En enero 2024, Amazon SageMaker lanzó una nueva versión (0.26.0) de contenedores de aprendizaje profundo (DLC) de inferencia de modelos grandes (LMI). Esta versión ofrece soporte para nuevos modelos (incluida la combinación de expertos), mejoras de rendimiento y usabilidad en todos los backends de inferencia, así como detalles de nueva generación para un mayor control y explicabilidad de la predicción (como el motivo de la finalización de la generación y las probabilidades de registro a nivel de token).
Los DLC de LMI ofrecen una interfaz de código bajo que simplifica el uso de hardware y técnicas de optimización de inferencias de última generación. LMI le permite aplicar paralelismo tensorial; las últimas técnicas eficientes de atención, procesamiento por lotes, cuantificación y gestión de memoria; transmisión de tokens; y mucho más, simplemente solicitando el ID del modelo y los parámetros opcionales del modelo. Con los DLC de LMI en SageMaker, puede acelerar el tiempo de obtención de valor para su inteligencia artificial generativa (IA) aplicaciones, descargue el trabajo pesado relacionado con la infraestructura y optimice los modelos de lenguajes grandes (LLM) para el hardware de su elección para lograr la mejor relación precio-rendimiento de su clase.
En esta publicación, exploramos las funciones más recientes introducidas en esta versión, examinamos puntos de referencia de rendimiento y brindamos una guía detallada sobre la implementación de nuevos LLM con DLC LMI en alto rendimiento.
Nuevas funciones con los DLC de LMI
En esta sección, analizamos las nuevas funciones en los backends de LMI y profundizamos en algunas otras que son específicas del backend. LMI actualmente admite los siguientes backends:
- Biblioteca distribuida por LMI – Este es el marco de AWS para ejecutar inferencia con LLM, inspirado en OSS, para lograr la mejor latencia y precisión posibles en el resultado.
- LMI vLLM – Esta es la implementación backend de AWS de la memoria eficiente vllm biblioteca de inferencia
- Kit de herramientas LMI TensorRT-LLM – Esta es la implementación del backend de AWS de NVIDIA TensorRT-LLM, que crea motores específicos de GPU para optimizar el rendimiento en diferentes GPU
- LMI de velocidad profunda – Esta es la adaptación de AWS de velocidadprofunda, que agrega procesamiento por lotes continuo verdadero, cuantificación SmoothQuant y la capacidad de ajustar dinámicamente la memoria durante la inferencia.
- LMI NeuronX – Puede utilizar esto para la implementación en Inferencia de AWS2 y tren de AWS-instancias basadas en lotes continuos reales y aceleraciones, basadas en el SDK de AWS Neuron
La siguiente tabla resume las características recién agregadas, tanto comunes como específicas del backend.
|
Común en todos los backends |
|||
|
|||
|
Específico del backend |
|||
|
Distribuido por LMI |
vllm | TensorRT-LLM |
NeuronaX |
|
|
|
|
Nuevos modelos compatibles
Se admiten nuevos modelos populares en todos los backends, como Mistral-7B (todos los backends), Mixtral basado en MoE (todos los backends excepto Transformers-NeuronX) y Llama2-70B (Transformers-NeuronX).
Técnicas de extensión de ventanas de contexto
El escalado de contexto basado en Rotary Positional Embedding (RoPE) ahora está disponible en los backends LMI-Dist, vLLM y TensorRT-LLM. El escalado de RoPE permite la extensión de la longitud de la secuencia de un modelo durante la inferencia a prácticamente cualquier tamaño, sin necesidad de realizar ajustes.
Las siguientes son dos consideraciones importantes al utilizar RoPE:
- Modelo de perplejidad – A medida que aumenta la longitud de la secuencia, por lo que puede los modelos perplejidad. Este efecto se puede compensar parcialmente realizando un ajuste mínimo en secuencias de entrada más grandes que las utilizadas en el entrenamiento original. Para obtener una comprensión profunda de cómo RoPE afecta la calidad del modelo, consulte Ampliando el RoPE.
- Rendimiento de inferencia – Las secuencias de mayor longitud consumirán la memoria de mayor ancho de banda (HBM) del acelerador. Este mayor uso de memoria puede afectar negativamente la cantidad de solicitudes simultáneas que su acelerador puede manejar.
Detalles de generación agregados
Ahora puede obtener dos detalles detallados sobre los resultados de la generación:
- razón_finalización – Esto proporciona el motivo para completar la generación, que puede ser alcanzar la longitud máxima de generación, generar un token de fin de oración (EOS) o generar un token de parada definido por el usuario. Se devuelve con el último fragmento de secuencia transmitido.
- log_probs – Esto devuelve la probabilidad logarítmica asignada por el modelo para cada token en el fragmento de secuencia transmitida. Puede utilizarlos como una estimación aproximada de la confianza del modelo calculando la probabilidad conjunta de una secuencia como la suma de los
log_probsde los tokens individuales, que pueden ser útiles para calificar y clasificar los resultados del modelo. Tenga en cuenta que las probabilidades de los tokens LLM generalmente son demasiado confiadas sin calibración.
Puede habilitar la salida de resultados de generación agregando detalles = Verdadero en su carga útil de entrada a LMI, dejando todos los demás parámetros sin cambios:
payload = {“inputs”:“your prompt”,
“parameters”:{max_new_tokens”:256,...,“details”:True}
}Parámetros de configuración consolidados
Finalmente, también se han consolidado los parámetros de configuración de LMI. Para obtener más información sobre todos los parámetros de configuración de implementación comunes y específicos del backend, consulte Configuraciones de inferencia de modelos grandes.
Backend distribuido por LMI
En AWS re:Invent 2023, LMI-Dist agregó operaciones colectivas nuevas y optimizadas para acelerar la comunicación entre GPU, lo que resulta en una menor latencia y un mayor rendimiento para modelos que son demasiado grandes para una sola GPU. Estos colectivos están disponibles exclusivamente para SageMaker, para instancias de p4d.
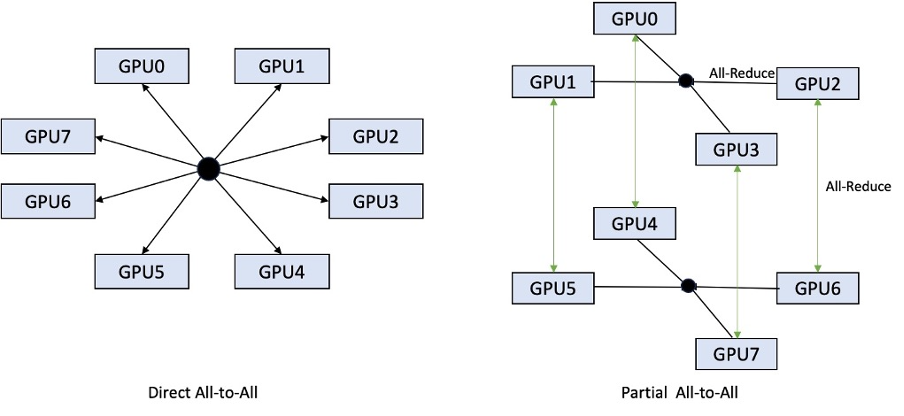
Mientras que la iteración anterior solo admitía la fragmentación en las 8 GPU, LMI 0.26.0 introduce soporte para un grado de tensor paralelo de 4, en un patrón parcial de todos a todos. Esto se puede combinar con Componentes de inferencia de SageMaker, con el que puede configurar de forma granular cuántos aceleradores se deben asignar a cada modelo implementado detrás de un punto final. Juntas, estas características brindan un mejor control sobre la utilización de recursos de la instancia subyacente, lo que le permite aumentar la tenencia múltiple del modelo hospedando diferentes modelos detrás de un punto final o ajustar el rendimiento agregado de su implementación para que coincida con su modelo y las características del tráfico.
La siguiente figura compara el total directo con el total parcial.
Backend de TensorRT-LLM
TensorRT-LLM de NVIDIA se introdujo como parte de la versión anterior del DLC de LMI (0.25.0), lo que permite un rendimiento de GPU de última generación y optimizaciones como SmoothQuant, FP8 y procesamiento por lotes continuo para LLM cuando se utilizan GPU de NVIDIA.
TensorRT-LLM requiere que los modelos se compilen en motores eficientes antes de su implementación. El DLC LMI TensorRT-LLM puede encargarse automáticamente de compilar una lista de modelos compatibles justo a tiempo (JIT), antes de iniciar el servidor y cargar el modelo para inferencia en tiempo real. La versión 0.26.0 del DLC aumenta la lista de modelos compatibles para la compilación JIT, presentando los modelos Baichuan, ChatGLM, GPT2, GPT-J, InternLM, Mistral, Mixtral, Qwen, SantaCoder y StarCoder.
La compilación JIT agrega varios minutos de sobrecarga al tiempo de escalado y aprovisionamiento de endpoints, por lo que siempre se recomienda compilar el modelo con anticipación. Para obtener una guía sobre cómo hacer esto y una lista de modelos compatibles, consulte Tutorial de compilación anticipada de modelos de TensorRT-LLM. Si el modelo seleccionado aún no es compatible, consulte Tutorial de compilación manual de modelos de TensorRT-LLM para compilar cualquier otro modelo que sea compatible con TensorRT-LLM.
Además, LMI ahora expone la cuantificación nativa de TensorRT-LLM SmootQuant, con parámetros para controlar el factor alfa y de escala por token o canal. Para obtener más información sobre las configuraciones relacionadas, consulte TensorRT-LLM.
back-end de vLLM
La versión actualizada de vLLM incluida en LMI DLC presenta mejoras de rendimiento de hasta un 50% impulsadas por el modo gráfico CUDA en lugar del modo ansioso. Los gráficos CUDA aceleran las cargas de trabajo de la GPU al iniciar varias operaciones de GPU a la vez en lugar de iniciarlas individualmente, lo que reduce los gastos generales. Esto es particularmente efectivo para modelos pequeños cuando se usa paralelismo tensorial.
El rendimiento adicional se obtiene a cambio del consumo adicional de memoria de la GPU. El modo de gráfico CUDA ahora es predeterminado para el backend vLLM, por lo que si tiene limitaciones en la cantidad de memoria de GPU disponible, puede configurar option.enforce_eager=True para forzar el modo ansioso de PyTorch.
Backend de Transformers-NeuronX
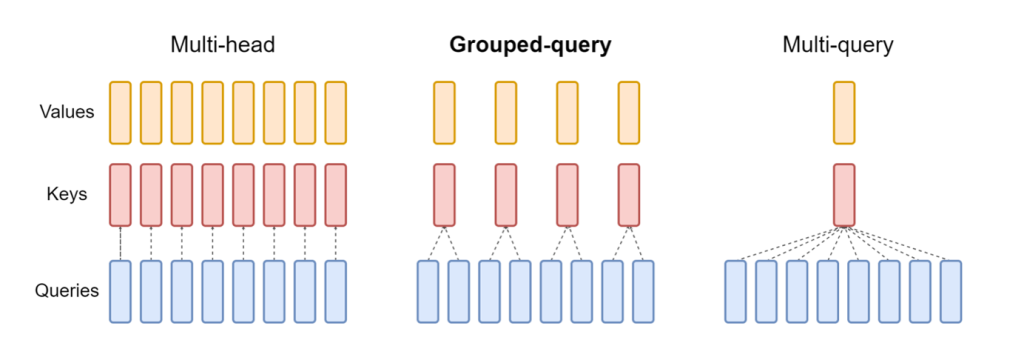
La versión actualizada de NeuronaX incluido en el DLC LMI NeuronX ahora admite modelos que cuentan con el mecanismo de atención de consultas agrupadas, como Mistral-7B y LLama2-70B. La atención de consultas agrupadas es una optimización importante del mecanismo de atención del transformador predeterminado, donde el modelo se entrena con menos cabezas de claves y valores que cabezas de consulta. Esto reduce el tamaño de la caché KV en la memoria de la GPU, lo que permite una mayor simultaneidad y mejora la relación precio-rendimiento.
La siguiente figura ilustra los métodos de atención de múltiples encabezados, consultas agrupadas y múltiples consultas (fuente).
Hay diferentes estrategias de fragmentación de caché KV disponibles para adaptarse a diferentes tipos de cargas de trabajo. Para obtener más información sobre estrategias de fragmentación, consulte Soporte de atención de consultas agrupadas (GQA). Puede habilitar la estrategia que desee (shard-over-heads, por ejemplo) con el siguiente código:
Además, la nueva implementación de NeuronX DLC introduce una API de caché para TransformerNeuronX que permite el acceso a la caché de KV. Le permite insertar y eliminar filas de caché KV de nuevas solicitudes mientras realiza inferencias por lotes. Antes de introducir esta API, se volvió a calcular la caché KV para cualquier solicitud recién agregada. En comparación con LMI V7 (0.25.0), hemos mejorado la latencia en más de un 33 % con solicitudes simultáneas y admitimos un rendimiento mucho mayor.
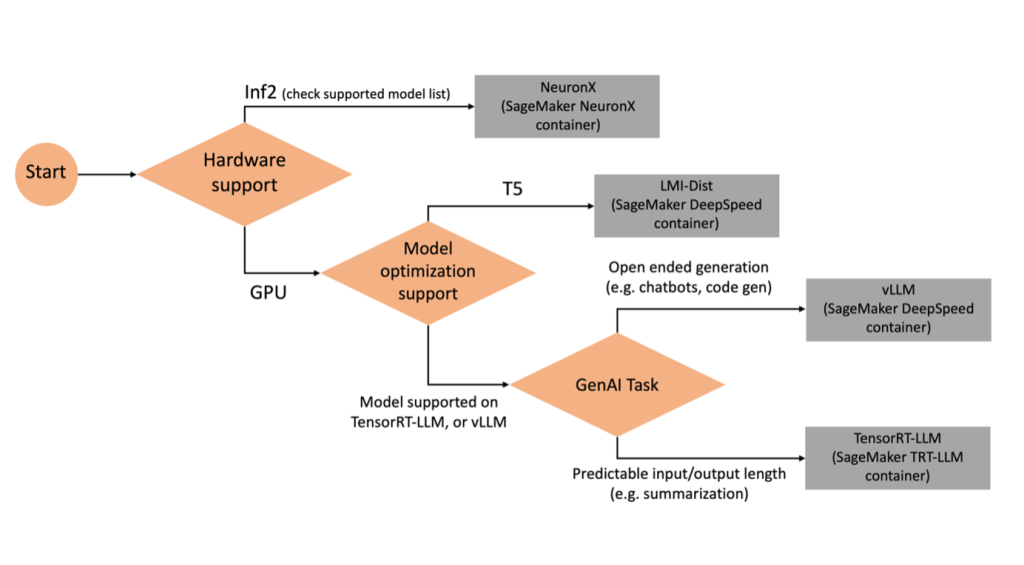
Seleccionar el backend correcto
Para decidir qué backend usar según el modelo y la tarea seleccionados, utilice el siguiente diagrama de flujo. Para obtener guías de usuario de backend individuales junto con los modelos compatibles, consulte Guías del usuario del backend de LMI.
Implemente Mixtral con LMI DLC con atributos adicionales
Veamos cómo puede implementar el modelo Mixtral-8x7B con el contenedor LMI 0.26.0 y generar detalles adicionales como log_prob y finish_reason como parte de la salida. También analizamos cómo puede beneficiarse de estos atributos adicionales a través de un caso de uso de generación de contenido.
El cuaderno completo con instrucciones detalladas está disponible en el Repositorio GitHub.
Empezamos importando las bibliotecas y configurando el entorno de la sesión:
Puede utilizar contenedores LMI de SageMaker para alojar modelos sin ningún código de inferencia adicional. Puede configurar el servidor modelo ya sea a través de las variables de entorno o un serving.properties archivo. Opcionalmente, podría tener un model.py archivo para cualquier preprocesamiento o posprocesamiento y un requirements.txt archivo para cualquier paquete adicional que deba instalarse.
En este caso utilizamos el serving.properties para configurar los parámetros y personalizar el comportamiento del contenedor LMI. Para obtener más detalles, consulte la Repositorio GitHub. El repositorio explica los detalles de los diversos parámetros de configuración que puede establecer. Necesitamos los siguientes parámetros clave:
- motor – Especifica el motor de ejecución que utilizará DJL. Esto impulsa la fragmentación y la estrategia de carga del modelo en los aceleradores del modelo.
- opción.model_id – Especifica el Servicio de almacenamiento simple de Amazon (Amazon S3) URI del modelo previamente entrenado o ID de modelo de un modelo previamente entrenado alojado dentro de un repositorio de modelos en Abrazando la cara. En este caso, proporcionamos el ID del modelo Mixtral-8x7B.
- opción.tensor_parallel_degree – Establece la cantidad de dispositivos GPU sobre los cuales Accelerate necesita particionar el modelo. Este parámetro también controla la cantidad de trabajadores por modelo que se iniciarán cuando se ejecute el servicio DJL. Establecemos este valor en
max(GPU máxima en la máquina actual). - opción.rolling_batch – Permite el procesamiento por lotes continuo para optimizar la utilización del acelerador y el rendimiento general. Para el contenedor TensorRT-LLM, usamos
auto. - opción.model_loading_timeout – Establece el valor de tiempo de espera para descargar y cargar el modelo para realizar inferencias.
- opción.max_rolling_batch – Establece el tamaño máximo del lote continuo, definiendo cuántas secuencias se pueden procesar en paralelo en un momento dado.
Empaquetamos el serving.properties archivo de configuración en formato tar.gz, para que cumpla con los requisitos de alojamiento de SageMaker. Configuramos el contenedor DJL LMI con tensorrtllm como motor de backend. Además, especificamos la última versión del contenedor (0.26.0).
A continuación, cargamos el archivo tar local (que contiene el serving.properties archivo de configuración) a un prefijo S3. Usamos el URI de imagen para el contenedor DJL y la ubicación de Amazon S3 en la que se cargó el tarball de artefactos que sirve el modelo, para crear el objeto de modelo de SageMaker.
Como parte de LMI 0.26.0, ahora puede utilizar dos detalles adicionales detallados sobre la salida generada:
- log_probs – Esta es la probabilidad logarítmica asignada por el modelo para cada token en el fragmento de secuencia transmitida. Puede utilizarlos como una estimación aproximada de la confianza del modelo calculando la probabilidad conjunta de una secuencia como la suma de las probabilidades logarítmicas de los tokens individuales, lo que puede resultar útil para puntuar y clasificar los resultados del modelo. Tenga en cuenta que las probabilidades de los tokens LLM generalmente son demasiado confiadas sin calibración.
- razón_finalización – Este es el motivo de la finalización de la generación, que puede ser alcanzar la duración máxima de generación, generar un token EOS o generar un token de parada definido por el usuario. Esto se devuelve con el último fragmento de secuencia transmitido.
Puede habilitarlos pasando "details"=True como parte de su aportación al modelo.
Veamos cómo puedes generar estos detalles. Usamos un ejemplo de generación de contenido para comprender su aplicación.
Definimos una LineIterator Clase auxiliar, que tiene funciones para recuperar bytes de forma perezosa de un flujo de respuesta, almacenarlos en un buffer y dividir el buffer en líneas. La idea es servir bytes del búfer mientras se recuperan más bytes de la secuencia de forma asincrónica.
Generar y utilizar la probabilidad de token como detalle adicional.
Considere un caso de uso en el que estamos generando contenido. Específicamente, tenemos la tarea de escribir un breve párrafo sobre los beneficios de hacer ejercicio regularmente para un sitio web centrado en el estilo de vida. Queremos generar contenido y generar una puntuación indicativa de la confianza que tiene el modelo en el contenido generado.
Invocamos el punto final del modelo con nuestro mensaje y capturamos la respuesta generada. Establecimos "details": True como parámetro de tiempo de ejecución dentro de la entrada del modelo. Debido a que la probabilidad logarítmica se genera para cada token de salida, agregamos las probabilidades logarítmicas individuales a una lista. También capturamos el texto completo generado a partir de la respuesta.
Para calcular la puntuación de confianza general, calculamos la media de todas las probabilidades de los tokens individuales y posteriormente obtenemos el valor exponencial entre 0 y 1. Esta es nuestra puntuación de confianza general inferida para el texto generado, que en este caso es un párrafo sobre los beneficios. de ejercicio regular.

Este fue un ejemplo de cómo se puede generar y utilizar log_prob, en el contexto de un caso de uso de generación de contenido. Del mismo modo, puedes utilizar log_prob como medida de puntuación de confianza para casos de uso de clasificación.
Alternativamente, puede usarlo para la secuencia de salida general o la puntuación a nivel de oración para evaluar el efecto de parámetros como la temperatura en la salida generada.
Generar y utilizar el motivo de finalización como detalle adicional.
Basémonos en el mismo caso de uso, pero esta vez tenemos la tarea de escribir un artículo más extenso. Además, queremos asegurarnos de que la salida no se trunca debido a problemas de longitud de generación (longitud máxima del token) o debido a que se encuentran tokens detenidos.
Para lograr esto, utilizamos el finish_reason atributo generado en la salida, monitorear su valor y continuar generando hasta que se genere toda la salida.
Definimos una función de inferencia que toma una entrada de carga útil y llama al punto final de SageMaker, transmite una respuesta y procesa la respuesta para extraer el texto generado. La carga útil contiene el texto del mensaje como entradas y parámetros como tokens máximos y detalles. La respuesta se lee en una secuencia y se procesa línea por línea para extraer los tokens de texto generados en una lista. Extraemos detalles como finish_reason. Llamamos a la función de inferencia en un bucle (solicitudes encadenadas) mientras agregamos más contexto cada vez, y realizamos un seguimiento de la cantidad de tokens generados y la cantidad de solicitudes enviadas hasta que finaliza el modelo.
Como podemos ver, aunque el max_new_token El parámetro está establecido en 256, utilizamos el atributo de detalle Finish_reason como parte de la salida para encadenar múltiples solicitudes al punto final, hasta que se genere la salida completa.

De manera similar, según su caso de uso, puede usar stop_reason para detectar una longitud de secuencia de salida insuficiente especificada para una tarea determinada o una finalización no deseada debido a una secuencia de parada humana.
Conclusión
En esta publicación, analizamos la versión v0.26.0 del contenedor AWS LMI. Destacamos mejoras clave de rendimiento, compatibilidad con nuevos modelos y nuevas funciones de usabilidad. Con estas capacidades, puede equilibrar mejor las características de costo y rendimiento y al mismo tiempo brindar una mejor experiencia a sus usuarios finales.
Para obtener más información sobre las capacidades de LMI DLC, consulte Paralelismo de modelos e inferencia de modelos grandes. Estamos emocionados de ver cómo utiliza estas nuevas capacidades de SageMaker.
Sobre los autores
 joão moura es arquitecto senior de soluciones especializado en IA/ML en AWS. João ayuda a los clientes de AWS (desde pequeñas empresas emergentes hasta grandes empresas) a capacitar e implementar modelos grandes de manera eficiente y, de manera más amplia, a construir plataformas de aprendizaje automático en AWS.
joão moura es arquitecto senior de soluciones especializado en IA/ML en AWS. João ayuda a los clientes de AWS (desde pequeñas empresas emergentes hasta grandes empresas) a capacitar e implementar modelos grandes de manera eficiente y, de manera más amplia, a construir plataformas de aprendizaje automático en AWS.
 Rahul Sharma es arquitecto senior de soluciones en AWS y ayuda a los clientes de AWS a diseñar y crear soluciones de IA/ML. Antes de unirse a AWS, Rahul pasó varios años en el sector financiero y de seguros, ayudando a los clientes a crear plataformas analíticas y de datos.
Rahul Sharma es arquitecto senior de soluciones en AWS y ayuda a los clientes de AWS a diseñar y crear soluciones de IA/ML. Antes de unirse a AWS, Rahul pasó varios años en el sector financiero y de seguros, ayudando a los clientes a crear plataformas analíticas y de datos.
 qing-lan es ingeniero de desarrollo de software en AWS. Ha estado trabajando en varios productos desafiantes en Amazon, incluidas soluciones de inferencia ML de alto rendimiento y un sistema de registro de alto rendimiento. El equipo de Qing lanzó con éxito el primer modelo de mil millones de parámetros en Amazon Advertising con una latencia muy baja requerida. Qing tiene un conocimiento profundo sobre la optimización de la infraestructura y la aceleración del aprendizaje profundo.
qing-lan es ingeniero de desarrollo de software en AWS. Ha estado trabajando en varios productos desafiantes en Amazon, incluidas soluciones de inferencia ML de alto rendimiento y un sistema de registro de alto rendimiento. El equipo de Qing lanzó con éxito el primer modelo de mil millones de parámetros en Amazon Advertising con una latencia muy baja requerida. Qing tiene un conocimiento profundo sobre la optimización de la infraestructura y la aceleración del aprendizaje profundo.
 Jian Sheng es ingeniero de desarrollo de software en Amazon Web Services y ha trabajado en varios aspectos clave de los sistemas de aprendizaje automático. Ha sido un colaborador clave del servicio SageMaker Neo, centrándose en la compilación de aprendizaje profundo y la optimización del tiempo de ejecución del marco. Recientemente, ha dirigido sus esfuerzos y contribuido a optimizar el sistema de aprendizaje automático para la inferencia de modelos grandes.
Jian Sheng es ingeniero de desarrollo de software en Amazon Web Services y ha trabajado en varios aspectos clave de los sistemas de aprendizaje automático. Ha sido un colaborador clave del servicio SageMaker Neo, centrándose en la compilación de aprendizaje profundo y la optimización del tiempo de ejecución del marco. Recientemente, ha dirigido sus esfuerzos y contribuido a optimizar el sistema de aprendizaje automático para la inferencia de modelos grandes.
 Tyler Osterberg es ingeniero de desarrollo de software en AWS. Se especializa en crear experiencias de inferencia de aprendizaje automático de alto rendimiento dentro de SageMaker. Recientemente, su atención se ha centrado en optimizar el rendimiento de los contenedores de aprendizaje profundo de Inferentia en la plataforma SageMaker. Tyler se destaca en la implementación de soluciones de alojamiento de alto rendimiento para modelos de lenguajes grandes y en la mejora de las experiencias de los usuarios utilizando tecnología de vanguardia.
Tyler Osterberg es ingeniero de desarrollo de software en AWS. Se especializa en crear experiencias de inferencia de aprendizaje automático de alto rendimiento dentro de SageMaker. Recientemente, su atención se ha centrado en optimizar el rendimiento de los contenedores de aprendizaje profundo de Inferentia en la plataforma SageMaker. Tyler se destaca en la implementación de soluciones de alojamiento de alto rendimiento para modelos de lenguajes grandes y en la mejora de las experiencias de los usuarios utilizando tecnología de vanguardia.
 Rupinder Grewal es un arquitecto senior de soluciones especializado en IA/ML en AWS. Actualmente se enfoca en servir modelos y MLOps en Amazon SageMaker. Antes de ocupar este puesto, trabajó como ingeniero de aprendizaje automático creando y alojando modelos. Fuera del trabajo, le gusta jugar tenis y andar en bicicleta por senderos de montaña.
Rupinder Grewal es un arquitecto senior de soluciones especializado en IA/ML en AWS. Actualmente se enfoca en servir modelos y MLOps en Amazon SageMaker. Antes de ocupar este puesto, trabajó como ingeniero de aprendizaje automático creando y alojando modelos. Fuera del trabajo, le gusta jugar tenis y andar en bicicleta por senderos de montaña.
 Patel Dhawal es Arquitecto Principal de Aprendizaje Automático en AWS. Ha trabajado con organizaciones que van desde grandes empresas hasta empresas emergentes medianas en problemas relacionados con la computación distribuida y la inteligencia artificial. Se enfoca en el aprendizaje profundo, incluidos los dominios de NLP y Computer Vision. Ayuda a los clientes a lograr una inferencia de modelos de alto rendimiento en SageMaker.
Patel Dhawal es Arquitecto Principal de Aprendizaje Automático en AWS. Ha trabajado con organizaciones que van desde grandes empresas hasta empresas emergentes medianas en problemas relacionados con la computación distribuida y la inteligencia artificial. Se enfoca en el aprendizaje profundo, incluidos los dominios de NLP y Computer Vision. Ayuda a los clientes a lograr una inferencia de modelos de alto rendimiento en SageMaker.
 Raghu Ramesha es arquitecto sénior de soluciones de aprendizaje automático en el equipo de servicios de Amazon SageMaker. Se centra en ayudar a los clientes a crear, implementar y migrar cargas de trabajo de producción de aprendizaje automático a SageMaker a escala. Se especializa en los dominios de aprendizaje automático, inteligencia artificial y visión por computadora, y tiene una maestría en Ciencias de la Computación de UT Dallas. En su tiempo libre le gusta viajar y la fotografía.
Raghu Ramesha es arquitecto sénior de soluciones de aprendizaje automático en el equipo de servicios de Amazon SageMaker. Se centra en ayudar a los clientes a crear, implementar y migrar cargas de trabajo de producción de aprendizaje automático a SageMaker a escala. Se especializa en los dominios de aprendizaje automático, inteligencia artificial y visión por computadora, y tiene una maestría en Ciencias de la Computación de UT Dallas. En su tiempo libre le gusta viajar y la fotografía.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-mixtral-and-llama-2-models-with-new-amazon-sagemaker-containers/

