AWS-asiakkaat terveydenhuollossa, rahoituspalveluissa, julkisella sektorilla ja muilla aloilla tallentavat miljardeja asiakirjoja kuvina tai PDF-tiedostoina Amazonin yksinkertainen tallennuspalvelu (Amazon S3). He eivät kuitenkaan pysty saamaan oivalluksia, kuten käyttämään asiakirjoihin lukittuja tietoja suurille kielimalleille (LLM) tai hakemaan, ennen kuin he poimivat tekstin, lomakkeet, taulukot ja muut jäsennellyt tiedot. AWS:n älykkäällä asiakirjankäsittelyllä (IDP) käyttämällä tekoälypalveluita, kuten Amazonin teksti, voit hyödyntää alan johtavaa koneoppimistekniikkaa (ML) käsitelläksesi tietoja nopeasti ja tarkasti PDF-tiedostoista tai asiakirjakuvista (TIFF, JPEG, PNG). Kun teksti on poimittu asiakirjoista, voit käyttää sitä perusmallin hienosäätämiseen, tiivistää tiedot perustusmallin avullatai lähetä se tietokantaan.
Tässä viestissä keskitymme käsittelemään suuren kokoelman asiakirjoja raakatekstitiedostoiksi ja tallentamaan ne Amazon S3:een. Tarjoamme sinulle kaksi erilaista ratkaisua tähän käyttötapaukseen. Ensimmäisen avulla voit suorittaa Python-komentosarjan mistä tahansa palvelimesta tai ilmentymästä, mukaan lukien Jupyter-muistikirja; tämä on nopein tapa päästä alkuun. Toinen lähestymistapa on erilaisten infrastruktuurikomponenttien avaimet käteen -käyttöönotto AWS Cloud Development Kit (AWS CDK) rakentaa. AWS CDK -rakenne tarjoaa joustavan ja joustavan kehyksen asiakirjojen käsittelyyn ja päästä päähän IDP-putkilinjan rakentamiseen. AWS CDK:n avulla voit laajentaa sen toimintoja sisältämään editoinnin, tallentaa tulos Amazon OpenSearchiintai lisää mukautettu AWS Lambda toimivat omalla liiketoimintalogiikallasi.
Molempien ratkaisujen avulla voit käsitellä miljoonia sivuja nopeasti. Ennen kuin käytät jompaakumpaa näistä ratkaisuista mittakaavassa, suosittelemme testaamaan asiakirjojen osajoukon varmistaaksesi, että tulokset vastaavat odotuksiasi. Seuraavissa osissa kuvataan ensin komentosarjaratkaisu ja sen jälkeen AWS CDK -konstruktiratkaisu.
Ratkaisu 1: Käytä Python-komentosarjaa
Tämä ratkaisu käsittelee asiakirjoja raakatekstiä varten Amazon Textractin kautta niin nopeasti kuin palvelu sallii sillä odotuksella, että jos skriptissä on vika, prosessi jatkuu siitä, mihin se jäi. Ratkaisu hyödyntää kolmea eri palvelua: Amazon S3, Amazon DynamoDBja Amazon Textract.
Seuraava kaavio havainnollistaa skriptin tapahtumien järjestystä. Kun skripti päättyy, valmistumisen tila ja käytetty aika palautetaan SageMaker-studiokonsoliin.

Olemme pakkaaneet tämän ratkaisun a .ipynb-skripti ja .py-skripti. Voit käyttää mitä tahansa käyttöönotettavia ratkaisuja tarpeidesi mukaan.
Edellytykset
Jos haluat suorittaa tämän skriptin Jupyter-muistikirjasta, AWS-henkilöllisyyden ja käyttöoikeuksien hallinta Muistikirjalle määritetyllä (IAM) roolilla on oltava oikeudet, jotka sallivat sen olla vuorovaikutuksessa DynamoDB:n, Amazon S3:n ja Amazon Textractin kanssa. Yleisenä ohjeena on tarjota vähiten käyttöoikeudet jokaiselle näistä palveluista AmazonSageMaker-ExecutionRole rooli. Lisätietoja saat osoitteesta Aloita AWS:n hallinnoimien käytäntöjen käyttäminen ja siirry kohti vähiten oikeuksia.
Vaihtoehtoisesti voit suorittaa tämän skriptin muista ympäristöistä, kuten Amazonin elastinen laskentapilvi (Amazon EC2) ilmentymä tai säilö, jota hallinnoisit, jos Python, Pip3 ja AWS SDK Pythonille (Boto3) on asennettu. Jälleen on käytettävä samoja IAM-käytäntöjä, jotka sallivat komentosarjan olla vuorovaikutuksessa eri hallittujen palvelujen kanssa.
Walkthrough
Tämän ratkaisun toteuttamiseksi sinun on ensin kloonattava arkisto GitHub.
Sinun on asetettava seuraavat muuttujat skriptiin, ennen kuin voit suorittaa sen:
- seurantataulukko – Tämä on luotavan DynamoDB-taulukon nimi.
- input_bucket – Tämä on lähdesijaintisi Amazon S3:ssa, joka sisältää asiakirjat, jotka haluat lähettää Amazon Textractiin tekstin havaitsemista varten. Anna tälle muuttujalle ryhmän nimi, kuten
mybucket. - output_bucket – Tämä on tarkoitettu sijainnin tallentamiseen, johon haluat Amazon Textractin kirjoittavan tulokset. Anna tälle muuttujalle ryhmän nimi, kuten
myoutputbucket. - _input_prefix (valinnainen) – Jos haluat valita tiettyjä tiedostoja S3-säihön kansiosta, voit määrittää tämän kansion nimen syöttöetuliitteeksi. Muussa tapauksessa jätä oletusarvo tyhjäksi valitaksesi kaikki.
Käsikirjoitus on seuraava:
Seuraava DynamoDB-taulukkoskeema luodaan, kun komentosarja suoritetaan:
Kun komentosarja suoritetaan ensimmäisen kerran, se tarkistaa, onko DynamoDB-taulukko olemassa, ja luo sen tarvittaessa automaattisesti. Kun taulukko on luotu, meidän on täytettävä se luettelolla Amazon S3:n dokumenttiobjektiviittauksista, jotka haluamme käsitellä. Suunniteltu skripti luettelee määritetyissä kohteissa olevat objektit input_bucket ja täyttävät automaattisesti taulukkoomme heidän nimensä suoritettaessa. Kestää noin 10 minuuttia yli 100,000 3 asiakirjan luettelemiseen ja näiden nimien täyttämiseen komentosarjasta DynamoDB-taulukkoon. Jos sinulla on miljoonia objekteja ämpäri, voit vaihtoehtoisesti käyttää Amazon SXNUMX:n inventaarioominaisuutta, joka luo CSV-nimien tiedoston ja täyttää DynamoDB-taulukon tästä luettelosta etukäteen omalla komentosarjallasi etkä käytä toimintoa nimeltä fetchAllObjectsInBucketandStoreName kommentoimalla sitä. Lisätietoja saat osoitteesta Amazon S3 -varaston määrittäminen.
Kuten aiemmin mainittiin, on olemassa sekä muistikirjaversio että Python-skriptiversio. Muistikirja on yksinkertaisin tapa aloittaa; yksinkertaisesti ajaa jokainen solu alusta loppuun.
Jos päätät suorittaa Python-komentosarjan CLI:stä, on suositeltavaa käyttää päätemultiplekseria, kuten tmux. Tämä estää komentosarjan pysähtymisen, jos SSH-istunto päättyy. Esimerkiksi: tmux new -d ‘python3 textractFeeder.py’.
Seuraava on käsikirjoituksen sisääntulokohta; täältä voit kommentoida tarpeettomia menetelmiä:
Seuraavat kentät asetetaan, kun komentosarja täyttää DynamoDB-taulukkoa:
- objektin nimi – Amazon S3:ssa sijaitsevan asiakirjan nimi, joka lähetetään Amazon Textractiin
- bucketName – Salo, johon asiakirjaobjekti on tallennettu
Nämä kaksi kenttää on täytettävä, jos päätät käyttää CSV-tiedostoa S3-varastoraportista ja ohitat skriptin sisällä tapahtuvan automaattisen täytön.
Nyt kun taulukko on luotu ja täytetty dokumenttiobjektiviittauksilla, komentosarja on valmis aloittamaan kutsumisen Amazon Textractille. StartDocumentTextDetection API. Amazon Textract, kuten muutkin hallinnoidut palvelut, sisältää a oletusraja sovellusliittymillä, joita kutsutaan transaktioksi sekunnissa (TPS). Tarvittaessa voit pyytää kiintiön lisäystä Amazon Textract -konsolista. Koodi on suunniteltu käyttämään useita säikeitä samanaikaisesti soitettaessa Amazon Textractiin palvelun suorituskyvyn maksimoimiseksi. Voit muuttaa tätä koodissa muokkaamalla threadCountforTextractAPICall muuttuja. Oletuksena tämä on 20 säiettä. Komentosarja lukee aluksi 200 riviä DynamoDB-taulukosta ja tallentaa ne muistiluetteloon, joka on kääritty luokkaan säikeiden turvallisuuden vuoksi. Jokainen soittajan lanka käynnistetään ja kulkee omalla uimaratallaan. Pohjimmiltaan Amazon Textract -soittosäie hakee kohteen muistiluettelosta, joka sisältää objektiviittauksemme. Sitten se kutsuu asynkronista start_document_text_detection API ja odota vahvistusta työtunnuksella. Työtunnus päivitetään sitten takaisin DynamoDB-riville kyseiselle objektille, ja säie toistuu hakemalla luettelosta seuraavan kohteen.
Seuraava on tärkein orkestrointikoodi käsikirjoitus:
Soittajan säikeet jatkavat toistamista, kunnes luettelossa ei ole enää kohteita, jolloin kukin ketju pysähtyy. Kun kaikki uintikaistalla toimivat säikeet ovat pysähtyneet, seuraavat 200 riviä noudetaan DynamoDB:stä ja aloitetaan uusi 20 säikeen sarja, ja koko prosessi toistuu, kunnes jokainen rivi, joka ei sisällä työtunnusta, haetaan DynamoDB:stä ja päivitetty. Jos komentosarja kaatuu jonkin odottamattoman ongelman vuoksi, komentosarja voidaan ajaa uudelleen osoitteesta orchestrate() menetelmä. Tämä varmistaa, että säikeet jatkavat tyhjiä työtunnuksia sisältävien rivien käsittelyä. Huomaa, että kun suoritat uudelleen orchestrate() -menetelmällä, kun komentosarja on pysähtynyt, on mahdollista, että muutama asiakirja lähetetään uudelleen Amazon Textractiin. Tämä luku on yhtä suuri tai pienempi kuin kaatumisen aikaan käynnissä olevien säikeiden lukumäärä.
Kun DynamoDB-taulukossa ei ole enää rivejä, jotka sisältävät tyhjän työtunnuksen, komentosarja pysähtyy. Kaikki Amazon Textractin JSON-ulostulot kaikille objekteille löytyvät output_bucket oletuksena alla textract_output kansio. Jokainen alikansio sisällä textract_output nimetään työtunnuksella, joka vastaa kyseisen objektin DynamoDB-taulukkoon tallennettua työtunnusta. Työtunnuskansiossa on JSON, jonka nimet ovat numeeriset alkaen numerosta 1 ja joka voi mahdollisesti kattaa muita JSON-tiedostoja, jotka on merkitty 2, 3 ja niin edelleen. Jatkuvat JSON-tiedostot ovat seurausta tiheistä tai monisivuisista asiakirjoista, joissa poimitun sisällön määrä ylittää Amazon Textractin JSON-oletuskoon 1,000 XNUMX lohkoa. Viitata Tukkia lisätietoja lohkoista. Nämä JSON-tiedostot sisältävät kaikki Amazon Textract -metatiedot, mukaan lukien asiakirjoista poimitun tekstin.
Löydät tämän ratkaisun Python-koodimuistikirjan version ja komentosarjan osoitteesta GitHub.
Puhdistaa
Kun Python-skripti on valmis, voit säästää kustannuksia sammuttamalla tai pysäyttämällä Amazon SageMaker Studio muistikirja tai astia, jonka keräsit ylös.
Siirrytään nyt toiseen ratkaisuumme suuria asiakirjoja varten.
Ratkaisu 2: Käytä palvelimetonta AWS CDK -rakennetta
Tämä ratkaisu käyttää AWS-vaihetoiminnot ja Lambda toimii IDP-putkilinjan ohjaamiseksi. Käytämme IDP AWS CDK -konstruktit, joiden ansiosta on helppoa työskennellä Amazon Textractin kanssa laajassa mittakaavassa. Lisäksi käytämme a Vaihefunktiot hajautettu kartta toistaa kaikki S3-säihön tiedostot ja aloittaa käsittelyn. Ensimmäinen lambda-toiminto määrittää, kuinka monta sivua asiakirjoissasi on. Tämän ansiosta liukuhihna voi käyttää automaattisesti joko synkronista (yksisivuisille asiakirjoille) tai asynkronista (monisivuisille asiakirjoille) API:ta. Asynkronista APIa käytettäessä ylimääräinen Lambda-toiminto kutsutaan kaikkiin JSON-tiedostoihin, jotka Amazon Textract tuottaa kaikille sivuillesi yhdeksi JSON-tiedostoksi, jotta myöhempien sovellusten on helppo käsitellä tietoja.
Tämä ratkaisu sisältää myös kaksi ylimääräistä lambdatoimintoa. Ensimmäinen toiminto jäsentää tekstin JSONista ja tallentaa sen tekstitiedostona Amazon S3:ssa. Toinen funktio analysoi JSONin ja tallentaa sen työkuorman mittareille.
Seuraava kaavio havainnollistaa Step Functions -työnkulkua.

Edellytykset
Tämä koodikanta käyttää AWS CDK:ta ja vaatii Dockerin. Voit ottaa tämän käyttöön osoitteesta AWS-pilvi9 esimerkki, jossa AWS CDK ja Docker on jo asennettu.
Walkthrough
Tämän ratkaisun toteuttamiseksi sinun on ensin kloonattava arkistoon.
Kun olet kloonannut arkiston, asenna riippuvuudet:
Ota sitten AWS CDK -pino käyttöön seuraavalla koodilla:
Sinun on annettava sekä lähderyhmä että lähdeetuliite (käsiteltävien tiedostojen sijainti) tälle ratkaisulle.
Kun käyttöönotto on valmis, siirry Step Functions -konsoliin, jossa sinun pitäisi nähdä tilakone ServerlessIDPArchivePipeline.
Avaa tilakoneen tietosivu ja teloitukset välilehti, valitse Aloita suoritus.
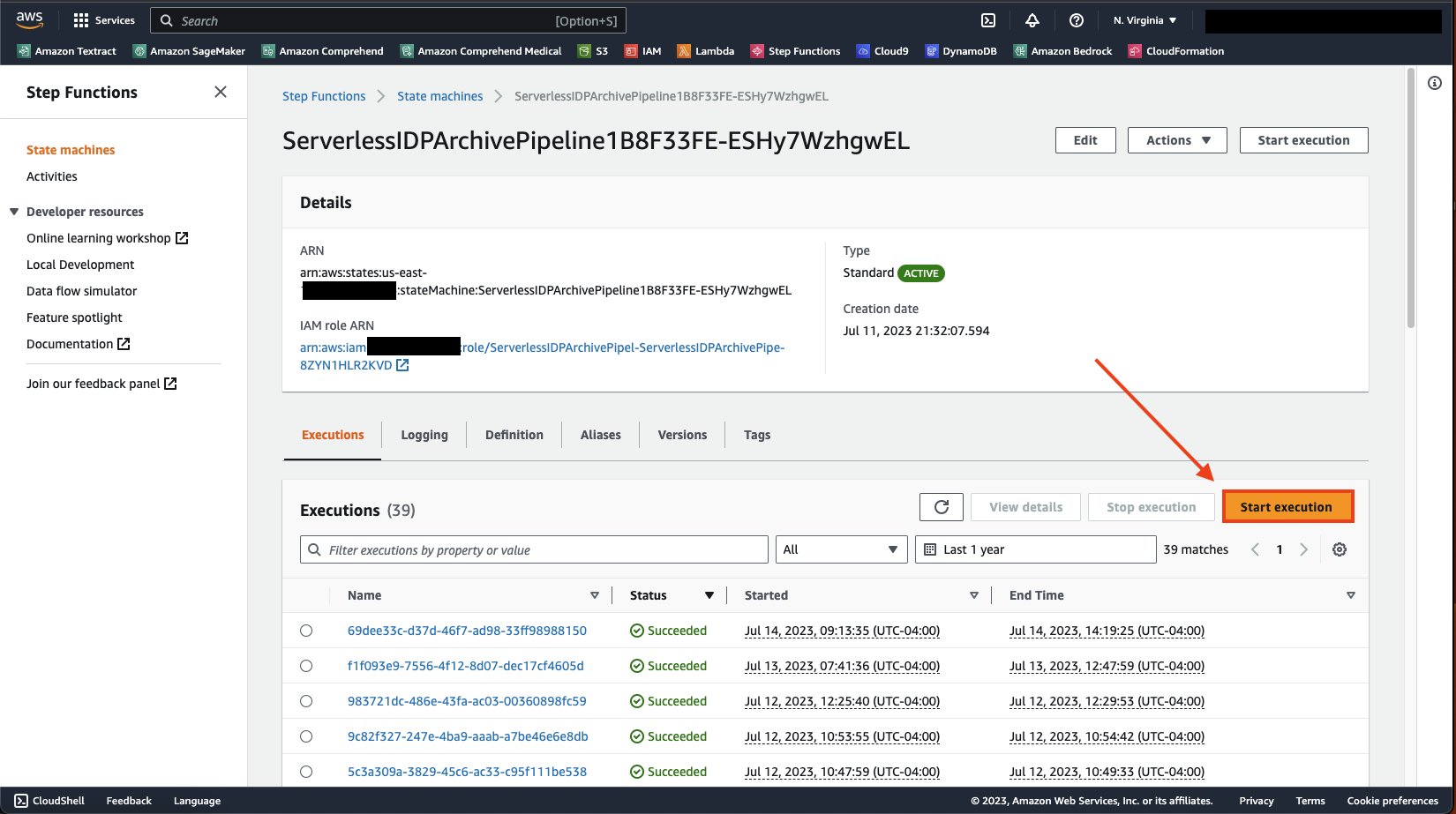
Valita Aloita suoritus uudelleen ajamaan tilakonetta.

Kun olet käynnistänyt tilakoneen, voit seurata liukuhihnaa katsomalla karttaajoa. Näet an Kohteen käsittelyn tila osio, kuten seuraava kuvakaappaus. Kuten näet, tämä on suunniteltu suorittamaan ja seuraamaan, mikä onnistui ja mikä epäonnistui. Tämä prosessi jatkuu, kunnes kaikki asiakirjat on luettu.

Tämän ratkaisun avulla sinun pitäisi pystyä käsittelemään miljoonia tiedostoja AWS-tililläsi ilman, että sinun tarvitsee huolehtia siitä, kuinka voit määrittää oikein, mitkä tiedostot lähetetään millekin API:lle tai vioittuneet tiedostot, jotka epäonnistuvat prosessissasi. Step Functions -konsolin kautta voit katsella ja seurata tiedostojasi reaaliajassa.
Puhdistaa
Kun putkilinjasi on suoritettu, voit puhdistaa sen palaamalla projektiisi ja antamalla seuraavan komennon:
Tämä poistaa kaikki tässä projektissa käyttöön otetut palvelut.
Yhteenveto
Tässä viestissä esittelimme ratkaisun, joka tekee asiakirjojen kuvien ja PDF-tiedostojen muuntamisesta tekstitiedostoiksi yksinkertaista. Tämä on keskeinen edellytys asiakirjojen käyttämiselle generatiiviseen tekoälyyn ja hakuun. Lisätietoja tekstin käyttämisestä perusmallien harjoittamiseen tai hienosäätämiseen on kohdassa Hienosäädä Llama 2 tekstin luomista varten Amazon SageMaker JumpStartissa. Jos haluat käyttää haun kanssa, katso Ota älykäs asiakirjahakuindeksi käyttöön Amazon Textractin ja Amazon OpenSearchin avulla. Lisätietoja AWS AI -palveluiden tarjoamista edistyneistä asiakirjojen käsittelyominaisuuksista on osoitteessa Ohjeet älykkääseen asiakirjojen käsittelyyn AWS:ssä.
Tietoja Tekijät
 Tim Condello on vanhempi tekoälyn (AI) ja koneoppimisen (ML) asiantuntijaratkaisujen arkkitehti Amazon Web Servicesissä (AWS). Hän keskittyy luonnolliseen kielenkäsittelyyn ja tietokonenäköön. Tim nauttii asiakkaiden ideoiden ottamisesta ja muuttamisesta skaalautuviksi ratkaisuiksi.
Tim Condello on vanhempi tekoälyn (AI) ja koneoppimisen (ML) asiantuntijaratkaisujen arkkitehti Amazon Web Servicesissä (AWS). Hän keskittyy luonnolliseen kielenkäsittelyyn ja tietokonenäköön. Tim nauttii asiakkaiden ideoiden ottamisesta ja muuttamisesta skaalautuviksi ratkaisuiksi.
 David Girling on vanhempi AI/ML-ratkaisuarkkitehti, jolla on yli kahdenkymmenen vuoden kokemus yritysjärjestelmien suunnittelusta, johtamisesta ja kehittämisestä. David on osa asiantuntijatiimiä, joka keskittyy auttamaan asiakkaita oppimaan, innovoimaan ja hyödyntämään näitä erittäin päteviä palveluita datansa avulla käyttötapauksiinsa.
David Girling on vanhempi AI/ML-ratkaisuarkkitehti, jolla on yli kahdenkymmenen vuoden kokemus yritysjärjestelmien suunnittelusta, johtamisesta ja kehittämisestä. David on osa asiantuntijatiimiä, joka keskittyy auttamaan asiakkaita oppimaan, innovoimaan ja hyödyntämään näitä erittäin päteviä palveluita datansa avulla käyttötapauksiinsa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/create-a-document-lake-using-large-scale-text-extraction-from-documents-with-amazon-textract/

