ایجاد خطوط لوله یادگیری ماشینی مقیاسپذیر و کارآمد برای سادهسازی توسعه، استقرار و مدیریت مدلهای ML بسیار مهم است. در این پست، ما چارچوبی برای خودکارسازی ایجاد یک گراف غیر چرخه ای جهت دار (DAG) برای خطوط لوله آمازون SageMaker بر اساس فایل های پیکربندی ساده را کد چارچوب و نمونه ها ارائه شده در اینجا فقط خطوط لوله آموزشی مدل را پوشش می دهد، اما می تواند به راحتی به خطوط لوله استنتاج دسته ای نیز گسترش یابد.
این چارچوب پویا از فایلهای پیکربندی برای هماهنگ کردن مراحل پیشپردازش، آموزش، ارزیابی، و ثبتنام برای موارد استفاده تک مدل و چند مدل بر اساس اسکریپتهای Python تعریفشده توسط کاربر، نیازهای زیرساخت (از جمله) استفاده میکند. ابر خصوصی مجازی آمازون زیرشبکه ها و گروه های امنیتی (Amazon VPC)، هویت AWS و مدیریت دسترسی نقش های (IAM)، سرویس مدیریت کلید AWS کلیدهای (AWS KMS)، رجیستری کانتینرها و انواع نمونه)، ورودی و خروجی سرویس ذخیره سازی ساده آمازون مسیرهای (Amazon S3) و برچسب های منابع. فایلهای پیکربندی (YAML و JSON) به پزشکان ML این امکان را میدهند که کدهای متمایز نشده را برای تنظیم خطوط لوله آموزشی با استفاده از نحو اعلانی مشخص کنند. این به دانشمندان داده امکان میدهد تا به سرعت مدلهای ML را بسازند و تکرار کنند، و مهندسان ML را قادر میسازد تا از طریق خطوط لوله ML یکپارچهسازی و تحویل پیوسته (CI/CD) سریعتر اجرا کنند و زمان تولید مدلها را کاهش دهند.
بررسی اجمالی راه حل
کد چارچوب پیشنهادی با خواندن فایل های پیکربندی شروع می شود. سپس به صورت پویا یک SageMaker Pipelines DAG را بر اساس مراحل اعلام شده در فایل های پیکربندی و تعاملات و وابستگی های بین مراحل ایجاد می کند. این چارچوب ارکستراسیون هم به موارد استفاده تک مدلی و هم چند مدلی پاسخ می دهد و یک جریان روان از داده ها و فرآیندها را فراهم می کند. مزایای اصلی این راه حل به شرح زیر است:
- اتوماسیون - کل گردش کار ML، از پیش پردازش داده تا رجیستری مدل، بدون مداخله دستی تنظیم شده است. این امر زمان و تلاش مورد نیاز برای آزمایش و عملیاتی سازی مدل را کاهش می دهد.
- تکرارپذیری – با یک فایل پیکربندی از پیش تعریف شده، دانشمندان داده و مهندسان ML می توانند کل گردش کار را بازتولید کنند و به نتایج ثابتی در چندین اجرا و محیط دست یابند.
- مقیاس پذیری - آمازون SageMaker در سرتاسر خط لوله استفاده میشود، و به پزشکان ML این امکان را میدهد تا مجموعههای داده بزرگ را پردازش کرده و مدلهای پیچیده را بدون نگرانی در زمینه زیرساخت آموزش دهند.
- انعطاف پذیری – این چارچوب انعطافپذیر است و میتواند طیف وسیعی از موارد استفاده از ML، چارچوبهای ML (مانند XGBoost و TensorFlow)، آموزش چند مدل و آموزش چند مرحلهای را در خود جای دهد. هر مرحله از DAG آموزشی را می توان از طریق فایل پیکربندی سفارشی کرد.
- حاکمیت مدل - رجیستری مدل آمازون SageMaker یکپارچه سازی امکان ردیابی نسخه های مدل را فراهم می کند و بنابراین آنها را با اطمینان به تولید ارتقا می دهد.
نمودار معماری زیر نشان می دهد که چگونه می توانید از چارچوب پیشنهادی در حین آزمایش و عملیاتی سازی مدل های ML استفاده کنید. در طول آزمایش، می توانید مخزن کد چارچوب ارائه شده در این پست و مخازن کد منبع خاص پروژه خود را در Amazon SageMaker Studioو محیط مجازی خود را تنظیم کنید (در ادامه این پست توضیح داده خواهد شد). سپس می توانید اسکریپت های پیش پردازش، آموزش و ارزیابی و همچنین گزینه های پیکربندی را تکرار کنید. برای ایجاد و اجرای DAG آموزشی SageMaker Pipelines، میتوانید نقطه ورودی فریمورک را فراخوانی کنید، که تمام فایلهای پیکربندی را میخواند، مراحل لازم را ایجاد میکند و آنها را بر اساس ترتیب مراحل و وابستگیهای مشخص شده هماهنگ میکند.
در طول عملیاتی شدن، خط لوله CI مخزن کد چارچوب و مخازن آموزشی خاص پروژه را در یک AWS CodeBuild job، جایی که اسکریپت نقطه ورودی فریم ورک فراخوانی می شود تا DAG آموزشی SageMaker Pipelines را ایجاد یا به روز کند و سپس آن را اجرا کند.

ساختار مخزن
La مخزن GitHub شامل دایرکتوری ها و فایل های زیر است:
- /framework/conf/ – این دایرکتوری حاوی یک فایل پیکربندی است که برای تنظیم متغیرهای مشترک در تمام واحدهای مدل سازی مانند زیر شبکه ها، گروه های امنیتی و نقش IAM در زمان اجرا استفاده می شود. یک واحد مدل سازی دنباله ای از حداکثر شش مرحله برای آموزش یک مدل ML است.
- /framework/createmodel/ – این دایرکتوری حاوی یک اسکریپت پایتون است که a را ایجاد می کند مدل SageMaker شی بر اساس مصنوعات مدل از a مرحله آموزش SageMaker Pipelines. شی مدل بعداً در a استفاده می شود تبدیل دسته ای SageMaker کار برای ارزیابی عملکرد مدل در یک مجموعه آزمایشی.
- /framework/modelmetrics/ – این دایرکتوری حاوی یک اسکریپت پایتون است که یک اسکریپت ایجاد می کند پردازش آمازون SageMaker کار برای تولید معیارهای مدل گزارش JSON برای یک مدل آموزش دیده بر اساس نتایج یک کار تبدیل دسته ای SageMaker انجام شده بر روی داده های آزمایشی.
- /چارچوب/خط لوله/ – این فهرست شامل اسکریپت های پایتون است که از کلاس های پایتون تعریف شده در فهرست های چارچوب دیگر برای ایجاد یا به روز رسانی SageMaker Pipelines DAG بر اساس پیکربندی های مشخص شده استفاده می کند. اسکریپت model_unit.py توسط pipeline_service.py برای ایجاد یک یا چند واحد مدل سازی استفاده می شود. هر واحد مدل سازی دنباله ای از حداکثر شش مرحله برای آموزش یک مدل ML است: پردازش، آموزش، ایجاد مدل، تبدیل، معیارها و مدل ثبت. تنظیمات برای هر واحد مدل سازی باید در مخزن مربوطه مدل مشخص شود. Pipeline_service.py همچنین وابستگی هایی را در بین مراحل SageMaker Pipelines (نحوه توالی یا زنجیره ای شدن مراحل درون و بین واحدهای مدلسازی) بر اساس بخش sagemakerPipeline تنظیم می کند که باید در فایل پیکربندی یکی از مخازن مدل (مدل لنگر) تعریف شود. این به شما امکان می دهد وابستگی های پیش فرض استنباط شده توسط SageMaker Pipelines را لغو کنید. در ادامه این پست در مورد ساختار فایل پیکربندی بحث می کنیم.
- /چارچوب/پردازش/ – این فهرست شامل یک اسکریپت پایتون است که یک کار پردازش SageMaker را بر اساس تصویر داکر و اسکریپت نقطه ورودی مشخص شده ایجاد می کند.
- /framework/registermodel/ – این فهرست شامل یک اسکریپت پایتون برای ثبت یک مدل آموزش دیده به همراه معیارهای محاسبه شده آن در SageMaker Model Registry است.
- /چارچوب/آموزش/ – این دایرکتوری حاوی یک اسکریپت پایتون است که یک کار آموزشی SageMaker ایجاد می کند.
- /framework/transform/ – این دایرکتوری حاوی یک اسکریپت پایتون است که یک کار تبدیل دسته ای SageMaker را ایجاد می کند. در زمینه آموزش مدل، از این برای محاسبه معیار عملکرد یک مدل آموزش دیده بر روی داده های آزمون استفاده می شود.
- /framework/utilities/ – این دایرکتوری شامل اسکریپت های کاربردی برای خواندن و پیوستن به فایل های پیکربندی و همچنین ورود به سیستم می باشد.
- /framework_entrypoint.py – این فایل محل ورود کد فریمورک است. یک تابع تعریف شده در فهرست /framework/pipeline/ را برای ایجاد یا به روز رسانی SageMaker Pipelines DAG و اجرای آن فراخوانی می کند.
- /مثال ها/ – این دایرکتوری شامل چندین نمونه از نحوه استفاده از این چارچوب اتوماسیون برای ایجاد DAG های آموزشی ساده و پیچیده است.
- /env.env – این فایل به شما اجازه می دهد تا متغیرهای رایج مانند زیرشبکه ها، گروه های امنیتی و نقش IAM را به عنوان متغیرهای محیطی تنظیم کنید.
- /requirements.txt – این فایل کتابخانه های پایتون را مشخص می کند که برای کد فریمورک مورد نیاز هستند.
پیش نیازها
قبل از استفاده از این راه حل، باید پیش نیازهای زیر را داشته باشید:
- یک حساب AWS
- SageMaker Studio
- نقش SageMaker با مجوزهای خواندن/نوشتن Amazon S3 و رمزگذاری/رمزگشایی AWS KMS
- یک سطل S3 برای ذخیره داده ها، اسکریپت ها و مصنوعات مدل
- به صورت اختیاری، رابط خط فرمان AWS (AWS CLI)
- Python3 (Python 3.7 یا بالاتر) و بسته های Python زیر:
- boto3
- حکیم ساز
- PyYAML
- بسته های پایتون اضافی که در اسکریپت های سفارشی شما استفاده می شود
راه حل را مستقر کنید
مراحل زیر را برای استقرار راه حل کامل کنید:
- مخزن آموزش مدل خود را طبق ساختار زیر سازماندهی کنید:
- کد چارچوب و کد منبع مدل خود را از مخازن Git کلون کنید:
-
- کلون
dynamic-sagemaker-pipelines-frameworkمخزن را در یک فهرست آموزشی. در کد زیر فرض می کنیم دایرکتوری آموزش فراخوانی شده استaws-train: - کد منبع مدل را در همان دایرکتوری کلون کنید. برای آموزش چند مدل، این مرحله را برای هر تعداد مدلی که برای آموزش نیاز دارید تکرار کنید.
- کلون
برای آموزش تک مدل، دایرکتوری شما باید به شکل زیر باشد:
برای آموزش چند مدل، دایرکتوری شما باید به شکل زیر باشد:
- متغیرهای محیطی زیر را تنظیم کنید. ستاره ها متغیرهای محیطی مورد نیاز را نشان می دهند. بقیه اختیاری هستند
| متغیر محیطی | توضیحات: |
SMP_ACCOUNTID* |
حساب AWS جایی که خط لوله SageMaker در آن اجرا می شود |
SMP_REGION* |
منطقه AWS که در آن خط لوله SageMaker اجرا می شود |
SMP_S3BUCKETNAME* |
نام سطل S3 |
SMP_ROLE* |
نقش SageMaker |
SMP_MODEL_CONFIGPATH* |
مسیر نسبی فایل های پیکربندی تک مدل یا چند مدل |
SMP_SUBNETS |
شناسههای زیرشبکه برای پیکربندی شبکه SageMaker |
SMP_SECURITYGROUPS |
شناسههای گروه امنیتی برای پیکربندی شبکه SageMaker |
برای موارد استفاده تک مدل، SMP_MODEL_CONFIGPATH خواهد بود <MODEL-DIR>/conf/conf.yaml. برای موارد استفاده چند مدل، SMP_MODEL_CONFIGPATH خواهد بود */conf/conf.yaml، که به شما امکان می دهد همه را پیدا کنید conf.yaml فایل ها با استفاده از ماژول glob پایتون و ترکیب آنها برای تشکیل یک فایل پیکربندی جهانی. در طول آزمایش (تست محلی)، می توانید متغیرهای محیطی را در داخل فایل env.env مشخص کنید و سپس با اجرای دستور زیر در ترمینال خود، آنها را صادر کنید:
توجه داشته باشید که مقادیر متغیرهای محیطی در env.env باید در داخل علامت نقل قول قرار داده شود (به عنوان مثال، SMP_REGION="us-east-1"). در طول عملیاتی شدن، این متغیرهای محیطی باید توسط خط لوله CI تنظیم شوند.
- با اجرای دستورات زیر یک محیط مجازی ایجاد و فعال کنید:
- با اجرای دستور زیر بسته های پایتون مورد نیاز را نصب کنید:
- آموزش مدل خود را ویرایش کنید
conf.yamlفایل ها. ساختار فایل پیکربندی را در بخش بعدی مورد بحث قرار می دهیم. - از ترمینال، با نقطه ورودی چارچوب تماس بگیرید تا DAG آموزشی SageMaker Pipeline را ایجاد یا بهروزرسانی کرده و اجرا کنید:
- لولههای SageMaker را که روی آن اجرا میشوند، مشاهده و اشکالزدایی کنید خطوط لوله تب SageMaker Studio UI.
ساختار فایل پیکربندی
دو نوع فایل پیکربندی در راه حل پیشنهادی وجود دارد: پیکربندی چارچوب و پیکربندی مدل. در این بخش هر کدام را به تفصیل شرح می دهیم.
پیکربندی چارچوب
La /framework/conf/conf.yaml فایل متغیرهایی را که در همه واحدهای مدل سازی مشترک هستند را تنظیم می کند. این شامل SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPSو SMP_MODELNAME. برای توضیحات این متغیرها و نحوه تنظیم آنها از طریق متغیرهای محیطی به مرحله 3 دستورالعمل استقرار مراجعه کنید.
پیکربندی مدل
برای هر مدل در پروژه باید موارد زیر را در قسمت مشخص کنیم <MODEL-DIR>/conf/conf.yaml فایل (ستاره بخشهای مورد نیاز را نشان میدهد؛ بقیه اختیاری هستند):
- /conf/models* – در این قسمت می توانید یک یا چند واحد مدل سازی را پیکربندی کنید. هنگامی که کد فریمورک اجرا می شود، به طور خودکار تمام فایل های پیکربندی را در طول زمان اجرا می خواند و آنها را به درخت پیکربندی اضافه می کند. از نظر تئوری، شما می توانید تمام واحدهای مدل سازی را به صورت یکسان مشخص کنید
conf.yamlفایل، اما توصیه می شود برای به حداقل رساندن خطاها، پیکربندی هر واحد مدلسازی را در فهرست مربوطه یا مخزن Git مشخص کنید. واحدها به شرح زیر است:- {نام مدل}* – نام مدل
- منبع_دایرکتوری* - مشترک
source_dirمسیری که باید برای تمام مراحل داخل واحد مدل سازی استفاده شود. - پیش پردازش – این بخش پارامترهای پیش پردازش را مشخص می کند.
- قطار - تعلیم دادن* – این قسمت پارامترهای شغل آموزشی را مشخص می کند.
- تبدیل* – این بخش پارامترهای شغلی SageMaker Transform را برای پیش بینی داده های تست مشخص می کند.
- ارزیابی – این بخش پارامترهای شغلی SageMaker Processing را برای ایجاد گزارش JSON معیارهای مدل برای مدل آموزش دیده مشخص می کند.
- ثبت* – این قسمت پارامترهایی را برای ثبت مدل آموزش دیده در SageMaker Model Registry مشخص می کند.
- /conf/sagemakerPipeline* – این بخش جریان لوله های SageMaker را شامل وابستگی های بین مراحل تعریف می کند. برای موارد استفاده تک مدل، این بخش در انتهای فایل پیکربندی تعریف شده است. برای موارد استفاده چند مدل،
sagemakerPipelineبخش فقط باید در فایل پیکربندی یکی از مدل ها (هر یک از مدل ها) تعریف شود. ما به این مدل به عنوان مدل لنگر. پارامترها به شرح زیر است:- خط لوله نام* – نام خط لوله SageMaker.
- مدل* - لیست تودرتو از واحدهای مدل سازی:
- {نام مدل}* – شناسه مدل، که باید با شناسه {model-name} در بخش /conf/models مطابقت داشته باشد.
- مراحل* -
- مرحله_نام* – نام مرحله برای نمایش در SageMaker Pipelines DAG.
- مرحله_کلاس* - (اتحادیه[پردازش، آموزش، ایجاد مدل، تبدیل، متریک، RegisterModel])
- مرحله_نوع* – این پارامتر فقط برای مراحل پیش پردازش مورد نیاز است که برای آن باید روی پیش پردازش تنظیم شود. این برای تشخیص مراحل پیش پردازش و ارزیابی مراحل، که هر دو دارای یک هستند، مورد نیاز است
step_classپردازش - enable_cache – ([اتحاد[درست، نادرست]]). این نشان می دهد که آیا فعال شود یا خیر ذخیره سازی SageMaker Pipelines برای این مرحله
- chain_input_source_step - ([لیست[نام_گام]]). می توانید از این برای تنظیم خروجی کانال یک مرحله دیگر به عنوان ورودی این مرحله استفاده کنید.
- chain_input_additional_prefix - این فقط برای مراحل Transform مجاز است
step_class، و می تواند همراه باchain_input_source_stepپارامتر برای مشخص کردن فایلی که باید به عنوان ورودی مرحله تبدیل استفاده شود.
- مراحل* -
- {نام مدل}* – شناسه مدل، که باید با شناسه {model-name} در بخش /conf/models مطابقت داشته باشد.
- وابستگی – این بخش دنباله ای را مشخص می کند که مراحل SageMaker Pipelines باید در آن اجرا شود. ما نماد Apache Airflow را برای این بخش تطبیق داده ایم (به عنوان مثال،
{step_name} >> {step_name}). اگر این بخش خالی بماند، وابستگیهای صریح مشخص شده توسطchain_input_source_stepپارامتر یا وابستگی های ضمنی جریان SageMaker Pipelines DAG را تعریف می کند.
توجه داشته باشید که توصیه می کنیم برای هر واحد مدلسازی یک مرحله آموزشی داشته باشید. اگر چندین مرحله آموزشی برای یک واحد مدلسازی تعریف شده باشد، مراحل بعدی به طور ضمنی آخرین مرحله آموزشی را برای ایجاد شی مدل، محاسبه معیارها و ثبت مدل انجام میدهند. اگر نیاز به آموزش چندین مدل دارید، توصیه می شود چندین واحد مدل سازی ایجاد کنید.
مثال ها
در این بخش، سه نمونه از DAG های آموزشی مدل ML ایجاد شده با استفاده از چارچوب ارائه شده را نشان می دهیم.
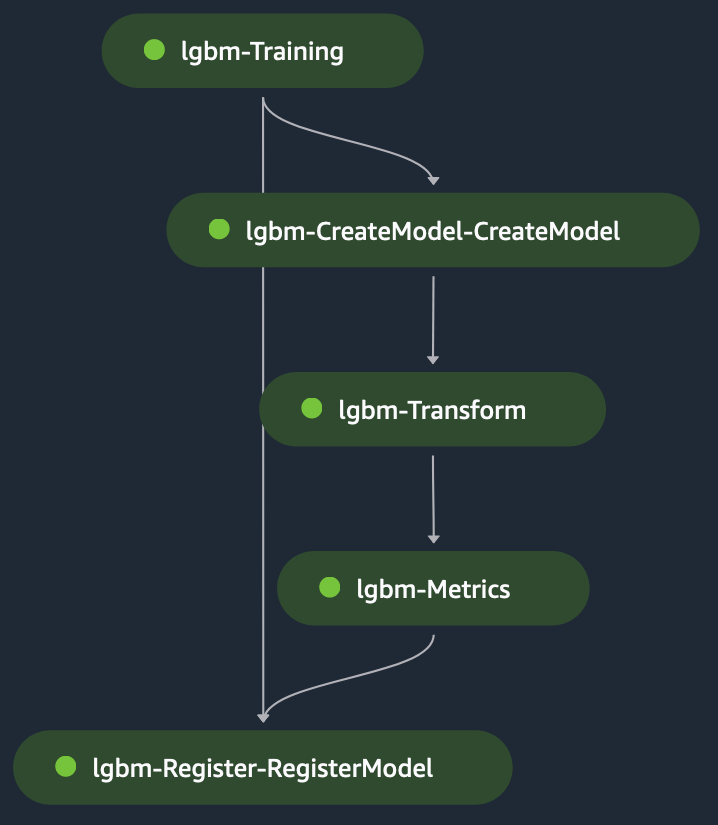
آموزش تک مدل: LightGBM
این یک مثال تک مدلی برای یک مورد استفاده طبقه بندی است که در آن از آن استفاده می کنیم LightGBM در حالت اسکریپت در SageMaker. مجموعه داده متشکل از متغیرهای طبقهای و عددی برای پیشبینی درآمد برچسب باینری (برای پیشبینی اینکه آیا موضوع خریدی انجام میدهد یا خیر). را اسکریپت پیش پردازش برای مدل سازی داده ها برای آموزش و آزمایش و سپس استفاده می شود آن را در یک سطل S3 قرار دهید. سپس مسیرهای S3 در اختیار شما قرار می گیرد مرحله آموزش در فایل پیکربندی
هنگامی که مرحله آموزش اجرا می شود، SageMaker فایل را در ظرف بارگیری می کند /opt/ml/input/data/{channelName}/، از طریق متغیر محیطی قابل دسترسی است SM_CHANNEL_{channelName} روی ظرف (channelName= 'train' یا 'test') اسکریپت آموزشی موارد زیر را انجام می دهد:
- فایل ها را به صورت محلی از مسیرهای کانتینر محلی با استفاده از بارگیری کنید بار NumPy ماژول
- تنظیم فراپارامترها برای الگوریتم آموزشی.
- مدل آموزش دیده را در مسیر کانتینر محلی ذخیره کنید
/opt/ml/model/.
SageMaker محتوا را تحت /opt/ml/model/ قرار می دهد تا یک tarball ایجاد کند که برای استقرار مدل در SageMaker برای میزبانی استفاده می شود.
مرحله تبدیل به عنوان ورودی مرحله بندی می شود فایل تست به عنوان ورودی و مدل آموزش دیده برای پیش بینی در مدل آموزش دیده. خروجی مرحله تبدیل است زنجیر شده به مرحله متریک برای ارزیابی مدل در برابر حقیقت زمین، که به صراحت به مرحله متریک ارائه می شود. در نهایت، خروجی مرحله متریک به طور ضمنی به مرحله ثبت زنجیر می شود تا مدل در SageMaker Model Registry با اطلاعات مربوط به عملکرد مدل تولید شده در مرحله متریک ثبت شود. شکل زیر نمایش تصویری از DAG آموزشی را نشان می دهد. برای این مثال می توانید به اسکریپت ها و فایل پیکربندی مراجعه کنید GitHub repo.
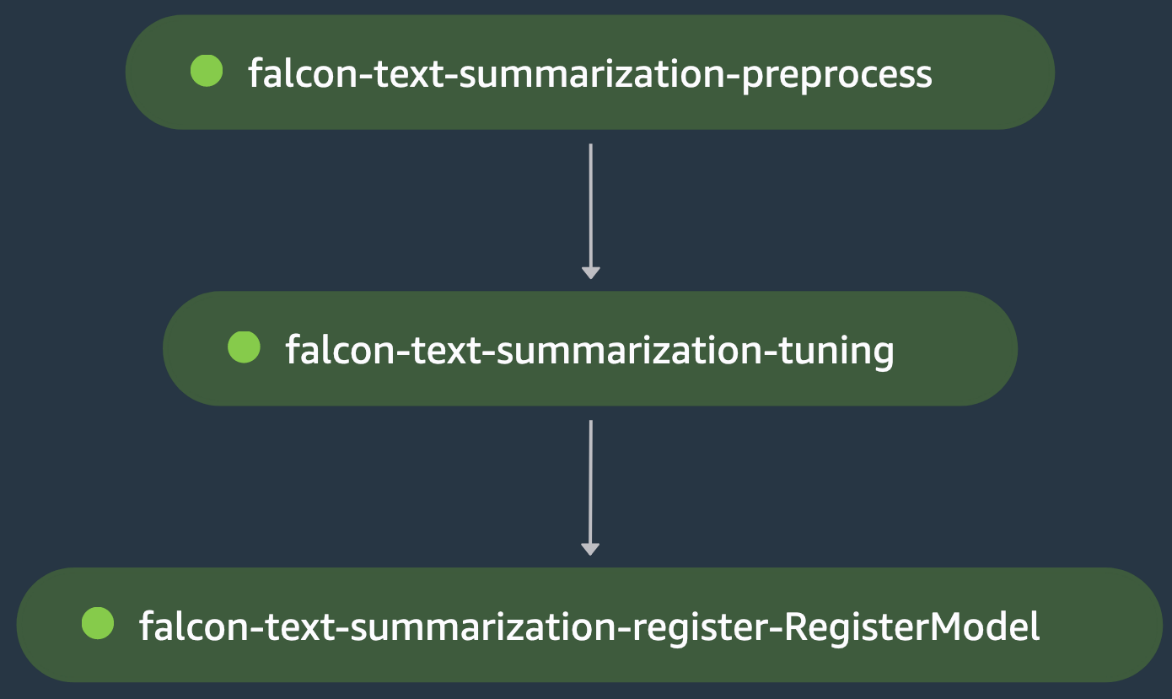
آموزش تک مدل: تنظیم دقیق LLM
این یکی دیگر از نمونه های آموزشی تک مدلی است، که در آن ما تنظیم دقیق یک مدل زبان بزرگ Falcon-40B (LLM) را از Hugging Face Hub برای یک مورد استفاده از خلاصه سازی متن هماهنگ می کنیم. را اسکریپت پیش پردازش بارگیری می کند سموم مجموعه داده از Hugging Face، نشانهساز را برای مدل بارگیری میکند، و تقسیمبندی دادههای قطار/آزمایش را برای تنظیم دقیق مدل روی دادههای این دامنه در مرحله فالکون-متن-خلاصه-پیش پردازش پردازش میکند.
خروجی است زنجیر شده به مرحله شاهین-متن-خلاصه-تنظیم، که در آن اسکریپت آموزشی Falcon-40B LLM را از Hugging Face Hub بارگیری می کند و تنظیم دقیق را با استفاده از آن شروع می کند LoRA در تقسیم قطار مدل در همان مرحله پس از تنظیم دقیق ارزیابی می شود که دروازه بانان ضرر ارزیابی برای شکست در مرحله تنظیم-خلاصه-تست شاهین، که باعث می شود خط لوله SageMaker قبل از اینکه بتواند مدل تنظیم شده را ثبت کند متوقف شود. در غیر این صورت، مرحله falcon-text-summarization-tuning با موفقیت اجرا می شود و مدل در SageMaker Model Registry ثبت می شود. شکل زیر یک نمایش بصری از DAG تنظیم دقیق LLM را نشان می دهد. اسکریپت ها و فایل پیکربندی برای این مثال در دسترس هستند GitHub repo.
آموزش چند مدل
این یک مثال آموزشی چند مدلی است که در آن یک مدل تجزیه و تحلیل مؤلفه اصلی (PCA) برای کاهش ابعاد آموزش داده شده است، و یک مدل پرسپترون چند لایه TensorFlow آموزش داده شده است. پیش بینی قیمت مسکن در کالیفرنیا. مرحله پیش پردازش مدل TensorFlow از یک مدل PCA آموزش دیده برای کاهش ابعاد داده های آموزشی خود استفاده می کند. ما یک وابستگی به پیکربندی اضافه می کنیم تا مطمئن شویم که مدل TensorFlow پس از ثبت مدل PCA ثبت شده است. شکل زیر یک نمایش تصویری از نمونه آموزش چند مدل DAG را نشان می دهد. اسکریپت ها و فایل های پیکربندی برای این مثال در دسترس هستند GitHub repo.

پاک کردن
مراحل زیر را برای پاکسازی منابع خود انجام دهید:
- از AWS CLI استفاده کنید فهرست و برداشتن هر خط لوله باقی مانده ای که توسط اسکریپت های پایتون ایجاد می شود.
- به صورت اختیاری، سایر منابع AWS مانند سطل S3 یا نقش IAM ایجاد شده در خارج از SageMaker Pipelines را حذف کنید.
نتیجه
در این پست، ما چارچوبی را برای خودکارسازی SageMaker Pipelines DAG بر اساس فایل های پیکربندی ارائه کردیم. چارچوب پیشنهادی یک راهحل آیندهنگر برای چالش تنظیم حجمهای کاری پیچیده ML ارائه میکند. با استفاده از یک فایل پیکربندی، SageMaker Pipelines انعطافپذیری را برای ایجاد ارکستراسیون با حداقل کد فراهم میکند، بنابراین میتوانید فرآیند ایجاد و مدیریت خطوط لوله تک مدل و چند مدل را ساده کنید. این رویکرد نه تنها باعث صرفه جویی در زمان و منابع می شود، بلکه بهترین شیوه های MLOps را نیز ترویج می کند و به موفقیت کلی طرح های ML کمک می کند. برای اطلاعات بیشتر در مورد جزئیات پیاده سازی، بررسی کنید GitHub repo.
درباره نویسنده
 لوئیس فیلیپه یپز باریوس، یک مهندس یادگیری ماشین با خدمات حرفه ای AWS است که بر روی سیستم های توزیع شده مقیاس پذیر و ابزارهای اتوماسیون برای تسریع نوآوری علمی در زمینه یادگیری ماشین (ML) متمرکز شده است. علاوه بر این، او به مشتریان سازمانی در بهینه سازی راه حل های یادگیری ماشین خود از طریق خدمات AWS کمک می کند.
لوئیس فیلیپه یپز باریوس، یک مهندس یادگیری ماشین با خدمات حرفه ای AWS است که بر روی سیستم های توزیع شده مقیاس پذیر و ابزارهای اتوماسیون برای تسریع نوآوری علمی در زمینه یادگیری ماشین (ML) متمرکز شده است. علاوه بر این، او به مشتریان سازمانی در بهینه سازی راه حل های یادگیری ماشین خود از طریق خدمات AWS کمک می کند.
 جینژائو فنگ، مهندس یادگیری ماشین در AWS Professional Services است. او بر روی معماری و پیادهسازی راهحلهای خط لوله هوش مصنوعی و کلاسیک ML در مقیاس بزرگ تمرکز دارد. او در FMOps، LLMOps و آموزش های توزیع شده تخصص دارد.
جینژائو فنگ، مهندس یادگیری ماشین در AWS Professional Services است. او بر روی معماری و پیادهسازی راهحلهای خط لوله هوش مصنوعی و کلاسیک ML در مقیاس بزرگ تمرکز دارد. او در FMOps، LLMOps و آموزش های توزیع شده تخصص دارد.
 خشن اسنانی، مهندس یادگیری ماشین در AWS است. پیشینه او در علم داده کاربردی با تمرکز بر عملیاتی کردن بارهای کاری یادگیری ماشین در فضای ابری در مقیاس است.
خشن اسنانی، مهندس یادگیری ماشین در AWS است. پیشینه او در علم داده کاربردی با تمرکز بر عملیاتی کردن بارهای کاری یادگیری ماشین در فضای ابری در مقیاس است.
 حسن شجاعی، یک دانشمند داده Sr. با خدمات حرفه ای AWS است که به مشتریان در صنایع مختلف کمک می کند تا چالش های تجاری خود را از طریق استفاده از داده های بزرگ، یادگیری ماشین و فناوری های ابری حل کنند. قبل از این نقش، حسن ابتکارات متعددی را برای توسعه تکنیکهای مدلسازی مبتنی بر فیزیک و دادهمحور برای شرکتهای برتر انرژی رهبری کرد. خارج از کار، حسن به کتاب، پیاده روی، عکاسی و تاریخ علاقه زیادی دارد.
حسن شجاعی، یک دانشمند داده Sr. با خدمات حرفه ای AWS است که به مشتریان در صنایع مختلف کمک می کند تا چالش های تجاری خود را از طریق استفاده از داده های بزرگ، یادگیری ماشین و فناوری های ابری حل کنند. قبل از این نقش، حسن ابتکارات متعددی را برای توسعه تکنیکهای مدلسازی مبتنی بر فیزیک و دادهمحور برای شرکتهای برتر انرژی رهبری کرد. خارج از کار، حسن به کتاب، پیاده روی، عکاسی و تاریخ علاقه زیادی دارد.
 الک جناب، یک مهندس یادگیری ماشین است که در توسعه و عملیاتی کردن راه حل های یادگیری ماشین در مقیاس برای مشتریان سازمانی تخصص دارد. الک مشتاق ارائه راه حل های نوآورانه به بازار است، به ویژه در زمینه هایی که یادگیری ماشینی می تواند تجربه کاربر نهایی را به طور معناداری بهبود بخشد. خارج از محل کار، او از بازی بسکتبال، اسنوبورد و کشف جواهرات پنهان در سانفرانسیسکو لذت می برد.
الک جناب، یک مهندس یادگیری ماشین است که در توسعه و عملیاتی کردن راه حل های یادگیری ماشین در مقیاس برای مشتریان سازمانی تخصص دارد. الک مشتاق ارائه راه حل های نوآورانه به بازار است، به ویژه در زمینه هایی که یادگیری ماشینی می تواند تجربه کاربر نهایی را به طور معناداری بهبود بخشد. خارج از محل کار، او از بازی بسکتبال، اسنوبورد و کشف جواهرات پنهان در سانفرانسیسکو لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

