojoukosta.
Amazon Comprehend on luonnollisen kielen käsittelypalvelu (NLP), joka käyttää ML:ää oivallusten ja suhteiden paljastamiseen strukturoimattomista tiedoista ilman infrastruktuurin hallintaa tai ML-kokemusta. Se tarjoaa toiminnot paikantamiseen erilaisia PII-entiteettityyppejä tekstin sisällä, esimerkiksi nimiä tai luottokorttien numeroita. Vaikka uusimmat generatiiviset tekoälymallit ovat osoittaneet jonkin verran henkilökohtaisten tunnistetietojen muokkauskykyä, ne eivät yleensä anna luotettavuuspisteitä henkilökohtaisten tunnistetietojen tunnistamiselle tai strukturoitua dataa, joka kuvaa, mitä on poistettu. Amazon Comprehendin PII-toiminto palauttaa molemmat, joten voit luoda editointityönkulkuja, jotka ovat täysin tarkastettavissa mittakaavassa. Lisäksi käyttämällä Amazon Comprehendia kanssa AWS PrivateLink tarkoittaa, että asiakasdata ei koskaan poistu AWS-verkosta ja on jatkuvasti suojattu samoilla tietojen käyttö- ja tietosuojasäädöillä kuin muutkin sovelluksesi.
Samanlainen kuin Amazon Comprehend, Amazon Macie käyttää sääntöihin perustuvaa moottoria tunnistamaan tallennettuja arkaluonteisia tietoja (mukaan lukien henkilökohtaisia tunnistetietoja). Amazonin yksinkertainen tallennuspalvelu (Amazon S3). Sen sääntöihin perustuva lähestymistapa perustuu kuitenkin tiettyjen avainsanoja, jotka osoittavat arkaluontoisia tietoja lähellä kyseisiä tietoja (30 merkin sisällä). Sitä vastoin Amazon Comprehendin NLP-pohjainen ML-lähestymistapa käyttää semmaattista ymmärrystä pitkistä tekstipaloista henkilökohtaisten tunnistetietojen tunnistamiseen, mikä tekee siitä hyödyllisemmän henkilökohtaisten tunnistetietojen löytämisessä strukturoimattomasta tiedosta.
Lisäksi Macie taulukkotiedoille, kuten CSV- tai tekstitiedostoille palauttaa vähemmän yksityiskohtaisia sijaintitietoja kuin Amazon Comprehend (joko rivin/sarakkeen ilmaisin tai rivinumero, mutta ei alku- ja loppumerkkisiirtymiä). Tämä tekee Amazon Comprehendistä erityisen hyödyllisen henkilökohtaisten tunnistetietojen poistamisessa jäsentämättömästä tekstistä, joka voi sisältää yhdistelmän PII-sanoja ja ei-PII-sanoja (esimerkiksi tukilippuja tai LLM-kehotteita), jotka on tallennettu taulukkomuotoon.
Amazon Sage Maker tarjoaa tarkoitukseen rakennettuja työkaluja ML-tiimeille automatisoida ja standardoida prosesseja ML-elinkaaren aikana. SageMaker MLOps -työkalujen avulla tiimit voivat helposti valmistella, kouluttaa, testata, vianmäärittää, ottaa käyttöön ja hallita ML-malleja mittakaavassa, mikä lisää datatieteilijöiden ja ML-insinöörien tuottavuutta ja säilyttää mallin suorituskyvyn tuotannossa. Seuraava kaavio havainnollistaa SageMaker MLOps -työnkulkua.
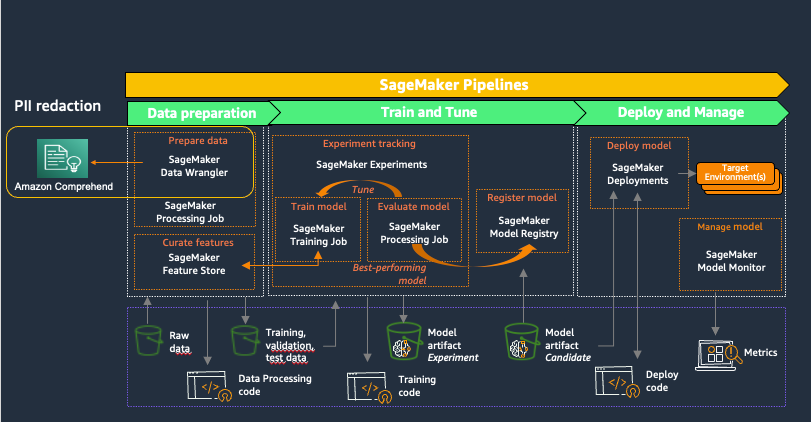
SageMaker Data Wrangler on ominaisuus Amazon SageMaker Studio joka tarjoaa päästä päähän -ratkaisun datajoukkojen tuomiseen, valmistelemiseen, muuntamiseen, esittelyyn ja analysoimiseen, jotka on tallennettu esimerkiksi Amazon S3:een tai Amazon Athena, yleinen ensimmäinen askel ML:n elinkaaressa. Voit käyttää SageMaker Data Wrangleria yksinkertaistamaan ja virtaviivaistamaan tietojoukon esikäsittelyä ja ominaisuuksien suunnittelua joko käyttämällä sisäänrakennettuja koodittomia muunnoksia tai mukauttamalla omilla Python-skripteilläsi.
Amazon Comprehendin käyttäminen henkilökohtaisten tunnistetietojen poistamiseen osana SageMaker Data Wrangler -tietojen valmistelutyönkulkua pitää kaiken tietojen myöhemmän käytön, kuten mallikoulutuksen tai päättelyn, organisaatiosi PII-vaatimusten mukaisina. Voit integroida SageMaker Data Wranglerin kanssa Amazon SageMaker -putkistot automatisoida päästä päähän ML-operaatioita, mukaan lukien tietojen valmistelu ja henkilötietojen poistaminen. Katso lisätietoja osoitteesta SageMaker Data Wranglerin integrointi SageMaker-putkilinjojen kanssa. Tämän viestin loppuosa esittelee SageMaker Data Wrangler -kulkua, joka käyttää Amazon Comprehendia poistamaan henkilökohtaisia tunnistetietoja taulukkomuotoiseen tietomuotoon tallennetusta tekstistä.
Tämä ratkaisu käyttää julkista synteettinen tietojoukko sekä mukautettu SageMaker Data Wrangler -kulku, joka on saatavana tiedostona GitHub. SageMaker Data Wrangler -virran käyttäminen henkilökohtaisten tunnistetietojen poistamiseen on seuraava:
- Avaa SageMaker Studio.
- Lataa SageMaker Data Wrangler -kulku.
- Tarkista SageMaker Data Wrangler -kulku.
- Lisää kohdesolmu.
- Luo SageMaker Data Wrangler -vientityö.
Tämä läpikäynti, mukaan lukien vientityön suorittaminen, kestää 20–25 minuuttia.
Edellytykset
Tätä läpikäyntiä varten sinulla on oltava seuraavat:
Avaa SageMaker Studio
Avaa SageMaker Studio suorittamalla seuraavat vaiheet:
- Valitse SageMaker-konsolissa studio navigointipaneelissa.
- Valitse verkkotunnus ja käyttäjäprofiili
- Valita Avaa Studio.
SageMaker Data Wranglerin uusien ominaisuuksien käytön aloittamiseksi on suositeltavaa päivitä uusimpaan versioon.
Lataa SageMaker Data Wrangler -kulku
Sinun on ensin noudettava SageMaker Data Wrangler -virtatiedosto GitHubista ja lähetettävä se SageMaker Studioon. Suorita seuraavat vaiheet:
- Siirry SageMaker Data Wrangleriin
redact-pii.flowtiedosto GitHubissa. - Lataa kulkutiedosto paikalliselle tietokoneellesi valitsemalla GitHubissa latauskuvake.
- Valitse SageMaker Studion navigointiruudusta tiedostokuvake.
- Valitse latauskuvake ja valitse sitten
redact-pii.flow.
Tarkista SageMaker Data Wrangler -kulku
Avaa SageMaker Studiossa redact-pii.flow. Muutaman minuutin kuluttua virtaus latautuu loppuun ja näyttää vuokaavion (katso seuraava kuvakaappaus). Vuo sisältää kuusi vaihetta: an S3 lähde vaihe, jota seuraa viisi muunnosvaihetta.

Valitse vuokaaviosta viimeinen vaihe, Poista PII. Kaikki vaiheet ruutu avautuu oikealle ja näyttää luettelon kulun vaiheista. Voit laajentaa jokaista vaihetta tarkastellaksesi tietoja, muuttaaksesi parametreja ja mahdollisesti lisätäksesi mukautetun koodin.
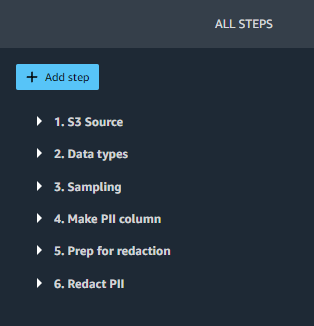
Käydään läpi virran jokainen vaihe.
Vaiheet 1 (S3 lähde) ja 2 (Tietotyypit) lisätään SageMaker Data Wranglerin toimesta aina, kun tietoja tuodaan uutta kulkua varten. Sisään S3 lähde, The S3 URI -kenttä osoittaa mallitietojoukkoon, joka on Amazon S3:een tallennettu CSV-tiedosto. Tiedostossa on noin 116,000 XNUMX riviä, ja kulku määrittää arvon Näytteenotto kentän arvoksi 1,000 1,000, mikä tarkoittaa, että SageMaker Data Wrangler ottaa näytteen XNUMX XNUMX rivistä, jotka näkyvät käyttöliittymässä. Tietotyypit asettaa tietotyypin kullekin tuotujen tietojen sarakkeelle.
Vaihe 3 (Näytteenotto) asettaa SageMaker Data Wranglerin vientityötä varten otottavien rivien lukumääräksi 5,000 XNUMX Arvioitu näytteen koko ala. Huomaa, että tämä eroaa käyttöliittymässä näytettäväksi otettujen rivien määrästä (vaihe 1). Jos haluat viedä tietoja useammilla riveillä, voit suurentaa tätä määrää tai poistaa vaiheen 3.
Vaiheet 4, 5 ja 6 käyttävät SageMaker Data Wrangler mukautetut muunnokset. Mukautettujen muunnosten avulla voit suorittaa oman Python- tai SQL-koodisi Data Wrangler -kulussa. Mukautettu koodi voidaan kirjoittaa neljällä tavalla:
- SQL:ssä PySpark SQL:n käyttäminen tietojoukon muokkaamiseen
- Pythonissa PySpark-tietokehyksen ja kirjastojen avulla tietojoukon muokkaamiseen
- Pythonissa käyttämällä a pandas tietokehystä ja kirjastoja muokataksesi tietojoukkoa
- Pythonissa tietojoukon sarakkeen muokkaaminen käyttäjän määrittämän funktion avulla
Python (pandas) -lähestymistapa edellyttää, että tietojoukkosi mahtuu muistiin, ja sitä voidaan käyttää vain yhdessä esiintymässä, mikä rajoittaa sen kykyä skaalata tehokkaasti. Kun työskentelet Pythonissa suurempien tietojoukkojen kanssa, suosittelemme käyttämään joko Python (PySpark) tai Python (käyttäjän määrittämä funktio) lähestymistapaa. SageMaker Data Wrangler optimoi Pythonin käyttäjän määrittämät toiminnot tarjotakseen Apache Spark -laajennuksen kaltaista suorituskykyä, ilman että sinun tarvitsee tuntea PySparkia tai Pandaja. Jotta tämä ratkaisu olisi mahdollisimman helppokäyttöinen, tämä viesti käyttää Python-käyttäjän määrittämää funktiota, joka on kirjoitettu puhtaalla Pythonilla.
Laajenna vaihe 4 (Tee PII-sarake) nähdäksesi sen tiedot. Tämä vaihe yhdistää erityyppiset henkilökohtaiset tunnistetiedot useista sarakkeista yhdeksi lauseeksi, joka tallennetaan uuteen sarakkeeseen, pii_col. Seuraavassa taulukossa on esimerkkirivi, joka sisältää tietoja.
| Asiakkaan nimi | asiakas_työ | Laskutusosoite | asiakkaan_sähköposti |
| Katie | Toimittaja | 19009 Vang Squares Suite 805 | [sähköposti suojattu] |
Tämä yhdistetään lauseeksi "Katie on toimittaja, joka asuu osoitteessa 19009 Vang Squares Suite 805 ja hän voi lähettää sähköpostia osoitteeseen [sähköposti suojattu]”. Lause on tallennettu pii_col, jota tämä viesti käyttää kohdesarakkeena muokattaessa.
Vaihe 5 (Valmistaudu editointiin) ottaa sarakkeen muokattavaksi (pii_col) ja luo uuden sarakkeen (pii_col_prep), joka on valmis tehokkaaseen editointiin Amazon Comprehendin avulla. Voit poistaa henkilökohtaisia tunnistetietoja toisesta sarakkeesta muuttamalla Syöttösarake tämän vaiheen kenttään.
On kaksi huomioon otettavaa tekijää tietojen tehokkaaseen poistamiseen Amazon Comprehendin avulla:
- - kustannukset henkilökohtaisten tunnistetietojen havaitsemisesta on määritetty yksikkökohtaisesti, jossa 1 yksikkö = 100 merkkiä, ja jokaisesta asiakirjasta veloitetaan vähintään 3 yksikköä. Koska taulukkotiedot sisältävät usein pieniä määriä tekstiä solua kohden, on yleensä aika- ja kustannustehokkaampaa yhdistää teksti useista soluista yhdeksi asiakirjaksi lähetettäväksi Amazon Comprehendille. Tämä välttää monien toistuvien toimintokutsujen aiheuttaman lisäkustannusten kertymisen ja varmistaa, että lähetettävä data on aina suurempi kuin 3 yksikön vähimmäismäärä.
- Koska teemme editoinnin SageMaker Data Wrangler -virran yhtenä vaiheena, kutsumme Amazon Comprehendia synkronisesti. Amazon Comprehend -sarjat a 100 kt (100,000 XNUMX merkkiä) raja synkronista funktiokutsua kohden, joten meidän on varmistettava, että kaikki lähettämämme teksti on tämän rajan alapuolella.
Nämä tekijät huomioon ottaen vaiheessa 5 valmistelee tiedot lähetettäväksi Amazon Comprehendille lisäämällä erotinmerkkijono jokaisen solun tekstin loppuun. Erottimena voit käyttää mitä tahansa merkkijonoa, joka ei esiinny muokattavassa sarakkeessa (mieluiten sellaista, jossa on mahdollisimman vähän merkkejä, koska ne sisältyvät Amazon Comprehend -merkkien kokonaismäärään). Tämän solun erottimen lisääminen antaa meille mahdollisuuden optimoida puhelun Amazon Comprehendille, ja sitä käsitellään tarkemmin vaiheessa 6.
Huomaa, että jos yksittäisen solun teksti on pidempi kuin Amazon Comprehend -raja, tämän vaiheen koodi katkaisee sen 100,000 15,000 merkiksi (vastaa suunnilleen 30 XNUMX sanaa tai XNUMX yksittäistä sivua). Vaikka tätä määrää tekstiä ei todennäköisesti tallenneta yhteen soluun, voit tarvittaessa muokata muunnoskoodia käsittelemään tätä reunatapausta toisella tavalla.
Vaihe 6 (Poista PII) ottaa syötteenä sarakkeen nimen redusoitavaksi (pii_col_prep) ja tallentaa muokatun tekstin uuteen sarakkeeseen (pii_redacted). Kun käytät mukautettua Python-funktion muunnosta, SageMaker Data Wrangler määrittelee tyhjän custom_func se vie pandat sarja (tekstisarake) syötteenä ja palauttaa samanpituisen muokatun pandassarjan. Seuraava kuvakaappaus näyttää osan Poista PII askel.
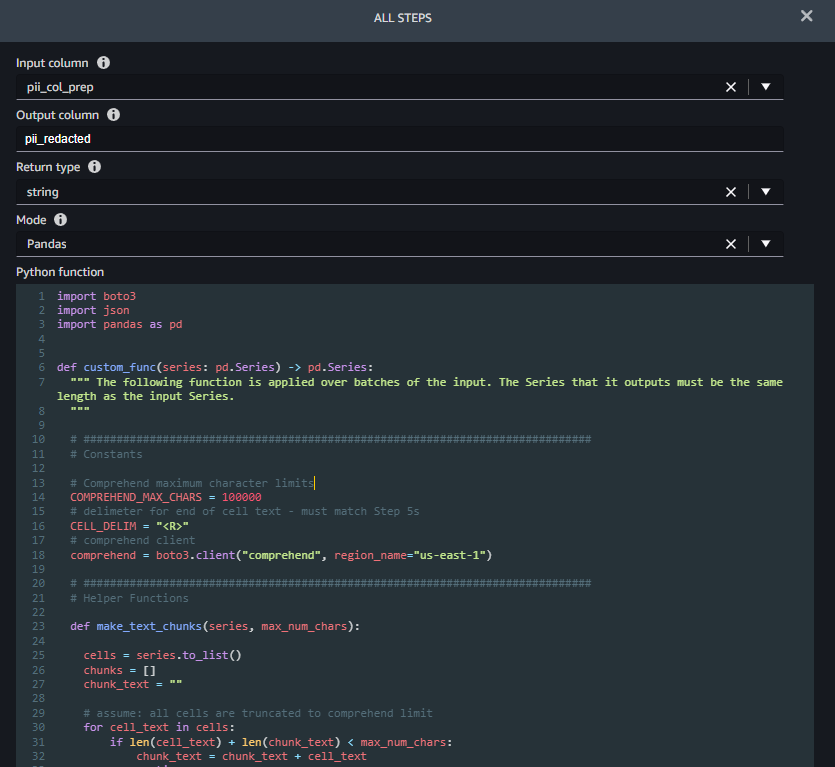
Toiminto custom_func sisältää kaksi aputoimintoa (sisäistä)
make_text_chunks– Tämä toiminto ketjuttaa tekstin sarjan yksittäisistä soluista (mukaan lukien niiden erottimet) pidemmiksi merkkijonoiksi (paloiksi) lähetettäväksi Amazon Comprehendille.redact_pii– Tämä toiminto ottaa tekstiä syötteenä, kutsuu Amazon Comprehendia tunnistamaan henkilökohtaisia tunnistetietoja, poistaa kaikki löydetyt ja palauttaa muokatun tekstin. Muokkaus tehdään korvaamalla mikä tahansa PII-teksti hakasulkeissa olevilla henkilökohtaisilla tunnistetiedoilla, esimerkiksi John Smith korvattaisiin tekstillä [NAME]. Voit muokata tätä toimintoa korvataksesi henkilökohtaiset tunnistetiedot millä tahansa merkkijonolla, mukaan lukien tyhjä merkkijono (“”) poistaaksesi sen. Voit myös muokata toimintoa tarkistaaksesi kunkin PII-entiteetin luottamuspisteet ja poistaa vain, jos se ylittää tietyn kynnyksen.
Kun sisäiset toiminnot on määritelty, custom_func käyttää niitä muokkaukseen, kuten seuraavassa koodiotteessa näkyy. Kun muokkaus on valmis, se muuntaa palaset takaisin alkuperäisiksi soluiksi, jotka se tallentaa pii_redacted sarake.
Lisää kohdesolmu
Muutostesi tuloksen näkemiseksi SageMaker Data Wrangler tukee vientiä Amazon S3:lle, SageMaker Pipelinesille, Amazon SageMaker -ominaisuuskauppaja Python-koodi. Jotta voimme viedä muokatut tiedot Amazon S3:een, meidän on ensin luotava kohdesolmu:
- Valitse SageMaker Data Wrangler -vuokaaviossa plusmerkki -kohdan vieressä Poista PII askel.
- Valita Lisää määränpää, valitse sitten Amazon S3.
- Anna muunnetulle tietojoukolle tulosteen nimi.
- Selaa tai syötä S3-sijainti tallentaaksesi muokatun datatiedoston.
- Valita Lisää määränpää.
Sinun pitäisi nyt nähdä kohdesolmu tietovirran lopussa.
Luo SageMaker Data Wrangler -vientityö
Nyt kun kohdesolmu on lisätty, voimme luoda vientityön datajoukon käsittelemiseksi:
- Valitse SageMaker Data Wranglerissa Luo työpaikka.
- Juuri lisäämäsi kohdesolmun pitäisi olla jo valittuna. Valita seuraava.
- Hyväksy kaikkien muiden vaihtoehtojen oletusasetukset ja valitse sitten ajaa.
Tämä luo a SageMaker-työ. Nähdäksesi työn tilan, siirry SageMaker-konsoliin. Laajenna navigointiruudussa Käsittely ja valitse Töiden käsittely. Kaikkien kohdesarakkeen 116,000 5.4 solun muokkaaminen vientityön oletusasetuksia käyttäen (kaksi ml.m8xsuuria esiintymää) kestää noin 0.25 minuuttia ja maksaa noin 3 dollaria. Kun työ on valmis, lataa tulostiedosto muokatun sarakkeen kanssa Amazon SXNUMX:sta.
Puhdistaa
SageMaker Data Wrangler -sovellus toimii ml.m5.4xlarge-esiintymässä. Sammuta se valitsemalla SageMaker Studiossa Juoksevat terminaalit ja ytimet navigointiruudussa. Vuonna KÄYNNISSÄ -osiosta, etsi esiintymä merkittynä Data Wrangler ja valitse sen vieressä oleva sammutuskuvake. Tämä sulkee ilmentymässä käynnissä olevan SageMaker Data Wrangler -sovelluksen.
Yhteenveto
Tässä viestissä keskustelimme siitä, kuinka käyttää mukautettuja muunnoksia SageMaker Data Wranglerissa ja Amazon Comprehendissä henkilökohtaisten tunnistetietojen poistamiseen ML-tietojoukosta. Sinä pystyt download SageMaker Data Wrangler -virtaus ja aloita henkilötietojen poistaminen taulukkotiedoistasi jo tänään.
Katso muita tapoja parantaa MLOps-työnkulkua käyttämällä mukautettuja SageMaker Data Wrangler -muunnoksia Mukautettujen muunnosten tekeminen Amazon SageMaker Data Wranglerissa NLTK:n ja SciPyn avulla. Lisää tietojen valmisteluvaihtoehtoja löytyy blogikirjoitussarjasta, joka selittää, kuinka Amazon Comprehendia käytetään reagoimaan, kääntämään ja analysoimaan tekstiä jommastakummasta Amazon Athena or Amazonin punainen siirto.
Tietoja Tekijät
 Tricia Jamison on vanhempi prototyyppiarkkitehti AWS Prototyping and Cloud Acceleration (PACE) -tiimissä, jossa hän auttaa AWS-asiakkaita toteuttamaan innovatiivisia ratkaisuja haastaviin koneoppimisen, esineiden internetin (IoT) ja palvelimettomien teknologioiden ongelmiin. Hän asuu New Yorkissa ja nauttii koripallosta, pitkistä matkoista ja lastensa edellä olemisesta.
Tricia Jamison on vanhempi prototyyppiarkkitehti AWS Prototyping and Cloud Acceleration (PACE) -tiimissä, jossa hän auttaa AWS-asiakkaita toteuttamaan innovatiivisia ratkaisuja haastaviin koneoppimisen, esineiden internetin (IoT) ja palvelimettomien teknologioiden ongelmiin. Hän asuu New Yorkissa ja nauttii koripallosta, pitkistä matkoista ja lastensa edellä olemisesta.
 Neelam Koshiya on Enterprise Solutions -arkkitehti AWS:ssä. Ohjelmistotekniikan taustalla hän siirtyi orgaanisesti arkkitehtuurirooliin. Tällä hetkellä hänen painopisteensä on auttaa yritysasiakkaita heidän pilvipalveluiden käyttöönotossa strategisten liiketoimintatulosten saavuttamiseksi. Syvyysalue on AI/ML. Hän on intohimoinen innovaatioihin ja osallisuuteen. Vapaa-ajallaan hän nauttii lukemisesta ja ulkoilusta.
Neelam Koshiya on Enterprise Solutions -arkkitehti AWS:ssä. Ohjelmistotekniikan taustalla hän siirtyi orgaanisesti arkkitehtuurirooliin. Tällä hetkellä hänen painopisteensä on auttaa yritysasiakkaita heidän pilvipalveluiden käyttöönotossa strategisten liiketoimintatulosten saavuttamiseksi. Syvyysalue on AI/ML. Hän on intohimoinen innovaatioihin ja osallisuuteen. Vapaa-ajallaan hän nauttii lukemisesta ja ulkoilusta.
 Adeleke Coker on AWS:n globaali ratkaisuarkkitehti. Hän työskentelee asiakkaiden kanssa maailmanlaajuisesti tarjotakseen ohjausta ja teknistä apua tuotantotyökuormien käyttöönotossa AWS:ssä. Vapaa-ajallaan hän nauttii oppimisesta, lukemisesta, pelaamisesta ja urheilutapahtumien katsomisesta.
Adeleke Coker on AWS:n globaali ratkaisuarkkitehti. Hän työskentelee asiakkaiden kanssa maailmanlaajuisesti tarjotakseen ohjausta ja teknistä apua tuotantotyökuormien käyttöönotossa AWS:ssä. Vapaa-ajallaan hän nauttii oppimisesta, lukemisesta, pelaamisesta ja urheilutapahtumien katsomisesta.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/automatically-redact-pii-for-machine-learning-using-amazon-sagemaker-data-wrangler/

