تخمین وضعیت یک تکنیک بینایی کامپیوتری است که مجموعه ای از نقاط روی اشیاء (مانند افراد یا وسایل نقلیه) را در تصاویر یا ویدیوها تشخیص می دهد. تخمین پوس دارای کاربردهای دنیای واقعی در ورزش، رباتیک، امنیت، واقعیت افزوده، رسانه و سرگرمی، کاربردهای پزشکی و غیره است. مدلهای تخمین پوز بر روی تصاویر یا ویدیوهایی آموزش داده میشوند که با مجموعهای از نقاط (مختصات) مشخص شده توسط یک دکل حاشیهنویسی شدهاند. برای آموزش مدل های تخمین ژست دقیق، ابتدا باید مجموعه داده بزرگی از تصاویر حاشیه نویسی را به دست آورید. بسیاری از مجموعه داده ها دارای ده ها یا صدها هزار تصویر حاشیه نویسی هستند و برای ساختن آنها منابع قابل توجهی نیاز است. اشتباهات برچسبگذاری برای شناسایی و جلوگیری از آن مهم است زیرا عملکرد مدل برای مدلهای تخمین پوزی به شدت تحت تأثیر کیفیت دادههای برچسبگذاری شده و حجم داده است.
در این پست، ما نشان می دهیم که چگونه می توانید از یک گردش کاری برچسب گذاری سفارشی در آن استفاده کنید Amazon SageMaker Ground Truth به طور خاص برای برچسب گذاری نقاط کلیدی طراحی شده است. این گردش کار سفارشی به سادهسازی فرآیند برچسبگذاری و به حداقل رساندن خطاهای برچسبگذاری کمک میکند، در نتیجه هزینه دریافت برچسبهای پوز با کیفیت بالا را کاهش میدهد.
اهمیت داده های با کیفیت بالا و کاهش خطاهای برچسب گذاری
دادههای با کیفیت بالا برای آموزش مدلهای تخمین پوز قوی و قابل اعتماد اساسی است. دقت این مدلها مستقیماً به صحت و دقت برچسبهای اختصاص داده شده به هر نقطه کلیدی مربوط میشود، که به نوبه خود به اثربخشی فرآیند حاشیهنویسی بستگی دارد. علاوه بر این، داشتن حجم قابل توجهی از دادههای متنوع و مشروحشده تضمین میکند که مدل میتواند طیف وسیعی از موقعیتها، تغییرات و سناریوها را بیاموزد که منجر به تعمیم و عملکرد بهتر در برنامههای مختلف دنیای واقعی میشود. دستیابی به این مجموعه دادههای بزرگ و حاشیهنویسی شامل حاشیهنویسهای انسانی میشود که به دقت تصاویر را با اطلاعات پوز برچسبگذاری میکنند. هنگام برچسب زدن نقاط مورد علاقه در تصویر، دیدن ساختار اسکلتی شی در هنگام برچسب زدن به منظور ارائه راهنمایی بصری به حاشیه نویس مفید است. این برای شناسایی خطاهای برچسبگذاری قبل از گنجاندن آنها در مجموعه دادهها مانند تعویض چپ و راست یا برچسبهای اشتباه (مانند علامتگذاری پا بهعنوان شانه) مفید است. به عنوان مثال، یک خطای برچسبگذاری مانند جابجایی چپ و راست انجام شده در مثال زیر را میتوان به راحتی با عبور از خطوط دکل اسکلت و عدم تطابق رنگها شناسایی کرد. این نشانههای بصری به برچسبگذاران کمک میکند تا اشتباهات را تشخیص دهند و منجر به مجموعهای تمیزتر از برچسبها میشود.
با توجه به ماهیت دستی برچسبگذاری، دستیابی به مجموعه دادههای برچسبگذاری شده بزرگ و دقیق میتواند مقرون به صرفه باشد و حتی بیشتر از آن با یک سیستم برچسبگذاری ناکارآمد. بنابراین، کارایی و دقت برچسبگذاری هنگام طراحی گردش کار برچسبگذاری بسیار مهم است. در این پست، نحوه استفاده از یک گردش کاری برچسبگذاری SageMaker Ground Truth سفارشی برای حاشیهنویسی سریع و دقیق تصاویر را نشان میدهیم، و بار توسعه مجموعههای داده بزرگ را برای گردشهای کاری تخمین پوز کاهش میدهد.

بررسی اجمالی راه حل
این راه حل یک پورتال وب آنلاین فراهم می کند که در آن نیروی کار برچسب زنی می تواند از یک مرورگر وب برای ورود به سیستم، دسترسی به کارهای برچسب زدن و حاشیه نویسی تصاویر با استفاده از رابط کاربری crowd-2d-skeleton (UI)، یک رابط کاربری سفارشی طراحی شده برای برچسب گذاری نقطه کلیدی و ژست استفاده کند. SageMaker Ground Truth. حاشیه نویسی یا برچسب های ایجاد شده توسط نیروی کار برچسب زنی سپس به یک صادر می شود سرویس ذخیره سازی ساده آمازون سطل (Amazon S3)، جایی که می توان از آنها برای فرآیندهای پایین دستی مانند آموزش مدل های بینایی کامپیوتری یادگیری عمیق استفاده کرد. این راه حل شما را با نحوه راه اندازی و استقرار اجزای لازم برای ایجاد یک پورتال وب و همچنین نحوه ایجاد مشاغل برچسب گذاری برای این گردش کار برچسب گذاری راهنمایی می کند.
در زیر نموداری از معماری کلی ارائه شده است.

این معماری از چندین مؤلفه کلیدی تشکیل شده است که در بخش های بعدی هر کدام را با جزئیات بیشتری توضیح می دهیم. این معماری یک پورتال اینترنتی آنلاین به میزبانی SageMaker Ground Truth در اختیار نیروی کار برچسبگذاری قرار میدهد. این پورتال به هر برچسبگذار اجازه میدهد تا وارد شود و کارهای برچسبگذاری خود را ببیند. پس از ورود به سیستم، برچسبگذار میتواند یک کار برچسبگذاری را انتخاب کند و با استفاده از رابط کاربری سفارشی که توسط آمازون CloudFront. ما استفاده می کنیم AWS لامبدا توابع برای پردازش داده های قبل از حاشیه نویسی و پس از حاشیه نویسی.
تصویر زیر نمونه ای از رابط کاربری است.
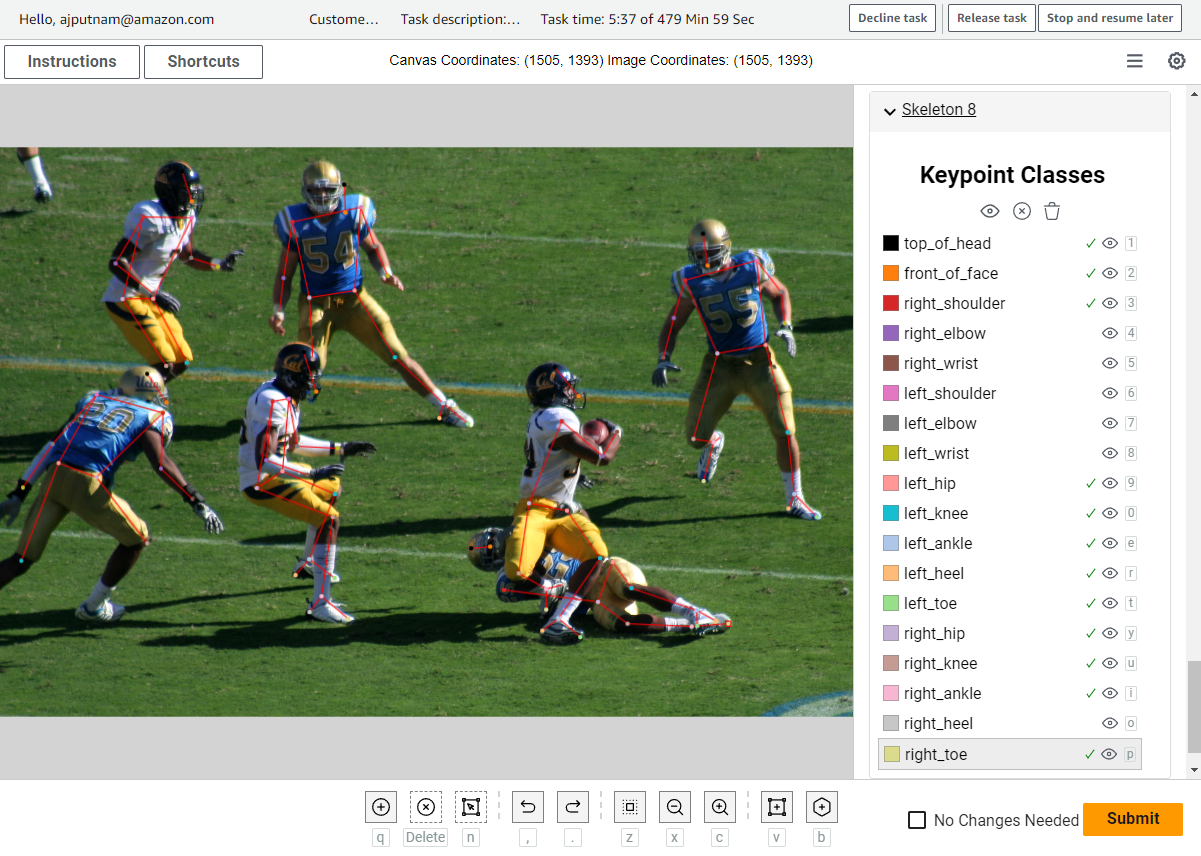
برچسبگذار میتواند با استفاده از رابط کاربری، نقاط کلیدی خاصی را روی تصویر علامتگذاری کند. خطوط بین نقاط کلیدی به طور خودکار برای کاربر بر اساس تعریف اسکلت ریگ که UI استفاده می کند ترسیم می شود. UI امکان سفارشی سازی های زیادی را فراهم می کند، مانند موارد زیر:
- نام نقاط کلیدی سفارشی
- رنگ های کلیدی قابل تنظیم
- رنگ های خط دکل قابل تنظیم
- ساختارهای اسکلت و دکل قابل تنظیم
هر یک از این ویژگیهای هدفمند برای بهبود سهولت و انعطافپذیری برچسبگذاری هستند. جزئیات سفارشی سازی UI خاص را می توان در GitHub repo و در ادامه این پست خلاصه می شود. توجه داشته باشید که در این پست، ما از تخمین ژست انسان به عنوان یک کار پایه استفاده میکنیم، اما میتوانید آن را به برچسبگذاری ژست شی با یک دکل از پیش تعریفشده برای اشیاء دیگر نیز مانند حیوانات یا وسایل نقلیه گسترش دهید. در مثال زیر، نشان میدهیم که چگونه میتوان از این برای برچسبگذاری نقاط یک کامیون جعبهای استفاده کرد.

SageMaker Ground Truth
در این راه حل، ما از SageMaker Ground Truth برای ارائه یک پورتال آنلاین و راهی برای مدیریت مشاغل برچسب زدن به نیروی کار برچسب زنی استفاده می کنیم. این پست فرض می کند که شما با SageMaker Ground Truth آشنا هستید. برای اطلاعات بیشتر مراجعه کنید Amazon SageMaker Ground Truth.
توزیع CloudFront
برای این راه حل، رابط کاربری برچسبگذاری به یک جزء جاوا اسکریپت سفارشی به نام مولفه crowd-2d-skeleton نیاز دارد. این جزء را می توان در یافت GitHub به عنوان بخشی از ابتکارات منبع باز آمازون. توزیع CloudFront برای میزبانی استفاده خواهد شد crowd-2d-skeleton.js، که توسط SageMaker Ground Truth UI مورد نیاز است. به توزیع CloudFront یک هویت دسترسی مبدأ اختصاص داده می شود که به توزیع CloudFront اجازه می دهد به crowd-2d-skeleton.js موجود در سطل S3 دسترسی داشته باشد. سطل S3 خصوصی باقی میماند و هیچ شیء دیگری در این سطل از طریق توزیع CloudFront در دسترس نخواهد بود، به دلیل محدودیتهایی که از طریق یک خطمشی سطل بر روی هویت دسترسی مبدا اعمال میکنیم. این یک عمل توصیه شده برای پیروی از اصل کمترین امتیاز است.
سطل آمازون S3
ما از سطل S3 برای ذخیره فایلهای مانیفست ورودی و خروجی SageMaker Ground Truth، الگوی رابط کاربری سفارشی، تصاویر برای کارهای برچسبگذاری و کد جاوا اسکریپت مورد نیاز برای رابط کاربری سفارشی استفاده میکنیم. این سطل خصوصی خواهد بود و برای عموم قابل دسترسی نیست. این سطل همچنین دارای یک خط مشی سطلی است که توزیع CloudFront را محدود می کند تا فقط بتواند به کد جاوا اسکریپت مورد نیاز برای رابط کاربری دسترسی داشته باشد. این مانع از میزبانی توزیع CloudFront از هر شی دیگری در سطل S3 می شود.
تابع لامبدا قبل از حاشیه نویسی
کارهای برچسبگذاری SageMaker Ground Truth معمولاً از یک فایل مانیفست ورودی استفاده میکنند که در قالب JSON Lines است. این فایل مانیفست ورودی حاوی ابرداده برای یک کار برچسبگذاری است، به عنوان مرجعی برای دادههایی عمل میکند که باید برچسبگذاری شوند، و به پیکربندی نحوه ارائه دادهها به حاشیهنویسها کمک میکند. تابع Lambda قبل از حاشیه نویسی، موارد را از فایل مانیفست ورودی قبل از ورود داده های مانیفست به الگوی UI سفارشی پردازش می کند. این جایی است که هر گونه قالب بندی یا اصلاحات ویژه در موارد می تواند قبل از ارائه داده ها به حاشیه نویسان در UI انجام شود. برای اطلاعات بیشتر در مورد عملکردهای Lambda قبل از حاشیه نویسی، رجوع کنید به قبل از حاشیه نویسی لامبدا.
تابع Lambda پس از حاشیه نویسی
مشابه عملکرد Lambda قبل از حاشیه نویسی، تابع پس از حاشیه نویسی پردازش داده های بیشتری را انجام می دهد که ممکن است بخواهید پس از پایان برچسب زدن همه برچسب ها، اما قبل از نوشتن نتایج خروجی حاشیه نویسی نهایی انجام دهید. این پردازش توسط یک تابع Lambda انجام می شود، که مسئول قالب بندی داده ها برای نتایج خروجی کار برچسب زدن است. در این راه حل، ما به سادگی از آن برای برگرداندن داده ها در فرمت خروجی دلخواه خود استفاده می کنیم. برای اطلاعات بیشتر در مورد توابع لامبدا پس از حاشیه نویسی، رجوع کنید پس از حاشیه نویسی لامبدا.
نقش تابع لامبدا پس از حاشیه نویسی
ما از یک هویت AWS و مدیریت دسترسی نقش (IAM) برای دسترسی تابع Lambda پس از حاشیه نویسی به سطل S3. این برای خواندن نتایج حاشیه نویسی و ایجاد هرگونه تغییر قبل از نوشتن نتایج نهایی در فایل مانیفست خروجی لازم است.
نقش SageMaker Ground Truth
ما از این نقش IAM استفاده میکنیم تا به کار برچسبگذاری SageMaker Ground Truth توانایی فراخوانی توابع Lambda و خواندن تصاویر، فایلهای مانیفست و الگوی رابط کاربری سفارشی در سطل S3 را بدهیم.
پیش نیازها
برای این راهنما، شما باید پیش نیازهای زیر را داشته باشید:
برای این راه حل، ما از CDK AWS برای استقرار معماری استفاده می کنیم. سپس یک کار برچسبگذاری نمونه ایجاد میکنیم، از پورتال حاشیهنویسی برای برچسبگذاری تصاویر در کار برچسبگذاری استفاده میکنیم و نتایج برچسبگذاری را بررسی میکنیم.
پشته AWS CDK را ایجاد کنید
پس از تکمیل تمام پیش نیازها، آماده استقرار راه حل هستید.
منابع خود را تنظیم کنید
برای تنظیم منابع خود مراحل زیر را انجام دهید:
- پشته نمونه را از GitHub repo.
- از دستور cd برای تغییر به مخزن استفاده کنید.
- محیط پایتون خود را ایجاد کنید و بسته های مورد نیاز را نصب کنید (برای جزئیات بیشتر به مخزن README.md مراجعه کنید).
- با فعال شدن محیط پایتون، دستور زیر را اجرا کنید:
- دستور زیر را برای استقرار CDK AWS اجرا کنید:
- برای اجرای اسکریپت post-deployment دستور زیر را اجرا کنید:
یک کار برچسب زدن ایجاد کنید
پس از اینکه منابع خود را تنظیم کردید، آماده ایجاد یک کار برچسب زدن هستید. برای اهداف این پست، با استفاده از نمونه اسکریپت ها و تصاویر ارائه شده در مخزن، یک کار برچسب گذاری ایجاد می کنیم.
- سی دی به
scriptsدایرکتوری در مخزن - با اجرای کد زیر نمونه تصاویر را از اینترنت دانلود کنید:
این اسکریپت مجموعه ای از 10 تصویر را دانلود می کند که ما از آنها در کار برچسب زدن مثال خود استفاده می کنیم. نحوه استفاده از داده های ورودی سفارشی خود را در ادامه این پست بررسی می کنیم.
- با اجرای کد زیر، یک کار برچسبگذاری ایجاد کنید:
این اسکریپت یک ARN نیروی کار خصوصی SageMaker Ground Truth را به عنوان آرگومان می گیرد، که باید ARN نیروی کاری باشد که در همان حسابی که این معماری را در آن مستقر کرده اید دارید. این اسکریپت فایل مانیفست ورودی را برای کار برچسبزنی ما ایجاد میکند، آن را در Amazon S3 آپلود میکند و یک کار برچسبگذاری سفارشی SageMaker Ground Truth ایجاد میکند. در ادامه این پست به بررسی جزئیات این اسکریپت خواهیم پرداخت.
مجموعه داده را برچسب گذاری کنید
پس از اینکه کار نمونه برچسب زدن را راه اندازی کردید، در کنسول SageMaker و همچنین پورتال نیروی کار ظاهر می شود.

در پورتال نیروی کار، شغل لیبلینگ را انتخاب کرده و انتخاب کنید شروع به کار.

تصویری از مجموعه داده نمونه به شما نمایش داده می شود. در این مرحله، میتوانید از رابط کاربری سفارشی crowd-2d-skeleton برای حاشیهنویسی تصاویر استفاده کنید. می توانید با مراجعه به رابط کاربری crowd-2d-skeleton آشنا شوید نمای کلی رابط کاربری. ما از تعریف دکل استفاده می کنیم چالش مجموعه داده های تشخیص نقطه کلید COCO به عنوان دکل ژست انسان. برای تکرار، میتوانید این را بدون مؤلفه رابط کاربری سفارشی ما برای حذف یا اضافه کردن امتیاز بر اساس نیازهای خود سفارشی کنید.
وقتی حاشیه نویسی یک تصویر را تمام کردید، انتخاب کنید ارسال. این شما را به تصویر بعدی در مجموعه داده می برد تا زمانی که همه تصاویر برچسب گذاری شوند.

به نتایج برچسبگذاری دسترسی داشته باشید
هنگامی که برچسب زدن تمام تصاویر در کار برچسب زدن را تمام کردید، SageMaker Ground Truth تابع Lambda پس از حاشیه نویسی را فراخوانی می کند و یک فایل output.manifest حاوی تمام حاشیه نویسی ها تولید می کند. این output.manifest در سطل S3 ذخیره می شود. در مورد ما، مکان مانیفست خروجی باید از مسیر URI S3 پیروی کند s3://<bucket name> /labeling_jobs/output/<labeling job name>/manifests/output/output.manifest. فایل output.manifest یک فایل JSON Lines است که در آن هر خط مربوط به یک تصویر واحد و حاشیه نویسی آن از نیروی کار برچسب زدن است. هر مورد JSON Lines یک شی JSON با فیلدهای زیاد است. رشته مورد علاقه ما نامیده می شود label-results. مقدار این فیلد یک شی حاوی فیلدهای زیر است:
- data_object_id – شناسه یا نمایه مورد مانیفست ورودی
- data_object_s3_uri – تصویر آمازون S3 URI است
- image_file_name – نام فایل تصویر
- image_s3_location – آدرس آمازون S3 تصویر
- توضیحات_اصلی - حاشیه نویسی های اصلی (تنها در صورتی تنظیم و استفاده می شود که از یک گردش کار قبل از حاشیه نویسی استفاده می کنید)
- به روز شده_حاشیه ها - حاشیه نویسی برای تصویر
- worker_id - کارگر نیروی کار که حاشیه نویسی را انجام داده است
- هیچ_تغییر_نیازی نیست - اینکه آیا کادر بررسی بدون نیاز به تغییر انتخاب شده است یا خیر
- was_modified - آیا داده های حاشیه نویسی با داده های ورودی اصلی متفاوت است یا خیر
- total_time_in_secons - مدت زمانی که کارگر نیروی کار برای حاشیه نویسی تصویر صرف کرد
با استفاده از این فیلدها، می توانید به نتایج حاشیه نویسی خود برای هر تصویر دسترسی داشته باشید و محاسباتی مانند میانگین زمان برای برچسب زدن یک تصویر را انجام دهید.
مشاغل برچسب زدن خود را ایجاد کنید
اکنون که یک نمونه کار برچسبگذاری ایجاد کردهایم و فرآیند کلی را درک میکنید، کدی را که مسئول ایجاد فایل مانیفست و راهاندازی کار برچسبگذاری است، راهنمایی میکنیم. ما روی بخشهای کلیدی اسکریپت تمرکز میکنیم که ممکن است بخواهید آنها را تغییر دهید تا کارهای برچسبگذاری خود را راهاندازی کنید.
ما تکههایی از کد را پوشش میدهیم create_example_labeling_job.py اسکریپت واقع در مخزن GitHub. اسکریپت با تنظیم متغیرهایی که بعداً در اسکریپت استفاده می شوند شروع می شود. برخی از متغیرها برای سادگی کدگذاری سختی دارند، در حالی که برخی دیگر که وابسته به پشته هستند، در زمان اجرا با واکشی مقادیر ایجاد شده از پشته AWS CDK ما به صورت پویا وارد می شوند.
اولین بخش کلیدی در این اسکریپت ایجاد فایل مانیفست است. به یاد بیاورید که فایل مانیفست یک فایل خطوط JSON است که حاوی جزئیات یک کار برچسبگذاری SageMaker Ground Truth است. هر شیء JSON Lines نشان دهنده یک مورد (مثلاً یک تصویر) است که باید برچسب گذاری شود. برای این گردش کار، شی باید شامل فیلدهای زیر باشد:
- منبع-مرجع – آمازون S3 URI به تصویری که می خواهید برچسب بزنید.
- حاشیه نویسی – فهرستی از اشیاء حاشیه نویسی که برای پیش از حاشیه نویسی گردش کار استفاده می شود. را ببینید مستندات crowd-2d-skeleton برای جزئیات بیشتر در مورد مقادیر مورد انتظار.
اسکریپت با استفاده از بخش کد زیر برای هر تصویر در پوشه تصویر یک خط مانیفست ایجاد می کند:
اگر می خواهید از تصاویر مختلف استفاده کنید یا به دایرکتوری تصویر دیگری اشاره کنید، می توانید آن بخش از کد را تغییر دهید. علاوه بر این، اگر از یک گردش کار پیش از حاشیه نویسی استفاده می کنید، می توانید آرایه حاشیه نویسی را با یک رشته JSON متشکل از آرایه و تمام اشیاء حاشیه نویسی آن به روز کنید. جزئیات فرمت این آرایه در مستند شده است مستندات crowd-2d-skeleton.
با آیتم های خط مانیفست که اکنون ایجاد شده است، می توانید فایل مانیفست را در سطل S3 که قبلا ایجاد کرده اید ایجاد و آپلود کنید:
اکنون که یک فایل مانیفست حاوی تصاویری که می خواهید برچسب گذاری کنید ایجاد کرده اید، می توانید یک کار برچسب گذاری ایجاد کنید. شما می توانید کار برچسب زدن را به صورت برنامه ریزی شده با استفاده از AWS SDK برای پایتون (Boto3). کد ایجاد یک کار برچسب زدن به شرح زیر است:
جنبه هایی از این کد که ممکن است بخواهید تغییر دهید عبارتند از LabelingJobName, TaskTitleو TaskDescription. LabelingJobName نام منحصربهفرد شغل برچسبگذاری است که SageMaker برای ارجاع به شغل شما استفاده میکند. این نامی است که در کنسول SageMaker ظاهر می شود. TaskTitle هدف مشابهی دارد، اما نیازی به منحصر به فرد بودن ندارد و نام شغلی است که در پورتال نیروی کار ظاهر می شود. ممکن است بخواهید این موارد را به چیزی که برچسب گذاری می کنید یا کار برچسب زدن به چه منظور است، مشخص کنید. در نهایت، ما آن را داریم TaskDescription رشته. این فیلد در پورتال نیروی کار ظاهر میشود تا زمینه بیشتری را برای برچسبگذاران در مورد اینکه وظیفه چیست، مانند دستورالعملها و راهنماییها برای کار، فراهم کند. برای اطلاعات بیشتر در مورد این زمینه ها و همچنین سایر زمینه ها، به ادامه مطلب مراجعه کنید مستندات create_labeling_job.
تنظیماتی را در UI انجام دهید
در این بخش، به برخی از روشهایی که میتوانید UI را سفارشی کنید، میپردازیم. در زیر لیستی از متداولترین سفارشیسازیهای بالقوه در رابط کاربری به منظور تنظیم آن با وظیفه مدلسازی شما آمده است:
- شما می توانید تعیین کنید که کدام نقاط کلیدی را می توان برچسب گذاری کرد. این شامل نام نقطه کلید و رنگ آن است.
- شما می توانید ساختار اسکلت (که نقاط کلیدی به هم متصل هستند) را تغییر دهید.
- می توانید رنگ خطوط را برای خطوط خاص بین نقاط کلیدی خاص تغییر دهید.
همه این سفارشیسازیهای رابط کاربری از طریق آرگومانهای ارسال شده به مؤلفه crowd-2d-skeleton، که جزء جاوا اسکریپت مورد استفاده در این است، قابل تنظیم هستند. قالب گردش کار سفارشی. در این الگو، کاربرد مولفه crowd-2d-skeleton را خواهید یافت. یک نسخه ساده شده در کد زیر نشان داده شده است:
در مثال کد قبلی، می توانید ویژگی های زیر را در کامپوننت مشاهده کنید: imgSrc, keypointClasses, skeletonRig, skeletonBoundingBoxو intialValues. ما هدف هر ویژگی را در بخشهای زیر توضیح میدهیم، اما سفارشیسازی رابط کاربری به همان اندازه ساده است که مقادیر این ویژگیها، ذخیره الگو و اجرای مجدد post_deployment_script.py قبلا استفاده کردیم
ویژگی imgSrc
La imgSrc ویژگی کنترل می کند که کدام تصویر در UI هنگام برچسب گذاری نشان داده شود. معمولاً برای هر آیتم خط مانیفست از یک تصویر متفاوت استفاده میشود، بنابراین این ویژگی اغلب به صورت پویا با استفاده از داخلی پر میشود. مایع زبان قالب در مثال کد قبلی می توانید ببینید که مقدار ویژگی روی آن تنظیم شده است {{ task.input.image_s3_uri | grant_read_access }}، که متغیر قالب مایع است که با واقعی جایگزین می شود image_s3_uri ارزش زمانی که الگو در حال ارائه است. فرآیند رندر زمانی شروع می شود که کاربر تصویری را برای حاشیه نویسی باز می کند. این فرآیند یک آیتم خطی را از فایل مانیفست ورودی می گیرد و آن را به تابع لامبدا قبل از حاشیه نویسی می فرستد. event.dataObject. تابع pre-annotation اطلاعات مورد نیاز خود را از آیتم خط می گیرد و a را برمی گرداند taskInput دیکشنری، که سپس به موتور رندر مایع منتقل می شود، که جایگزین متغیرهای مایع در قالب شما می شود. به عنوان مثال، فرض کنید یک فایل مانیفست با خط زیر دارید:
این داده ها به تابع pre-annotation منتقل می شوند. کد زیر نشان می دهد که چگونه تابع مقادیر را از شی رویداد استخراج می کند:
شی ای که از تابع برگردانده می شود در این حالت مانند کد زیر خواهد بود:
سپس داده های برگردانده شده از تابع در دسترس موتور قالب مایع قرار می گیرد، که مقادیر الگو را با مقادیر داده های برگردانده شده توسط تابع جایگزین می کند. نتیجه چیزی شبیه کد زیر خواهد بود:
ویژگی keypointClasses
La keypointClasses ویژگی مشخص می کند که کدام نقاط کلیدی در UI ظاهر می شوند و توسط حاشیه نویس ها استفاده می شوند. این ویژگی یک رشته JSON حاوی لیستی از اشیا را می گیرد. هر شی نشان دهنده یک نقطه کلیدی است. هر شی نقطه کلیدی باید شامل فیلدهای زیر باشد:
- id - یک مقدار منحصر به فرد برای شناسایی آن نقطه کلیدی.
- رنگ - رنگ نقطه کلیدی به عنوان یک رنگ هگز HTML نشان داده شده است.
- برچسب - نام یا کلاس کلید.
- x - این ویژگی اختیاری تنها در صورتی مورد نیاز است که بخواهید از قابلیت ترسیم اسکلت در رابط کاربری استفاده کنید. مقدار این ویژگی، موقعیت x نقطه کلید نسبت به کادر محدود اسکلت است. این مقدار معمولاً توسط ابزار Skeleton Rig Creator. اگر در حال انجام حاشیه نویسی نقطه کلید هستید و نیازی به کشیدن یک اسکلت کامل در یک زمان ندارید، می توانید این مقدار را روی 0 تنظیم کنید.
- y – این ویژگی اختیاری شبیه x است، اما برای بعد عمودی.
برای اطلاعات بیشتر در مورد keypointClasses صفت را ببینید مستندات keypointClasses.
ویژگی skeletonRig
La skeletonRig ویژگی کنترل می کند که کدام نقاط کلیدی باید خطوطی بین آنها کشیده شود. این ویژگی یک رشته JSON حاوی لیستی از جفتهای برچسب نقطه کلید میگیرد. هر جفت به UI اطلاع می دهد که کدام نقاط کلیدی را بین آنها خط بکشد. مثلا، '[["left_ankle","left_knee"],["left_knee","left_hip"]]' به UI اطلاع می دهد که بین آنها خط بکشد "left_ankle" و "left_knee" و بین آنها خط بکشید "left_knee" و "left_hip". این می تواند توسط ابزار Skeleton Rig Creator.
ویژگی skeletonBoundingBox
La skeletonBoundingBox ویژگی اختیاری است و تنها در صورتی لازم است که بخواهید از قابلیت ترسیم اسکلت در UI استفاده کنید. قابلیت ترسیم اسکلت توانایی حاشیه نویسی کل اسکلت ها با یک عمل حاشیه نویسی واحد است. ما در این پست به این ویژگی نمی پردازیم. مقدار این ویژگی، ابعاد جعبه مرزی اسکلت است. این مقدار معمولاً توسط ابزار Skeleton Rig Creator. اگر در حال انجام حاشیه نویسی نقطه کلید هستید و نیازی به کشیدن یک اسکلت کامل در یک زمان ندارید، می توانید این مقدار را روی null قرار دهید. برای بدست آوردن این مقدار توصیه می شود از ابزار Skeleton Rig Creator استفاده کنید.
ویژگی intialValues
La initialValues ویژگی برای پر کردن UI با حاشیهنویسیهای بهدستآمده از فرآیند دیگر (مانند کار برچسبگذاری دیگر یا مدل یادگیری ماشین) از قبل استفاده میشود. این هنگام انجام کارهای تعدیل یا بررسی مفید است. دادههای این فیلد معمولاً به صورت پویا در همان توضیحات برای پر میشوند imgSrc صفت. جزئیات بیشتر را می توان در مستندات crowd-2d-skeleton.
پاک کردن
برای جلوگیری از تحمیل هزینه در آینده، باید اشیاء موجود در سطل S3 خود را حذف کنید و پشته AWS CDK خود را حذف کنید. می توانید اشیاء S3 خود را از طریق کنسول آمازون SageMaker یا از طریق آن حذف کنید رابط خط فرمان AWS (AWS CLI). بعد از اینکه تمام اشیاء S3 را در سطل حذف کردید، می توانید با اجرای کد زیر CDK AWS را از بین ببرید:
با این کار منابعی که قبلا ایجاد کرده اید حذف می شود.
ملاحظات
ممکن است برای تولید گردش کار شما به مراحل اضافی نیاز باشد. در اینجا برخی از ملاحظات بسته به مشخصات ریسک سازمان شما وجود دارد:
- اضافه کردن دسترسی و گزارش برنامه
- افزودن فایروال برنامه وب (WAF)
- تنظیم مجوزهای IAM برای پیروی از حداقل امتیاز
نتیجه
در این پست، اهمیت کارایی و دقت برچسبگذاری در مجموعه دادههای تخمین پوز را به اشتراک گذاشتیم. برای کمک به هر دو مورد، نشان دادیم که چگونه میتوانید از SageMaker Ground Truth برای ایجاد جریانهای کاری برچسبگذاری سفارشی برای پشتیبانی از وظایف برچسبگذاری پوز مبتنی بر اسکلت استفاده کنید، با هدف افزایش کارایی و دقت در طول فرآیند برچسبگذاری. ما نشان دادیم که چگونه میتوانید کد و مثالها را به الزامات مختلف برچسبگذاری تخمین پوز سفارشی گسترش دهید.
ما شما را تشویق میکنیم که از این راهحل برای وظایف برچسبگذاری خود استفاده کنید و برای کمک یا درخواستهای مربوط به گردشهای کاری برچسبگذاری سفارشی، با AWS درگیر شوید.
درباره نویسنده
 آرتور پاتنام یک دانشمند تمام پشته داده در خدمات حرفه ای AWS است. تخصص آرتور حول محور توسعه و ادغام فناوریهای جلویی و بکاند در سیستمهای هوش مصنوعی است. خارج از محل کار، آرتور از کاوش در آخرین پیشرفت های فناوری، گذراندن وقت با خانواده و لذت بردن از فضای باز لذت می برد.
آرتور پاتنام یک دانشمند تمام پشته داده در خدمات حرفه ای AWS است. تخصص آرتور حول محور توسعه و ادغام فناوریهای جلویی و بکاند در سیستمهای هوش مصنوعی است. خارج از محل کار، آرتور از کاوش در آخرین پیشرفت های فناوری، گذراندن وقت با خانواده و لذت بردن از فضای باز لذت می برد.
 بن فنکر یک دانشمند ارشد داده در خدمات حرفه ای AWS است و به مشتریان کمک کرده است تا راه حل های ML را در صنایع مختلف از ورزش گرفته تا مراقبت های بهداشتی و تولید بسازند. او دکتری دارد. در فیزیک از دانشگاه A&M تگزاس و 6 سال تجربه در صنعت. بن از بیسبال، مطالعه و بزرگ کردن بچه هایش لذت می برد.
بن فنکر یک دانشمند ارشد داده در خدمات حرفه ای AWS است و به مشتریان کمک کرده است تا راه حل های ML را در صنایع مختلف از ورزش گرفته تا مراقبت های بهداشتی و تولید بسازند. او دکتری دارد. در فیزیک از دانشگاه A&M تگزاس و 6 سال تجربه در صنعت. بن از بیسبال، مطالعه و بزرگ کردن بچه هایش لذت می برد.
 جارویس لی یک دانشمند ارشد داده با خدمات حرفه ای AWS است. او بیش از شش سال است که با AWS کار می کند و با مشتریان در زمینه یادگیری ماشین و مشکلات بینایی کامپیوتری کار می کند. خارج از محل کار از دوچرخه سواری لذت می برد.
جارویس لی یک دانشمند ارشد داده با خدمات حرفه ای AWS است. او بیش از شش سال است که با AWS کار می کند و با مشتریان در زمینه یادگیری ماشین و مشکلات بینایی کامپیوتری کار می کند. خارج از محل کار از دوچرخه سواری لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/skeleton-based-pose-annotation-labeling-using-amazon-sagemaker-ground-truth/

