Generatiivinen tekoäly on avannut paljon potentiaalia tekoälyn alalla. Näemme lukuisia käyttötapoja, mukaan lukien tekstin luominen, koodin luominen, yhteenveto, käännös, chatbotit ja paljon muuta. Yksi tällainen kehittyvä alue on luonnollisen kielen käsittelyn (NLP) käyttö avatakseen uusia mahdollisuuksia käyttää tietoja intuitiivisten SQL-kyselyjen avulla. Monimutkaisten teknisten koodien sijaan yrityskäyttäjät ja data-analyytikot voivat esittää dataan ja oivalluksiin liittyviä kysymyksiä selkeällä kielellä. Ensisijainen tavoite on luoda automaattisesti SQL-kyselyitä luonnollisen kielen tekstistä. Tätä varten tekstisyöte muunnetaan jäsennellyksi esitykseksi ja tästä esityksestä luodaan SQL-kysely, jolla voidaan päästä tietokantaan.
Tässä viestissä esittelemme tekstiä SQL:ään (Text2SQL) ja tutkimme käyttötapauksia, haasteita, suunnittelumalleja ja parhaita käytäntöjä. Erityisesti keskustelemme seuraavista asioista:
- Miksi tarvitsemme Text2SQL:n
- Avainkomponentit Text to SQL
- Nopeat tekniset näkökohdat luonnolliselle kielelle tai tekstistä SQL:ksi
- Optimoinnit ja parhaat käytännöt
- Arkkitehtuurin kuviot
Miksi tarvitsemme Text2SQL:n?
Nykyään perinteisessä data-analytiikassa, tietovarastoinnissa ja tietokantoissa on saatavilla suuri määrä tietoa, jota ei välttämättä ole helppo kysyä tai ymmärtää suurimmalle osalle organisaation jäsenistä. Text2SQL:n ensisijainen tavoite on tehdä kyselytietokannoista helpommin saatavilla ei-teknisille käyttäjille, jotka voivat toimittaa kyselynsä luonnollisella kielellä.
NLP SQL:n avulla yrityskäyttäjät voivat analysoida tietoja ja saada vastauksia kirjoittamalla tai puhumalla kysymyksiä luonnollisella kielellä, kuten seuraavat:
- "Näytä kunkin tuotteen kokonaismyynti viime kuussa"
- "Mitkä tuotteet tuottivat enemmän tuloja?"
- "Mikä prosenttiosuus asiakkaista on jokaiselta alueelta?"
Amazonin kallioperä on täysin hallittu palvelu, joka tarjoaa valikoiman tehokkaita perusmalleja (FM) yhden API:n kautta, mikä mahdollistaa Gen AI -sovellusten rakentamisen ja skaalaamisen helposti. Sitä voidaan hyödyntää luomaan SQL-kyselyitä, jotka perustuvat yllä lueteltujen kaltaisiin kysymyksiin, ja kyselemään organisaation jäsenneltyä dataa ja luomaan luonnollisen kielen vastauksia kyselyvastaustiedoista.
SQL-tekstin avainkomponentit
Text-to-SQL-järjestelmissä on useita vaiheita luonnollisen kielen kyselyjen muuntamiseksi suoritettavaksi SQL:ksi:
- Luonnollisen kielen käsittely:
- Analysoi käyttäjän syötekysely
- Pura avainelementit ja tarkoitus
- Muunna strukturoituun muotoon
- SQL-sukupolvi:
- Karttaa puretut tiedot SQL-syntaksiin
- Luo kelvollinen SQL-kysely
- Tietokantakysely:
- Suorita tekoälyn luoma SQL-kysely tietokannassa
- Hae tulokset
- Palauta tulokset käyttäjälle
Yksi Large Language Models (LLM) -mallien merkittävä ominaisuus on koodin luominen, mukaan lukien SQL (Structured Query Language) tietokantoille. Näitä LLM:itä voidaan hyödyntää luonnollisen kielen kysymyksen ymmärtämiseen ja vastaavan SQL-kyselyn luomiseen tulosteena. LLM:t hyötyvät ottamalla käyttöön kontekstin sisäistä oppimista ja hienosäätämällä asetuksia sitä mukaa kun dataa tarjotaan.
Seuraava kaavio havainnollistaa Text2SQL:n peruskulkua.

Nopeat tekniset näkökohdat SQL:n luonnolliselle kielelle
Kehote on ratkaisevan tärkeä käytettäessä LLM:itä luonnollisen kielen kääntämiseen SQL-kyselyiksi, ja nopean suunnittelun kannalta on useita tärkeitä näkökohtia.
Tehokas nopea suunnittelu on avainasemassa luonnollisen kielen kehittämisessä SQL-järjestelmiin. Selkeät, suoraviivaiset kehotteet tarjoavat parempia ohjeita kielimallille. Antamalla kontekstin, jossa käyttäjä pyytää SQL-kyselyä, sekä asiaankuuluvat tietokantaskeeman tiedot mahdollistavat mallin kääntämisen tarkoituksen tarkasti. Muutaman annotoidun esimerkin luonnollisen kielen kehotteista ja vastaavista SQL-kyselyistä sisällyttäminen auttaa ohjaamaan mallia tuottamaan syntaksiyhteensopivaa tulosta. Lisäksi RAG (Retrieval Augmented Generation), jossa malli hakee samanlaisia esimerkkejä käsittelyn aikana, lisää kartoitustarkkuutta. Hyvin suunnitellut kehotteet, jotka antavat mallille riittävät ohjeet, kontekstin, esimerkit ja haun lisäyksen, ovat ratkaisevan tärkeitä luonnollisen kielen luotettavassa kääntämisessä SQL-kyselyiksi.
Seuraavassa on esimerkki peruskehotteesta, jossa on tietokannan koodiesitys julkaisusta Suurien kielimallien muutaman otoksen tekstistä SQL:ksi -ominaisuuksien parantaminen: tutkimus nopeista suunnittelustrategioista.
Kuten tässä esimerkissä havainnollistetaan, kehotteeseen perustuva muutaman otoksen oppiminen tarjoaa mallille kourallisen huomautettuja esimerkkejä itse kehotteessa. Tämä osoittaa mallin luonnollisen kielen ja SQL:n välisen kohdekartoituksen. Yleensä kehote sisältää noin 2–3 paria, jotka näyttävät luonnollisen kielen kyselyn ja vastaavan SQL-käskyn. Nämä muutamat esimerkit ohjaavat mallia luomaan syntaksiyhteensopivia SQL-kyselyitä luonnollisesta kielestä ilman laajoja koulutustietoja.
Hienosäätö vs. nopea suunnittelu
Kun rakennamme luonnollista kieltä SQL-järjestelmiin, joudumme usein keskusteluun siitä, onko mallin hienosäätö oikea tekniikka vai onko tehokas nopea suunnittelu oikea tapa edetä. Molempia lähestymistapoja voidaan harkita ja valita oikeiden vaatimusten perusteella:
-
- Hienosäätö – Perusmalli on esiopetettu suurelle yleiselle tekstikorpukselle ja sitä voidaan sitten käyttää ohjepohjainen hienosäätö, joka käyttää merkittyjä esimerkkejä parantaakseen valmiiksi koulutetun perusmallin suorituskykyä teksti-SQL:llä. Tämä mukauttaa mallin kohdetehtävään. Hienosäätö kouluttaa mallin suoraan lopputehtävään, mutta vaatii monia teksti-SQL-esimerkkejä. Voit käyttää valvottua hienosäätöä LLM:n perusteella parantaaksesi tekstistä SQL:ksi muuntamisen tehokkuutta. Tätä varten voit käyttää useita tietojoukkoja, kuten Hämähäkki, WikiSQL, AJOJAHTI, BIRD-SQLtai CoSQL.
- Nopea suunnittelu – Malli on koulutettu suorittamaan kehotteet, jotka on suunniteltu kysymään kohdeSQL-syntaksia. Luotaessa SQL:ää luonnollisesta kielestä LLM:ien avulla, selkeät ohjeet kehotteessa on tärkeää mallin tulosteen ohjaamiseksi. Kommentoi kehotteeseen eri komponentteja, kuten sarakkeisiin osoittamista, skeemaa ja ohjeista sitten, minkä tyyppinen SQL luodaan. Nämä toimivat kuten ohjeet, jotka kertovat mallille, kuinka SQL-ulostulo muotoillaan. Seuraava kehote näyttää esimerkin, jossa osoitat taulukon sarakkeita ja ohjeistat luomaan MySQL-kyselyn:
Tehokas tapa tekstistä SQL-malleihin on aloittaa ensin perustason LLM:stä ilman tehtäväkohtaista hienosäätöä. Hyvin muotoiltuja kehotteita voidaan sitten käyttää perusmallin mukauttamiseen ja ohjaamiseen käsittelemään tekstistä SQL-kuvaukseen. Tämän nopean suunnittelun avulla voit kehittää ominaisuuksia ilman hienosäätöä. Jos perusmallin nopealla suunnittelulla ei saavuteta riittävää tarkkuutta, pienen teksti-SQL-esimerkkijoukon hienosäätöä voidaan sitten tutkia yhdessä nopean suunnittelun kanssa.
Hienosäädön ja nopean suunnittelun yhdistelmää voidaan tarvita, jos nopea suunnittelu pelkällä esikoulutetulla raakamallilla ei täytä vaatimuksia. On kuitenkin parasta kokeilla aluksi nopeaa suunnittelua ilman hienosäätöä, koska tämä mahdollistaa nopean iteroinnin ilman tiedonkeruuta. Jos tämä ei tuota riittävää suorituskykyä, hienosäätö yhdessä nopean suunnittelun kanssa on kannattava seuraava askel. Tämä kokonaisvaltainen lähestymistapa maksimoi tehokkuuden ja sallii silti räätälöinnin, jos puhtaasti kehotteisiin perustuvat menetelmät eivät riitä.
Optimointi ja parhaat käytännöt
Optimointi ja parhaat käytännöt ovat välttämättömiä tehokkuuden lisäämiseksi ja resurssien optimaalisen käytön varmistamiseksi ja oikeiden tulosten saavuttamiseksi parhaalla mahdollisella tavalla. Tekniikat auttavat parantamaan suorituskykyä, hallitsemaan kustannuksia ja saavuttamaan laadukkaamman lopputuloksen.
Kun kehitetään tekstistä SQL:ksi järjestelmiä käyttämällä LLM:itä, optimointitekniikat voivat parantaa suorituskykyä ja tehokkuutta. Seuraavassa on joitain tärkeitä huomioitavia alueita:
- välimuistia – Parantaaksesi viivettä, kustannusten hallintaa ja standardointia voit tallentaa jäsennetyt SQL:n ja tunnistetut kyselykehotteet välimuistiin tekstistä SQL:ksi LLM:stä. Näin vältytään toistuvien kyselyjen uudelleenkäsittelyltä.
- Seuranta – Lokeja ja mittareita kyselyn jäsentämisestä, pikatunnistuksesta, SQL:n luomisesta ja SQL-tuloksista tulee kerätä tekstistä SQL:ksi LLM-järjestelmän valvomiseksi. Tämä tarjoaa näkyvyyttä optimointiesimerkille, joka päivittää kehotteen tai palaa hienosäätöön päivitetyn tietojoukon avulla.
- Toteutetut näkymät vs. taulukot – Toteutetut näkymät voivat yksinkertaistaa SQL:n luomista ja parantaa yleisten teksti-SQL-kyselyjen suorituskykyä. Taulukoiden suora kysely voi johtaa monimutkaiseen SQL:ään ja myös suorituskykyongelmiin, kuten jatkuvaan suorituskykytekniikoiden, kuten indeksien, luomiseen. Lisäksi voit välttää suorituskykyongelmia, kun samaa taulukkoa käytetään samanaikaisesti muilla käyttöalueilla.
- Päivitetään tietoja – Toteutetut näkymät on päivitettävä aikataulussa, jotta tiedot pysyvät ajan tasalla tekstistä SQL-kyselyihin. Voit käyttää eräpäivitys- tai asteittaista virkistysmenetelmiä yleiskustannusten tasapainottamiseksi.
- Keskitetty tietoluettelo – Keskitetyn tietoluettelon luominen tarjoaa yhden lasinäkymän organisaation tietolähteille ja auttaa LLM:itä valitsemaan sopivat taulukot ja kaaviot tarkempien vastausten antamiseksi. Vektori upotukset keskitetystä tietokatalogista luotu voidaan toimittaa LLM:lle yhdessä tarvittavien ja tarkkojen SQL-vastausten luomiseen tarvittavien tietojen kanssa.
Käyttämällä optimoinnin parhaita käytäntöjä, kuten välimuistin tallentamista, seurantaa, materialisoituja näkymiä, ajoitettua päivitystä ja keskitettyä luetteloa, voit parantaa merkittävästi tekstistä SQL:ksi siirtävien järjestelmien suorituskykyä ja tehokkuutta LLM:itä käyttämällä.
Arkkitehtuurin kuviot
Katsotaanpa joitain arkkitehtuurimalleja, jotka voidaan toteuttaa tekstistä SQL-työnkulkuun.
Nopea suunnittelu
Seuraava kaavio havainnollistaa arkkitehtuuria kyselyjen luomiseksi LLM:llä käyttämällä kehotesuunnittelua.
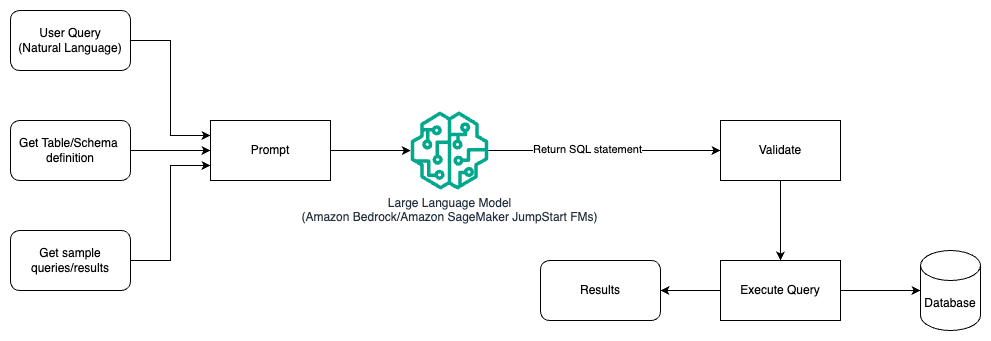
Tässä mallissa käyttäjä luo kehotepohjaisen muutaman otoksen oppimisen, joka tarjoaa mallille huomautetut esimerkit itse kehotteessa, joka sisältää taulukon ja skeeman tiedot sekä joitakin esimerkkikyselyitä tuloksineen. LLM käyttää toimitettua kehotetta palauttaakseen tekoälyn luoman SQL:n, joka tarkistetaan ja suoritetaan sitten tietokantaa vastaan tulosten saamiseksi. Tämä on yksinkertaisin malli nopean suunnittelun aloittamiseen. Tätä varten voit käyttää Amazonin kallioperä or perusmallit in Amazon SageMaker JumpStart.
Tässä mallissa käyttäjä luo kehotteeseen perustuvan muutaman otoksen oppimisen, joka tarjoaa mallille kommentoidut esimerkit itse kehotteessa, joka sisältää taulukon ja skeeman tiedot sekä joitakin esimerkkikyselyitä tuloksineen. LLM käyttää toimitettua kehotetta palauttaakseen tekoälyn luoman SQL:n, joka tarkistetaan ja suoritetaan tietokantaa vastaan tulosten saamiseksi. Tämä on yksinkertaisin malli nopean suunnittelun aloittamiseen. Tätä varten voit käyttää Amazonin kallioperä joka on täysin hallittu palvelu, joka tarjoaa valikoiman tehokkaita perusmalleja (FM:itä) johtavilta tekoälyyrityksiltä yhden API:n kautta sekä laajan valikoiman ominaisuuksia, joita tarvitset luovien tekoälysovellusten rakentamiseen turvallisuuden, yksityisyyden ja vastuullisen tekoälyn avulla. tai JumpStart Foundation -mallit joka tarjoaa huippuluokan perusmalleja käyttötapauksiin, kuten sisällön kirjoittamiseen, koodin luomiseen, kysymyksiin vastaamiseen, tekstin kirjoittamiseen, yhteenvetoon, luokitteluun, tiedonhakuun ja muihin
Nopea suunnittelu ja hienosäätö
Seuraava kaavio havainnollistaa arkkitehtuuria kyselyjen luomiseksi LLM:llä käyttämällä nopeaa suunnittelua ja hienosäätöä.
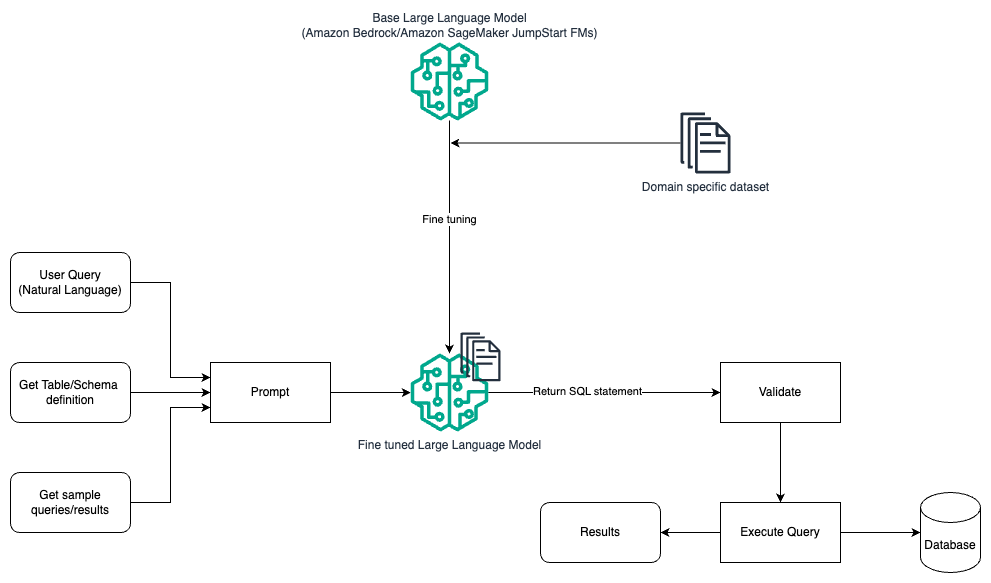
Tämä kulku on samanlainen kuin edellinen malli, joka perustuu enimmäkseen nopeaan suunnitteluun, mutta sisältää lisäksi verkkoaluekohtaisen tietojoukon hienosäädön. Hienosäädettyä LLM:ää käytetään luomaan SQL-kyselyt, joilla on mahdollisimman vähän kontekstin sisäistä arvoa kehotteessa. Tätä varten voit käyttää SageMaker JumpStartia LLM:n hienosäätämiseen verkkotunnuskohtaisessa tietojoukossa samalla tavalla kuin harjoittaisit ja ottaisit käyttöön minkä tahansa mallin Amazon Sage Maker.
Nopea suunnittelu ja RAG
Seuraava kaavio havainnollistaa arkkitehtuuria kyselyjen luomiseksi LLM:llä käyttämällä kehotesuunnittelua ja RAG:ta.
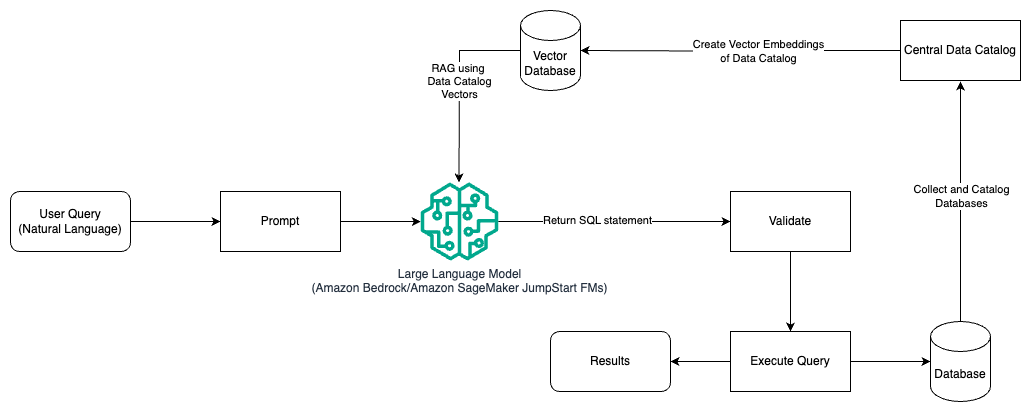
Tässä mallissa käytämme Haku laajennettu sukupolvi käyttämällä vektori upotuskauppoja, kuten Amazon Titan Embeddings or Cohere Embed, On Amazonin kallioperä keskustietokatalogista, esim AWS-liima Tietoluettelo, tietokannoista organisaation sisällä. Vektori upotukset on tallennettu vektoritietokantoihin, kuten Vector Engine Amazon OpenSearch Serverless -sovellukselle, Amazon Relational Database Service (Amazon RDS) PostgreSQL:lle jossa pgvector laajennus tai Amazon Kendra. LLM:t käyttävät vektori upotuksia valitakseen oikeat tietokannat, taulukot ja sarakkeet taulukoista nopeammin luodessaan SQL-kyselyjä. RAG:n käyttäminen on hyödyllistä, kun LLM:n haettava tieto ja asiaankuuluvat tiedot on tallennettu useisiin eri tietokantajärjestelmiin ja LLM:n on voitava etsiä tai tehdä kyselyitä kaikista näistä eri järjestelmistä. Tämä on paikka, jossa keskitetyn tai yhdistetyn dataluettelon vektori upottaminen LLM:ille johtaa tarkempiin ja kattavampiin tietoihin, jotka LLM:t palauttavat.
Yhteenveto
Tässä viestissä keskustelimme siitä, kuinka voimme luoda arvoa yritystiedoista luonnollisen kielen avulla SQL-sukupolkuun. Tarkastelimme avainkomponentteja, optimointia ja parhaita käytäntöjä. Opimme myös arkkitehtuurimalleja perusohjelmoinnista hienosäätöön ja RAG:iin. Lisätietoja saat osoitteesta Amazonin kallioperä luoda ja skaalata generatiivisia tekoälysovelluksia helposti perusmalleilla
Tietoja Tekijät
 Randy DeFauw on AWS:n vanhempi ratkaisuarkkitehti. Hän on suorittanut MSEE-tutkinnon Michiganin yliopistosta, jossa hän työskenteli autonomisten ajoneuvojen tietokonenäön parissa. Hän on myös suorittanut MBA-tutkinnon Colorado State Universitystä. Randy on toiminut erilaisissa tehtävissä teknologia-alalla ohjelmistosuunnittelusta tuotehallintaan. In astui Big Data -avaruuteen vuonna 2013 ja jatkaa tämän alueen tutkimista. Hän työskentelee aktiivisesti projekteissa ML-tilassa ja on esiintynyt lukuisissa konferensseissa, mukaan lukien Strata ja GlueCon.
Randy DeFauw on AWS:n vanhempi ratkaisuarkkitehti. Hän on suorittanut MSEE-tutkinnon Michiganin yliopistosta, jossa hän työskenteli autonomisten ajoneuvojen tietokonenäön parissa. Hän on myös suorittanut MBA-tutkinnon Colorado State Universitystä. Randy on toiminut erilaisissa tehtävissä teknologia-alalla ohjelmistosuunnittelusta tuotehallintaan. In astui Big Data -avaruuteen vuonna 2013 ja jatkaa tämän alueen tutkimista. Hän työskentelee aktiivisesti projekteissa ML-tilassa ja on esiintynyt lukuisissa konferensseissa, mukaan lukien Strata ja GlueCon.
 Nitin Eusebius on AWS:n vanhempi yritysratkaisuarkkitehti, jolla on kokemusta ohjelmistosuunnittelusta, yritysarkkitehtuurista ja AI/ML:stä. Hän on syvästi intohimoinen luovan tekoälyn mahdollisuuksien tutkimiseen. Hän tekee yhteistyötä asiakkaiden kanssa auttaakseen heitä rakentamaan hyvin suunniteltuja sovelluksia AWS-alustalle, ja hän on omistautunut ratkaisemaan teknologian haasteita ja avustamaan heidän pilvimatkallaan.
Nitin Eusebius on AWS:n vanhempi yritysratkaisuarkkitehti, jolla on kokemusta ohjelmistosuunnittelusta, yritysarkkitehtuurista ja AI/ML:stä. Hän on syvästi intohimoinen luovan tekoälyn mahdollisuuksien tutkimiseen. Hän tekee yhteistyötä asiakkaiden kanssa auttaakseen heitä rakentamaan hyvin suunniteltuja sovelluksia AWS-alustalle, ja hän on omistautunut ratkaisemaan teknologian haasteita ja avustamaan heidän pilvimatkallaan.
 Arghya Banerjee on vanhempi ratkaisuarkkitehti AWS:ssä San Franciscon lahden alueella. Hän keskittyy auttamaan asiakkaita ottamaan käyttöön ja käyttämään AWS Cloudia. Arghya keskittyy Big Data-, Data Lakes-, Streaming-, Batch Analytics- ja AI/ML-palveluihin ja -teknologioihin.
Arghya Banerjee on vanhempi ratkaisuarkkitehti AWS:ssä San Franciscon lahden alueella. Hän keskittyy auttamaan asiakkaita ottamaan käyttöön ja käyttämään AWS Cloudia. Arghya keskittyy Big Data-, Data Lakes-, Streaming-, Batch Analytics- ja AI/ML-palveluihin ja -teknologioihin.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

