شناسایی آمازون اضافه کردن تجزیه و تحلیل تصویر و ویدئو به برنامه های خود را آسان می کند. این مبتنی بر همان فناوری یادگیری عمیق اثبات شده، بسیار مقیاس پذیر و توسعه یافته توسط دانشمندان بینایی کامپیوتر آمازون برای تجزیه و تحلیل روزانه میلیاردها تصویر و ویدیو است. برای استفاده از آن نیازی به تخصص یادگیری ماشین (ML) نیست و ما به طور مداوم ویژگیهای بینایی کامپیوتری جدیدی را به این سرویس اضافه میکنیم. آمازون Rekognition شامل یک API ساده و با کاربری آسان است که می تواند به سرعت هر تصویر یا فایل ویدیویی ذخیره شده در آن را تجزیه و تحلیل کند. سرویس ذخیره سازی ساده آمازون (Amazon S3).
مشتریان در صنایعی مانند فناوری تبلیغات و بازاریابی، بازیها، رسانهها، و خردهفروشی و تجارت الکترونیک به تصاویر آپلود شده توسط کاربران نهایی خود (محتوای تولید شده توسط کاربر یا UGC) به عنوان یک مؤلفه مهم برای ایجاد تعامل در پلتفرم خود متکی هستند. آنها استفاده می کنند تعدیل محتوای شناسایی آمازون برای شناسایی محتوای نامناسب، ناخواسته و توهینآمیز به منظور محافظت از اعتبار برند خود و تقویت جوامع ایمن کاربران.
در این پست به موارد زیر می پردازیم:
- Content Moderation مدل نسخه 7.0 و قابلیت ها
- چگونه تجزیه و تحلیل انبوه شناسایی آمازون برای تعدیل محتوا کار می کند؟
- چگونه می توان پیش بینی اعتدال محتوا را با تجزیه و تحلیل انبوه و تعدیل سفارشی بهبود بخشید
مدل تعدیل محتوا نسخه 7.0 و قابلیت ها
Amazon Rekognition Content Moderation نسخه 7.0 26 برچسب تعدیل جدید اضافه می کند و طبقه بندی برچسب های تعدیل را از دسته برچسب های دو لایه به سه لایه گسترش می دهد. این برچسبهای جدید و طبقهبندی گسترده مشتریان را قادر میسازد تا مفاهیم دقیق محتوایی را که میخواهند تعدیل کنند، شناسایی کنند. علاوه بر این، مدل به روز شده قابلیت جدیدی را برای شناسایی دو نوع محتوای جدید، محتوای متحرک و مصور معرفی می کند. این به مشتریان اجازه می دهد تا قوانین دقیقی را برای گنجاندن یا حذف چنین انواع محتوایی از گردش کار تعدیل خود ایجاد کنند. با این به روز رسانی های جدید، مشتریان می توانند محتوا را مطابق با خط مشی محتوای خود با دقت بالاتر تعدیل کنند.
بیایید به یک مثال تشخیص برچسب اعتدال برای تصویر زیر نگاه کنیم.

جدول زیر برچسبهای تعدیل، نوع محتوا و امتیازات اطمینان بازگشتشده در پاسخ API را نشان میدهد.
| برچسب های اعتدال | سطح طبقه بندی | نمرات اعتماد به نفس |
| خشونت | L1 | ٪۱۰۰ |
| خشونت گرافیکی | L2 | ٪۱۰۰ |
| انفجارها و انفجارها | L3 | ٪۱۰۰ |
| انواع محتوا | نمرات اعتماد به نفس |
| مصور | ٪۱۰۰ |
برای به دست آوردن طبقه بندی کامل برای Content Moderation نسخه 7.0، به ما مراجعه کنید راهنمای توسعه دهنده.
تجزیه و تحلیل انبوه برای تعدیل محتوا
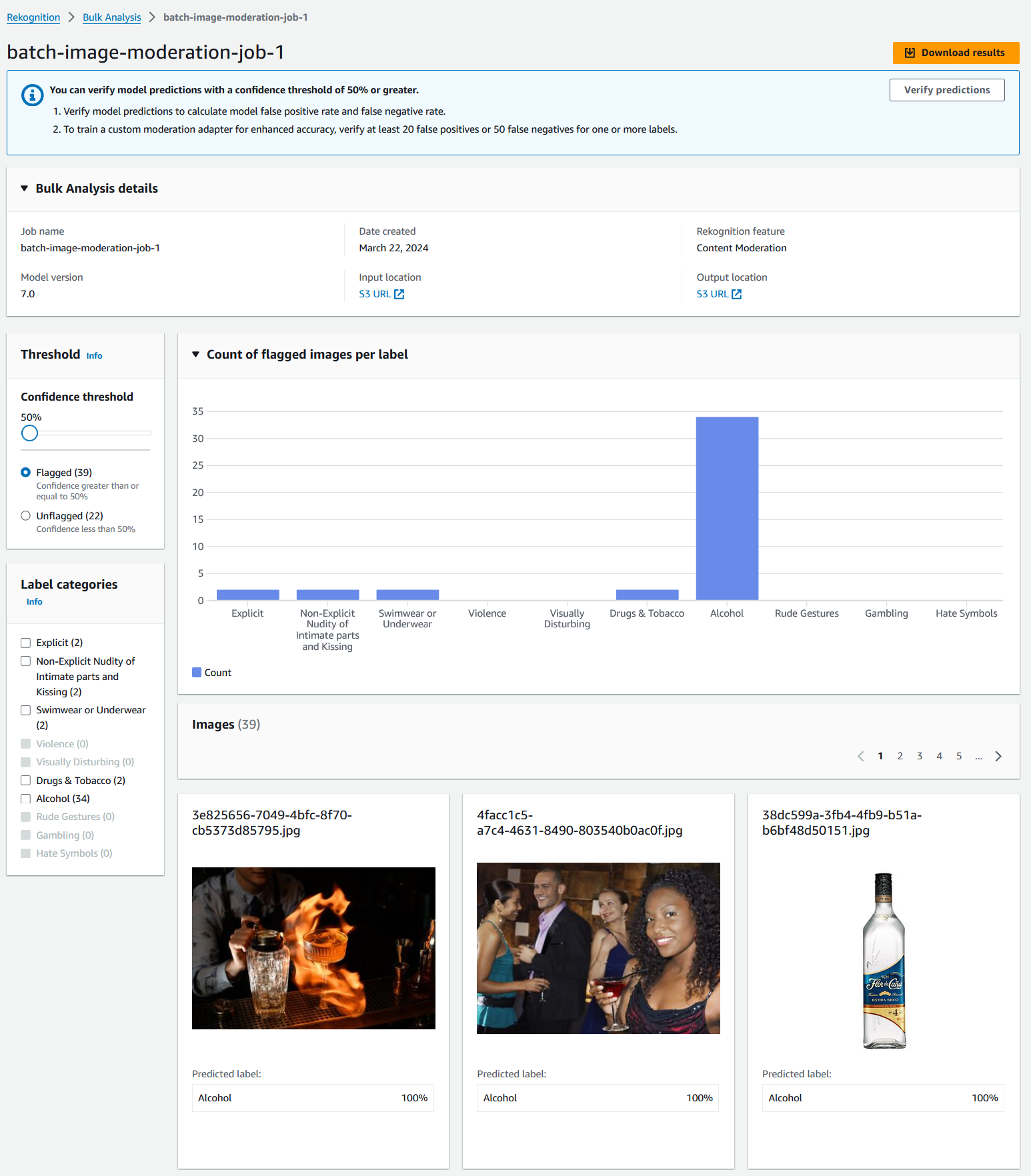
Amazon Rekognition Content Moderation علاوه بر تعدیل در زمان واقعی، تعدیل تصویر دستهای را با استفاده از تجزیه و تحلیل انبوه شناسایی آمازون. این به شما امکان میدهد تا مجموعههای تصویری بزرگ را به صورت ناهمزمان تجزیه و تحلیل کنید تا محتوای نامناسب را شناسایی کنید و بینشهایی در مورد دستههای تعدیل اختصاص داده شده به تصاویر به دست آورید. همچنین نیاز به ساخت راه حل تعدیل تصویر دسته ای برای مشتریان را از بین می برد.
میتوانید از طریق کنسول آمازون Rekognition یا با تماس مستقیم با APIها با استفاده از AWS CLI و AWS SDK به ویژگی تجزیه و تحلیل انبوه دسترسی پیدا کنید. در کنسول آمازون Rekognition می توانید تصاویری را که می خواهید آنالیز کنید بارگذاری کنید و با چند کلیک به نتیجه برسید. پس از تکمیل کار تجزیه و تحلیل انبوه، میتوانید پیشبینیهای برچسب تعدیل را شناسایی و مشاهده کنید، مانند برهنگی صریح، غیر صریح برهنگی اعضای صمیمی و بوسیدن، خشونت، مواد مخدر و تنباکو، و موارد دیگر. همچنین برای هر دسته برچسب یک امتیاز اطمینان دریافت می کنید.
در کنسول آمازون Rekognition یک کار تجزیه و تحلیل انبوه ایجاد کنید
مراحل زیر را تکمیل کنید تا تجزیه و تحلیل انبوه شناسایی آمازون را امتحان کنید:
- در کنسول آمازون Rekognition، را انتخاب کنید تحلیل انبوه در صفحه ناوبری
- را انتخاب کنید تجزیه و تحلیل انبوه را شروع کنید.
- نام شغلی را وارد کنید و تصاویر را برای تجزیه و تحلیل مشخص کنید، یا با وارد کردن یک مکان سطل S3 یا با آپلود تصاویر از رایانه خود.
- به صورت اختیاری، می توانید یک را انتخاب کنید آداپتور برای تجزیه و تحلیل تصاویر با استفاده از آداپتور سفارشی که با استفاده از Custom Moderation آموزش داده اید.
- را انتخاب کنید تجزیه و تحلیل را شروع کنید برای اجرای کار

پس از تکمیل فرآیند، می توانید نتایج را در کنسول شناسایی آمازون مشاهده کنید. همچنین، یک کپی JSON از نتایج تجزیه و تحلیل در محل خروجی آمازون S3 ذخیره خواهد شد.
درخواست API تجزیه و تحلیل انبوه آمازون
در این بخش، ما شما را از طریق ایجاد یک کار تجزیه و تحلیل انبوه برای تعدیل تصویر با استفاده از رابط های برنامه نویسی راهنمایی می کنیم. اگر فایلهای تصویری شما قبلاً در سطل S3 نیستند، آنها را آپلود کنید تا از دسترسی آمازون Rekognition مطمئن شوید. مشابه ایجاد یک کار تجزیه و تحلیل انبوه در کنسول شناسایی آمازون، هنگام فراخوانی StartMediaAnalysisJob API، شما باید پارامترهای زیر را ارائه دهید:
- OperationsConfig – اینها گزینه های پیکربندی برای کار تحلیل رسانه ای هستند که باید ایجاد شوند:
- MinConfidence - حداقل سطح اطمینان با محدوده معتبر 0-100 برای برچسب های تعدیل برای بازگشت. آمازون Rekognition هیچ برچسبی را با سطح اطمینان کمتر از این مقدار مشخص شده بر نمی گرداند.
- ورودی - این شامل موارد زیر است:
- S3Object – اطلاعات شی S3 برای فایل مانیفست ورودی، از جمله سطل و نام فایل. فایل ورودی شامل خطوط JSON برای هر تصویر ذخیره شده در سطل S3 است. مثلا:
{"source-ref": "s3://MY-INPUT-BUCKET/1.jpg"}
- S3Object – اطلاعات شی S3 برای فایل مانیفست ورودی، از جمله سطل و نام فایل. فایل ورودی شامل خطوط JSON برای هر تصویر ذخیره شده در سطل S3 است. مثلا:
- OutputConfig - این شامل موارد زیر است:
- S3Bucket – نام سطل S3 برای فایل های خروجی.
- S3KeyPrefix – پیشوند کلید برای فایل های خروجی.
کد زیر را ببینید:
می توانید همان تحلیل رسانه را با استفاده از دستور AWS CLI زیر فراخوانی کنید:
نتایج API تجزیه و تحلیل انبوه آمازون
برای دریافت لیست کارهای آنالیز انبوه می توانید استفاده کنید ListMediaAnalysisJobs. پاسخ شامل تمام جزئیات مربوط به فایل های ورودی و خروجی کار تجزیه و تحلیل و وضعیت کار است:
شما همچنین می توانید فراخوانی کنید list-media-analysis-jobs دستور از طریق AWS CLI:
Amazon Rekognition Bulk Analysis دو فایل خروجی را در سطل خروجی تولید می کند. فایل اول است manifest-summary.json، که شامل آمار کار تجزیه و تحلیل انبوه و لیستی از خطاها است:
فایل دوم است results.json، که شامل یک خط JSON برای هر تصویر تجزیه و تحلیل شده در قالب زیر است. هر نتیجه شامل دسته سطح بالا (L1) یک برچسب شناسایی شده و دسته سطح دوم برچسب (L2)، با امتیاز اطمینان بین 1 تا 100. برخی از برچسبهای طبقهبندی سطح 2 ممکن است دارای برچسبهای طبقهبندی سطح 3 (L3) باشند. این اجازه می دهد تا یک طبقه بندی سلسله مراتبی از محتوا.

شما می توانید آداپتورهای تعدیل سفارشی بعداً با انتخاب آداپتور سفارشی و در حین ایجاد یک کار تجزیه و تحلیل انبوه جدید یا از طریق API با ارسال شناسه آداپتور منحصر به فرد آداپتور سفارشی، تصاویر خود را تجزیه و تحلیل کنید.
خلاصه
در این پست، مروری بر Content Moderation نسخه 7.0، تجزیه و تحلیل انبوه برای تعدیل محتوا، و نحوه بهبود پیش بینی های Content Moderation با استفاده از تجزیه و تحلیل انبوه و مدیریت سفارشی ارائه کردیم. برای امتحان برچسبهای تعدیل جدید و تجزیه و تحلیل انبوه، به حساب AWS خود وارد شوید و کنسول شناسایی آمازون را بررسی کنید. تعدیل تصویر و تحلیل انبوه.
درباره نویسندگان
 مهدی حقی یک معمار ارشد راه حل در تیم AWS WWCS، متخصص در AI و ML در AWS است. او با مشتریان سازمانی کار می کند و به آنها کمک می کند تا به مهاجرت، مدرن سازی و بهینه سازی حجم کاری خود برای ابر AWS کمک کنند. او در اوقات فراغت از پخت غذاهای ایرانی و قلع و قمع الکترونیک لذت می برد.
مهدی حقی یک معمار ارشد راه حل در تیم AWS WWCS، متخصص در AI و ML در AWS است. او با مشتریان سازمانی کار می کند و به آنها کمک می کند تا به مهاجرت، مدرن سازی و بهینه سازی حجم کاری خود برای ابر AWS کمک کنند. او در اوقات فراغت از پخت غذاهای ایرانی و قلع و قمع الکترونیک لذت می برد.
 شیپرا کانوریا مدیر محصول اصلی در AWS است. او مشتاق کمک به مشتریان برای حل پیچیده ترین مشکلاتشان با قدرت یادگیری ماشینی و هوش مصنوعی است. قبل از پیوستن به AWS، شیپرا بیش از 4 سال را در آمازون الکسا گذراند، جایی که بسیاری از ویژگیهای مرتبط با بهرهوری را در دستیار صوتی الکسا راهاندازی کرد.
شیپرا کانوریا مدیر محصول اصلی در AWS است. او مشتاق کمک به مشتریان برای حل پیچیده ترین مشکلاتشان با قدرت یادگیری ماشینی و هوش مصنوعی است. قبل از پیوستن به AWS، شیپرا بیش از 4 سال را در آمازون الکسا گذراند، جایی که بسیاری از ویژگیهای مرتبط با بهرهوری را در دستیار صوتی الکسا راهاندازی کرد.
 ماریا هاندوکو مدیر محصول ارشد در AWS است. او بر کمک به مشتریان برای حل چالش های تجاری خود از طریق یادگیری ماشینی و بینایی کامپیوتر تمرکز دارد. او در اوقات فراغت خود از پیاده روی، گوش دادن به پادکست ها و کاوش در غذاهای مختلف لذت می برد.
ماریا هاندوکو مدیر محصول ارشد در AWS است. او بر کمک به مشتریان برای حل چالش های تجاری خود از طریق یادگیری ماشینی و بینایی کامپیوتر تمرکز دارد. او در اوقات فراغت خود از پیاده روی، گوش دادن به پادکست ها و کاوش در غذاهای مختلف لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/improving-content-moderation-with-amazon-rekognition-bulk-analysis-and-custom-moderation/

